PPT截图版权来自微信公众号言十爱,西南交通大学计算机与人工智能学院官号
笔记按照报告类别划分而非报告时间划分,且笔记和感想仅为个人浅见
可能存在分类分得比较抓马的情况,主要是初学者搞不清细类别
目录
1. 联邦学习
1.1. 可信联邦学习和联邦大模型-杨强
1.2. 时空大数据联邦计算-童咏昕
1.3. 可信联邦学习的多目标优化-范力欣
1.4. 基于知识流动的联邦学习-刘洋
2. 城市
2.1. 城市计算:从理论体系到产业实践-郑宇
2.2. 时空扩散点过程-李勇
2.3. 时空人工智能:概念,方法和应用-张钧波
3. 机器学习
3.1. 排演(Rehearsal):从预测到决策-周志华
3.2. 预训练语言模型在网页搜索中的应用-殷大伟
3.3. 基于规则表征学习的可解释分类模型-王建勇
3.4. From Imbalanced to Zero-Shot Node Classification of Graphs-巩志国
3.5. 伴随式认知诊断:方法与应用-刘淇
3.6. 面向科学智能的图机器学习-王杰
3.7. 图数据中的异常检测研究-杨洋
3.8. 稳健弱监督学习理论与方法-李宇峰
4. 科学
4.1. AI for Science推进科研新范式-漆远
5. 大模型
5.1. ChatGLM:从千亿模型到ChatGPT的一点思考-唐杰
5.2. 圆桌论坛:AI大模型
5.3. 青年学者关于大模型的Spotlight
5.4. 大模型背后的可解释性-叶杰平
6. 群体智能
6.1. 人机物融合群智计算系统-郭斌
7. 深度学习
7.1. 复杂图数据建模与学习-石川
7.2. 基于活动(或过程),状态和事件的知识图谱-宋阳秋
7.3. GraphMAE:生成式图预训练模型-东昱晓
7.4. 基于深度学习的ETA估计-鲍立胜
8. Reference List
1. 联邦学习
1.1. 可信联邦学习和联邦大模型-杨强
(1)Federated machine learning/Federated Learning(FL):Set a shared global model with a large central sever for scattered clients (Liang et al., 2023). The main approaches of reducing heterogeneous data are data augmentation, regularized client-side loss, meta-learning, multi-task learning and client-side clustering (Liang et al., 2023). Moreover, FL is based on distributed machine learning(Li et al., 2023).
(2)企业会在自己的数据中加入噪声(水印),以加密和区分自己的数据
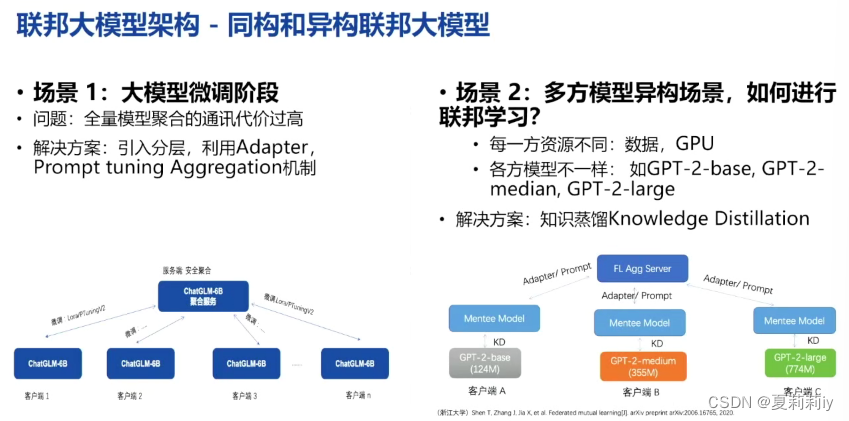
(3)联邦学习中的统一框架
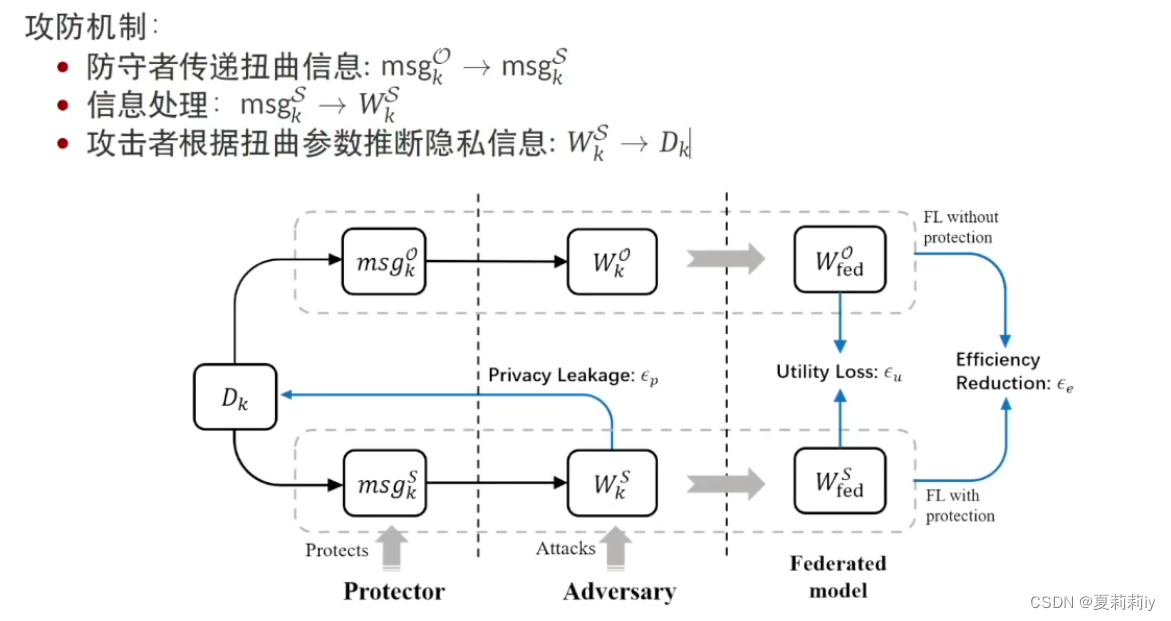

(4)联邦学习多目标优化帕累托最优解(Pareto Front)
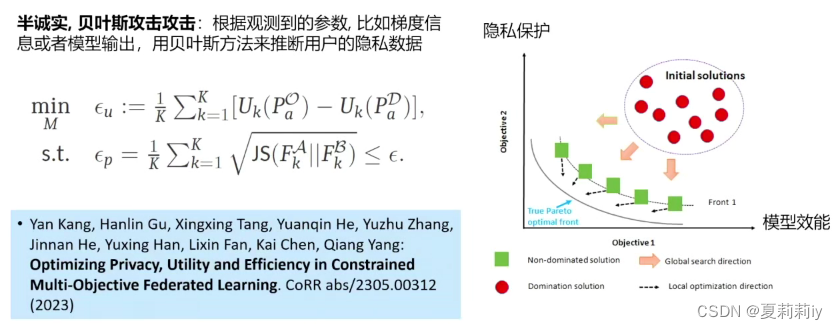
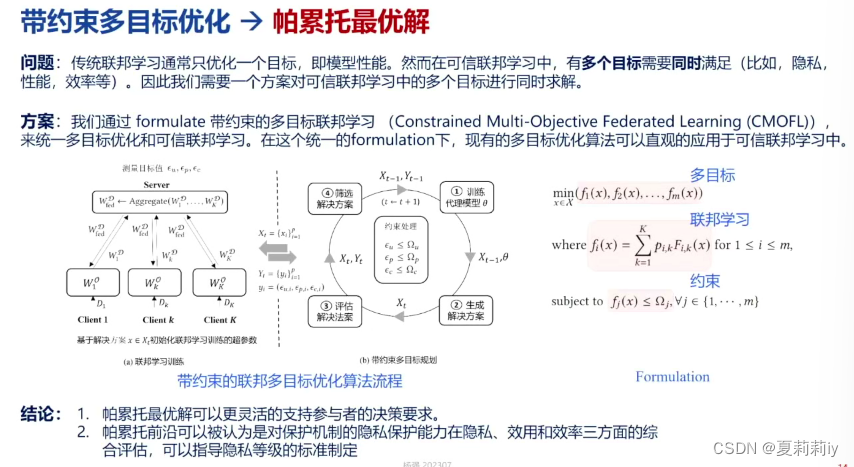
(5) 联邦学习多目标优化

