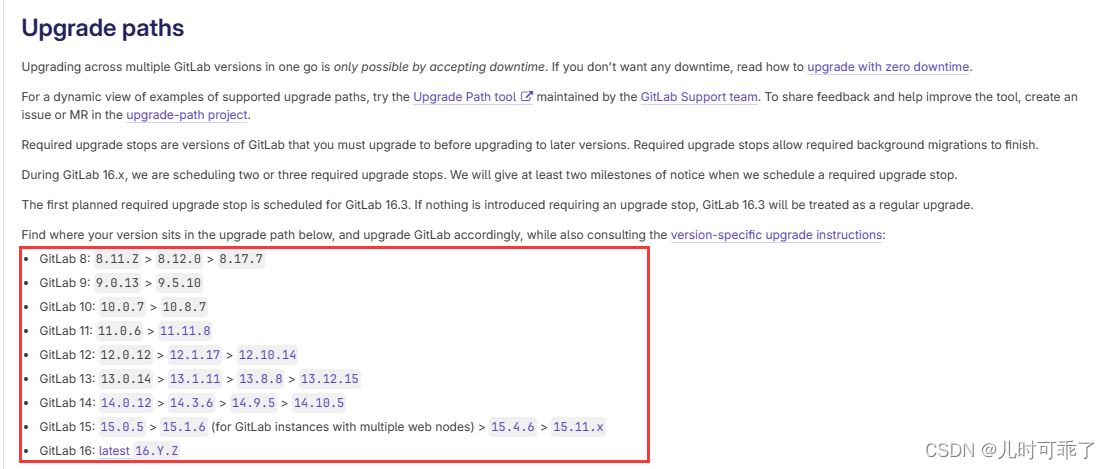
MySQL系列文章
MySQL(一)基本架构、SQL语句操作、试图
MySQL(二)索引原理以及优化
MySQL(三)SQL优化、Buffer pool、Change buffer
MySQL(四)事务原理及分析
MySQL(五)缓存策略
MySQL(六)主从复制
数据库三范式
文章目录
- MySQL系列文章
- 前言
- 一、MySQL网络结构
- 二、一条SQL语句经历的步骤
- 三、MySQL操作
- 增
- 删
- 查
- 改
- 高级查询
- 分组查询
- 聚合查询
- 多表联合查询
- 四、视图
前言
MySQL是关系型数据库。数据库就是用来保存数据的。
那关系型又是什么意思?
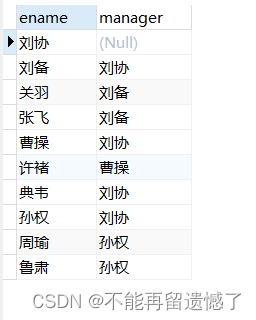
关系型数据库就是类似于excel表格,每一行每一列中的每一个单元都能在表格中找到相关联的数据。
整个库就像一张关系网。
例如:
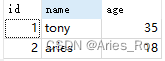
那非关系型数据库又是什么?
