情绪与股市关系的研究由来已久,情绪是市场的一个重要影响因素已成为共识。
15年股灾时,亲历了一次交易灾难,眼见朋友的数千万在一周不到的时间内灰飞烟灭。那段时间市场的疯狂,让人深刻地明白:某些时候,股票市场这个抽象、复杂的系统,反映的不再是价值与供需,而仅仅是人的贪婪与恐惧。
说明
这份代码是股市情感分析项目的一部分,这个项目的本意是利用互联网提取投资者情绪,为投资决策的制定提供参考。
在国内这样一个非有效的市场中,分析投资者的情绪似乎更有意义。
这里我们利用标注语料分析股评情感,利用分析结果构建指标,之后研究指标与股市关系。
可以按以下顺序运行代码:
python model_ml.py
python compute_sent_idx.py
python plot_sent_idx.py
数据
数据位于data目录下,包括三部分:
标注的股评文本:这些数据比较偏门,不是很好找,这里搜集整理了正负语料各4607条,已分词。
从东财股吧抓取的上证指数股评文本:约50万条,时间跨度为17年4月到18年5月。东财上证指数吧十分活跃,约7秒就有人发布一条股评。
上证指数数据:直接从新浪抓取下来的。
模型
情感分类模型也是文本分类模型,常用的包括机器学习模型与深度学习模型。
model_ml.py:机器学习模型,对比测试了8个模型。
model_dl.py:深度学习模型,对比测试了3个模型。
结果
在经过情感分析、指标构建这两个流程之后,我们可以得到一些有趣的结果,例如看涨情绪与股市走势的关系。
我们使用的看涨指标公式为:
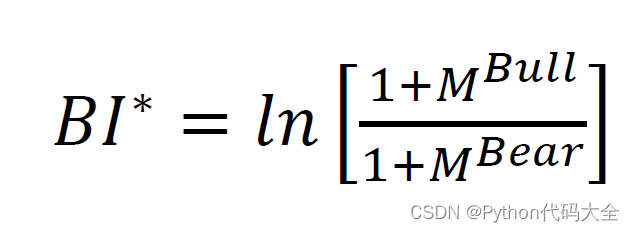
经过处理之后,“看涨”情绪与股市走势的关系可以描画出来:
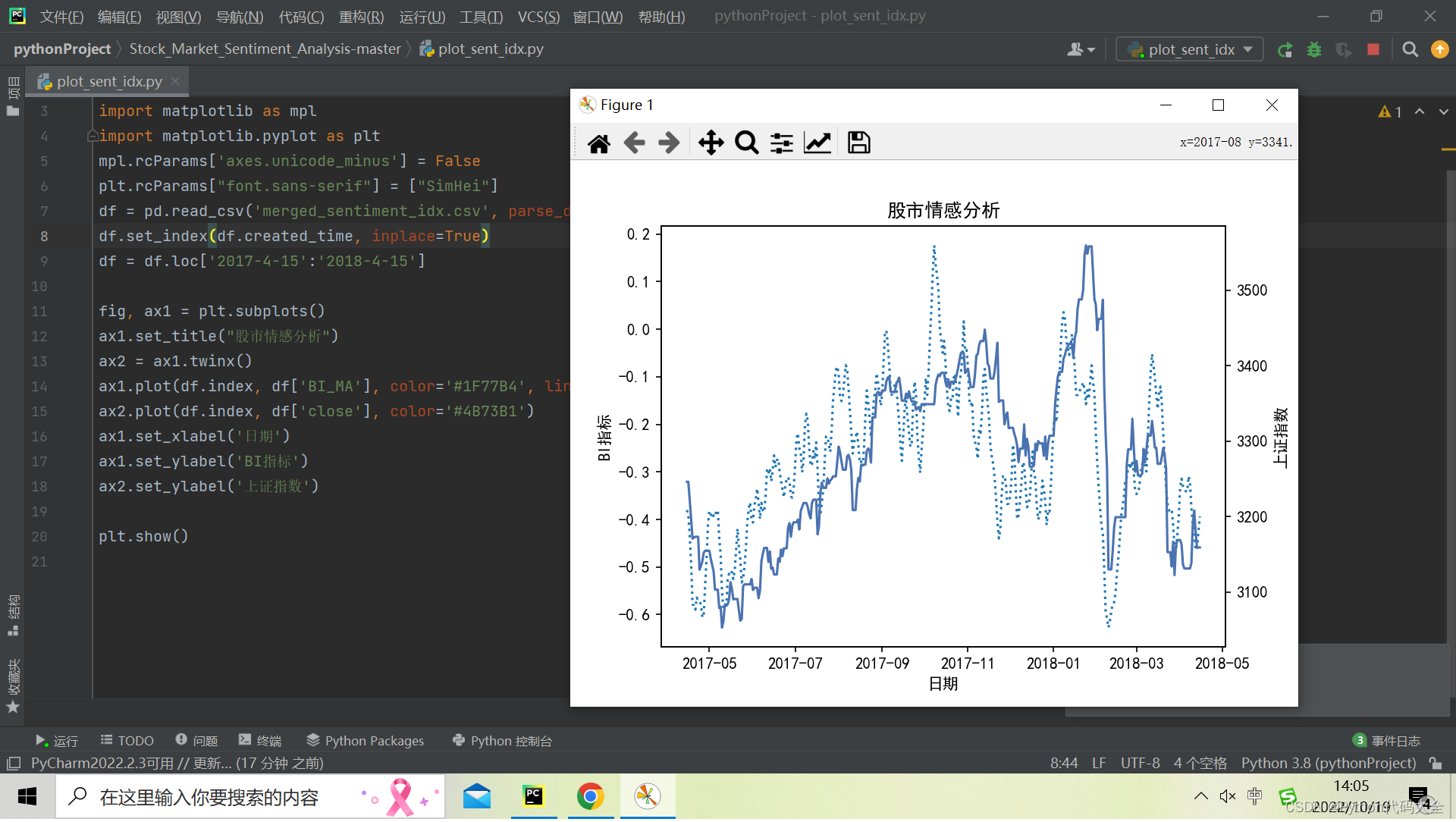
这里只展示诸多关系中的一个。
总结
这份代码仅为了演示如何从互联网中提取投资者情绪,并研究情绪与股市的关系。
model_ml.py
import os
from time import time
import pandas as pd
import numpy as np
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.utils.extmath import density
from sklearn import svm
from sklearn import naive_bayes
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
from sklearn.utils import shufflenp.random.seed(42)comment_file = './data/stock_comments_seg.csv'
data_path = './data'
pos_corpus = 'positive.txt'
neg_corpus = 'negative.txt'
K_Best_Features = 3000def load_dataset():pos_file = os.path.join(data_path, pos_corpus)neg_file = os.path.join(data_path, neg_corpus)pos_sents = []with open(pos_file, 'r', encoding='utf-8') as f:for sent in f:pos_sents.append(sent.replace('\n', ''))neg_sents = []with open(neg_file, 'r', encoding='utf-8') as f:for sent in f:neg_sents.append(sent.replace('\n', ''))balance_len = min(len(pos_sents), len(neg_sents))pos_df = pd.DataFrame(pos_sents, columns=['text'])pos_df['polarity'] = 1pos_df = pos_df[:balance_len]neg_df = pd.DataFrame(neg_sents, columns=['text'])neg_df['polarity'] = 0neg_df = neg_df[:balance_len]return pd.concat([pos_df, neg_df]).reset_index(drop=True)
