目录
- 什么是搜索引擎?
- 搜索引擎的原理
- 什么是搜索引擎爬取?
- 什么是搜索引擎索引?
- 什么是搜索引擎检索?
- 什么是搜索引擎排序?
- 搜索引擎的目的是什么?
- 搜索引擎如何赚钱?
- 搜索引擎如何建立索引?
- 网页抓取
- 文本处理
- 建立倒排索引
- 索引优化
- 索引更新
- 搜索引擎如何对页面进行排名
- 反向链接
- 关键词匹配
- 内容质量
- 页面结构
- 用户体验
- 搜索引擎如何个性化结果
- 本文要点总结
在当今的数字时代,搜索引擎已经成为人们获取信息的主要途径之一。然而,你是否知道搜索引擎是如何工作的,以及它们为什么如此重要?
什么是搜索引擎?
搜索引擎是一种计算机程序,通过互联网或企业内部网络检索信息。用户输入关键词或短语后,搜索引擎会扫描网络上的网页、文件、图像、视频、音频等各种类型的信息资源,根据一定的算法进行排序,并将最相关的结果返回给用户。
目前,全球范围内使用最广泛的搜索引擎包括 Google、百度、必应、雅虎等。这些搜索引擎在搜索算法、人工智能、自然语言处理等方面不断创新,以提供更准确、个性化的搜索结果。
搜索引擎的原理
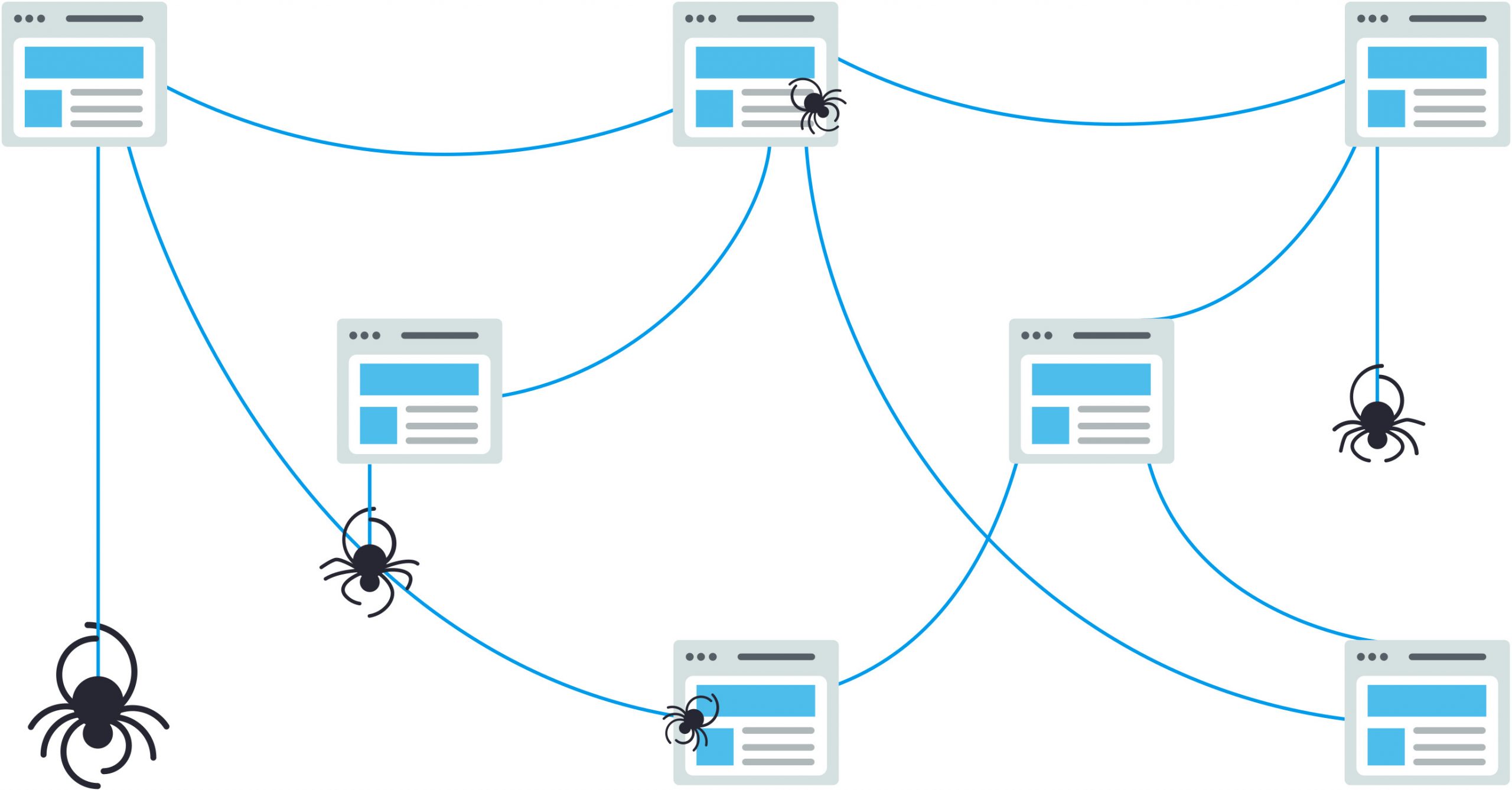
搜索引擎通过使用网络爬虫抓取数十亿个页面来工作。爬虫也称为蜘蛛或机器人,它们在网络中导航并按照链接查找新页面。然后,这些页面将被添加到搜索引擎从中提取结果的索引中。
搜索引擎的主要工作原理可以概括为爬取、索引、检索和排序。
-
爬取:搜索引擎会使用爬虫程序自动收集互联网上所有可访问的网页内容,并将其存储在自己的数据库中。爬虫程序会按照一定的规则遍历网络上的所有网页,并将它们的内容下载到搜索引擎的服务器上。
-
索引:搜索引擎会对收集到的网页内容进行分析和分类,并将其保存在一个索引库中,以便后续搜索时快速查找相关内容。搜索引擎会分析网页中的关键词、标题、描述等元素,并进行分词、去除停用词等处理,生成一个倒排索引表,以便快速查找相关的网页信息。
-
检索:当用户输入关键词并提交搜索请求后,搜索引擎会根据索引库中的信息,找到与关键词相关的网页或其他资源。搜索引擎会将用户输入的关键词与索引库中的关键词进行匹配,找到最相关的网页或其他资源,并返回给用户。
