ultralytics仓库使用自己的数据集训练RT-DETR
RT-DETR由百度开发,是一款尖端的端到端物体检测器(基于transformer架构),在提供实时性能的同时保持高精度。它利用视觉变换器(ViT)的力量,通过解耦尺度内交互和跨尺度融合来高效处理多尺度特征。RT-DETR具有很强的适应性,支持使用不同解码器层灵活调整推理速度,而无需重新训练。
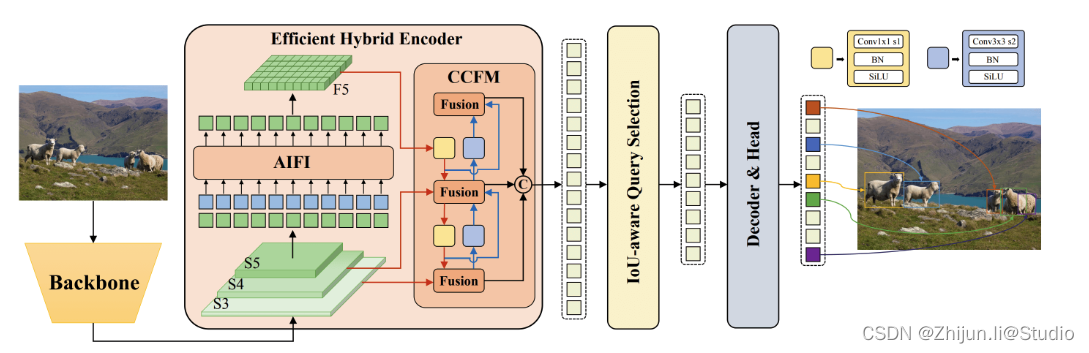
相关指标如下所示:
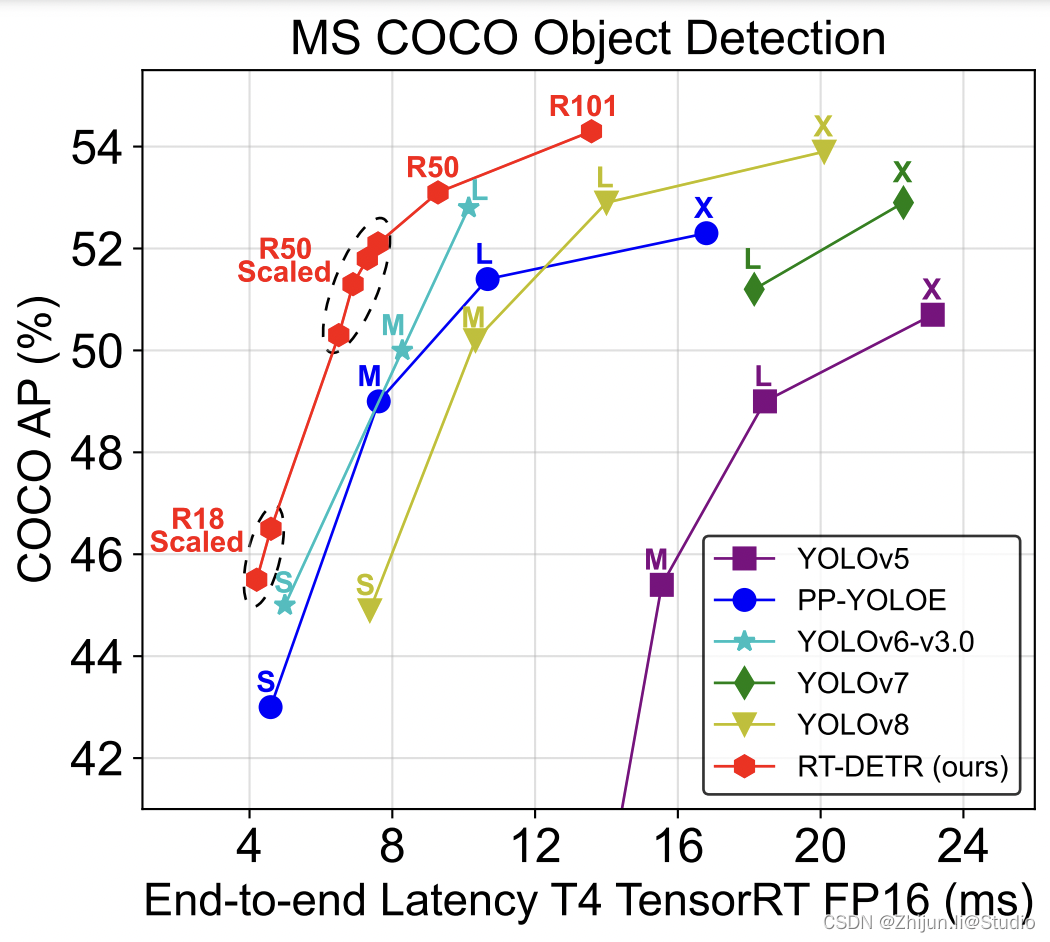
ultralytics相关文档:https://docs.ultralytics.com/models/rtdetr/
一、数据准备
使用labelimg标注后的数据格式准备如下:
.
├── ./data-heidian
│ ├── ./data-heidian/Annotations
│ │ ├── ./data-heidian/Annotations/fall_0.xml
│ │ ├── ./data-heidian/Annotations/fall_1000.xml
│ │ ├── ...
│ ├── ./data-heidian/images
│ │ ├── ./data-heidian/images/fall_0.jpg
│ │ ├── ./data-heidian/images/fall_1000.jpg
│ │ ├── ...
二、查看标签列表
注意修改indir = 'data-heidian/Annotations'这个路径,得到标签列表
import os
from unicodedata import name
import xml.etree.ElementTree as ET
import globdef count_num(indir):label_list = []# 提取xml文件列表os.chdir(indir)annotations = os.listdir('.')annotations = glob.glob(str(annotations) + '*.xml')dict = {} # 新建字典,用于存放各类标签名及其对应的数目for i, file in enumerate(annotations): # 遍历xml文件# actual parsingin_file = open(file, encoding='utf-8')tree = ET.parse(in_file)root = tree.getroot()# 遍历文件的所有标签for obj in root.iter('object'):name = obj.find('name').textif (name in dict.keys()):dict[name] += 1 # 如果标签不是第一次出现,则+1else:dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1# 打印结果print("各类标签的数量分别为:")for key in dict.keys():print(key + ': ' + str(dict[key]))label_list.append(key)print("标签类别如下:")print(label_list)if __name__ == '__main__':# xml文件所在的目录,修改此处indir = 'data-heidian/Annotations'count_num(indir) # 调用函数统计各类标签数目