非关系型数据库就类似于redis这种,用键值来存储。类似于哈希表数据结构。可以想象,键值对存储中的每个存储数据之间是没有关联的。
例如:
tony:35
aries:18
一、MySQL网络结构
MySQL分为服务端和客户端。我们安装好MySQL需要启动服务端,然后用客户端连接。当然可以多个客户端连接一个MySQL服务端。因此客户端和服务端连接就涉及到网络通信。而MySQL 网络架构通常是指服务端实现的网络架构,因为要与多个客户端连接,所有需要考虑到并发的场景。
Mysql网络的主要处理方式是IO多路复用 select + 阻塞的 io;select只监听listenfd,不会管连接线程的读写。select是跨平台的,mysql可以在Linux和windows下运行;
而redis(使用epoll)只能在Linux下运行,在windows中使用的是用select替换的,并且windows没有fork子线程,功能不全。
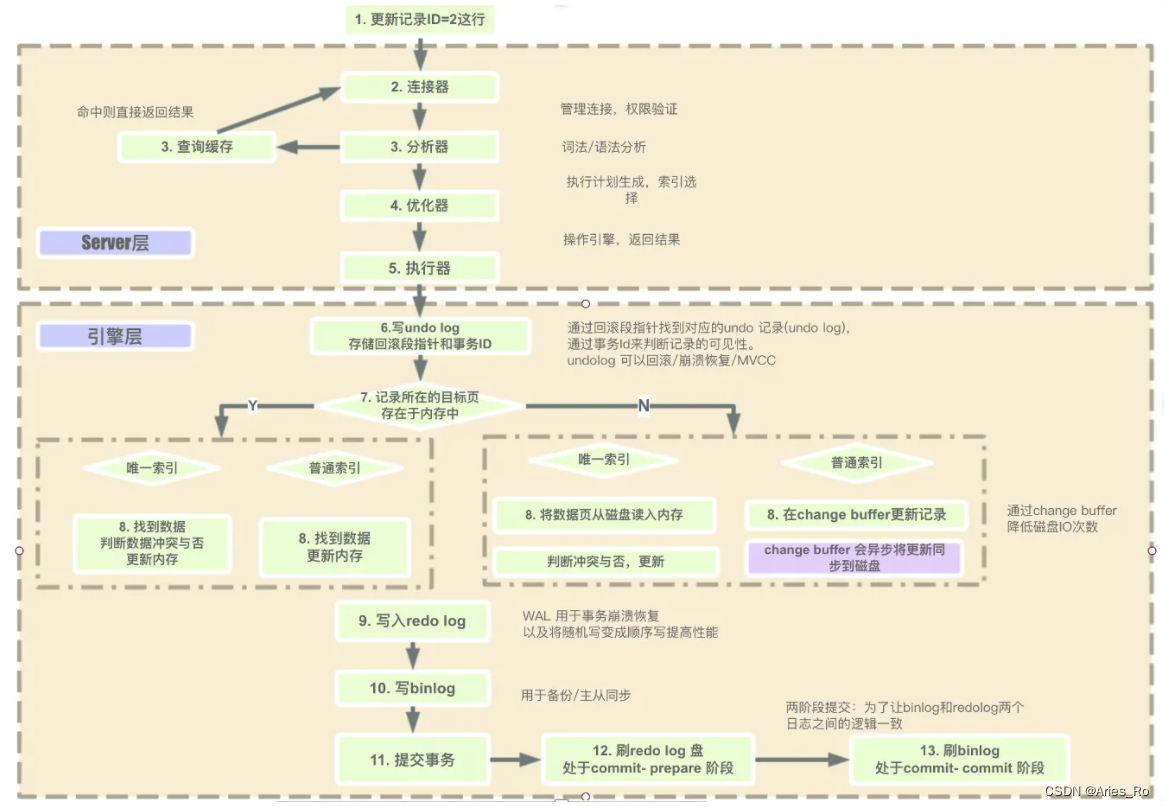
二、一条SQL语句经历的步骤
一条SQL语句在服务端经历的步骤还是比较复杂:
首先经历连接器(建立,管理连接,校验用户信息)然后通过查询缓存,查到直接命中,没查到会继续运行然后sql语句被分析器语句分析,语法分析,生成语法树;经过优化器选择最优的执行步骤;通过执行器根据执行计划,从存储引擎获取数据,并返回客户端。
三、MySQL操作
增
insert
INSERT INTO `table_name`(`field1`, `field2`, ...,`fieldn`) VALUES (value1, value2, ..., valuen);
//例如
INSERT INTO test_db (id, name, age) VALUES ("3", "lihua", 27);
删
删除数据的三种方式:drop,truncate,delete速度依次降低
DROP TABLE `table_name`;//删除整张表,包括索引,约束,触发器等(不能回滚)
TRUNCATE TABLE `table_name`;//删除表数据,以以页为单位删除;其他保留(不能回滚)
DELETE TABLE `table_name`;//删除部分或全部数据,逐行删除,其他保留(条件删除)可以回滚
查
SELECT field1, field2,...fieldN FROM table_name[WHERE Clause]
改
UPDATE table_name SET field1=new_value1,field2=new_value2 [, fieldn=new_valuen]
高级查询
高级查询主要了解分组查询和聚合查询
分组查询
即增加条件判断:
1.where condition
2.group by column having condition
-- 分组加group_concat
| id | name | gender | age |
|----|--------|--------|-----|
| 1 | Alice | Female | 20 |
| 2 | Bob | Male | 22 |
| 3 | Charlie| Male | 21 |
| 4 | Dave | Male | 23 |
| 5 | Eve | Female | 19 |
SELECT `gender`, group_concat(`age`) FROM `student` GROUP BY `gender`;//以gender分组,将同组的age合并起来组成一个年龄字符串
| gender | group_concat(age) |
|--------|---------------------|
| Female | 20,19 |
| Male | 22,21,23 |-- 分组加条件(having的条件可以用select中本条命令查到的,而where做不到)
SELECT `gender`, count(*) FROM as num `student` where num > 6;
————————————————
聚合查询

SELECT sum(`num`) FROM `score`;多表联合查询
分为内联查询和外联查询
内联:inner join,只取两张表有对应关系的记录
