随着信息技术的快速发展,数据量越来越大,海量的表查询操作需要消耗大量的时间,成为影响数据库访问性能提高的主要因素。为了提升数据库操作的查询效率和用户体验,在关系型数据库管理系统(MySQL)中通过 range 分区和 Merge 存储,提出优化的分区分表算法。实验证明,优化后的算法在实现大数据量的表查询操作中,工作效率明显提高。
目录
1 分区分表的目的及 MySQL 的分区方式
1.1 分区分表的目的
1.2 MySQL 的分区方式及优点
2 Merge 存储引擎
2.1 Merge 存储引擎的操作
2.2 Merge 存储引擎的优点
3 使用 range 分区实现 MySQL 分区设计
3.1 员工表的创建及记录添加
3.2 修改分区语句
信息技术快速发展,数据库中的表越来越多,大数据应用正成为软件应用的主流。在未进行分表的
情况下,数据查询等操作的开销越来越大,数据库所能承载的数据量、数据处理能力都将遭遇瓶颈,最终导致系统的响应时间和吞吐量等关键指标不断下降。
MySQL 是应用最为广泛的关系型数据库管理系统之一,具有高性能、易部署、易使用、存储数据方便等特点,可以处理拥有上千万条记录的大型数据库,在应用系统中被大量使用。利用 MySQL 分表技术将大表进行分裂,通过分片和逻辑分割,将优化数据库性能,提高数据库的查询效率。若表查询操作频繁,分表设计将直接影响系统的应用性能和网络的服务质量。本文在 MySQL 表中通过 range 分区和 Merge 存储,提出优化的分区分表算法,提升用户在查询海量数据时的工作效率,使用户获得良好的使用体验。
1 分区分表的目的及 MySQL 的分区方式
1.1 分区分表的目的
当一个数据库表中的数据量过大时,会面临以下问题:数据操作变慢,进行 select,join,update,delete 等操作时,会对全表操作;不便于存储,出现磁盘空间存储不下这张表的情况。通过数据表分区,减小数据文件的大小,提高磁盘读写性能,在一定程度上能解决上述问题。
在系统设计数据库时,如果数据表的数据量超过几百万条,查询一次所花的时间会增加;如果联合查询,则有可能会死机。分表的目的就在于减小数据库的负担,缩短查询时间。
1.2 MySQL 的分区方式及优点
MySQL 提供了多种分区方式,常见的有:
①range 分区,基于一个给定连续区间范围,把数据分配到不同的分区,如按照商品号进行分区,在创建表时,可以使用 partition by range 子句来设置分区方式;
②list 分区,按照某个离散的列表将数据分区,如按照订单状态进行分区,在创建表时,可以使用partition by list 子句来设置分区方式;
③hash 分区,根据数据的哈希值将数据均匀地分散到多个分区中,可以提高查询和负载均衡的效率,在创建表时,可以使用 partition by hash 子句来设置分区方式;
④组合分区,将多个分区方式结合起来,如先按照日期范围进行分区,再按照订单状态进行分区,在创建表时,可 以 使 用 partition by range/list/hash 子 句 和partition by subpartition 子句来设置组合分区方式。
采用 MySQL 分区,主要优点为:和单个磁盘或者文件系统分区相比,可以存储更多数据;在 where子句中包含分区条件时,可以只扫描必要的一个或多个分区来提高查询效率,在涉及 sum()和 count()这类聚合函数的查询时,可以在每个分区上并行处理,最终只需要汇总分区得到的结果;对于已经过期或者不需要保存的数据,可以通过删除与这些数据有关的分区来快速删除数据;通过跨多个磁盘分散数据查询,获得更大的查询吞吐量。
2 Merge 存储引擎
研究大量的临时数据时,需要使用内存存储引擎,以存储所有的表格数据。在 MySQL 中,默认配
置了许多不同的存储引擎,以便灵活处理各种数据。Merge 存储引擎是将一定数量的 myisam 表联合成一个整体,在超大规模数据存储时非常有用。
2.1 Merge 存储引擎的操作
Merge 存储引擎中,myisam 表结构完全相同,索引也按照同样的顺序和方式定义。Merge 表本身并没有任何数据,对 Merge 类型的表进行插入、更新、删除、查询等操作,实际是对内部的 myisam 表进行操作。删除 Merge 表只是删除 Merge 表的定义,对内部的 myisam 表没有任何影响。
对 Merge 类 型 表 的 插 入 操 作,通 过 insert _method 子句定义,可以有三个不同的值。first 值使插入作用在第一张表上;last 值使插入作用在最后一张表上;若不定义子句,则表示不能对 Merge 表执行插入操作。
2.2 Merge 存储引擎的优点
Merge 存储引擎的优点主要体现在以下方面:查询速度比一张大表查询效率更高;引用多个数据表无须发出多条查询,查询 Merge 表就可以查到所有数据;适用于存储日志数据,将不同月份的数据存入不同的表,使用 myisampack 工具压缩数据减少空间,Merge 表查询正常工作;方便维护修复单个的小表,比修复大数据表更加容易;多个子表映射到一个总表的速度非常快,Merge 表本身不会存储和维护任何索引,索引都是由各个关联的子表存储和维护,所以创建和重新映射 Merge 表的速度非常迅速。