三、生成xml对应的txt
import os
import os.path
import xml.etree.ElementTree as ETclass_names = ['big_gray', 'gray', 'line', 'big_black', 'black', 'sandian']
dirpath = 'data-heidian/Annotations'
newdir = 'data-heidian/labels'if not os.path.exists(newdir):os.makedirs(newdir)for fp in os.listdir(dirpath):root = ET.parse(os.path.join(dirpath, fp)).getroot()xmin, ymin, xmax, ymax = 0, 0, 0, 0sz = root.find('size')width = float(sz[0].text)height = float(sz[1].text)filename = root.find('filename').texttxt_filename = os.path.join(newdir, fp.split('.')[0] + '.txt')with open(txt_filename, 'a+') as f:for child in root.findall('object'):name = child.find('name').textclass_num = class_names.index(name)sub = child.find('bndbox')xmin = float(sub[0].text)ymin = float(sub[1].text)xmax = float(sub[2].text)ymax = float(sub[3].text)try:x_center = (xmin + xmax) / (2 * width)y_center = (ymin + ymax) / (2 * height)w = (xmax - xmin) / widthh = (ymax - ymin) / heightexcept ZeroDivisionError:print(filename, '的 width有问题')f.write(' '.join([str(class_num), str(x_center), str(y_center), str(w), str(h) + '\n']))# If no objects were found, create an empty .txt fileif root.findall('object') == []:open(txt_filename, 'a').close()四、生成ultralytics训练所需的coco8格式
import os
import random
import shutil# 图片文件夹路径和对应的 txt 文件夹路径
image_folder = 'data-heidian/images'
txt_folder = 'data-heidian/labels'# 创建 coco8-data 文件夹,如果已存在则报错提示删除
output_folder = 'coco8-data'
if os.path.exists(output_folder):raise ValueError(f"Folder '{output_folder}' already exists. Please remove it first.")
