通用人工智能综述
- 通用人工智能综述
- 背景介绍
- 模型演进
- 之前的模型的问题
- 学习三阶段
- 数据组织和效果评估
- 注册
- API调用
- 官方提供的模型
- 官方功能汇总
- Notion
- 元语AI
- 指令汇总
通用人工智能综述
背景介绍
ChatGPT是一个通用功能型助手。2022年12月5日,OpenAl首席执行言Sam Altman在社交媒体上发文称,ChatGPT推出五天,已突破100万用户。Al聊天机器人ChatGPT爆火出圈,已成为一个标志性事件。微软正洽谈100亿美元增持股份,并很快将其整合到微软云中。

上图中展示了两个例子,展现出了惊人的效果。
ChatGPT之所以这么受欢迎,—方面是由于其理解用户意图的能力和生成的效果比较好;另—方面,通过对话机器人的形式,使得人人都能使用。
下面将从模型演进、最初模型存在的问题、ChatGPT模型学习的三个阶段、训练 ChatGPT模型的数据组织和效果几个方面进行介绍。
模型演进
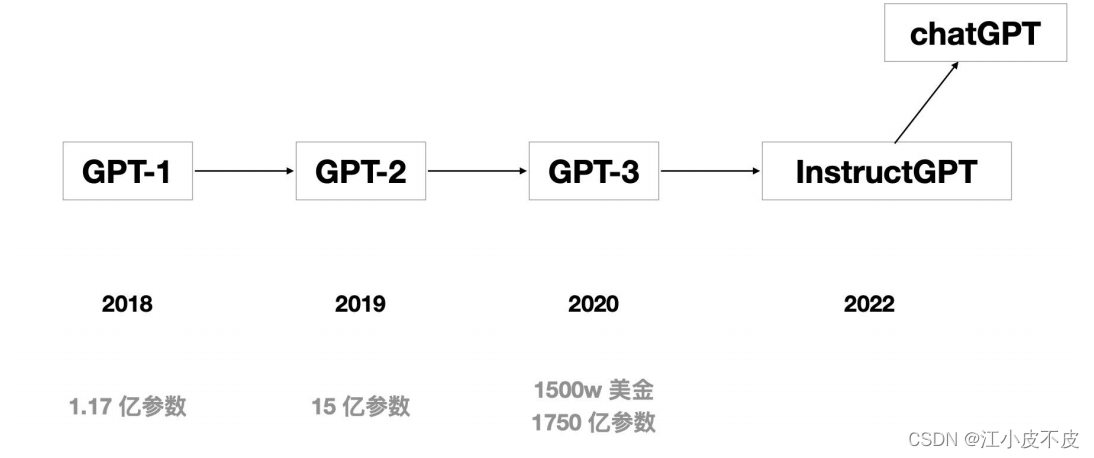
ChatGPT技术也经过了几代模型的演进,最初的 GPT模型是在2018年提出的,模型参数只有1.17亿; 2019年的时候GPT-2模型参数是15亿;到了2020年 GPT-3模型参数达到了1750亿;通过几代的模型更新迭代,到2022年出现了ChatGPT模型。
之前的模型的问题
在ChatGPT模型出来之前的模型存在什么样的问题呢?通过分析发现存在的一个比较显著的问题是对齐问题,虽然大模型的生成能力比较强,但是生成的答案有时候不符合用户意图。通过研究发现造成对齐问题出现的主要原因是语言模型训练的训练目标是预测下一个词,而不是按照用户意图来生成。为了解决对齐问题,在训练 ChatGPT模型过程中加入了基于人类反馈的强化学习( Reinforcement Learning from HumanFeedback,RLHF)过程。
学习三阶段
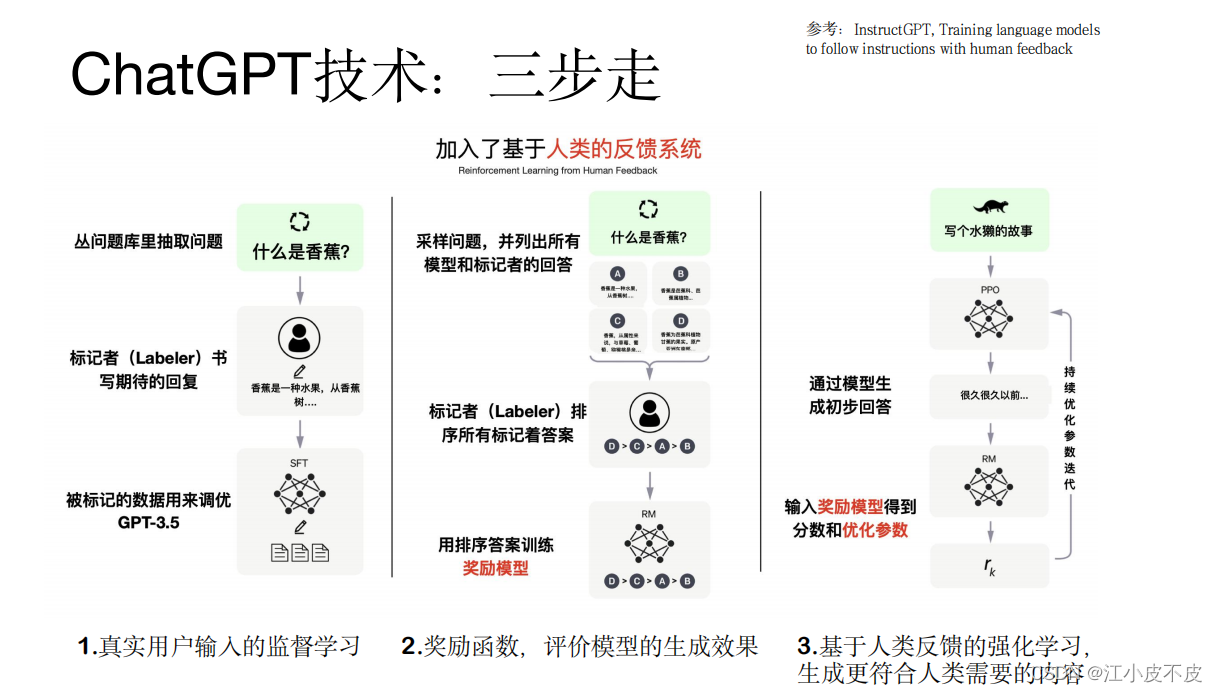
ChatGPT模型的训练过程是按照三步骤走的形式进行的。
- 第—步是在GPT模型基础上使用真实用户的输入进行监督学习,在这个过程中数据来自真实用户,数据质量比较高也比较宝贵。
- 第二步是训练一个奖励模型,对于一个query通过不同模型会产生不同的输出结果,标记者对所有模型的输出结果进行一个排序,用这些排序后的数据训练奖励模型。
