代码:https://github.com/alibaba
taobao-kernel
http://kernel.taobao.org/
https://github.com/alibaba/taobao-kernel
淘宝内核是淘宝内核开发团队基于RHEL6官方内核自己定制的内核,他与RHEL6系列内核的主要区别包括:
1. 修改了一些编译脚本和错误,使得这个内核可以在RHEL5系列的系统中编译和使用,从而能够让广大用户既能够拥有RHEL5系列的稳定,同时享受到2.6.32系列内核诸多新功能和优化,并省去了重新安装操作系统的麻烦。
2. 修复了一些Redhat内核中的bug。在使用Redhat系列内核时,经常会遇到一些内核bug等,我们秉承公开的原则会及时向Redhat反馈(通过bugzilla的方式,详细见【1】),但是Redhat代码更新的过程很漫长,导致我们的问题无法及时得到解决,也没有立即可用的版本,于是我们会把这些修复加入淘宝内核中(patches.taobao目录下的部分patches),等Redhat合并了fix以后再从淘宝内核中摘除。
3. 增加了一些我们认为对淘宝业务有很大收益的特性比如netoops,bigalloc等(patches.taobao目录下的部分patches),这些特性如果等待Redhat去实现需要更长的时间,所以只能自己来做。
---------------------------------
AliJVM
http://jvm.taobao.org/index.php?title=首页
阿里有几万台Java应用服务器,上千名Java工程师、及上百个Java应用。为此,核心系统研发部专用计算组的工作之一是专注于OpenJDK的优化及定制,根据业务、应用特点及开发者需要,提供稳定,高效和深度定制的JVM版本:TaobaoJVM。
AliJVM基于OpenJDK HotSpot VM,是国内第一个优化、定制且开源的服务器版Java虚拟机。目前已经在淘宝、天猫上线,全部替换了Oracle官方JVM版本,在性能,功能上都初步体现了它的价值。
性能优化*Performance Tuning(针对淘宝x86平台的专用优化)
定制*Customization(根据淘宝业务需求)
Bug修复*Bug fixing
基于OpenJDK深度定制的淘宝JVM(TaobaoVM)
其实从严格意义上来说,在提升Java虚拟机性能的同时,却严重依赖物理CPU类型。也就是说,部署有TaobaoVM的服务器中,CPU全都是清一色的Intel CPU,且编译手段采用的是Intel C/CPP Compiler进行编译,以此对GC性能进行提升。除了优化编译效果外,TaobaoVM还使用了crc32指令实现JVM intrinsic降低JNI的调用开销
在提升Java虚拟机性能的同时,却严重依赖物理CPU类型。也就是说,部署有TaobaoVM的服务器中,CPU全都是清一色的Intel CPU,且编译手段采用的是Intel C/CPP Compiler进行编译,以此对GC性能进行提升。除了优化编译效果外,TaobaoVM还使用了crc32指令实现JVM intrinsic降低JNI的调用开销
除了在性能优化方面下足了功夫,TaobaoVM还在HotSpot的基础之上大幅度扩充了一些特定的增强实现。比如创新的GCIH(GC invisible heap)技术实现off-heap,这样一来就可以将生命周期较长的Java对象从heap中移至heap之外,并且GC不能管理GCIH内部的Java对象,这样做最大的好处就是降低了GC的回收平率以及提升了GC的回收效率,并且GCIH中的对象还能够在多个Java虚拟机进程中实现共享。其他扩充技术还有利用PMU hardware的Java profiling tool和诊断协助功能等。
---------------------------------
TProfiler
TProfiler是一个可以在生产环境长期使用的性能分析工具
https://github.com/alibaba/TProfiler
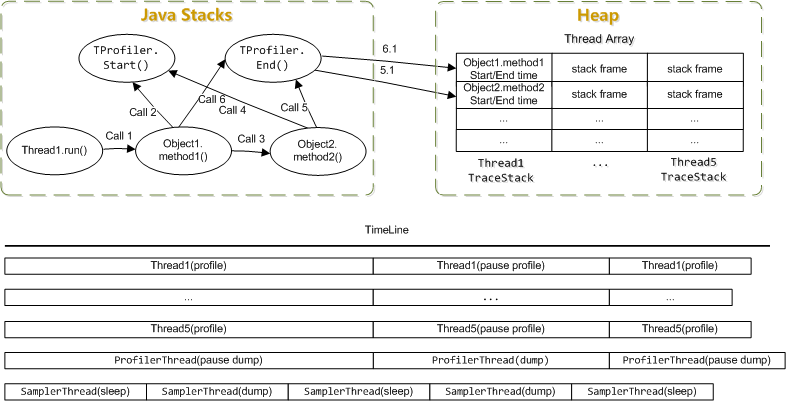
TProfiler是一个可以在生产环境长期使用的性能分析工具.它同时支持剖析和采样两种方式,记录方法执行的时间和次数,生成方法热点 对象创建热点 线程状态分析等数据,为查找系统性能瓶颈提供数据支持.
