亲测有效!解决PyCharm下PyEMD安装报错 ModuleNotFoundError: No module named ‘PyEMD‘

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/8020.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

上海亚商投顾:沪指冲高回落 大金融板块全天强势 上海亚商投
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪
市场全天冲高回落,深成指、创业板指午后翻绿。大金融板块全天强势,天茂集团…

【unity游戏开发之InputSystem——02】InputAction的使用介绍(基于unity6开发介绍)
文章目录 前言一、InputAction简介1、InputAction是什么?2、示例 二、监听事件started 、performed 、canceled1、启用输入检测2、操作监听相关3、关键参数 CallbackContext4、结果 三、InputAction参数相关1、点击齿轮1.1 Actions 动作(1)动…
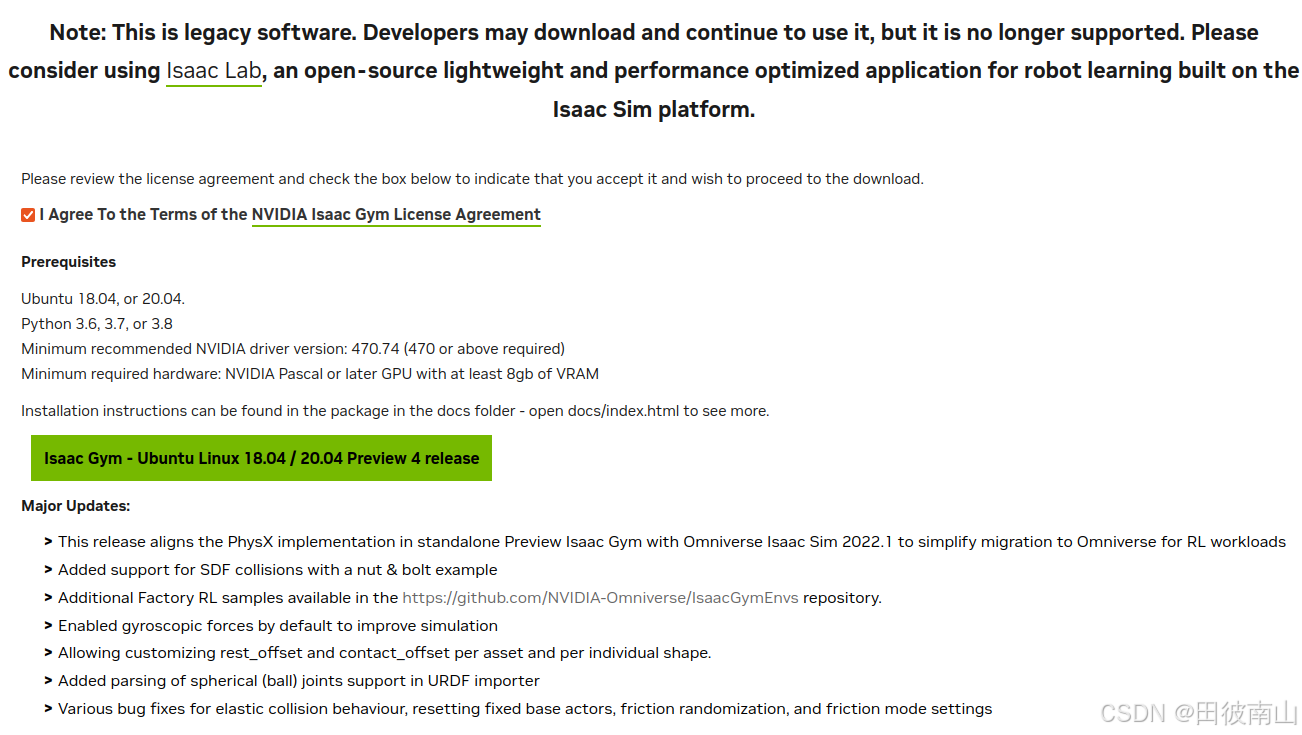
ubuntu22安装issac gym记录
整体参考:https://blog.csdn.net/Yakusha/article/details/144306858 安装完成后的整体版本信息
ubuntu:22.04内核:6.8.0-51-generic显卡:NVIDIA GeForce RTX 3050 OEM显卡驱动:535.216.03cuda:12.2cudnn&…

Linux下Ubuntun系统报错find_package(BLAS REQUIRED)找不到
Linux下Ubuntun系统报错find_package(BLAS REQUIRED)找不到
这次在windows的WSL2中遇到了一个非常奇怪的错误,就是
CMake Error at /usr/share/cmake-3.22/Modules/FindPackageHandleStandardArgs.cmake:230 (message):Could NOT find BLAS (missing: BLAS_LIBRAR…


CommonAPI学习笔记-1
CommonAPI学习笔记-1
一. 整体结构 CommonAPI分为两层:核心层和绑定层,使用了Franca来描述服务接口的定义和部署,而Franca是一个用于定义和转换接口的框架(https://franca.github.io/franca/)。
核心层和通信中间…
单片机基础模块学习——DS18B20温度传感器芯片
不知道该往哪走的时候,就往前走。 一、DS18B20芯片原理图 该芯片共有三个引脚,分别为
GND——接地引脚DQ——数据通信引脚VDD——正电源 数据通信用到的是1-Wier协议
优点:占用端口少,电路设计方便 同时该协议要求通过上拉电阻…

