项目结构
https://github.com/Collapsar-G/social_worker_library
后端使用以下模块:
pymsql、flask
前端使用vue搭建
完成过程
在完成上参考了《“系统安全”课程项目:一个实用社工库的建设》,加入了一些自己的理解。
数据初始化
导出为csv格式
由于拿到手的数据是SQL Server的MDF文件,在解压后多达90G,查询起来有诸多不便,所以将数据统一导出为 .csv 格式,方便进行下一步的项目搭建。
.csv文件用
\r做字段间分隔符,用\r\n做行分隔符。在一开始的时候由于考虑不够周全,所以使用,做分隔符,结果发现在昵称、群名字、群简介等数据中有,的存在会使.csv格式出错。在检查确认文件中不会出现\r\n后采用了新的分割方式。(QQ群简介的换行是用<br>来实现)
统一csv文件为 UTF-8 编码
由于拿到手的文件编码方式不统一,存在很多乱码,所以需要统一文件格式,决定将文件编码统一为UTF-8。但是对每一个csv文件单独设置编码有些麻烦,所以就查询资料发现了chardet库,可以获取文件的编码方式,但是在实际使用过程中会发现,这个库识别编码速度奇慢,而且有些文件识别不出来。
参考资料:chardet库:识别文件的编码格式
继续查资料,发现了cchardet这个库,可以更快更准确地获得文件的编码方式,所以换用cchardet来获取文件编码,代码如下:
def get_encoding(filename):"""Returns the file encoding format"""with open(filename, 'rb') as f:print(chardet.detect(f.read()))return chardet.detect(f.read())['encoding']"""
输出:{'encoding': 'UTF-8', 'confidence': 0.9900000095367432}
"""
这样就可以通过遍历文件目录下的所有文件并重新读写来实现目录下所有文件的重新编码:
遍历文件目录代码如下:
def traverseFile(root):"""return list with all files in root"""file_list = []for f in os.listdir(root):f_path = root + '/' + fif os.path.isfile(f_path):file_list.append(f_path)else:file_list += traverseFile(f_path)return file_list
文件统一编码为UTF-8代码如下:
def to_utf8(root):"""return file with encode utf-8"""print("Start encoding file")for fn in traverseFile(root):encoding = get_encoding(fn)if encoding != "UTF-8":with open(fn, 'r', encoding=get_encoding(fn), errors='ignore') as f:reader = f.read()with open(fn, "w", encoding="utf-8") as csvfile:csvfile.write(reader)print(fn, "successful")else:print(fn, " don't need to code")
在编码UTF-8时还出现了一些小状况:
会出现一些无法读取的字符(未知原因,大部分编码都是正常的)所以在查询后发现,可以在打开文件时加上一条
errors='ignore',如上面代码中所写,这样忽视掉极少数异常编码后终于可以正常运行了。

csv文件放入数据库
由于csv文件将同一数据分为了若干表,并且建索引有些繁琐,所以决定批量导入MySQL来建立索引。如果一条一条读写的话速度有些慢,经过查询发现MySQL有语句LOAD DATA可以导入csv文件。
在导入过程中,一开始没有设置主键,所以导入速度很快,但是有个缺点是重复数据可以频繁输入,同时查询时速度特别慢,所以决定添加主键。为了之后前端方便,所以将每一个数据表的添加信息放入config.py文件中,在添加到数据库完成后写入config.json文件,具体代码如下:
resources_add_list = {"GroupData": ["./DATA/GroupData", "QQNum,QunNum", "id,QQNum,Nick,Age,Gender,Auth,QunNum"],"QunInfo": ["./DATA//QunInfo", "QunNum", "id,QunNum,MastQQ,CreateDate,Title,Class,QunText"]}
resources_add_list只有要新附加到数据库中的信息,其中,"GroupData"、"QunInfo"是数据表的名字,对应列表中第一项是文件目录,第二项是主键(同时也是前端可用于查询的项),第三项是数据表的不同列。
