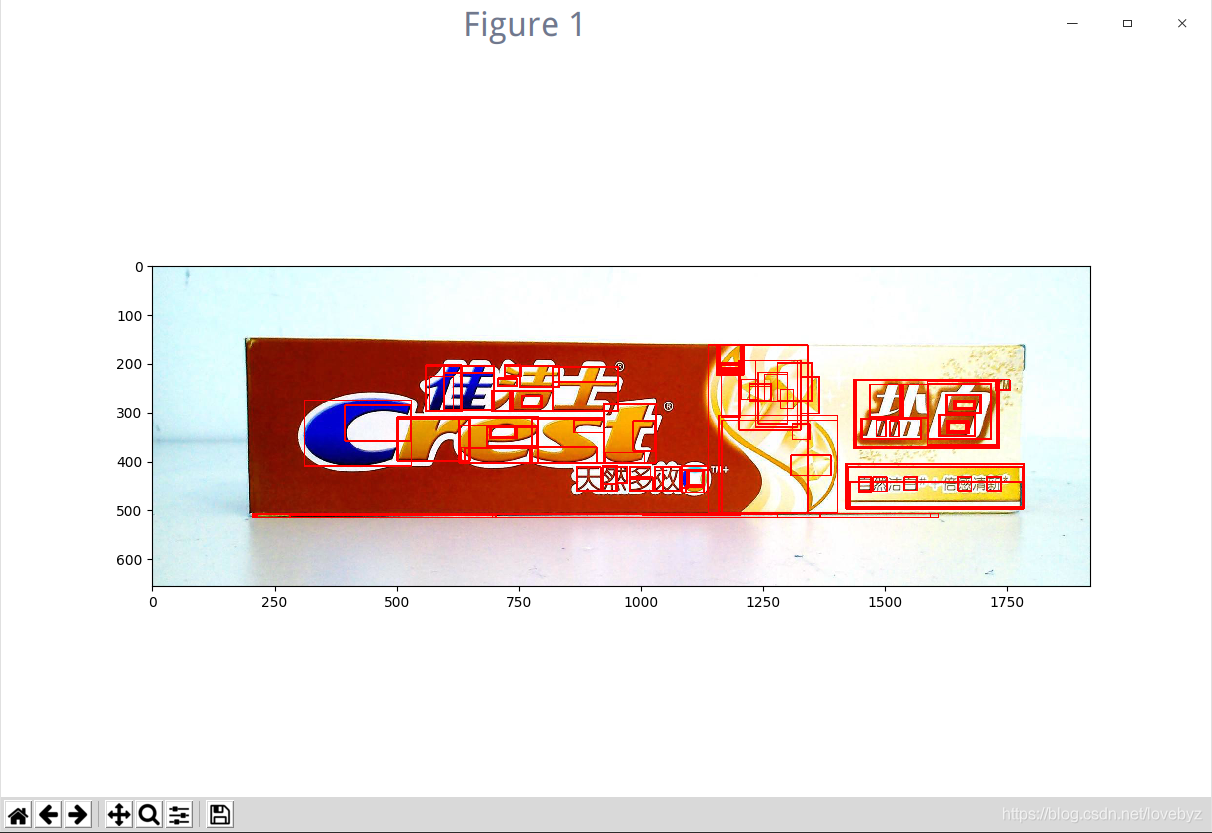
图像识别主要用到了两个第三方的iOS框架:OpenCV和TesseractOCR,OpenCV用来做图像处理,定位到身份证号码的区域,TesseractOCR则是对定位到的区域内的内容进行识别。
OpenCV中的一些简单的处理图像的方法:灰度处理、二值化、腐蚀、边缘检测等等。
Tesseract Open Source OCR Engine (main repository)- https://github.com/tesseract-ocr/tesseract
开源OCR识别彩票内容项目 LotteryHelper- https://github.com/MZCretin/LotteryHelper
图像识别的发展经历了三个阶段:文字识别、数字图像处理与识别、物体识别。神经网络的图像识别技术和非线性降维的图像识别技术及图像识别技术的应用。
模式识别是人工智能和信息科学的重要组成部分。模式识别是指对表示事物或现象的不同形式的信息做分析和处理从而得到一个对事物或现象做出描述、辨认和分类等的过程。
计算机的图像识别技术就是模拟人类的图像识别过程。在图像识别的过程中进行模式识别是必不可少的。模式识别原本是人类的一项基本智能。模式识别主要分为三种:统计模式识别、句法模式识别、模糊模式识别。图像识别问题的数学本质属于模式空间到类别空间的映射问题。
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,并对质量不佳的图像进行一系列的增强与重建技术手段,从而有效改善图像质量。
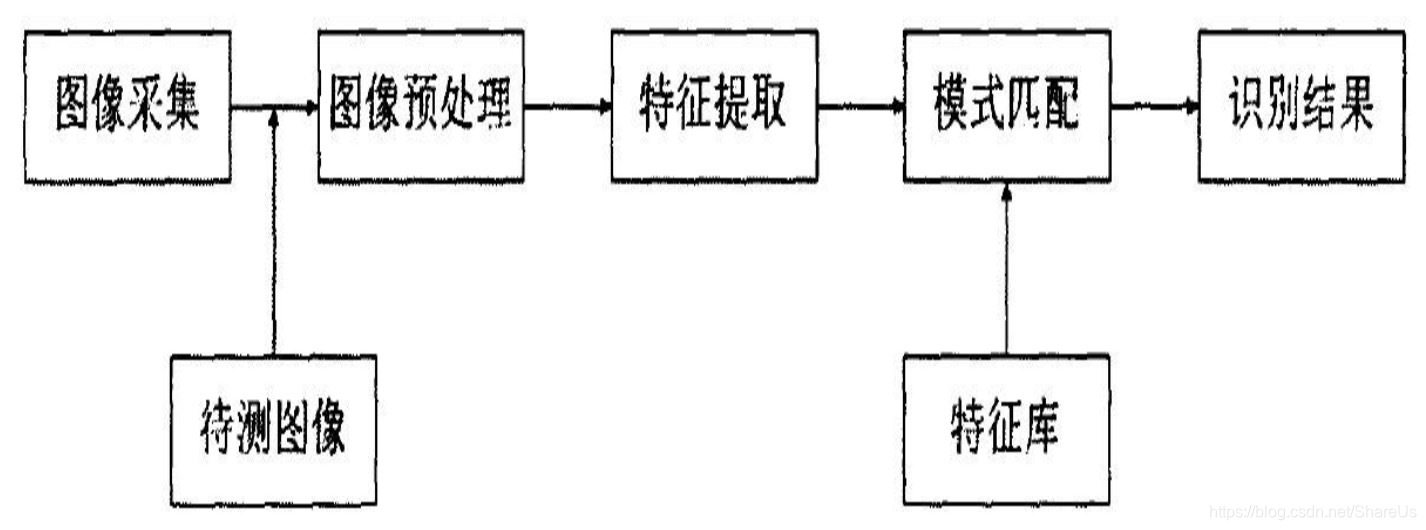
-- 图像识别技术的过程分以下几步:信息的获取、预处理、特征抽取和选择、分类器设计和分类决策。
1.信息的获取是指通过传感器,将光或声音等信息转化为电信息。也就是获取研究对象的基本信息并通过某种方法将其转变为机器能够认识的信息。
2.预处理主要是指图像处理中的去噪、平滑、变换等的操作,从而加强图像的重要特征。
3.特征抽取和选择是指在模式识别中,需要进行特征的抽取和选择。简单的理解就是我们所研究的图像是各式各样的,如果要利用某种方法将它们区分开,就要通过这些图像所具有的本身特征来识别,而获取这些特征的过程就是特征抽取。在特征抽取中所得到的特征也许对此次识别并不都是有用的,这个时候就要提取有用的特征,这就是特征的选择。特征抽取和选择在图像识别过程中是非常关键的技术之一,所以对这一步的理解是图像识别的重点。
