最近很多人都尝试在M1/M2芯片下跑chatglm/chatglm2,结果都不太理想,或者是说要32G内存才可以运行。本文使用cpu基于chatglm-cpp运行chatglm2的int4版本。开了多个网页及应用的情况下(包括chatglm2),总体内存占用9G左右。chatglm2可以流畅的运行了。虚拟环境为python 3.10,使用conda 创建。
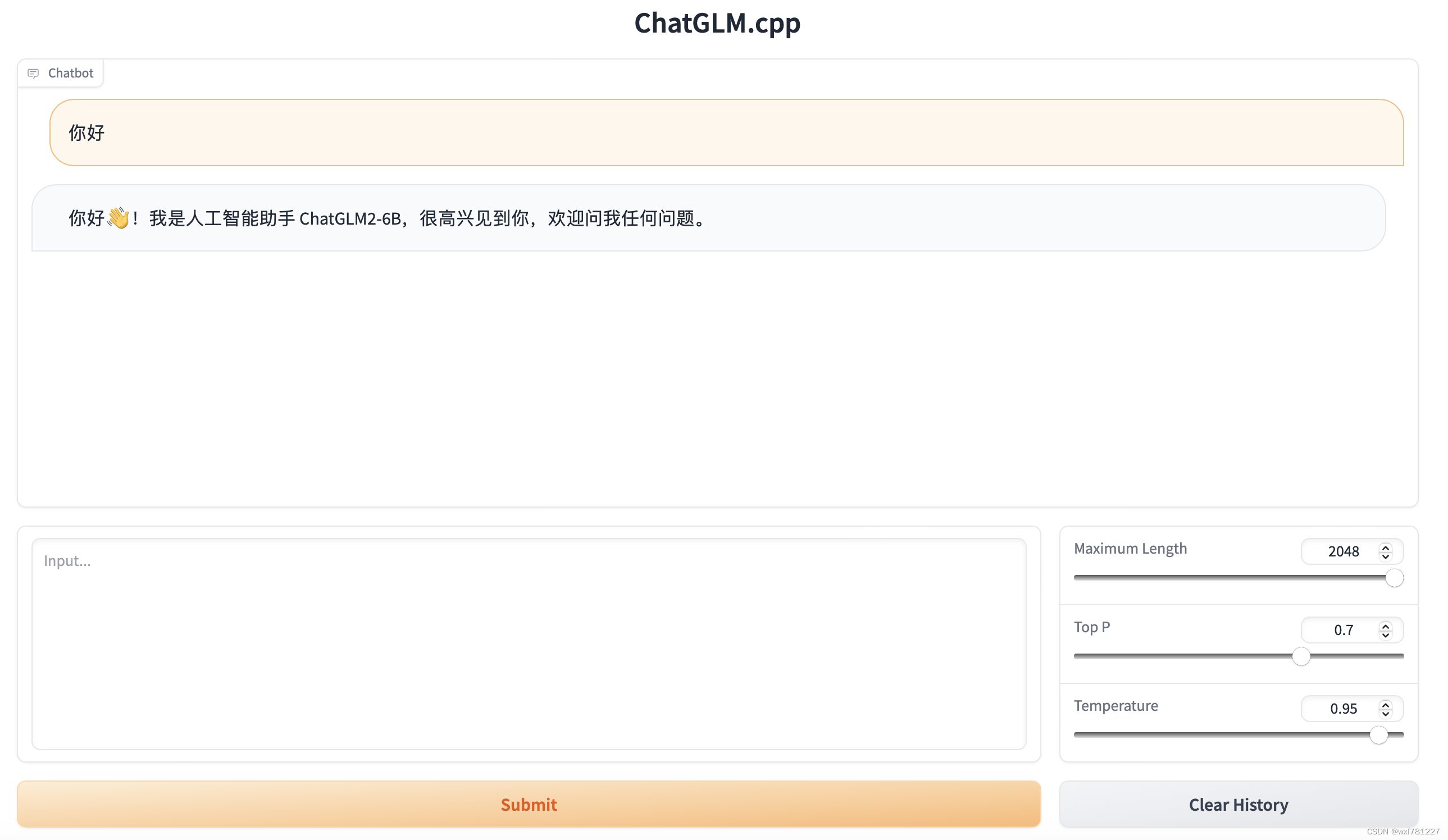
具体部署过程如下:
1.安装brew,主要需要安装core及cask
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
2.添加git配置
git config --global --add safe.directory /opt/homebrew/Library/Taps/homebrew/homebrew-coregit config --global --add safe.directory /opt/homebrew/Library/Taps/homebrew/homebrew-cask3. 安装cmake
brew install cmake4. 下载chatglm-cpp
git clone --recursive https://github.com/li-plus/chatglm.cpp.git && cd chatglm.cpp5. 转换chatglm2模型(模型下载THUDM/chatglm2-6b at main,依赖安装)
python3 convert.py -i THUDM/chatglm2-6b -t q4_0 -o chatglm2-ggml.bin6. build main
cmake -B build
cmake --build build -j7. 命令行调用
./build/bin/main -m chatglm2-ggml.bin -p 你好 --top_p 0.8 --temp 0.8 # ChatGLM2-6B
# 你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。8. 安装chatglm-cpp
pip install -U chatglm-cpp9. 运行web_demo.py
cd examples && python web_demo.py -m ../chatglm-ggml.bin