文章目录
- 一. ELK日志分析系统概述
- 1.ELK 简介
- 2.ELK日志分析系统
- 2.1 ElasticSearch
- 2.1.1 ElasticSearch概述
- 2.1.2 ElasticSearch核心概念(作用)
- 2.2 Kiabana
- 2.2.1 Kiabana 概念
- 2.2.2 Kiabana 主要功能
- 2.3 Logstash
- 2.3.1 Logstash 概念
- 2.3.2 Logstash主要组件
- 2.3.3 Logstash理念、作用
- 2.4 可以添加的其它组件
- 2.4.1 Filebeat
- 2.4.2 缓存/消息队列(redis、kafka、RabbitMQ等)
- 2.4.3 Fluentd
- 3.为什么要使用 ELK
- 4.完整日志系统基本特征
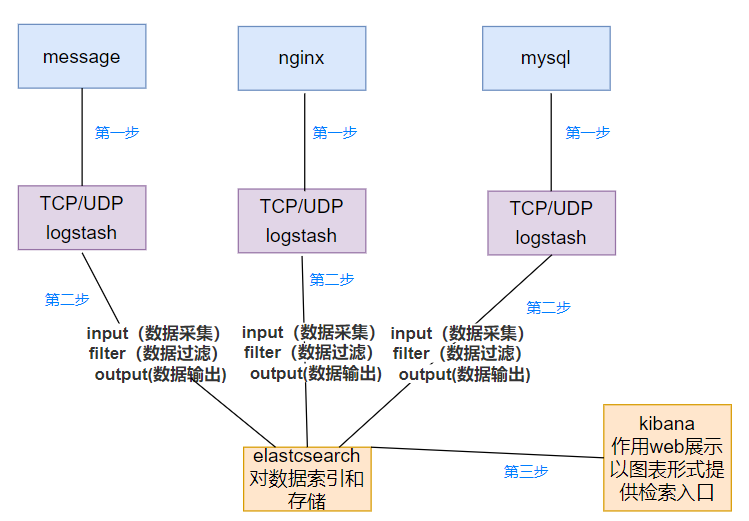
- 5.ELK 的工作过程
- 5.1 ELK 的工作原理
- 5.2 ELK 的数据流图示
- 二.部署ELK日志分析系统
- 1. ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
- 1.1 环境准备
- 1.2 部署 Elasticsearch 软件
- 1.3 安装 Elasticsearch-head 插件
- 2. ELK Logstash 部署(在 Apache 节点上操作)
- 2.1 更改主机名
- 2.2 安装Apahce服务(httpd)
- 2.3 安装Java环境
- 2.4 安装logstash
- 2.5 测试 Logstash
- 2.6 定义 logstash配置文件
- 3.ELK Kiabana 部署(在 Node1 节点上操作)
- 3.1 安装 Kiabana
- 3.2 设置 Kibana 的主配置文件
- 3.3 启动 Kibana 服务
- 3.4 验证 Kibana
- 3.5 将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
- 三.Filebeat+ELK 部署
- 1. 安装 Filebeat(Filebeat节点)
- 2.设置 filebeat 的主配置文件
- 3.在 Logstash 组件所在节点上新建一个 Logstash 配置文件(apache节点)
- 4.浏览器访问 http://192.168.198.13:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
- 总
- 排错思路
- 1.ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)部分排错
- 2.filebeat端排错
- 3.logstash端排错
- 4.kibana端排错
一. ELK日志分析系统概述
1.ELK 简介
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。
(1)提高安全性
(2)集中存放日志
(3)缺陷:对日志的分析困难
2.ELK日志分析系统
2.1 ElasticSearch
2.1.1 ElasticSearch概述
(1)提供了一个分布式多用户能力的全文搜索引擎,通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
(2)Elasticsearch 是用 Java 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 Elasticsearch 通信。
2.1.2 ElasticSearch核心概念(作用)
(1)接近实时
(2)集群(es数据日志搜索)
(3)节点
(4)索引(es)
索引(库)——类型(表)——文档(记录)
(5)分片和副本(备份——每个都有副本,如其中一个挂了,副本还可以继续正常工作、容灾)
2.2 Kiabana
2.2.1 Kiabana 概念
通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
总:将Elasticsearch中的数据优化可视化的展示出来
2.2.2 Kiabana 主要功能
(1)Elasticsearch无缝之集成
(2)整合数据,复杂数据分析
(3)让更多团队成员受益
(4)接口灵活,分享更容易
(5)配置简单,可视化多数据源
(6)简单数据导出
2.3 Logstash
2.3.1 Logstash 概念
(1)一款强大的数据数据处理工具
(2)可实现数据传输,格式处理,格式化输出(输出给es)
(3)数据输入,数据加工(如过滤、改写等)以及数据输出
2.3.2 Logstash主要组件
(1)shipper:主要负责监控日志,日志变动,集新的日志
(2)indexer:存储(日志存储者)主要是日志接收和写入本地
(3)broker:连接组件,并对组件进行搜索日志文件存储另一个平台上
(4)search and storage:搜索和存储
(5)web interface:展示web界面
2.3.3 Logstash理念、作用
input(数据采集) filter(数据过滤) output(数据输出)
2.4 可以添加的其它组件
2.4.1 Filebeat
- Filebeat概念
(1)轻量级的开源日志文件数据搜集器。
(2)通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。行解析
- Filebeat 结合 logstash 带来好处
(1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
(2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
(3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
(4)使用条件数据流逻辑组成更复杂的处理管道
2.4.2 缓存/消息队列(redis、kafka、RabbitMQ等)
可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
2.4.3 Fluentd
- 概念
是一个流行的开源数据收集器。
- 特点
由于 logstash 太重量级的缺点:
(1)解决Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。
(2)相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
(3)在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。 它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
3.为什么要使用 ELK
(1)由于会通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
(2)单台机器的日志我们使用grep、awk等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。数十上百台服务器会很繁琐并且效率低下,使用集中化的日志管理:开源的syslog,将所有服务器上的日志收集汇总