- 第三步是把模型生成的初步答案输入到奖励模型当中,奖励模型会对这个答案进行一个评价,如果生成的答案符合用户的意图就给一个正向的反馈,否则就给一个负向的反馈,从而把模型调教的越来越好,这就是引入强化学习的目的,使得生成的结果更符合人类的需要。训练ChatGPT模型过程中三步走的过程如下图。
数据组织和效果评估

在训练模型之前我们需要准备好所用的数据集,在这个过程中就会遇到数据冷启动的问题,可以通过以下三个方面来解决:
- 搜集旧系统用户使用的数据集
- 让标注人员根据之前真实用户输入的问题标注一些相似的prompt和输出
- 数据标注人员从问答、写故事、生成等自己想的一些prompt。
训练ChatGPT模型的数据包含三部分数据集(77k真实数据)∶
- 基于真实用户prompt的监督学习数据,用户prompt,模型response,数据量有13k。
- 用于训练奖励模型的数据集,这部分数据对于—个prompt对应多个response的排序,数据星有33k。
- 基于奖励模型使用强化学习技术进行模型训练的数据集,只需要用户prompt,数据量有31k,对质量要求较高。
完成ChatGPT模型训练后,对于模型的评价也是比较充分的,主要从以下几个方面来评价:
- 模型生成的结果是否符合用户的意图
- 生成的结果能不能满足用户提到的约束
- 模型在客服领域能否有好的效果
注册
API调用
import openai
import osopenai.api_key = "sk-FsC9DyyuwbnqrxW7VoOhT3BlbkddffffbdOUrZJk85yWDIQ"
#代理
os.environ["http_proxy"] = "127.0.0.1:19580"
os.environ["https_proxy"] = "127.0.0.1:19580"Prompt_52CV = """
请写一段Python程序,实现从文件夹test读取所有png格式图像,
检测图片是否含有猫和狗,如有,请把该图片保存到文件夹train中。
注意:
1.请使用开源的目标检测算法,如需要安装软件,请说明使用pip的安装命令。
2.程序运行时,请打印每张图片处理的时间,程序运行的最后,需要统计有多少张图片检测到猫和狗,并统计运行总计用时。
3.需要考虑到文件读取和写入失败的异常判断,如果出现异常,需给出提示。
4.请以python代码的格式输出。
