1.1.1 课题来源于背景
本文选取的研究对象是某家法律电商平台,由于网站访问量的不断上升和网站内容的不断增多,用户很难从网站中及时找到自己想了解和感兴趣的相关信息,这极大地影响了用户的使用体验,导致很多用户的流失。本文决定对网站进行用户行为的探索和分析,并利用个性化推荐算法和网站的实际情况尝试对不同的用户做出个性化推荐。若能将合适的内容推荐给需要的用户,便能使用户对网站的好感度不断上升,逐步对网站产生依赖,从而形成稳定的客户源,促进企业长期的发展。
1.2 国内外研究现状
随着网络技术的不断发展,电子商务这一概念逐渐进入了很多人的生活中,无论是国外的亚马逊网站,还是国内的淘宝、天猫等购物网站都取得了很不错的效果,电商平台具有方便、快捷、高效的特点,其优越性是传统门店所无法比拟的。加上现在电商平台的安全保障和物流服务可在全国范围内配送,很多用户更乐于网上购物。而这一趋势也逐渐扩大到了各行各业,很多的企业开始将自身产品通过网络平台进行销售,电子商务化已经成为当今社会的主流趋势。
1.2.1 国外研究现状
二十世纪九十年代,电子商务在国外发展开来,很多人们开始进行网上购物。随着电子商务网站中商品信息数量的剧增,可供人们选择的商品越来越多,这些大量的信息进入用户的视野,对用户造成了一定的困扰。用户如何快速地找到自己感兴趣的商品已经变得尤为重要。在这种时代潮流下,便出现了搜索引擎和推荐系统。
随着 Web2.0 时代的到来,互联网技术得到了进一步的发展,特别是电商网站大量普及和应用。为了效仿传统购物超市中营销员这一角色,解决如何用机器更精准的向用户推荐商品这一难题,出现了许多著名的推荐算法。协同过滤则属于其中最为成功的算法之一,协同过滤受到了许多学者的关注并不断加以优化,如今已经在很多领域都取得了不错的成果。亚马逊是最早使用推荐系统的电子商务平台,基于物品的 ItemCF 算法(协同过滤算法)于 1998 年正式上线,这一算法将用户推向了一个电子商务领域发展的新高度[2]。个性化推荐算法陆续在各大电子商务网站中得到了应用,展现出了其显著功效。传统的、单一的推荐算法往往存在着冷启动、数据稀疏性、拓展性等问题[3]。随后,一大批优秀的学者开始对其性能进行优化并且开始研究各类推荐算法的结合使用。使用推荐系统已经成为了信息技术企业之间互相竞争的必备工具[4]。
1.2.2 国内研究现状
我国电子商务技术相比国外起步较晚,而对推荐系统的研究更是晚于国外。在国内,豆瓣网是最早开始使用个性化推荐的网站之一,它通过记录客户对于电影、音乐、书籍等的浏览历史和评价,然后分析用户的浏览喜好,从而为用户提供相应的资讯和相似作品的推荐。而提到国内的推荐系统,今日头条无非是其中的佼佼者,其独特的推荐算法能够精准预测用户喜好,极大地提高了用户的使用体验,在短短几年内就吸引了数亿的用户。除此之外,腾讯的 QQ 看点、淘宝的猜你喜欢、抖音的短视频推荐等都很好的发挥了个性化推荐的作用,且取得了很不错的效果。