(3)一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
总:日志集中化、集中化管理
提高效率、性能安全
4.完整日志系统基本特征
收集:能够采集多种来源的日志数据
传输:能够稳定的把日志数据解析过滤并传输到存储系统
存储:存储日志数据
分析:支持 UI 分析
警告:能够提供错误报告,监控机制
5.ELK 的工作过程
5.1 ELK 的工作原理
(1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
(2)Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
(3)Elasticsearch 对格式化后的数据进行索引和存储。
(4)Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理。
5.2 ELK 的数据流图示
二.部署ELK日志分析系统
Node1节点(4C/8G):node1/192.168.198.13——————Elasticsearch Kibana
Node2节点(4C/8G):node2/192.168.198.14——————Elasticsearch
Apache节点:apache/192.168.198.15——————————Logstash Apache
1. ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
1.1 环境准备
#关闭防火墙和安全机制
systemctl stop firewalld
setenforce 0
#更改主机名
Node1节点:hostnamectl set-hostname node1
Node2节点:hostnamectl set-hostname node2
su
#配置域名解析
vim /etc/hosts
192.168.198.13 node1
192.168.198.14 node2
#查看Java环境 注:版本问题
#如果没有安装,yum -y install java
java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)建议使用jdk
1.2 部署 Elasticsearch 软件
(1)安装elasticsearch—rpm包
#上传elasticsearch-5.5.0.rpm到/opt目录下
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm
(2)加载系统服务
#安装elasticsearch
systemctl daemon-reload
#重新加载system管理
systemctl enable elasticsearch.service
rpm -ivh elasticsearch-5.5.0.rpm
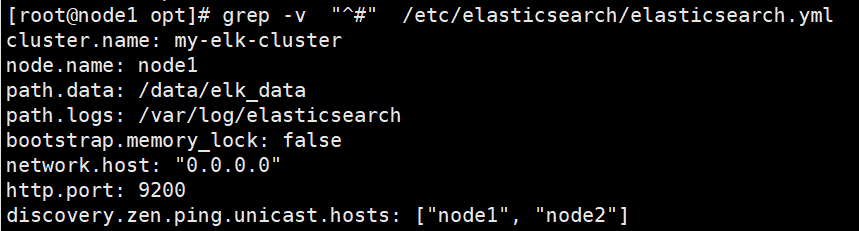
(3)修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: "0.0.0.0"
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
#过滤非#开头的行检查配置是否有问题
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
(4)创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
(5)启动elasticsearch是否成功开启(此处查看端口会有些慢,可以直接查看服务状态)
systemctl start elasticsearch.service
netstat -antp | grep 9200tcp6 0 0 :::9200 :::* LISTEN 48041/java
(6)查看节点信息
浏览器访问 http://192.168.198.13:9200 、 http://192.168.198.14:9200 查看节点 Node1、Node2 的信息。
浏览器访问 http://192.168.198.13:9200/_cluster/health?pretty 、 http://192.168.198.14:9200/_cluster/health?pretty查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。
浏览器访问 http://192.168.198.13:9200/_cluster/state?pretty 检查群集状态信息。
#使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oQmlup1f-1690975008851)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802161400427.png)]](https://img-blog.csdnimg.cn/8abf294273154ed0b8ab24ed9cb82dba.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hbSHck94-1690975008852)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802161501188.png)]](https://img-blog.csdnimg.cn/4e5181ccef634d53b806f7caf5de0464.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ndQF9njs-1690975008852)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802162200130.png)]](https://img-blog.csdnimg.cn/089914966d3f4898871c52658b2fe785.png)
1.3 安装 Elasticsearch-head 插件
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
(1)编译安装 node
#上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make -j4 && make install
(2)安装 phantomjs(前端的框架)
#上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到
cd /opt
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
(3)安装 Elasticsearch-head 数据可视化工具
#上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
(4)修改 Elasticsearch 主配置文件
vim /etc/elasticsearch/elasticsearch.yml
......