(6)将三个维度连结成一个维度来统一进行比较

(7)将收益设置远小于惩罚时,攻击者则会不敢攻击

(8)数据时第五生产要素,因此数据交易非常重要
(9)联邦大模型:多个本地模型的结合

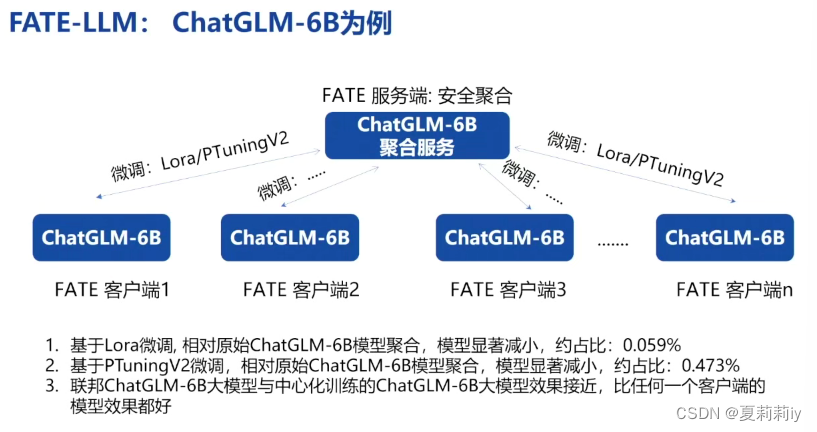
(10)联邦学习是从企业大模型传到个人本地数据之间的防火墙。联邦学习和迁移学习是大模型落地的金钥匙。
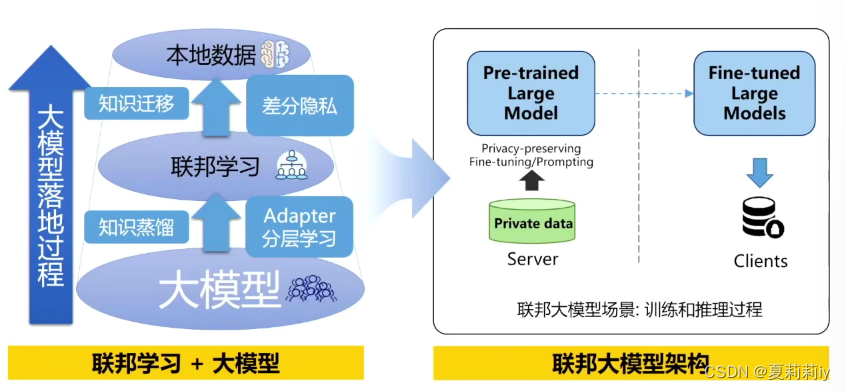
(11)Transfer Learning(TL) is able to transfer knowledge from different but similar samples (Sun & Zhang, 2023). It is a machine learning that used for solve data lacking problem (Hu et al., 2023).
1.2. 时空大数据联邦计算-童咏昕
(1)跨平台/域协同应用,多源自治,倡导“数据不动计算动”以保证数据安全
(2)隐私信息定义
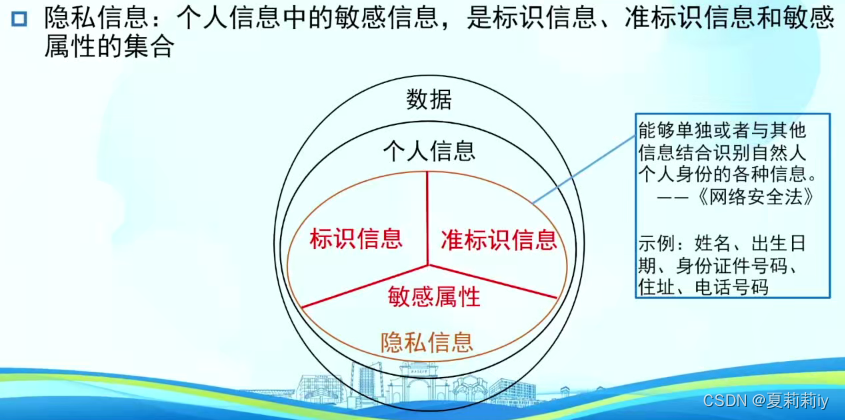
①标识信息:如身份证,指纹等,一对一标识
②准标识信息:如身高,血型,体重等
③敏感信息:个人轨迹,收入等
(3)保护个人隐私不一定要加密,可以进行数据脱敏,让别人无法准确识别身份
(4)经典羊吃草模型
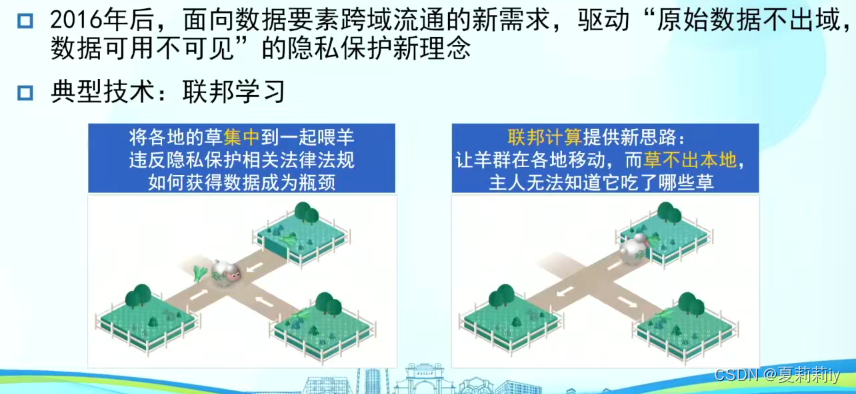
(5)案例
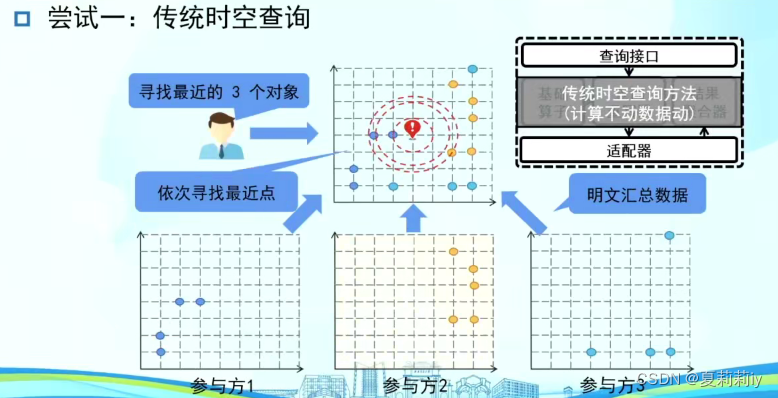
(6)贪心策略:k近邻查询
①传统时空查询:计算不动数据动(直接把自己的数据位置给别人,不安全)
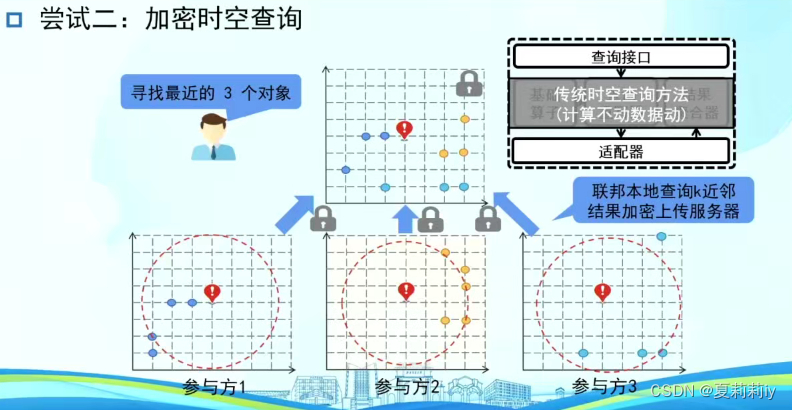
②加密时空查询(冗余加密计算效率低,部分原始数据出本地违背约束条件)
③联邦k近邻:查询重写思路,重写器
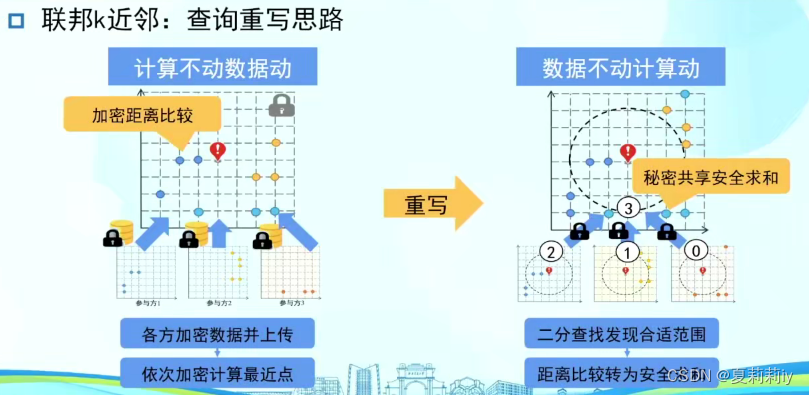
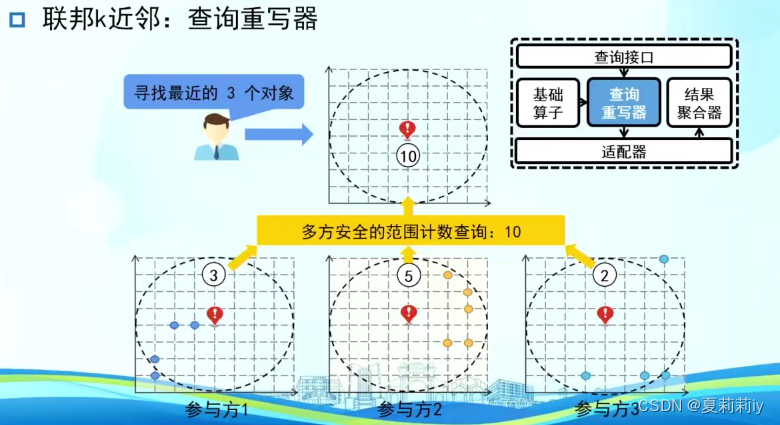
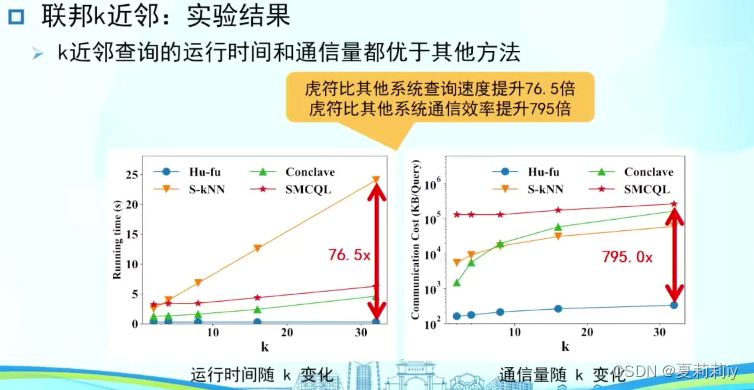
但还是存在问题,需要引进学习方法,不然短期的错配会导致长期的蝴蝶效应
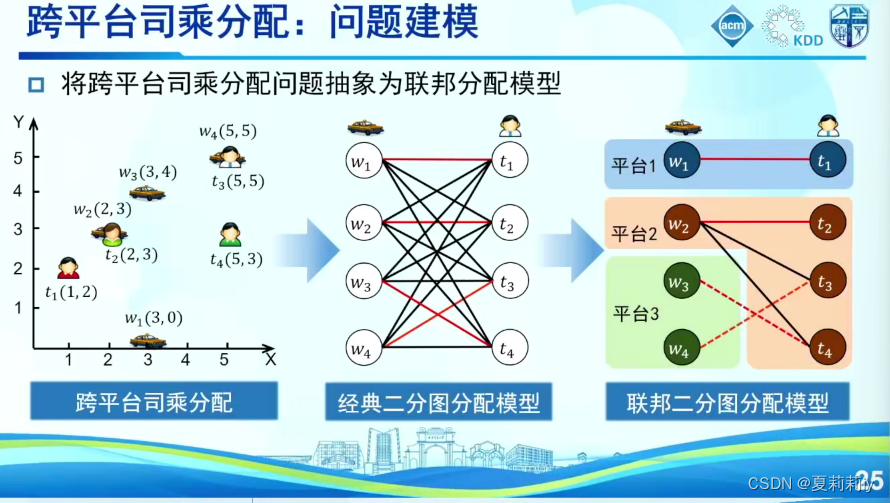
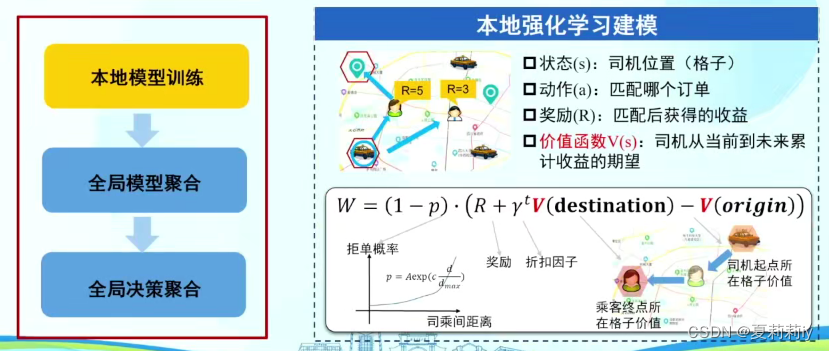
(7)基于联邦强化学习的司乘分配算法思路
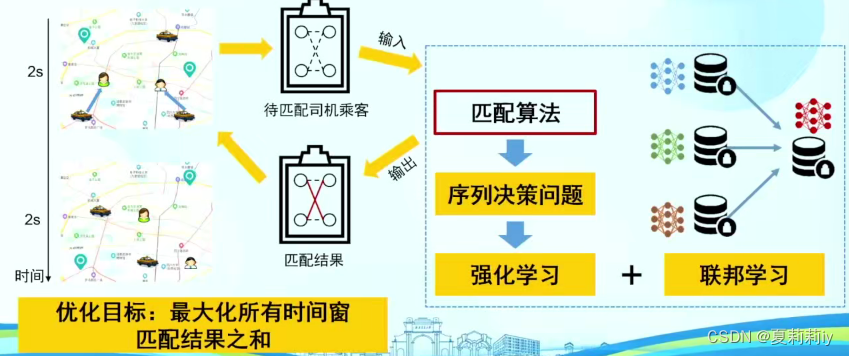
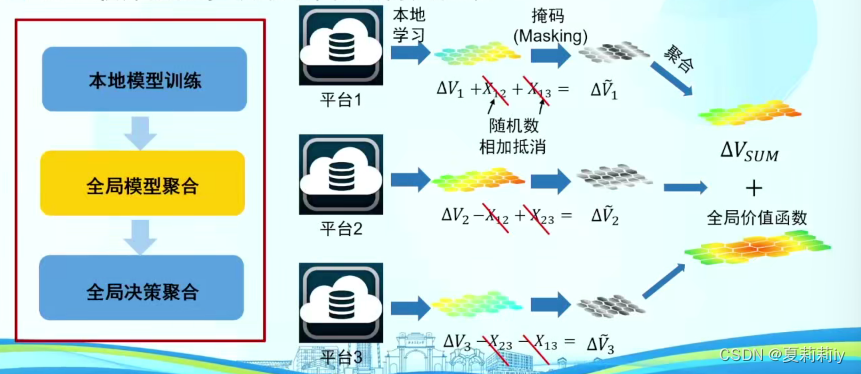
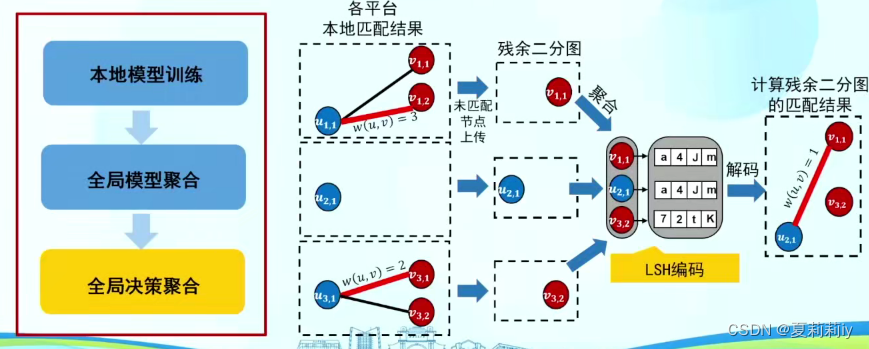
(8)时空联邦计算系统虎符(OpenHufu)

(9)未来挑战
①个体视角的隐私:保护权益的前提是讨论个人数据所有权和应享有的权利
②安全高效:防御平台攻击(可信执行环境,TEE),保护计算过程(安全多方计算,SMC),数据脱敏防御差分攻击(K匿名,差分隐私DP)
③激励机制:共享数据的激励
1.3. 可信联邦学习的多目标优化-范力欣
(1)可信联邦学习