目前推荐系统已成为国内学者研究的热点之一,国内研究者在资源数据处理的准确度、智能数据挖掘等涉及到推荐系统的各个方面都取得了丰硕的成果[1]。西安电子科技大学的孔德卫为了解决了协同过滤算法存在的矩阵稀疏性和可拓展性的问题提出了一种新的混合协同过滤推荐算法[5]。南京邮电大学的沈鹏和李涛中将协同过滤算法与内容属性过滤的优点结合,提出了一种改进的混合推荐算法[6]。张玉叶教授用 Python 的序列字典代替了二维数组存放稀疏矩阵,有效提高了算法的效率[7]。广州大学王敏针对个性化精度的问题,采用 K-means 算法对协同过滤进行了优化,有效提高了精度[8]。天津理工大学的石京京等人重新对物品相似度的计算做了定义,加入了物品间联系的计算,进一步提高了推荐的准确率[9]。在推荐系统中,协同过滤因其推荐范围广、算法较为简单、易于实现等优点,受到越来越多学者的关注[10]。 虽然目前和国外相比,我国的研究水平还有很大不足,但是毫无疑问,未来国内推荐系统必将在各个领域大量应用和快速发展。
2 相关理论与关键技术
2.1 个性化推荐系统概述
个性化推荐系统尚没有得到明确定义,但其实质都是由机器模拟销售人员向用户进行商品推荐的过程。个性化推荐在我们目前的生活中无处不在,我们所有的上网行为都会伴随着一系列的推荐。例如,当看完某部电影时系统会向用户推荐类似电影、当进入淘宝时系统会主动根据用户的历史行为和购买喜好推荐用户可能喜欢商品、当在知乎浏览和点赞过某篇创作,系统会主动推荐许多类似话题等。个性化推荐在提升用户浏览体验的同时也为企业带来了一定的收益。
目前,个性化推荐算法主要分为以下几类:基于内容过滤的推荐(CBF)、基于网络结构的推荐、协同过滤推荐(CF)、基于关联规则的推荐(ARB)、基于矩阵分解的推荐(MFB)等[5]。
2.2 协同过滤算法
协同过滤算法是众多推荐系统中应用最早、最为流行、最为成功的推荐算法之一。Tapestry 是最早被提出的个性化推荐系统[11],GroupLens[12, 13]则是最早被提出的个性化协同过滤系统[14]。协同过滤推荐算法的核心思想较为简单,例如,某个用户的好朋友对于某部观看过的电影评价很高并推荐观看时,该用户很有可能也会喜欢这部电影。即在具有相似兴趣偏好的用户之间进行交叉推荐[15]。
协同过滤算法可分为两类:基于用户的协同过滤(UserCF)和基于的项目协同过滤(ItemCF)[16],下面分别进行介绍。
2.2.1 基于用户的协同过滤
UserCF 算法的基本思想,当需要对用户 3 做出推荐时,先找到与用户 3 兴趣爱好相似的用户 1,然后从用户 1 感兴趣但是用户 3 没有接触过的物品中为用户 3 做出推荐,算法的示意图如图 2.1 所示。其核心计算包括两部分:
(1)确定与当前用户兴趣相似的用户。
(2)根据相似用户的喜好生成推荐列表。
2.2.2 基于项目的协同过滤
ItemCF 算法的基本思想:当需要对用户 1 做出推荐时,若已知用户 1 对物品 A 感兴趣,只需找到与物品 A 相似度较高的物品集合 B,然后找出物品集合 B 中用户 1 尚未接触过的产品,并对其生成推荐列表。即若是 A 与 B 两种物品的相似度较高,则对物品 A 感兴趣的用户也很大可能对物品 B 感兴趣。算法示意图如图 2.2 所示。其核心计算包括两部分:
(1) 物品间相似度的计算。
(2) 根据物品之间的相似度为用户生成推荐列表。
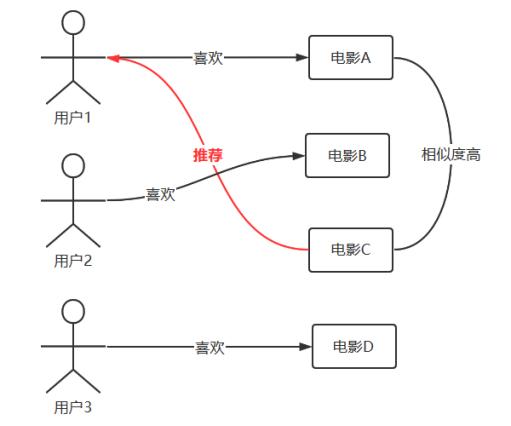
图 2.1 UserCF 算法示意图

图 2.2 ItemCF 算法示意图
2.2.3 异同点分析
从问题的角度分析,UserCF 算法解决“将当前物品推荐给哪个用户?”的问题,ItemCF 算法解决“将哪个物品推荐给当前用户?”的问题。两者的目标对象是恰好相反的,但是从推荐结果来说却是一致的。
从数据的角度分析,UserCF 算法需要维护一个庞大的兴趣相似度矩阵,当网站的用户不断增加时,计算其相似度所需的时间和空间成本都会成倍的增长。而 ItemCF 算法维护的是物品相似度矩阵,在物品数量小于用户的情况下,系统会稳定很多,相比前者更加适合电商网站。
总的来说,ItemCF 算法适合物品数远小于用户数的情景,UserCF 则相反。
2.3 物品相似度
在很多情况下,用户对物品的偏好程度并不会明确地表现出来,此时就需要根据用户的浏览记录或购买历史记录进行分析,得出用户的购物喜好,才能将相似商品推荐给用户。物品相似度则很好的解决了这一重要问题。常见的物品相似度有余弦相似度、Person 系数和 Jaccard 相似系数。
下面对其计算公式分别进行介绍。
2.3.1 余弦相似度
说明:结果绝对值越接近 1,相似度越高。

(1)
2.3.2 Person 相关系数
说明:结果绝对值越接近 1,相似度越高。
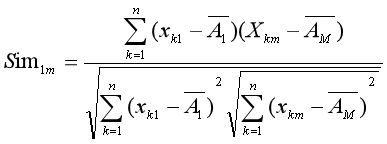
(2)
2.3.3 Jaccard 相似系数
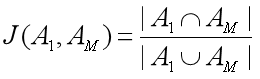
(3)
说明:结果取值越接近 1,相似度越高。
3 实验准备阶段
3.1 系统需求分析
本系统旨在分析探索目标网站的用户访问习惯和找出网站的各个话题下的热点问题,并通过分析网站实际情况建立合适的以协同过滤推荐为主的混合推荐模型对不同的用户进行个性化服务推荐,提升网站的访问量和用户体验。
3.2 可行性分析
3.2.1 技术可行性
拟采用的协同过滤算法作为常见推荐算法之一,目前已经在很多领域都取得了不错的成果,而其实现方法网上也能找到很多参考。Jaccard 相似系数最适合该系统,其计算是基于已实现的用户物品矩阵的,常规方法是按照公式(3)进行计算,或者可调用库函数,但是效率都不高。这里引进一种向量化的计算方式,更高效、符合系统要求的完成相似度的计算和物品相似度矩阵的构造。
3.2.2 经济可行性
若能将合适的内容推荐给需要的用户,便能使用户对网站的好感度不断上升,逐步对网站产生依赖,从而形成稳定的客户源,促进企业长期的发展。
3.2.3 操作可行性
Python 提供了很多的插件可用于进行数据处理,PyCharm 更是很好的提高了开发效率。Pandas 库的使用极大方便了对于数据的处理,可利用其内部函数直接读取数据库,在针对大量数据的问题上,Pandas 也提供了分块读取的功能。
