第一部分:回归分析的介绍
定义:回归分析是数据分析中最基础也是最重要的分析工具,绝大多数的数据分析问题,都可以使用回归的思想来解决。回归分析的人数就是,通过研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的。
常见的回归分析有五类:线性回归,0-1回归,定序回归,计数回归和生存回归,其划分的依据是因变量Y的类型。本讲我么你主要学习线性回归。
回归的思想:
第一个关键词:相关性
相关性!= 因果性,我们不能因为出两者有相关性就得出两者是由因果关系的。
第二个关键词:Y
第三个关键词是:X
0-1回归的例子(0-1回归的例子一般只有两个答案所以Y只有两个值来表示)
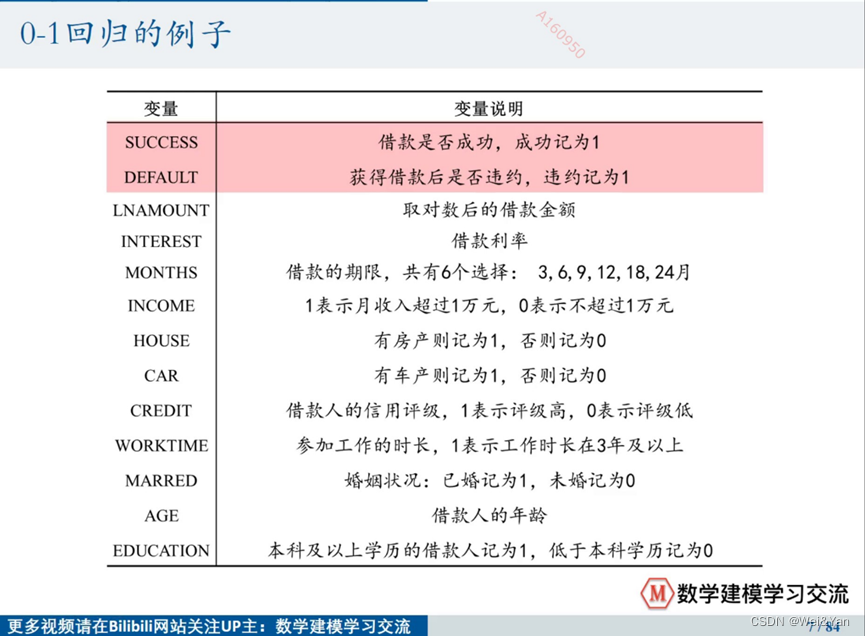
回归分析的使命:
第二部分:不同数据类型的处理方法

数据的分类:
- 横截面数据

2. 时间序列数据:

3. 面板数据
-

-
不同数据类型的处理方法:

-
第三部分:对于线性回归的理解以及生性问题的研究
一元线性回归:
存在扰动项:yi-y^i=yi-B^0-B^1xi

-
对于线性的理解:

回归系数的解释:

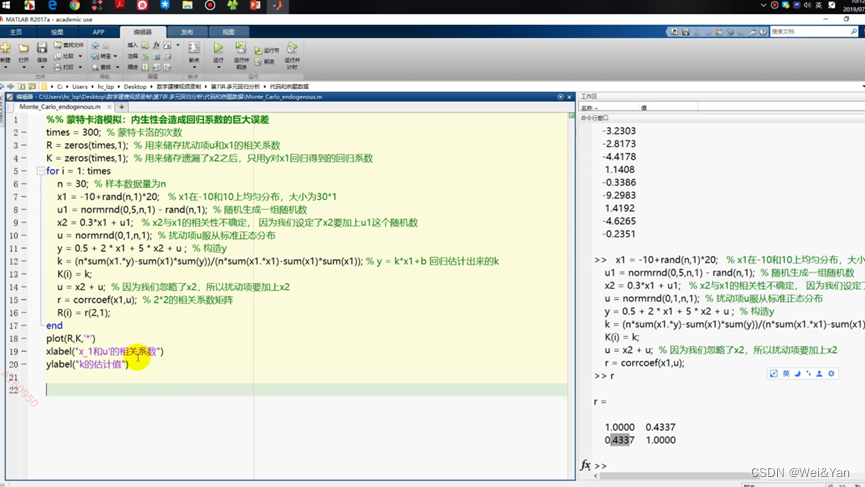
关于内生性的探究:
扰动项与所有的自变量不存在相关性的时候则模型具有外生性。因此我们需要对模型的自变量与扰动项求其相关性。