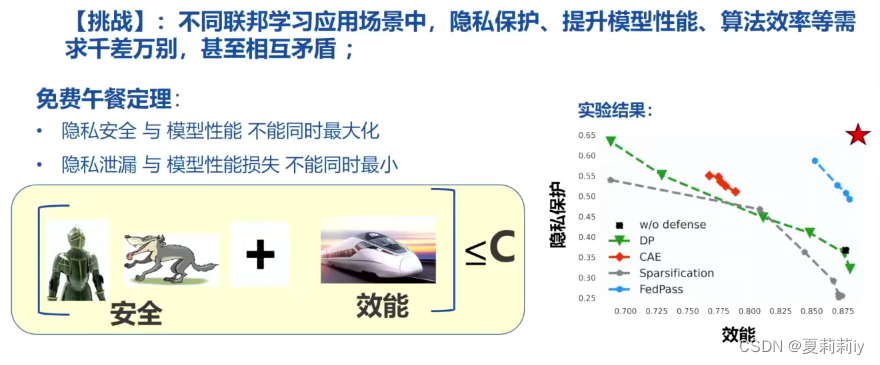
(2)联邦学习中的理论与公式 

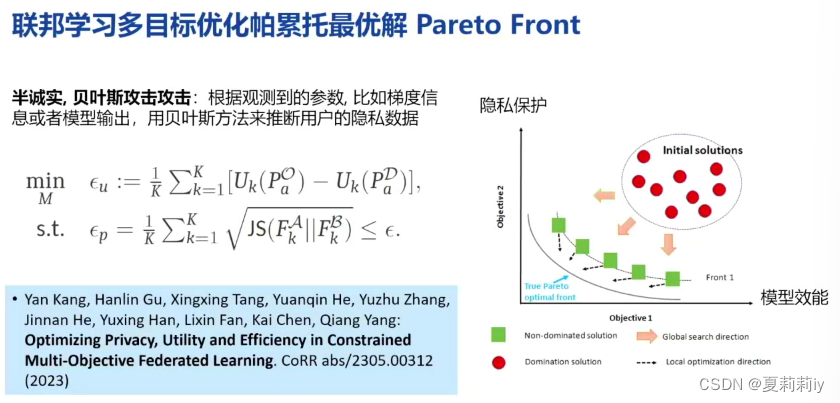
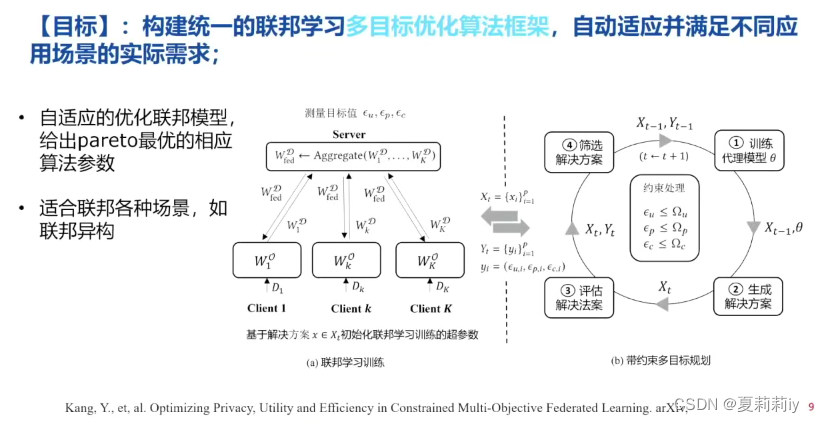

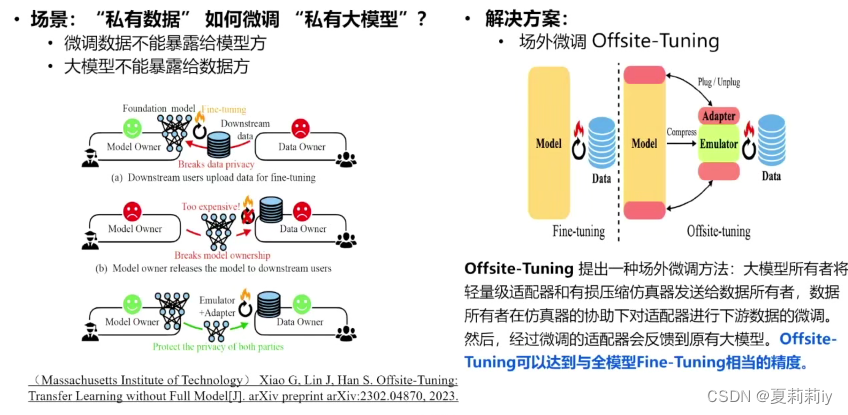
(3)模型数据保护
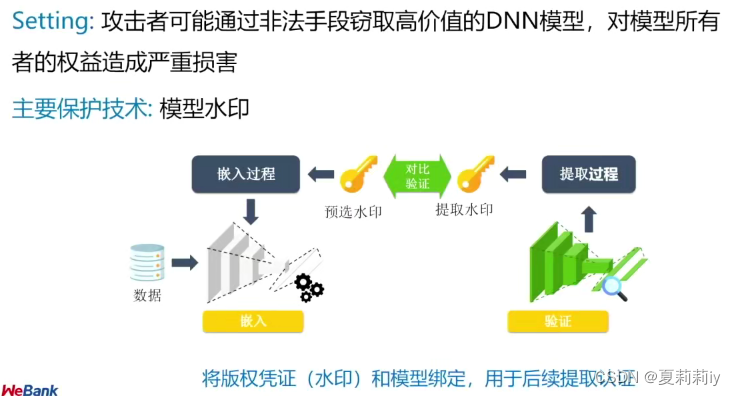
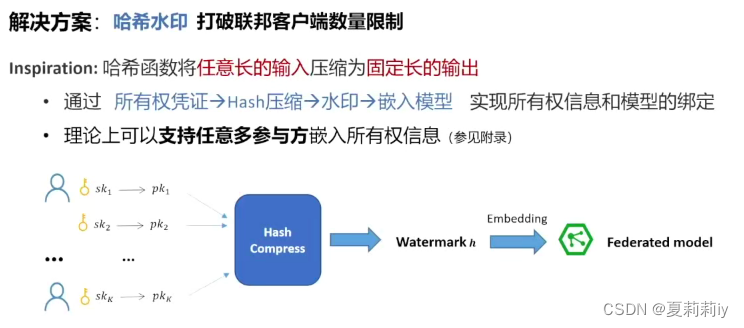
(4)模型水印(有点像白盒嵌水印,黑盒嵌加密水印?)
①白盒水印:提取水印需访问模型参数。参数选择→水印嵌入→版权验证
②黑盒水印:触发集生成→黑盒水印嵌入→版权验证
(5)深度DNN模型加水印
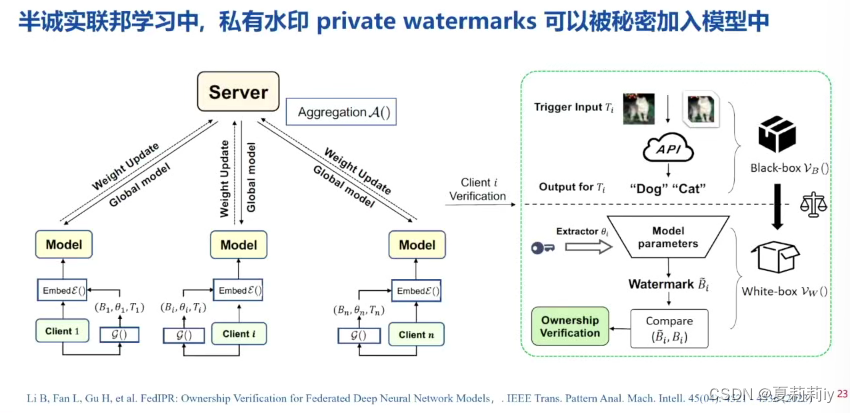

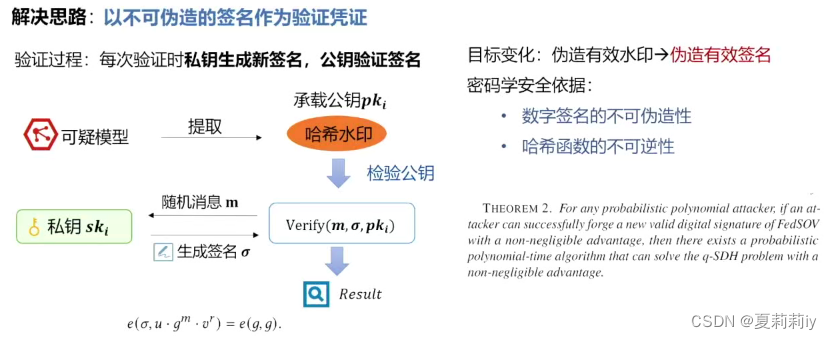
(6)结合数字签名的安全版权验证方案


1.4. 基于知识流动的联邦学习-刘洋
(1)联邦学习解决的是跨设备vs跨机构的问题
(2)为了隐私,手机数据不再上传,而是应该上传模型
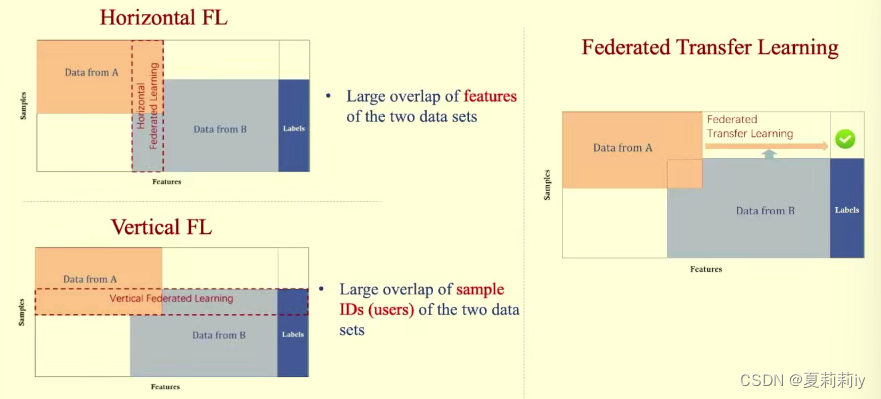
(3)横向,纵向与迁移联邦模型(有个知乎讲解:横向联邦学习、纵向联邦学习和联邦迁移学习的区别【只看这一篇就够了】 - 知乎 (zhihu.com))
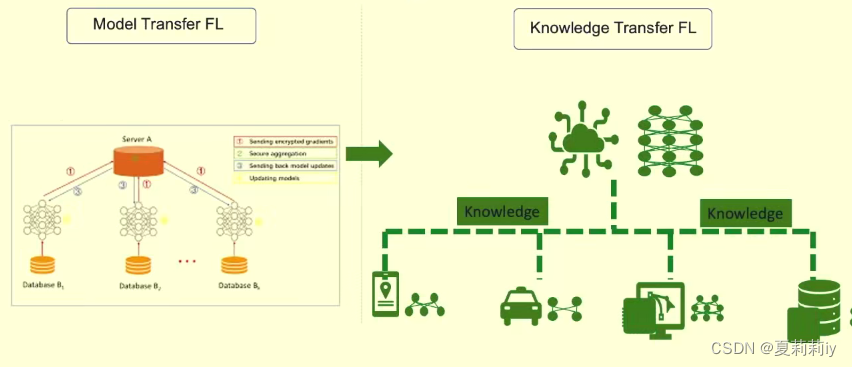
(4)知识流动与模型流动
(5)安全性:模型逆向攻击(?)
(6)后面太过专业略过
2. 城市
2.1. 城市计算:从理论体系到产业实践-郑宇
(1)只能说感觉不是很适合个体学生啊,这是很庞大的项目
(2)以数据为中心,摆脱了对业务变化的牵制
(3)智慧城市框架和总体概念
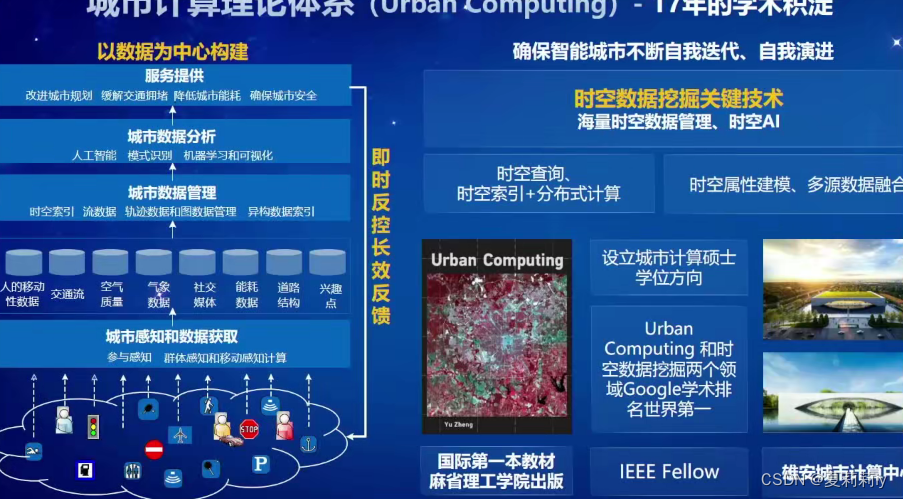