TProfiler在JVM启动时把时间采集程序注入到字节码中,整个过程无需修改应用源码.运行时会把数据写到日志文件,一般情况下每小时输出的日志小于50M.
字节码修改:
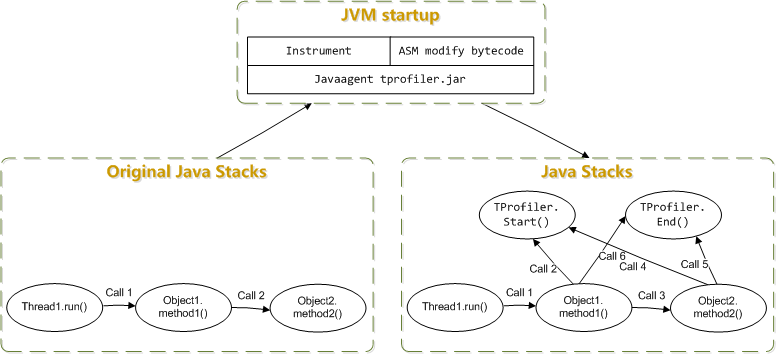
运行实现原理
---------------------------------
Jstom
https://github.com/alibaba/jstorm
jstorm可以看作是storm的java增强版本,除了内核用纯java实现外,还包括了thrift、python、facet ui。从架构上看,其本质是一个基于zk的分布式调度系统。
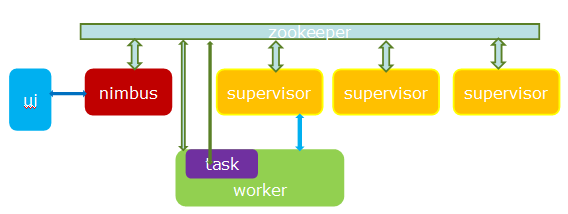
更多参考此文:Jstom简介
------------------------------------------------
tengine
http://tengine.taobao.org/
Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性。

------------------------------------------------
Dubbo
http://dubbo.io/
DUBBO是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点。
用户指南和使用背景
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
阿里内部并没有采用Zookeeper做为注册中心,而是使用自己实现的基于数据库的注册中心,即:Zookeeper注册中心并没有在阿里内部长时间运行的可靠性保障,此Zookeeper桥接实现只为开源版本提供,其可靠性依赖于Zookeeper本身的可靠性。
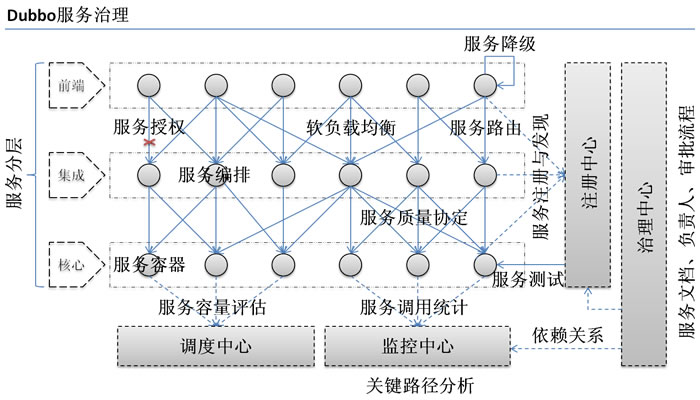
Dubbo与Zookeeper、SpringMVC整合和使用(负载均衡、容错)
Zookeeper作为Dubbo服务的注册中心,Dubbo原先基于数据库的注册中心,没采用Zookeeper,Zookeeper一个分布式的服务框架,是树型的目录服务的数据存储,能做到集群管理数据 ,这里能很好的作为Dubbo服务的注册中心,Dubbo能与Zookeeper做到集群部署,当提供者出现断电等异常停机时,Zookeeper注册中心能自动删除提供者信息,当提供者重启时,能自动恢复注册数据,以及订阅请求。
---------------------
Druid
http://www.oschina.net/p/druid/
Druid是一个JDBC组件,它包括三部分:
DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系。
DruidDataSource 高效可管理的数据库连接池。
SQLParser
Druid可以做什么?