内生性的蒙特卡洛模拟:

Matlab实操:

核心解释变量和控制变量
对于我们想要求取的因素当作变量,其余的因素可以看作扰动项。

第四部分:四种模型的解释,与你变量的设置以及交互项的解释
回归系数的解释:

什么时候取对数?

四种模型的回归系数解释:


特殊的自变量:虚拟变量、
对于定性变量我们可以用数字来进行表示如女性为1,男性为0.


多分类的虚拟变量:
为了避免完全多重共线性的影响,引入的虚拟变量的个数一般是分类数减1.

还有交互项(两个自变量相乘)的自变量

第五部分:案列引入

Stata软件的介绍:

文件导入:


Stata中一些函数的作用:// 按键盘上的PageUp可以使用上一次输入的代码(Matlab中是上箭头)// 清除所有变量clear// 清屏 和 matlab的clc类似cls// 导入数据(其实是我们直接在界面上粘贴过来的,我们用鼠标点界面导入更方便 本条请删除后再复制到论文中,如果评委老师看到了就知道这不是你写的了)// import excel "C:\Users\hc_lzp\Desktop\数学建模视频录制\第7讲.多元回归分析\代码和例题数据\课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrowimport excel "课堂中讲解的奶粉数据.xlsx", sheet("Sheet1") firstrow// 定量变量的描述性统计summarize 团购价元 评价量 商品毛重kg// 定性变量的频数分布,并得到相应字母开头的虚拟变量tabulate 配方,gen(A)tabulate 奶源产地 ,gen(B)tabulate 国产或进口 ,gen(C)tabulate 适用年龄岁 ,gen(D)tabulate 包装单位 ,gen(E)tabulate 分类 ,gen(F)tabulate 段位 ,gen(G)// 下面进行回归regress 评价量 团购价元 商品毛重kg// 下面的语句可帮助我们把回归结果保存在Word文档中// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)// ssc install reg2docx, all replace// 如果安装出现connection timed out的错误,可以尝试换成手机热点联网,如果手机热点也不能下载,就不用这个命令吧,可以自己做一个回归结果表,如果觉得麻烦就直接把回归结果截图。est store m1reg2docx m1 using m1.docx, replace// *** p<0.01 ** p<0.05 * p<0.1// Stata会自动剔除多重共线性的变量regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4est store m2reg2docx m2 using m2.docx, replace// 得到标准化回归系数regress 评价量 团购价元 商品毛重kg, b// 画出残差图regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4rvfplot// 残差与拟合值的散点图graph export a1.png ,replace// 残差与自变量团购价的散点图rvpplot 团购价元graph export a2.png ,replace// 为什么评价量的拟合值会出现负数?