(4)城市操作系统的机遇和价值
①新型数据孤岛凸显
②赋能支撑不足
③生态化缺失
(5)智慧城市主要是动态,以前做的数据都偏静态,不易更新
2.2. 时空扩散点过程-李勇
(1)纯纯city skyline pro max,落地也没必要酱紫落
(2)城市移动
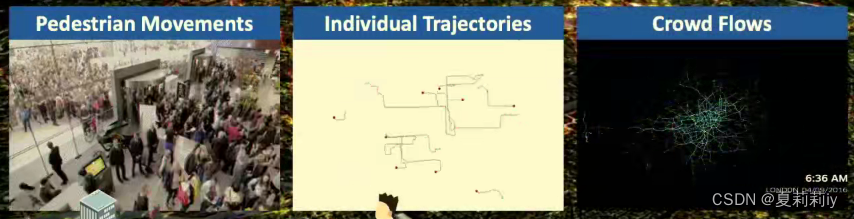
①单个地方人口流动
②单个人移动轨迹
③整个城市人流
(3)基于模型驱动的基本思路
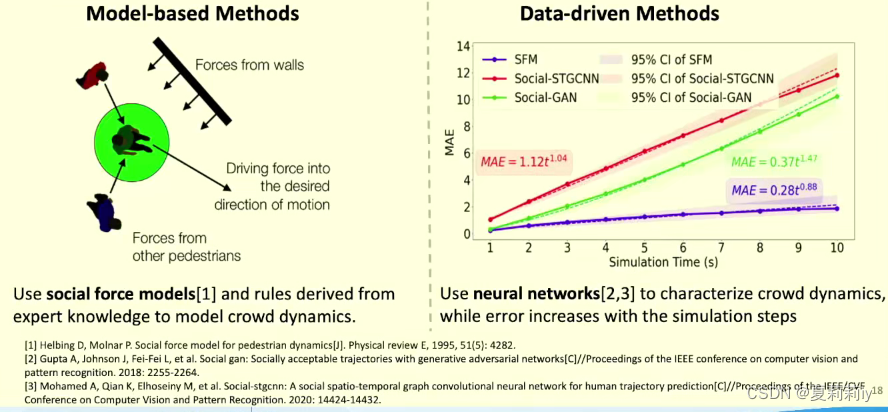
(4)模型驱动和数据驱动相结合
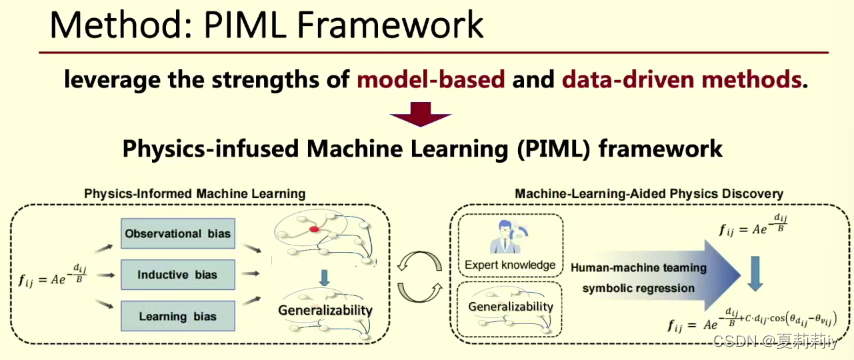
本质上是图神经网络的结构
(5)“Graph Neural Networks(GNN) is able to handle the topological structure information of the picture and derive high-level representations of nodes in the graph”(Li et al., 2023).(这句话直接quatation了,paraphrase不动)
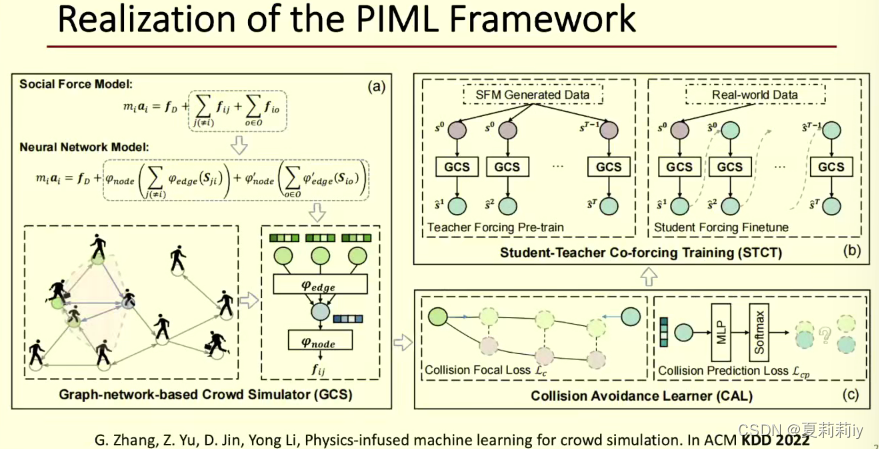
2.3. 时空人工智能:概念,方法和应用-张钧波
(1)城市火灾预测(所以这种大多数都是人为的情况下有什么好预测的?工厂和森林一直高风险就好了?)
(2)都是时空模型就不截图了
3. 机器学习
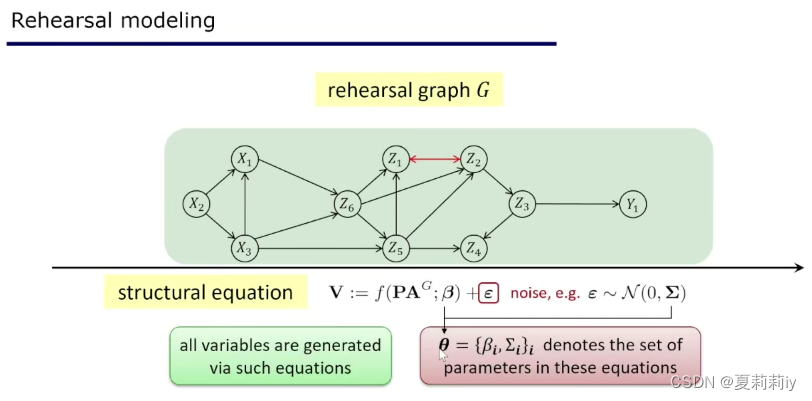
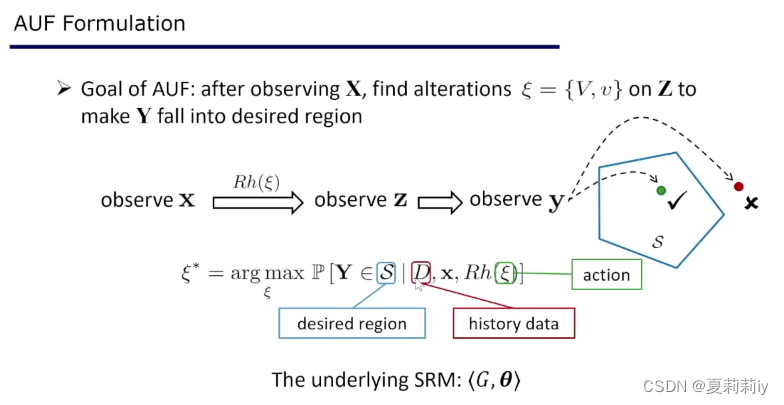
3.1. 排演(Rehearsal):从预测到决策-周志华
(1)仅作为周教授的初步构想,最近大模型预测已经非常成功了,因此要思考做决策
(2)决策仅靠相关性是不够的,因果性帮助也不大(都不是人们所需要的)

(3)正确的认识可能带来错误的决策
(4)排演:假设采取,需要排除不好的情况,而非排练那种为了做得更好
(5)排演框架

(6)决策要尽量少(Q:但是对于每个人来说决策应该是不一样的吧?这种是否又类似了私人助理呢?并不是说所有人都像例子里面的油价涨了就要换自行车)
(9)决策的时效性相当重要
(10)排演的假设检验(类似贝叶斯网)



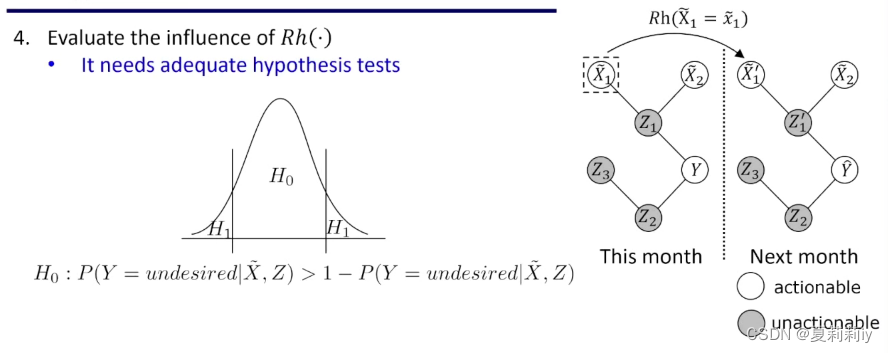
(11)是我不懂的数学

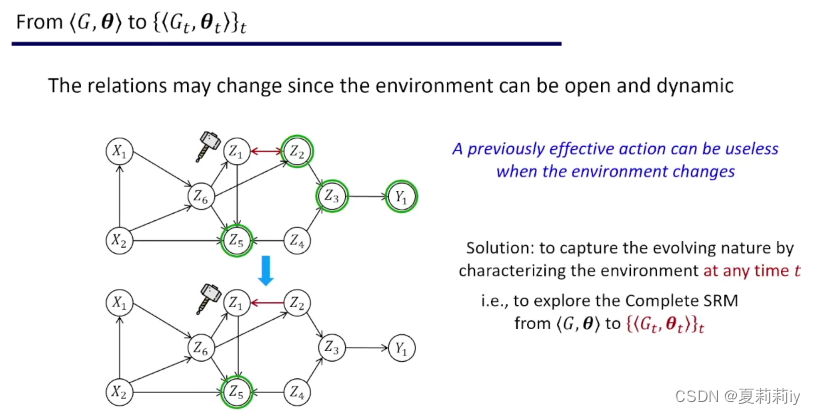
(12)图模型
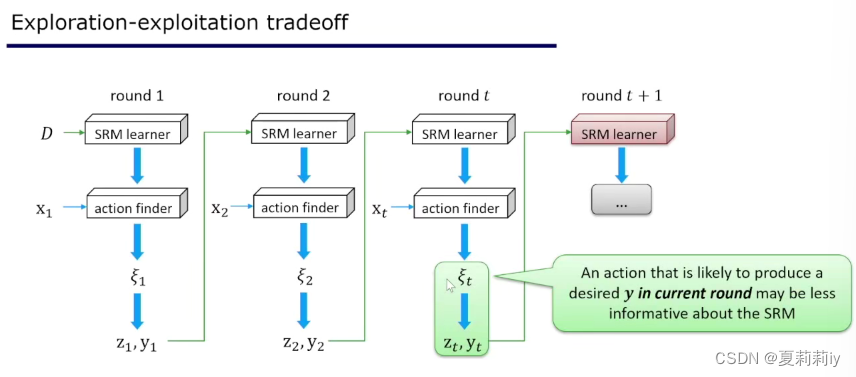
(13)Q:感觉这些决策只能基于已有,如快撞车时根据障碍判断转向。但若是对于个人决策,如如何营销等,只能根据曾有过的营销方法而不能开拓新东西。
3.2. 预训练语言模型在网页搜索中的应用-殷大伟
(1)检索模型
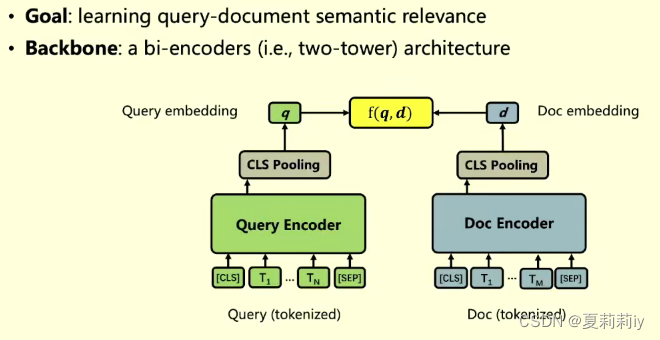
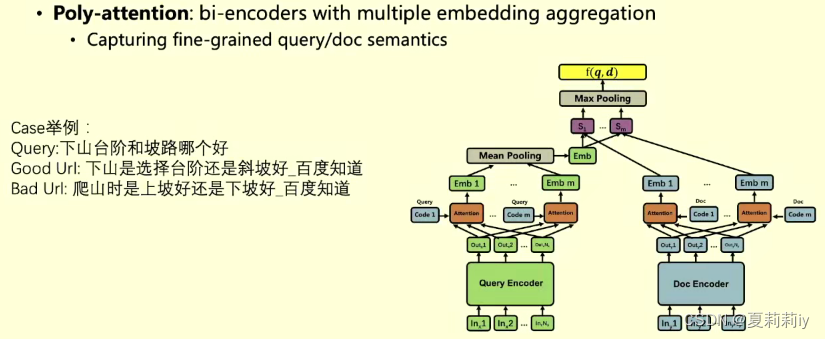

