目录
Spring Boot数据访问基础知识
Spring Data
ORM
JDBC
JPA
JDBC简单实现
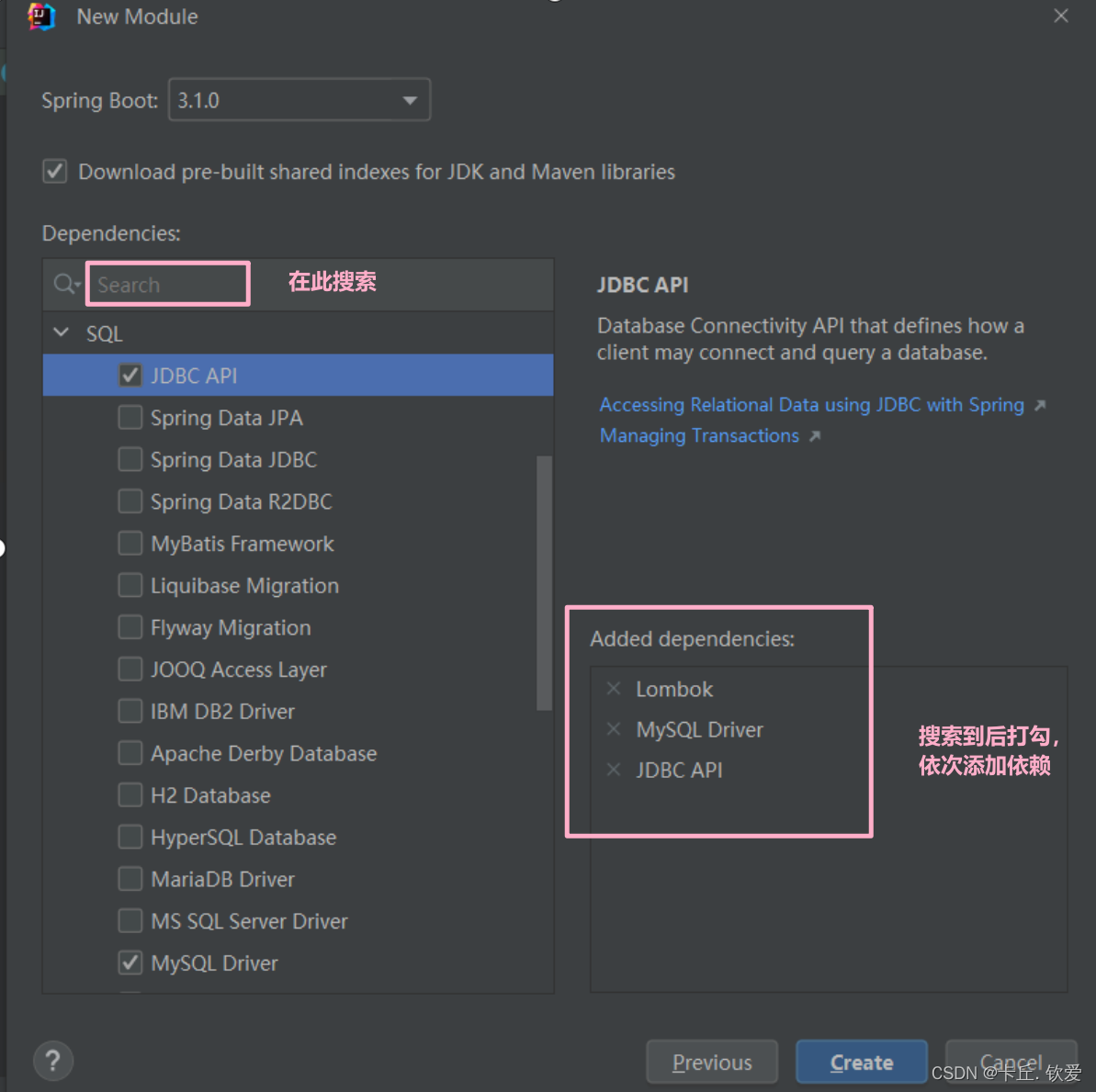
步骤1:新建Maven项目,添加依赖
步骤2:配置数据源—让程序可以访问到
步骤3:配置数据源—让IDEA可以访问到
步骤4:添加数据库和表
步骤5:建立各层级框架,写入相对应代码
步骤6:测试各个接口方法
总结
Spring Boot数据访问基础知识
Spring Data
Spring Data 项目是Spring的子项目,目的是为了简化构建基于 spring 框架应用的数据访问计数,包括非关系数据库、Map-Reduce 框架、云数据服务等等;另外也包含对关系数据库的访问支持。
Spring Data是一个用于简化数据库访问,并支持云服务的开源框架。其主要目标是使得数据库的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。此外,它还支持基于关系型数据库的数据服务,如OracleRAC等。对于拥有海量数据的项目,可以用Spring Data来简化项目的开发,就如Spring Framework对JDBCORM的支持一样,Spring Data会让数据的访问变得更加方便。
ORM
对象-关系映射(Object-Relational Mapping,简称ORM),面向对象的开发方法是当今企业级应用开发环境中的主流开发方法,关系数据库是企业级应用环境中永久存放数据的主流数据存储系统。对象和关系数据是业务实体的两种表现形式,业务实体在内存中表现为对象,在数据库中表现为关系数据。内存中的对象之间存在关联和继承关系,而在数据库中,关系数据无法直接表达多对多关联和继承关系。因此,对象-关系映射(ORM)系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。
ORM框架及优缺点
JDBC
idbc (Java DataBase Connectivitv)是iava连接数据库操作的原生接口。JDBC对Java程序员而言是APl,对实现与数据库连接的服务提供商而言是接口模型。作为API,JDB为程序开发提供标准的接口,并为各个数据库商及第三方中间件厂商实现与数据库的连接提供了标准方法。一句话概括:jdbc是所有框架操作数据库的必须要用的,由数据库厂商提供,但是为了方便java程序员调用各个数据库,各个数据库厂商都要实现idbc接口。
在我们的Spirng boot依赖中,JDBC的使用选择JDBCAPI。
Spring-data-jdbc不是普通的jdbc。它拥有了类似jpa的一些特性,比如能够根据方法名推导出sql,基本的CRUD等,也拥有了写原生sql的能力。最为关键的是,它非常的清爽,不需要依赖hibernte或者jpa。
JPA