1) 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
2) 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
3) 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
4) SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。
在线文档
-----------------------------
fastjson
http://www.oschina.net/p/fastjson
fastjson 是一个性能很好的 Java 语言实现的 JSON 解析器和生成器,来自阿里巴巴的工程师开发。
主要特点:
快速FAST (比其它任何基于Java的解析器和生成器更快,包括jackson)
强大(支持普通JDK类包括任意Java Bean Class、Collection、Map、Date或enum)
零依赖(没有依赖其它任何类库除了JDK)
------------------------------
FastDFS
http://bbs.chinaunix.net/forum-240-1.html
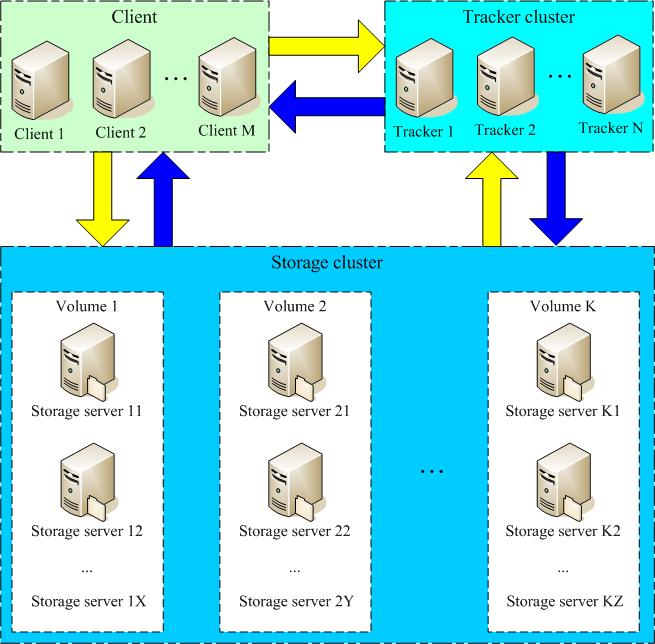
FastDFS是一个开源的分布式文件系统,对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS服务端有两个角色:跟踪器(tracker)和存储节点(storage)。跟踪器主要做调度工作,在访问上起负载均衡的作用。
存储节点存储文件,完成文件管理的所有功能:存储、同步和提供存取接口,FastDFS同时对文件的meta data进行管理。
http://www.oschina.net/p/fastdfs
https://sourceforge.net/projects/fastdfs/
-----------------------
TFS
https://github.com/alibaba/tfs
TFS是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。高可扩展、高可用、高性能、面向互联网服务。
http://tfs.taobao.org/
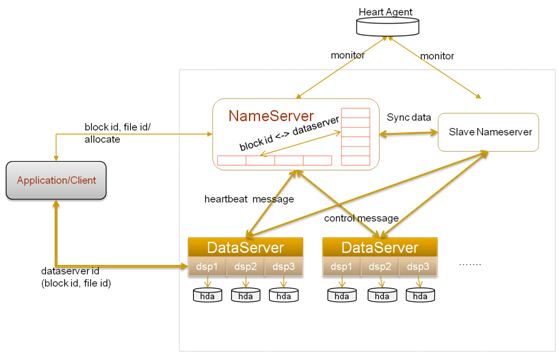
TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
TFS的总体结构
一个TFS集群由两个!NameServer节点(一主一备)和多个!DataServer节点组成。这些服务程序都是作为一个用户级的程序运行在普通Linux机器上的。