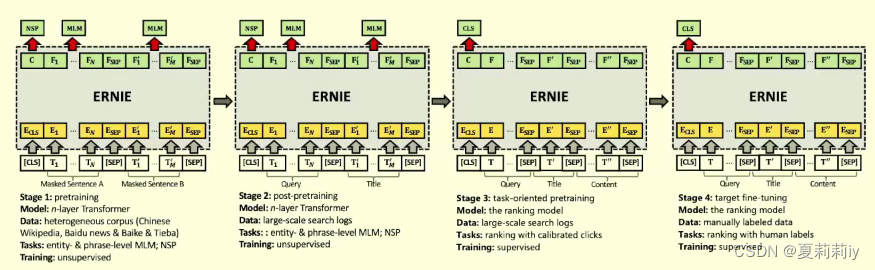
这个是3和4有区别,基于用户点击页面停留时长来判断预测的准确性
(2)⭐例举了检索的很多问题
①Missing key term
②Entity mismatch
③Entity disorder
(3)知识增强排序
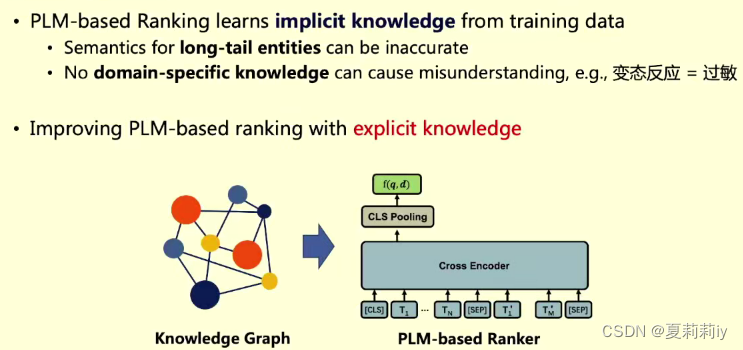
①先删去无用信息
②制作Meta-graph
③把Meta-graph植入到语言预训练模型当中(包含了同义数据的转换和显示)
(4)用大语言模型(LLM)完成生成AI

①可能改写错了(contradictory):consistency feedback
②引用错地儿(less supported):citation feedback
③全错了:overall feedback
3.3. 基于规则表征学习的可解释分类模型-王建勇
(1)背景和动机

(2)记忆规则模型是透明的,且有可解释性
(3)规则模型的参数和结构都是离散的,很难采用梯度下降,规则表示学习训练完之后可以转化成规则模型
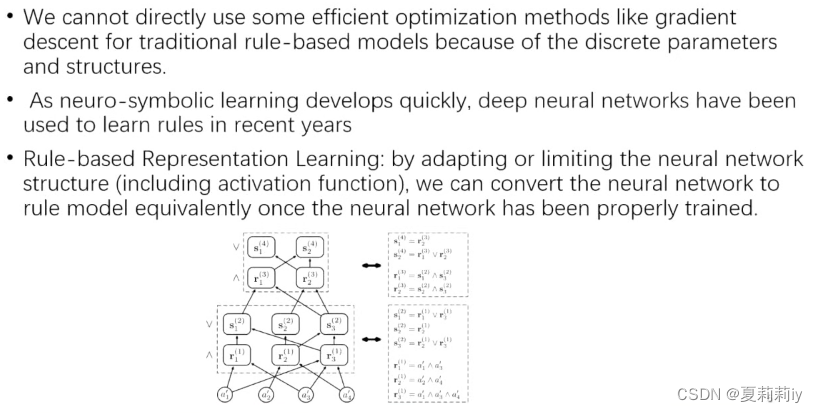
(4)层级
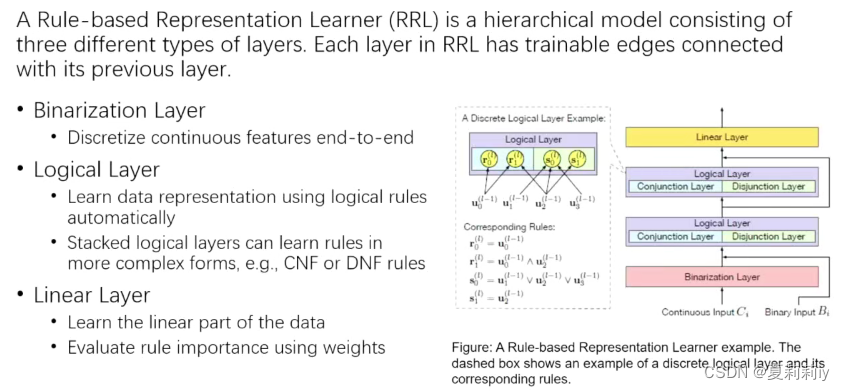
①二值化层
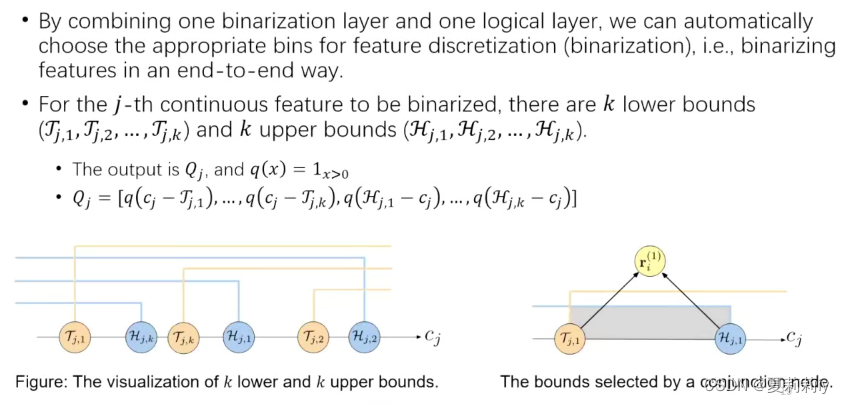
②逻辑层
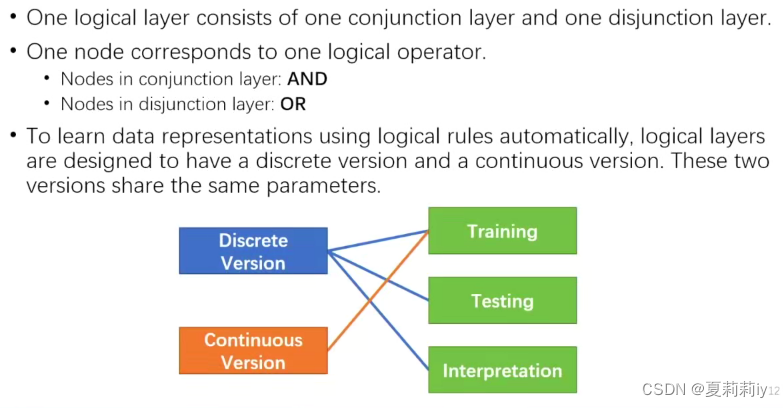


连乘导致梯度下降,可以引入投影函数,下图i为投影函数要满足的三个条件
③线性层
(5)Gradient Grafting(接枝共聚?)
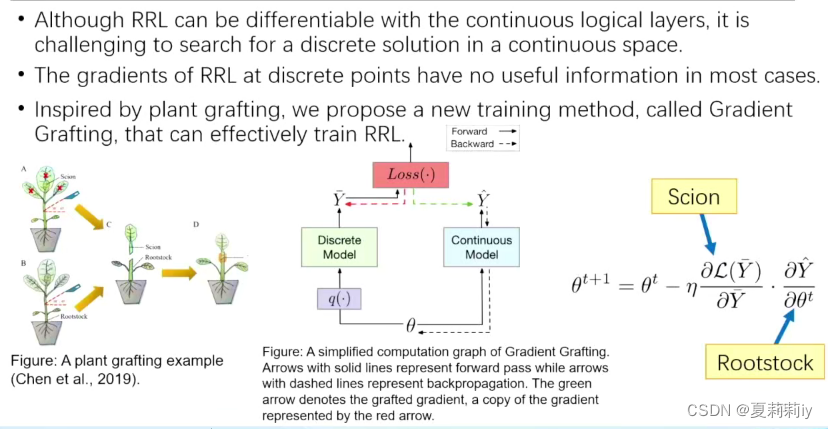
(6)模型解释
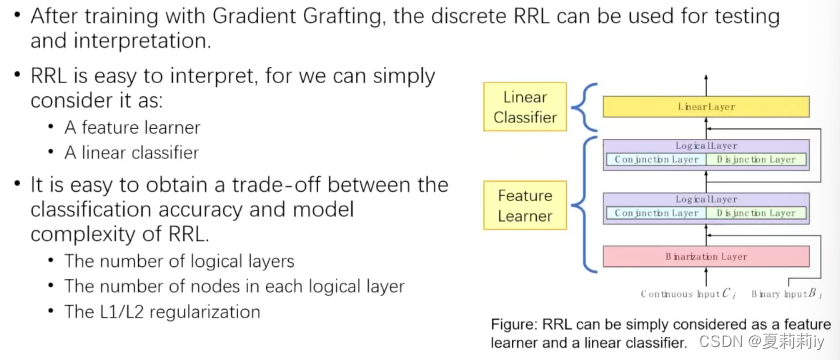
只用连续的数据会让结果不太令人满意,因此需要离散和连续的数据一起处理
(7)模型的复杂程度
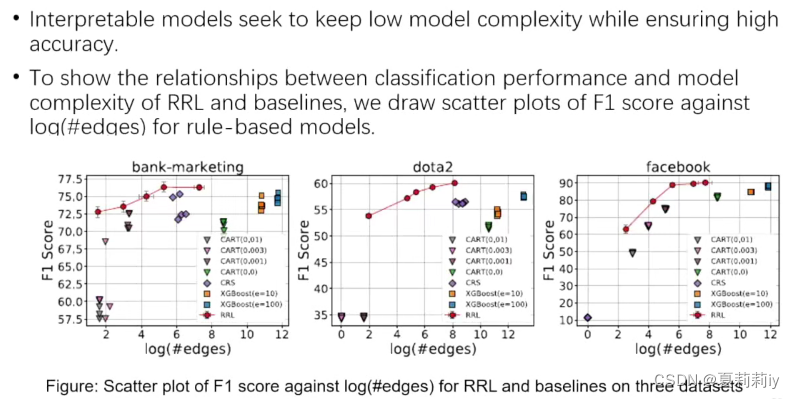
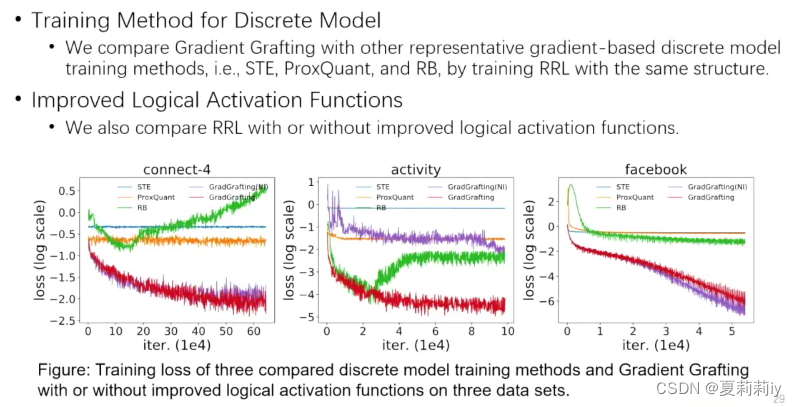