数据写入数据库代码如下:
def load_csv(csv_file_path, table_name, primary_key, database=DATABASE):"""Load csv into mysql"""print("writing %s into table %s" % (csv_file_path, table_name))# 打开csv文件file = open(csv_file_path, 'r', encoding=get_encoding(csv_file_path))# 读取csv文件第一行字段名,创建表reader = file.readline()b = reader.split(',')colum = ''# primary_key = ''for a in b:colum = colum + a + ' varchar(255),'# primary_key = primary_key + a + ','# colum = colum[:-1]# primary_key = primary_key[:-1]# 编写sql,create_sql负责创建表,data_sql负责导入数据create_sql = 'create table if not exists ' + table_name + ' ' + '(' + colum + 'primary key' + '(' + primary_key + ')' + ')' + ' DEFAULT CHARSET=utf8 '# create_sql = 'create table if not exists ' + table_name + ' ' + '(' + colum + ')' + ' DEFAULT CHARSET=utf8'data_sql = "LOAD DATA LOCAL INFILE '%s' INTO TABLE %s FIELDS TERMINATED BY '\\r' LINES TERMINATED BY '\\r\\n' " \"IGNORE 1 LINES" % (csv_file_path, table_name)print(data_sql)# 使用数据库cur.execute('use %s' % database)# 设置编码格式cur.execute('SET NAMES utf8;')cur.execute('SET character_set_connection=utf8;')# 执行create_sql,创建表cur.execute(create_sql)# 执行data_sql,导入数据cur.execute(data_sql)conn.commit()# 关闭连接# conn.close()# cur.close()def data2mysql(root, table_name, primary_key):"""loat all csv to mysql:param root::return:"""for fn in traverseFile(root):load_csv(fn, table_name, primary_key)
数据初始化完整代码:点击跳转
后端api搭建
后端使用flask框架搭建,计划搭建三个接口:
测试后端连接
功能描述:在用户进入页面初始化时掉用,检测api是否正常
请求链接:/s/
请求方式:POST
**参数详情:**无
返回参数:
| 参数 | 类型 | 说明 |
|---|---|---|
| code | number | 状态码,200表示正常,500服务器异常 |
| msg | string | 提示信息 |
示例:
{"code": 200,"msg": "success!"
}
获取项目参数
**功能描述:**返回项目的完整参数
请求链接:/s/config/
请求方式:POST
**参数详情:**无
返回参数:
| 参数 | 类型 | 说明 |
|---|---|---|
| code | number | 状态码,200表示正常,400API异常,500服务器异常 |
| msg | string | 提示信息 |
| config | json | 项目参数文件 |
示例:
{"code": 200,"config": {"GroupData": {"result_class": {"Age": null,"Auth": null,"Gender": null,"Nick": null,"QQNum": null,"QunNum": null,"id": null},"search_key": {"QQNum": "","QunNum": ""}},"QunInfo": {"result_class": {"Class": null,"CreateDate": null,"MastQQ": null,"QunNum": null,"QunText": null,"Title": null,"id": null},"search_key": {"QunNum": ""}}},"msg": "Success!"