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有
systemctl restart elasticsearch
(5)启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
cd /usr/local/src/elasticsearch-head/
npm run start &> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt serverRunning "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
#另起端口查看elasticsearch-head 监听的端口是 9100
netstat -natp |grep 9100tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 93946/grunt
(6)通过 Elasticsearch-head 查看 Elasticsearch 信息
通过浏览器访问http://192.168.198.13:9100/ 地址如遇到打开集群健康值不是green,显示未连接的可以(查看Elasticsearch处的地址是否是localhost,并把localhost改为自己的9200端口地址)连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WDdDgE6M-1690975008853)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802185826734.png)]](https://img-blog.csdnimg.cn/e371889241f543d097d915e760e25eae.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CBhyJnfp-1690975008853)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802185937293.png)]](https://img-blog.csdnimg.cn/9a14b69a94b947beb027600b2e1caaeb.png)
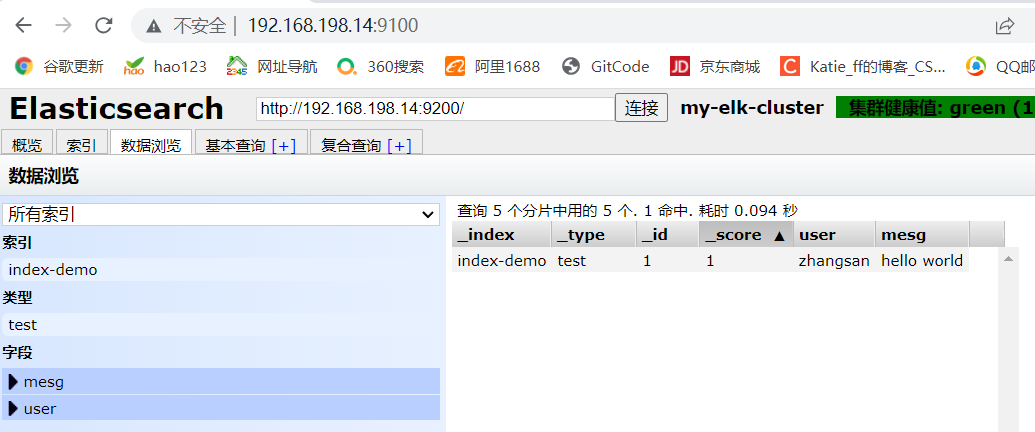
(7)插入索引
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。#输出结果如下
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
#显示出以下结果
{"_index" : "index-demo","_type" : "test","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"created" : true
}
浏览器访问 http://192.168.198.13:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。