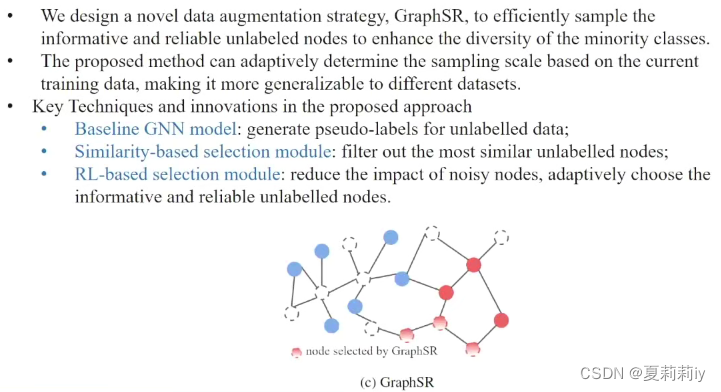
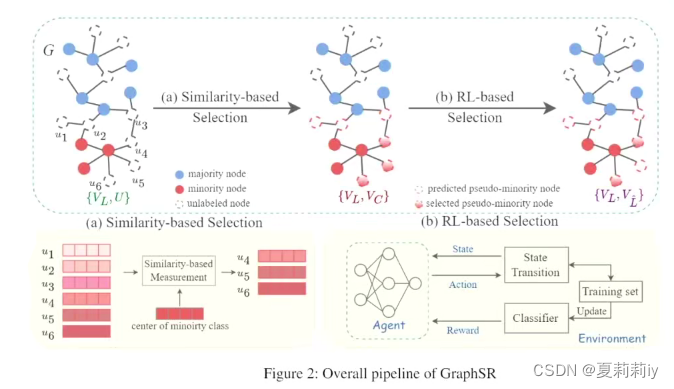
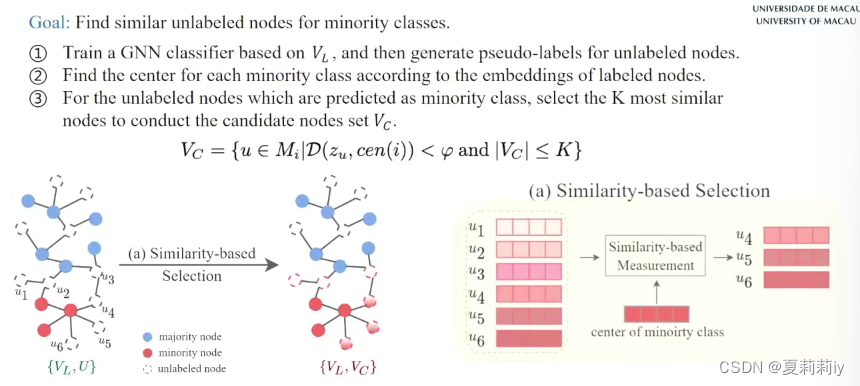
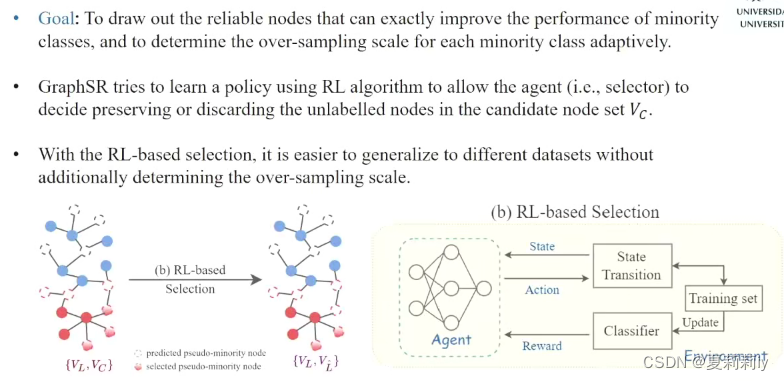
3.4. From Imbalanced to Zero-Shot Node Classification of Graphs-巩志国
(1)样本学习
①零样本学习(Zero-Shot Learning):利用原有的知识进行迁移学习或逻辑推理,来实现对从未见过的模型的分类
②一次样本学习(One-Shot Learning):通过一个样本来学得一个事物的特征并能够辨别出类似事物
③少样本学习(Few-Shot Learning):从少量样本中学到分类
(2)节点分类
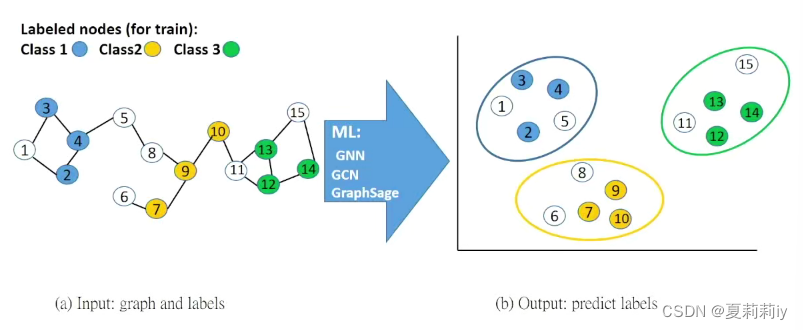
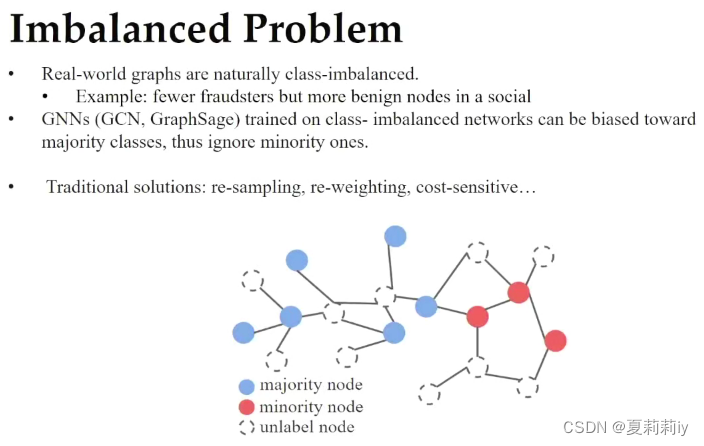
(3)非平衡问题
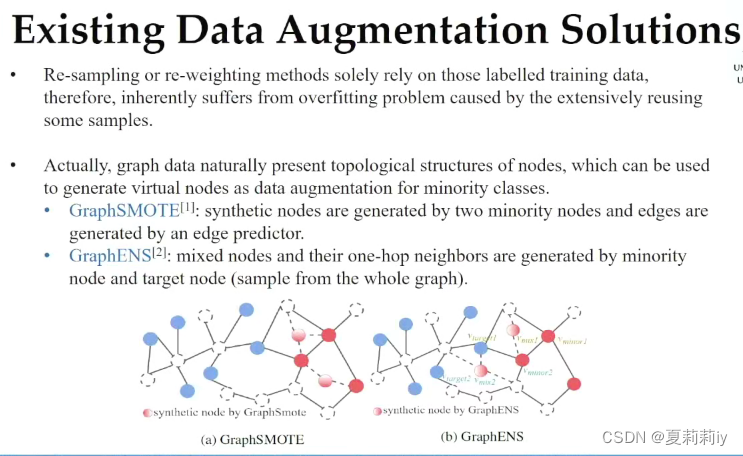
①用两个原本红色节点创建了一个新节点,但还是可能会过拟合,不容易泛化
②创建一个虚拟节点,由小类别组成,泛化能力更强,但是可能虚拟节点越界
(4)动机
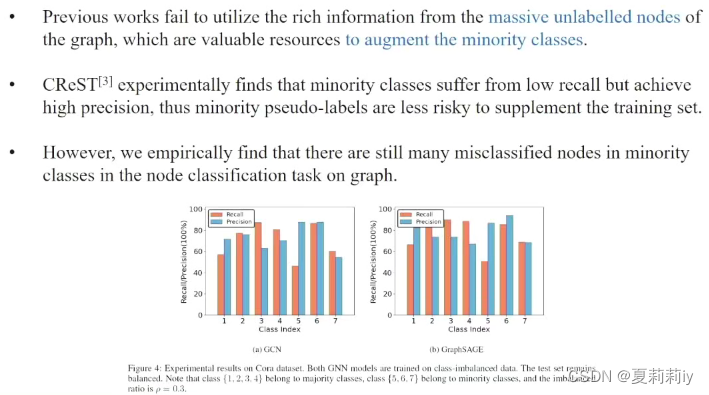
(5)伪标签
根据概率分类





(6)分布结构

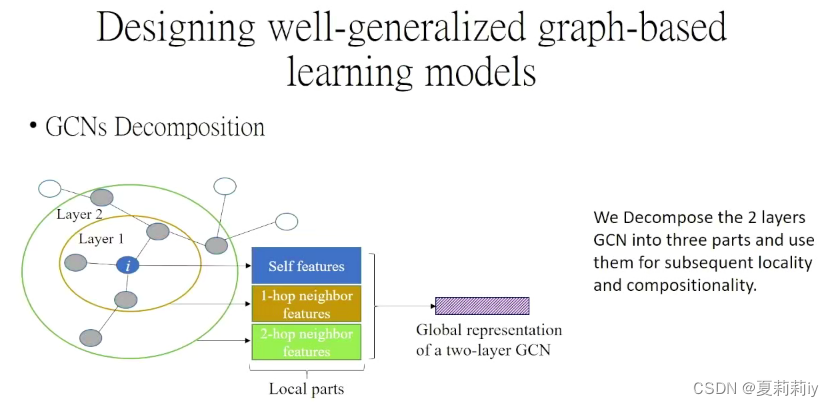


3.5. 伴随式认知诊断:方法与应用-刘淇
(1)用户画像(就不多说了)
(2)基于认知诊断的自适应测试(其实还好吧就像扇贝现在测词汇量应该也是用这种)
(3)基于多维能力刻画的演化学习探索

