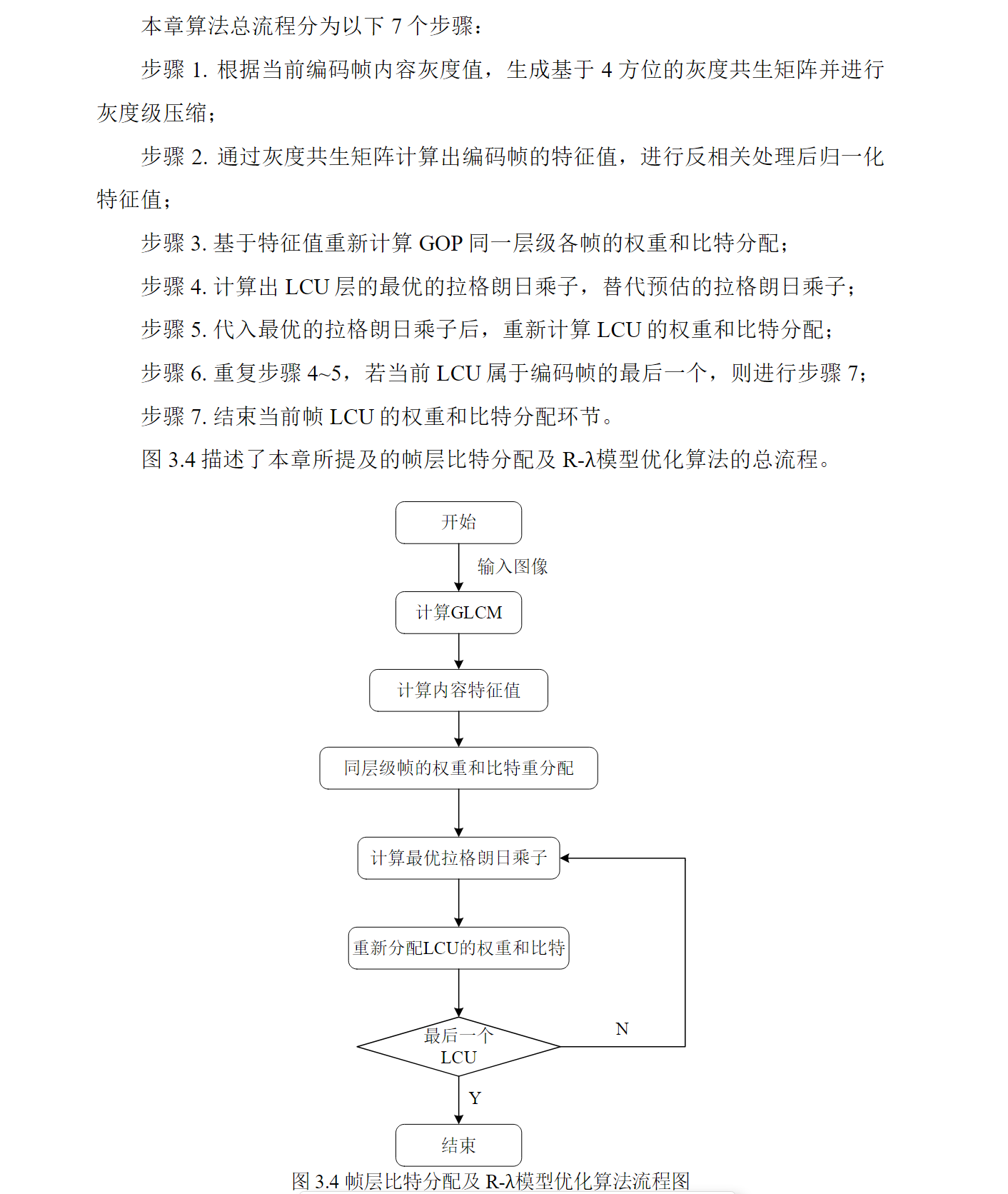
ELK 企业级日志分析系统
- 一、ELK 概述
- 1.ELK 简介
- 2.日志分析系统
- 二、为什么要使用 ELK
- 1.原因:
- 2.完整日志系统基本特征
- 3.ELK 的工作原理
- 三、部署ELK
- 1.ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
- 2.部署 Elasticsearch 软件(在Node1、Node2节点上操作)
- 3.安装 Elasticsearch-head 插件(在Node1、Node2节点上操作)
- 4.ELK Logstash 部署(在 Apache 节点上操作)
- 5.测试 Logstash:
- 6.定义 logstash配置文件
- 四、ELK Kiabana 部署(在 Node1 节点上操作)
- 1.安装 Kiabana
- 2.设置 Kibana 的主配置文件
- 3.启动 Kibana 服务
- 4.验证 Kiabana
- 5.将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
- 五、Filebeat+ELK 部署
- 1.安装 Filebeat
- 2.设置 filebeat 的主配置文件
- 3.在 Logstash 组件所在节点上新建一个 Logstash 配置文件
- 4.测试
- 六、总结:
- 1.Elasticsearch:
- 2.Logstash:
- 3.Kibana:
一、ELK 概述
1.ELK 简介
(1)什么是ELK:
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。
(2)日志服务器的作用:提高安全性,集中存放日志。
(3)缺陷:对日志分析困难。
2.日志分析系统
(1)ElasticSearch:
① 是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
② Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
③ Elasticsearch是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,
也可用于搜索许多不同类型的文档。
(2)Kiabana:
① Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能,有强大的数据可视化 Dashboard。
② Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
(3)Logstash:
① 作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
② Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
③ 相对 input(数据采集) filter(数据过滤) output(数据输出)
-
可以添加的其它组件:
- Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。行解析,
-
filebeat 结合 logstash 带来好处:
- 通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
- 从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
- 将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
- 使用条件数据流逻辑组成更复杂的处理管道
-
缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
(4)Fluentd:
① 是一个流行的开源数据收集器。由于 logstash 太重量级的缺点,Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
② 在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。 它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
二、为什么要使用 ELK
1.原因:
(1)日志主要包括系统日志、应用程序日志和安全日志。
(2)分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
(3)一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关
键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
2.完整日志系统基本特征
(1)收集:能够采集多种来源的日志数据
(2)传输:能够稳定的把日志数据解析过滤并传输到存储系统
(3)存储:存储日志数据
(4)分析:支持 UI 分析
(5)警告:能够提供错误报告,监控机制
3.ELK 的工作原理
(1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
(2)Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
(3)Elasticsearch 对格式化后的数据进行索引和存储。
(4)Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理。
input 数据采集
output 数据输出
filter 数据过滤