点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4h49CgFa-1690975008853)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802190032904.png)]](https://img-blog.csdnimg.cn/4c437888a9d24704808e182bb8db6697.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EbE2pwmp-1690975008854)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802190051696.png)]](https://img-blog.csdnimg.cn/eb30d57ceae44bf0b8ed727d448a2226.png)
2. ELK Logstash 部署(在 Apache 节点上操作)
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
2.1 更改主机名
hostnamectl set-hostname apache
su
2.2 安装Apahce服务(httpd)
yum -y install httpd
systemctl start httpd
2.3 安装Java环境
yum -y install java
java -version
2.4 安装logstash
#上传软件包 logstash-5.5.1.rpm 到/opt目录下
cd /opt
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
2.5 测试 Logstash
Logstash 命令常用选项:
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。
定义输入和输出流:
#输入采用标准输入,输出采用标准输出(类似管道)
logstash -e 'input { stdin{} } output { stdout{} }'
......
#键入内容(标准输入)
www.baidu.com
#输出结果(标准输出)
2023-08-02T11:04:55.407Z apache www.baidu.com
#键入内容(标准输入)
www.sina.com.cn
#输出结果(标准输出)
2023-08-02T11:05:41.073Z apache www.sina.com.cn
//执行 ctrl+c 退出#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
......
www.baidu.com #键入内容(标准输入)
{"@timestamp" => 2023-08-02T11:06:53.982Z, #输出结果(处理后的结果)"@version" => "1","host" => "apache","message" => "www.baidu.com"
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J8h0CdPh-1690975008854)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802191445727.png)]](https://img-blog.csdnimg.cn/aeaaf285a67f4a95878ae90e1aff8d0f.png)
#使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.198.13:9200"] } }'输入 输出 对接
......
www.baidu.com #键入内容(标准输入)
www.sina.com.cn #键入内容(标准输入)