3.6. 面向科学智能的图机器学习-王杰
(1)相关问题分类
①节点级别:节点分类,节点回归
②边级别:边预测,边分类
③图级别:图分类,图回归
(2)当前进展
①基于领域信息挖掘的自监督图表征方法
②基于层次分解的图模型加速和推理方法
③基于分布偏移不变特征的鲁棒训练方法
3.7. 图数据中的异常检测研究-杨洋
(1)可以量化各个行业的经济复苏,从而扶持一些更需要帮助的行业
(2)构造社交网络
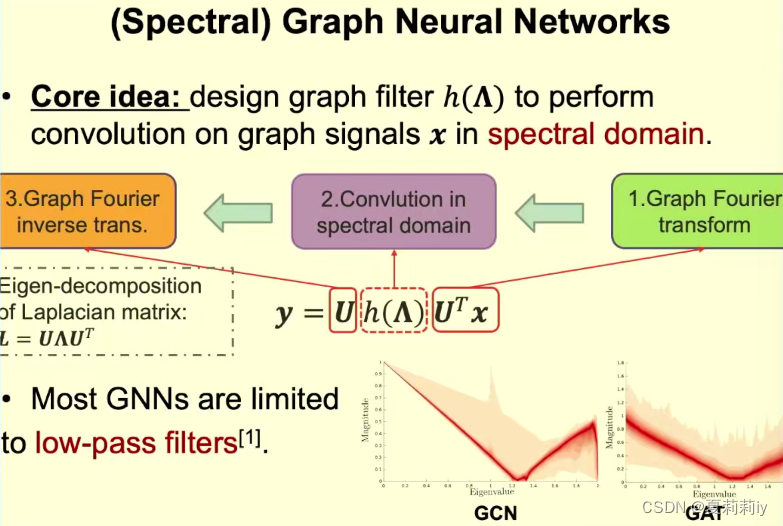
①谱方法:尝试把在原始空间和节点中难以执行的卷积操作投影在新的谱空间进行操作,如对一个图的拉普拉斯矩阵进行特征分解,然后互相正交特征向量作为基底构成谱空间,相当于对原始空间做傅里叶变化,然后在其上定义谱空间卷积核,再做傅里叶逆变换,把卷积的结果投影回原始空间中
②大部分图神经网络都扮演了一个低通滤波器的角色,过滤掉高频信号,仅仅留下低频信号
③图的高频和低频指的是节点和节点之间的变化大或小
(3)后面太多了,略过
3.8. 稳健弱监督学习理论与方法-李宇峰
(1)机器学习再开放环境下性能很不稳定
(2)弱监督:少量有标注样本+海量未标注样本
(3)后面过于专业略过
4. 科学
4.1. AI for Science推进科研新范式-漆远
(1)科学智能发展的六大关键要素
①AI出发科研范式转型的突破方向
②大规模智能异构算力与开源协作
③海量的可信科学数据
④基础科学与人工智能知识体系的复合型高端人才
⑤科学场景的AI新算法
⑥突破方向的验证与研发能力
(2)然后很broad的讲了一大堆AI和不同科学的结合,感觉过于像科普了,就不深入分析了
5. 大模型
5.1. ChatGLM:从千亿模型到ChatGPT的一点思考-唐杰
(1)新型大模型:GLM-自回归填空
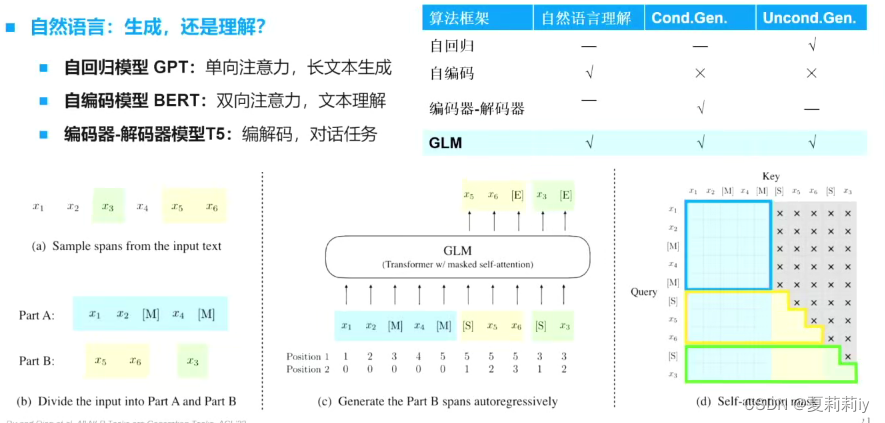
使用双向注意力,比单向精度更高
(2)稳定训练方法
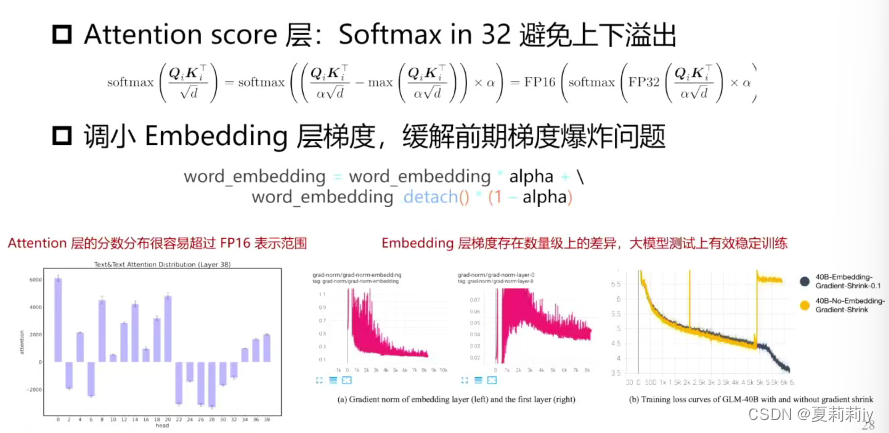
使用自适应的步长
(3)双系统的认知智能
①系统1:直觉性思考(很快)
②系统2:推理性思考(需要时间)
5.2. 圆桌论坛:AI大模型
(1)大模型最适合的和最不适合的方向
①适合对话,感情陪伴,个人聊天/科研助理
②没有不太适合的,只是可能成本高(唐杰:不太适合搜索?推荐?)
(2)模型构建:是不是数据驱动和知识结合很重要?
①知识加数据是很重要的,知识应该融合在模型中,积累知识,通用迁移
②希望ai有推理的能力
③加外挂(数据库包)非常的方便,但是也可能会一定程度缺失推理能力,而且知识库有点贵和费时
④大模型最后不应该是黑盒,而是成为可以解释的东西
⑤ai的目前答案或解释可能并不是最优的
⑥ai记忆力的重要性(如人类快速的直觉性思考)
(3)大模型会被颠覆掉吗?大模型未来的能力
①可能大模型不具逻辑性,只是博闻强记
②可能有抽象和迁移的能力,将很多能力泛化成由同一个模型得到的
③可能从前的经验会成为阻碍前进的包袱
(4)在数据训练时对数据的预处理和参数的调整策略上面有无实际经验和案例分享?
①不是说所有人都要去做大模型,毕竟时间和金钱成本都是很高的
②可以训开源大模型玩但是没有必要和大厂PK
(5)计算机行业变成重资产重工业的行业了
①技术的变革时没有办法的,是技术发展的必然
(6)经典模型被大模型颠覆了
①没有用的东西或许也可以做出来,作为一种铺垫和探索
②把大模型和小模型结合起来使用
(7)大模型背后可解释吗?
①应该可以解释,也拥有智能
5.3. 青年学者关于大模型的Spotlight
(1)因果去偏(?)
(2)小模型可以做大再缩小,拆解张量
(3)多模态知识图谱,挖掘时序
(4)预训练和微调
5.4. 大模型背后的可解释性-叶杰平
(1)AlphaFold给生活带来了很大的改变
(2)transformer
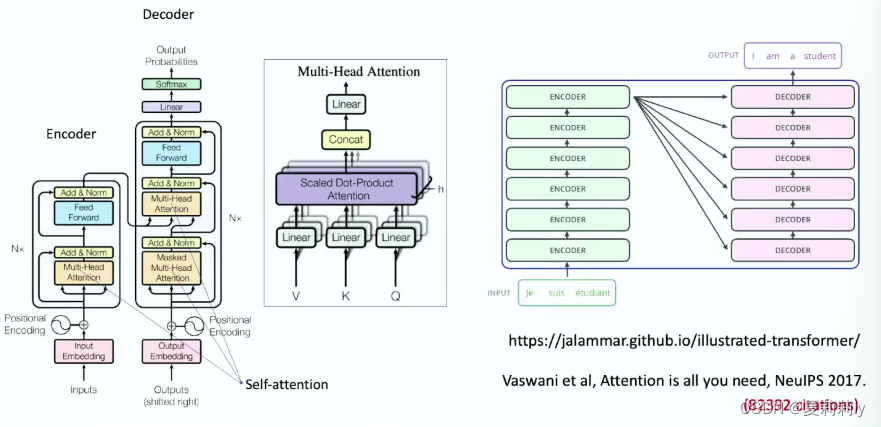
(3)大语言模型有规律性吗? 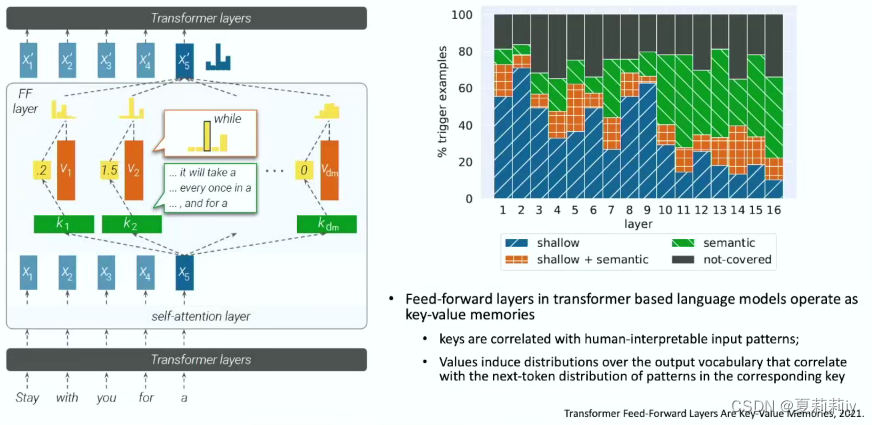
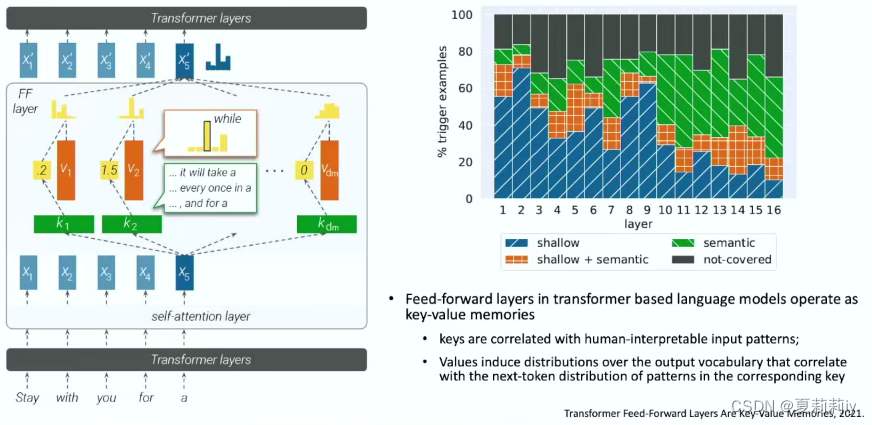


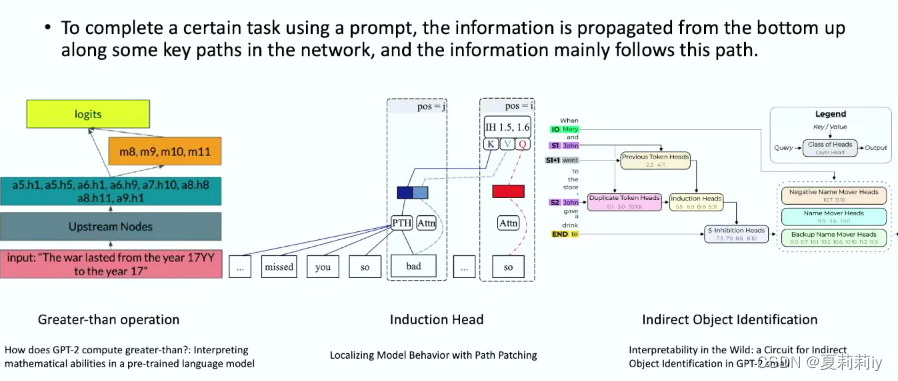
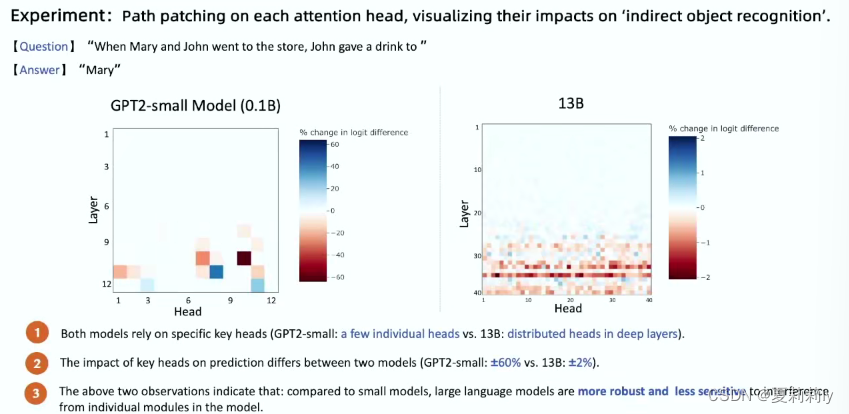
①可能大预言模型的匹配更多基于概率预测。又及,即使去掉一些模块也不会影响结果,因为可能有其他的模块也能做同样的工作。
②大语言模型在预训练领域没什么效果?
(4)大语言模型的五种提升层次
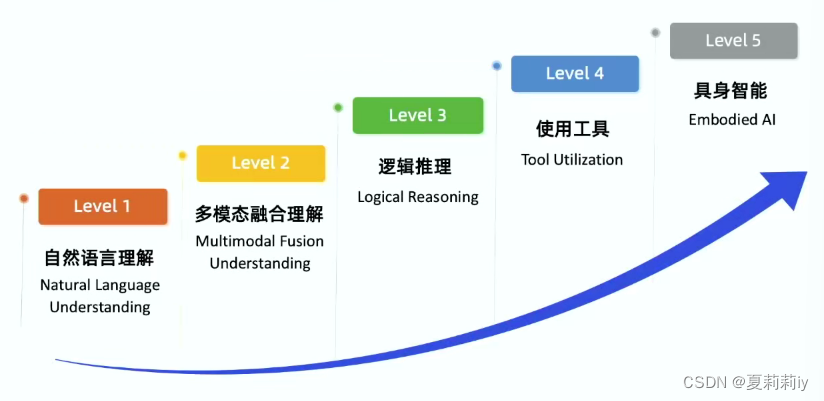
6. 群体智能
6.1. 人机物融合群智计算系统-郭斌
(1)这是多个小模型融合,不是大模型
(2)CrowdHMT平台
平台针对人、机、物融合群智计算背景下,存在的端设备资源受限、云边端设备计算异质等问题,分为机理、学习、计算三个层次,对群智协作增强机理、群智能体分布式学习、群智能体知识迁移、边端协同深度计算、端自适应模型压缩、软硬协同嵌入智能六个核心技术的实践研究、原型系统及积累资源进行共享。
CrowdHMT平台对包括智能制造、智慧旅游、智能家居、智慧城市、智慧交通、军事智能六个应用领域中的典型场景进行了系统实践,并对关键技术/算法/模块/数据进行开源,且支持该领域开发人员的下载与二次开发。欢迎各领域相关工作者来访,共同推进人机物群智计算领域的发展,共建人、机、物协作互补的智慧空间。
来源:crowdhmt-aboutus
(3)CrowdHMT新挑战
①群智涌现的非确定性
②群智计算的可演化性
③群智质量的可保障性
(4)感觉主要是项目性质的了,根据不同情况提出不同的智能方法,而且说的都是些框架
7. 深度学习
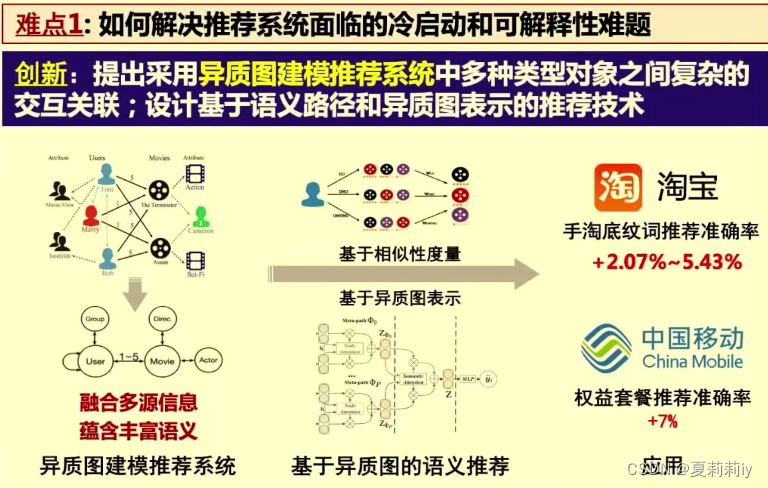
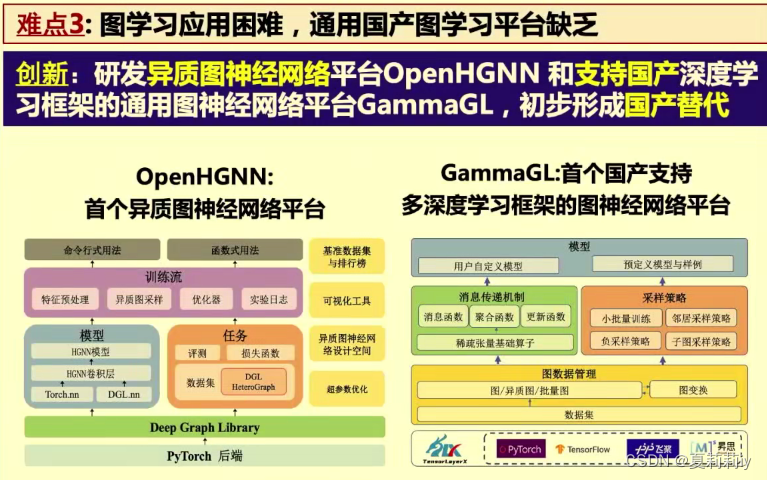
7.1. 复杂图数据建模与学习-石川
(1)复杂图数据特点和科学挑战