"""Answer = openai.ChatCompletion.create(model="gpt-3.5-turbo",temperature=0,max_tokens=3000,top_p=1,frequency_penalty=0,presence_penalty=0,messages=[{"role": "system", "content": "You are a useful assistant."},{"role": "user", "content": Prompt_52CV}]
)# print the completion
print(Answer)f = open('test-chatgpt-52cv.py','w',encoding='utf-8')
print(Answer["choices"][0]["message"]["content"].strip(" \n"),file=f)f.close()
官方提供的模型
| MODELS | DESCRIPTION |
|---|---|
| GPT-3.5 | 一组改进 GPT-3 的模型,可以理解并生成自然语言或代码 |
| DALL·E | 可以在给定自然语言提示的情况下生成和编辑图像的模型 |
| Whisper | 可以将音频转换为文本的模型 |
| Embeddings | 一组可以将文本转换为数字形式的模型 |
| CodexLimited beta | 一组可以理解和生成代码的模型,包括将自然语言转换为代码 |
| Moderation | 可以检测文本是否敏感或不安全的微调模型 |
| GPT-3 | 一组可以理解和生成自然语言的模型 |
官方功能汇总
https://platform.openai.com/examples
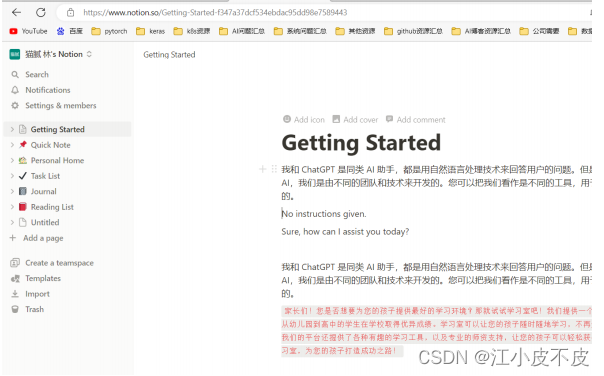
Notion
https://www.notion.so/
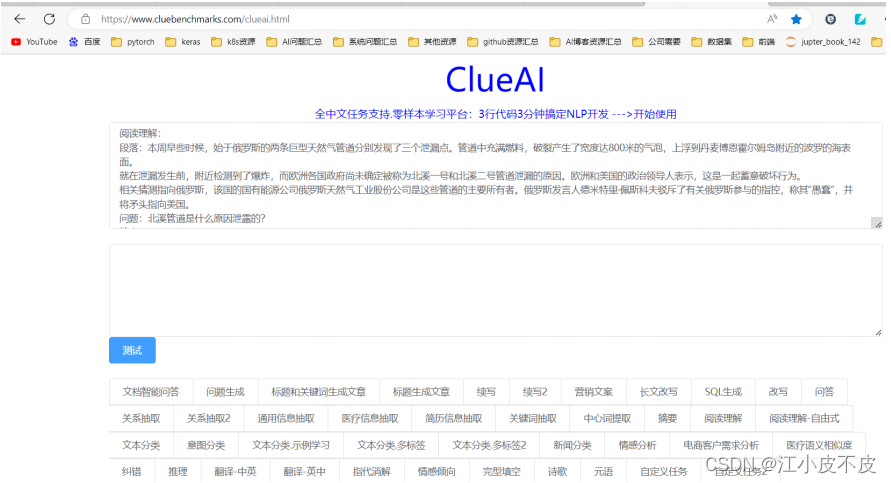
元语AI
https://www.cluebenchmarks.com/clueai.html
指令汇总
https://mp.weixin.qq.com/s?__biz=MzkxMzM3NzA1NA==&mid=2247484091&idx=1&sn=a6a720bdbc027186ee5bff0117db8735&chksm=c17fd0caf60859dc527b6332401d139d40ad55d3be51f2641c283fd8c5cfcf72acd3c0136f35&token=539485804&lang=zh_CN#rd