Golang Gin系列-9:Gin 集成Swagger生成文档
文档一直是一项乏味的工作(以我个人的拙见),但也是编码过程中最重要的任务之一。在本文中,我们将学习如何将Swagger规范与Gin框架集成。我们将实现JWT认证,请求体作为表单数据和JSON。这里唯一的先决条件是Gin服务器。…

< OS 有关 > 阿里云:轻量应用服务器 的使用 :轻量化 阿里云 vpm 主机
原因:
< OS 有关 > 阿里云:轻量应用服务器 的使用 :从新开始 配置 SSH 主机名 DNS Tailscale 更新OS安装包 最主要是 清除阿里云客户端这个性能杀手-CSDN博客
防止 I/O 祸害系统
操作:
查看进程&#x…

设计模式的艺术-代理模式
结构性模式的名称、定义、学习难度和使用频率如下表所示: 1.如何理解代理模式 代理模式(Proxy Pattern):给某一个对象提供一个代理,并由代理对象控制对原对象的引用。代理模式是一种对象结构型模式。 代理模式类型较多…

K8S极简教程(4小时快速学会)
1. K8S 概览
1.1 K8S 是什么
K8S官网文档:https://kubernetes.io/zh/docs/home/ 1.2 K8S核心特性
服务发现与负载均衡:无需修改你的应用程序即可使用陌生的服务发现机制。存储编排:自动挂载所选存储系统,包括本地存储。Secret和…

python3+TensorFlow 2.x(五)CNN
目录 CNN理解
code实现人脸识别
数据集准备:
code实现
模型解析
结果展示
结果探讨
基于vgg16的以图搜图
数据准备
图库database
检索测试集datatest
code实现
code解析
结果展示 CNN理解
卷积神经网络(CNN)是深度学习中最强大…

(一)HTTP协议 :请求与响应
前言
爬虫需要基础知识,HTTP协议只是个开始,除此之外还有很多,我们慢慢来记录。
今天的HTTP协议,会有助于我们更好的了解网络。
一、什么是HTTP协议
(1)定义
HTTP(超文本传输协议ÿ…

FPGA实现任意角度视频旋转(完结)视频任意角度旋转实现
本文主要介绍如何基于FPGA实现视频的任意角度旋转,关于视频180度实时旋转、90/270度视频无裁剪旋转,请见本专栏前面的文章,旋转效果示意图如下:
为了实时对比旋转效果,采用分屏显示进行处理,左边代表旋转…

如何移植ftp服务器到arm板子?
很多厂家提供的sdk,一般都不自带ftp服务器功能,
需要要发人员自己移植ftp服务器程序。
本文手把手教大家如何移植ftp server到arm板子。
环境
sdk:复旦微
Buildroot 2018.02.31. 解压
$ mkdir ~/vsftpd
$ cp vsftpd-3.0.2.tar.gz ~/vs…

【阅读笔记】基于整数+分数微分的清晰度评价算子
本文介绍的是一种新的清晰度评价算子,整数微分算子分数微分算子
一、概述
目前在数字图像清晰度评价函数中常用的评价函数包括三类:灰度梯度评价函数、频域函数和统计学函数,其中灰度梯度评价函数具有计算简单,评价效果好等优点…

LabVIEW 保存文件 生产者/消费者设计
LabVIEW 保存文件 生产者/消费者设计 简介生产消费模式设计结构 简介
主从模式的数据通信是利用全局变量、局域变量或共享变量实现的,由于这些变量的每次复制都是原始数据的一个副本,占据了大量的空间。实际上,只需要使用一部分缓冲区作为数…

网络安全 | F5-Attack Signatures-Set详解
关注:CodingTechWork
创建和分配攻击签名集 可以通过两种方式创建攻击签名集:使用过滤器或手动选择要包含的签名。 基于过滤器的签名集仅基于在签名过滤器中定义的标准。基于过滤器的签名集的优点在于,可以专注于定义用户感兴趣的攻击签名…

宏_wps_宏修改word中所有excel表格的格式_设置字体对齐格式_删除空行等
需求:
将word中所有excel表格的格式进行统一化,修改其中的数字类型为“宋体, 五号,右对齐, 不加粗,不倾斜”,其中的中文为“宋体, 五号, 不加粗,不倾斜”
数…

项目集成RabbitMQ
文章目录 1.common-rabbitmq-starter1.创建common-rabbitmq-starter2.pom.xml3.自动配置1.RabbitMQAutoConfiguration.java2.spring.factories 2.测试使用1.创建common-rabbitmq-starter-demo2.目录结构3.pom.xml4.application.yml5.TestConfig.java 配置交换机和队列6.TestCon…
推荐文章
- ip地址是手机号地址还是手机地址
- (八)趣学设计模式 之 装饰器模式!
- (十)Mapbox GL JS 中点击 Marker 时获取与该 Marker 相关的自定义数据的解决办法
- .gitattributes与git lfs
- .net core 中使用AsyncLocal传递变量
- [b01lers2020]Life on Mars1
- [Python学习日记-79] socket 开发中的粘包现象(解决模拟 SSH 远程执行命令代码中的粘包问题)
- [Qt5] QJson数据之间的转换以及QByteArray图像数据压缩
- [SAP ABAP] 性能优化
- [创业之路-343]:创业:一场认知重构与组织进化的双向奔赴
- [深度学习]基于C++和onnxruntime部署yolov12的onnx模型
- [特殊字符] 2025蓝桥杯备赛Day8——B2118 验证子串