MIT 6.830数据库系统 -- lab six
- 项目拉取
- 引言
- steal/no-force策略
- redo log与undo log
- 日志格式和检查点
- 开始
- 回滚
- 练习1:LogFile.rollback()
- 恢复
- 练习2:LogFile.recover()
- 测试结果
- 疑问点分析
项目拉取
原项目使用ant进行项目构建,我已经更改为Maven构建,大家直接拉取我改好后的项目即可:
- https://gitee.com/DaHuYuXiXi/simple-db-hw-2021
然后就是正常的maven项目配置,启动即可。各个lab的实现,会放在lab/分支下。
引言
在本实验中,我们将要实现基于日志的中止回滚和崩溃恢复。源码中提供了定义日志格式的代码,并在事务期间的适当时间将记录附加到日志文件中。我们将使用日志文件的内容完成回滚和恢复。
源码中提供的日志代码产生了用于物理上整页undo和redo的记录。当页是首次读入时,代码记住了整页的原始内容做为前置镜像。当事务更新页时,相应的日志记录包含已存储的前置镜像以及修改后的页面做为后置镜像。我们将使用前置镜像在中止期间进行回滚,在recovery期间undo丢失的事务,后置镜像用于在recovery期间redo成功的事务。
我们可以不做整个页面的物理撤销(那么ARIES必须做逻辑撤销),因为我们正在做页面级别的锁定,并且因为我们没有索引,在撤销时索引的结果可能与最初编写日志时的结构不同。页面级锁定简化事情的原因是,如果一个事务修改了一个页面,那么它一定有一个排他锁,这意味着没有其他事务同时修改它,因此我们可以通过覆盖整个页面来撤销对它的修改。
BufferPool已经实现了通过删除脏页来中止事务,并且通过强制在提交时将脏页刷新至磁盘来假装实现原子提交。日志允许更加灵活的缓冲区管理(STEAL & NO-FORCE),测试代码会在特定的时机调用BufferPool.flushAllPages()方法来验证这种灵活性
steal/no-force策略
lab6要实现的是simpledb的日志系统,以支持回滚和崩溃恢复;在lab4事务中,我们并没有考虑事务执行过程中,如果机器故障或者停电了数据丢失的问题,bufferpool采用的是no-steal/force的策略,而这个实验我们实现的是steal/no-force策略,两种策略的区别如下:
- steal/no-steal: 是否允许一个uncommitted的事务将修改更新到磁盘
- 如果是steal策略,那么此时磁盘上就可能包含uncommitted的数据,因此系统需要记录undo log,以防事务abort时进行回滚(roll-back)。
- 如果是no steal策略,就表示磁盘上不会存在uncommitted数据,因此无需回滚操作,也就无需记录undo log。
- force/no-force:
- force策略表示事务在committed之后必须将所有更新立刻持久化到磁盘,这样会导致磁盘发生很多小的写操作(更可能是随机写)。
- no-force表示事务在committed之后可以不立即持久化到磁盘, 这样可以缓存很多的更新批量持久化到磁盘,这样可以降低磁盘操作次数(提升顺序写),但是如果committed之后发生crash,那么此时已经committed的事务数据将会丢失(因为还没有持久化到磁盘),因此系统需要记录redo log,在系统重启时候进行前滚(roll-forward)操作。
redo log与undo log
为了支持steal/no-force策略,即我们可以将未提交事务的数据更新到磁盘,也不必在事务提交时就一定将修改的数据刷入磁盘,我们需要用日志来记录一些修改的行为。在simpledb中,日志不区分redo log和undo log,格式较为简单,也不会记录事务执行过程中对记录的具体修改行为。
对于redo log,为确保事务的持久性,redo log需要事务操作的变化,simpledb中用UPDATE格式的日志来保存数据的变化,在每次将数据页写入磁盘前需要用logWrite方法来记录变化:
public synchronized void logWrite(TransactionId tid,Page before,Page after)