3.3 数据集简介
本文采用的数据集来自北京某家法律网站一段时期内的用户访问数据,该数据集包含有 837450 条用户访问记录,包含了用户 ID、用户所访问网址、网址关键字、访问时间、访问来源等多个属性。
3.4 实验环境说明
操作系统:Ubuntu 18.04.2 LTS
编程环境:Python3.6.9
开发工具:PyCharm 2019.3.3 (Community Edition)
数据库服务器:MySql5.7.29
3.5 模型评价标准
本文将数据划分为训练集和测试集时采用随机划分的方法,保证测评结果的可靠性。
但是随机性实验的不确定性因素较多,特别是在数据集不足够大的情况下,对于结果的影响会比较大,为了避免过拟合现象,应该进行多次相同重复试验并对某些明显偏离预期的实验结果进行人为的剔除,而最终的评测指标应为多次实验结果的平均值。
本系统采用多种不同的方式来对推荐模型的性能进行评估。下面分别进行介绍。
(1) 准确率(Precision):用户喜欢当前推荐网址的概率。
若向用户推荐了 5 个网址,其中只有 2 个是用户感兴趣的,那么其 Precision 值就是 40%。
其计算公式为:
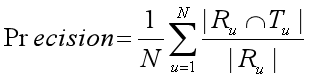
(4)
(2) 召回率(Recall):用户喜欢的网址被推荐的概率。
若向用户推荐了 5 个网址,其中有 2 个是用户感兴趣的,但是用户感兴趣的共有
10 个网址,那么其 Recall 值就是 20%。其计算公式为:
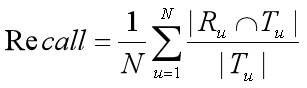
(5)
说明:在上述公式(1)、(2)中,
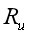
表示用户 u 的推荐网址集合,
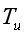
表示用户 u 真正感兴趣的网址集合。
(3) F1 指标(F1-score):综合的评价指标,计算公式为:
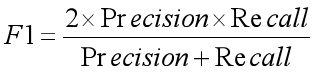
(6)
(4) 推荐成功率:若生成的推荐列表中有一个成功被用户点击,则视为推荐成功。比如给用户推荐了三个网址,只要其中有一个是用户真正喜欢的,那么这次推荐就可视为是有效推荐,该指标针对推荐总体效果而言。
个人认为推荐准确率这一指标对目标网站的推荐具有重要的意义,只要推荐的 K 个
页中,能有一个被用户成功点击,就达到了推荐的效果。而当用户跳转到新的页面后,接下来的推荐就会由下一次的算法进行生成,也很好的利用了 ItemCF 算法的本身特点。推荐网页的个数 K 不应该太多,太大量的推荐是没有意义的,也容易让用户产生反感,适得其反。
4 系统具体实现
该系统可分为四个模块,如图 4.1 所示。具体实现过程如下。

图 4.1 功能模块图
4.1 数据探索分析
对初始的用户访问数据集进行探索分析,确定用户访问行为的特点和用户感兴趣的热点话题。下面分别对网页类型、网页点击次数和网页排名进行探索分析,探索用户访问行为的总体特点和规律。并通过进一步的数据分析,解释其可能出现的原因和拟定解决方案。