三、部署ELK
| 节点名 | IP地址 | 安装软件 |
|---|---|---|
| Node1节点(2C/4G) | 192.168.174.15 | Elasticsearch Kiabana |
| Node2节点(2C/4G) | 192.168.174.17 | Elasticsearch |
| Apache节点 | 192.168.174.13 | Logstash Apache |
三台服务器都关闭防火墙,安全机制:
systemctl stop firewalld
setenforce 0
1.ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
(1)环境准备:
- 更改主机名、配置域名解析、查看Java环境
[root@wang3 ~]# hostnamectl set-hostname node1
[root@wang3 ~]# su
[root@wang5 ~]# hostnamectl set-hostname node2
[root@wang5 ~]# su
[root@node2 ~]#
#在node1,node2上修改:
vim /etc/hosts
192.168.174.15 node1
192.168.174.17 node2
#查看Java版本,如果没有需要安装:
java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
2.部署 Elasticsearch 软件(在Node1、Node2节点上操作)
(1)安装elasticsearch—rpm包
#上传elasticsearch-5.5.0.rpm到/opt目录下
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm
(2)加载系统服务
systemctl daemon-reload
systemctl enable elasticsearch.service
(3)修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]grep -v "^#" /etc/elasticsearch/elasticsearch.yml

(4)创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
(5)启动elasticsearch是否成功开启
systemctl start elasticsearch.service
netstat -antp | grep 9200
(6)查看节点信息
- 浏览器访问 http://192.168.174.15:9200 、 http://192.168.174.17:9200 查看节点 Node1、Node2 的信息。


- 浏览器访问 http://192.168.174.15:9200/_cluster/health?pretty 查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。

3.安装 Elasticsearch-head 插件(在Node1、Node2节点上操作)
(1)编译安装 node
#上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -ycd /opt
tar zxvf node-v8.2.1.tar.gzcd node-v8.2.1/
./configure
make -j2 && make install
(2)安装 phantomjs(前端的框架)
#上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
(3)安装 Elasticsearch-head 数据可视化工具
#上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
(4)修改 Elasticsearch 主配置文件
vim /etc/elasticsearch/elasticsearch.yml
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有systemctl restart elasticsearch
(5)启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
cd /usr/local/src/elasticsearch-head/
npm run start &> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt serverRunning "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100#elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100
(6)通过 Elasticsearch-head 查看 Elasticsearch 信息
通过浏览器访问 http://192.168.174.15:9100/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。

(7)插入索引
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
[root@node1 elasticsearch-head]# curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"billkin","mesg":"hello world"}'
{"_index" : "index-demo","_type" : "test","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"created" : true
}
- 浏览器访问 http://192.168.174.15:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。

4.ELK Logstash 部署(在 Apache 节点上操作)
- Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
(1)更改主机名
hostnamectl set-hostname apache
(2)安装Apahce服务(httpd)
yum -y install httpd
systemctl start httpd
(3)安装Java环境
yum -y install java
java -version
(4)安装logstash
#上传软件包 logstash-5.5.1.rpm 到/opt目录下
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.serviceln -s /usr/share/logstash/bin/logstash /usr/local/bin/
5.测试 Logstash:
(1)Logstash 命令常用选项:
| 选项 | 作用 |
|---|---|
| -f | 通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。 |
| -e | 从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。 |
| -t | 测试配置文件是否正确,然后退出。 |
(2)测试:
定义输入和输出流:
#输入采用标准输入,输出采用标准输出(类似管道)
logstash -e 'input { stdin{} } output { stdout{} }'
......
www.baidu.com #键入内容(标准输入)
2023-08-02T09:45:37.960Z apache www.baidu.com #输出结果(标准输出)
www.sina.com.cn #键入内容(标准输入)
2023-08-02T09:41:46.944Z apache www.sina.com.cn #输出结果(标准输出) //执行 ctrl+c 退出#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
www.baidu.com
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path //usr/share/logstash/config/log4j2.properties. Using default config which logs to console
17:42:35.128 [[main]-pipeline-manager] INFO logstash.pipeline - Starting pipeline {"id"=>"main", "pipeline.workers"=>1, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>125}
17:42:35.217 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
The stdin plugin is now waiting for input:
{"@timestamp" => 2023-08-02T09:42:35.244Z,"@version" => "1","host" => "apache","message" => "www.baidu.com"
}
17:42:35.405 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}#使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.174.15:9200"] } }'输入 输出 对接
......
www.baidu.com #键入内容(标准输入)
www.sina.com.cn #键入内容(标准输入)
www.google.com #键入内容(标准输入)//结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.174.15:9100/ 查看索引信息和数据浏览。
6.定义 logstash配置文件
- Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
(1)组件:
| 组件 | 含义 |
|---|---|
| input | 表示从数据源采集数据,常见的数据源如Kafka、日志文件等 |
| filter | 表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式 |
| output | 表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。 |
(2)格式:
input {…}
filter {…}
output {…}
(3)修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
chmod +r /var/log/messages #让 Logstash 可以读取日志vim /etc/logstash/conf.d/system.conf
input {file{path =>"/var/log/messages" #指定要收集的日志的位置type =>"system" #自定义日志类型标识start_position =>"beginning" #表示从开始处收集}
}
output {elasticsearch { #输出到 elasticsearchhosts => ["192.168.174.15:9200"] #指定 elasticsearch 服务器的地址和端口index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式}
}systemctl restart logstash
(4)浏览器访问 http://192.168.174.15:9100/ 查看索引信息