jpa(Java Persistence API)是java持久化规范,是orm框架的标准,主流rm框架都实现了这个标准。Sun引入新的JPAORM规范出于两个原因:其一,简化现有Java EE和Java SE应用开发工作;其二,Sun希望整合ORM技术,实现天下归一。ORM是一种思想,是插入在应用程序与JDBC API之间的一个中间层,JDBC并不能很好地支持面向对象的程序设计,ORM解决了这个问题,通过JDBC将字段高效的与对象进行映射。具体实现有hibernate、spring data jpa open jpa。
Spring DataJPA可以理解为JPA规范的再次封装抽象,底层还是使用了 Hibernate 的JPA技术实现
JDBC简单实现
在Spring boot中,我们通过数据源拿到数据库连接,可以使用原生的JDBC语句来操作数据库。Spring本身也对原生的JDBC做了轻量级的封装,即dbcTemplate。 配置DBC的依赖后,Spring boot配置好了JdbcTemplat 放在了容器中,程序员只需自己注入即可使用。下面是一个简单的CRUD例子。
步骤1:新建Maven项目,添加依赖

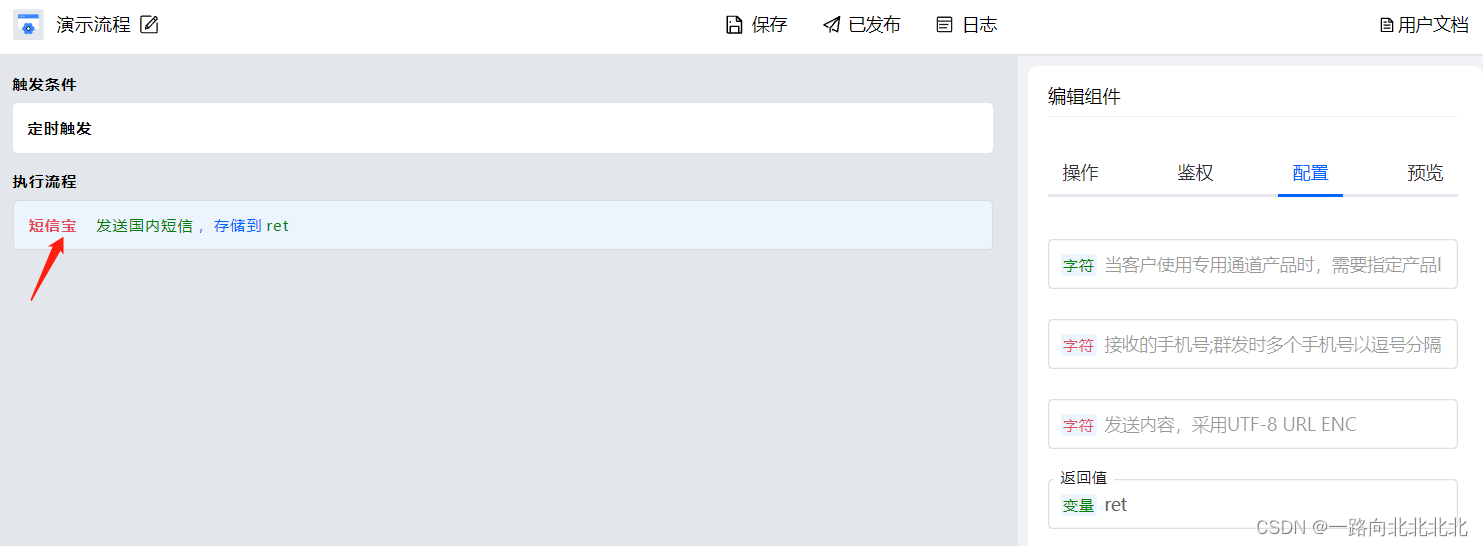
步骤2:配置数据源—让程序可以访问到
注意:创建项目后,要设置好自己的本地仓库,我之前的文章有讲如何设置
等待依赖下载完成,写入以下配置信息。包括驱动、数据源地址、数据源访问用户名和密码

spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/testdb?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456步骤3:配置数据源—让IDEA可以访问到
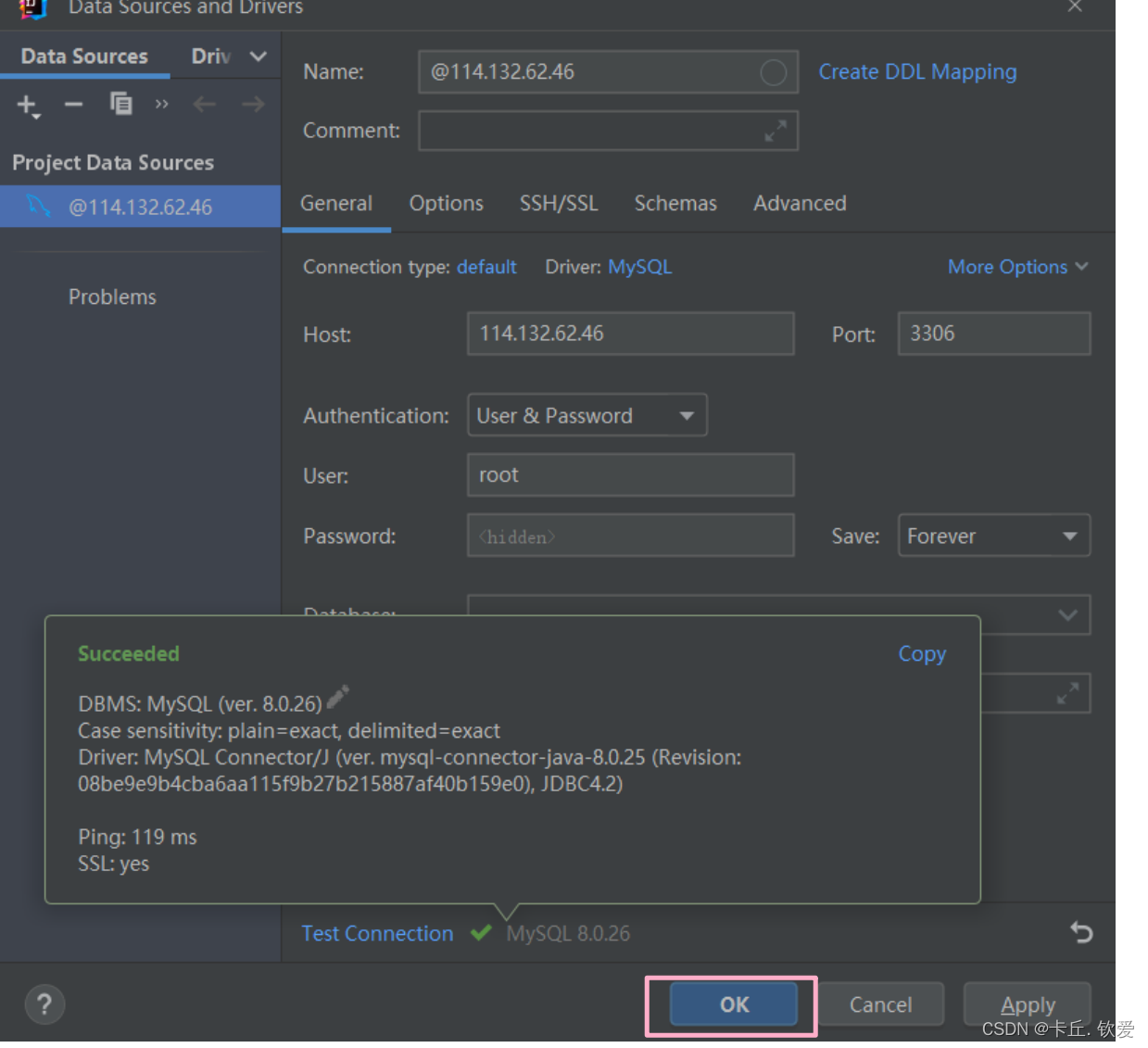
如图所示,点击右边的 databases 或者 数据库 则弹出图片菜单
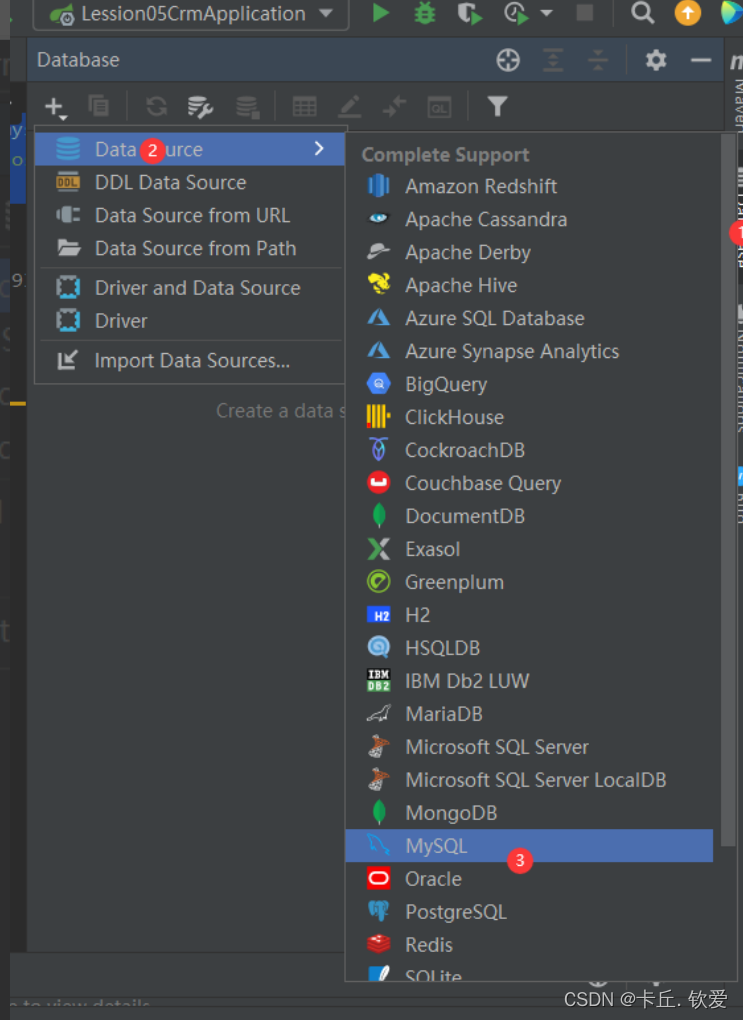

下载驱动完成后,测试链接成功。点击OK确认
步骤4:添加数据库和表

代码依次为data.sql 、Schema.sql 、user.sql
INSERT INTO `article` VALUES ('1','2101','SpringBoot 核心注解','核心注解的主要作用','00000008976','2023-01-16 12:11:12','2023-01-16 12:19:19');INSERT INTO `article` VALUES ('2','356752','JVM 调优','HotSpot 虚拟机详解','00000000026','2023-06-16 12:15:27','2023-06-16 18:15:30');INSERT INTO `article` VALUES ('3','454','JVM核心思想','编程的各种难题','0000000008','2023-08-5 12:15:27','2023-08-5 19:15:30');DROP DATABASE IF EXISTS `Blog`;