4.1.1 网页类型分析
根据数据集中网页类型(fullURLld)这一属性的前 3 位数字(该属性本身有 6 或 7 位数字),可得出每个类型网页的浏览数和其占比,其结果如图 4.2 所示。
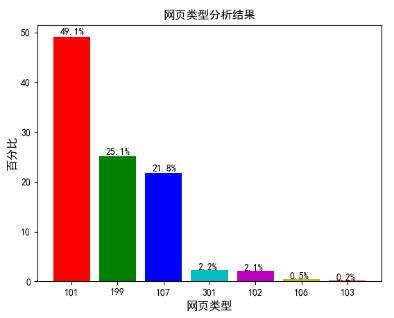
图 4.2 网页类型分析结果
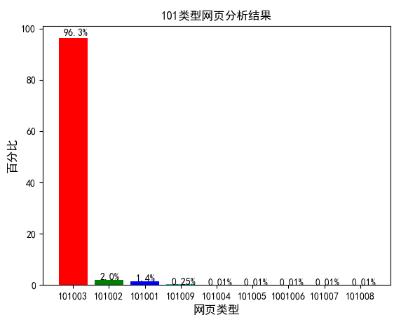
图 4.3 101 类型网页分析结果
通过图 4.2 可看出,浏览量比较多的三中网页类型分别为 101、199、107。分别对应咨询相关、其他类型和知识相关网页。根据网页类型(fullURLld)对其分别进行更详细的分析,其结果如图 4.3 所示。通过图 4.3 可看出,在网页类型 101 中,占比最多的为 101003,其对应的网页类型为咨询内容页。接着是 101002 和 101001,分别对应咨询列表页和咨询首页。
而 107 和 199 类型的网页都是只有一个内部类型,那么就要通过其他办法进行内部划分。例如按照网址的详情进行正则匹配进行划分,结果如图 4.4 所示。或依据网页关键词进行划分,结果如图 4.5 所示。
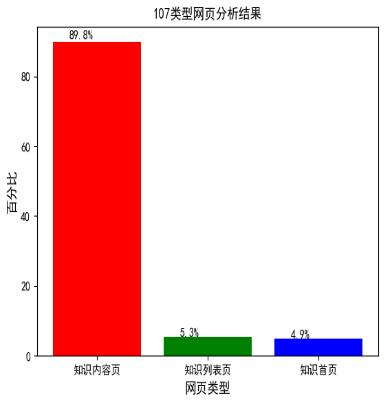
图 4.4 107 类型网页分析结果
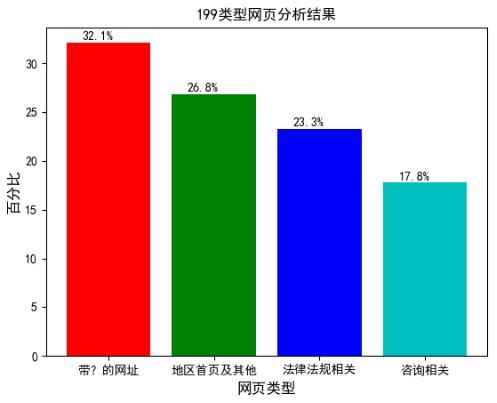
图 4.5 199 类型网页分析结果
通过图 4.5 可轻易发现在 199 类型中有点大量带有‘?’的网址,利用其网页关键字信息对其进行进一步分析,结果如图 4.6 所示。
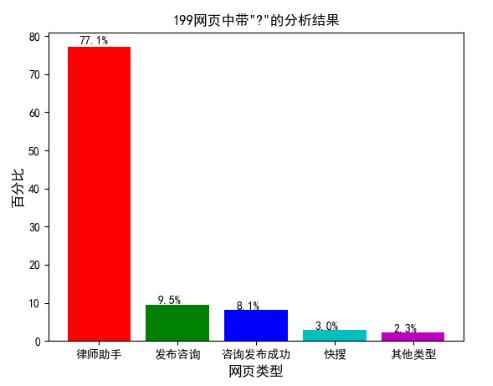
图 4.6 199 网页中带“?”的分析结果
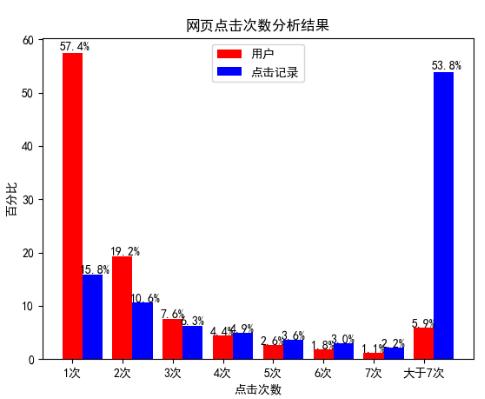
图 4.7 网页点击次数分析结果
结论:在众多类型的网页中,用户对咨询和知识相关的内容最感兴趣,应该着重将该类网页推荐给用户。在后续系统中,将着重对这些内容进行模型的构建和分析。
4.1.2 点击次数分析
统计用户浏览网页次数的情况,结果如图 4.7 所示,可得出两个结论。
结论一:大约 20% 的用户,为网站提供了 70% 的浏览量。(大体上满足二八原则)。
结论二:有 76.6% 的用户点击不超过两个网页。经验证发现,这些用户都是通过百度等搜索引擎进去的某个问题详情页,在找到或者未找到想要的答案后便离开了。如何通过向新用户推荐其感兴趣的网页,让这些用户多在网站内停留一会,已经成为当前急需解决的问题。
4.1.3 热门网址统计
根据不同类别对网页的流行度进行分析,得出用户比较感兴趣的话题。
例如,婚姻类型的热点话题分别为离婚协议书的写法、最新产假规定和中国婚姻法规定。咨询类型的热点话题分别为火车和高铁上是否可以带酒,收入证明的写法和最低工资标准。热点话题往往会得到大多数人的青睐,可能会在后面的推荐中取得很不错的效果。