}
查询接口
**功能描述:**返回项目的完整参数
请求链接:/s/config/
请求方式:POST
参数详情:
| 参数 | 类型 | 说明 |
|---|---|---|
| database | string | 数据表名称 |
| 其它参数 | string | database数据表对应的主键中任意几个 |
{"database":"QunInfo","QunNum":"1000000"
}
返回参数:
| 参数 | 类型 | 说明 |
|---|---|---|
| code | number | 状态码,200表示正常,400API异常,500服务器异常 |
| msg | string | 提示信息 |
| data | json | 查找的对应结果 |
| class_data | json | data中每一项数据对应的class |
示例:
{"class_data": ["id","QunNum","MastQQ","CreateDate","Title","Class","QunText"],"code": 200,"data": [["355462","1000000","62","2005-01-29","北京怀柔欧曼重卡","2977","☆喜歡..や偷看..ゞě.伱的臉ぐ☆<br/>┊ず..帶着ぺ股.ふ.香甜的氣味..ヅ┊"]],"msg": "success"
}
前端搭建
前端使用vue+Vuetify搭建,本来打算表单可以利用config接口的信息动态生成,每次添加数据不用改动前端,但是在实现过程中遇到了一些问题,索性放弃。
数据查询界面
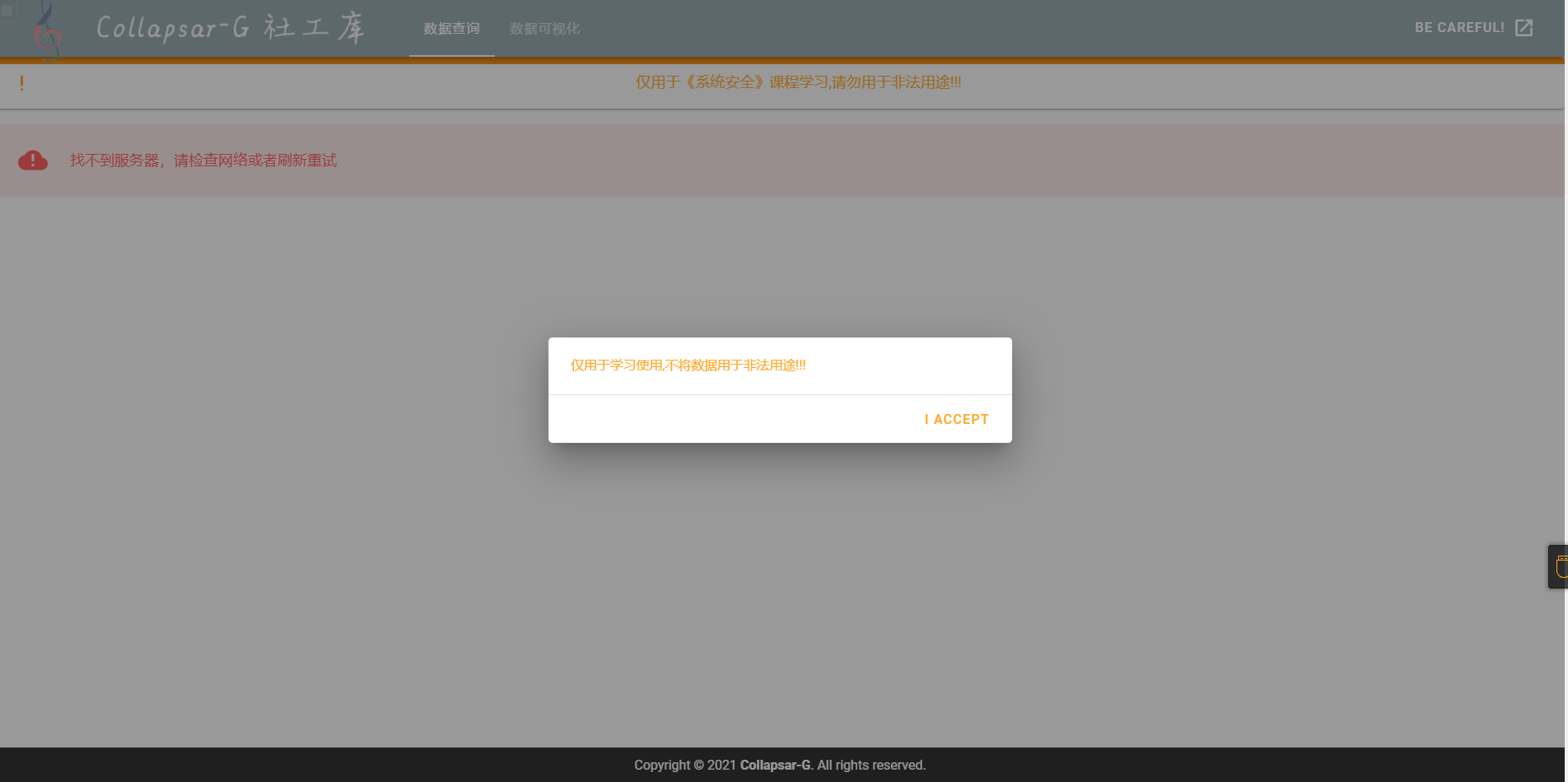
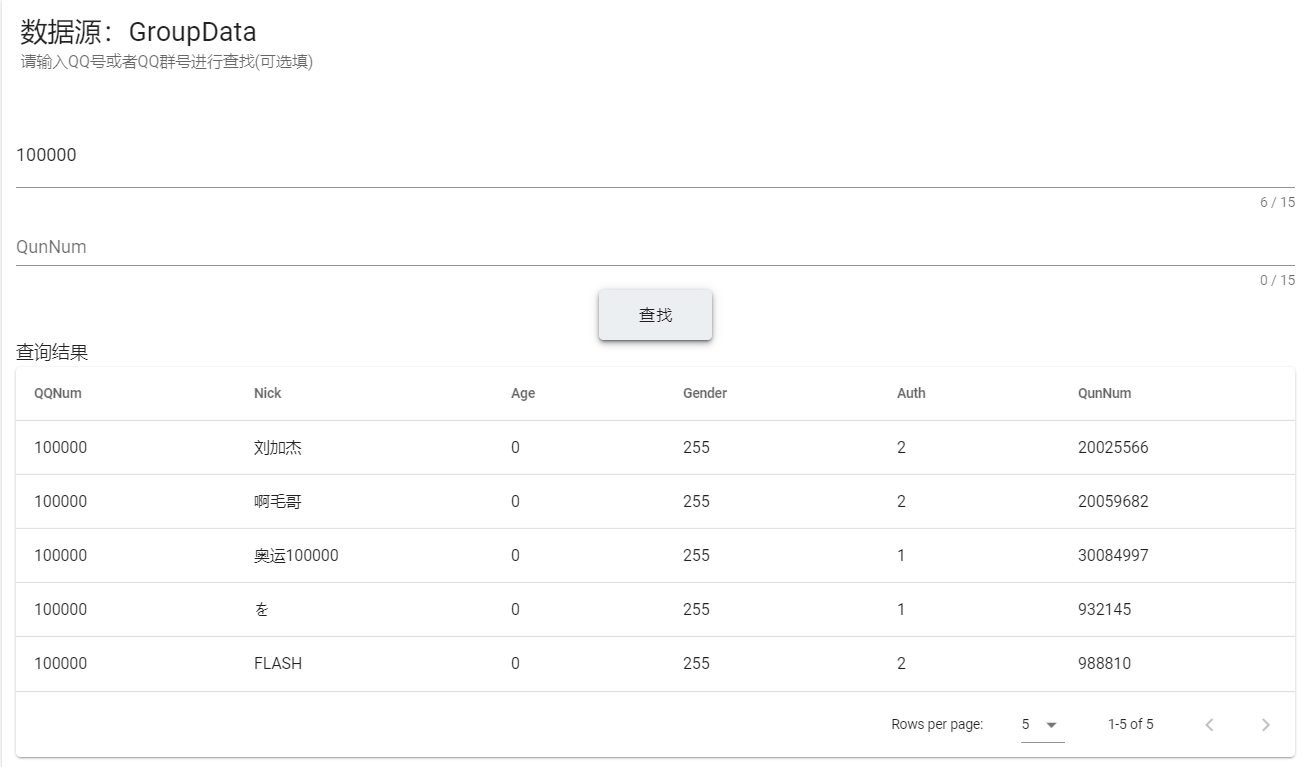
社交网络可视化界面
可视化后端
在一开始打算做动态的可视化,在搜索社交网络可视化过程中,发现一个名为netwulf的python库,效果如下:
import networkx as nx
from netwulf import visualizeG = nx.barabasi_albert_graph(100,m=1)
visualize(G)
测试效果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ePk1Dk9a-1619275673795)(https://cdn.jsdelivr.net/gh/Collapsar-G/image/img/20210318195301.gif)]
效果不太理想,所以改用networkx库来生成静态图像:
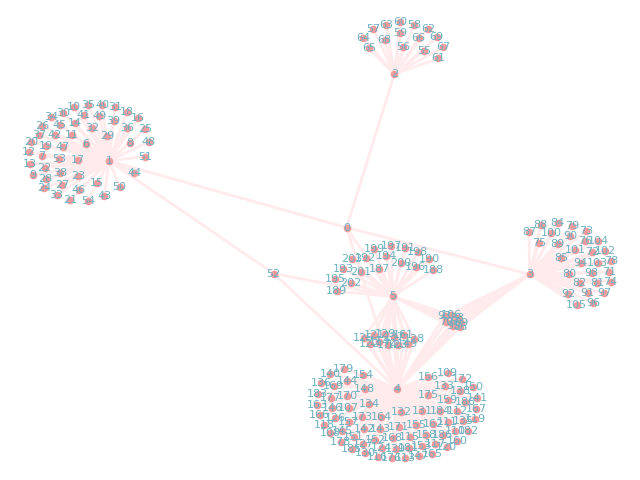
具体代码如下:
import json
from flask import Blueprint, request, jsonify
import networkx as nx
import matplotlib.pyplot as plt
import pymysql
from io import BytesIO
import base64
from config import SQL_config, DATABASE
import simplejson# SQL_config = {'host': 'localhost',