create database Blog;Use Blog;DROP TABLE IF EXISTS `article`;
CREATE TABLE `article`
(`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`user_id` int(11) NOT NULL COMMENT '作者 ID',`title` varchar(100) NOT NULL COMMENT '文章标题',`summary` varchar(200) DEFAULT NULL COMMENT '文章概要',`read_count` int(11) unsigned zerofill NOT NULL COMMENT '阅读读数',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '最后修改时间',PRIMARY KEY (`id`)
) ENGINE = InnoDBAUTO_INCREMENT = 1DEFAULT CHARSET = utf8mb4;DROP DATABASE IF EXISTS `testdb`;
create database testdb;Use testdb;DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (`user_id` int NOT NULL AUTO_INCREMENT COMMENT '用户 ID',`user_name` varchar(255) DEFAULT NULL COMMENT '用户名',`status` varchar(255) DEFAULT NULL COMMENT '用户状态',PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;添加之后,在user点击左上角的三角形按钮创建库表 (另外两个sql语句可以自行娱乐,本文章不会用上)

步骤5:建立各层级框架,写入相对应代码
数据库和表建好之后,我们要建立各层级的软件包,里面存放不同的代码来让项目更加美观和使用,框架和代码如下:
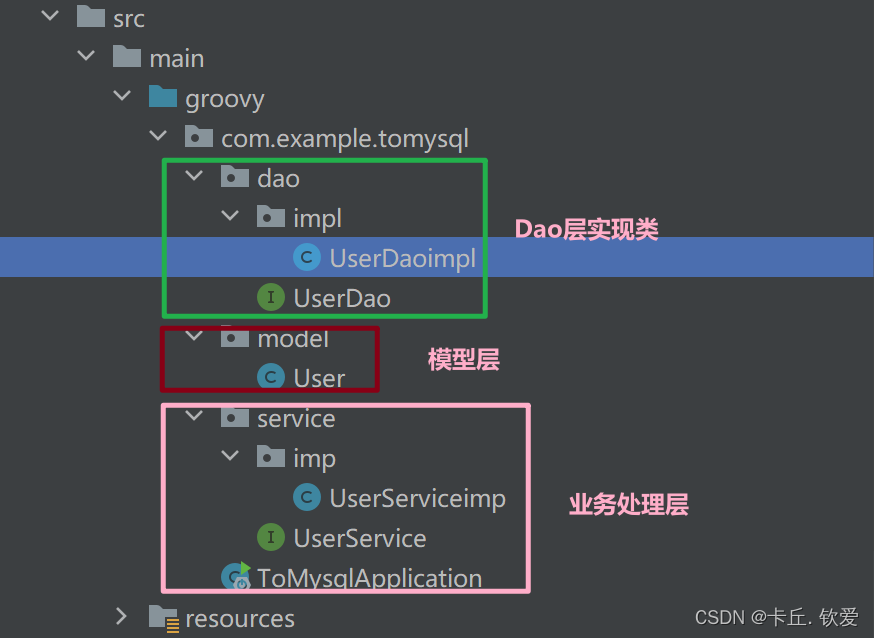



各文件代码如下,注释有该文件的名称,大家只要复制粘贴就好
//useDao
public interface UserDao {int addUser(User user);int update(User user);int delete(User user);int count(User user);List<User> getList(User user);User getUser(User user);void batchAddUser(List<Object[]> batchArgs);}//UserDaoimpl