# return pd.concat([pos_df, neg_df]).sample(frac=1).reset_index(drop=True)def load_dataset_tokenized():pos_file = os.path.join(data_path, pos_corpus)neg_file = os.path.join(data_path, neg_corpus)pos_sents = []with open(pos_file, 'r', encoding='utf-8') as f:for line in f:tokens = line.split(' ')sent = []for t in tokens:if t.strip():sent.append(t.strip())pos_sents.append(sent)neg_sents = []with open(neg_file, 'r', encoding='utf-8') as f:for line in f:tokens = line.split(' ')sent = []for t in tokens:if t.strip():sent.append(t.strip())neg_sents.append(sent)balance_len = min(len(pos_sents), len(neg_sents))texts = pos_sents + neg_sentslabels = [1] * balance_len + [0] * balance_lenreturn texts, labelsdef KFold_validation(clf, X, y):acc = []pos_precision, pos_recall, pos_f1_score = [], [], []neg_precision, neg_recall, neg_f1_score = [], [], []kf = KFold(n_splits=5, shuffle=True, random_state=42)for train, test in kf.split(X):X_train = [X[i] for i in train]X_test = [X[i] for i in test]y_train = [y[i] for i in train]y_test = [y[i] for i in test]# vectorizer = TfidfVectorizer(analyzer='word', tokenizer=lambda x : (w for w in x.split(' ') if w.strip()))def dummy_fun(doc):return docvectorizer = TfidfVectorizer(analyzer='word',tokenizer=dummy_fun,preprocessor=dummy_fun,token_pattern=None)vectorizer.fit(X_train)X_train = vectorizer.transform(X_train)X_test = vectorizer.transform(X_test)clf.fit(X_train, y_train)preds = clf.predict(X_test)acc.append(metrics.accuracy_score(y_test, preds))pos_precision.append(metrics.precision_score(y_test, preds, pos_label=1))pos_recall.append(metrics.recall_score(y_test, preds, pos_label=1))pos_f1_score.append(metrics.f1_score(y_test, preds, pos_label=1))neg_precision.append(metrics.precision_score(y_test, preds, pos_label=0))neg_recall.append(metrics.recall_score(y_test, preds, pos_label=0))neg_f1_score.append(metrics.f1_score(y_test, preds, pos_label=0))return (np.mean(acc), np.mean(pos_precision), np.mean(pos_recall), np.mean(pos_f1_score),np.mean(neg_precision), np.mean(neg_recall), np.mean(neg_f1_score))def