在TFS中,将大量的小文件(实际数据文件)合并成为一个大文件,这个大文件称为块(Block), 每个Block拥有在集群内唯一的编号(Block Id), Block Id在!NameServer在创建Block的时候分配, !NameServer维护block与!DataServer的关系。Block中的实际数据都存储在!DataServer上。而一台!DataServer服务器一般会有多个独立!DataServer进程存在,每个进程负责管理一个挂载点,这个挂载点一般是一个独立磁盘上的文件目录,以降低单个磁盘损坏带来的影响。
------------------------
canal和outer
canal
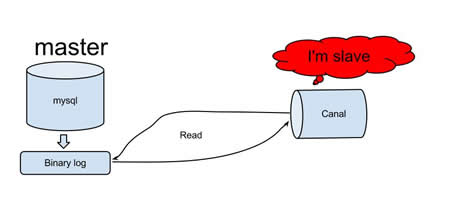
canal 是阿里巴巴mysql数据库binlog的增量订阅&消费组件。
定位: 基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql
原理相对比较简单:
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
mysql master收到dump请求,开始推送binary log给slave(也就是canal)
canal解析binary log对象(原始为byte流)
--------
otter 基于Canal开源产品,获取数据库增量日志数据。准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统。
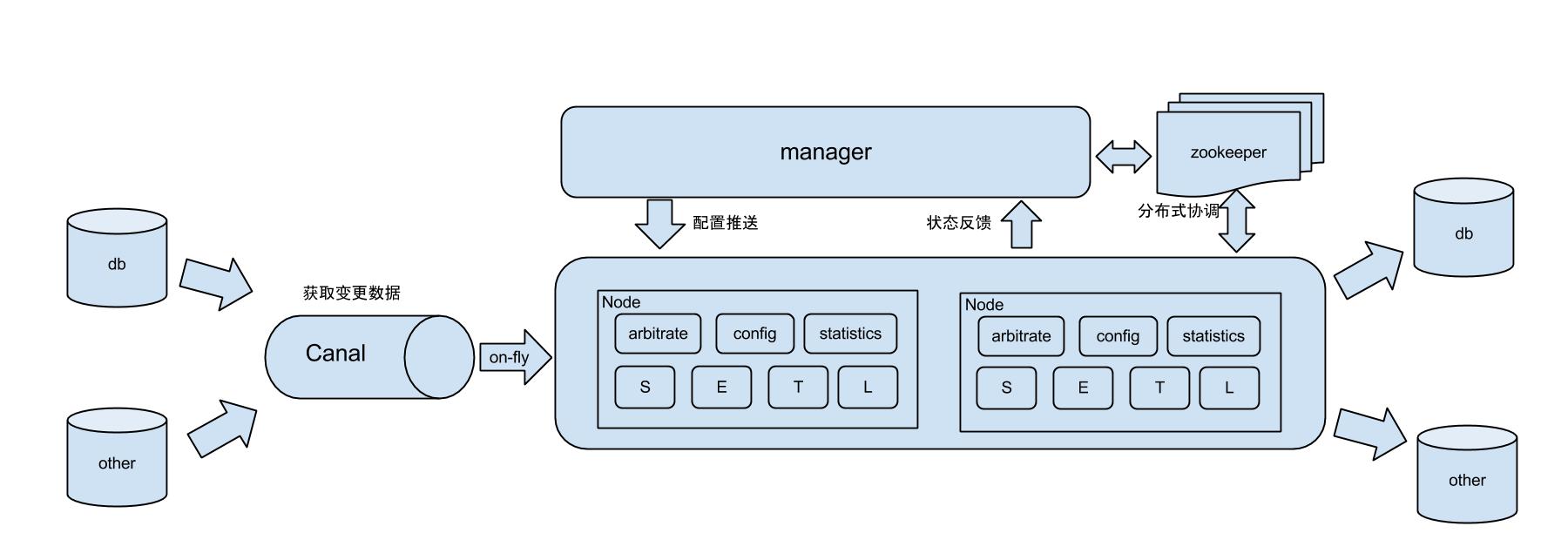
分布式数据库同步系统otter(解决中美异地机房)
杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
1. 异构库同步
a. mysql -> mysql/oracle. (目前开源版本只支持mysql增量,目标库可以是mysql或者oracle,取决于canal的功能)
2. 单机房同步 (数据库之间RTT < 1ms)
a. 数据库版本升级 b. 数据表迁移 c. 异步二级索引
3. 跨机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同不,RTT > 200ms,亮点)
4. 双向同步
a. 避免回环算法 (通用的解决方案,支持大部分关系型数据库) b. 数据一致性算法 (保证双A机房模式下,数据保证最终一致性,亮点)
5. 文件同步
a. 站点镜像 (进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片).
