目录
- 1. 需求分析
- 1.1 介绍一些核心概念
- 核心概念1
- 核心概念2
- 1.2 消息队列服务器(Broker Server)要提供的核心 API
- 1.3 交换机类型
- 1.3.1 类型介绍
- 1.3.2 转发规则:
- 1.4 持久化
- 1.5 关于网络通信
- 1.5.1 客户端与服务器提供的对应方法
- 1.5.2 客户端额外需要提供的方法
- 1.6 消息应答模式
- 1.7 需求分析小结
- 2. 系统设计 - 模块设计
- 3. 代码实现
- 3.1 创建项目
- 3.2 项目结构
- 3.3 Exchange 类
- 3.4 MSGQueue 类
- 3.5 Binding 类
- 3.6 Message 类
- 4. 数据库
- 4.1 依赖引入与配置文件
- 4.2 建库建表
- 4.2.1 exchange 表
- 4.2.2 MSGQueue 表
- 4.2.3 Binding 表
- 4.2.4 arguments 的转换
- 4.3 插入、查找和删除
- 4.4 DatabaseManager
- 4.4.1 初始化
- 4.4.2 其他数据库操作
- 5. 消息持久化
- 5.1 整体分析
- 5.2 代码实现
- 5.2.1 消息统计文件的读写
- 5.2.2 创建消息目录和文件
- 5.2.3 删除消息目录和文件
- 5.2.4 实现消息序列化
- 5.2.5 把消息写进文件
- 5.2.6 删除消息
- 5.3 加载文件中的所有消息
- 5.4 实现消息文件垃圾回收
- 6. 统一硬盘操作
- 7. 内存数据管理
- 7.1 设计数据结构
- 7.2 实现交换机和队列的管理
- 7.3 实现绑定的管理
- 7.4 实现消息的管理
- 7.5 实现待确认消息的管理
- 7.6 实现数据从硬盘上恢复
- 8. 虚拟主机设计
- 8.1 需求回顾
- 8.2 创建 VirtualHost 类
- 8.3 实现 exchangeDeclare 和 exchangeDelete
- 8.4 实现 queueDeclare 和 queueDelete
- 8.5 实现 queueBind 和 queueUnbind
- 8.6 实现 basicPublish
- 8.7 转发规则的实现
- 8.7.1 知识回顾及补充
- 8.7.2 检查 bindingKey 和 routingKey 合法性
- 8.7.3 实现 route 方法 和 routeTopic
- 8.8 实现 basicConsume
- 8.9 实现 basicAck
- 9. 网络通信设计
- 9.1 定义应用层协议
- 补充:序列化相关
- java 标准库提供的针对二进制序列化的方案:
1. 需求分析
1.1 介绍一些核心概念
核心概念1
- 生产者(Producer):生产者负责生成数据并将其放入缓冲区(队列)中。生产者可以是一个线程或多个线程,它们可以并行地生成数据。当缓冲区(队列)已满时,生产者需要等待,直到有空间可用。
- 消费者(Consumer):消费者负责从缓冲区(队列)中取出数据并进行处理。消费者也可以是一个线程或多个线程,它们可以并行地处理数据。当缓冲区(队列)为空时,消费者需要等待,直到有数据可用。
- 中间人(Broker):就是上述的 缓冲区(队列),除了队列也可以用其他数据结构,我们这里采用队列。
- 发布(Publish):生产者将生成数据并将其放入缓冲区(队列)中的过程就叫做发布。
- 订阅(Subscribe):消费者通过与中间人进行注册,可以获取他们感兴趣的数据,这个注册过程称为“订阅”。
- 消费(Consume):消费者从中间人这里取数据的动作。
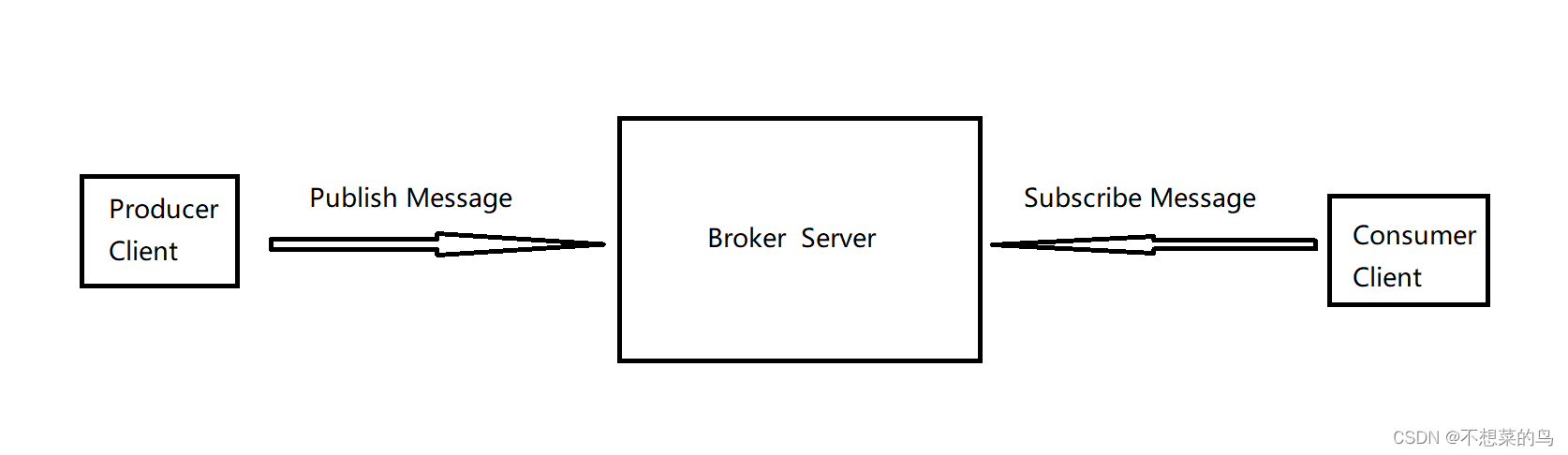
这里的生产者和消费者都可以是很多个(最常见的就是多个生产者多个消费者)。这里的服务器值得是服务器上跑的服务器程序(一个/一种具体的程序)
核心概念2
Broker Server 内部也涉及到一些关键概念
- 虚拟主机(Virtual Host),指在消息队列系统中创建的逻辑实体,用于隔离和管理不同的消息队列,每个虚拟主机可以独立运行自己的服务,Broker Server 会根据用户的需求和配置,将请求转发到相应的虚拟主机上,从而实现多个网站或应用程序在同一台服务器上运行的效果。这种方式可以提高服务器的利用率,降低成本,并且使不同的用户可以共享同一台服务器的资源。
简单来说就类似于 MySQL 中的 database,算是一个“逻辑”上的数据集合。一个 Broker Server 中可以组织多中不同类别的数据,这些不同类别的数据就可以在使用 虚拟主机 做出逻辑上的区分。 - 交换机(Exchange):生产者把消息投递给 Broker Server,实际上实现先把消息交给了 Broker Server 上的某个交换机,再由交换机把消息转发给对应的队列。
- 队列(Queue):正在用来存储处理消息的实体。我们可以认为,一个大的消息队列中,可以有很多具体的小的队列。
- 绑定(Binding):把交换机和队列之间,建立起联系。可以把交换机和队列的关系,视为数据库中的“多对多”这样的关系。一个交换机可以对应到多个队列,一个队列也可以被对个交换机对应。在数据库中,为了表示这种多对多的关系,会使用一个中间表/关联表。我们可以想象,在 mq 中,也存在这样的中间表,那么所谓的“绑定”其实就是中间表中的一项。
- 消息(Message):具体来说,可以认为是服务器 A 给服务器 B 发的请求(通过 MQ 转发),就是一个消息;同理,服务器 B 给服务器 A 返回的响应(通过 MQ 转发),也是一个消息。消息中具体包含什么信息,都是程序员自定义的(根据需求)。
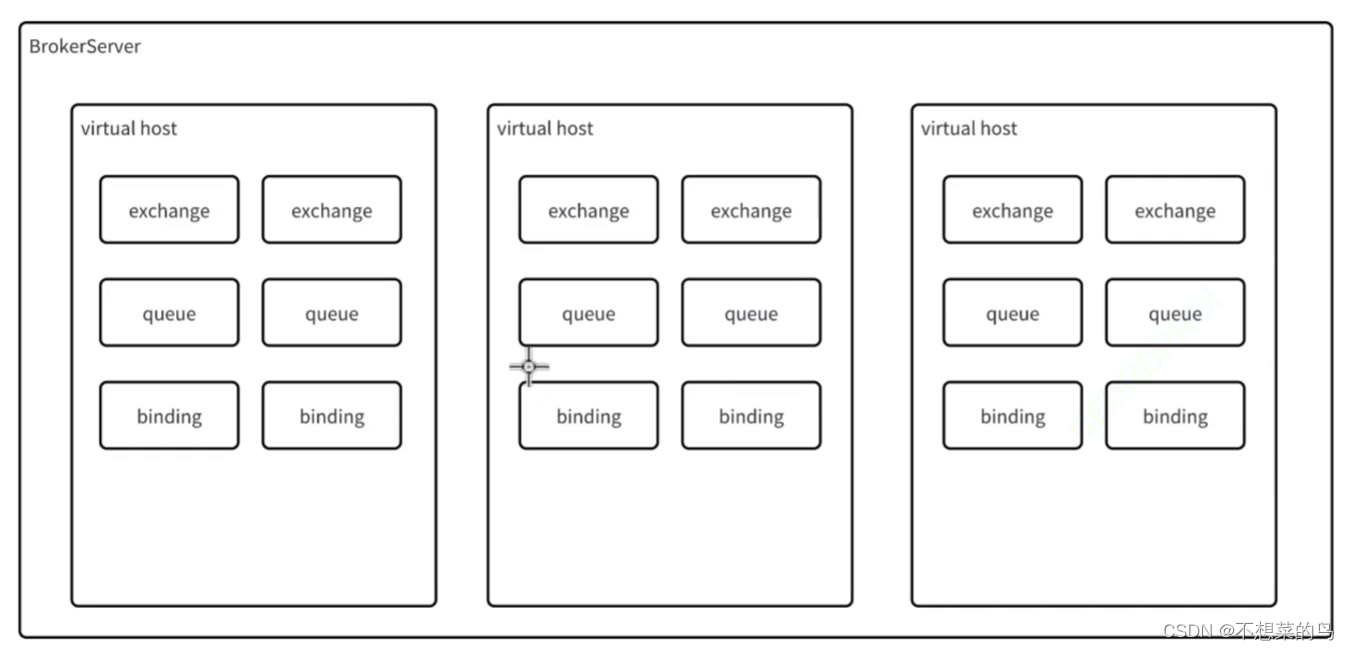
RabbitMQ 就是按照上述概念来组织的。
1.2 消息队列服务器(Broker Server)要提供的核心 API
- 创建队列(queueDeclare):此处不使用 Create 而是使用 Declare 是有原因的。Create 就只是单纯的“创建”,而 Declare 起到的效果是不存在则创建,存在就什么都不做。
- 销毁队列(queueDelete)
- 创建交换机(exchangeDeclare)
- 销毁交换机(exchangeDelete)
- 创建绑定(queueBind)
- 解除绑定(queueUnbind)
- 发布消息(basicPublish)
- 订阅消息(basicConsume)
- 确认消息(basicAck):这个 api 起到的效果是可以让消费者显式的告诉 broker server,这个消息我已经处理完毕了。这样的话可以提高整个系统的可靠性,保证消息处理没有遗漏。我们这里主要实现肯定的确认,不实现否认确认(RabbitMQ都提供了)
补充说明:我们是否要搞一个 api,叫做“消费消息”,让消费者通过这个 api 从服务器上取走消息呢?我们这个项目中不搞,因为对于 MQ 和 消费者之间的工作模式有两种
- Push(推):Broker 把收到的数据主动的发送给订阅的消费者。RabbitMQ 只支持这种模式。
- Pull(拉):消费者主动调用 Broker 的 api 取数据。
咱们的这个项目是以 RabbitMQ 作为蓝本的,上述的 API 的名称以及用法,都是参考了RabbitMQ 的。
1.3 交换机类型
1.3.1 类型介绍
交换机在转发消息的时候,会有一套转发规则,所以我们提供了几种不同的交换机类型(ExchangeType)来描述这里的不同的转发规则。
RabbitMQ 主要实现了四种交换机类型(AMQP 协议定义的):
- Direct 直接交换机
- Fanout 扇出交换机
- Topic 主题交换机
- Header 消息头交换机:这种交换机规则复杂并且应用场景比较少。
我们这个项目主要实现前三种交换机。
1.3.2 转发规则:
-
Direct 直接交换机:生产者发送消息的时候,会指定一个“目标队列”的名字。交换机收到消息之后,就会查看绑定的队列里,有没有匹配的队列,如果有,就转发过去(把消息塞进对应的队列中),如果没有,消息直接丢弃。
-
Fanout 扇出交换机:交换机会把收到的消息转发给每一个队列。
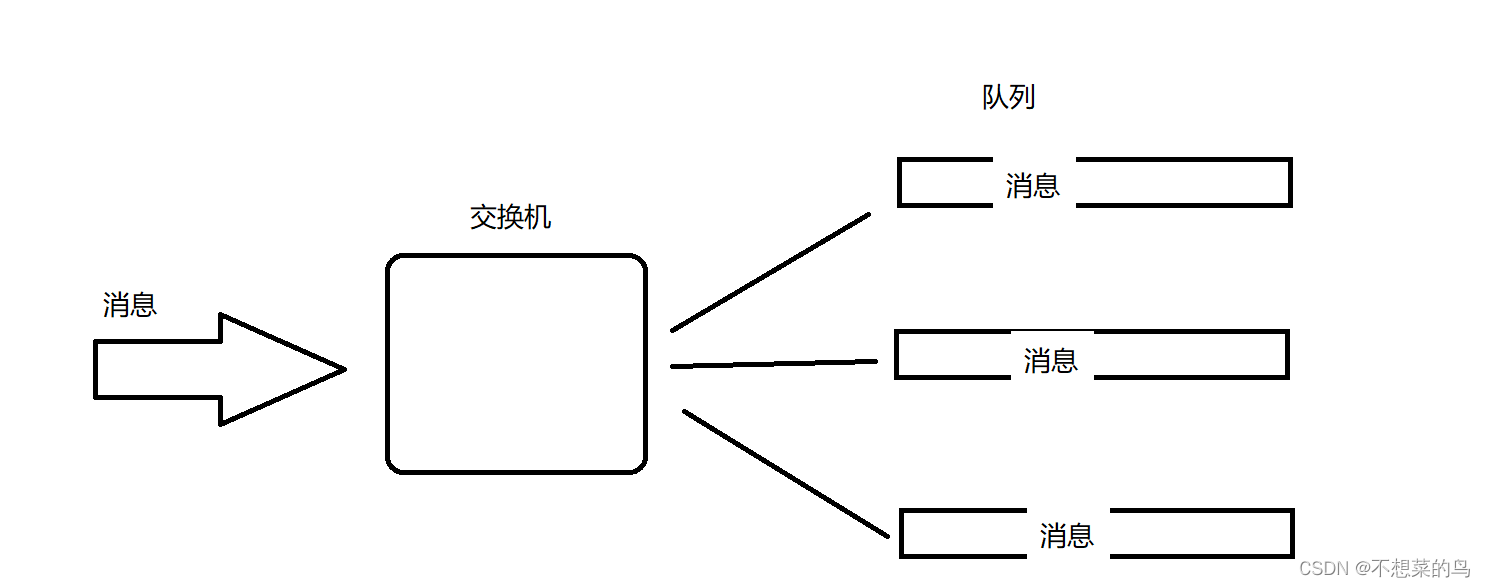
-
Topic 主题交换机:
有两个关键概念:
1)bindingKey,把队列和交换机绑定的时候,指定一个单词(像是一个暗号一样)
2)routingKey,生产者发送消息的时候,也指定一个单词
如果当前的 routingKey 和 bindingKey 能够对上暗号,此时就可以把这个消息转发到相应的队列中了。
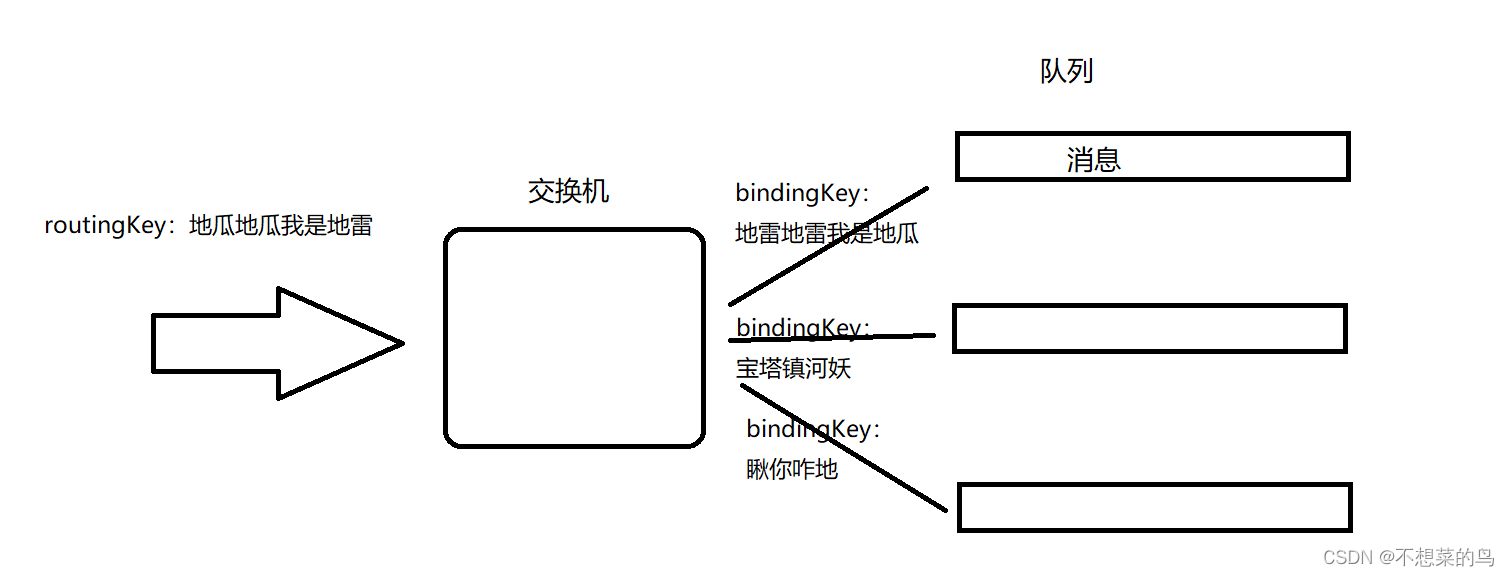
此时的消息只会转发给最上面的队列。
这里的 routingKey 和 bindingKey 怎样算是对得上暗号,这个具体规则我们后面再细说。
上述的三种交换机类型,就像 QQ 群发红包一样,假设我会魔法:
- 专属红包,我发的时候,必须指定某个人能领 => 直接交换机
- 我发 20 块钱红包,然后我开始施展魔法(很刑),群里的每个群友都能领到 20 块钱 => 扇出交换机
- 画图红包,我发 20 块钱红包,同时出个题,画一个苹果,只有花的好,画的像才能领,也就是说画的画和我出的题目得匹配得上才行。(还需要搭配我的魔法,领到红包的钱也都是 20 快钱) => 主题交换机
1.4 持久化

