ABSTRACT
1、大多数现有的语义文本匹配方法在此设置中取得的成功有限,因为它们无法从长格式文本中捕获和提取主要思想和主题。
2、提出了SMASH RNN,综合了来自不同文档结构级别的信息,包括段落、句子和单词。基于注意力的分层 RNN 导出每个文档结构级别的表示。然后,将从不同级别学习的表示聚合起来,以学习整个文档的更全面的语义表示。对于语义文本匹配,连体结构耦合一对文档的表示,并推断概率分数作为它们的相似性。
3、通过三个实际应用对SMASH RNN进行了广泛的实证评估,包括电子邮件附件建议,相关文章推荐和引文推荐。
1 INTRODUCTION
语义匹配的困难有两个方面:
第一,单词和短语的语义可能是模棱两可的;
第二,当文本较长时,单个单词,短语和句子的语义可能被埋在复杂的文档结构中。
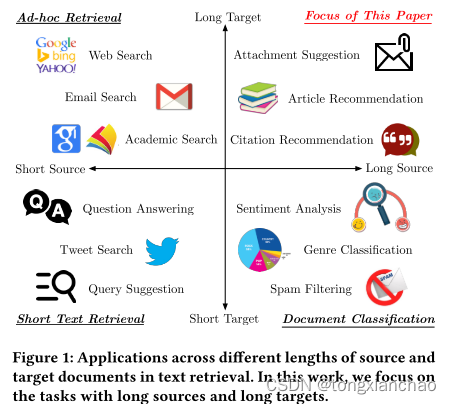
网络搜索使用短源查询,同时针对长格式文档; 在左下方,像Twitter搜索 这样的短文本检索任务使用短源查询,并针对短文档; 在右下方,像情感分析这样的文档分类任务旨在将长格式文档分类为一组有限的类。图的右上部分在语义文本匹配设置中探索的相对较少,并且,正如我们经验证明的那样,当源和目标文档变长时,许多先前提出的语义匹配方法会恶化。这提出了一个重要的研究挑战,因为长格式文档的语义文本匹配可以使无数应用程序受益,例如相关文章推荐,电子邮件附件建议,引文推荐等。
现有的深度学习方法显着提高了语义文本匹配的领域,但它们主要集中在短文档上,并且在处理长格式文档时存在明显的缺陷。首先,核心主题或想法可能很难从长篇文档的复杂叙述中识别和提取。以前的一些研究利用注意力机制从句子中提取重要的单词,但是有价值的信息仍然可以在长篇文档中的大量句子和段落中被稀释。其次,尚未考虑到长格式文件的复杂结构信息。大多数现有方法都依赖于单词级知识来计算文本相似性。诸如句子和段落之间的关系之类的结构信息通常被忽略。第三,文档的语义可能会在漫长的叙述过程中漂移。例如,在多个段落的范围内,找到作者在一系列主题中移动的文档并不少见。RNN或CNN都不能自然地捕捉或遵循这样的语义漂移。基于RNN的方法可以通过顺序处理具有不同语义的句子来获得令人困惑的文档表示。当尝试汇集和过滤不同的语义时,基于CNN的方法可能会恶化。
自然语言文档一般遵循层次结构,以帮助人们阅读和理解它们。因此,利用这些结构来训练机器学习模型至关重要,该模型可以完全捕获长格式文档的语义。最一般地,文档可以表示为段落,句子和单词序列的层次结构。文档中的不同段落和句子可以具有不同的语义含义和重要性。与这项工作最相似的研究是使用句子级信息进行文档分类。正如我们将在实验部分中显示的那样,对于长格式文档,基于句子级别的文档表示仍然不能令人满意,因为同一文档中的句子可能与不同的重要性和不同的语义相关联。相反,对文档结构的深刻理解可以有效地促进语义文本匹配。