os.mkdir(output_folder)# 在 coco8-data 下创建 images 和 labels 文件夹
images_folder = os.path.join(output_folder, 'images')
labels_folder = os.path.join(output_folder, 'labels')
os.mkdir(images_folder)
os.mkdir(labels_folder)# 在 images 和 labels 下分别创建 train 和 val 文件夹
train_images_folder = os.path.join(images_folder, 'train')
val_images_folder = os.path.join(images_folder, 'val')
os.mkdir(train_images_folder)
os.mkdir(val_images_folder)train_labels_folder = os.path.join(labels_folder, 'train')
val_labels_folder = os.path.join(labels_folder, 'val')
os.mkdir(train_labels_folder)
os.mkdir(val_labels_folder)# 获取图片文件和 txt 文件的列表
image_files = sorted([f for f in os.listdir(image_folder) if f.lower().endswith(('.jpg', '.png', '.jpeg'))])
txt_files = sorted([f for f in os.listdir(txt_folder) if f.lower().endswith('.txt')])# 随机打乱数据顺序
random.shuffle(image_files)
random.shuffle(txt_files)# 划分数据集
split_ratio = 0.8 # 8:2 比例
split_index = int(len(image_files) * split_ratio)
train_image_files = image_files[:split_index]
val_image_files = image_files[split_index:]# 移动图片和对应的 txt 到训练集和验证集文件夹
for image_file in train_image_files:shutil.copy(os.path.join(image_folder, image_file), os.path.join(train_images_folder, image_file))txt_file = os.path.splitext(image_file)[0] + '.txt'if txt_file in txt_files:shutil.copy(os.path.join(txt_folder, txt_file), os.path.join(train_labels_folder, txt_file))for image_file in val_image_files:shutil.copy(os.path.join(image_folder, image_file), os.path.join(val_images_folder, image_file))txt_file = os.path.splitext(image_file)[0] + '.txt'if txt_file in txt_files:shutil.copy(os.path.join(txt_folder, txt_file), os.path.join(val_labels_folder, txt_file))print("Data splitting and copying completed.")五、新建coco8.yaml
在data-heidian目录下新建一个coco8.yaml的文件,注意修改自己的路径和标签名(建议绝对路径)
coco8.yaml是ultralytics定义的一个用于快速训练的测试文件,按着这个要求修改即可
# Ultralytics YOLO 🚀, AGPL-3.0 license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Example usage: yolo train data=coco8.yaml
# parent
# ├── ultralytics
# └── datasets
# └── coco8 ← downloads here (1 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/lzj/xxx/coco8-data # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)# Classes
names:0: big_gray1: gray2: line3: big_black4: black5: sandian六、开始训练
yolo task=detect mode=train model=rtdetr-l.pt data=data-heidian/coco8.yaml batch=2 epochs=100 imgsz=1280 workers=8 device=0 single_cls=False
相关的配置参数与yolov8训练基本一致,具体细节后面再加以补充~

![[git] git基础知识](https://img-blog.csdnimg.cn/fc5274d6c7af4208bd83544644ef01bc.png)