// 描述性统计并给出分位数对应的数值summarize 评价量,d// 作评价量的概率密度估计图kdensity 评价量graph export a3.png ,replace// 异方差BP检验estat hettest ,rhs iid// 异方差怀特检验estat imtest,white// 使用OLS + 稳健的标准误regress 评价量 团购价元 商品毛重kg A1 A2 A3 B1 B2 B3 B4 B5 B6 B7 B8 B9 C1 C2 D1 D2 D3 D4 D5 E1 E2 E3 E4 F1 F2 G1 G2 G3 G4, rest store m3reg2docx m3 using m3.docx, replace// 计算VIFestat vif// 逐步回归(一定要注意完全多重共线性的影响)// 向前逐步回归(后面的r表示稳健的标准误)stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pe(0.05)// 向后逐步回归(后面的r表示稳健的标准误)stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r pr(0.05)// 向后逐步回归的同时使用标准化回归系数(在r后面跟上一个b即可)stepwise reg 评价量 团购价元 商品毛重kg A1 A3 B1 B2 B3 B4 B5 B6 B7 B9 C1 D1 D2 D3 D4 E1 E2 E3 F1 G1 G2 G3, r b pr(0.05)// 补充语法 (大家不需要具体的去学Stata软件,掌握我课堂上教给大家的一些命令应对数学建模比赛就可以啦)// 事实上大家学好Excel,学好后应对90%的数据预处理问题都能解决// (1) 用已知变量生成新的变量generate lny = log(评价量) generate price_square = 团购价元 ^2generate interaction_term = 团购价元*商品毛重kg// (2) 修改变量名称,因为用中文命名变量名称有时候可能容易出现未知Bugrename 团购价元 price
-
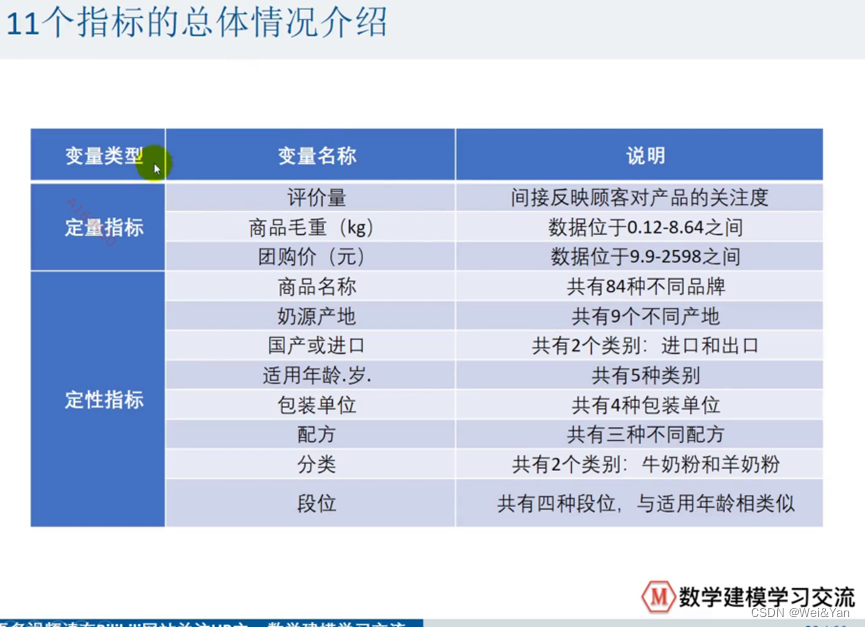
案列中的各指标介绍:
Stata中的回归语句:
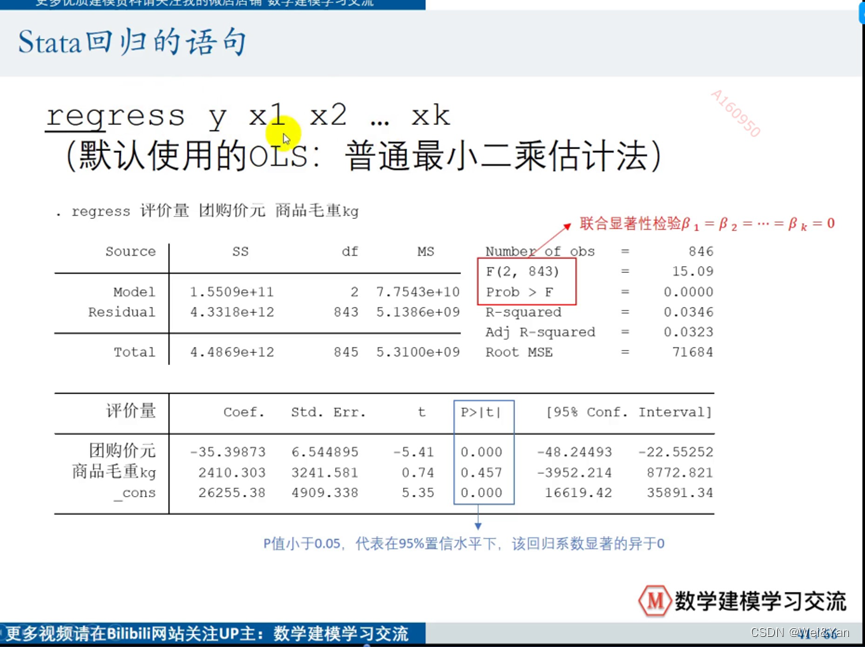
表中的Model对应SSR,Residual对应SSE,Total对应SST
Df(自由度)那一列分别是:k,n-k-1,n-1。
看prob若<0.1(假设为90%)通过。
拟合优度较低怎么办:

拟合出现负值的原因:

标准化回归系数:

Stata标准化回归命令:


第六部分异方差多重共线性以及交互项的解释:
扰动项要满足的条件:、

异方差以及如何解决:

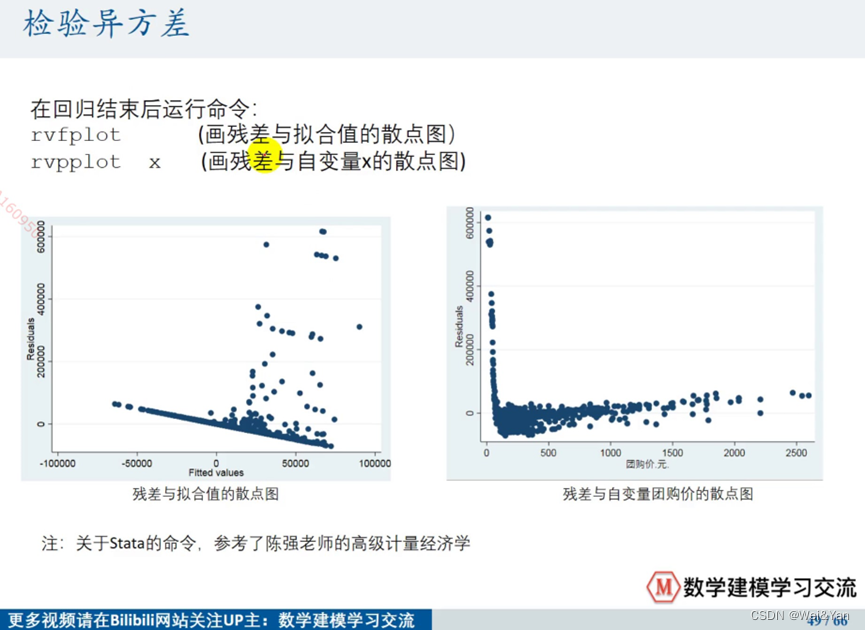
检验异方差:
拟合值出现负数的原因
拟合值分布不均匀,R^2过小,出现负数。