在本文中,我们提出了基于 Siamese 多深度注意力的分层 RNN(SMASH RNN)来解决长格式文档语义匹配的问题。在连体网络的two-tower结构下,所提出模型的每个tower都是一个多深度的基于注意力的分层RNN(MASH RNN)。MASH RNN作为我们模型的主要组成部分,可以导出全面的文档表示来自多层次的文档结构。例如,文档的单词、句子和段落级别的知识可以通过三个不同深度的基于注意力的分层 RNN 导出。为了生成全面的文档表示,MASH RNN 连接所有这些文档级别的表示,旨在捕获具体的低级别观察和抽象的高级见解。结合来自 MASH RNN 的源文档和目标文档的文档表示,SMASH RNN 根据源文档和目标文档的表示以及一个额外的全连接层来估计语义匹配分数。
我们的贡献可以总结如下:
• 据我们所知,本文是在改善长格式文档语义文本匹配模型的最新性能的背景下,广泛利用文档结构以实现更好的文档表示的第一项工作。
• 我们提出了用于长格式文档语义文本匹配的SMASHRNN框架。MASH RNN是SMASH RNN的主要组件,它从文档结构的多个抽象级别学习文档表示。
• 在三个不同应用程序的公开可用数据集上进行了实验: 电子邮件附件建议,相关文章推荐和引文推荐。实验结果证明了smash RNN的有效性。我们还提供了深入的实验分析,以证明我们提出的框架的鲁棒性。
3 SEMANTIC TEXT MATCHING FOR LONG-FORM DOCUMENTS WITH SMASH RNN
3.1 Problem Statement
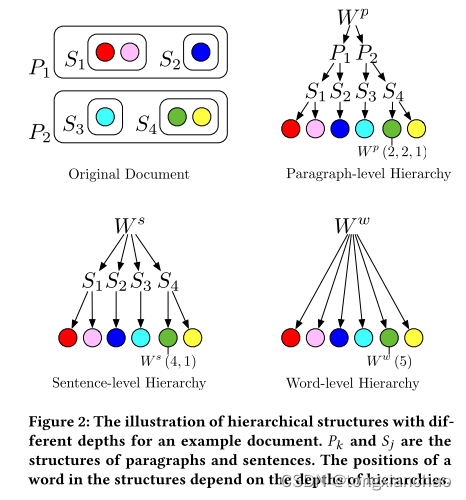
我们假设层次结构分为三个级别-段落,句子和单词。图2给出了文档d具有不同深度的层次结构的图示。d中的单词可以拟合为三个层次结构,即Wp,Ws和ww,深度3 (段落级),深度2 (句子级),和深度1 (单词级别) 分别。更准确地说,Wp (k,j,i) 是第k段第j句中的第i个单词,给定了段落级别; Ws (j,i) 是第j个句子中的第i个单词,给定句子级别的层次结构; Ww (i) 是深度为1的单词级别的第i个单词,这只是一个长序列。三个不同层次结构中的底层单词完全相同,而它们的注释根据层次深度和文档结构而不同。
3.2 Framework Overview
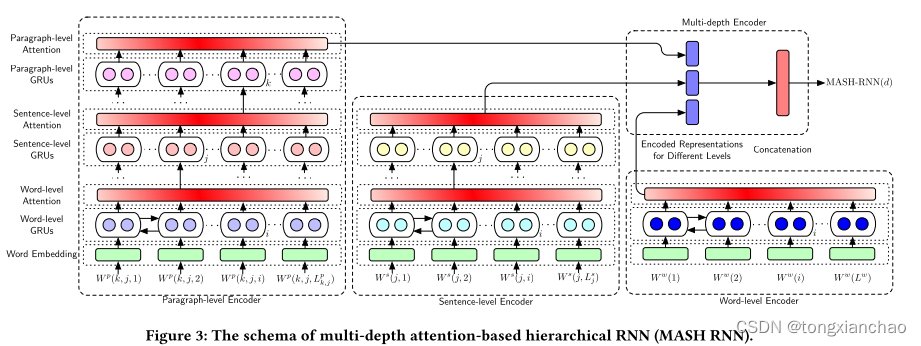
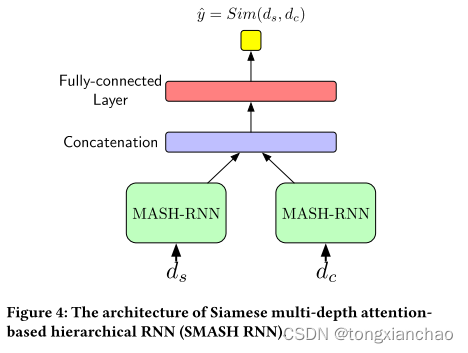
图3和4说明了我们提出的基于Siamese多深度关注的分层RNN (SMASH RNN) 的框架。在Siamese结构下,每个SMASH RNN都有两个基于多深度注意力的分层RNN (MASH RNN) 塔。对于每个文档,MASH RNN根据来自不同文档结构级别的知识得出信息表示。对于每个级别,基于注意力的分层RNN (具有相应的级别深度) 被构造为编码器,以生成该级别的表示。例如,段落级编码器使用深度3编码器生成段落级表示,而句子级编码器使用深度2编码器生成句子级表示。然后通过连接不同级别的表示来获得最终的文档表示,全面覆盖所有文档结构级别的知识。为了估计语义文本匹配的语义相似性,SMASH RNN采用带有两个MASH RNN塔的暹罗结构。给定由MASH RNN为源和目标文档生成的表示形式,具有非线性的全连接层推断概率得分,以检查具有sigmoid函数的两个文档之间的语义关系 [34]。