-
排序:搜索引擎将根据一定的算法对搜索结果进行排序,并将最相关的结果展示在前面,以便用户快速找到所需信息。搜索引擎的排序算法通常会考虑网页与关键词的相关度、网页的权威度和可信度、用户的搜索历史和位置等因素。
什么是搜索引擎爬取?
搜索引擎爬取是指搜索引擎通过自动化程序(也称为爬虫、蜘蛛或机器人)在互联网上自动收集和检索网页内容的过程。搜索引擎爬取程序会从一个网页开始,然后通过其中的链接逐步遍历整个互联网上的网页(可能是网页、图像、视频、PDF 等),将网页内容下载并存储在搜索引擎的服务器上。
搜索引擎爬取程序通常会按照一定的策略和规则进行爬取。例如,它们会优先爬取高质量、高权威度的网站,以及包含与搜索关键词相关的内容的网页。搜索引擎爬取程序还会识别并排除一些不需要的内容,例如重复的网页、垃圾信息、过时的网页等。
搜索引擎爬取的频率可以根据网站的更新频率和重要性进行调整。对于更新频率较高的网站,搜索引擎会更频繁地进行爬取,以保证搜索结果的及时性和准确性。
什么是搜索引擎索引?
搜索引擎索引是指搜索引擎将从互联网上爬取到的网页内容进行分析、处理和分类,生成一种数据结构,以便用户在搜索时能够快速查找到相关的信息资源。
搜索引擎索引通常包括以下几个方面的内容:
-
1.关键词:搜索引擎会从网页的标题、正文、链接文本等位置提取出关键词,并对其进行分词、去除停用词等处理。
-
2.URL:搜索引擎会将每个网页的URL作为索引的一个重要标识,以便用户在搜索时能够快速找到相关的网页。
-
3.网页内容的描述:搜索引擎会从网页中提取出一段描述文字,以便在搜索结果中显示给用户,帮助用户更好地了解网页的内容。
-
4.网页的权威度和可信度:搜索引擎会根据一些指标,如网页的外部链接数量、质量等,对网页进行排序和评估,以便向用户呈现最可信、最权威的信息资源。
搜索引擎索引的目的是让用户在搜索时能够快速找到相关的信息资源。搜索引擎会通过自己的算法对索引中的内容进行处理和分析,并生成一个排序后的结果列表,以便用户在搜索结果中找到最相关的信息资源。
什么是搜索引擎检索?