4.2 数据预处理
4.2.1 属性规约
由于初始数据集中数据量特别的庞大,属性也很多,但是真正对研究有用的属性并不是很多,所以在预处理开始前,便只将对研究有用的属性保留并导出生成新的数据集,舍弃其余没用的属性。经分析,模型需要的属性有用户的真实 IP(realIP)、网址(fullURL)、网址类型(fullURLID)和网页标题(pageTitle)。
4.2.2 数据清洗
在探索分析的过程中发现了许多不适合参与推荐的网址,需要将这些网址提前删去。数据清洗的规则和结果如表 4.1 所示。
表 4.1 数据清洗规则表
删除数据规则 | 删除数据记录 | 百分比 |
律师助手数据 | 54927 | 0.07 |
咨询发布成功数据 | 5220 | 0.01 |
中间类型网页数据 | 22 | 0.00 |
不包含 lawtime 关键字 | 81 | 0.00 |
非 HTML 类型数据 | 106258 | 0.13 |
非婚姻类型数据 | 639645 | 0.78 |
重复浏览记录数据 | 14646 | 0.02 |
由于数据量太大,使得后面的工作很难进行,决定选取婚姻类型的话题进行接下来的工作,也就是说在预处理阶段筛选婚姻类型数据,可以在模型构建阶段极大的减少算法的时间复杂度和减轻计算机的硬件负担。
4.2.3 数据变换
经过探索分析发现,存在许多带“?”的网址和存在翻页功能的网址,即不同的网址对应相同的内容。若是直接将这类网址在清洗阶段删除掉,会导致损失大量的有效数据,对后面的研究产生一定的影响,所以这类网址应该对其进行还原并进行去重操作。也就是说,直接把存在翻页的网页第二页内容推荐给用户显然是不合适的,因此需要从目标网页的第二页还原到第一页(首页)。
4.3 模型构建
本系统采用的核心算法为 CF 算法,并基于目标网站的特性(用户多、物品少),选择使用 ItemCF 算法。而且由于目标网站的用户行为只有浏览与否,而没有像其他电商网站的购买、评分和评论行为,也就是说不存在显式的兴趣偏好,所以在相似度的计算方面采用最合适的 Jaccard 相似系数。其工作流程图如图 4.8 所示。

图 4.8 ItemCF 算法工作流程图
4.3.1 数据集的划分
经过数据预处理的婚姻类型数据,共包含 16651 条访问记录。根据选取的 N 值(N 为提前设置好的用户最少访问网页个数,当用户访问网页数大于 N 时才可入选模型数据集,例如若是某个用户只访问了一个网页,那么便无法进行后续的模型学习和测评,这类数据属于无效数据)对数据进行筛选,然后将其按照一定的比例随机地划分为训练集数据和测试集数据,分别用于模型的学习和性能评测。
4.3.2 测试集用户字典的构造
为了方便对模型推荐结果的评测,构建测试集用户网址浏览字典。其 Key 值对应用户的 IP,Values 值对应此用户访问过的所有网址。例如表 4.2 所示。
表 4.2 用户网址浏览字典
Key | Values |
用户 8 | 网址 A、网址 B、网址 C |
用户 9 | 网址 C、网址 A |