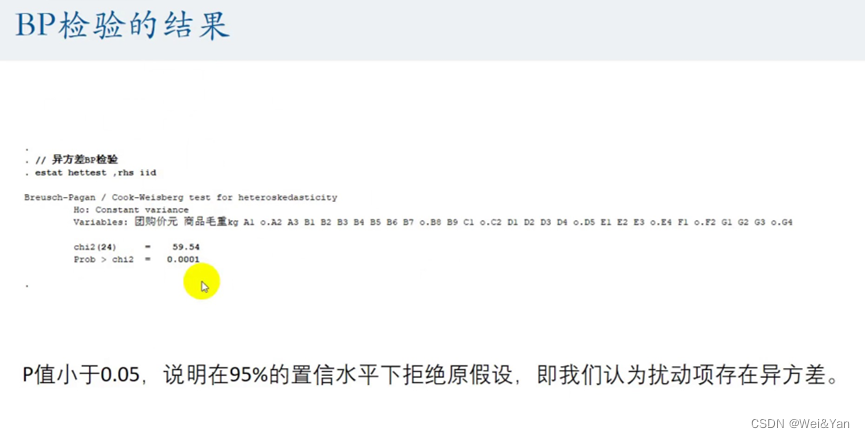
异方差的假设性检验:
BP检验的结果:
怀特检验:
异方差的处理方法: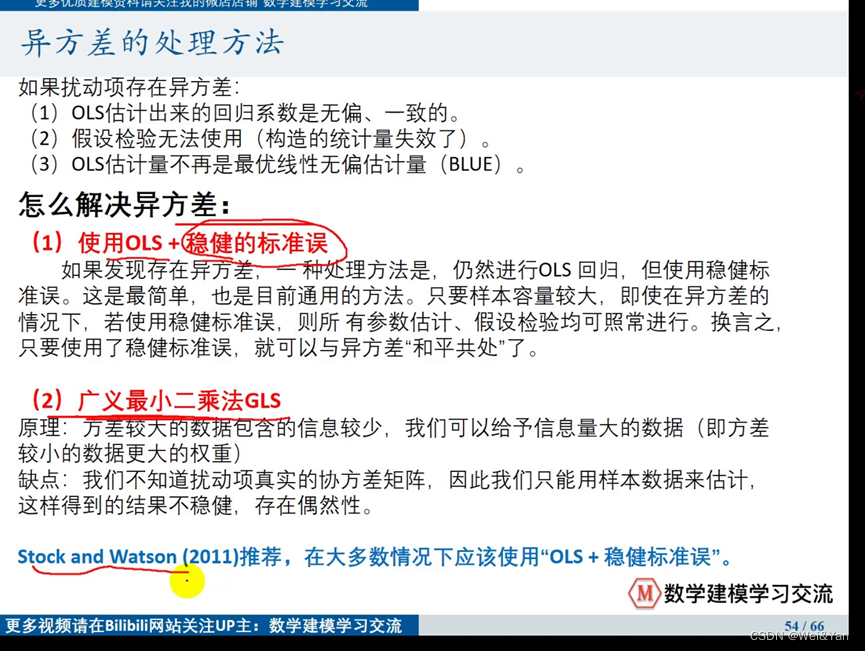
Stata中的OLS+稳健的标准误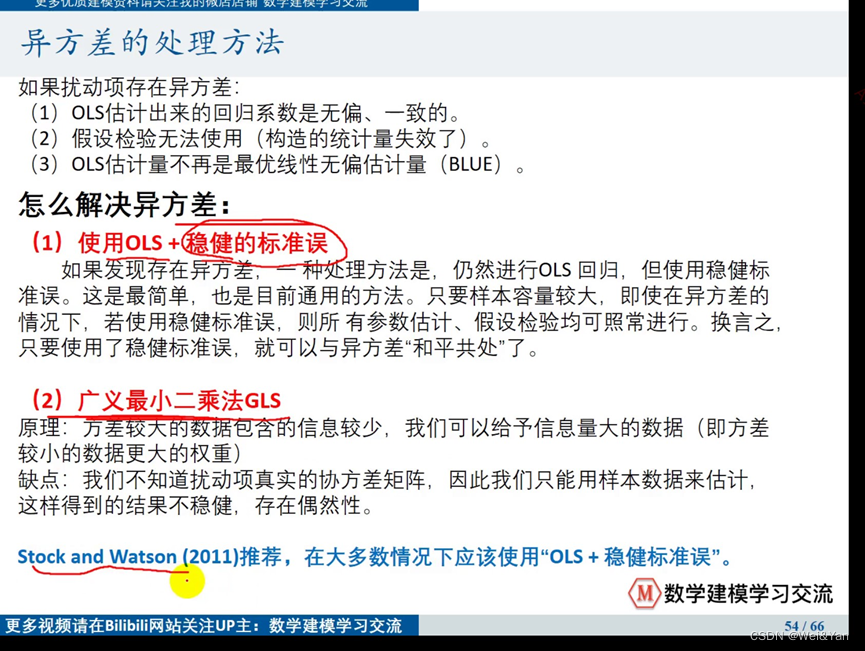