上图这些概念对应的数据都需要存储和管理起来。我们内存和硬盘上都会存一份,以内存为主硬盘为辅。
在内存中存储的原因:
对于 MQ 来说,能够高效的转发处理数据,是非常关键的指标,因此使用内存来组织上述数据,效率就会比硬盘上要高很多。
在硬盘上存储的原因:
为了防止内存中的数据随着进程重启/主机重启而丢失。
我们把数据存在硬盘上就叫做持久化。
1.5 关于网络通信
1.5.1 客户端与服务器提供的对应方法
其他的服务器(生产者/消费者)通过网络与我们的 Broker Server 进行交互的。此处我们设定,使用 TCP + 自定义的应用层协议,实现生产者/消费者 和 Broker Server 之间的交互工作。
这里的自定义的应用层协议做的主要工作,就是让客户端可以通过网络,调用 broker server 提供的编程接口:

因此,在客户端这一侧,也需要提供对应的上述的这些方法,只不过服务器端的上述方法,效果是真正干实事的,把管理数据吧进行调整。客户端这边的上述方法,则只是发送请求/接收响应。
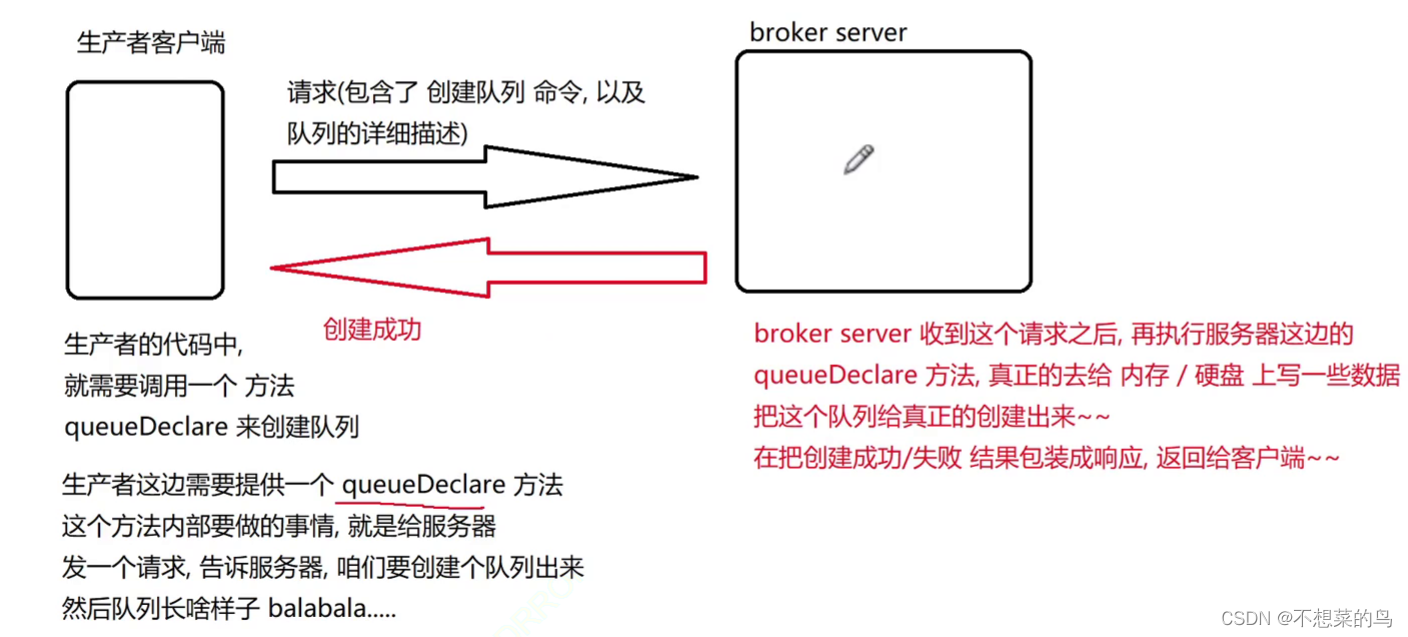
当响应回来了,客户端的 queueDeclare 就会获取到这个响应,看到说创建队列成功,此时 queueDeclare 就算执行完毕了。
此处,客户端调用了一个本地方法,结果这个方法在背后,给服务器发了一些列消息,由服务器完成了一系列的工作。站在调用者的角度来说,只知道这个功能已经完成,并不知道这背后的细节。
虽然调用的是一个本地方法,实际上就好像调用了一个远端服务器的方法一样 => 远程过程调用(RPC)。远程过程调用(RPC)是一种通信机制,可以视为是编写客户端服务器程序,通信过程的一种设计思想。
1.5.2 客户端额外需要提供的方法
客户端除了提供上述的 9 个和服务器这边对应的方法外,还需要再提供四个方法,支撑其他工作。
- 创建 Connection
- 关闭 Connection
- 创建 Channel
- 关闭 Channel
说明:
Connection:一个 Connection 对象,就代表一个 TCP 连接。
Channel:通道/信道。
一个 Connection 里面可以包含多个 Channel,每个 Channel 上面传输的数据都是互不相干的。
TCP 中建立/断开一个连接,成本还挺高的,因此很多时候,并不希望频繁的建立断开 TCP 连接。所以我们才去的策略是,TCP 连接上去之后,我们不着急断开,如果想进行通信,我们就在 TCP 的这个链接里面创建一个 Channel,通过 Channel 传输数据进行通信,如果暂时不用通信,那我们就把这个 Channel 销毁就行,TCP 连接本身不变,如果后续还想和服务器通信,那就再创建一个 Channel 就行。这里的 Channel 只是逻辑上的一个概念,它的创建和销毁比 TCP 连接的简历和断开要轻量很多。
举个例子:
假设我要去医院挂水,我需要挂三种药水,对应着三瓶药,我不用三个管接三根针来打,只需要一根管一根针即可,因为打完一瓶药水,可以从上面把空瓶拿走换成下一瓶药。这里的这一根管一根针就相当于 Connection,三瓶药水就相当于 Channel。
1.6 消息应答模式
- 自动应答:消费者把消息取走了,就算是应答了,其实就相当于没应答,即使消费者在处理消息时发生错误,消息也不会重新发送。自动应答适用于那些不需要保证消息可靠性的场景。
- 手动应答:basicAck 方法属于手动应答,消费者需要主动调用这个 api 来进行应答。。只有当消费者明确地发送确认消息给消息队列后,消息队列才会将该消息标记为已处理,并从队列中删除。如果消费者在处理消息时发生错误,可以选择不发送确认消息,这样消息队列会将消息重新发送给其他消费者进行处理。手动应答适用于那些需要保证消息可靠性的场景。
自动应答可以提高消息处理的效率,但可能会导致消息丢失。手动应答可以确保消息的可靠性,但会增加消息处理的复杂性和延迟。因此,在设计消息队列系统时,需要根据业务需求权衡选择合适的应答机制。我们这个项目也需要对这两种情况作出支持。
1.7 需求分析小结



上述要做的这些工作的最终目标,就是实现一个“分布式系统下”这样的生产者消费者模型。但是在当前情况下,咱们的 broker server 并不支持分布式部署(集群功能),只是一个单级的 broker server,但是能够给多个生产者消费者提供服务。
2. 系统设计 - 模块设计
3. 代码实现
3.1 创建项目
创建一个 Spring Boot 项目,这个如果不会的话可以看看这篇文章:http://t.csdn.cn/3LTDY
我们这里就不演示如何创建项目了。
罅隙队列中存在下列比较核心的概念:
- 交换机 exchange
- 队列 queue
- 绑定 binding
- 消息 message
这些都是在 broker server 中实现的
所以我们要首当其冲的将这几个概念能够在代码中表示出来。
3.2 项目结构
3.3 Exchange 类
这个类表示一个交换机
@Data
public class Exchange {// 此处使用 name 来作为交换机的身份标识。(唯一的)private String name;// 交换机类型,DIRECT FANOUT TOPICprivate ExchangeType type = ExchangeType.DIRECT;// 该交换机是否要持久化存储,true 表示需要, false 表示不需要private boolean durable = false;// 如果当前交换机没人使用了,就会自动删除// 这个属性暂时放在这里,在后续的代码中并没有真的实现这个自动删除功能,属于锦上添花private boolean autoDelete = false;// arguments 表示的是创建交换机时指定一些额外的参数选项,后续代码也是没有真正实现。private Map<String, Object> arguments = new HashMap<>();
}
枚举类,表示交换机的类型
public enum ExchangeType {DIRECT(0),FANOUT(1),TOPIC(2);private final int type;private ExchangeType(int type) {this.type = type;}public int getType(){return type;}}
3.4 MSGQueue 类
这个类表示一个存储消息的队列
@Data
public class MSGQueue {// 表示队列的身份标识private String name;// 标识队列是否持久化private boolean durable = false;// 这个属性如果为 true,表示这个队列只能被一个消费者使用// 这个 独占 功能,也是先列出来,但是后续我们并不实现private boolean exclusive = false;// 如果当前交换机没人使用了,就会自动删除private boolean autoDelete = false;// arguments 表示扩展参数,后续代码也是没有真正实现。private Map<String, Object> arguments = new HashMap<>();
}
3.5 Binding 类
表示队列与交换机之间的关系
@Data
public class Binding {private String exchangeName;private String queueName;// 这个就相当于文章中介绍的QQ画图红包的出题private String bindingKey;
}
3.6 Message 类
表示一个要传递的消息
一个 Message 主要包含两个部分:
- 属性部分 BasicProperties
- 正文部分 byte[] (正文是支持二进制数据的)
@Data
public class BasicProperties implements Serializable {// 消息的唯一身份标识,此处为了保证 id 的唯一性,使用 UUIDprivate String messageId;// 是一个消息上带有的内容,和 bindingKey 做匹配 (交换机类型为 TOPIC)// 如果当前的交换机类型是 DIRECT,此时 routingKey 就表示要转发的队列名// 如果当前的交换机类型是 FANOUT,此时 routingKey 无意义(不使用)private String routingKey;// 这个属性表示消息是否要持久化。1 表示不持久化,2 表示持久化private int deliverMode = 1;// 其实针对 RabbitMQ 来说,BasicProperties 里面还有很多别的属性,但是我们这里就先不考虑了。
}
@Data
public class Message implements Serializable {private static final long serialVersionUID = 1L;// 这两个属性是 Message 最核心的部分private BasicProperties basicProperties = new BasicProperties();private byte[] body;// 下面的属性则是辅助用的属性// Message 后续会存储到文件中(如果持久化的话)// 一个文件中会存储很多的消息,如何找到某个消息在文件中的具体位置呢?// 使用下列的两个偏移量来进行表示。[offsetBeg, offsetEnd)// 这俩属性并不需要被序列化保存到文件中,因为此时消息一旦被写入文件之后,所在的位置就固定了,并不需要单独存储。// 这俩属性存在的目的,主要是为了让内存中的 Message 对象,能够快速的找到对应放的硬盘中的 Message 位置private transient long offsetBeg = 0; // 消息数据的开头举例文件开头的位置偏移(字节)private transient long offsetEnd = 0; // 消息数据的结尾距离文件开头的位置偏移(字节)// 使用这个属性表示改消息在文件中是否是有效消息。(针对文件中的消息,如果删除,使用逻辑删除的方式)// 0x1 表示有效,0x0 表示无效private byte isValue = 0x1;// 创建一个工厂方法,让工厂方法帮我们封装一下创建 Message 对象的过程。// 这个方法中创建的 Message 对象,会自动生成唯一的 MessageId// 万一 routingKey 和 basicProperties 里的 routingKey 冲突, 以外面的为主public static Message createMessageWithId(String routingKey, BasicProperties basicProperties, byte[] body) {Message message = new Message();if (basicProperties != null) {message.setBasicProperties(basicProperties);}// 此处生成的 MessageId 以 M- 作为前缀。message.setMessageId("M-" + UUID.randomUUID().toString());message.setRoutingKey(routingKey);message.setBody(body);// 此处是把 body 和 basicProperties 先设置出来,这俩是 Message 的核心内容// 而 offsetBeg offsetEnd isValue 是消息持久化的时候才会用到。在把消息写入文件之前再进行设置// 此处只是在内存中创建一个 Message 对象return message;}public String getMessageId() {return basicProperties.getMessageId();}public void setMessageId(String messageId) {basicProperties.setMessageId(messageId);}public String getRoutingKey() {return basicProperties.getRoutingKey();}public void setRoutingKey(String routingKey) {basicProperties.setRoutingKey(routingKey);}public int getDeliverMode() {return basicProperties.getDeliverMode();}public void setDeliverMode(int mode) {basicProperties.setDeliverMode(mode);}}
4. 数据库
4.1 依赖引入与配置文件
根据前面的约定我们知道,我们把交换机、队列、绑定的信息放在数据库中,把消息放在文件中。但是由于 MySQL 本身比较重量,我们为了方便,简化环境,采取更轻量的 SLQite。
我们直接使用 maven,引入依赖即可使用 SQLite。
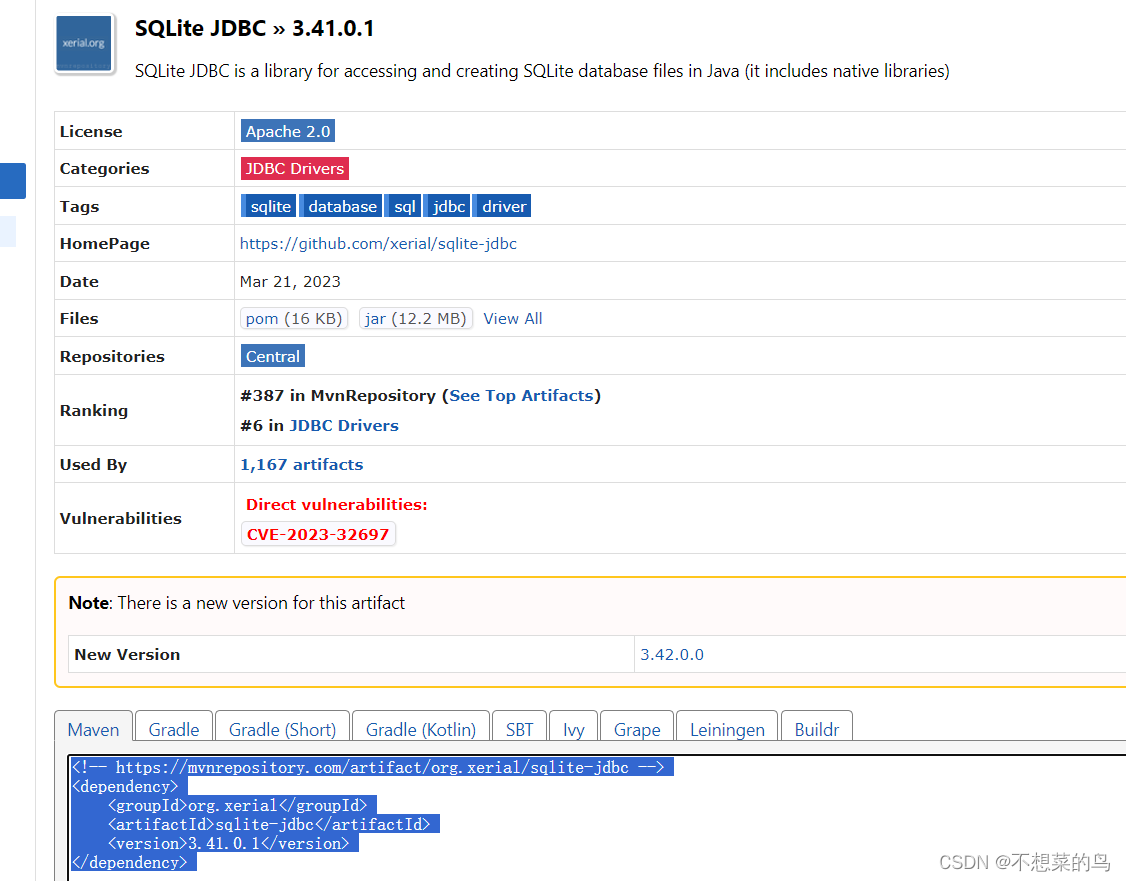
将依赖粘贴到我们的项目中即可。
此时引入依赖之后,我们还需要配置一下配置文件即 application.yml 或者 application.properties,我们使用 yml 的。
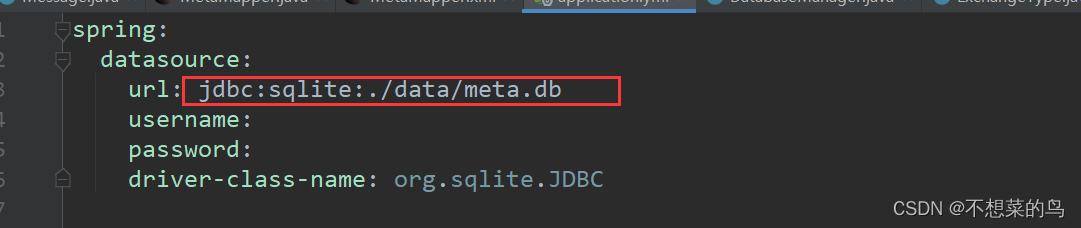
spring:datasource:url: jdbc:sqlite:./data/meta.dbusername:password:driver-class-name: org.sqlite.JDBC