3 使用 range 分区实现 MySQL 分区设计
在系统设计中,随着数据量的逐渐增加,查询数据效率会降低,通过采用 range 分区算法,加快数据的访问速度,快速查询所需数据。range 分区表根据 values less than 操作符把数据划分为不同的区,在进行数据查询时不需要全表查询,只需要对某个区进行查询,大大缩小了搜索范围,查询效率快速提升,数据处理能力进一步加强,满足了海量数据查询遭遇瓶颈的问题。下面以员工的查询为例说明 range 分区算法的实现。
3.1 员工表的创建及记录添加
首先,创建员工表。
create table employees_new(id int not null,fname varchar(30),
lname varchar(30),
hired date not null default '1973 -01 -01',
separated date not null default '9999 -12 -31',
job_code int not null default 0,
store_id int not null default 0)
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21));
其次,给 employees_new 插入 7 条记录。
insert into employees _ new ( id,fname,lname,hired,store_id) values(1,'张三丰','张','2020 -06 -04',1);
insert into employees _ new ( id,fname,lname,hired,store_id) values(2,'李思思','李','2019 -07 -01',5);
insert into employees _ new ( id,fname,lname,hired,store_id) values(3,'王墨海','王','2018 -12 -14',10);
insert into employees _ new ( id,fname,lname,hired,store_id) values(4,'赵家琪','赵','2021 -06 -06',15);
insert into employees _ new ( id,fname,lname,hired,store_id) values(5,'田草草','田','2022 -01 -20',20);
insert into employees _ new ( id,fname,lname,hired,store_id) values(6,'范小宣','范','2023 -03 -06',9);
insert into employees _ new ( id,fname,lname,hired,store_id) values(7,'刘振国','刘','2022 -03 -20',20);
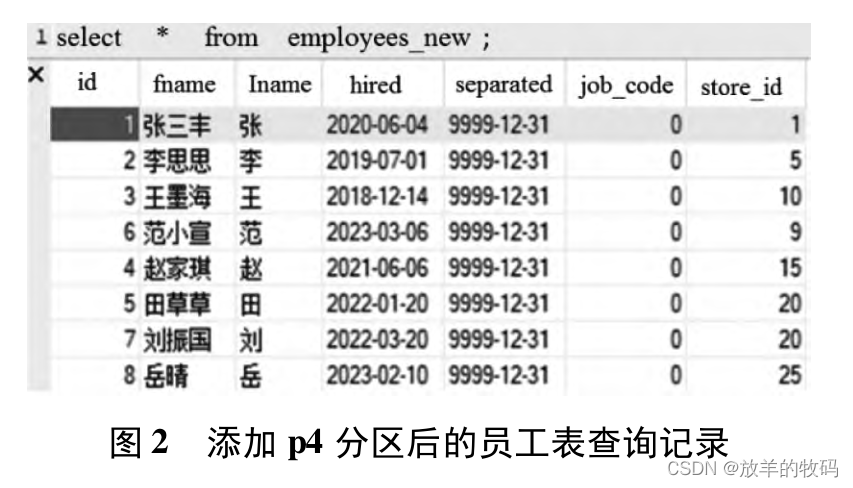
添加完成后,查询结果如图 1 所示。

3.2 修改分区语句
根据 range 分区方案,store_id 为1 ~5 的员工相对应的所有行保存在分区 p0 中,store_id 为 6 ~10 的员工保存在 p1 中,依次类推。注意,每个分区都是按照顺序进行定义的,从最低到最高。根据partition by range 语法的要求,增加一条 store_id >21 的行,出现错误,原因是没有规则包含了 store_id≥21 的行,服务器不知道把此记录保存在哪里。
为解决 store_id > 21,在设置分区时使用 valuesless than maxvalue 子句,该子句提供给所有大于明确指定的最高值。maxvalue 表示最大可能的整数值。因此,通过增加 p4 分区,存储所有 store_id≥21的行,再执行插入语句就可以解决上述问题。sql 过程如下。
alter table employees_new add partition(partitionp4 values less than maxvalue);
insert into employees _ new ( id,fname,lname,hired,store_id) values(8,' 岳晴',' 岳','2023 - 02 -10',25);
现在可以看到增加了一条记录后的员工查询结果,如图 2 所示。
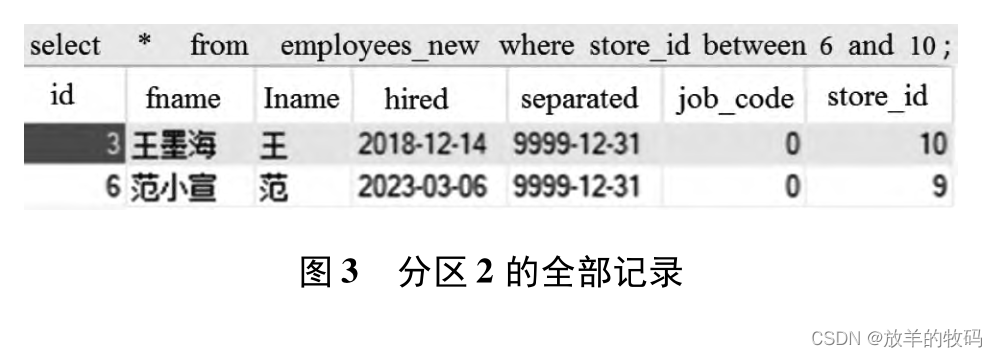
3.3查询分区 2 记录语句
查询哪些记录在分区 2 中,sql 语句如下。
select * from employees _ new where store _ idbetween 6 and 10;
查询结果如图 3 所示。