四、ELK Kiabana 部署(在 Node1 节点上操作)
1.安装 Kiabana
#上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm
2.设置 Kibana 的主配置文件
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.174.15:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
3.启动 Kibana 服务
systemctl start kibana.service
systemctl enable kibana.servicenetstat -natp | grep 5601
4.验证 Kiabana
浏览器访问 http://192.168.174.15:5601
第一次登录需要添加一个 Elasticsearch 索引:Index name or pattern
//输入:system-* #在索引名中输入之前配置的 Output 前缀“system”单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果

5.将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
vim /etc/logstash/conf.d/apache_log.conf
input {file{path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"}file{path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}
}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.174.15:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.174.15:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}
}
(1)浏览器访问 http://192.168.174.15:9100 查看索引是否创建:

(2)测试:
浏览器访问 http://192.168.174.15:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 apache_access-,并单击“Create”按钮。在用相同的方法添加 apache_error-索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access- 、apache_error- 索引, 可以查看相应的图表及日志信息。

五、Filebeat+ELK 部署
| 节点 | IP地址 | 安装软件 |
|---|---|---|
| node1 | 192.168.174.15 | Elasticsearch Kibana |
| node2 | 192.168.174.17 | Elasticsearch |
| apache | 192.168.174.13 | Apache logstash |
| filebeat | 192.168.174.12 | Filebeat |
在新节点上操作
1.安装 Filebeat
#上传软件包 filebeat-6.2.4-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.2.4-linux-x86_64.tar.gz
mv filebeat-6.2.4-linux-x86_64/ /usr/local/filebeat
2.设置 filebeat 的主配置文件
cd /usr/local/filebeat
cp filebeat.yml filebeat.yml.bak
vim filebeat.yml
filebeat.prospectors:- type: log #指定 log 类型,从日志文件中读取消息enabled: truepaths:- /var/log/messages #指定监控的日志文件- /var/log/*.logfields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: logservice_id: 192.168.174.12--------------Elasticsearch output-------------------
(全部注释掉)----------------Logstash output---------------------
output.logstash:hosts: ["192.168.174.13:5044"] #指定 logstash 的 IP 和端口#启动 filebeat
./filebeat -e -c filebeat.yml
3.在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.dvim logstash.conf
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["192.168.174.15:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}#启动 logstash
logstash -f logstash.conf
4.测试
浏览器访问 http://192.168.174.15:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
六、总结:
1.Elasticsearch:
是一个分布式的实时搜索和分析引擎。它用于存储、搜索和分析大规模数据,具有强大的全文搜索和复杂查询的能力。
2.Logstash:
是一个用于收集、处理和转换日志数据的数据处理管道。它可以从不同的来源(如文件、数据库、网络等)收集数据,经过过滤和转换后将数据发送到不同的目的地。
3.Kibana:
是一个用于可视化和分析数据的工具。它提供了强大的数据分析和可视化功能,可以创建仪表盘、图表和地图等,以便更好地理解和展示数据。
-
ELK堆栈通常用于日志管理和分析,它可以帮助组织从海量的日志数据中提取有用的信息、进行故障排除和性能优化等任务。Elasticsearch用于存储和搜索日志数据,Logstash用于收集和处理日志数据,Kibana用于展示和分析日志数据。
-
ELK还可以与其他工具和技术集成,如Beats(用于轻量级数据收集)、X-Pack(用于安全、监控和管理)等,以增强其功能和扩展性。
总结起来,ELK提供了一个强大的、可扩展的解决方案,用于日志管理、搜索和分析,帮助组织处理和利用大量的日志数据,以便于故障排除、性能优化和业务洞察等用途。




![el-table点击表格某一行添加到URL参数,访问带参URL加载表格内容并滚动到选中行位置 [Vue3] [Element-plus 2.3]](https://img-blog.csdnimg.cn/98e5ad2a0182413294979e6591abeb03.png)