-------------------
DataX
https://github.com/alibaba/DataX
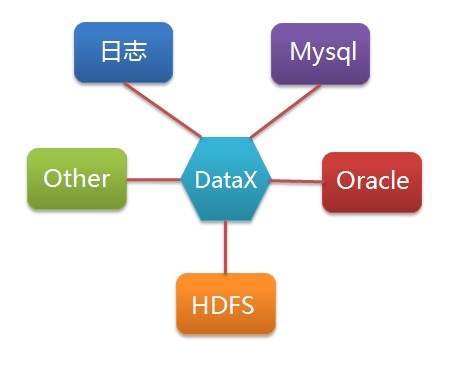
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换,由淘宝数据平台部门完成。
-----------------
LVS
LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。
http://www.linuxvirtualserver.org/ https://github.com/alibaba/LVS
---------------
Tair
http://code.taobao.org/p/tair/src/
Tair是淘宝自主开发的一个分布式key/value存储系统。
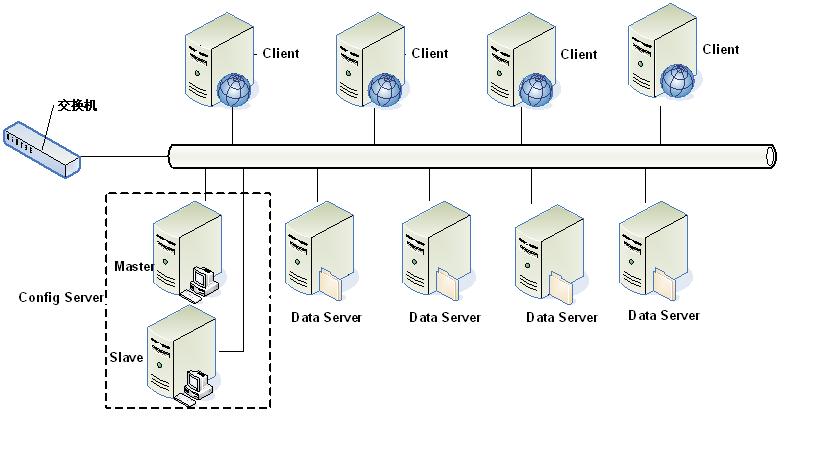
tair 是淘宝自己开发的一个分布式 key/value 存储引擎. tair 分为持久化和非持久化两种使用方式. 非持久化的 tair 可以看成是一个分布式缓存. 持久化的 tair 将数据存放于磁盘中. 为了解决磁盘损坏导致数据丢失, tair 可以配置数据的备份数目, tair 自动将一份数据的不同备份放到不同的主机上, 当有主机发生异常, 无法正常提供服务的时候, 其于的备份会继续提供服务.
tair 的总体结构
tair 作为一个分布式系统, 是由一个中心控制节点和一系列的服务节点组成. 我们称中心控制节点为config server. 服务节点是data server. config server 负责管理所有的data server, 维护data server的状态信息. data server 对外提供各种数据服务, 并以心跳的形式将自身状况汇报给config server. config server是控制点, 而且是单点, 目前采用一主一备的形式来保证其可靠性. 所有的 data server 地位都是等价的.
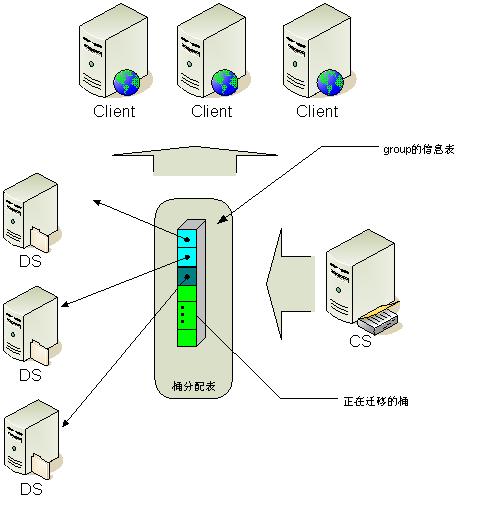
tair 的分布采用的是一致性哈希算法, 对于所有的key, 分到Q个桶中, 桶是负载均衡和数据迁移的基本单位. config server 根据一定的策略把每个桶指派到不同的data server上. 因为数据按照key做hash算法, 所以可以认为每个桶中的数据基本是平衡的. 保证了桶分布的均衡性, 就保证了数据分布的均衡性.