# 'port': 3306,
# 'user': 'root',
# 'passwd': '8520',
# 'charset': 'utf8mb4',
# 'local_infile': 1
# }
# DATABASE = 'ssdata'## 显示中文,及字体设置
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['font.size'] = 10
plt.rcParams['axes.unicode_minus'] = Falseconn = pymysql.connect(**SQL_config)
cur = conn.cursor()
# 使用数据库
cur.execute('use %s' % DATABASE)
# 设置编码格式
cur.execute('SET NAMES utf8;')
cur.execute('SET character_set_connection=utf8;')visualization = Blueprint('visualization', __name__)@visualization.route('/visualization/', methods=['POST'])
def visualizationdata():"""查询接口@param content:数据的查询@return code(200=正常返回,400=错误),data"""try:param = request.get_json()key = param.get('key')value = param.get('value')except:return jsonify(code=400, msg='参数错误')if key not in ["QQNum", "QunNum"]:return jsonify(code=400, msg='参数错误')result = result2bs64(key, value, 1)if result["code"] == 400:return jsonify(code=400, msg='参数错误')elif result["code"] == 200:return jsonify(code=200, msg='successful!', image=result["image"], id2data=result["id2data"])elif result["code"] == 300:return jsonify(code=300, msg="未查询到相关数据")else:return jsonify(code=400, msg='未知错误')def get_weight(key, value, n):f = open('./config.json', 'r')content = f.read()config = json.loads(content)f.close()table = "GroupData"# print("success")SQL = ""ls = []SQL = "select * from %s where %s= %s " % (table, key, "'"+value+"'")print(SQL)try:result = cur.execute(SQL)print(result)data = cur.fetchall()print(data)conn.commit()except():return {"code": 400, "msg": "数据读取错误"}if result == 0:return {"code": 300, "msg": "未查询到相关数据"}qqnum_ls = ["QQNum", "QunNum"]qunnum_ls = ["QunNum", "QQNum"]label2id = {}id2data = {}ls_label2id = []node = 0G = nx.Graph()G.add_node(node)label2id[str(key + ":" + value)] = nodeid2data[node] = str(key + ":" + value)ls_label2id.append(str(key + ":" + value))node += 1if key == "QQNum":# SQL = "select * from %s where %s=%s " % (database, key, value)ls = qqnum_ls * nls2 = qunnum_ls * nv = [value]# print(ls)for i in range(len(ls)):# print(i)temp = []for ve in v:SQL = "select * from %s where %s=%s " % (table, ls[i], "'"+ve+"'")try:result = cur.execute(SQL)data = cur.fetchall()conn.commit()except():return {"code": 400, "msg": "数据读取错误"}if result == 0:continueelse:# print(data)for h in data:te = h[list(config["resources_list"][table][1].split(sep=',', maxsplit=-1)).index(ls2[i])]temp.append(te)if str(ls2[i] + ":" + te) in ls_label2id:# G.add_node(label2id[str(ls2[i] + te)])G.add_edge(label2id[str(ls[i] + ":" + ve)], label2id[str(ls2[i] + ":" + te)])else:G.add_node(node)ls_label2id.append(str(ls2[i] + ":" + te))label2id[str(ls2[i] + ":" + te)] = nodeid2data[node] = str(ls2[i] + ":" + te)node += 1G.add_edge(label2id[str(ls[i] + ":" + ve)], label2id[str(ls2[i] + ":" + te)])# print(temp)v = temp[:]return {"code": 200, "msg": "successful!", "G": G, "id2data": id2data}if key == "QunNum":# SQL = "select * from %s where %s=%s " % (database, key, value)ls2 = qqnum_ls * nls = qunnum_ls * nv = [value]# print(ls)for i in range(len(ls)):# print(i)temp = []for ve in v:SQL = "select * from %s where %s=%s " % (table, ls[i], "'"+ve+"'")try:result = cur.execute(SQL)data = cur.fetchall()conn.commit()except():return {"code": 400, "msg": "数据读取错误"}if result == 0:continueelse:# print(data)for h in data:te = h[list(config["resources_list"][table][1].split(sep=',', maxsplit=-1)).index(ls2[i])]temp.append(te)if str(ls2[i] + ":" + te) in ls_label2id:# G.add_node(label2id[str(ls2[i] + te)])G.add_edge(label2id[str(ls[i] + ":" + ve)], label2id[str(ls2[i] + ":" + te)])else:G.add_node(node)ls_label2id.append(str(ls2[i] + ":" + te))label2id[str(ls2[i] + ":" + te)] = nodeid2data[node] = str(ls2[i] + ":" + te)node += 1G.add_edge(label2id[str(ls[i] + ":" + ve)], label2id[str(ls2[i] + ":" + te)])# print(temp)v = temp[:]return {"code": 200, "msg": "successful!", "G": G, "id2data": id2data}def result2bs64(key, value, n=1):print(key, value, n)result = get_weight("QQNum", value, 1)if result["code"] == 200:G = result["G"]pos = nx.spring_layout(G, iterations=1000)nx.draw(G, pos, with_labels=True, node_size=20, node_color="#F39A9D", edge_color="#FFEAEC", alpha=1.0,font_size=8,font_color='#6DB1BF', width=2)# plt.show()save_file = BytesIO()plt.savefig(save_file, format='png')# 转换base64并以utf8格式输出save_file_base64 = base64.b64encode(save_file.getvalue()).decode('utf8')return {"code": 200, "msg": "successful!", "id2data": result["id2data"],"image": "data:image/png;base64," + str(save_file_base64)}else:return result
参考资料:Networkx绘图和整理功能的参数,networkx,画图,函数参数
warning:特别要注意的是,由于把生成图的脚本写在了flask的路由里,所以每次生成图片的缓存不会自动清除,每一次查询都会在原图上继续添加节点,在查询资料G.clear()可以删除图中的所有结点,但是尝试后不能正常使用,索性将生成图片的函数封装如单独的包 utils.py中。
!!!!