SQLite 数据库是吧数据存储在当前硬盘的某个指定的文件中,我们这里是 ./ ,说明是相对路径。谈到相对路径,要明确“基准路径”“工作路径”,如果实在 IDEA 中直接运行程序,此时的工作路径就是当前项目所在的路径。如果是通过 java -jar 方式运行程序,此时我们在哪个目录下执行的命令,哪个目录就是 工作路径。

对于 SQLite 来说,并不需要指定用户名和密码。因为 SQLite 不是客户端服务器结构的程序,就只有自己一个人访问,把数据放在本地文件上,和网络无关,就只有本地主机才能访问。
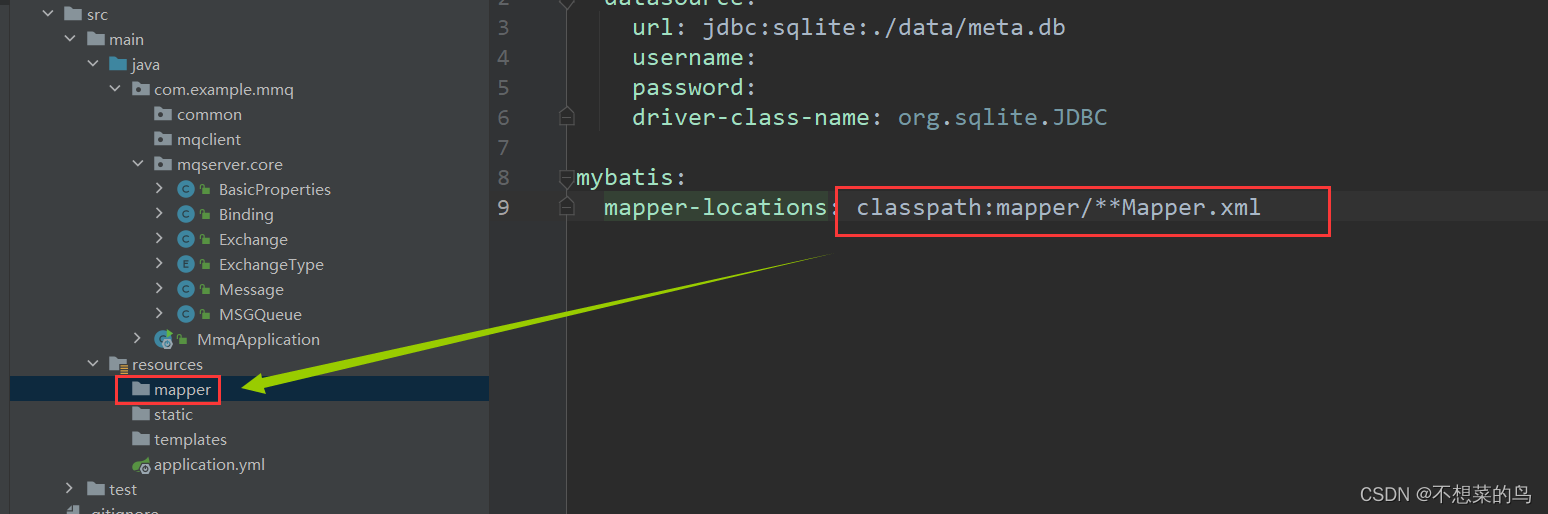
我们也可以使用 MyBatis 来操作数据库以达到事半功倍的效果,下面我们就来配置一下 MyBatis:
mybatis:mapper-locations: classpath:mapper/**Mapper.xml
4.2 建库建表
当我们把上述的配置和依赖都准备好了以后,程序启动聚会自动建库。我们只需要考虑建表,此时我们就要考虑如何设计表:
我们根据之前对项目的设计就可以知道,主要就是简历上图中的三张表,根据之前代码中设计好的核心类,很容易把这几个表设计出来。然后我们就需要分析一下这个建表操作的具体执行时机,可能有人写程序最常见的操作就是先把数据库的表创建好,然后在启动服务器,需要建表的时候,就写 SQL 语句,到 MySQL 客户端中执行就行,这些操作都是在部署阶段完成的,只部署一次即可,但是很多程序可能会涉及到反复部署多次,所以我们期望通过代码,自动完成建表操作。
此时我们还是通过 MyBatis 来实现,创建表用 update 标签就行:
4.2.1 exchange 表
<update id="createExchangeTable">create table if not exists exchange(name varchar(50) primary key ,type int,durable boolean,autoDelete boolean,arguments varchar(1024));
</update>
@Mapper
public interface MetaMapper {// 提供三个核心的建表方法void createExchangeTable();void createQueueTable();void createBindingTable();
}
需要注意的是,arguments 在核心类中的属性是这样的:

我们需要把它转化成 json 格式的字符串才能存到数据库的表中,所以我们使用 varchar(1024)。
4.2.2 MSGQueue 表
<update id="createQueueTable">create table if not exists queue (name varchar(50) primary key ,durable boolean,exclusive boolean,autoDelete boolean,arguments varchar(1024));</update>
4.2.3 Binding 表
<update id="createBindingTable">create table if not exists binding (exchangeName varchar(50),queueName varchar(50),bindingKey varchar(256));
</update>
当前我们这三张表的建表语句就写好了。我们可以发现,我们是把每个建表语句都单独的用一个 update 标签来实现,并且对应一个 java 方法,能否改成使用一个 update 标签就包含多个建表语句,同时借助一个 java 方法,完成上述多个表的创建呢?首先 MyBatis 是支持一个标签中包含多个 SQL 语句的,但是前提是搭配 MySQL 或者 Oracle,对于 SQLite 来说是无法做到的。如果在一个 update 标签中写了多个 SQL 语句,只有第一个生效,所以我们暂时无法做到只用一个标签实现,如果读者中有人有办法实现,也可以留言教一教博主。
4.2.4 arguments 的转换
思路:
为了实现 arguments 这个键值对和数据库中的字符串类型相互转换的关键要点,在于 MyBatis 在完成数据库操作的时候,会自动地调用到对象的 getter 和 setter 方法,也就是我们使用 @Data 注解里自动生成的方法:
- 比如 MyBatis 在往数据库中写数据,就会调用对象的 getter 方法,得到属性的值,再往数据库中写。如果这个过程中,让 arguments 得到的结果是 String 类型的,此时,就可以直接把这个数据写到数据库中了。
- MyBatis 从数据库读数据的时候,就会调用对象的 setter 方法,将数据库中读到的数据结果设置到对象的属性中。如果这个过程中,让 setArguments 参数是一个 String,并且在 setArguments 内部针对字符串解析,解析成一个 Map 对象,此时也就完成了对 arguments 这个属性的设置了。
代码实现:
@Data
public class MSGQueue {// 表示队列的身份标识private String name;// 标识队列是否持久化private boolean durable = false;// 这个属性如果为 true,表示这个队列只能被一个消费者使用// 这个 独占 功能,也是先列出来,但是后续我们并不实现private boolean exclusive = false;// 如果当前交换机没人使用了,就会自动删除private boolean autoDelete = false;// arguments 表示扩展参数,后续代码也是没有真正实现。private Map<String, Object> arguments = new HashMap<>();public String getArguments(){ObjectMapper objectMapper = new ObjectMapper();try {return objectMapper.writeValueAsString(arguments);} catch (JsonProcessingException e) {e.printStackTrace();}return "{}";}public void setArguments(String argumentsJson) {ObjectMapper objectMapper = new ObjectMapper();try {this.arguments = objectMapper.readValue(argumentsJson, new TypeReference<HashMap<String,Object>>() {});} catch (JsonProcessingException e) {e.printStackTrace();}}
}
@Data
public class Exchange {// 此处使用 name 来作为交换机的身份标识。(唯一的)private String name;// 交换机类型,DIRECT FANOUT TOPICprivate ExchangeType type = ExchangeType.DIRECT;// 该交换机是否要持久化存储,true 表示需要, false 表示不需要private boolean durable = false;// 如果当前交换机没人使用了,就会自动删除// 这个属性暂时放在这里,在后续的代码中并没有真的实现这个自动删除功能,属于锦上添花private boolean autoDelete = false;// arguments 表示的是创建交换机时指定一些额外的参数选项,后续代码也是没有真正实现。// 为了把这个 arguments 存到数据库中,需要把 Map 转成 json 格式的字符串private Map<String, Object> arguments = new HashMap<>();public String getArguments(){// 是把当前的 arguments 参数,从 Map 转成 String(json)ObjectMapper objectMapper = new ObjectMapper();try {return objectMapper.writeValueAsString(arguments);} catch (JsonProcessingException e) {e.printStackTrace();}// 如果真的发生异常,就返回空的 json 字符串return "{}";}// 这个方法,是从数据库读数据之后,构造 Exchange 对象,会自动调用到public void setArguments(String argumentsJson) {ObjectMapper objectMapper = new ObjectMapper();// 把参数中的 argumentsJson 按照 json 格式解析// 转成上述的 Map 对象try {this.arguments = objectMapper.readValue(argumentsJson, new TypeReference<HashMap<String,Object>>() {});} catch (JsonProcessingException e) {e.printStackTrace();}}}
4.3 插入、查找和删除
@Mapper
public interface MetaMapper {// 提供三个核心的建表方法void createExchangeTable();void createQueueTable();void createBindingTable();// 新增、查找和删除void insertExchange(Exchange exchange);List<Exchange> selectAllExchange();void deleteExchange(String exchangeName);void insertQueue(MSGQueue queue);List<MSGQueue> selectAllQueue();void deleteQueue(String queueName);void insertBinding(Binding binding);List<Binding> selectAllBinding();void deleteBinding(Binding binding);
}
<insert id="insertExchange">insert into exchange values (#{name},#{type},#{durable},#{autoDelete},#{arguments});</insert><select id="selectAllExchange" resultType="com.example.mmq.mqserver.core.Exchange">select * from exchange;</select><delete id="deleteExchange">delete from exchange where name = #{exchangeName};</delete><insert id="insertQueue">insert into queue values (#{name},#{durable},#{exclusive},#{autoDelete},#{arguments});</insert><select id="selectAllQueue" resultType="com.example.mmq.mqserver.core.MSGQueue">select * from queue;</select><delete id="deleteQueue">delete from queue where name = #{queueName};</delete><insert id="insertBinding">insert into binding values (#{exchangeName}, #{queueName}, #{bindingKey});</insert><select id="selectAllBinding" resultType="com.example.mmq.mqserver.core.Binding">select * from binding;</select><delete id="deleteBinding">delete from binding where exchangeName=#{exchangeName} and queueName=#{queueName};</delete>
4.4 DatabaseManager
我们创建一个 DatabaseMananger 类来整合上述的数据库操作
4.4.1 初始化
我们使用 init 方法来进行数据库的初始化,我们期望的效果:
- 如果数据库已经存在了,不做任何操作
- 如果数据库不存在,就创建数据库,创建表,构造默认数据
我们通过 meta.db 这个文件是否存在来判定数据库是否存在,别忘了我们之前对数据库的配置:
public void init() {if (!checkDBExists()) {// 先创建 data 目录File dataDir = new File("./data");dataDir.mkdirs();createTable();createDefaultData();System.out.println("[DatabaseManager] 数据库初始化完成!");} else {System.out.println("[DatabaseManager] 数据库已经存在!");}}private boolean checkDBExists() {File file = new File("./data/meta.db");if (file.exists()) {return true;} else {return false;}}private void createTable() {metaMapper.createExchangeTable();metaMapper.createQueueTable();metaMapper.createBindingTable();System.out.println("[DatabaseManager] 创建表完成!");}/*** 此处要添加的默认数据主要是添加一个默认的交换机* RabbitMQ 有一个这样的设定:带有一个匿名的交换机,类型是 DIRECT*/private void createDefaultData() {Exchange exchange = new Exchange();exchange.setName("");exchange.setType(ExchangeType.DIRECT);exchange.setDurable(true);exchange.setAutoDelete(false);metaMapper.insertExchange(exchange);System.out.println("[DatabaseManager] 创建初始数据完成!");}
此时我们就完成了对数据库初始化的方法编写,但是还存在一个 bug,就是 metaMapper 现在还是空的,用到其方法势必会报空指针异常,所以我们需要先把 metaMapper 对象初始化出来:
我们找到启动类,在里面添加一个静态属性:
public static ConfigurableApplicationContext context;
这个启动类里的 run 方法的返回值就是一个 ConfigurableApplicationContext 对象,我们可以打开源码看看:

所以我们直接用上述的 context 来接收 run 方法即可:
@SpringBootApplication
public class MmqApplication {public static ConfigurableApplicationContext context;public static void main(String[] args) {context = SpringApplication.run(MmqApplication.class, args);}}
然后我们回到 DatabaseManager 类,在 init 方法一开始就得到 MetaMapper 对象,利用 context.getBean() 方法进行依赖查找然后注入:
metaMapper = MmqApplication.context.getBean(MetaMapper.class);
此时就解决了空指针问题。
4.4.2 其他数据库操作
我们把其他数据库操作也封装到这个类中:
public void insertExchange(Exchange exchange) {metaMapper.insertExchange(exchange);}public List<Exchange> selectAllExchanges(){return metaMapper.selectAllExchange();}public void deleteExchange(String exchangeName) {metaMapper.deleteExchange(exchangeName);}public void insertQueue(MSGQueue queue) {metaMapper.insertQueue(queue);}public List<MSGQueue> selectAllQueue(){return metaMapper.selectAllQueue();}public void deleteQueue(String queueName) {metaMapper.deleteQueue(queueName);}public void insertBinding(Binding binding) {metaMapper.insertBinding(binding);}public List<Binding> selectAllBinding(){return metaMapper.selectAllBinding();}public void deleteBinding(Binding binding) {metaMapper.deleteBinding(binding);}
5. 消息持久化
5.1 整体分析
在前面我们已经约定 Message(消息)放在文件里存储,不放在数据库中:
- 消息操作不涉及到复杂的增删改查
- 消息数量可能会非常多,数据库的访问效率并不高
下面我们设定消息如何在文件中存储:
首先我们要明确消息是依附于队列的,所以我们存储的时候就把消息按照队列的维度展开。
此处我们已经有了个 data 目录(meta.db 就在这个目录里),在 data 中创建一些子目录,每个队列都有一个子目录,子目录的名字就是队列名:

每个队列的子目录下,在分配两个文件,来存储信息:
第一个文件:queue_data.txt 这里保存消息的内容
第二个文件:queue_stat.txt 这里保存消息的统计信息
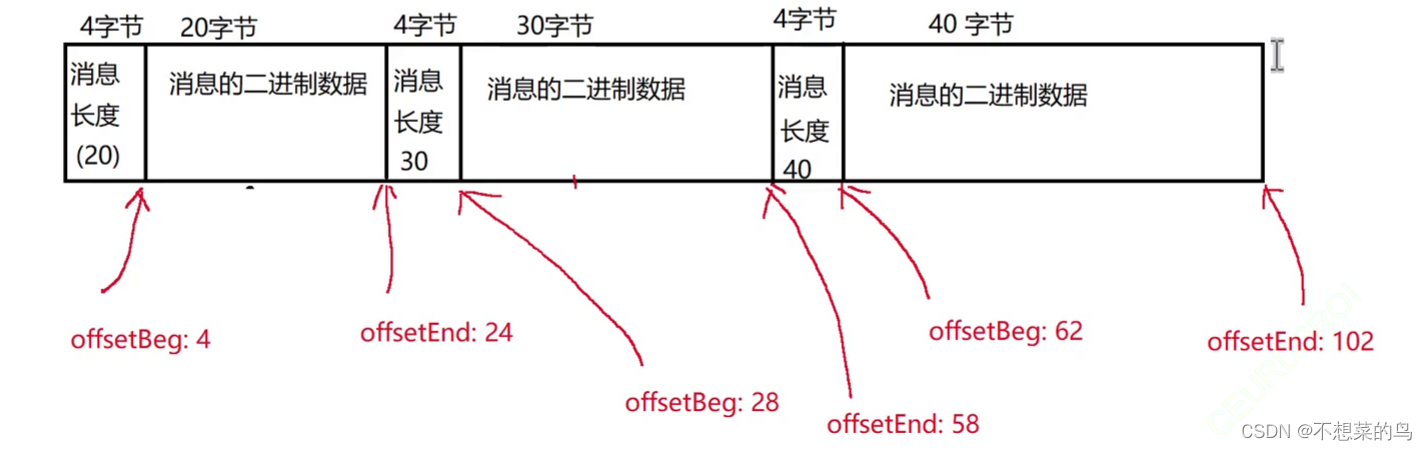
对于 queue_data 这个文件我们做出如下约定:
这个文件包含若干个消息,每个消息都以二进制的方式存储,每个消息由这几个部分构成:

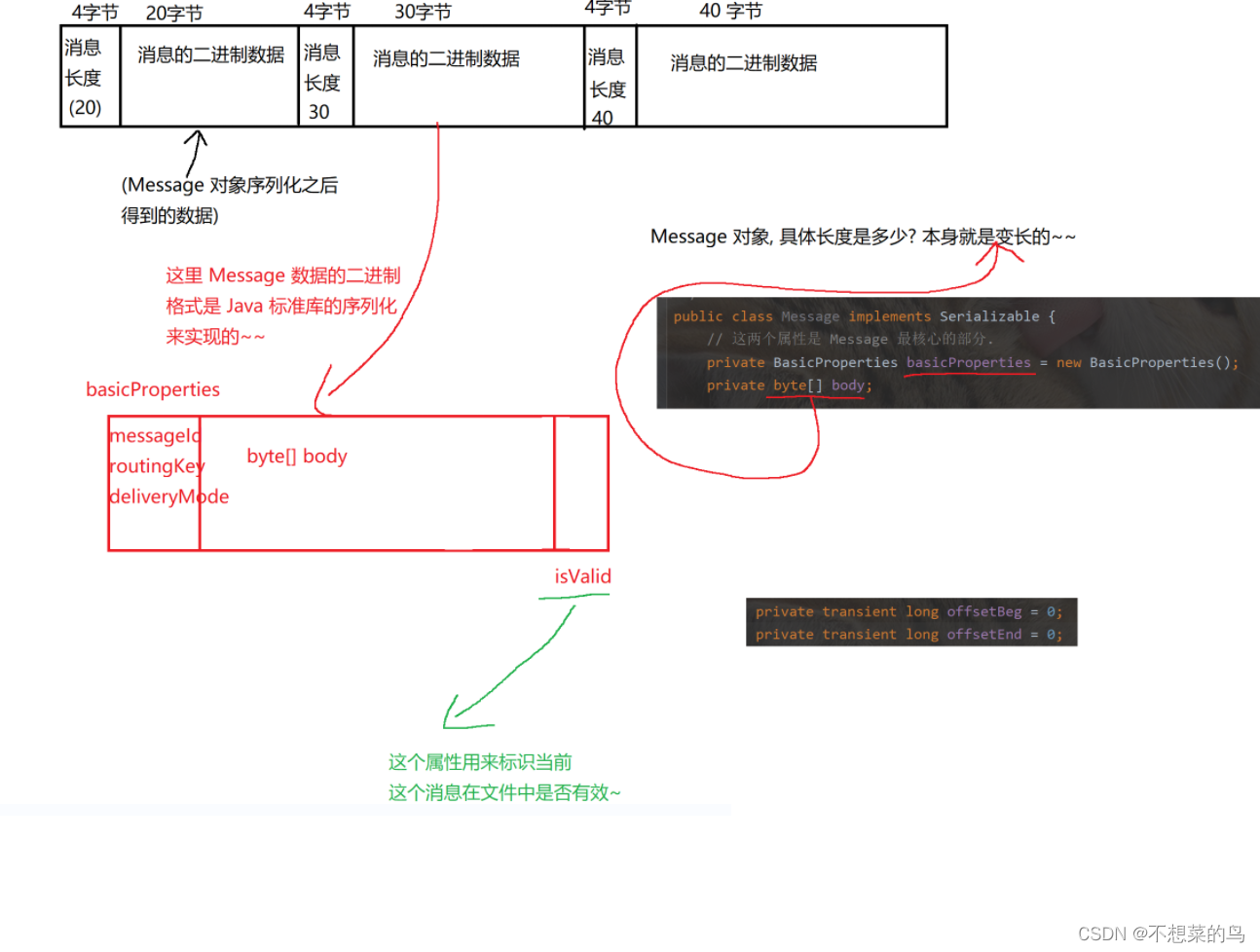
关于 queue_stat,使用这个文件来保存消息的统计信息,只存一行数据,文本格式,这一行有两列:
第一列:queue_data.txt 中总的消息的数目
第二列:queue_data.txt 中有效消息的数目
两者使用 \t 分割
形如:2000\t1500
此时我们还需要考虑到的一个点是,如果某个队列中的消息特别的多,而且都是有效消息,此时就会导致整个消息的数据文件非常大,后续针对整个文件的各种操作,陈本就会上升很多,比如有个文件大小是 10G,刺水如果触发一次 GC,整体的耗时就会非常高了。
为了解决这个事情,RabbitMQ 才去的方案是把一个大的文件,拆成若干个小的文件。
文件拆分:当单个文件长度达到一定阈值之后,就会拆分成两个文件(拆着拆着就成了很多文件)
文件合并:每个单独的文件都会进行 GC。如果 GC 之后发现文件变小了很多,就可能会和相邻的其他文件合并。
这样做就可以在消息特别多的时候,也能保证性能上的及时响应。
但是由于这一块的逻辑非常复杂,暂时我们就不实现了,我们只考虑一个文件的情况。
5.2 代码实现
我们创建 MessagerFileManager 来实现消息在文件中的存储删除等操作:
public class MessageFileManager {// 定义一个内部类来表示该队列的统计信息static public class Stat {public int totalCount; // 总消息数量public int validCount; // 有效消息数量}// 预定消息文件所在的目录和文件名// 这个方法,用来获取到指定队列对应的消息文件所在的路径private String getQueueDir(String queueName) {return "./data/" + queueName;}// 这个方法用来获取该队列的消息数据文件// 注意,二进制文件,使用 txt 作为后缀不太合适,因为 txt 一般指文本文件,但是将就着吧private String getQueueDataPath(String queueName) {return getQueueDir(queueName) + "/queue_data.txt";}// 这个方法用来获取该队列的消息统计文件路径private String getQueueStatPath(String queueName) {return getQueueDir(queueName) + "/queue_stat.txt";}}
下面还是在 MessageFileManager 这个类中进行编写
5.2.1 消息统计文件的读写
俗话说得好,柿子还得挑软的捏,消息统计文件的读写实现起来较为简单,我们就先实现这个:
private Stat readStat(String queueName) {// 由于当前的消息统计文件是文本文件,可以直接使用 Scanner 来读取文件内容Stat stat = new Stat();try (InputStream inputStream = new FileInputStream(getQueueStatPath(queueName))){Scanner scanner = new Scanner(inputStream);stat.totalCount = scanner.nextInt();stat.validCount = scanner.nextInt();return stat;} catch (IOException e) {e.printStackTrace();}return null;}private void writeStat(String queueName, Stat stat){// 使用 PrintWrite 来写文件// OutputStream 打开文件,默认情况下会直接把源文件清空,此时相当于新的文件覆盖了旧的。try (OutputStream outputStream = new FileOutputStream(getQueueStatPath(queueName))) {PrintWriter printWriter = new PrintWriter(outputStream);printWriter.write(stat.totalCount + "\t" + stat.validCount);printWriter.flush();} catch (IOException e) {e.printStackTrace();}}
5.2.2 创建消息目录和文件
public void createQueueFiles(String queueName) throws IOException {// 1. 先创建队列对应的消息目录File baseDir = new File(getQueueDir(queueName));if (!baseDir.exists()) {boolean isSuccess = baseDir.mkdirs();if (!isSuccess) {throw new IOException("创建目录失败!baseDir=" + baseDir.getAbsolutePath());}}// 2. 创建队列数据文件File queueDataFile = new File(getQueueDataPath(queueName));if (!queueDataFile.exists()) {boolean isSuccess = queueDataFile.mkdirs();if (!isSuccess) {throw new IOException("创建文件失败!queueDataFile="+queueDataFile.getAbsolutePath());}}// 3. 创建消息统计文件File queueStatFile = new File(getQueueStatPath(queueName));if (!queueStatFile.exists()) {boolean isSuccess = queueStatFile.mkdirs();if (!isSuccess) {throw new IOException("创建文件失败!queueStatFile="+queueStatFile.getAbsolutePath());}}// 4. 给消息统计文件设定初始值,0\t0Stat stat = new Stat();stat.validCount = 0;stat.totalCount = 0;writeStat(queueName, stat);}
5.2.3 删除消息目录和文件
// 删除队列的目录和文件// 队列也是可以删除的,党队列删除以后,对应的文件自然也要删除public void destoryQueueFiles(String queueName) throws IOException {// 先删除里面的文件,再删除目录File queueDataFile = new File(getQueueDataPath(queueName));boolean succ1 = queueDataFile.delete();File queueStatFile = new File(getQueueStatPath(queueName));boolean succ2 = queueStatFile.delete();File baseDir = new File(getQueueDir(queueName));boolean succ3 = baseDir.delete();if (!succ1 || !succ2 || !succ3) {// 有任意一个删除失败,就算删除失败throw new IOException("删除队列目录和文件失败!baseDir" +baseDir.getAbsolutePath());}}
我们还需要一个判断队列中的数据文件和统计文件是否存在的方法,后续也会用到:
public boolean checkFilesExits(String queueName) {// 判断队列的数据文件和统计文件是否都存在File queueDataFile = new File(getQueueDataPath(queueName));if (!queueDataFile.exists()) {return false;}File queueStatFile = new File(getQueueStatPath(queueName));if (!queueStatFile.exists()) {return false;}return true;}
5.2.4 实现消息序列化
首先我们要理解一下什么叫序列化:把一个对象(结构化的数据)转成一个 字符串/字节数组,或者说是转化成某种特定的数据结构,以便可以在网络上传输或存储到磁盘等介质中。序列化通常是在发送数据到网络或存储到磁盘之前进行的,在接收或读取数据时需要进行反序列化操作以还原数据。我们可能比较熟悉使用 JSON 来完成序列化和反序列化,就是使用 jsckson 提供的 ObjectMapper 实现。
但是由于 JSON 序列化得到的结果是文本数据,不好存储二进制,而 Message 里面存储的 body 部分,是二进制数据,所以我们这里是不方便使用 JSON 进行序列化的。
我们会在文章末尾简单介绍说明一下 序列化相关的内容,感兴趣的可以跳到末尾看看。
针对二进制序列化,我们使用 java 标准库提供的方案:ObjectInputStream 和 ObjectOutputStream。
我们创建 BinaryTool 类,在里面定义方法实现序列化,由于序列化在很多地方都要用到,所以该类我们放在 common 这个包下面:
代码实现:
public class BinaryTool{// 把一个对象序列化成一个字节数组public static byte[] toBytes(Object object) throws IOException {// 这个流对象相当于一个变长的字节数组// 就可以把 object 序列化的数据给逐渐的写入到 byteArrayOutputStream 中,再统一转成 byte[]try (ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)){// 此处的 writeObject 就会把给对象进行序列化,生成的二进制字节数据,就会写入到 objectOutputStream 中// 由于 objectOutputStream 又是关联到了 byteArrayOutputStream,最终结果就写入到了 byteArrayOutputStream 中了。objectOutputStream.writeObject(object);// 这个操作就是把 byteArrayOutputStream 中持有的二进制数据取出来,转成 byte[]return byteArrayOutputStream.toByteArray();}}}// 把一个字节数组反序列化成一个对象public static Object fromBytes(byte[] data) throws IOException, ClassNotFoundException {Object object = null;try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)) {try (ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)) {// 此处的 readObject 就是从 data 这个 byte[] 中读取数据并进行反序列化object = objectInputStream.readObject();}}return object;}
}
这里的逻辑不仅仅是 Message,其他的 java 中的对象,也是可以通过这样的逻辑进行序列化和反序列化。
当然要想让这个对象能够序列化或者反序列化,需要让这个对象的类实现了 Serializable 接口:

5.2.5 把消息写进文件
在 MessageFileManager这个类中实现:
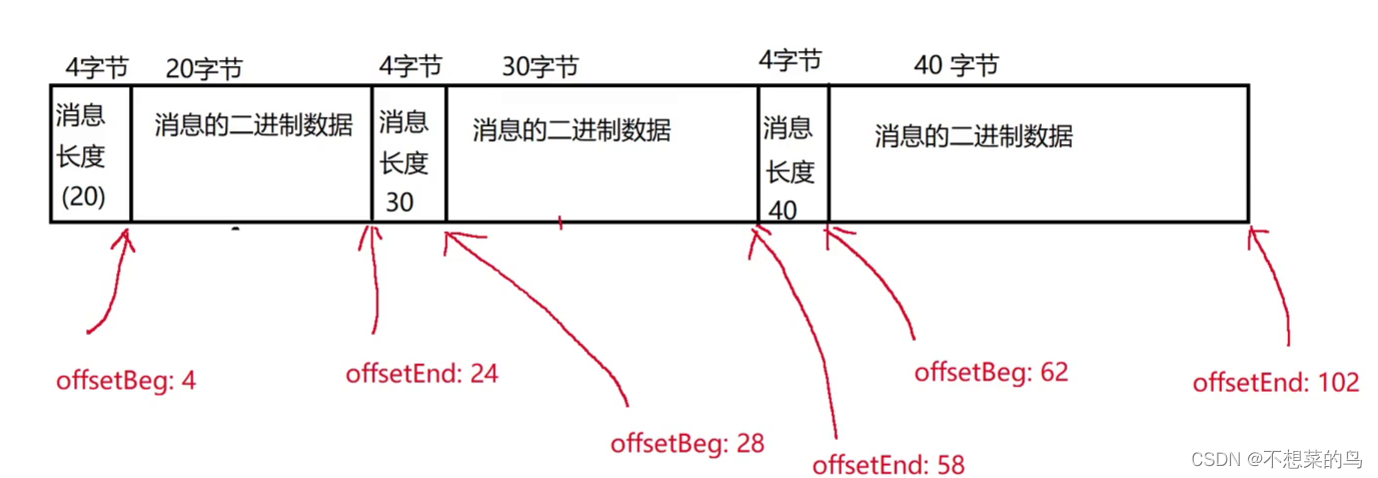
// 使用这个方法来把一个新的消息放到对应的文件中// queue 表示要把消息写入到的队列,message 则是要写的消息public void sendMessage(MSGQueue queue, Message message) throws MQException, IOException {// 1. 检查一下当前要写入的队列对应的文件是否存在if (!checkFilesExits(queue.getName())) {throw new MQException("[MessageFileManager] 队列对应的文件不存在!queueName=" + queue.getName());}// 2. 把 Message 对象进行序列化,转成二进制的字节数组byte[] messageBinary = BinaryTool.toBytes(message);// 3. 先获取到当前队列数据文件的长度,用这个来计算出改 Messag 对象的 offseBeg 和 offsetEnd// 把新的 Message 数据,写入到队列数据文件末尾。此时 Message 对象的 offsetBeg 就是当前文件长度 + 4// offsetEnd 就是当前文件长度 + 4 + message 自身长度File queueDataFile = new File(getQueueDataPath(queue.getName()));// 通过 queueDataFile.length() 就能获取到文件的长度,单位字节message.setOffsetBeg(queueDataFile.length() + 4);message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length);// 4. 写入消息到数据文件,注意,此处是追加写入到数据文件的末尾try (OutputStream outputStream = new FileOutputStream(queueDataFile, true)) {try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)) {// 接下来要先写当前文件的长度,占据四个字节dataOutputStream.writeInt(messageBinary.length);// 写入消息本体dataOutputStream.write(messageBinary);}}// 5. 更新消息统计文件Stat stat = readStat(queue.getName());stat.totalCount += 1;stat.validCount += 1;writeStat(queue.getName(), stat);}
此时可能有人就忘了这个 offsetBeg 和 offsetEnd 是怎么算的了,我们这里再回顾一下:
我们可以打开 writeInt 方法的源码来看看这个方法是怎么实现写入四个字节的:
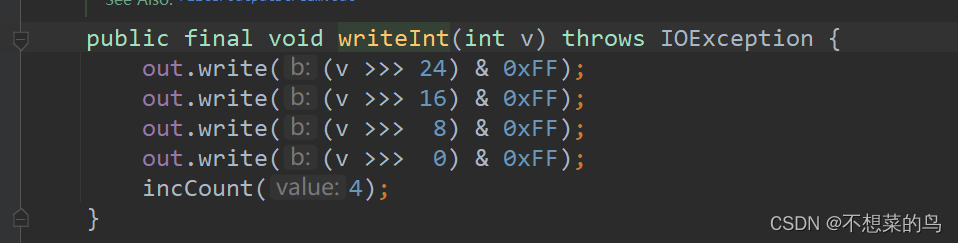
显然是通过 逻辑右移操作实现的。
此时我们写消息的代码基本就实现完成了,但是还存在问题:
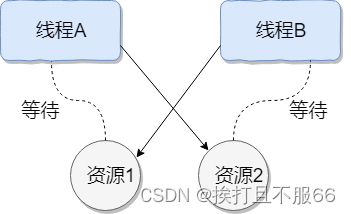
- 在写入消息到队列数据文件时,没有对文件进行加锁,存在并发写入的问题。如果多个线程同时写入同一个队列数据文件,可能会导致数据写入错误或者文件损坏。应该使用锁来保证线程安全。
- 在更新消息统计文件时,没有对文件进行加锁,存在并发写入的问题。同样,应该使用锁来保证线程安全。
所以我们需要加锁来解决问题,我们以 队列对象 进行加锁即可:
public void sendMessage(MSGQueue queue, Message message) throws MQException, IOException {// 1. 检查一下当前要写入的队列对应的文件是否存在if (!checkFilesExits(queue.getName())) {throw new MQException("[MessageFileManager] 队列对应的文件不存在!queueName=" + queue.getName());}// 2. 把 Message 对象进行序列化,转成二进制的字节数组byte[] messageBinary = BinaryTool.toBytes(message);synchronized (queue) {// 3. 先获取到当前队列数据文件的长度,用这个来计算出改 Messag 对象的 offseBeg 和 offsetEnd// 把新的 Message 数据,写入到队列数据文件末尾。此时 Message 对象的 offsetBeg 就是当前文件长度 + 4// offsetEnd 就是当前文件长度 + 4 + message 自身长度File queueDataFile = new File(getQueueDataPath(queue.getName()));// 通过 queueDataFile.length() 就能获取到文件的长度,单位字节message.setOffsetBeg(queueDataFile.length() + 4);message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length);// 4. 写入消息到数据文件,注意,此处是追加写入到数据文件的末尾try (OutputStream outputStream = new FileOutputStream(queueDataFile, true)) {try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)) {// 接下来要先写当前文件的长度,占据四个字节dataOutputStream.writeInt(messageBinary.length);// 写入消息本体dataOutputStream.write(messageBinary);}}// 5. 更新消息统计文件Stat stat = readStat(queue.getName());stat.totalCount += 1;stat.validCount += 1;writeStat(queue.getName(), stat);}}
5.2.6 删除消息
这里的删除是逻辑删除,也就是把硬盘上存储的数据里的 isValid 属性设置为 0,我们可以分三步完成:
- 先把文件中的这段数据读出来,还原成 Message 对象
- 把 isValid 改成 0
- 把上述数据重新写回到文件
具体打算是使用复制算法来实现垃圾回收也就是删除消息,如果不太清楚什么是复制算法,可以看看博主的这篇文章:http://t.csdn.cn/Gby1R。我们这里的做法是遍历原有的文件,把所有有效数据都拷贝到一个新的文件中,再把之前整个就得文件都删除。我们知道复制算法比较适用于当前的空间里的有效数据不多,大部分都是无效数据的情况,那么究竟我们啥时候触发一次 GC?啥时候才知道当前有效数据不多,垃圾很多呢?此处我们做出这样的约定:当总的消息数目超过 2000,有效消息数目低于总消息数目的 50%,就触发一次 GC。
这里的 2000 和 50% 都是我们自己拍脑门决定的,其它的数也都可以,主要是这个思想。
我们之前读写文件都是使用 FileInputStream 和 FileOutputStream,也都是从文件头开始读写的,但是此处我们需要的是在文件中的指定位置进行读写,这叫随机访问,这就用到了 offsetBeg 和 offsetEnd 这两个属性,用到的类是 RandomAccessFile。
这里可能有人对 随机访问 会有所疑惑,我们简单说明一下:
随机访问是指在计算机科学中,可以直接访问存储设备中的任意位置或数据的能力。与顺序访问不
同,随机访问不需要按照顺序逐个访问数据,而是可以直接跳转到所需的位置。这种访问方式可以提高
数据访问的效率,特别是在需要频繁访问不同位置的数据时。其实就像数组的下标一样,它的时间复杂
度是 O(1),就是因为这个原理。
public void deleteMessage(MSGQueue queue, Message message) throws IOException, ClassNotFoundException {synchronized (queue) {try(RandomAccessFile randomAccessFile = new RandomAccessFile(getQueueDataPath(queue.getName()), "rw")){// 1.byte[] bufferSrc = new byte[(int) (message.getOffsetEnd() - message.getOffsetBeg())];randomAccessFile.seek(message.getOffsetBeg());randomAccessFile.read(bufferSrc);Message diskMessage = (Message) BinaryTool.fromBytes(bufferSrc);// 2.diskMessage.setIsValue((byte) 0);// 3.byte[] bufferDest = BinaryTool.toBytes(diskMessage);randomAccessFile.seek(message.getOffsetBeg());randomAccessFile.write(bufferDest);}// 更新统计文件Stat stat = new Stat();if (stat.validCount > 0) {stat.validCount -= 1;}writeStat(queue.getName(), stat);}}
此时可能有人就对 seek 方法不太了解,这个方法就是改变文件光标,就相当于鼠标光标一样,我们想从文本的哪个地方开始修改,我们就可以移动我们的鼠标光标过去就行,这个 seek 方法的效果就是这样。
当然线程安全问题还是需要加锁处理的。
5.3 加载文件中的所有消息
此时格式还是按照之前约定的来:
public LinkedList<Message> loadAllMessageFromQueue(String queueName) throws IOException, MQException, ClassNotFoundException {LinkedList<Message> messages = new LinkedList<>();try (InputStream inputStream = new FileInputStream(getQueueDataPath(queueName))) {try (DataInputStream dataInputStream = new DataInputStream(inputStream)) {// 使用这个变量记录当前文件光标long currentOffset = 0;while (true) {// 1. 读取当前消息长度,这里的 readInt 可能会读到文件末尾(EOF)// 读到末尾就会抛出 EOFException 异常int messageSize = dataInputStream.readInt();// 2. 按照这个长度,读取消息内容byte[] buffer = new byte[messageSize];int actualSize = dataInputStream.read(buffer);if (actualSize != messageSize) {// 如果不匹配,说明文件有问题,格式错乱了throw new MQException("[MessageFileManager] 文件格式错误!queueName" + queueName);}// 3. 把这个读到的二进制数据,反序列化回 Message 对象Message message = (Message) BinaryTool.fromBytes(buffer);// 4. 判断这个消息对象是不是无效对象if (message.getIsValue() != 0x1) {currentOffset += (4 + messageSize);continue;}// 5. 有效数据,则把这个 Message 对象加入到链表中。// 当然,加入之前还要先确定 offsetBeg 和 offsetEndmessage.setOffsetBeg(currentOffset + 4);message.setOffsetEnd(currentOffset + 4 + messageSize);currentOffset += (4 + messageSize);messages.add(message);}} catch (EOFException e) {// 这个 catch 并非真是处理“异常”,而是处理业务逻辑,当文件读完时会抛出该异常。// 所以这里也不需要做什么事情System.out.println("[MessageFileManager] 恢复 Message 数据完成!");}}return messages;}
通过这个方法,从文件中读取出所有的消息内容,加载到内存中(具体来说是放到一个链表中)。
这个方法,准备在程序启动的时候调用。
这里使用 LinkedList 主要目的是为了后续的头删操作。
5.4 实现消息文件垃圾回收
之前我们已经实现了逻辑上的删除,也就是将 Message 中的 isValid 置为 0x0,并没有真的把这个消息从硬盘上删除,就可能会导致垃圾文件越来越多,越来越大,所以我们就要实现垃圾回收了,垃圾回收在前面的 5.2.6 我们也讲过,现在再来回顾一下:

首先先判断是否要进行 GC:
public boolean checkGC(String queueName) {Stat stat = readStat(queueName);if (stat.totalCount > 2000 && (double) stat.validCount / (double) stat.totalCount < 0.5) {return true;}return false;}
我还需要一个方法,用来创建新的消息存放文件,然后就可以和之前老的文件使用复制算法了,:
private String getQueueDataNewPath(String queueName) {return getQueueDir(queueName) + "/queue_data_new.txt";}
具体的思路:
- 创建一个新的文件,名字就是 queue_data_new.txt
- 把之前消息数据文件的有效消息都读出来,写到新文件中
- 删除旧的文件,再把新的文件改名回 queue_data.txt
- 更新统计文件
代码实现:
public void gc(MSGQueue queue) throws MQException, IOException, ClassNotFoundException {synchronized (queue) {// 由于 gc 操作可能比较耗时,此处统计一下执行消耗的时间long gcBeg = System.currentTimeMillis();// 1. 创建新文件File queueDataNewFile = new File(getQueueDataNewPath(queue.getName()));if (queueDataNewFile.exists()) {// 正常情况下,这个文件是不应该存在的,如果存在,就是意外,说明上次 gc 了一半,程序意外崩溃了throw new MQException("[MessageFileManager] gc 时发现该队列的 queue_data_new.txt 已经存在!queueName=" + queue.getName());}boolean isOk = queueDataNewFile.createNewFile();if (!isOk) {throw new MQException("[MessageFileManager] 创建文件失败!queueDataNewFile=" + queueDataNewFile.getAbsolutePath());}// 2. 从旧文件里读出所有有效消息对象LinkedList<Message> messages = loadAllMessageFromQueue(queue.getName());// 3. 有效消息写入到新文件中try (OutputStream outputStream = new FileOutputStream(queueDataNewFile)) {try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)){for (Message message : messages) {byte[] buffer = BinaryTool.toBytes(message);dataOutputStream.writeInt(buffer.length);dataOutputStream.write(buffer);}}}// 4. 删除旧文件,重命名新文件File queueDataOldFile = new File(getQueueDataPath(queue.getName()));isOk = queueDataOldFile.delete();if (!isOk) {throw new MQException("[MessageFileManager] 删除旧的文件失败!queueDataOldFile=" + queueDataOldFile.getAbsolutePath());}// queue_data_new.txt => queue_data.txtisOk = queueDataNewFile.renameTo(queueDataOldFile);if (!isOk) {throw new MQException("[MessageFileManager] 文件重命名失败!queueDataNewFile=" + queueDataNewFile.getAbsolutePath()+ ", queueDataOldFile=" + queueDataOldFile.getAbsolutePath());}// 5. 更新统计文件Stat stat = readStat(queue.getName());stat.totalCount = messages.size();stat.validCount = messages.size();writeStat(queue.getName(), stat);long gcEnd = System.currentTimeMillis();System.out.println("[MessageFileManager] gc 执行完毕! queueName=" + queue.getName()+", time=" + (gcEnd-gcBeg));}}
6. 统一硬盘操作
目前为止,我们已经使用数据库管理了交换机、绑定、队列。又使用了数据文件管理了消息。接下来就搞一个类 DiskDataCenter ,把上述两个部分整合在一起,对上层提供一套统一的接口:
public class DiskDataCenter {private DatabaseManager databaseManager = new DatabaseManager();private MessageFileManager messageFileManager = new MessageFileManager();public void init() {// 针对上述两个实例进行初始化databaseManager.init();messageFileManager.init();}// 封装交换机操作public void insertExchange(Exchange exchange) {databaseManager.insertExchange(exchange);}public void deleteExchange(String exchangerName) {databaseManager.deleteExchange(exchangerName);}public List<Exchange> selectAllExchange() {return databaseManager.selectAllExchanges();}// 封装队列操作public void insertQueue(MSGQueue queue) throws IOException {databaseManager.insertQueue(queue);// 创建队列的同时,不仅仅是把队列对象写到数据库中,还需要创建出对应的目录和文件messageFileManager.createQueueFiles(queue.getName());}public void deleteQueue(String queueName) throws IOException {databaseManager.deleteQueue(queueName);// 删除队列的同时,不仅仅是把队列从数据库中删除,还需要删除对应的目录和文件messageFileManager.destoryQueueFiles(queueName);}public List<MSGQueue> selectAllQueue() {return databaseManager.selectAllQueue();}// 封装绑定操作public void insertBinding(Binding binding) {databaseManager.insertBinding(binding);}public void deleteBinding(Binding binding) {databaseManager.deleteBinding(binding);}public List<Binding> selectAllBinding() {return databaseManager.selectAllBinding();}// 封装消息操作public void sendMessage(MSGQueue queue, Message message) throws MQException, IOException {messageFileManager.sendMessage(queue, message);}public void deleteMessage(MSGQueue queue, Message message) throws IOException, ClassNotFoundException, MQException {messageFileManager.deleteMessage(queue, message);if (messageFileManager.checkGC(queue.getName())) {messageFileManager.gc(queue);}}public LinkedList<Message> loadAllMessageFromQueue(String queueName) throws MQException, IOException, ClassNotFoundException {return messageFileManager.loadAllMessageFromQueue(queueName);}}
7. 内存数据管理
7.1 设计数据结构
交换机:直接使用 HashMap,key 是 name,value 是 Exchange 对象
队列:直接使用 HashMap,key 是 name,value 是 MSGQueue 对象
绑定:使用嵌套的 HashMap。key 是 exchangeName,value 是一个 HashMap,这个HashMap的 key 是 queueName, value 是 Binding 对象。
消息:使用 HashMap。key 是 messageId,value 是 Message 对象
队列与消息之间的关联,也就是每个队列中有哪些消息:使用嵌套的 HashMap。key 是 queueName,value 是一个 LinkedList,里面的每个元素是一个 Message 对象。
除此之外,我们还需要表示“未被确认”的消息:
我们此处实现的 MQ,支持两种应答模式(ACK),详情请回顾 1.6,我们这里简单说明一下:

未被确认也就是说存储了哪些消息被消费者取走了,但还没有应答。我们还是使用嵌套的 HashMap。key 是 queueName,value 是 HashMap,其中 key 是messageId,value 是 Message 对象。
我们创建类 MemoryDataCenter 来实现上述操作:
代码实现:
public class MemoryDataCenter {private ConcurrentHashMap<String, Exchange> exchangeMap = new ConcurrentHashMap<>();private ConcurrentHashMap<String, MSGQueue> queueMap = new ConcurrentHashMap<>();private ConcurrentHashMap<String, ConcurrentHashMap<String, Binding>> bindingsMap = new ConcurrentHashMap<>();private ConcurrentHashMap<String, Message> messageMap = new ConcurrentHashMap<>();// 队列与消息的关系private ConcurrentHashMap<String, LinkedList<Message>> queueMessageMap = new ConcurrentHashMap<>();// 待确认的消息private ConcurrentHashMap<String, ConcurrentHashMap<String, Message>> queueMessageWaitAckMap = new ConcurrentHashMap<>();}
7.2 实现交换机和队列的管理
public void insertExchange(Exchange exchange) {exchangeMap.put(exchange.getName(), exchange);}public Exchange getExchange(String exchangeName) {return exchangeMap.get(exchangeName);}public void deleteExchange(String exchangeName) {exchangeMap.remove(exchangeName);}public void insertQueue(MSGQueue queue) {queueMap.put(queue.getName(), queue);}public MSGQueue getQueue(String queueName) {return queueMap.get(queueName);}public void deleteQueue(String queueName) {queueMap.remove(queueName);}
7.3 实现绑定的管理
public void insertBinding(Binding binding) throws MQException {// 先使用 exchangeName 查一下,对应的 哈希表 是否存在,不存在就创建一个
// ConcurrentHashMap<String, Binding> bindingMap = bindingsMap.get(binding.getExchangeName());
// if (bindingMap == null) {
// bindingMap = new ConcurrentHashMap<>();
// bindingsMap.put(binding.getExchangeName(), bindingMap);
// }ConcurrentHashMap<String, Binding> bindingMap = bindingsMap.computeIfAbsent(binding.getExchangeName(),k -> new ConcurrentHashMap<>());// 再根据 queueName 查一下,如果已经存在,就抛出异常,不存在才能插入。synchronized (bindingMap) {if (bindingMap.get(binding.getQueueName()) != null) {throw new MQException("[MemoryDataCenter] 绑定已经存在!exchangeName=" + binding.getExchangeName() +", queueName=" + binding.getQueueName());}bindingMap.put(binding.getQueueName(), binding);}}/*** 获取绑定,写两个版本* 1. 根据 exchangeName 和 queueName 确定唯一一个绑定* 2. 根据 exchangeName 获取到所有的 绑定* @param exchangeName* @param queueName* @return*/public Binding getBinding(String exchangeName, String queueName) {ConcurrentHashMap<String, Binding> bindingMap = bindingsMap.get(exchangeName);if (bindingMap == null) {return null;}return bindingMap.get(queueName);}public ConcurrentHashMap<String, Binding> getBindings(String exchangeName) {return bindingsMap.get(exchangeName);}public void deleteBinding(Binding binding) throws MQException {ConcurrentHashMap<String, Binding> bindingMap = bindingsMap.get(binding.getExchangeName());if (bindingMap == null) {// 该交换机没有绑定任何队列throw new MQException("[MemoryDatacenter] 绑定不存在!exchangeName=" + binding.getExchangeName() +", queueName=" + binding.getQueueName());}bindingMap.remove(binding.getQueueName());}
7.4 实现消息的管理
public void addMessage(Message message) {messageMap.put(message.getMessageId(), message);System.out.println("[MemoryDataCenter] 新消息添加成功!messageId=" + message.getMessageId());}public Message getMessage(String messageId) {return messageMap.get(messageId);}public void removeMessage(String messageId) {messageMap.remove(messageId);System.out.println("[MemoryDataCenter] 消息被移除!messageId=" + messageId);}// 发送消息到指定队列public void senMessage(MSGQueue queue, Message message) {LinkedList<Message> messages = queueMessageMap.computeIfAbsent(queue.getName(),k -> new LinkedList<>());synchronized (messages) {messages.add(message);}addMessage(message);System.out.println("[MemoryDataCenter] 消息被投递到队列中!messageid=" + message.getMessageId());}// 从队列中取消息public Message pollMessage(String queueName) {LinkedList<Message> messages = queueMessageMap.get(queueName);if (messages == null) {return null;}synchronized (messages) {if (messages.size() == 0) {return null;}// 链表中有元素,就进行头删Message curMessage = messages.remove(0);System.out.println("[MemoryDataCenter] 消息从队列中取出!messageId=" + curMessage.getMessageId());return curMessage;}}// 获取指定队列中的消息个数public int getMessageCount(String queueName) {LinkedList<Message> messages = queueMessageMap.get(queueName);if (messages == null) {return 0;}synchronized (messages) {return messages.size();}}
7.5 实现待确认消息的管理
// 添加未确认的消息public void addMessageWaitAck(String queueName, Message message) {ConcurrentHashMap<String, Message> messageHashMap = queueMessageWaitAckMap.computeIfAbsent(queueName,k -> new ConcurrentHashMap<>());messageHashMap.put(message.getMessageId(), message);System.out.println("[MemoryDataCenter] 消息进入待确认队列!messageId=" + message.getMessageId());}// 删除未确认的消息public void removeMessageWaitAck(String queueName, String messageId) {ConcurrentHashMap<String, Message> messageHashMap = queueMessageWaitAckMap.get(queueName);if (messageHashMap == null) {return;}messageHashMap.remove(messageId);System.out.println("[MemoryDataCenter] 消息从待确认队列删除!messageId=" + messageId);}// 获取指定的未确认的消息public Message getMessageWaitAck(String queueName, String messageId) {ConcurrentHashMap<String, Message> messageHashMap = queueMessageWaitAckMap.get(queueName);if (messageHashMap == null) {return null;}return messageHashMap.get(messageId);}
7.6 实现数据从硬盘上恢复
public void recovery(DiskDataCenter diskDataCenter) throws MQException, IOException, ClassNotFoundException {exchangeMap.clear();queueMap.clear();bindingsMap.clear();messageMap.clear();queueMessageMap.clear();// 1. 恢复所有的交换机数据List<Exchange> exchanges = diskDataCenter.selectAllExchange();for (Exchange exchange : exchanges) {exchangeMap.put(exchange.getName(), exchange);}// 2. 恢复所有的队列数据List<MSGQueue> queues = diskDataCenter.selectAllQueue();for (MSGQueue queue : queues) {queueMap.put(queue.getName(), queue);}// 3. 恢复所有的绑定数据List<Binding> bindings = diskDataCenter.selectAllBinding();for (Binding binding : bindings) {ConcurrentHashMap<String, Binding> bindingMap = bindingsMap.computeIfAbsent(binding.getExchangeName(),k -> new ConcurrentHashMap<>());bindingMap.put(binding.getQueueName(), binding);}// 4. 恢复所有的消息// 遍历所有的队列,根据每个队列的名字,获取到所有的消息for (MSGQueue queue : queues) {LinkedList<Message> messages = diskDataCenter.loadAllMessageFromQueue(queue.getName());queueMessageMap.put(queue.getName(), messages);for (Message message : messages) {messageMap.put(message.getMessageId(), message);}}}
注意!针对“未确认消息” 这部分内存中存在的数据,不需要从何硬盘中恢复。之前考虑硬盘存储的时候,也没有设定这一块。一旦在等待 ack 的过程中,服务器重启了,此时这些未被确认的消息就恢复成未被取走的消息。这个消息在硬盘上存储的时候,就被当做是“未被取走”。
8. 虚拟主机设计
8.1 需求回顾
根据前面的讲解,我们知道这个虚拟主机就类似于 MySQL 的 database,把交换机、队列、绑定、消息等进行逻辑上的隔离。我们这里为了简单,只实现单个的虚拟主机,不实现添加、删除虚拟主机,但是会在设计数据结构上留下这样的拓展空间。
当然,虚拟主机不仅仅要管理数据,还需要提供核心 api 以供上层代码进行调用。
核心 api:
- 创建交换机 exchangeDeclare
- 删除交换机 exchangeDelete
- 创建队列 queueDeclare
- 删除队列 queueDelete
- 创建绑定 queueBind
- 删除绑定 queueUnbind
- 发生消息 basicPublish
- 订阅消息 basicConsume
- 确认消息 basicAck
这些核心 api 的作用就是把之前写的内存中的数据管理和硬盘的数据管理串起来,这些 api 的实现也就是我们整个核心业务逻辑了。
8.2 创建 VirtualHost 类
public class VirtualHost {private String virtualHostName;private MemoryDataCenter memoryDataCenter = new MemoryDataCenter();private DiskDataCenter diskDataCenter = new DiskDataCenter();public String getVirtualHostName() {return virtualHostName;}public MemoryDataCenter getMemoryDataCenter() {return memoryDataCenter;}public DiskDataCenter getDiskDataCenter() {return diskDataCenter;}public VirtualHost(String virtualHostName) {this.virtualHostName = virtualHostName;// 对于 MemoryDataCenter 来说,不需要额外的初始化操作。只要对象 new 出来就行// 但是对于 DiskDataCenter 来说,则需要进行初始化操作,建库建表和初始数据的设定// 另外还需要针对硬盘的数据,进行恢复到内存中diskDataCenter.init();try {memoryDataCenter.recovery(diskDataCenter);} catch (MQException | ClassNotFoundException | IOException e) {e.printStackTrace();System.out.println("[VirtualHost] 恢复内存数据失败!");}}}
针对VirtualHost 这个类,作为业务逻辑的整合者,就需要对代码中抛出的异常进行处理了。
8.3 实现 exchangeDeclare 和 exchangeDelete
此时我们需要考虑一个问题,就是如何表示交换机和虚拟主机之间的从属关系?
方案一:参考数据库设计,“一对多”的方案,就可以给交换机表添加个属性,虚拟主机的id/name…
方案二:重新约定,交换机的名字 = 虚拟主机的名字 + 交换机的真实名字
虚拟主机的目的是为了保证隔离,就是不同虚拟主机之间的内容不要相互影响
我们采用方案二,我们约定,在 VirtualHost 中的核心 api 里,都需要对 exchangeName 和 queueName 做出转换。
代码实现:
public boolean exchangeDeclare(String exchangeName, ExchangeType exchangeType, boolean durable, boolean autoDelete,Map<String, Object> arguments){// 把交换机的名字,加上虚拟主机作为前缀exchangeName = virtualHostName + exchangeName;try {synchronized (exchangeLocker) {// 1. 判断该交换机是否已经存在,直接通过内存查询Exchange existsExchange = memoryDataCenter.getExchange(exchangeName);if (existsExchange != null) {// 该交换机已经存在System.out.println("[VirtualHost] 交换机已经存在!exchangeName=" + exchangeName);return true;}// 2. 真正创建交换机Exchange exchange = new Exchange();exchange.setName(exchangeName);exchange.setType(exchangeType);exchange.setDurable(durable);exchange.setArguments(arguments);// 3. 把交换机对象写入硬盘if (durable) {diskDataCenter.insertExchange(exchange);}// 5. 把交换机对象写入内存memoryDataCenter.insertExchange(exchange);System.out.println("[VirtualHost] 交换机创建完成!exchangeName=" + exchangeName);}return true;} catch (Exception e) {System.out.println("[VirtualHost] 交换机创建失败!exchangeName=" + exchangeName);e.printStackTrace();return false;}}
public boolean exchangeDelete(String exchangeName) {exchangeName = virtualHostName + exchangeName;try {synchronized (exchangeLocker) {// 1. 先找到对应的交换机Exchange toDelete = memoryDataCenter.getExchange(exchangeName);if (toDelete == null) {throw new MQException("[virtualHost] 交换机不存在,无法删除!");}// 2. 删除硬盘上的数据if (toDelete.isDurable()) {diskDataCenter.deleteExchange(exchangeName);}// 3. 删除内存中的交换机数据memoryDataCenter.deleteExchange(exchangeName);System.out.println("[VirtualHost] 交换机删除成功!exchangeName=" + exchangeName);}return true;} catch (Exception e) {System.out.println("[VirtualHost] 交换机删除失败!exchangeName=" + exchangeName);e.printStackTrace();return false;}}
我们为了保证线程安全问题,声明了一个私有属性 exchangeLocker 做为锁对象,给创建交换机和删除交换机加锁。
8.4 实现 queueDeclare 和 queueDelete
public boolean queueDeclare(String queueName, boolean durable, boolean exclusive, boolean autoDelete,Map<String, Object> arguments) {queueName = virtualHostName + queueName;try {synchronized (queueLocker) {// 1. 判断队列是否存在MSGQueue existsQueue = memoryDataCenter.getQueue(queueName);if (existsQueue != null) {System.out.println("[VirtualHost] 队列已经存在!queueName=" + queueName);return true;}// 2. 创建队列对象MSGQueue queue = new MSGQueue();queue.setName(queueName);queue.setDurable(durable);queue.setExclusive(exclusive);queue.setAutoDelete(autoDelete);queue.setArguments(arguments);// 3. 写进硬盘if (durable) {diskDataCenter.insertQueue(queue);}// 4. 写进内存memoryDataCenter.insertQueue(queue);System.out.println("[VirtualHost] 队列创建成功!queueName=" + queueName);}return true;} catch (Exception e) {System.out.println("[VirtualHost] 队列创建失败!queueName=" + queueName);e.printStackTrace();return false;}}
public boolean queueDelete(String queueName) {queueName = virtualHostName + queueName;try {synchronized (queueLocker) {// 1. 根据队列名字,查询队列对象MSGQueue queue = memoryDataCenter.getQueue(queueName);if (queue == null) {throw new MQException("[VirtualHost] 队列不存在!queueName=" + queueName);}// 2. 删除硬盘数据if (queue.isDurable()) {diskDataCenter.deleteQueue(queueName);}// 3. 删除内存数据memoryDataCenter.deleteQueue(queueName);System.out.println("[VirtualHost] 队列删除成功!queueName=" + queueName);}return true;} catch (Exception e) {System.out.println("[VirtualHost] 队列删除失败!queueName=" + queueName);e.printStackTrace();return false;}}
同样的
8.5 实现 queueBind 和 queueUnbind
public boolean queueBind(String queueName, String exchangeName, String bindingKey) {queueName = virtualHostName + queueName;exchangeName = virtualHostName + exchangeName;try {synchronized (exchangeLocker) {synchronized (queueLocker) {// 1. 判断当前绑定是否已经存在Binding existsBinding = memoryDataCenter.getBinding(exchangeName, queueName);if (existsBinding != null) {throw new MQException("[VirtualHost] binding 已经存在!queueName=" + queueName + ", exchangeName=" + exchangeName);}// 2. 验证 bindingKey 是否合法if(!router.checkBindingKey(bindingKey)){throw new MQException("[VirtualHost] 非法!bindingKey=" + bindingKey);}// 3. 创建 Binding 对象Binding binding = new Binding();binding.setExchangeName(exchangeName);binding.setQueueName(queueName);binding.setBindingKey(bindingKey);// 4. 获取一下对应的交换机和队列。如果交换机或者队列不存在,这样的绑定也是无法创建的。MSGQueue queue = memoryDataCenter.getQueue(queueName);if (queue == null) {throw new MQException("[VirtualHost] 队列不存在!queueName=" + queueName);}Exchange exchange = memoryDataCenter.getExchange(exchangeName);if (exchange == null) {throw new MQException("[VirtualHost] 交换机不存在!exchangeName=" + exchangeName);}if (exchange.isDurable() && queue.isDurable()) {diskDataCenter.insertBinding(binding);}memoryDataCenter.insertBinding(binding);}}System.out.println("[VirtualHost] 绑定创建成功!exchangeName=" + exchangeName + ", queueName=" + queueName);return true;} catch (Exception e) {System.out.println("[VirtualHost] 绑定创建失败!exchangeName=" + exchangeName + ", queueName=" + queueName);e.printStackTrace();return false;}}
我们创建 Router 类来提供检查 routingKey 安全性问题:
public class Router {public static boolean checkBindingKey(String bindingKey) {// todoreturn true;}
}
暂时先不实现。
ppublic boolean queueUnbind(String queueName, String exchangeName) {queueName = virtualHostName + queueName;exchangeName = virtualHostName + exchangeName;try {synchronized (exchangeLocker) {synchronized (queueLocker) {// 1. 获取绑定,看是否存在Binding binding = memoryDataCenter.getBinding(exchangeName, queueName);if (binding == null) {throw new MQException("[VirtualHost] 删除绑定失败!绑定不存在!exchangeName=" + exchangeName + ", queueName=" + queueName);}diskDataCenter.deleteBinding(binding);memoryDataCenter.deleteBinding(binding);System.out.println("[VirtualHost] 删除绑定成功!");}}return true;} catch (Exception e) {System.out.println("[VirtualHost] 删除绑定失败!");e.printStackTrace();return false;}}
我们使用 exchangeLocker 和 queueLocker 两把锁来加锁,注意两把锁的加锁顺序要一致,不然可能会导致死锁。
此时对于删除绑定的方法还存在问题:假如我们先删除交换机的话,那么绑定就删不掉了。为了解决这个问题,我们这里提供两种方案:
- 参考类似于 MySQL 的外键一样。删除队列/交换机的时候,判定一下当前交换机/队列是否存在对应的绑定。如果存在,则禁止删除队列/交换机,要求先解除绑定,再尝试删除队列/交换机。
- 删除绑定的时候,干脆就不校验交换机/队列是否存在,直接就尝试删除。
我们就采取第二种,简单粗暴。我们就可以修改代码了:
public boolean queueUnbind(String queueName, String exchangeName) {queueName = virtualHostName + queueName;exchangeName = virtualHostName + exchangeName;try {// 1. 获取绑定,看是否存在Binding binding = memoryDataCenter.getBinding(exchangeName, queueName);if (binding == null) {throw new MQException("[VirtualHost] 删除绑定失败!绑定不存在!exchangeName=" + exchangeName + ", queueName=" + queueName);}diskDataCenter.deleteBinding(binding);memoryDataCenter.deleteBinding(binding);System.out.println("[VirtualHost] 删除绑定成功!");return true;} catch (Exception e) {System.out.println("[VirtualHost] 删除绑定失败!");e.printStackTrace();return false;}}
8.6 实现 basicPublish
发送消息到指定的交换机、队列中。
public boolean basicPublish(String exchangeName, String routingKey, BasicProperties basicProperties, byte[] body) {try {// 1. 转换交换机的名字exchangeName = virtualHostName + exchangeName;// 2. 检查 routingKey 是否合法if (!router.checkRoutingKey(routingKey)) {throw new MQException("[VirtualHost] routingKey 非法!routingKey=" + routingKey);}// 3. 查找交换机对象Exchange exchange = memoryDataCenter.getExchange(exchangeName);if (exchange == null) {throw new MQException("[VirtualHost] 交换机不存在!exchangeName=" + exchangeName);}// 4. 判定交换机的类型if (exchange.getType() == ExchangeType.DIRECT) {// 按照直接交换机的方式来转发消息// 以 routingKey 作为队列的名字,直接把消息写入指定队列中// 此时,可以无视绑定关系String queueName = virtualHostName + routingKey;// 5. 构造消息对象Message message = Message.createMessageWithId(routingKey, basicProperties, body);// 6. 查找给队列名对应的对象MSGQueue queue = memoryDataCenter.getQueue(queueName);if (queue == null) {throw new MQException("[VirtualHost] 队列不存在!queueName=" + queueName);}// 7. 队列存在,直接给队列中写入消息sendMessage(queue, message);} else {// 按照 fanout 和 topic 的方式来转发消息// 5. 找到改交换机关联的所有绑定,并遍历这些绑定对象ConcurrentHashMap<String, Binding> bindingsMap = memoryDataCenter.getBindings(exchangeName);for (Map.Entry<String, Binding> entry : bindingsMap.entrySet()) {// 1) 获取到绑定对象,判断对应的队列是否存在Binding binding = entry.getValue();MSGQueue queue = memoryDataCenter.getQueue(binding.getQueueName());if (queue == null) {// 此处就不抛出异常了,可能有很多个这样的队列// 我们不希望因为一个队列的失败,影响到其他队列的消息的传输System.out.println("[VirtualHost] basicPublish 发送消息时,发现队列不存在!queueName=" + binding.getQueueName());continue;}// 2) 构造消息对象Message message = Message.createMessageWithId(routingKey, basicProperties, body);// 3) 判断这个消息是否能转发给改队列// 如果是 fanout,所有绑定的队列都要转发的// 如果是 topic,还需要判定一下 bindingKey 和 routingKey 是否匹配if (!router.route(exchange.getType(), binding, message)) {continue;}// 4) 真正转发消息给队列sendMessage(queue, message);}}return true;} catch (Exception e) {System.out.println("[VirtualHost] 消息发送失败!");e.printStackTrace();return false;}}
sendMessage 方法的实现,这个方法也实在 VirtualHost 类中:
private void sendMessage(MSGQueue queue, Message message) throws MQException, IOException {// 此处发送消息,就是把消息写入到硬盘 和 内存上int deliverMode = message.getDeliverMode();// deliverMode 为 1 表示不持久化,为 2 表示持久化if (deliverMode == 2) {diskDataCenter.sendMessage(queue, message);}// 写入内存memoryDataCenter.senMessage(queue, message);// todo 此处还需要补充一个逻辑,通知消费者可以消费消息了。}
这里的 todo 等待我们写到消费者相关逻辑那里,再完成。
8.7 转发规则的实现
8.7.1 知识回顾及补充
Router 类的实现:
我们先来回顾一下 topic 类型的交换机的转发规则:
bindingKey(创建绑定的时候,给绑定指定的字符串,相当于出题)
routingKey(发布消息的时候,给消息上指定的特殊字符串,相当于答题)
那么我们就来翻译翻译,什么叫做能匹配上:
routingKey:形如 aaa.bbb.11
- 由数字、字母、下划线组成
- 使用 . 把整个 routingKey 分成多个部分
bindingKey:
- 数字、字母、下划线
- 使用 . 把整个 bindingKey 分成多个部分
- 支持两种特殊符号作为通配符: * 和 #,* 和 # 必须是作为被 . 分割出来的独立的部分
aaa.*.bbb(合法) aaa.#b.cc(不合法)
- * 可以匹配任何一个独立的部分
- # 可以匹配任何 0 个或者多个独立的部分
举几个例子:
①
bindingKey:aaa.bbb.ccc,没有 * 和 #。此时 routingKey 必须和 routingKey 一模一样才算匹配成功
②
bindingKey:aaa.*.ccc,有 * 号
此时的 routingKey 如下:
aaa.bbb.ccc(匹配成功)
aaa.b.ccc(匹配成功)
aaa.b.b.ccc(匹配失败)
③
bindingKey:aaa.#.ccc
此时routingKey如下:
aaa.bbb.ccc(匹配成功)
aaa.b.b.ccc(匹配成功)
aaa.ccc(匹配成功)
aaa.b.b.b(匹配失败)
8.7.2 检查 bindingKey 和 routingKey 合法性
public boolean checkBindingKey(String bindingKey) {if (bindingKey.length() == 0) {// 空字符串 合法。比如在使用 direct/fanout 交换机时, bindingKey 用不上return true;}for (int i = 0; i < bindingKey.length(); i++) {char ch = bindingKey.charAt(i);if (ch >= 'A' && ch <= 'Z') {continue;}if (ch >= 'a' && ch <= 'z') {continue;}if (ch >= '0' && ch <= '9') {continue;}if (ch == '_' || ch == '.' || ch == '*' || ch == '#') {continue;}return false;}// 检查 * 和 # 是否是独立的部分String[] words = bindingKey.split("\\.");for (String word : words) {// 检查 word 长度 > 1 并且包含了 * 或者 #,就是非法的格式了if (word.length() > 1 && (word.contains("*") || word.contains("#"))) {return false;}}// 约定一下,通配符之间的相邻关系(人为约定,为了实现起来方便)// 1. aaa.#.#.bbb => 非法// 2. aaa.#.*.bbb => 非法// 3. aaa.*.#.bbb => 非法// 4. aaa.*.*.bbb => 合法for (int i = 0; i < words.length - 1; i++) {if (words[i].equals("#") && words[i + 1].equals("#")) {return false;}if (words[i].equals("#") && words[i + 1].equals("*")) {return false;}if (words[i].equals("*") && words[i + 1].equals("#")) {return false;}}return true;}public boolean checkRoutingKey(String routingKey) {if (routingKey.length() == 0) {// 空字符串也是合法情况,比如在使用 fanout 交换机的时候, routingKey 用不上,就可以设为""return true;}for (int i = 0; i < routingKey.length(); i++) {char ch = routingKey.charAt(i);if (ch >= 'A' && ch <= 'Z') {continue;}if (ch >= 'a' && ch <= 'z') {continue;}if (ch >= '0' && ch <= '9') {continue;}if (ch == '_' || ch == '.') {continue;}return false;}return true;}
8.7.3 实现 route 方法 和 routeTopic
route 方法用来判断该消息是否可以转发给这个绑定对应的队列。routeTopic 方法描述了 topic 交换机的转发规则。
代码实现:
public boolean route(ExchangeType exchangeType, Binding binding, Message message) throws MQException {// 根据不同的 exchangeType 使用不同的判定转发规则if (exchangeType == ExchangeType.TOPIC) {return routeTopic(binding, message);} else if (exchangeType == ExchangeType.FANOUT) {// 如果是 fanout,所有绑定的队列都要转发的return true;} else {// 其他情况是不应该存在的throw new MQException("[Router] 交换机类型非法!exchangeType=" + exchangeType);}}private boolean routeTopic(Binding binding, Message message) {String[] bindingTokens = binding.getBindingKey().split("\\.");String[] routingTokens = message.getRoutingKey().split("\\.");int bindingIndex = 0;int routingIndex = 0;while (bindingIndex < bindingTokens.length && routingIndex < routingTokens.length) {if (bindingTokens[bindingIndex].equals("*")) {bindingIndex++;routingIndex++;continue;} else if (bindingTokens[bindingIndex].equals("#")) {bindingIndex++;if (bindingIndex == bindingTokens.length) {// 说明 # 后面没东西了,那么一定能够匹配成功return true;}// # 后面还有东西,拿着这个内容,去 routingKey 中往后找,找到对应的位置// findNextMatch 这个方法用来查找改部分在 routingKey 的位置,返回下标,没找到就返回 -1routingIndex = findNextMatch(routingTokens, routingIndex, bindingTokens[bindingIndex]);if (routingIndex == -1) {return false;}// 找到了,继续往后匹配bindingIndex++;routingIndex++;} else {if (!bindingTokens[bindingIndex].equals(routingTokens[routingIndex])) {return false;}bindingIndex++;routingIndex++;}}// 判定是否是双方同时达到末尾if (bindingIndex == bindingTokens.length && routingIndex == routingTokens.length) {return true;}return false;}private int findNextMatch(String[] routingTokens, int routingIndex, String bindingToken) {for (int i = routingTokens.length - 1; i >= routingIndex; i--) {if (routingTokens[i].equals(bindingToken)) {return i;}}return -1;}
8.8 实现 basicConsume
订阅消息。添加一个队列的订阅者,当队列收到消息之后,就要把消息推送给对应的订阅者。
推送消息给消费者的基本实现思路:
- 让 broker server 把有哪些消费者管理好
- 收到对应的消息,把消息推送给消费者
消费者调用 basicConsume,就是订阅某个队列的消息。basicConsume 方法参数:
public boolean basicConsume(String consumerTag, String queueName, boolean autoAck, Consumer consumer) {}
consumerTag 是消费者的身份标识;autoAck 是消息被消费完后,应答的方式,为 true 自动应答,为 false 手动应答;consumer 是一个回调函数。此处类型设定为函数式接口,这样后续调用 basicConsume 并且传实参的时候,就可以使用 lambda。
@FunctionalInterface
public interface Consumer {// Delivery 的意思是“投递”,这个方法预期是在每次服务器收到消息之后,来调用// 通过这个方法把消息推送给对应的消费者void handleDelivery(String consumerTag, BasicProperties basicProperties, byte[] body);
}
消费者是以队列为维度订阅消息的,一个队列可以有多个消费者。此处我们约定消费者之间按照“轮询”的方式进行消费。
那么在代码中我们具体是怎么实现消费者的管理呢:
先定义一个类 ConsumerEnv,描述一个消费者(也会包含一些消费者消费过程中用到的数据)。再给每个队列对象(MSGQueue 对象)加上属性 List,包含肉干个上述的消费者对象。
// 当前队列都有哪些消费者订阅private List<ConsumerEnv> consumerEnvList = new ArrayList<>();// 记录当前取到了第几个消费者,方便实现轮询策略private AtomicInteger consumerSeq = new AtomicInteger(0);// 添加一个新的订阅者public void addConsumerEnv(ConsumerEnv consumerEnv) {synchronized (this) {consumerEnvList.add(consumerEnv);}}// 订阅者的删除暂时先不考虑// 挑选一个订阅者用来处理当前的消息(按照轮询的方式)public ConsumerEnv chooseConsumer() {if (consumerEnvList.size() == 0) {// 该队列没有人订阅return null;}// 计算一下当前要取的元素的下标int index = consumerSeq.get() % consumerEnvList.size();consumerSeq.getAndIncrement();return consumerEnvList.get(index);}
@Data
public class ConsumerEnv {private String consumerTag;private String queueName;private boolean autoAck;// 通过这个回调来处理收到的消息private Consumer consumer;
}
接下来我们来说明一下消费消息的整体思路,借助画图来说明:

此时还有一个很关键的问题,假设此时来了一个消息进入某个队列,那么对于线程池来说,他怎么知道是哪个队列来了新消息,他怎么知道去哪个队列中去取消息,然后只想后续逻辑。为了能够让线程池知道要执行哪个回调函数以及参数是哪个消息(来自哪个队列),我们单独搞一个扫描线程,感知到哪个队列收到了新消息:
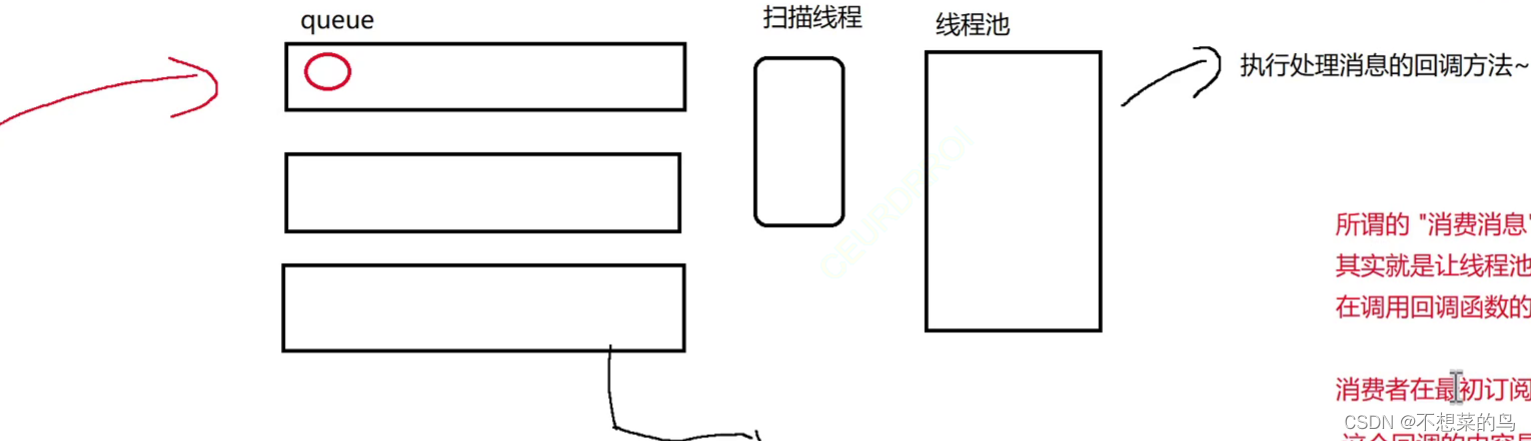
此时可能有人就会疑惑,为啥搞了扫描线程还要再搞个线程池呢,直接一个扫描线程既让他获取到消息和消费者回调,又来执行这个回调不就行了吗?原因是这样的,由于消费者给出的回调具体干什么是不一定的,可能操作就比较耗时,此时如果只有一个线程就很可能周转不开,导致后续消息处理的变慢。
还有一个问题就是当前有很多队列,但是扫描线程就一个,那么扫描线程如何知道当前是哪个队列中来了新的消息呢?一个简单粗暴的办法就是让扫描线程不停地循环遍历所有的队列,如果发现有新的元素就立即处理,如果说消息连续不断并且均匀的进入队列,这个方法还挺实用,但是如果不是这样,这个线程就会做出很多无用功。总的来说,这个方法不够优雅。更好的办法是引入一个阻塞碎裂,这个队列中的元素就是有消息的队列的队列名字,扫描线程只需要盯住这一个阻塞队列即可,此时阻塞队列中传递的队列名,就相当于“令牌”。每次拿到一个“令牌”才能从对应的队列中取一个消息。
接下来我们就通过代码来实现其中的细节:
我们创建 ConsumerManager 类来实现消费消息的核心逻辑
public class ConsumerManager {// 持有一个上层的 VirtualHost 对象的引用,用来操作数据。private VirtualHost parent;// 指定一个线程池,负责去执行具体的回调任务private ExecutorService workerPool = Executors.newFixedThreadPool(4);// 存放“令牌”的队列private BlockingQueue<String> tokenQueue = new LinkedBlockingQueue<>();// 扫描线程private Thread scannerThread = null;public ConsumerManager(VirtualHost parent) {this.parent = parent;}// 这个方法的调用时机就是发送消息的时候public void notifyConsume(String queueName) throws InterruptedException {tokenQueue.put(queueName);}
}
此时还记得之前的 sendMessage 代码吗:

此时这里的 todo 我们就可以填上了:
// 此处还需要补充一个逻辑,通知消费者可以消费消息了。consumerManager.notifyConsume(queue.getName());
接下来我们就回过头来继续实现 basicConsume 方法:
public boolean basicConsume(String consumerTag, String queueName, boolean autoAck, Consumer consumer) {// 构造一个 ConsumerEnv 对象,把这个对应的队列找到,再把这个 Consumer 对象添加到该队列中queueName = virtualHostName + queueName;try {consumerManager.addConsumer(consumerTag, queueName, autoAck, consumer);System.out.println("[VirtualHost] basicConsume 成功!queueName=" + queueName);return true;} catch (Exception e) {System.out.println("[VirtualHost] basicConsume 失败!queueName=" + queueName);e.printStackTrace();return false;}}
这里还涉及到 ConsumerManager 里的 addConsumer 方法:
public void addConsumer(String consumerTag, String queueName, boolean autoAck, Consumer consumer) throws MQException {// 找到对应的队列MSGQueue queue = parent.getMemoryDataCenter().getQueue(queueName);if (queue == null) {throw new MQException("[ConsumerManager] 队列不存在!queueName=" + queueName);}ConsumerEnv consumerEnv = new ConsumerEnv(consumerTag, queueName, autoAck, consumer);synchronized (queue) {queue.addConsumerEnv(consumerEnv);// 如果当前队列中已经有了一些消息了,需要立即就消费掉int n = parent.getMemoryDataCenter().getMessageCount(queueName);for (int i = 0; i < n; i++) {// 这个方法调用一次就消费一条消息consumeMessage(queue);}}}private void consumeMessage(MSGQueue queue) {// 1. 按照轮询的方式,找个消费者出来ConsumerEnv luckyDog = queue.chooseConsumer();if (luckyDog == null) {// 当前队列没有消费者,暂时不消费,等后面有消费者出现再说return;}// 2. 从队列中取出一个消息Message message = parent.getMemoryDataCenter().pollMessage(queue.getName());if (message == null) {// 当前队列中还没有消息,也不需要消费return;}// 3. 把消息带入到消费者的回调方法中,丢给线程池执行workerPool.submit(() ->{luckyDog.getConsumer().handleDelivery(luckyDog.getConsumerTag(), message.getBasicProperties(), message.getBody());System.out.println("[ConsumerManager] 消息被成功消费!queueName=" + queue.getName());});}
此时的 consumeMessage 还没有结束。
既然是消费消息,那我们不能避开 消息确认,也就是我们要能确保消息被正确消费掉了,也就是消费者的回调方法顺利执行完了(中间没出错,没抛异常啥的),这个时候这条消息的实名也就完成了,也就可以被删除了。否则消息就不能删,因为还要重新消费它。
那么为了达到消息不丢失的效果,我们这样处理:
- 在真正执行回调之前,我们把这个消息先放到“待确认集合”中,这样就可以避免因为回调失败导致的消息丢失。这个集合我们在 MemoryDataCenter 类中已经声明过了:

- 真正执行回调
- 当前消费者采取的是 autoAck=true,就认为回调执行完毕不抛异常就算消费成功,然后就可以删除消息了(硬盘、内存、待确认集合)。
- 当前消费者采取的是 autoAck=false,手动应答。就需要消费者这边在自己的回调方法内部,显示调用 basicAck 这个核心 api。basicAck 这个方法在 VirtualHost 中实现:
此时完善后的代码:
private void consumeMessage(MSGQueue queue) {// 1. 按照轮询的方式,找个消费者出来ConsumerEnv luckyDog = queue.chooseConsumer();if (luckyDog == null) {// 当前队列没有消费者,暂时不消费,等后面有消费者出现再说return;}// 2. 从队列中取出一个消息Message message = parent.getMemoryDataCenter().pollMessage(queue.getName());if (message == null) {// 当前队列中还没有消息,也不需要消费return;}// 3. 把消息带入到消费者的回调方法中,丢给线程池执行workerPool.submit(() ->{try {// 1. 把消息放到待确认的集合里, 这个操作势必在执行回调之前parent.getMemoryDataCenter().addMessageWaitAck(queue.getName(), message);// 2. 真正执行回调luckyDog.getConsumer().handleDelivery(luckyDog.getConsumerTag(), message.getBasicProperties(), message.getBody());// 3. 如果当前是“自动应答”,就可以直接删除消息了// 如果当前是“手动应答”,则先不处理,交给回叙消费者调用 basicAck 方法来处理if (luckyDog.isAutoAck()) {if (message.getDeliverMode() == 2) {parent.getDiskDataCenter().deleteMessage(queue, message);}parent.getMemoryDataCenter().removeMessageWaitAck(queue.getName(), message.getMessageId());// 删除内存里消息中心里的消息parent.getMemoryDataCenter().removeMessage(message.getMessageId());System.out.println("[ConsumerManager] 消息被成功消费!queueName=" + queue.getName());}} catch (Exception e) {e.printStackTrace();}});}
此时我们分析一下,当下对消息丢失的处理:

- 执行回调方法 handleDelivery 时抛异常了,后续逻辑执行不了,此时这个消息就会始终在待确认集合中,但是一直在待确认集合中也不合适。RabbitMQ 的做法是另外搞了个扫描线程(当然其实 RabbitMQ 里面不叫线程,叫进程,但是这个进程不是操作系统的进程,是 erlang 中的概念)。这个线程就负责关注这个待确认集合中每个待确认消息呆多久了,如果呆的时间超出了特定范围,就会把这个消息放到一个特定的队列“死信队列”。这个“死信队列”也是程序员手动配置的,不过这个逻辑我们此处就不实现了
- 执行回调过程中,broker server 崩溃了,内存数据全没了,但是硬盘数据还在,正在消费还没消费完的消息还存在于硬盘上,所以当 broker server 重启之后,这个消息就又被加载辉内存,就像从来没被消费过一样,消费者就有机会重新消费到这个消息。重复消费的问题,应该由消费者的业务代码负责保证,broker server 管不了。
8.9 实现 basicAck
接下来我们继续实现 basicAck:
public boolean basicAck(String queueName, String messageId) {queueName = virtualHostName + queueName;try {Message message = memoryDataCenter.getMessage(messageId);if (message == null) {throw new MQException("[VirtualHost] 要确认的消息不存在!messageId=" + messageId);}MSGQueue queue = memoryDataCenter.getQueue(queueName);if (queue == null) {throw new MQException("[VirtualHost] 要确认的队列不存在!queueName=" + queueName);}if (message.getDeliverMode() == 2) {diskDataCenter.deleteMessage(queue,message);}memoryDataCenter.removeMessage(messageId);memoryDataCenter.removeMessageWaitAck(queueName,messageId);System.out.println("[VirtualHost] basicAck 成功!queueName=" + queueName + ", messageId=" + messageId);return true} catch (Exception e) {System.out.println("[VirtualHost] basicAck 失败!queueName=" + queueName + ", messageId=" + messageId);e.printStackTrace();return false;}9. 网络通信设计
9.1 定义应用层协议
我们的消息队列不是单机程序,而是 服务器-客户端 结构的程序,要通过网络进行传输数据,基于TCP 协议,但是我们知道 TCP 只是传输层协议,于是我们基于 TCP 自定义应用层协议。
约定自定义应用层协议的协议格式:
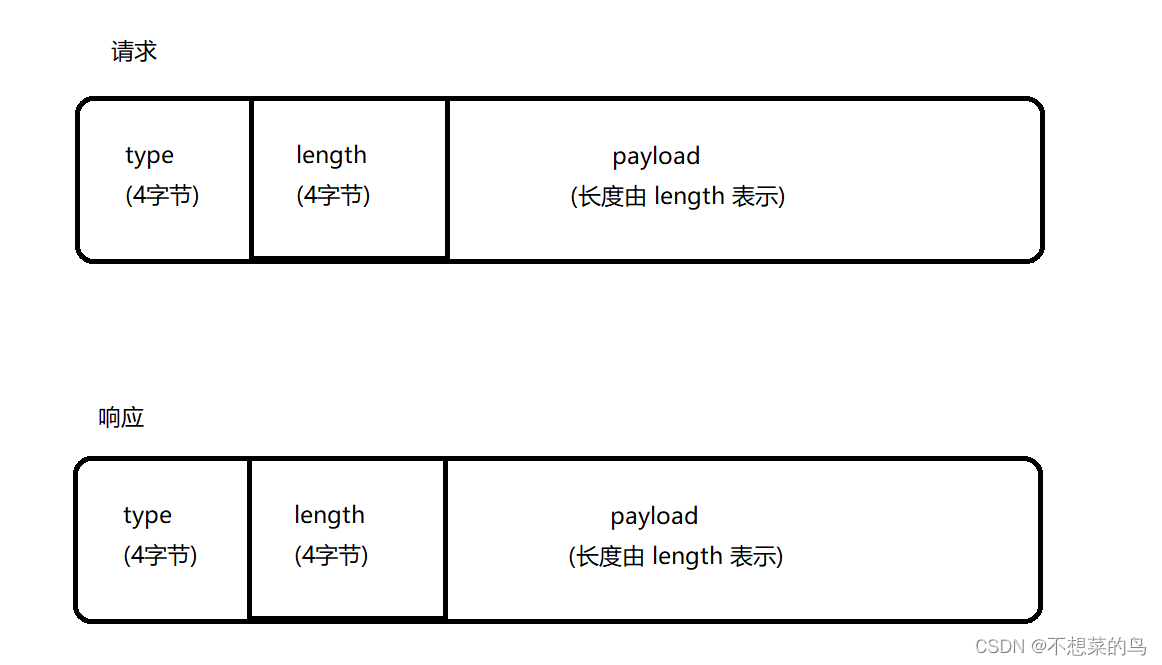
type 描述当前这个请求和响应是干啥的。在咱们的 mq 中,客户端(生产者 + 消费者)和服务器(Broker Server)之间要进行的操作就是 VirtualHost 中的那些核心 api。我们希望客户端能够通过网络远程调用上述 API,此处的 type 就是在描述当前这个请求/响应是在调用哪个 api。
针对 type,我们做出如下约定:
- 0x1 创建 channel
- 0x2 关闭 channel 关于 channel 可以回顾 1.5.2
- 0x3 创建 exchange
- 0x4 销毁 exchange
- 0x5 创建 queue
- 0x6 销毁 queue
- 0x7 创建 binding
- 0x8 销毁 binding
- 0x9 发送 message
- 0xa 订阅 message
- 0xb 返回 ack
- 0xc 服务器给客户端推送的消息。(被订阅的消息)响应独有的。
length 描述了后面的 payload的长度。
payload 会根据当前是请求还是响应以及当前的 type 而有不同的取值,举个例子:
比如 type 是 0x3(创建交换机),同时当前是一个请求,此时 payload 里的内容就相当于是 exchangeDeclare 的参数序列化的结果。
比如 type 是 0x3(创建交换机),同时当前是一个响应,此时 payload 里的内容就相当于是 exchangDeclare 的返回结果的序列化内容。
接下来就是代码实现了,我们在 common 包下定义 Request 类来表示一个网络通信的请求对象,按照自定义协议的格式来展开的:
@Data
public class Request {private int type;private int length;private byte[] payload;
}
同理,我们在搞一个 Response 类:
@Data
public class Response {private int type;private int length;private byte[] payload;
}
我们再实现一个 BasicArguments 类,使用这个类来表示方法的公共参数/辅助的字段,后续每个方法又会有一些不同的参数,不同的参数再分别使用不同的子类来表示。代码如下:
@Data
public class BasicArguments implements Serializable {// 表示一次 请求/响应 的身份标识,可以把请求和响应对上protected String rid;// 这次通信使用的 channel 的身份标识protected String channelId;
}
再实现一个 BasicReturns 类,这个类表示各个远程调用的方法的返回值的公共信息:
@Data
public class BasicReturns implements Serializable {// 用来表示唯一的请求和响应protected String rid;// 用来表示一个 channelprotected String channelId;// 表示当前这个远程调用方法的返回值protected boolean ok;
}
我们知道每个核心方法的参数是有不同的,所以我们需要给每一个需要被远程调用的方法都创建出对应的类来表示改方法中的一些相关参数,继续在 common 包下创建:
@Data
public class ExchangeDeclareArguments extends BasicArguments implements Serializable {private String exchangeName;private ExchangeType exchangeType;private boolean durable;private boolean autoDelete;private Map<String, Object> arguments;
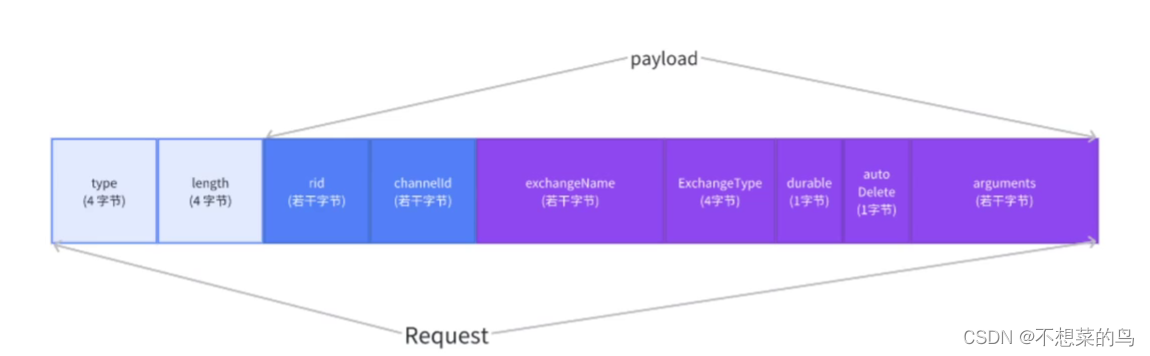
}根据上述代码,请求的报文格式就变成这样了:
这个时候我们就能在调用这个方法时,把该传递的参数传递过去:

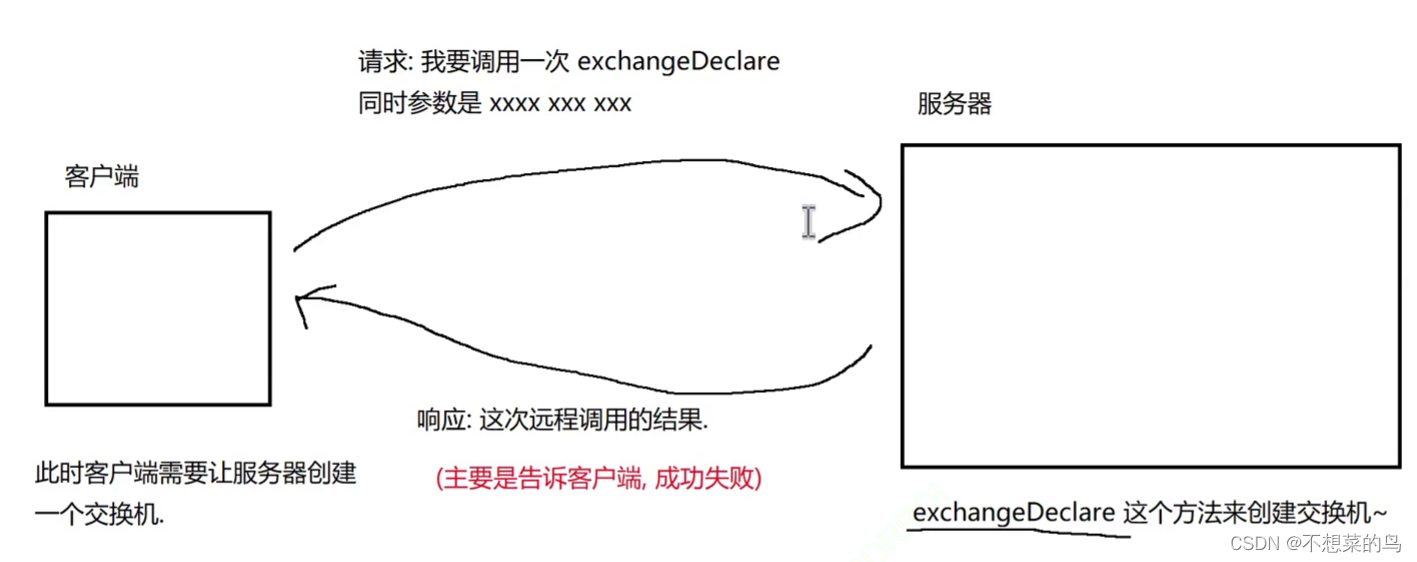
下面我们就来说明一下,创建交换机的流程,画图说明:
这里的请求报文就是上文中的图,响应其实和请求格式差不多,根据 BasicReturns 类来组成 payload:
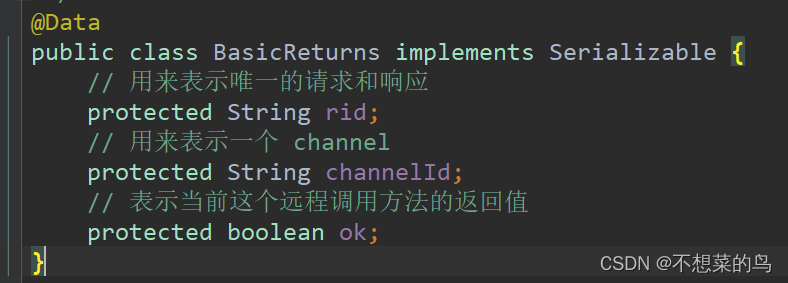
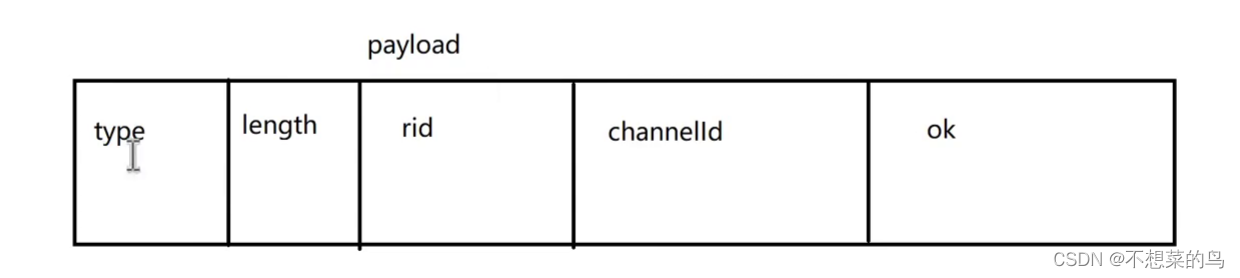
这里的 ok 就表示成功还是失败。
下面我们再来写其他的类,也是按照上述方式,也都是在 common 包下:
@Data
public class ExchangeDeleteArguments extends BasicArguments implements Serializable {private String exchangeName;
}
@Data
public class QueueDeclareArguments extends BasicArguments implements Serializable {private String queueName;private boolean durable;private boolean exclusive;private boolean autoDelete;private Map<String, Object> arguments;
}
@Data
public class QueueDeleteArguments extends BasicArguments implements Serializable {private String queueName;
}
@Data
public class QueueBindArguments extends BasicArguments implements Serializable {private String queueName;private String exchangeName;private String bindingKey;
}
@Data
public class QueueUnbindArguments extends BasicArguments implements Serializable {private String queueName;private String exchangeName;
}
@Data
public class BasicPublishArguments extends BasicArguments implements Serializable {private String exchangeName;private String routingKey;private BasicProperties basicProperties;private byte[] body;
}
补充:序列化相关
注意,我们这里只讲知识,不讲代码如何使用。
JSON 是 一种基于文本的数据交换格式,它的设计初衷是为了方便在不同的系统和编程语言之间传输和共享数据。JSON 本身只支持字符串、数字、布尔值、数组和对象等数据类型,不能直接表示二进制数据,因此在序列化二进制数据时需要将其转换成字符串,然后再进行序列化。这个过程会导致数据的大小增加,同时也会增加序列化和反序列化的时间和计算成本,因此不太方便。
另外,JSON 的编码和解码是基于 Unicode 字符集的,而二进制数据中可能包含不合法的 Unicode 字符,这也会导致在序列化和反序列化时出现问题。为了解决这个问题,需要对二进制数据进行编码和解码处理,这进一步增加了序列化和反序列化的复杂度。
相比之下,一些专门针对二进制数据的序列化格式,比如 Protocol Buffers 和 MessagePack,可以更高效地序列化和反序列化二进制数据,并且支持更多的数据类型和数据结构。
Protocol Buffers 和 MessagePack 都是高效的二进制数据序列化格式,它们比 JSON 更适合处理二进制数据。它们的设计目的是为了在不同的系统和编程语言之间高效地传输和共享数据,在序列化和反序列化的过程中可以大大减少数据大小和计算成本。
Protocol Buffers 是由 Google 开发的一种二进制数据序列化格式,它的特点是高效、紧凑、可扩展、跨语言等。使用 Protocol Buffers 可以定义数据结构的格式和字段,然后通过编译器生成对应的代码,实现快速的序列化和反序列化。Protocol Buffers 支持多种编程语言,包括 Java、C++、Python、Go、Ruby 等。
MessagePack 是一种开源的二进制数据序列化格式,它的设计目标是简单、高效、快速、小巧,可以在多种编程语言和平台之间快速地传输数据。MessagePack 的数据格式类似于 JSON,但是采用二进制表示,可以更快速地进行序列化和反序列化。MessagePack 支持多种编程语言,包括 Java、C++、Python、Ruby、PHP 等。
需要注意的是,虽然 Protocol Buffers 和 MessagePack 可以更高效地处理二进制数据,但是它们的使用也需要根据具体的场景和需求进行选择。在处理文本数据、简单数据结构或者需要跨平台和跨语言传输的数据时,JSON 仍然是一种很好的选择。
java 标准库提供的针对二进制序列化的方案:
Java 标准库提供了两种针对二进制序列化的方案:Java 序列化和外部可重用的二进制数据序列化格式(Externalizable)。
Java 序列化
Java 序列化是一种将 Java 对象序列化成二进制数据的机制,它可以将 Java 对象转换成字节流并进行传输或持久化。Java 序列化是 Java 标准库提供的一种序列化方式,它可以序列化任意实现了 Serializable 接口的 Java 对象,并且支持对象的嵌套和循环引用。
Java 序列化的使用非常简单,只需要让需要序列化的 Java 对象实现 Serializable 接口即可,然后使用 ObjectOutputStream 进行序列化,使用 ObjectInputStream 进行反序列化。但是需要注意的是,Java 序列化的性能和序列化后的数据大小通常都不如专门针对二进制数据序列化的格式。
外部可重用的二进制数据序列化格式
Java 标准库还提供了一种被称为 Externalizable 的接口,它允许 Java 对象通过实现 writeExternal 和 readExternal 方法来手动控制对象的序列化和反序列化。与 Serializable 接口不同的是,Externalizable 接口需要程序员显式地定义对象的序列化方式,这样可以更加精细地控制序列化的过程,从而实现更高效的序列化和反序列化。
Java 序列化和 Externalizable 适用于以下情况:
-
对象的序列化和反序列化比较简单,不需要进行特殊的处理。
-
需要存储或传输的对象比较小,或者需要存储或传输的对象数量比较少。
-
应用场景对性能要求不高,或者对数据的大小没有明确的限制。
-
对象的结构比较简单,没有复杂的嵌套关系或循环引用关系。
对象需要进行兼容性处理,即可以在不同版本的程序之间进行序列化和反序列化,或者可以在不同的平台和编程语言之间进行传输。
需要注意的是,虽然 Java 序列化和 Externalizable 都可以实现 Java 对象的二进制序列化,但是它们并不是专门针对二进制序列化的格式。因此,在需要高效处理二进制数据的场景下,可以选择使用其他专门针对二进制序列化的格式,比如 Protocol Buffers、MessagePack、Avro 等。