搜索引擎检索是指用户在搜索引擎中输入关键词或短语,搜索引擎根据用户输入的关键词,在已经建立好的索引库中查找相关的信息资源,然后将最相关的结果列表展示给用户的过程。
搜索引擎检索包括以下几个步骤:
-
1.用户输入关键词或短语:用户在搜索引擎的搜索框中输入与自己需求相关的关键词或短语。
-
2.搜索引擎根据关键词进行匹配:搜索引擎会将用户输入的关键词与索引库中的关键词进行匹配,找到与其相关的网页或其他信息资源。
-
3.搜索引擎排序:搜索引擎会根据一定的算法对搜索结果进行排序,将最相关的结果展示在前面,以便用户快速找到所需信息。
-
4.展示搜索结果:搜索引擎将排序后的搜索结果列表展示给用户,用户可以根据自己的需求选择相应的信息资源。
搜索引擎检索的目的是让用户能够快速找到与自己需求相关的信息资源。搜索引擎会根据用户的搜索历史、位置等信息,提供个性化的搜索结果,以满足用户的需求。
什么是搜索引擎排序?
搜索引擎排序是指搜索引擎根据一定的算法对检索到的信息资源进行排序,以便将最相关的结果展示在搜索结果列表的前面,让用户能够快速找到与自己需求相关的信息。
搜索引擎排序通常会考虑以下几个因素:
-
网页与关键词的相关度:搜索引擎会根据网页中出现的关键词数量、位置等因素,计算出网页与关键词的相关度,相关度越高的网页排名越靠前。
-
网页的权威度和可信度:搜索引擎会根据网页的外部链接数量、质量等指标,评估网页的权威度和可信度,权威度和可信度越高的网页排名越靠前。
-
网页的更新频率:搜索引擎会根据网页的更新频率,对其进行排序,更新频率越高的网页排名越靠前。
-
用户的搜索历史和位置:搜索引擎会根据用户的搜索历史和位置信息,提供个性化的搜索结果,将与用户需求和位置相关的信息排名靠前。
搜索引擎排序的目的是让用户能够快速找到与自己需求相关的信息资源,并提供最优质的信息资源给用户。搜索引擎排序算法是搜索引擎的核心技术之一,不断地进行改进和优化,以提供更准确、更个性化的搜索结果。
搜索引擎的目的是什么?