多重共线性:
检验: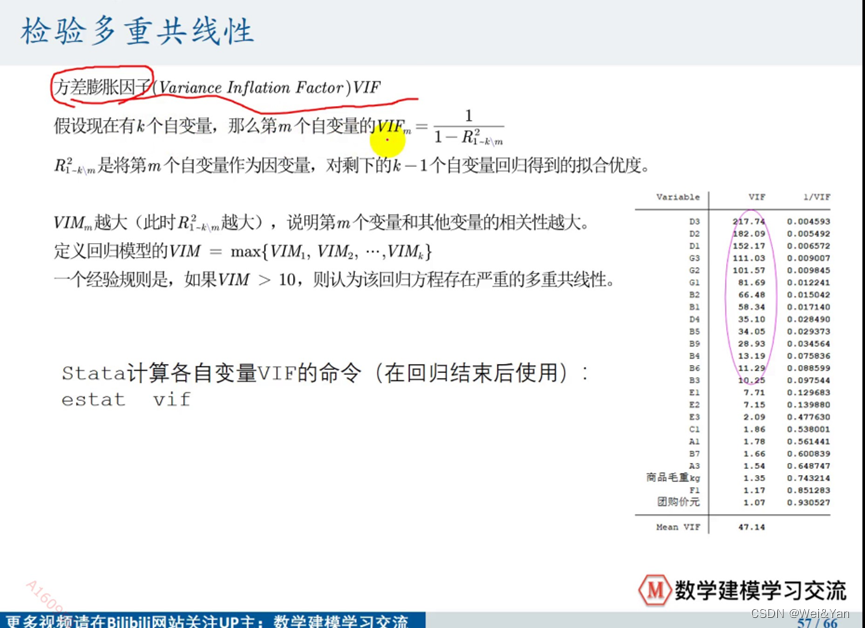
处理: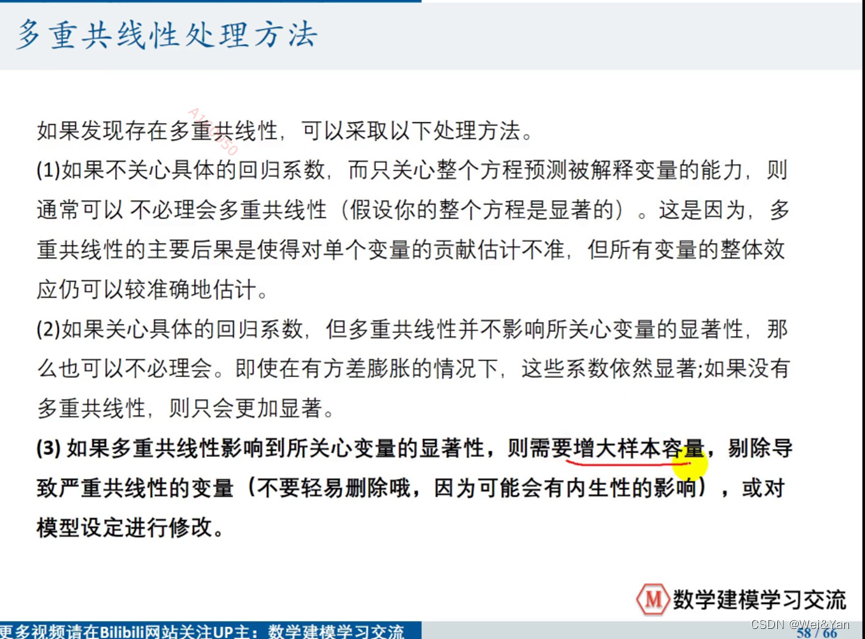
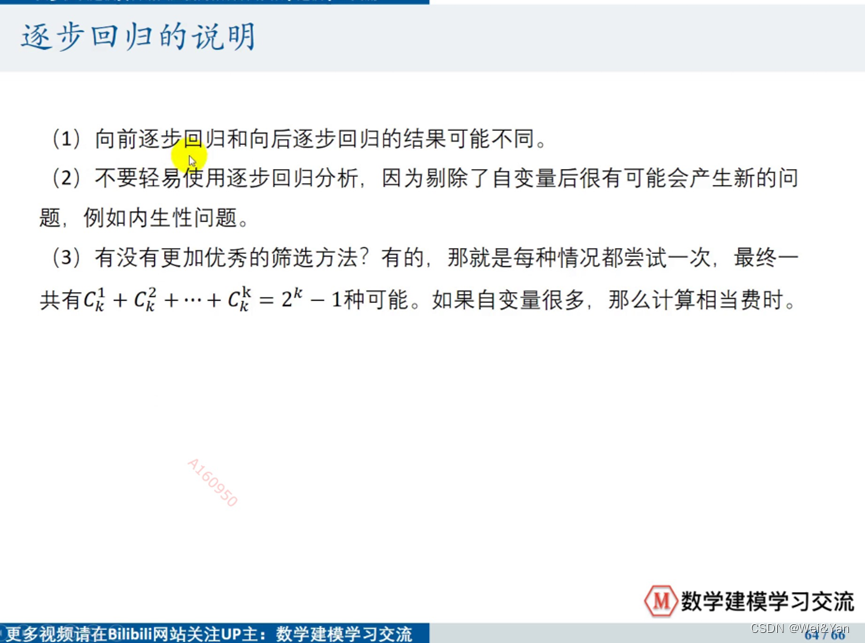
逐步回归分析
Stata中的逐步回归分析的实现:


完全多重共线性的错误: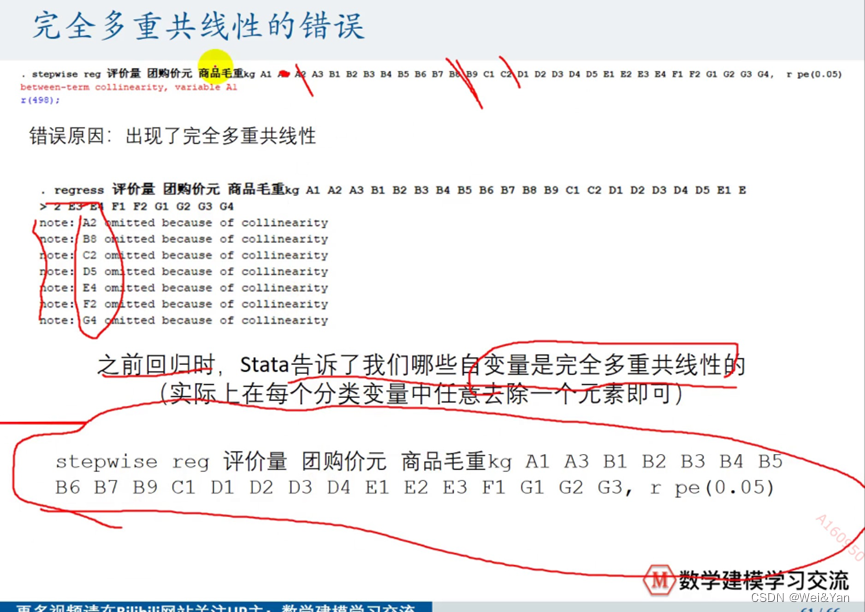
更新:
Lasso回归
由于数据中的一些自变量会导致模型出现共线性,所以利用Losso回归将一些不重要的自变量剔除掉。
Losso回归的实现我们利用stata操作:
我们拿棉花产量估计作为案例
对于自变量量纲不同,需要标准化。
Stata中将数据标准化的函数为:egen 重命名 = 需要标准化的自变量。(本案例的量纲相同,只是举如何标准化例子)
如何用stata进行lasso回归呢?
最后stata会生成一个数据表,和一个表格。
数据表解析:
数据表中带*的表示λmin,MSPEmin。即我们最小调参数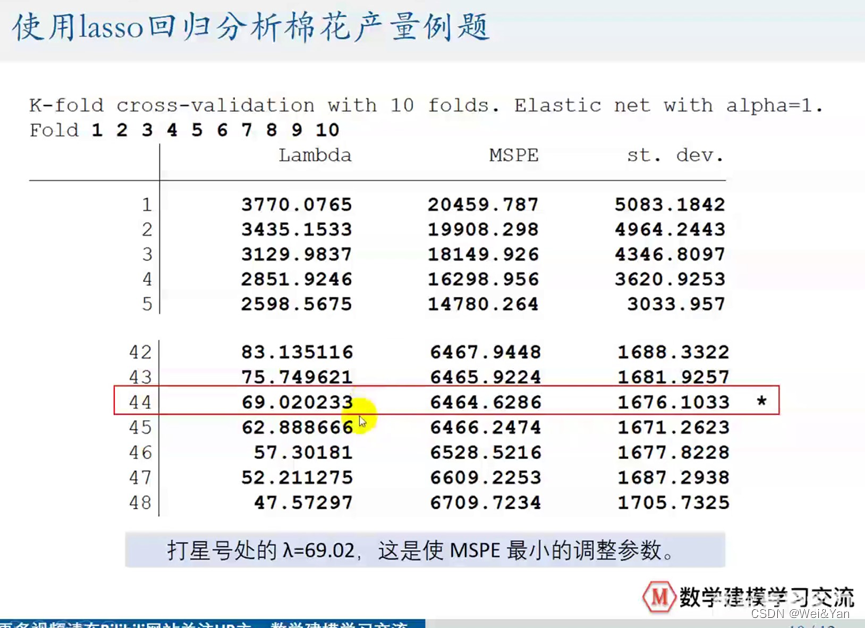