-----------------------------------------
OceanBase
OceanBase是阿里巴巴集团研发的可扩展的关系数据库,实现了数千亿条记录、数百TB数据上的跨行跨表事务。
http://code.taobao.org/p/OceanBase/wiki/index/
OceanBase的目标是支持数百TB的数据量以及数十万TPS、数百万QPS的访问量。无论是数据量还是访问量,即使采用非常昂贵的小型机甚至是大型机,单台关系数据库系统都无法承受。而经过对在线业务数据的分析,我们发现虽然其数据量十分庞大,例如几十亿条、上百亿条甚至更多记录,但最近一段时间(例如一天)的修改量往往并不多,通常不超过几千万条到几亿条,因此,OceanBase决定采用单独的更新服务器来记录最近一段时间的修改增量,而以前的数据保持不变。每次查询都需要把基准数据和增量数据融合后返回给客户端。
OceanBase将写事务集中在独立的更新服务器上,可以避免复杂的分布式事务,高效地实现跨行跨表事务。更新服务器上的修改增量通过定期合并操作融合多台基准数据服务器中,从而避免其成为瓶颈,实现了良好的扩展性。
揭秘阿里服务互联网金融的关系数据库——OceanBase
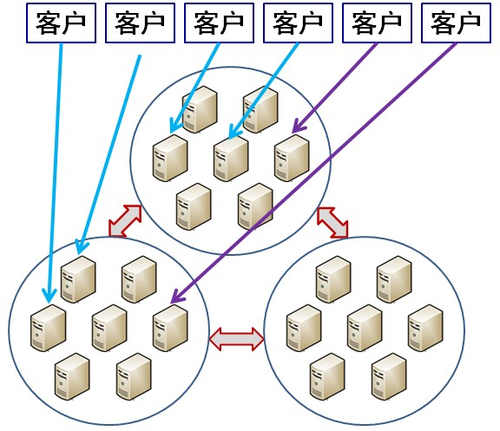
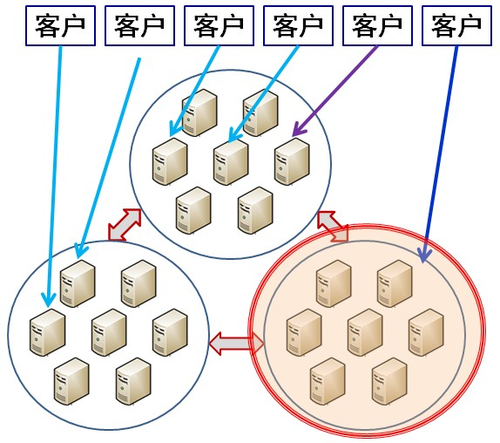
OceanBase则是“多活”设计,即多个库(3个,5个等)每个都可以有部分读写流量,升级时先把要升级的库的读写流量切走,升级后先进行数据对比,正常后逐步引入读写流量(白名单,1%,5%,10%......),一切正常并运行一段时间后再升级其他的库。
----------------------
RocketMQ
https://github.com/alibaba/RocketMQ
阿里RocketMQ Quick Start
RocketMQ单机支持1万以上的持久化队列,前提是足够的内存、硬盘空间,过期数据数据删除(RocketMQ中的消息队列长度不是无限的,只是足够大的内存+数据定时删除)
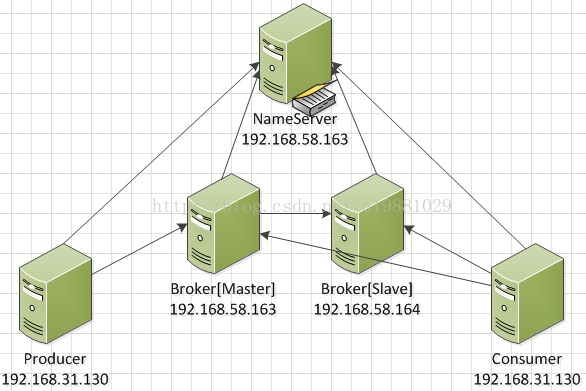
RocketMQ与Kafka对比(18项差异)【深度比较非常好】
Kafka无限消息堆积,高效的持久化速度吸引了我们,但是同时发现这个消息系统主要定位于日志传输,对于使用在淘宝交易、订单、充值等场景下还有诸多特性不满足,为此我们重新用Java语言编写了RocketMQ,定位于非日志的可靠消息传输(日志场景也OK),目前RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
数据可靠性,性能对比,单机支持的队列数,消息投递实时性,消费失败重试,消息顺序,定时消息,分布式事务消息,消息查询,消息回溯,消费并行度,消息轨迹,开发语言友好性,Broker端消息过滤,消息堆积能力
RocketMQ支持异步实时刷盘,同步刷盘,同步复制,异步复制
Kafka使用异步刷盘方式,异步复制/同步复制
Kafka单机写入TPS约在百万条/秒,消息大小10个字节
RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节。
Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长。Kafka分区数无法过多的问题