这样,对于这些脏页,即使断电丢失数据了,我们也可以通过事务id来判断事务是否已经提交(这里提交事务会记录另一种格式的日志),如果事务已经提交,则重启时根据日志的内容就可以把数据恢复了;总而言之,通过这样的方式,可以让simpledb支持崩溃恢复;
对于undo log,我们采用的是在page中使用一个变量oldData保存一份当前页旧的快照数据:
public abstract class BTreePage implements Page {...protected byte[] oldData;
}public class BTreeRootPtrPage implements Page {...private byte[] oldData;
}public class HeapPage implements Page {...byte[] oldData;
}
数据页一开始的旧数据是空的,那什么时候会对旧数据进行更新呢?答案是事务提交时,当事务提交时,就意味着这个修改已经是持久化到磁盘了,新的事务修改后就数据页的数据就是脏数据了,而在新事务回滚时,由于我们采用的是steal策略,脏页可能已经在页面淘汰时被写入磁盘中了,那么该如何进行恢复呢?答案是before-image,即oldData,通过上一次成功事务的数据,我们可以恢复到事务开始前的样子,这样,就可以实现了事务的回滚了。
日志格式和检查点
simpleDB日志相关逻辑主要集中在LogFile中,本节我们来看看simpleDB中几种日志格式和checkpoint机制。
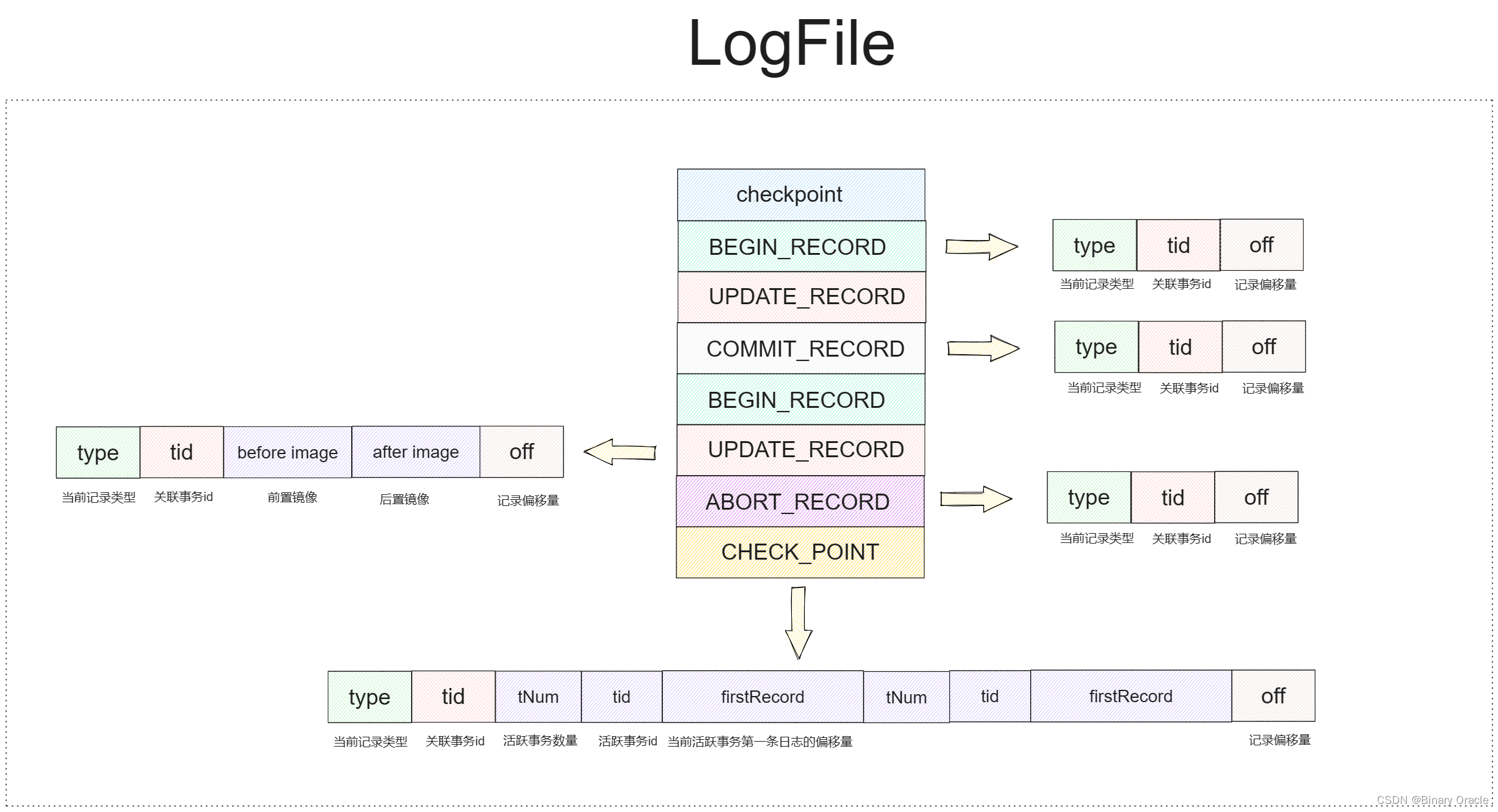
log file的格式如下所述:
-
日志文件格式概述:
- 文件中的第一个长整数表示上次写入的检查点的偏移量,如果没有检查点则为 -1。
- 文件中的其余数据由日志记录组成,这些记录的长度可变。
-
日志记录格式:
- 每个日志记录以一个整数类型和一个长整数事务 ID 开始。
- 每个日志记录以表示记录开始位置的长整数文件偏移量结束。
-
五种记录类型:
- ABORT(中止)、COMMIT(提交) 和 BEGIN(开始) 记录不包含额外数据。
- UPDATE(更新) 记录由两个条目组成:before image 和 after image。这些image是序列化的 Page 对象,可以使用
LogFile.readPageData()和LogFile.writePageData()方法访问。详见LogFile.print()的示例。 - CHECKPOINT(检查点) 记录包含在检查点时处于活动状态的事务以及它们在磁盘上的第一条日志记录。记录的格式包括事务数量的整数计数,以及每个活动事务的长整数事务 ID 和长整数第一条记录偏移量。
开始
我们必须在lab5代码的基础上实现lab6,我们需要修改现存的部分代码并且添加一些新文件:
我们的代码需要做出如下改变:
1、向BufferPool.flushPage()方法中调用writePage(p)方法之前的位置插入如下代码,其中p是被写入页的引用:
private synchronized void flushPage(PageId pid) throws IOException {Page flush = pageCache.get(pid);// 通过tableId找到对应的DbFile,并将page写入到对应的DbFile中int tableId = pid.getTableId();DbFile dbFile = Database.getCatalog().getDatabaseFile(tableId);// append an update record to the log, with a before-image and after-imageTransactionId dirtier = flush.isDirty();if (dirtier != null) {Database.getLogFile().logWrite(dirtier, flush.getBeforeImage(), flush);Database.getLogFile().force();}// 将page刷新到磁盘dbFile.writePage(flush);flush.markDirty(false, null);}