benchmark_clfs():print('Loading dataset...')X, y = load_dataset_tokenized()classifiers = [('LinearSVC', svm.LinearSVC()),('LogisticReg', LogisticRegression()),('SGD', SGDClassifier()),('MultinomialNB', naive_bayes.MultinomialNB()),('KNN', KNeighborsClassifier()),('DecisionTree', DecisionTreeClassifier()),('RandomForest', RandomForestClassifier()),('AdaBoost', AdaBoostClassifier(base_estimator=LogisticRegression()))]cols = ['metrics', 'accuracy', 'pos_precision', 'pos_recall', 'pos_f1_score', 'neg_precision', 'neg_recall', 'neg_f1_score']scores = []for name, clf in classifiers:score = KFold_validation(clf, X, y)row = [name]row.extend(score)scores.append(row)df = pd.DataFrame(scores, columns=cols).Tdf.columns = df.iloc[0]df.drop(df.index[[0]], inplace=True)df = df.apply(pd.to_numeric, errors='ignore')return dfdef dummy_fun(doc):return docdef eval_model():print('Loading dataset...')X, y = load_dataset_tokenized()clf = svm.LinearSVC()vectorizer = TfidfVectorizer(analyzer='word',tokenizer=dummy_fun,preprocessor=dummy_fun,token_pattern=None)X = vectorizer.fit_transform(X)print('Train model...')clf.fit(X, y)print('Loading comments...')df = pd.read_csv(comment_file)df.dropna(inplace=True)df.reset_index(drop=True, inplace=True)df['created_time'] = pd.to_datetime(df['created_time'], format='%Y-%m-%d %H:%M:%S')df['polarity'] = 0df['title'].apply(lambda x: [w.strip() for w in x.split()])texts = df['title']texts = vectorizer.transform(texts)preds = clf.predict(texts)df['polarity'] = predsdf.to_csv('stock_comments_analyzed.csv', index=False)if __name__ == '__main__':scores = benchmark_clfs()print(scores)scores.to_csv('model_ml_scores.csv', float_format='%.4f')eval_model()完整源代码包下载:市情感分析源代码
Python代码大全,海量代码任你下载






![Tampermonkey[油猴插件]开发者的神级工具!](https://img-blog.csdnimg.cn/20190220174724251.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3podXl1bmJvXw==,size_16,color_FFFFFF,t_70)