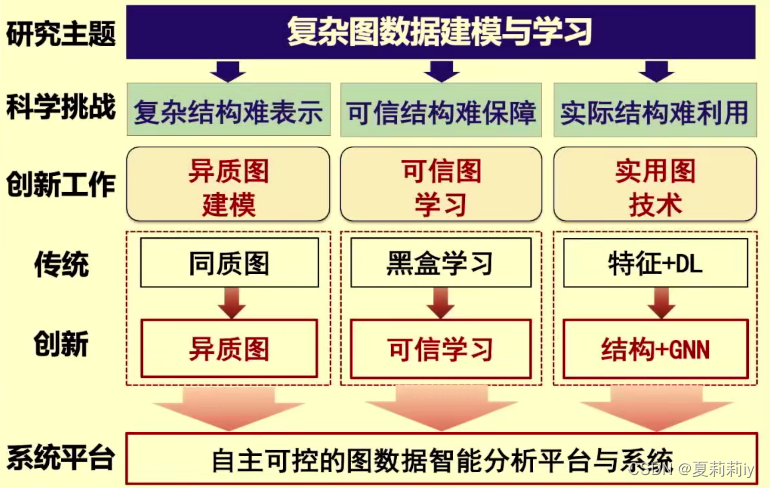
(2)异质图建模难点
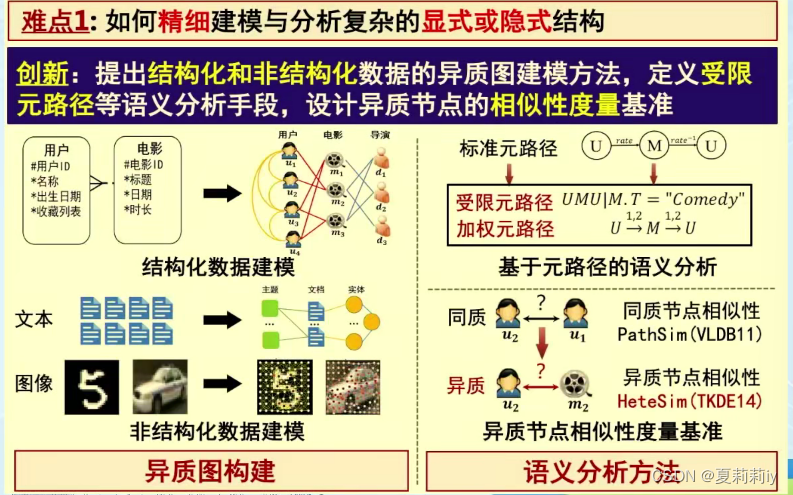

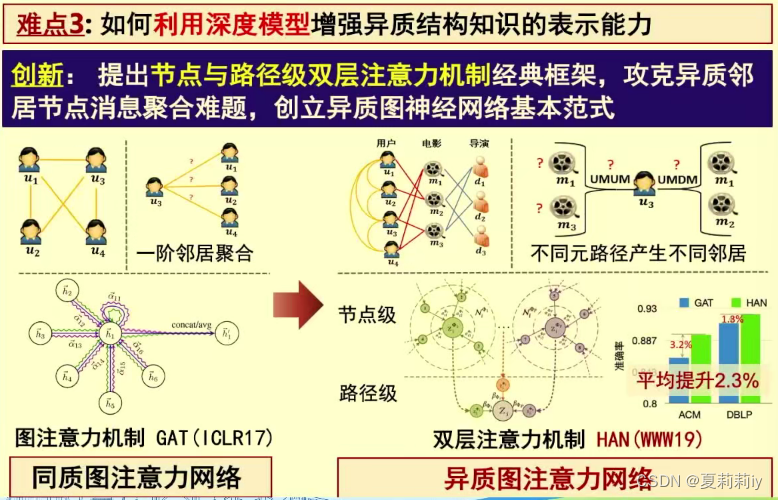
(3)可信图神经网络
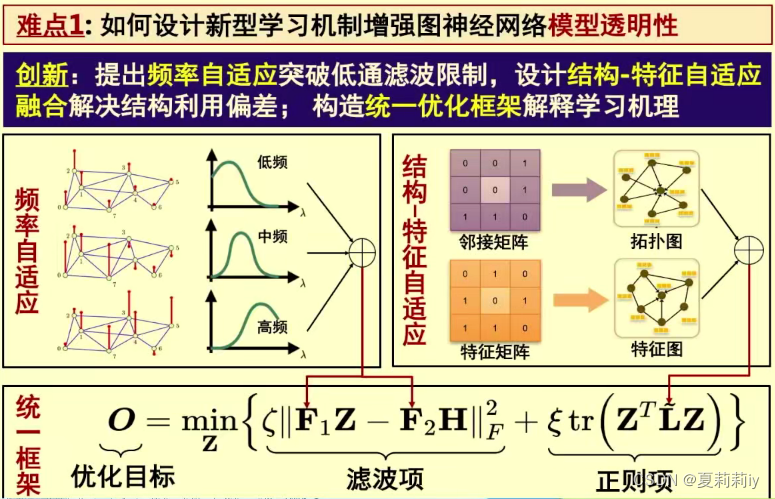
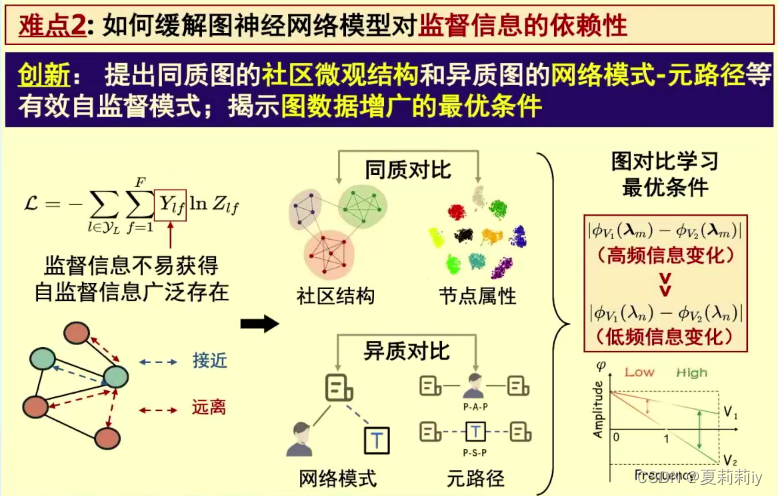
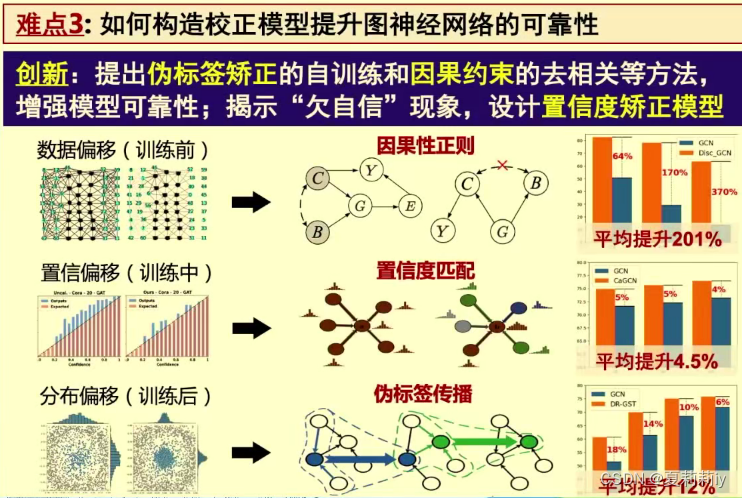
(4)图学习技术与开源平台

7.2. 基于活动(或过程),状态和事件的知识图谱-宋阳秋
(1)Knowledge graph stores semantic information and one-way or two-way relationships between nodes and edges in the form of graphs (Murali et al., 2023).
(2)过于专业,略过
7.3. GraphMAE:生成式图预训练模型-东昱晓
(1)Heterogeneous Graph Transformer(HGT)

7.4. 基于深度学习的ETA估计-鲍立胜
(1)预估到达时间(Estimated Time of Arrival,ETA)
(2)ETA算法演进

(3)空间预训练(BERT-MLM)

8. Reference List
Hu, H. et al. (2023) 'Polarimetric image denoising on small datasets using deep transfer learning', Optics & Laser Technology, vol.166, 109632, doi: Redirecting
Li, H. et al. (2023) 'Review on security of federated learning and its application in healthcare', Future Generation Computer Systems, vol.144, pp. 271-290, doi: Redirecting
Li, X. et al. (2023) 'A survey of graph neural network based recommendation in social networks', Neurocomputing, vol. 549, 126441, doi: Redirecting
Liang, T. et al. (2023) 'Efficient one-off clustering for personalized federated learning', Knowledge-Based Systems, 110813. doi: Redirecting
Murali, L. et al. (2023) 'Towards electronic health record-based medical knowledge graph construction, completion, and applications: A literature study', Journal of Biomedical Informatics, vol. 143, 104403, doi: Redirecting
Sun, F. & Zhang, Q. (2023) 'Robust transfer learning of high-dimensional generalized linear model', Physica A: Statistical Mechanics and its Applications, vol. 618, 128674, doi: Redirecting







![[fashion]女性的穿衣技巧](http://www.hzeye.com/upfiles/bbs/2004-12/20041213112424.JPG)