www.google.com #键入内容(标准输入)//结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.16898.13:9100/ 查看索引信息和数据浏览。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WVpXV9h2-1690975008854)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802190814812.png)]](https://img-blog.csdnimg.cn/767efa8ee3b141ef9879379170133db1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JcgyHkxQ-1690975008855)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802190911623.png)]](https://img-blog.csdnimg.cn/038a10a019bd467b83ebde51ad8430c8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OocgbCSf-1690975008855)(C:\Users\zhao\AppData\Roaming\Typora\typora-user-images\image-20230802190929681.png)]](https://img-blog.csdnimg.cn/1ef5cbb5a7dd40e482382f577ad7a1cb.png)
2.6 定义 logstash配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
#格式如下:
input {…}
filter {…}
output {…}
#在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file { path =>“/var/log/messages” type =>“syslog”}
file { path =>“/var/log/httpd/access.log” type =>“apache”}
}
#修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
chmod +r /var/log/messages #让 Logstash 可以读取日志
vim /etc/logstash/conf.d/system.conf
input {file{path =>"/var/log/messages" #指定要收集的日志的位置type =>"system" #自定义日志类型标识start_position =>"beginning" #表示从开始处收集}
}
output {elasticsearch { #输出到 elasticsearchhosts => ["192.168.198.13:9200"] #指定 elasticsearch 服务器的地址和端口index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式}
}
systemctl restart logstash
浏览器访问 http://192.168.198.13:9100/ 查看索引信息

3.ELK Kiabana 部署(在 Node1 节点上操作)
3.1 安装 Kiabana
#上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm
3.2 设置 Kibana 的主配置文件