搜索引擎的主要目的是帮助用户快速、方便地找到他们需要的信息资源。随着互联网上信息资源的快速增长,用户很难通过单独访问每个网站来找到所需的信息。搜索引擎通过收集和索引互联网上的信息资源,使用户能够通过简单的搜索操作,找到与自己需求相关的信息资源。
具体来说,搜索引擎的目的包括以下几个方面:
-
收集和索引信息资源:搜索引擎通过爬虫程序自动收集互联网上所有可访问的网页内容,并将其存储在自己的数据库中,然后对其进行分析和处理,生成一种数据结构,以便用户在搜索时能够快速查找到相关的信息资源。
-
提供个性化的搜索结果:搜索引擎会根据用户的搜索历史、位置等信息,提供个性化的搜索结果,让用户能够更快地找到与自己需求相关的信息资源。
-
展示最相关的信息资源:搜索引擎会根据一定的算法对检索到的信息资源进行排序,将最相关的结果展示在搜索结果列表的前面,以便用户能够快速找到所需的信息资源。
-
提供多种搜索方式:搜索引擎不仅支持文本搜索,还支持图片搜索、视频搜索、新闻搜索等多种搜索方式,为用户提供多样化的搜索体验。
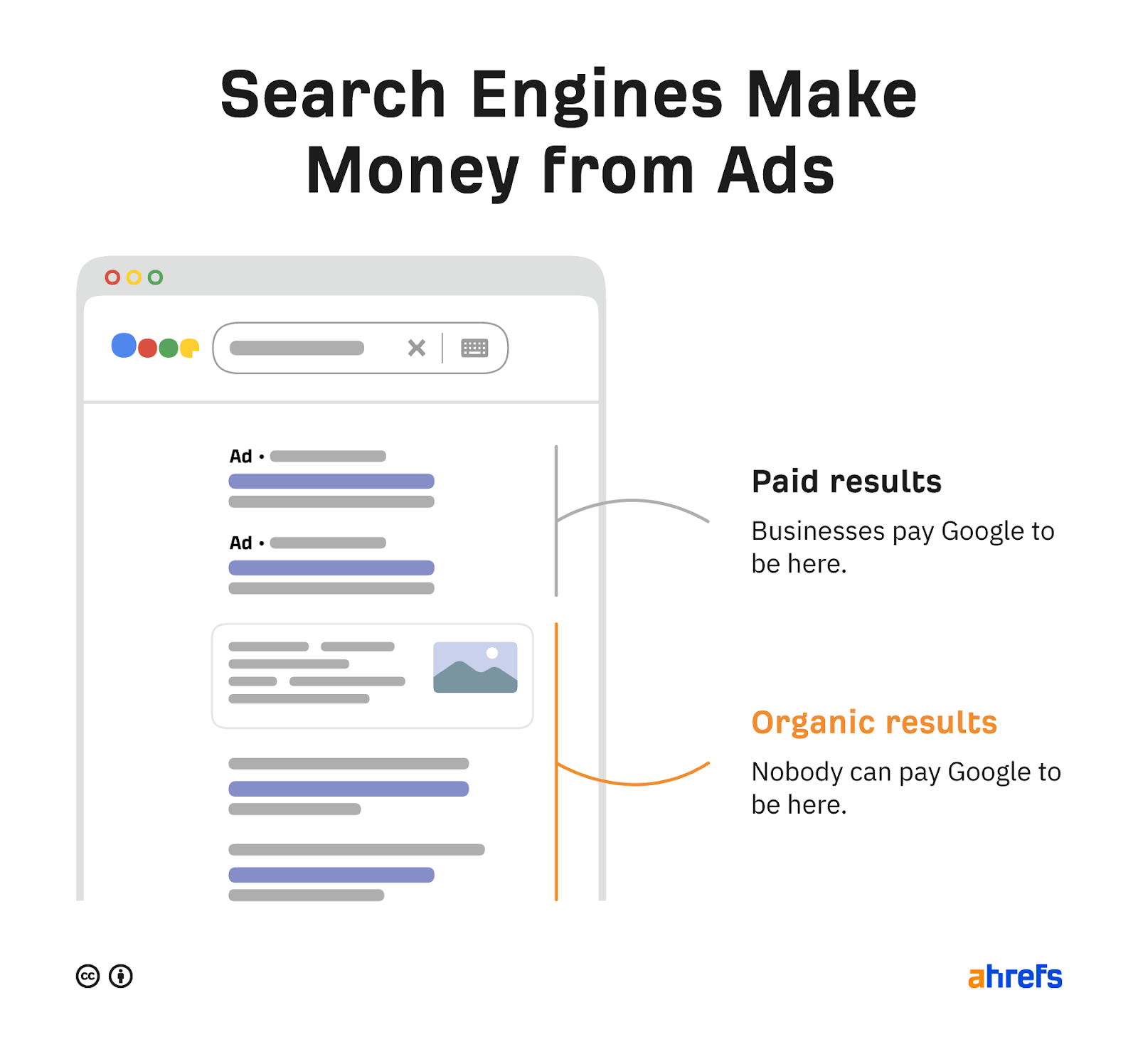
搜索引擎如何赚钱?
搜索引擎主要通过以下几种方式赚钱:
-
广告收入:搜索引擎会在搜索结果页面中显示广告,当用户点击广告时,广告主会向搜索引擎支付费用,搜索引擎通过这种方式获得广告收入。
-
联盟营销:搜索引擎会与其他网站或公司合作,向其提供搜索服务,并从中获得一定的收益。例如,搜索引擎会将其搜索服务嵌入到其他网站中,并按照用户点击次数或搜索次数等标准向合作方收取费用。
-
数据交易:搜索引擎会将其收集和索引的数据出售给其他公司或机构,以帮助其分析市场趋势、用户需求等信息。
-
付费搜索服务:搜索引擎会向用户提供付费搜索服务,例如,企业可以向搜索引擎支付费用,以保证其网站在搜索结果列表中排名靠前。
需要注意的是,搜索引擎通常会保持中立和公正的态度,不会将广告、联盟营销等因素影响搜索结果的排序。搜索引擎也会尽力保护用户的隐私和信息安全,避免将用户的个人信息泄露给第三方。
搜索引擎如何建立索引?