//从两个名为"course"和"teacher"的表中获取课程ID和对应的教师ID。
假设"course"表中有以下数据:
| cid | name | teacher_id |
|-----|-------------|-----------|
| 1 | Calculus | 101 |
| 2 | Physics | 102 |
| 3 | Chemistry | 103 |
| 4 | Computer Science | 105 |
| 5 | Biology | 104 |
"teacher"表中有以下数据:
| tid | name |
|-----|-----------|
| 101 | Smith |
| 102 | Johnson |
| 103 | Lee |
| 104 | Davis |
SELECT cid FROM `course` INNER JOIN `teacher` ON course.teacher_id =teacher.tid;
| cid |
|-----|
| 1 |
| 2 |
| 3 |
| 5 |
外联:分为left join和 right join;在内连接的基础上保留左表/右表没有对应关系的记录
假设"course"表中有以下数据:| cid | name | teacher_id |
|-----|-------------|-----------|
| 1 | Calculus | 101 |
| 2 | Physics | 102 |
| 3 | Chemistry | 103 |
| 4 | Computer Science | 101 |
| 5 | Biology | 104 |"teacher"表中有以下数据:| tid | name |
|-----|-----------|
| 101 | Smith |
| 102 | Johnson |
| 103 | Lee |
SELECT course.cid teacher.name FROM `course` LEFT JOIN `teacher` ON course.teacher_id =teacher.tid;
| cid | name |
|-----|---------|
| 1 | Smith |
| 2 | Johnson |
| 3 | Lee |
| 4 | Smith |
| 5 | NULL |
SELECT course.cid teacher.name FROM `course` RIGHT JOIN `teacher` ON course.teacher_id =teacher.tid;
| cid | name |
|-----|---------|
| 1 | Smith |
| 4 | Smith |
| 2 | Johnson |
| 3 | Lee |
四、视图
视图( view )是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。其内容由查询定义。
视图只做select查询,不做增删改(虽然可以做,但是一般不用,限制比较多)。在工作项目中:比如一个充值表,我只给你一个视图,不会给你表,你就没法修改这个核心资源。只能查,不能改。
作用:
- 可复用,减少重复语句书写;类似程序中函数的作用; 重构利器:
(假如因为某种需求,需要将 user 拆成表 usera 和表 userb来查询;如果应用程序使用 sql 语句: select * from user 那就会提示该表不存在;若此时不直接拆表,而创建视图 create view user as select a.name,a.age,b.sex from usera as a, userb as b where a.name=b.name; 则只需要更改数据库结构,而不需要更改应用程序;)
逻辑更清晰,屏蔽查询细节,关注数据返回;- 权限控制,某些表对用户屏蔽,但是可以给该用户通过视图来对该表操作;





![【练】要求定义一个全局变量 char buf[] = “1234567“,创建两个线程,不考虑退出条件,打印buf](https://img-blog.csdnimg.cn/158df8a0b0db4788b75ad8e5ba8490ad.png)