4.分类器设计是指通过训练而得到一种识别规则,通过此识别规则可以得到一种特征分类,使图像识别技术能够得到高识别率。分类决策是指在特征空间中对被识别对象进行分类,从而更好地识别所研究的对象具体属于哪一类。
预处理算法:滤波;图像增强;图像分割;预处理算法结果:构成训练样本和测试样本;
特征 提取:形状进行归一化处理;提取各阶矩特征值;特征值进行归一化处理;训练SVM得参数设计电气设备的分类器;
神经网络图像识别技术是一种比较新型的图像识别技术,是在传统的图像识别方法和基础上融合神经网络算法的一种图像识别方法。
在对车牌上的字符进行识别的过程中就用到了基于模板匹配算法和基于人工神经网络算法。想让计算机具有高效地识别能力,最直接有效的方法就是降维。降维分为线性降维和非线性降维。例如主成分分析(PCA)和线性奇异分析(LDA)等就是常见的线性降维方法,它们的特点是简单、易于理解。
计算机的图像识别技术在公共安全、生物、工业、农业、交通、医疗等很多领域都有应用。例如交通方面的车牌识别系统;公共安全方面的人脸识别技术、指纹识别技术;农业方面的种子识别技术、食品品质检测技术;医学方面的心电图识别技术等。
图像识别技术是立体视觉、运动分析、数据融合等实用技术的基础,在导航、地图与地形配准、自然资源分析、天气预报、环境监测、生理病变研究等许多领域可广泛应用。
图像识别主要包括有对模板库图像样本的训练和对待测试图像样本的分类识别两部分。样本图像训练的基本思想是将样本图像的特征所属的类别构成模板库;图像识别的基本思想是按照训练过程中的特征提取方法,提取待测样本的特征与模板库中的训练样本进行匹配,匹配程度最高的即为识别结果。
动态图像识别技术。
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对像的技术。图像识别是人工智能的一个重要领域。目前主要的图像识别方法有基于神经网络的图像识别方法、基于小波矩的图像识别方法等。
作为图像识别技术的基础操作,通过对采集到的图像进行増强、恢复、边缘检测W及分割等预处理操作来提高图像的质量。
图像的增强主要通过对采集图像进行灰度变换、滤波、锐化等一系列操作,提髙图像质量及其视觉效果的清晰度,使图像能够更加适用于计算机的进一步分析和处理。