表格分析:
Selected表示核心自变量
Lasso表示Lasso估计的x系数与估计值。
Past-est OLS:标准多元线性回归的x系数与估计值。
Lasso只帮助我们剔除可能会产生多重共线性的自变量xi,在生成多元线性回归模型时我们仍选择标准多元回归模型的参数。
注意:seed后随意数的不同,核心变量也会相对发生改变。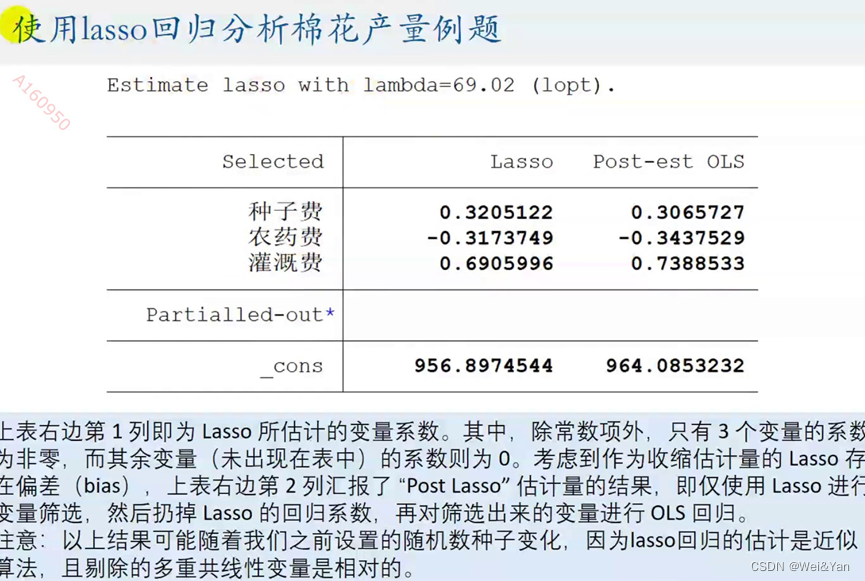
Lasso回归使用:帮助我们在对数据建立多元线性回归模型时筛选出不重要的变量。
步骤:1.判断自变量量纲是否一样,若不一样需要标准化预处理
2.对变量使用lasso回归,系数不为0的变量即要留下的重要变量。