发现这个bug还是存在,继续debug,发现在networks这个包中调用了matplotlib.pyplot来生成图片,所以需要添加代码plt.clf()来释放内存。
继续测试发现还是不能正常运行,继续找bug发现自己在生成base64格式的图片时,调用:
from io import BytesIO
save_file = BytesIO()plt.savefig(save_file, format='png')
来将图片写入内存,所以需要用save_file.close()来释放内存。
继续测试,发现生成的图片恢复正常
实现结果:
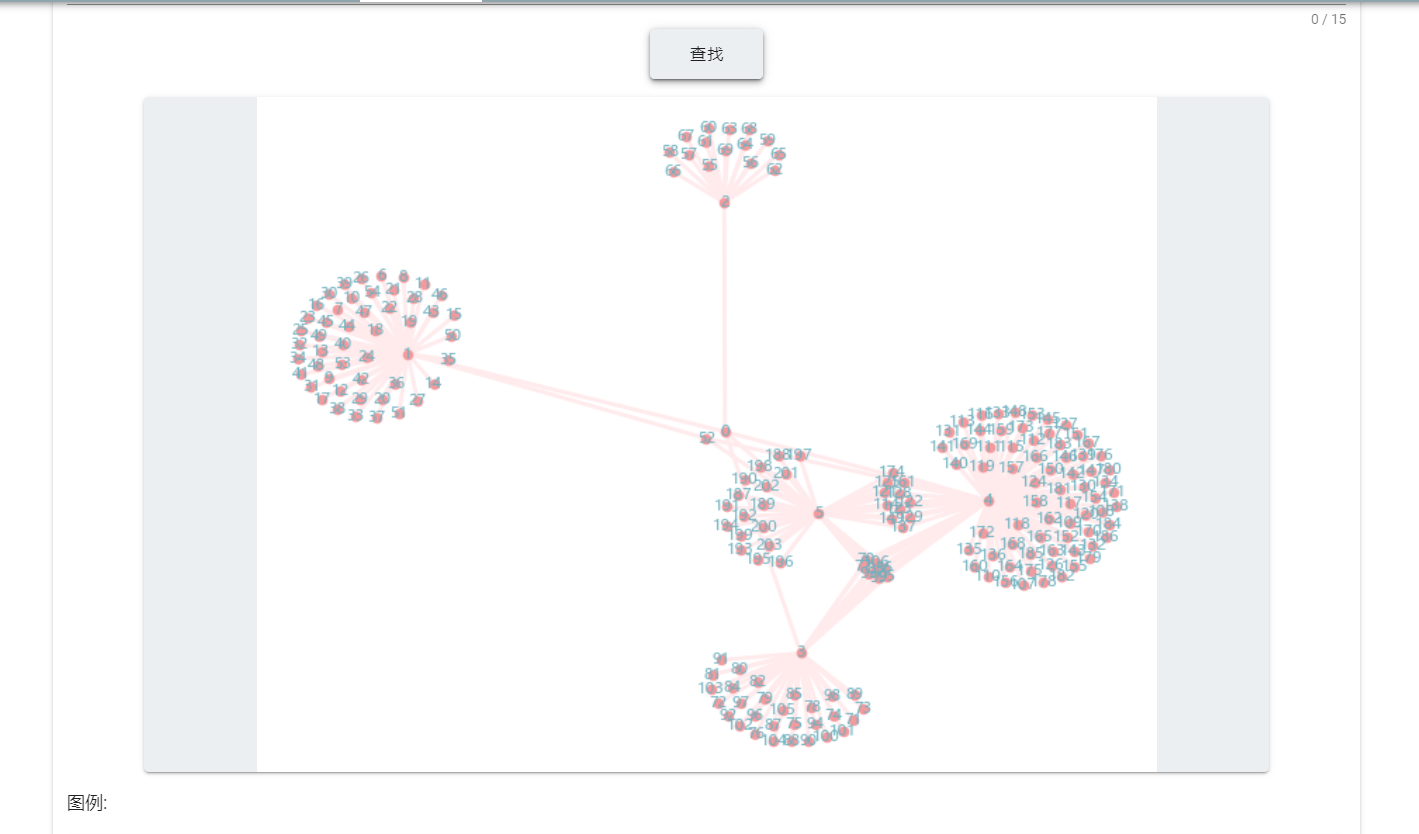
可视化2.0
利用了蚂蚁的antv/G6框架,实现了数据的实时可视化,双击节点继续查询。
视频链接:https://cloud.collapsar.online/2021-03-23%2011-48-38.mkv
参考链接:https://g6.antv.vision/zh/examples/net/forceDirected#forceDirectedPreventOverlap
代码:https://github.com/Collapsar-G/social_worker_library
Docker部署
windows下Docker安装出现了bug,暂时还没有配置好Docker环境,暂未实现。
总结
基本上实现了数据的自动插入数据库,自动建立索引,在插入新数据时,在config.py文件中输入要插入的相关参数,后使用initialization.py文件可以实现自动化加载到数据库。前端UI中,只需添加几个数据就可以实现前端界面的更改(社交网络可视化部分改动可能较多)。
参考文献
- Networkx绘图和整理功能的参数,networkx,画图,函数参数
- chardet库:识别文件的编码格式
- antv