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.198.13:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
3.3 启动 Kibana 服务
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 100973/node 3.4 验证 Kibana
浏览器访问 http://192.168.198.13:5601
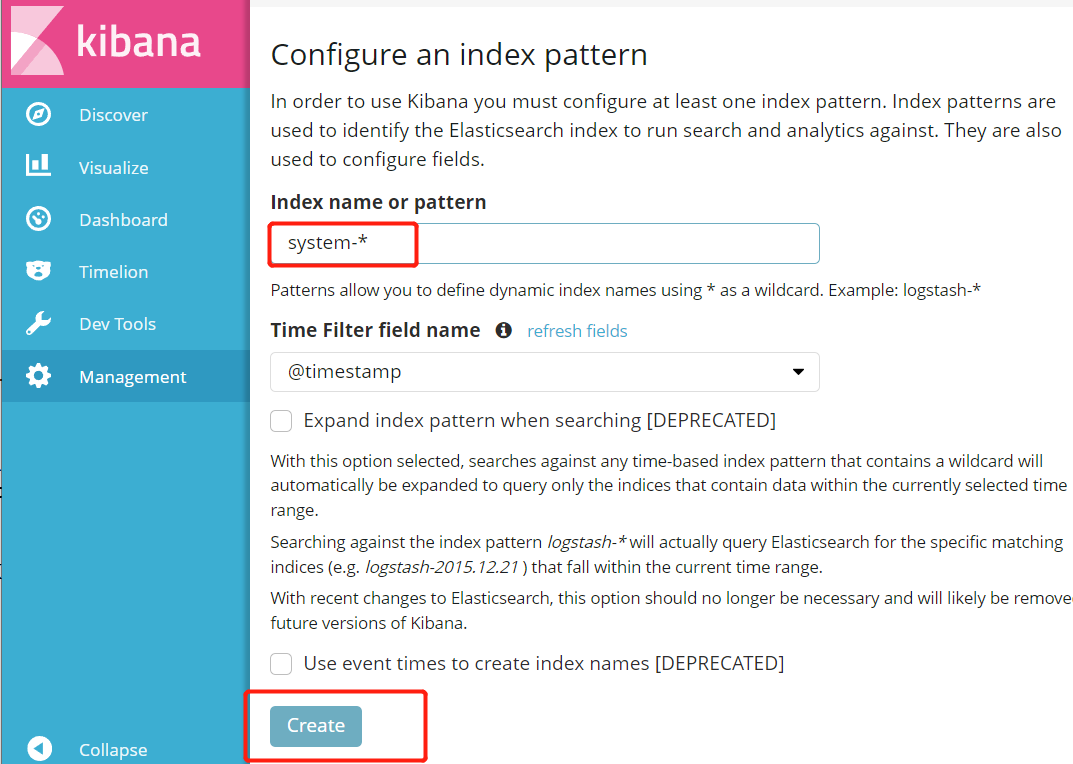
#第一次登录需要添加一个 Elasticsearch 索引:
Index name or pattern
//输入:system-* #在索引名中输入之前配置的 Output 前缀“system”
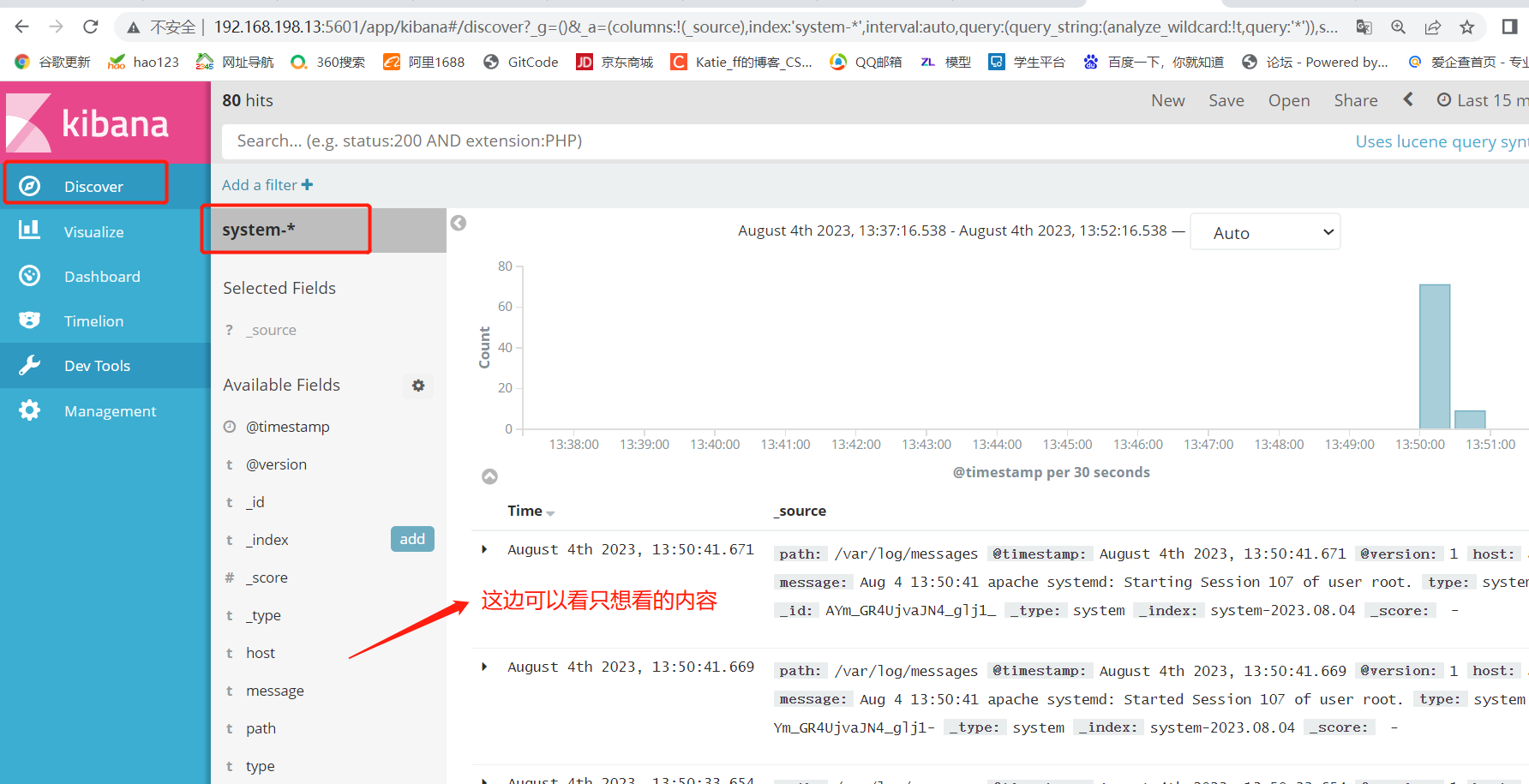
单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
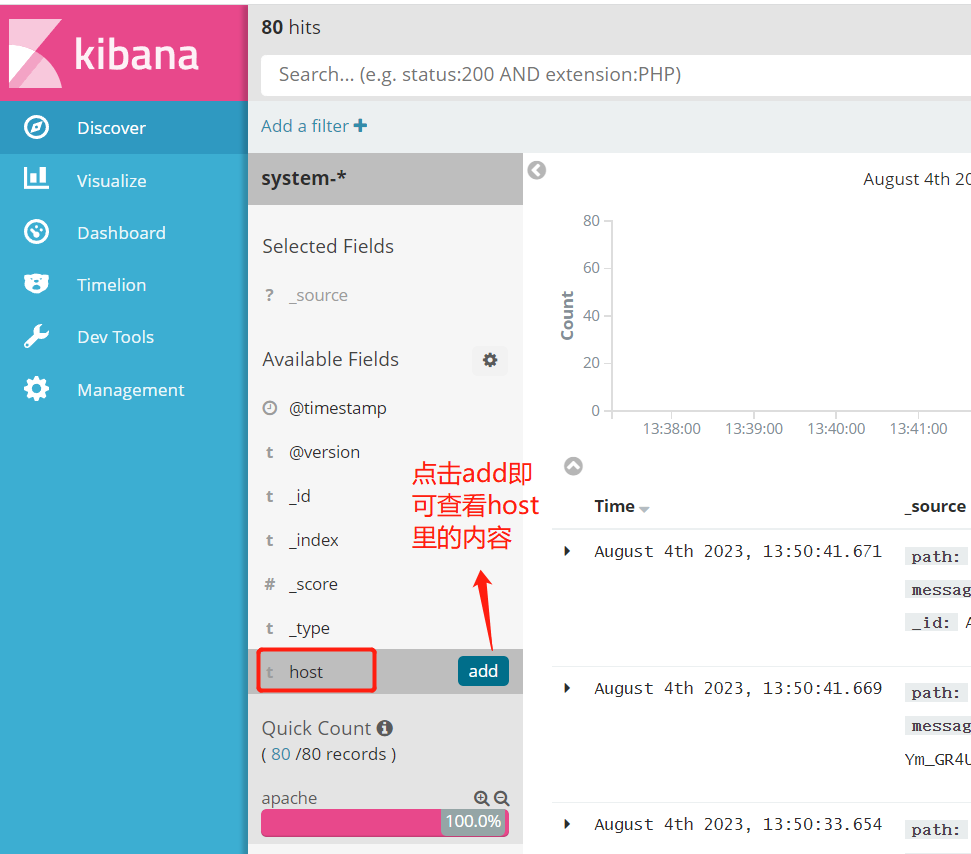
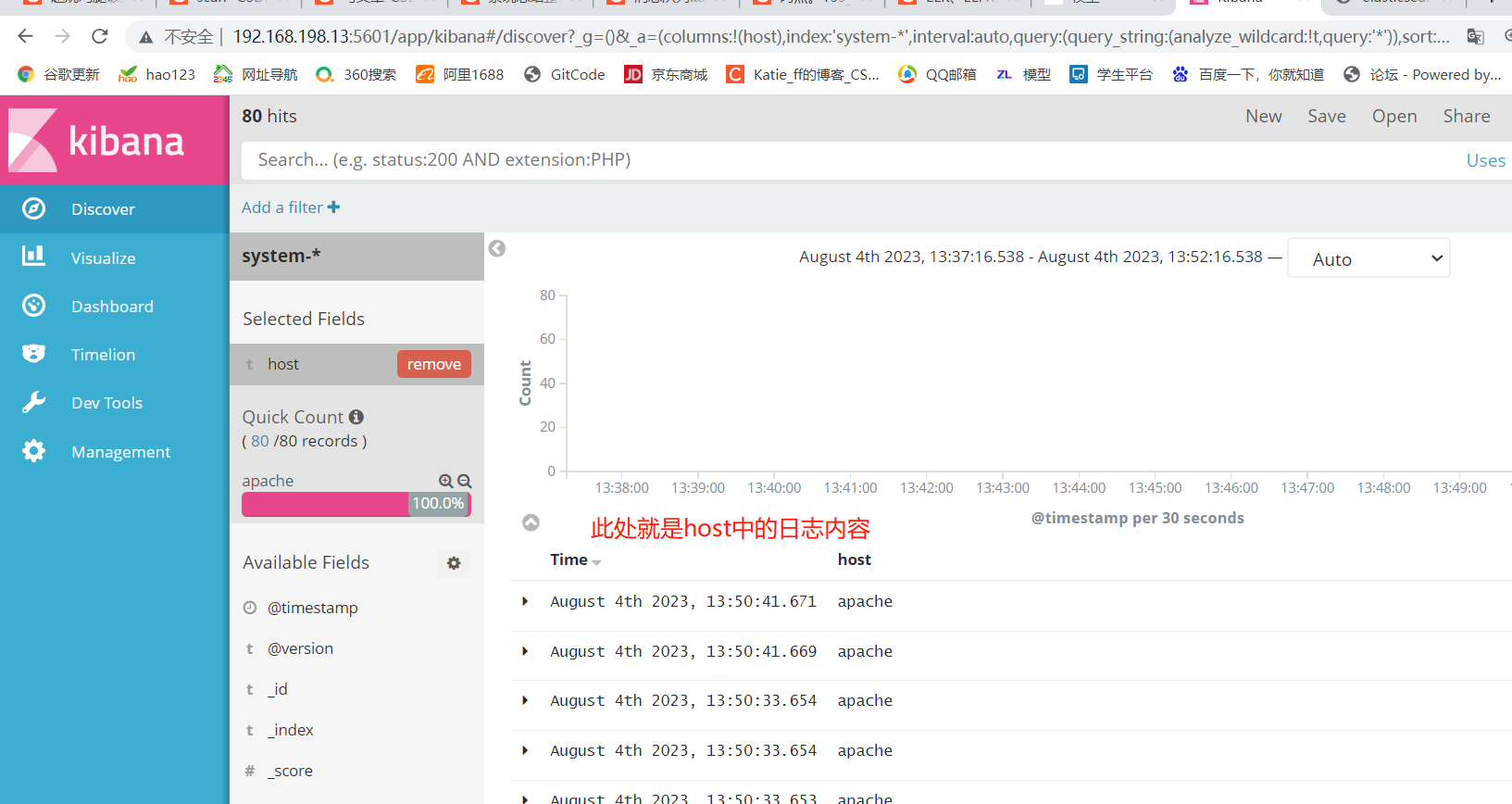
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果
3.5 将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
Apache节点
vim /etc/logstash/conf.d/apache_log.conf
input {file{path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"}file{path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}
}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.198.13:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.198.13:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf
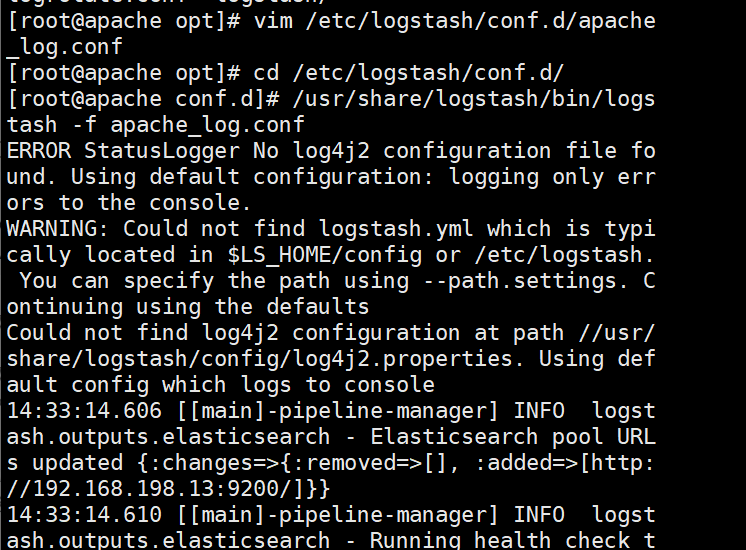
浏览器访问 http://192.168.198.13:9100 查看索引是否创建,此处如果没有生成apache_access的索引有以下
配置文件错误:检查 Apache 的配置文件中是否正确配置了 AccessLog 指令。在 Apache 的主配置文件中通常可以找到 AccessLog 指令,用于指定访问日志的格式和位置。确保指令正确配置并且未被注释掉。例如,一般配置为:
# 指定访问日志文件的存储位置和格式
CustomLog /path/to/apache/logs/access.log combined
确保这个指令在配置文件中未被注释,并且目录和文件的权限正确。权限问题:确保日志文件及其存储目录具有足够的权限,以便 Apache 服务器能够在运行时写入日志文件。检查日志文件的所属用户和组是否正确,并确保其具有可写权限。重新启动 Apache:在修改了配置文件后,需要重新启动 Apache 服务器,以使配置文件的更改生效。执行以下命令重启 Apache:/path/to/apache/bin/apachectl restart # 替换为你的 Apache 安装路径