@Repository
public class UserDaoimpl implements UserDao {@Resourceprivate JdbcTemplate jdbcTemplate;@Resourceprivate NamedParameterJdbcTemplate namedParameterJdbcTemplate;@Overridepublic int addUser(User user) {String sql = "INSERT into `user` (`user`.user_name,`user`.`status`) VALUES(?,?);";return jdbcTemplate.update(sql, user.getUserName(), user.getStatus());}@Overridepublic int update(User user) {String sql = "UPDATE `user` SET status=? WHERE user_name=?;";return jdbcTemplate.update(sql, user.getStatus(), user.getUserName());}@Overridepublic int delete(User user) {String sql = "DELETE FROM `user` where user_name=?;";return jdbcTemplate.update(sql, user.getUserName());}@Overridepublic int count(User user) {String sql = "SELECT COUNT(*) FROM `user` where `status`=?;";return jdbcTemplate.queryForObject(sql, Integer.class, user.getStatus());}@Overridepublic List<User> getList(User user) {String sql = "SELECT * FROM `user` where `status`=?;";return jdbcTemplate.query(sql, new BeanPropertyRowMapper<User>(User.class), user.getStatus());}@Overridepublic User getUser(User user) {String sql = "SELECT * FROM `user` where `user_id`=?;";return jdbcTemplate.queryForObject(sql, new BeanPropertyRowMapper<User>(User.class), user.getStatus());}@Overridepublic void batchAddUser(List<Object[]> batchArgs) {String sql = "INSERT into `user` (`user`.user_name,`user`.`status`) VALUES(?,?);";jdbcTemplate.batchUpdate(sql,batchArgs);}