搜索引擎建立索引的过程可以分为以下几个步骤:
-
网页抓取:搜索引擎使用爬虫程序从互联网上抓取网页内容。爬虫程序会从一个网页开始,通过其中的链接跟踪到其他网页,直到抓取到全部或指定范围的网页为止。
-
文本处理:搜索引擎对抓取到的网页进行文本处理,去除HTML标签、停用词等无关信息,提取出网页中的关键词和内容。
-
建立倒排索引:搜索引擎将提取出的关键词和内容建立倒排索引,即将每个关键词和出现该关键词的网页列表建立一个映射关系。倒排索引可以快速地找到包含某个关键词的网页列表。
-
索引优化:搜索引擎会对建立的索引进行优化,以提高搜索效率和准确性。例如,搜索引擎会对不同的关键词赋予不同的权重,以反映关键词的重要性。
-
索引更新:搜索引擎会定期更新索引,以反映互联网上信息资源的变化和增长。
搜索引擎建立索引的过程并不是一次性完成的,而是一个持续的过程。搜索引擎会不断地抓取新的网页内容,并将其加入到索引库中,以便用户能够找到最新、最相关的信息资源。
网页抓取
搜索引擎使用爬虫程序从互联网上抓取网页内容。爬虫程序会从一个网页开始,通过其中的链接跟踪到其他网页,直到抓取到全部或指定范围的网页为止。在抓取网页内容的过程中,搜索引擎需要考虑网络环境、网站反爬虫策略等因素,以避免过度抓取或被网站封禁。但最常见的三种是:
- 反向链接:谷歌拥有数千亿个网页的索引,如果有人从已知页面链接到新页面,Google 可以从那里找到它。
- 站点地图:站点地图可以帮助搜索引擎更快地了解网站的内容和结构,提高网站在搜索结果中的排名和曝光度。
- URL 提交:Google 允许网站所有者请求在Google Search Console中抓取各个网址。
文本处理
搜索引擎对抓取到的网页进行文本处理,去除HTML标签、停用词等无关信息,提取出网页中的关键词和内容。同时,搜索引擎会进行词形还原、同义词转换等操作,以扩展搜索结果的覆盖范围。文本处理也是搜索引擎建立索引的关键步骤之一,直接影响搜索结果的准确性。
建立倒排索引
搜索引擎将提取出的关键词和内容建立倒排索引,即将每个关键词和出现该关键词的网页列表建立一个映射关系。倒排索引可以快速地找到包含某个关键词的网页列表。搜索引擎需要对倒排索引进行优化,以提高搜索效率和准确性,例如将关键词按照出现频率进行排序,或者将关键词按照重要性进行加权。
索引优化
搜索引擎会对建立的索引进行优化,以提高搜索效率和准确性。例如,搜索引擎会对不同的关键词赋予不同的权重,以反映关键词的重要性。搜索引擎还会根据用户的搜索历史、位置等信息,对搜索结果进行个性化排序,以提供更符合用户需求的结果。
索引更新
搜索引擎会定期更新索引,以反映互联网上信息资源的变化和增长。索引更新频率取决于搜索引擎的更新策略和数据量大小,一般来说,搜索引擎会每隔数小时或数天对索引进行更新。索引更新也是搜索引擎维护其搜索质量和用户满意度的重要手段之一。
搜索引擎如何对页面进行排名
搜索引擎对页面进行排名的过程是一个复杂的算法,主要包括以下几个方面的考虑:
-