RocketMQ单机支持最高5万个队列,Load不会发生明显变化
Kafka使用短轮询方式,实时性取决于轮询间隔时间,0.8以后版本支持长轮询。
RocketMQ使用长轮询,同Push方式实时性一致,消息的投递延时通常在几个毫秒。
Kafka消费失败不支持重试。
RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
例如充值类应用,当前时刻调用运营商网关,充值失败,可能是对方压力过多,稍后再调用就会成功,如支付宝到银行扣款也是类似需求。
这里的重试需要可靠的重试,即失败重试的消息不因为Consumer宕机导致丢失。
消息查询对于定位消息丢失问题非常有帮助,例如某个订单处理失败,是消息没收到还是收到处理出错了。对于定位消息丢失问题非常有帮助,例如某个订单处理失败,是消息没收到还是收到处理出错了。
消息回溯最典型业务场景如consumer做订单分析,但是由于程序逻辑或者依赖的系统发生故障等原因,导致今天消费的消息全部无效,需要重新从昨天零点开始消费,那么以时间为起点的消息重放功能对于业务非常有帮助。
-----------------------
Tsar
tsar是淘宝自己开发的一个采集工具,主要用来收集服务器的系统信息(如cpu,io,mem,tcp等),以及应用数据(如squid haproxy nginx等)。
收集到的数据存储在磁盘上,可以随时查询历史信息,输出方式灵活多样,另外支持将数据存储到mysql中,也可以将数据发送到nagios报警服务器。
http://code.taobao.org/p/tsar/wiki/index/
https://github.com/alibaba/tsar
淘宝开发的系统监控工具 Tsar 开源
-----------------------
TDDL
淘宝分布式数据层
https://github.com/alibaba/tb_tddl
http://www.oschina.net/p/tddl
数据到了百亿级别的时候,任何一个库都无法存放了,于是分成2个、4个、8个、16个、32个……直到1024个、2048个。
这时候,数据查询的中间件对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一 个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
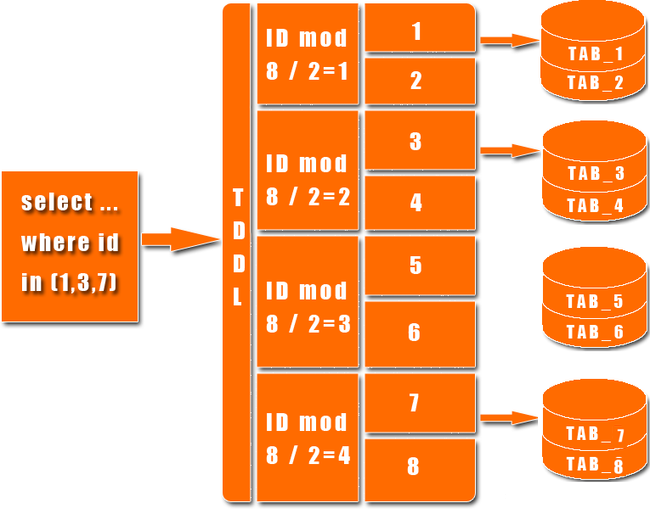
剖析淘宝TDDL(TAOBAO DISTRIBUTE DATA LAYER)
TDDL 必须要依赖 diamond 配置中心( diamond 是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置)。
-----------------------
Diamond
淘宝分布式配置管理服务Diamond 原文地址:http://codemacro.com/2014/10/12/diamond/
zookeeper的一种应用就是分布式配置管理(基于ZooKeeper的配置信息存储方案的设计与实现)。百度也有类似的实现:disconf。