}//User
@Data
@AllArgsConstructor
@ToString
@NoArgsConstructor
public class User {private Integer userId;private String userName;private String status;}//UserService
public interface UserService {public int addUser(User user);public int updateUser(User user);public int deleteUser(User user);public int countUser(User user);public List<User> getList(User user);public User getUser(User user);public void batchAddUser(List<Object[]> batchArgs);
}//UserServiceimp
@Service("userService")
public class UserServiceimp implements UserService {@Resourceprivate UserDao userDao;@Overridepublic int addUser(User user){return userDao.addUser(user);}@Overridepublic int updateUser(User user){return userDao.update(user);}@Overridepublic int deleteUser(User user) {return userDao.delete(user);}@Overridepublic int countUser(User user) {return userDao.count(user);}@Overridepublic List<User> getList(User user) {return userDao.getList(user);}@Overridepublic User getUser(User user) {return userDao.getUser(user);}@Overridepublic void batchAddUser(List<Object[]> batchArgs) {userDao.batchAddUser(batchArgs);}
}步骤6:测试各个接口方法
我们在test的测试类下建立测试方法,可以依次测试我们写好的接口。注意要一段一段语句测试,否则会出错,测试代码我已写好注释


@Resourceprivate JdbcTemplate jdbcTemplate;@AutowiredUserService userService;@Testvoid taa(){User user=new User();user.setUserName("阿三");user.setStatus("在线");// 新增用户int i = userService.addUser(user);System.out.println("新增用户成功");// 修改用户
// User user1 =new User();
// user1.setUserName("乌鸦哥");
// user1.setStatus("在线");
// int u = userService.updateUser(user1);
// System.out.println("修改用户成功");//批量添加
// List<Object[]> batchArgs = new ArrayList<>();
// Object[] a1 = {"}
// Object[] a2 = {"b","在线"};
// Object[] a3 = {"c","在线"};
// Object[] a4 = {"d","在线"};
// batchArgs.add(a1);
// batchArgs.add(a2);
// batchArgs.add(a3);
// batchArgs.add(a4);
// userService.batchAddUser(batchArgs);
// System.out.println("批量增加完毕");//查询在线用户数量
// User user2 = new User();
// user2.setStatus("在线");
// int a = userService.countUser(user2);
// System.out.println("在线用户个数为: "+ a);//获取用户列表(user2在线)
// List<User> userList = userService.getList(user2);
// System.out.println("在线用户列表查询成功");//遍历在线列表
// for (User user3 : userList){
// System.out.println("用户ID:"+ user3.getUserId() +",用户名:"+
// user3.getUserName() + " ,状态:"+ user3.getStatus()
// );
// }}总结
以上就是今天的内容了,本文章主要讲了Spring Boot中的数据访问基础知识,以及如何使用JDBC进行简单的数据访问。而Spring Boot的自动化配置和简化开发极大地提高了开发效率,希望大家能有所收获。如本文有不妥之处,欢迎大家评论区点赞留言转发~