通常可将图像噪声大致分为高斯噪声、椒盐噪声和颗粒噪声H类U"。
常用的图像锐化算法有;梯度算子法、Roberts算子法、Sobel算子法、Prewitt算子法以及拉普拉斯算子法等。
图像分割的基本思想是将图像分割成若干个互不相关的具有相似或一致性特征的目标区域。分割方法的选取取决于图像中目标的特征,这些特征可以是目标的颜色、几何形状、灰度值或者空间纹理等。
图像特征提取的基本思想是依据图像中目标的特性,将其分割为不同的子集后,提取出所需的图像目标特征,其目的在于求出对图像中目标的分类最为有效的特征,使识别的性能达到最佳。对于图像的识别来讲,提取出最能反映分类本质的图像特征以及如何提取这些特征是图像识别技术的关键。常见的特征提取法有基于颜色、纹理、形状以及空间关系等特征的提取方法。
图像的分类识别是区分并分离各个目标的过程。对目标进行分类识别的关键不仅取决于提取图像中目标特征的结果,更取决于识别算法的选取。分类识别算法的选取对最终识别结果的准确程度有着决定性的作用。目前常见的分类识别方法主要有模板匹配法、人工神经网络法和支持向量机法等。
-- 基于SVM的图像识别主要分三步:
(1)构建训练样本集,利用SVM对样本的特征值进行训练,根据训练所得参数,构建基于SVM的识别分类器;
(2)将测试样本的特征值输入分类器中,得到属于各个目标分类后的概率;
(3)根据概率决定目标最终所属的类别,获得识别结果。
图像的旋转和缩放容易引起图像的重采样和重量化。有两个最常见的大方向,一是2B的整体解决方案,二是2C的移动互联网应用。
一般工业使用中,采用工业相机拍摄图片,然后再利用软件根据图片灰阶差做进一步识别处理,图像识别软件国外代表的有康耐视等,国内代表的有图智能等。
机器视觉的应用领域也十分广泛,例如用于军事侦察、危险环境的自主机器人,邮政、医院和家庭服务的智能机器人。此外机器视觉还可用于工业生产中的工件识别和定位,太空机器人的自动操作等。机器的图像识别也是类似的,通过分类并提取重要特征而排除多余的信息来识别图像。
在“先验知识库”的方法中,事物的形状、颜色、表面纹理等特征受到视角和观察环境所影响,在不同角度、不同光线、不同遮挡的情况下会产生变化。因此,研究者的新方法是,通过局部特征的识别来判断事物,对事物建立一个局部特征索引,即使视角或观察环境发生变化,也能比较准确地匹配上。
-- 图像识别过程