Diamond则是淘宝开源的一种分布式配置管理服务的实现。Diamond本质上是一个Java写的Web应用,其对外提供接口都是基于HTTP协议的,在阅读代码时可以从实现各个接口的controller入手。
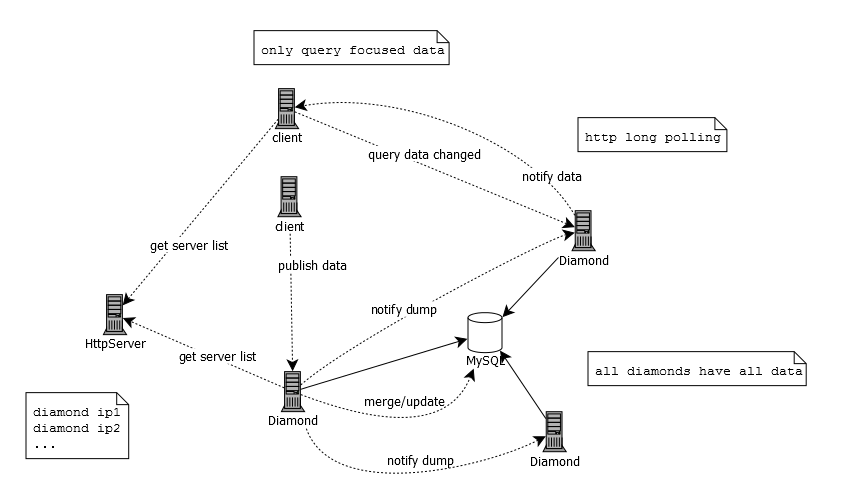
Diamond中的数据是简单的key-value结构。应用方订阅数据则是基于key来订阅,未订阅的数据当然不会被推送。数据从类型上又划分为聚合和非聚合。因为数据推送者可能很多,在整个分布式环境中,可能有多个推送者在推送相同key的数据,这些数据如果是聚合的,那么所有这些推送者推送的数据会被合并在一起;反之如果是非聚合的,则会出现覆盖。
数据的来源可能是人工通过管理端录入,也可能是其他服务通过配置管理服务的推送接口自动录入。
Diamond服务是一个集群,是一个去除了单点的协作集群。
Diamond服务集群每一个实例都可以对外完整地提供服务,那么意味着每个实例上都有整个集群维护的数据。
虽然Diamond去除了单点问题,不过问题都下降到了mysql上。但由于其作为配置管理的定位,其数据量就mysql的应用而言算小的了,所以可以一定程度上保证整个服务的可用性。
由于Diamond服务器没有master,任何一个实例都可以读写数据,那么针对同一个key的数据则可能面临冲突。这里应该是通过mysql来保证数据的一致性。每一次客户端请求写数据时,Diamond都将写请求投递给mysql,然后通知集群内所有Diamond实例(包括自己)从mysql拉取数据。当然,拉取数据则可能不是每一次写入都能拉出来,也就是最终一致性。
Diamond中没有把数据放入内存,但会放到本地文件。对于客户端的读操作而言,则是直接返回本地文件里的数据。
----------------------
Cobar
基于MySQL的分布式数据库服务中间件
https://github.com/alibaba/cobar
Cobar是提供关系型数据库(MySQL)分布式服务的中间件,它可以让传统的数据库得到良好的线性扩展,并看上去还是一个数据库,对应用保持透明。
产品在阿里巴巴稳定运行3年以上。
接管了3000+个MySQL数据库的schema。
集群日处理在线SQL请求50亿次以上。
集群日处理在线数据流量TB级别以上。
关系型数据的分布式处理系统 Cobar
Cobar是关系型数据的分布式处理系统,它可以在分布式的环境下像传统数据库一样为您提供海量数据服务。以下是快速启动场景:
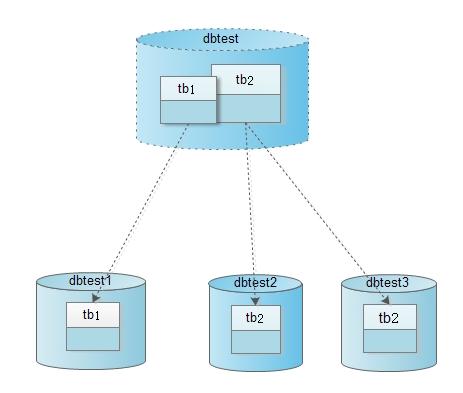
系统对外提供的数据库名是dbtest,并且其中有两张表tb1和tb2。
tb1表的数据被映射到物理数据库dbtest1的tb1上。
tb2表的一部分数据被映射到物理数据库dbtest2的tb2上,另外一部分数据被映射到物理数据库dbtest3的tb2上。
Cobar使用文档(可用作MySQL大型集群解决方案)
----------------------
beatles
https://github.com/cenwenchu/beatles
小规模即时流数据分析集群,分析规则抽象于SQL,计算规则采用MapReduce模式。
--------------------------------
综合
淘宝开放平台技术历程
=========================
参考:http://www.oschina.net/project/alibaba