反向链接: 反向链接是指其他网站指向目标网站的链接。搜索引擎会将反向链接数量和质量作为衡量网站权威性和受欢迎程度的重要因素之一。反向链接数量越多、质量越高的网站,排名越有可能靠前。
-
关键词匹配: 搜索引擎会根据用户的搜索关键词,匹配网页中的相关内容。如果网页中包含与搜索关键词相关的内容,那么该网页就有可能被搜索引擎排名靠前。
-
内容质量: 搜索引擎会评估网页的内容质量,包括内容的原创性、深度、准确性、可读性等因素。内容质量越高的网页,越有可能被搜索引擎排名靠前。
-
页面结构: 搜索引擎会分析网页的结构,包括标题标签、段落、图片、链接等元素是否合理,是否与网页内容相关。良好的页面结构可以提高搜索引擎的理解度,从而提高排名。
-
用户体验: 搜索引擎会考虑用户的搜索体验,包括搜索结果的点击率、用户对网页的停留时间、反弹率等因素。如果用户对某个网页的体验好,那么该网页排名就有可能靠前。
反向链接
反向链接(backlink),也称为入站链接(inbound link)、外部链接(external link)或引荐链接(referring link),是指从其他网站指向某个网站的链接。反向链接是指向目标网站的链接,与正向链接是目标网站指向其他网站的链接相对应。
反向链接在搜索引擎优化(SEO)中具有重要意义。搜索引擎会将反向链接作为网站权威性和受欢迎程度的衡量因素之一,即反向链接数量越多、质量越高,目标网站的排名就越有可能靠前。此外,反向链接还可以带来更多的流量和曝光机会,提高目标网站的知名度和品牌价值。
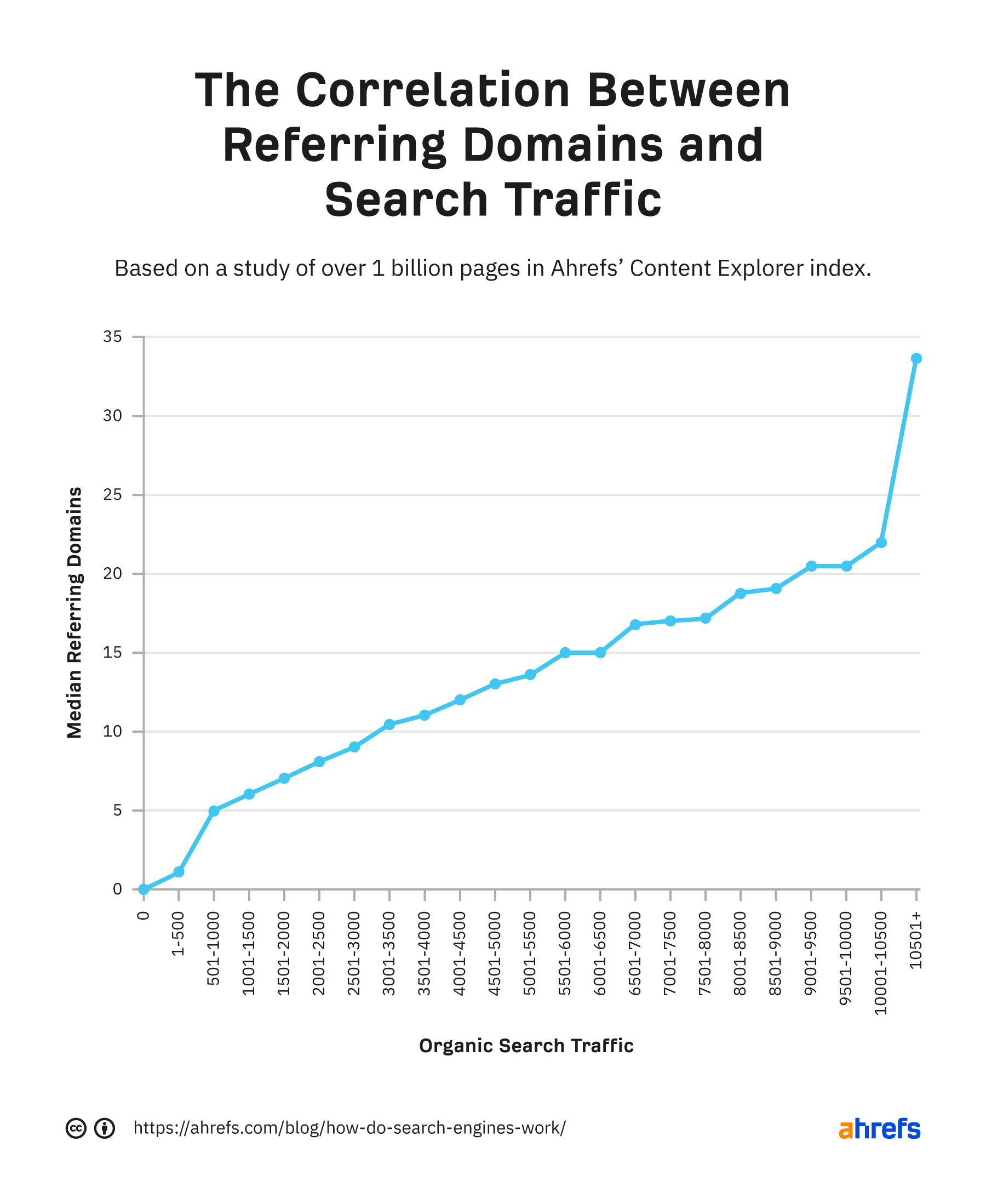
需要注意的是,反向链接的质量和自然度很重要。搜索引擎会将低质量、人工操控的反向链接视为作弊行为,可能会对目标网站进行惩罚。因此,建立高质量、自然的反向链接,需要有良好的内容质量、良好的用户体验和良好的社交媒体宣传等方面的支持。
关键词匹配
关键词匹配(Keyword matching)是指搜索引擎根据用户输入的搜索关键词,匹配网页中的相关内容,并将相关的网页展示给用户的过程。关键词匹配是搜索引擎优化(SEO)的一个重要因素之一,可以影响网站的排名和曝光度。
关键词匹配通常包括以下几个方面的因素:
-
关键词密度: 关键词密度指的是网页中特定关键词出现的频率。通常认为,关键词密度在2%-5%之间是比较合适的。过高的关键词密度可能被搜索引擎认为是作弊行为,从而对网站进行惩罚。
-
关键词位置: 网页中关键词的位置也是影响关键词匹配的重要因素之一。通常认为,关键词出现在标题、开头、结尾等位置会被搜索引擎认为更加重要。
-
关键词相关性: 关键词相关性指的是网页内容与关键词的相关程度。如果网页中的内容与搜索关键词高度相关,那么该网页就有可能被搜索引擎排名靠前。
-
关键词变体: 搜索引擎会考虑搜索关键词的变体,包括单复数形式、时态、同义词、拼写错误等。因此,在编写网页内容时,需要考虑到这些变体,以提高关键词匹配的准确性。
需要注意的是,关键词匹配不应该成为网页内容的唯一考虑因素。良好的内容质量、页面结构、反向链接等因素也是影响网站排名和曝光度的重要因素之一。在编写网页内容时,需要保持自然、流畅的语言,避免过度关注关键词密度和位置等因素,从而提高用户体验和搜索引擎排名。