访问量太少:如果你的网站目前没有太多访问量,可能会出现产生 apache_error 日志但未生成 apache_access 日志的情况。因为 apache_access 日志记录的是客户端请求和服务器响应的详细信息,如果没有足够的访问量,可能会导致日志文件为空或者没有生成。
通过检查配置文件、权限和重新启动 Apache 服务器,可以解决大多数导致没有生成 apache_access 日志的问题。如果问题仍然存在,可以继续检查 Apache 的其他日志文件,如错误日志和系统日志,以了解更多的错误信息。
在保证权限、配置文件都没有问题的情况,即是在测试中访问量小的原因

浏览器访问 http://192.168.198.13:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 apache_access-,并单击“Create”按钮。在用相同的方法添加 apache_error-索引。


选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access- 、apache_error- 索引, 可以查看相应的图表及日志信息。

三.Filebeat+ELK 部署
Node1节点(4C/8G):node1/192.168.198.13 Elasticsearch Kibana
Node2节点(4C/8G):node2/192.168.198.14 Elasticsearch
Apache节点:apache/192.168.198.15 Logstash Apache
Filebeat节点:filebeat/192.168.198.18 Filebeat
1. 安装 Filebeat(Filebeat节点)
#上传软件包 filebeat-6.2.4-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.2.4-linux-x86_64.tar.gz
mv filebeat-6.2.4-linux-x86_64/ /usr/local/filebeat
2.设置 filebeat 的主配置文件
cd /usr/local/filebeat
cp filebeat.yml filebeat.yml_bak
vim filebeat.yml
#=========================== Filebeat prospectors ===================== ========
- type: log #指定 log 类型,从日志文件中读取消息
#24行修改为enabled: truepaths:#28行后添加- /var/log/messages #指定监控的日志文件- /var/log/*.logfields: #46取消注释,可以使用 fields 配置选项设置一些参数字段添加到 output 中service_name: filebeatlog_type: log#filebeat地址service_id: 192.168.198.18--------------Elasticsearch output-------------------
#146行(全部注释掉)----------------Logstash output---------------------
#156行
output.logstash:hosts: ["192.168.198.17:5044"] #指定 logstash 的 IP 和端口(apache地址)
#启动 filebeat
./filebeat -e -c filebeat.yml
#或者
/usr/local/filebeat/filebeat -e -c filebeat.yml