用户 10 | 网址 E、网址 B、网址 A、网址 D |
4.3.3 用户物品矩阵的构建
对训练集的用户数据构造用户物品矩阵,例如表 4.3 所示。
表 4.3 用户物品矩阵
网址 A | 网址 B | 网址 C | 网址 D | 网址 E | |
用户 1 | 1 | 1 | 0 | 0 | 1 |
用户 2 | 0 | 1 | 0 | 1 | 0 |
用户 3 | 1 | 1 | 1 | 1 | 1 |
用户 4 | 1 | 1 | 0 | 1 | 0 |
用户 5 | 1 | 1 | 0 | 0 | 1 |
用户 6 | 0 | 0 | 0 | 1 | 0 |
用户 7 | 1 | 0 | 0 | 0 | 0 |
4.3.4 物品相似度矩阵的构建
依据上一阶段的用户物品矩阵和公式(3),很容易可以计算出物品相似度矩阵,结果例如表 4.4 所示。
表 4.4 物品相似度矩阵
网址 A | 网址 B | 网址 C | 网址 D | 网址 E | |
网址 A | 0.00 | 0.67 | 0.20 | 0.29 | 0.60 |
网址 B | 0.67 | 0.00 | 0.20 | 0.50 | 0.60 |
网址 C | 0.20 | 0.20 | 0.00 | 0.25 | 0.33 |
网址 D | 0.29 | 0.50 | 0.25 | 0.00 | 0.17 |
网址 E | 0.60 | 0.60 | 0.33 | 0.17 | 0.00 |
4.3.5 推荐列表的生成
有了上述的物品相似度矩阵,便可轻易的找出与当前访问网址相似度较高的前 K 个网址,对用户生成推荐列表,例如表 4.5 所示。
表 4.5 推荐列表
访问网址 | 推荐网址 1 | 推荐网址 2 | |
用户 8 | 网址 A | 网址 B | 网址 E |
用于 9 | 网址 C | 网址 E | 网址 D |
用户 10 | 网址 E | 网址 A | 网址 B |
4.4 模型测评
借助之前构建好的测试集用户浏览字典,分别从 Precision、Recall、F1-score 和推荐成功率对当前模型进行评估。上述测评结果如表 4.6 所示。
表 4.6 测评结果
用户 8 | 用户 9 | 用户 10 | 平均值 | |
Precision | 0.50 | 0.00 | 1.00 | 0.50 |
Recall | 0.50 | 0.00 | 0.67 | 0.39 |
F1-score | 0.50 | 0.00 | 0.80 | 0.43 |
推荐成功率 | 1 | 0 | 1 | 0.67 |
5 模型测试与总结
很明显,上述 ItemCF 算法有个致命的缺陷:若是当前用户浏览的网址在已知的物品相似度矩阵中找不到,那么便不存在与其相似的物品(网址),推荐也便无从谈起。那么便需要与非个性化推荐进行结合使用,这里使用了两种比较常见的非个性化推荐算法:Popular 算法与 Random 算法。
Popular 算法:按照当前话题下网址的流行度,找到用户没有浏览过的前 K 个热门网址,为用户生成推荐列表。