上述代码可以使日志系统向日志中写入一条update记录;调用force()方法是为了确保在脏页刷新到磁盘之前日志记录先记录到磁盘中
2、在updateBufferPool中记录当前事务修改产生的脏页:
private void updateBufferPool(List<Page> pages, TransactionId tid) throws DbException {for (Page page : pages) {page.markDirty(true, tid);}// 记录当前事务修改产生的脏页Database.getTransactionById(tid).addDirtyPages(pages);}
3、BufferPool.transactionComplete()方法为已提交事务污染的每个页调用flushPage()方法;对每个脏页,在刷新完成之后添加p.setBeforeImage()调用:
/*** Write all pages of the specified transaction to disk.* 该方法只有在事务正常提交时才会被调用,从而将当前事务已经修改的部分数据页同步到磁盘*/public synchronized void flushPages(TransactionId tid) throws IOException {// some code goes here// not necessary for lab1|lab2// 当前事务修改产生的脏页集合可能在事务没有提交前就已经落盘了 -- no steal mode// 但是落盘时记录的Before Image是事务开启前的旧数据,此时事务提交了,需要更新Before Image到最新状态for (Page page : Database.getTransactionById(tid).getDirtyPages()) {// use current page contents as the before-image for the next transaction that modifies this page.page.setBeforeImage();flushPage(page.getId());}}
这部分代码可能与网上大多数人做法不同,具体大家可以拉取源码仓库查看。
当一个更新提交后,页的前置镜像也需要更新,以便稍后中止的事务回滚到次提交的页面版本
注意:
- 我们不能仅在
flushPage()方法中调用setBeforeImage()方法,因为即使事务没有被提交flushPage()方法也可能被调用。- 测试代码就会做这样的事,如果我们通过调用
flushPages()来实现transactionComplete()方法,那么我们可能需要向flushPages()传递额外的参数去告诉这个方法该刷新是用于提交还是未提交的事务。- 但是,强烈建议在本案例中重写
transactionComplete()方法直接调用flushPage()
当做完上述代码的修改之后,我们可以进行LogTest系统测试,此时我们会发现可以通过其中三个子测试,剩余的测试会失败:
% ant runsystest -Dtest=LogTest...[junit] Running simpledb.systemtest.LogTest[junit] Testsuite: simpledb.systemtest.LogTest[junit] Tests run: 10, Failures: 0, Errors: 7, Time elapsed: 0.42 sec[junit] Tests run: 10, Failures: 0, Errors: 7, Time elapsed: 0.42 sec[junit] [junit] Testcase: PatchTest took 0.057 sec[junit] Testcase: TestFlushAll took 0.022 sec[junit] Testcase: TestCommitCrash took 0.018 sec[junit] Testcase: TestAbort took 0.03 sec[junit] Caused an ERROR[junit] LogTest: tuple present but shouldn't be...