内容质量
内容质量(Content quality)指的是网页中所提供的内容的质量和价值。高质量的内容可以提高用户体验,吸引更多的访问者,并为网站带来更高的排名和曝光度。在搜索引擎优化(SEO)中,内容质量是一个非常重要的因素。
以下是影响内容质量的一些因素:
-
原创性: 原创性指的是网页中的内容是否是原创的,是否复制或抄袭自其他网站或来源。搜索引擎会对原创性进行评估,并给出相应的排名。
-
深度: 深度指的是网页中所提供的内容是否充分、详细、全面。内容深度越高,越能吸引用户的注意力和兴趣。
-
准确性: 网页中所提供的内容应该准确无误,避免错误和误导。准确性可以提高用户的信任度和忠诚度。
-
可读性: 网页中所提供的内容应该易于阅读和理解,避免过于专业化或难以理解的语言和术语。
-
更新频率: 搜索引擎会考虑网站的更新频率。定期更新网站内容可以提高用户体验和排名。
需要注意的是,内容质量不应该被看作一个简单的指标。它是网站的核心,需要考虑到用户的需求和利益,提供有价值的信息和服务。高质量的内容可以提高用户体验、增加网站的流量和曝光度,从而为网站带来更多的收益和价值。
页面结构
页面结构(Page structure)指的是网页中各个元素的排布和组织方式。良好的页面结构可以提高用户体验,提高搜索引擎排名,增加网站的流量和曝光度。
下面是一些影响页面结构的因素:
-
标题标签: 标题标签是网页的主要标题,也是搜索引擎评估网页主题和内容的重要因素之一。标题标签应该简明扼要、准确描述网页内容。
-
段落: 段落可以帮助用户快速了解网页内容和结构。段落应该有适当的长度、结构清晰,易于阅读和理解。
-
图片: 图片可以吸引用户的关注,提高用户体验。需要注意的是,图片应该有适当的大小和格式,避免过大或过小的图片影响用户体验和页面速度。
-
链接: 链接可以帮助用户快速了解网页的结构和内容。需要注意的是,链接应该有适当的数量和质量,避免过度链接和链接的质量低下影响用户体验和搜索引擎排名。
-
导航: 导航可以帮助用户快速找到所需的网页内容。导航应该简单明了、易于使用,避免过于复杂或混乱的导航结构。
良好的内容质量、关键词匹配、反向链接等因素也是影响网站排名和曝光度的重要因素之一。在设计页面结构时,需要考虑到用户的需求和习惯,提供清晰、简单、易用的页面结构,从而提高用户体验和搜索引擎排名。
用户体验
用户体验(User experience, UX)指的是用户在使用产品或服务时的感受和反应,包括感知、情感、反应、心理和行为等方面。在网站设计和开发中,用户体验是一个非常重要的因素,对网站的流量、转化率和口碑等方面都有着重要的影响。
以下是一些影响用户体验的因素:
-
易用性: 网站应该易于使用和导航,避免用户迷失或感到困惑。易用性包括简洁的页面结构、清晰的导航、简单的操作和明确的用户反馈等方面。
-
可访问性: 网站应该易于访问和使用,包括网站设计、可用性和可访问性等方面。需要考虑到用户的不同需求和能力,提供适当的辅助功能和支持。