3.在 Logstash 组件所在节点上新建一个 Logstash 配置文件(apache节点)
cd /etc/logstash/conf.d
vim logstash.conf
input {beats {port => "5044"}
}
output {elasticsearch {hosts => ["192.168.198.13:9200"]index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"}stdout {codec => rubydebug}
}
#启动 logstash
logstash -f logstash.conf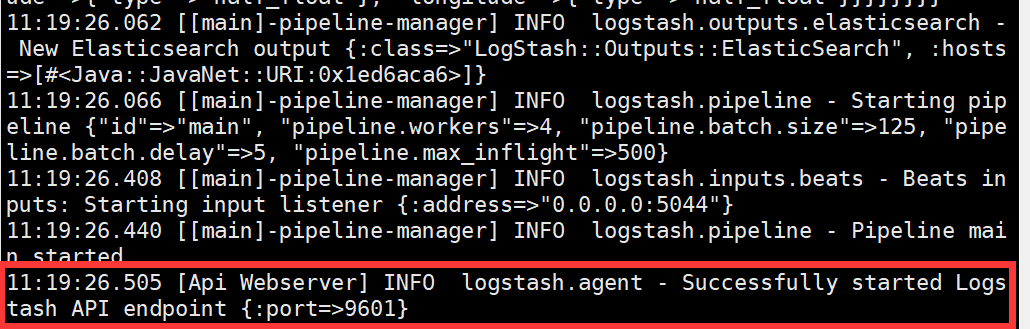
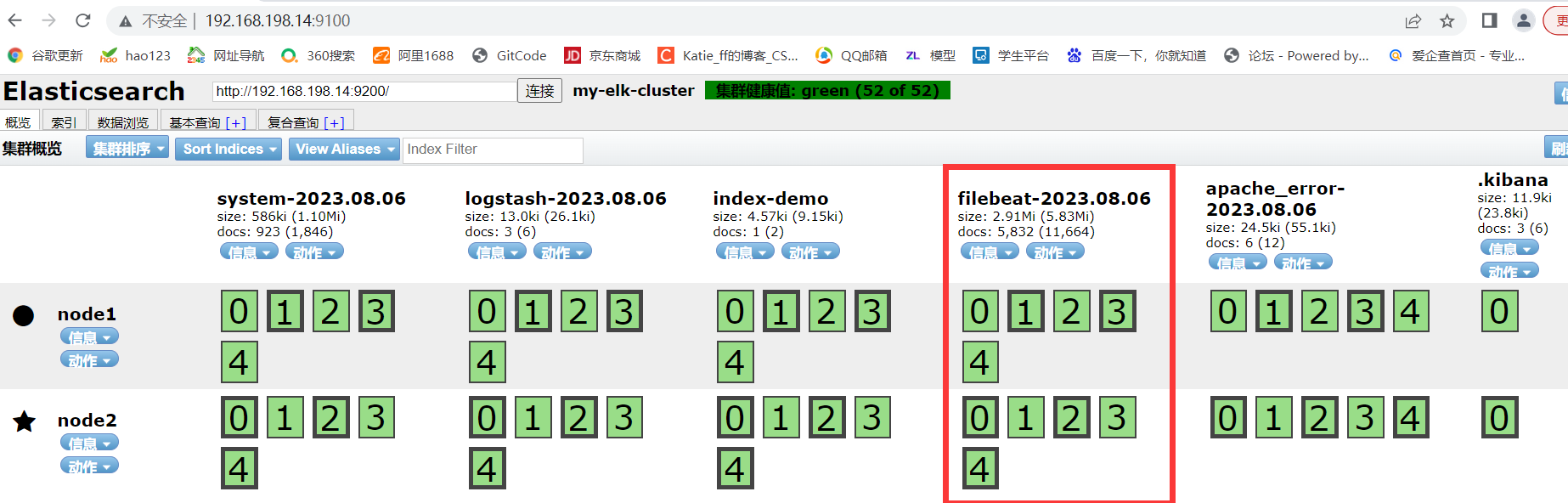
4.浏览器访问 http://192.168.198.13:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。

总
排错思路
1.ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)部分排错
(1)查看此配置文件:vim /etc/elasticsearch/elasticsearch.yml 中的配置是否错误,注意指定节点名字node1、node2
(2)查看端口是否起来,问题防火墙问题
(3)网页登陆时如出现未连接问题,需修改localhost为本机登陆地址方可
2.filebeat端排错
(1)查看filebeat上的配置文件有没有写错,filebeat的配置文件是yml文件,一定要注意格式和原本配置文件格式需一致。
(2)查看filebeat上能否ping通apache节点的地址,若ping不通则要查看防火墙和filebeat的配置文件是否指向错误,或者在logstash加载filebeat配置文件时即执行 logstash -f logstash.conf时查看弹出的日志中是否有connection fail或者no route等字样,此2个错误表示防火墙或者5044端口与filebeat不通
3.logstash端排错
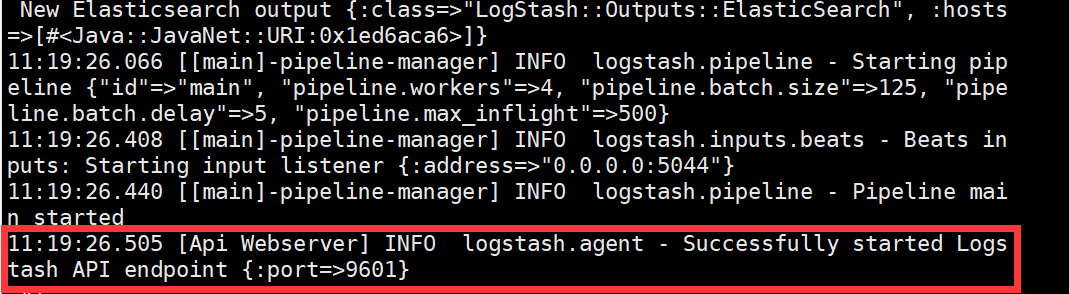
(1)首先在加载配置文件是查看是否与filebeat成功建立连接,若不成功检查端口5044和防火墙selinux等是否关闭。
如成功如下
(2)看logstash的日志文件tail -f -n 50 /var/log/logstash/logstash-plain.log是否有output到ES的字样,连接成功截图如下。若没有output则检查filebeat或logstash自身是否成功采集数据,主要查看配置文件和端口防火墙问题
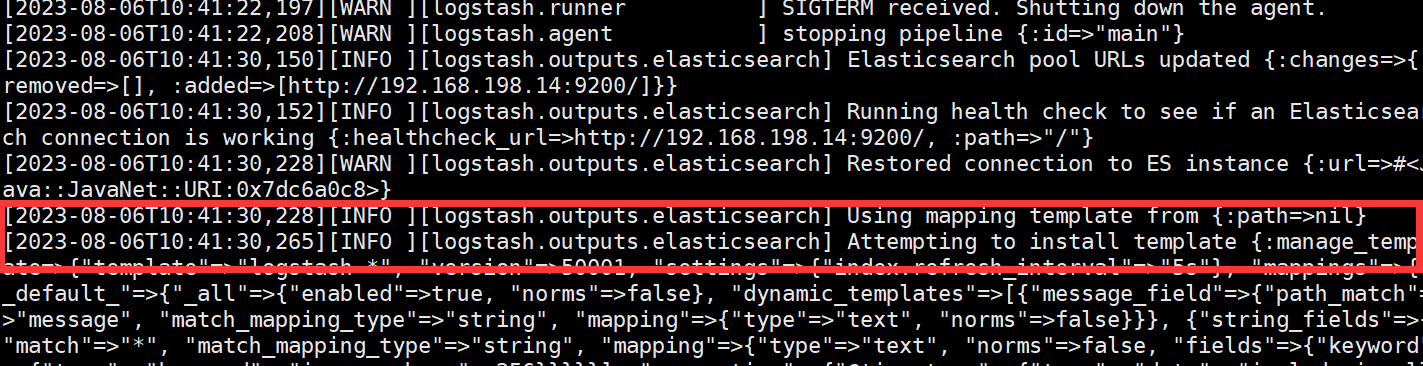
4.kibana端排错
(1)若kibana侧不能创建索引,则需要在ES上查看是否有对应名称的索引,命令如下
curl -X GET “192.168.198.13:9200/_cat/indices/?v”

(2)如果ES上没有数据,需要去排查logstash上是否将数据传输过来,若ES上有索引但是kibana创建索引成功后日志显示No results found。则需要调整一下获取的时间,或者访问一下服务产生一些日志。












![[Pytorch]卷积运算conv2d](https://img-blog.csdnimg.cn/5c7c1fefc62b46ac9fd9cd13ddf53621.png)