3.3 MASH RNN for Document Representation
我们将重点放在三个层次的文档结构上——段落、句子和单词层次。
MASHRNN中编码器的计算遵循自下而上的原则,并带有双向递归神经网络 (bi-rnn)。以段落级编码器为例。给定段落级层次结构中第k段中的第j个句子,我们首先通过单词嵌入层将句子中的单词嵌入到向量中,如下所示:
单词级:
![]()
Lp ,k,j是句子的长度,单词嵌入层emb(·) 将单词嵌入到带有嵌入矩阵的向量中。要对句子进行编码,bi-rnn会在前向传递和后向传递期间读取嵌入向量的序列。在前向传递中,bi-rnn创建了一系列前向隐藏状态
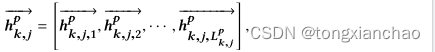
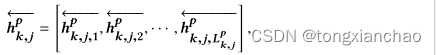
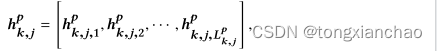
计算单词注意
![]()
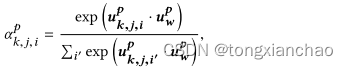
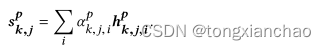
句子级:
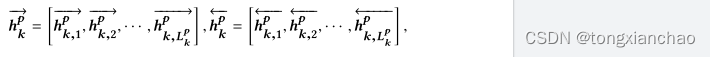
![]()
计算句子注意力
![]()
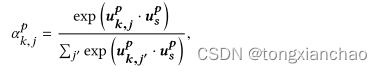

段落级:
![]()
![]()
计算段落注意力:
![]()
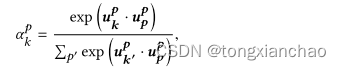

最终结果:
![]()
3.4 SMASH RNN for Semantic Text Matching
估计源文档ds和候选文档dc之间的语义相似性的SMASH RNN的结构,给定ds和dc,它们是MASH RNN对两个文档生成的表示,最终的特征向量可以表示为xf = [ds ;dc]。
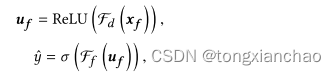
3.5 Learning and Optimization
损失函数:
![]()
4 EXPERIMENTS
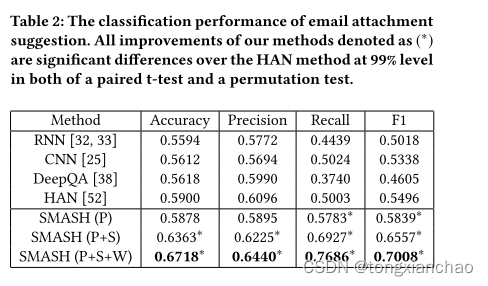
5 CONCLUSIONS
(1) 长格式文档的语义文本匹配具有影响力,具有许多有用的应用;
(2) 分层文档结构的使用对于语义文本匹配至关重要,尤其是对于长格式文档的建模;
(3) SMASH RNN可以准确地捕获长格式文档的复杂语义,即使重要消息可能发生在文档结构的任何位置以及任何级别。