-
可靠性: 网站应该稳定可靠,避免错误和崩溃等问题。可靠性包括技术稳定性、数据安全性和备份等方面。
-
快速性: 网站应该快速响应,避免用户等待和失去耐心。快速性包括页面速度、加载时间和响应时间等方面。
-
可信度: 网站应该建立用户的信任和忠诚,避免欺诈和虚假信息等问题。可信度包括网站内容的准确性、真实性和专业性等方面。
用户体验不是一个简单的指标,它需要综合考虑用户的需求、行为和反应等多方面因素。在设计网站时,需要以用户为中心,从用户的角度出发,考虑到用户的需求和反应,提供优质的用户体验,从而提高网站的流量、转化率和口碑。
搜索引擎如何个性化结果
搜索引擎个性化结果(Personalized search results)是指根据用户的搜索历史、地理位置、兴趣爱好、人口统计信息等因素,对搜索结果进行定制化和个性化的展示。搜索引擎通过收集和分析用户的数据,利用机器学习和数据挖掘技术,为用户提供更加准确和相关的搜索结果。
以下是一些搜索引擎个性化结果的实现方式:
-
搜索历史记录: 搜索引擎可以根据用户的搜索历史记录,为用户推荐相关的搜索结果。如果用户在过去搜索过某个主题,搜索引擎会显示更多与该主题相关的搜索结果。
-
地理位置: 搜索引擎可以根据用户的地理位置,为用户提供与当地相关的搜索结果。例如,当用户搜索“餐厅”时,搜索引擎会显示附近的餐厅信息。
-
兴趣爱好: 搜索引擎可以根据用户的兴趣爱好,为用户推荐相关的搜索结果。例如,如果用户经常搜索音乐相关的内容,搜索引擎会显示更多与音乐相关的搜索结果。
-
人口统计信息: 搜索引擎可以根据用户的人口统计信息,例如性别、年龄、职业等,为用户推荐相关的搜索结果。例如,如果用户是一个年轻的母亲,搜索引擎会推荐与育儿相关的搜索结果。
-
人工干预: 搜索引擎可以通过人工干预的方式,为用户提供个性化的搜索结果。例如,搜索引擎可以让用户自定义搜索偏好,或者为用户提供个性化的搜索建议。
搜索引擎个性化结果并不是一成不变的。搜索引擎会不断地收集和分析用户的数据,以及不断地更新和改进自己的算法,从而提供更加准确、相关和个性化的搜索结果。
本文要点总结
- 搜索引擎的原理由4个主要部分组成:爬取,索引,检索,排序
- 搜索引擎的主要目的是帮助用户快速、方便地找到他们需要的信息资源
- 搜素引擎主要通过广告收入,付费搜索服务,联盟营销等赚钱
- 搜索引擎通过5步建立索引:网页抓取,文本处理,建立倒排索引,索引优化,索引更新
- 影响搜索引擎排名的主要因素:反向链接,关键词匹配,内容质量,页面结构,用户体验等
- Google 根据您的位置、语言和搜索历史记录,兴趣爱好,人工干预来个性化其结果。
原文链接:https://zmrw.net/how-do-search-engines-work/
![[Docker实现测试部署CI/CD----Jenkins集成相关服务器(3)]](https://img-blog.csdnimg.cn/a403a6ebee2949b2bec1f6a16de79589.png)