Random 算法:随机的挑选当前话题中用户没有浏览过的 K 个网址,为用户生成推荐列表。
通过大量、随机的实验发现,Random 算法的各项评测指标都要远远低于 ItemCF 算法和 Popular 算法,这也是意料之中的。在物品很多的情况下很难通过随机化推荐的方式为用户推荐到满意的内容,但是该推荐算法可以提高冷门物品(网址)的曝光率,在某种特定条件下可以适当采用。而 Popular 算法的表现则超出预期的好,在各项指标上甚至超越了 ItemCF 算法。究其原因,很可能是因为当前的物品相似度矩阵的规模还不够大,数据集不够全面,还没有发挥协同过滤算法最大的性能。加上由于目标网站的性质和人们的行为特点,比较热门的内容往往会得到更多人的关注,所以可利用 Popular 算法解决 ItemCF 算法的冷启动问题。
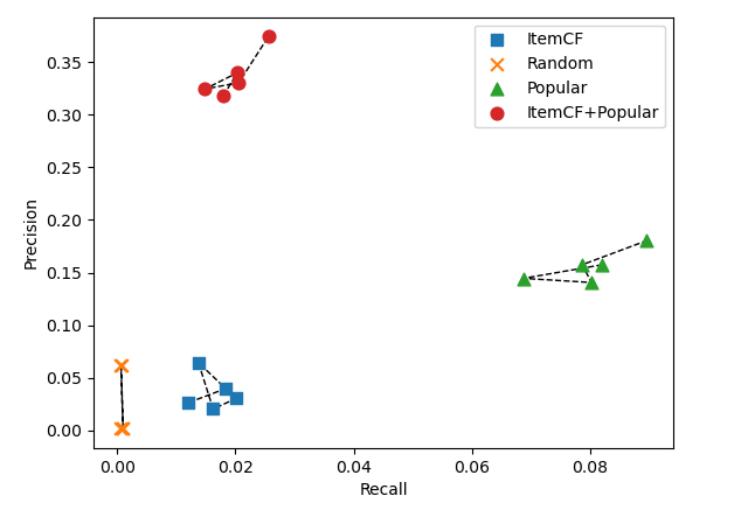
图 5.1 准确率-召回率图
图 5.1 和图 5.2 是多次随机性实验中较为典型的结果,由图 5.1 可看出,Popular 算法在 Recall 和 Precision 指标上甚至都要优于 ItemCF 算法,这是超出预期的。而将 ItemCF 算法与 Popular 算法结合后可以极大的提高推荐的 Precision,而其 Recall 相比较 ItemCF 算法也有一定的提升。由图 5.2 可以看出,随着推荐个数 K 的提升,各个算法的推荐成功率都大体呈上升趋势,而 ItemCF 算法与 Popular 算法的结合推荐,可以使当前的推荐成功率进一步提升,对于网站的实际应用来说,该提升是极为重要和有意义的。
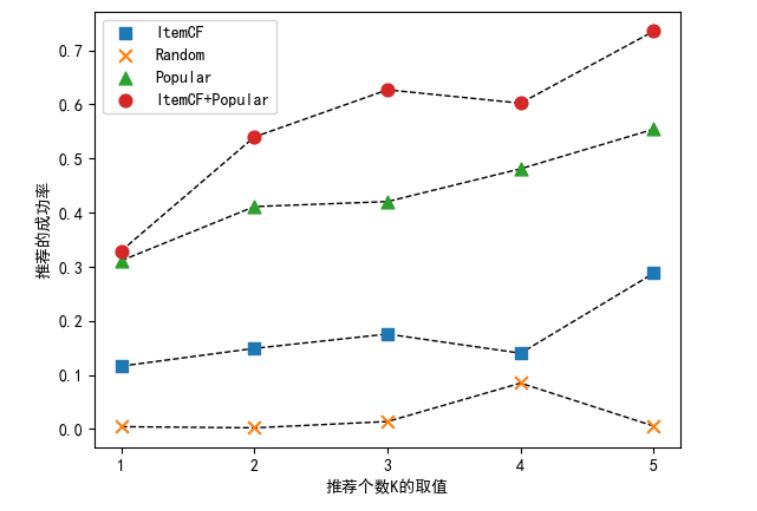
图 5.2 推荐成功率图
由于给新用户一开始推荐的是热门网址,加上新用户也倾向于热点话题的浏览,而老用户才会浏览一些比较非热门的网址。在 ItemCF 算法中,两个网址同时被浏览的次数越多,则其相似度就越高,这就可能导致由于某几个热门网址同时被一些新用户浏览,其相似度就会很高,那么系统会总是将这些网址推荐给用户,对于老用户的使用体验便很不好,因此需要对相似度的计算公式(3)进行进一步的改进,改进后相似度的计算公式为:
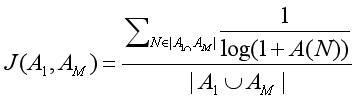
(7)
最终确立的推荐模型工作流程图如图 5.3 所示。(物品相似度矩阵已提前构造完毕)
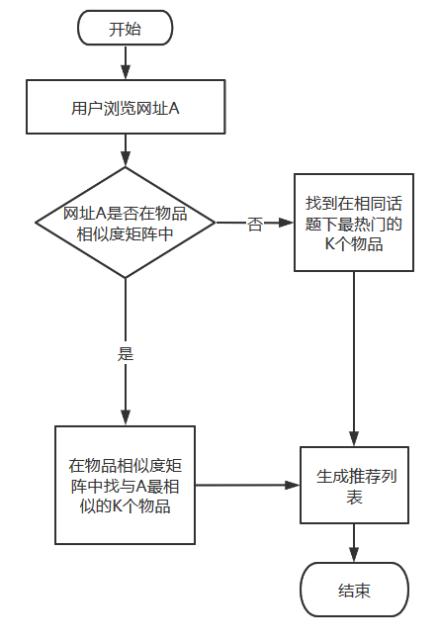
图 5.3 最终推荐流程图
经过上述的分析,已经确立了合适的推荐模型。当用户浏览网址时,首先在物品相似度矩阵中查找此网址,若存在,则直接根据相似度进行推荐。若是不存在,那么就找到在相同话题下最热门的 K 个物品,为用户生成推荐列表即可。该模型不仅可以解决 ItemCF 算法的冷启动问题,而且在各项性能指标上都取得了可观的提升。
项目:https://download.csdn.net/download/qq_38735017/87425101