如果通过的测试少于这三个子测试的话,说明我们对已有代码的修改并不兼容,我们需要解决这些问题
回滚
阅读LogFile.java文件中对于日志文件格式描述的注释;我们可以在LogFile.java文件中看到一系列函数,例如logCommit(),它用于生成各种类型的日志记录并添加到日志中。
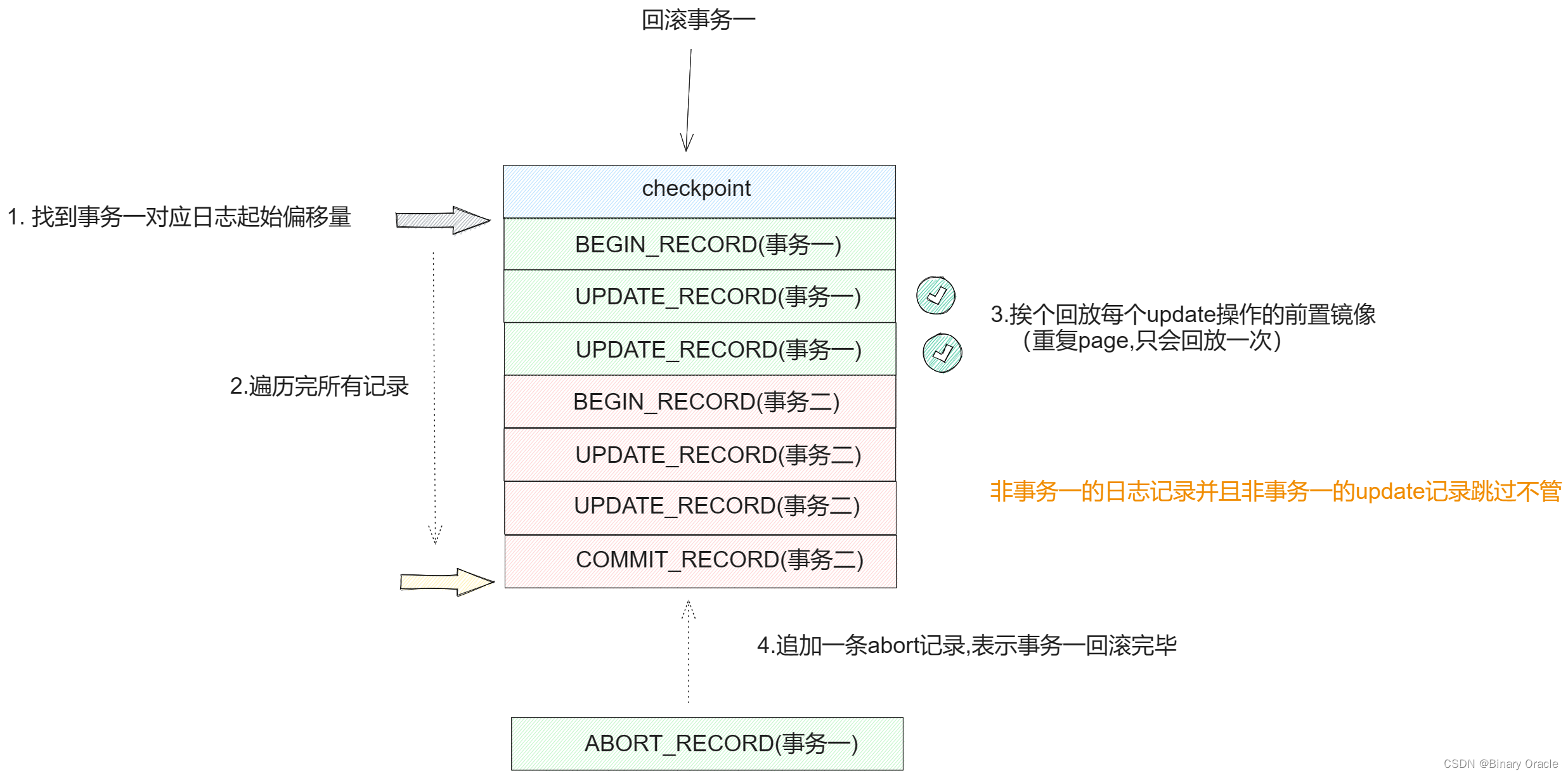
我们的第一个任务是实现LogFile.java的rollback()函数。当事务中止时,并且事务释放掉它的锁之前会调用该函数。它的任务就是撤销事务对数据库可能的更改。
rollback()方法需要读取日志文件,查找所有的与中止事务有关的更新记录,从每条记录中提取前置镜像,并且将前置镜像写入表文件。使用raf.seek()在日志文件中进行范围移动,并且使用raf.readInt()等方法进行检验。使用readPageData()方法读取前置和后置镜像。我们可以使用tidToFirstLogRecord映射(从事务id映射到堆文件中的偏移量)确定对于一个特定的事务从哪开始读取日志文件。在将前置镜像写回表文件之前,我们需要丢弃缓冲池中缓存的对应的页。
在开发期间,Logfile.print()方法对于展示现在的日志内容非常有用。
练习1:LogFile.rollback()
实现LogFile.rollback()方法。
代码编写完成后我们需要通过LogTest系统测试的TestAbort和TestAbortCommitInterleaved子测试。
实现代码如下所示:
public void rollback(TransactionId tid)throws NoSuchElementException, IOException {synchronized (Database.getBufferPool()) {synchronized (this) {preAppend();// some code goes here// 获取事务tid对应的日志记录偏移量Long offset = tidToFirstLogRecord.get(tid.getId());// 读取日志记录raf.seek(offset);Set<PageId> pageIdSet = new HashSet<>();// 前置判断,判断raf是否已经遍历到末尾while (raf.getFilePointer() != raf.length()) {int type = raf.readInt();long transactionId = raf.readLong();if (transactionId != tid.getId()) {continue;}// 前置判断,判断日志记录类型是否为包含前置镜像和后置镜像的UPDATE类型if (type == UPDATE_RECORD) {// 读取事务对应页的前置镜像,并根据前置镜像进行回滚Page before = readPageData(raf);Page after = readPageData(raf);// 前置镜像idPageId pid = before.getId();// 确保记录的事务id和当前回滚的事务的id相等// 并且该页面此前没有进行过回滚,如果进行过回顾则无需重复回滚if (transactionId == tid.getId() && !pageIdSet.contains(pid)) {pageIdSet.add(pid);// 丢弃BufferPool中事务对应的pidDatabase.getBufferPool().discardPage(pid);// 将前置镜像写回表文件Database.getCatalog().getDatabaseFile(pid.getTableId()).writePage(before);}} else if (type == CHECKPOINT_RECORD) {int count = raf.readInt();while (count-- > 0) {raf.readLong();raf.readLong();}}raf.readLong();}// 将raf的文件指针指向正确的偏移位置raf.seek(raf.length());}}}
恢复
如果数据库崩溃并且重启,在任何新事务开始前会调用LogFile.recover()方法。我们的实现必须满足如下条件:
- 如果有最后一个检查点的话需要读取最后一个检查点
- 从检查点开始向前扫描日志文件(如果没有检查点则从日志文件开始扫描)以建立失败事务集合。重做已提交事务的更新操作。我们可以放心在检查点开始redo,因为
LogFile.logCheckpoint()方法将所有的脏页都刷新到磁盘了 - 撤销失败事务的更新
练习2:LogFile.recover()
实现LogFile.recover()方法。
完成本次练习后,需要通过LogTest的所有子测试:
再完成本练习之前,我们先来看一下lab中已经为我们提供好的checkpoint方法是如何实现的:
-
写入检查点记录
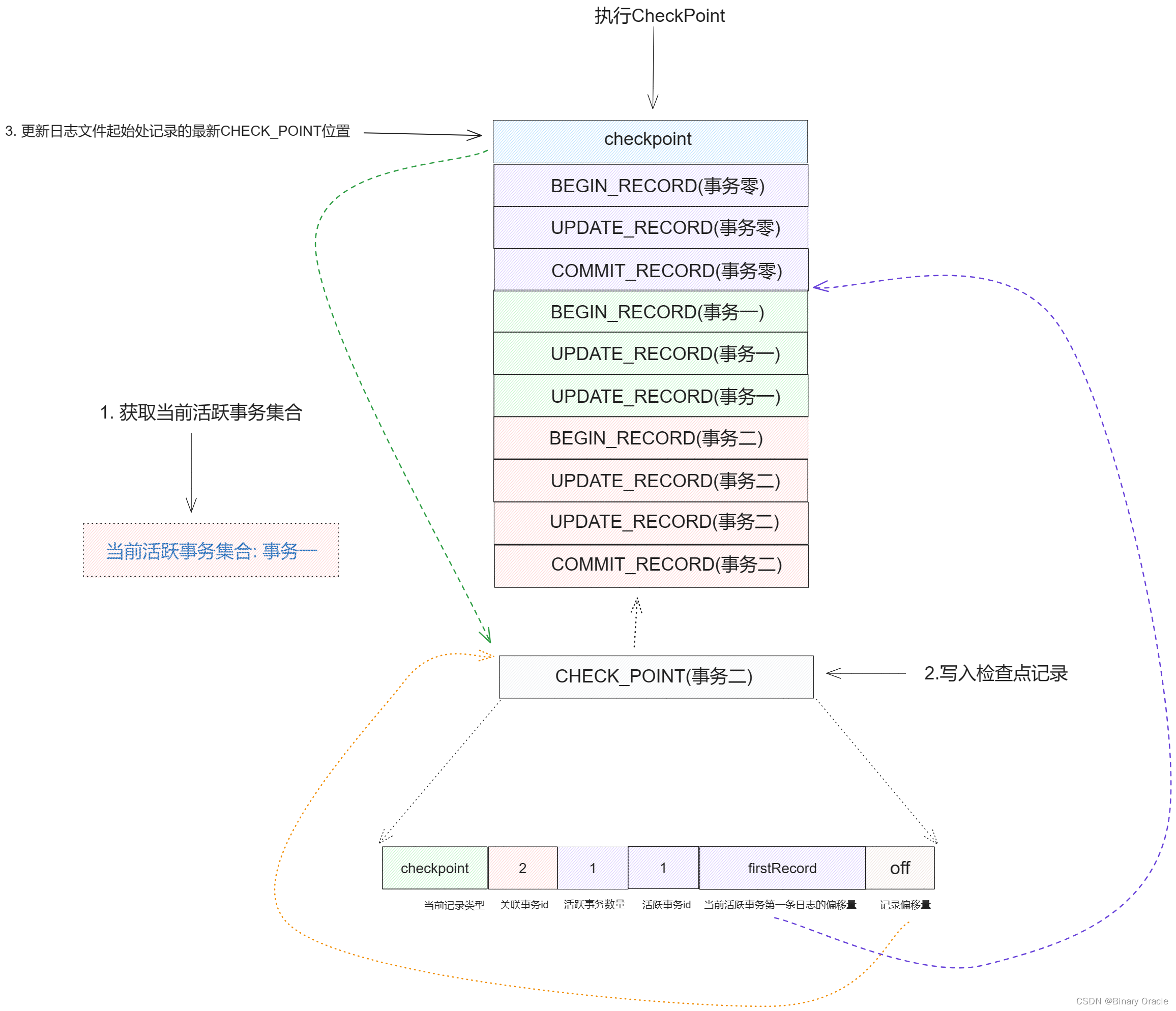
-
缩减无用日志
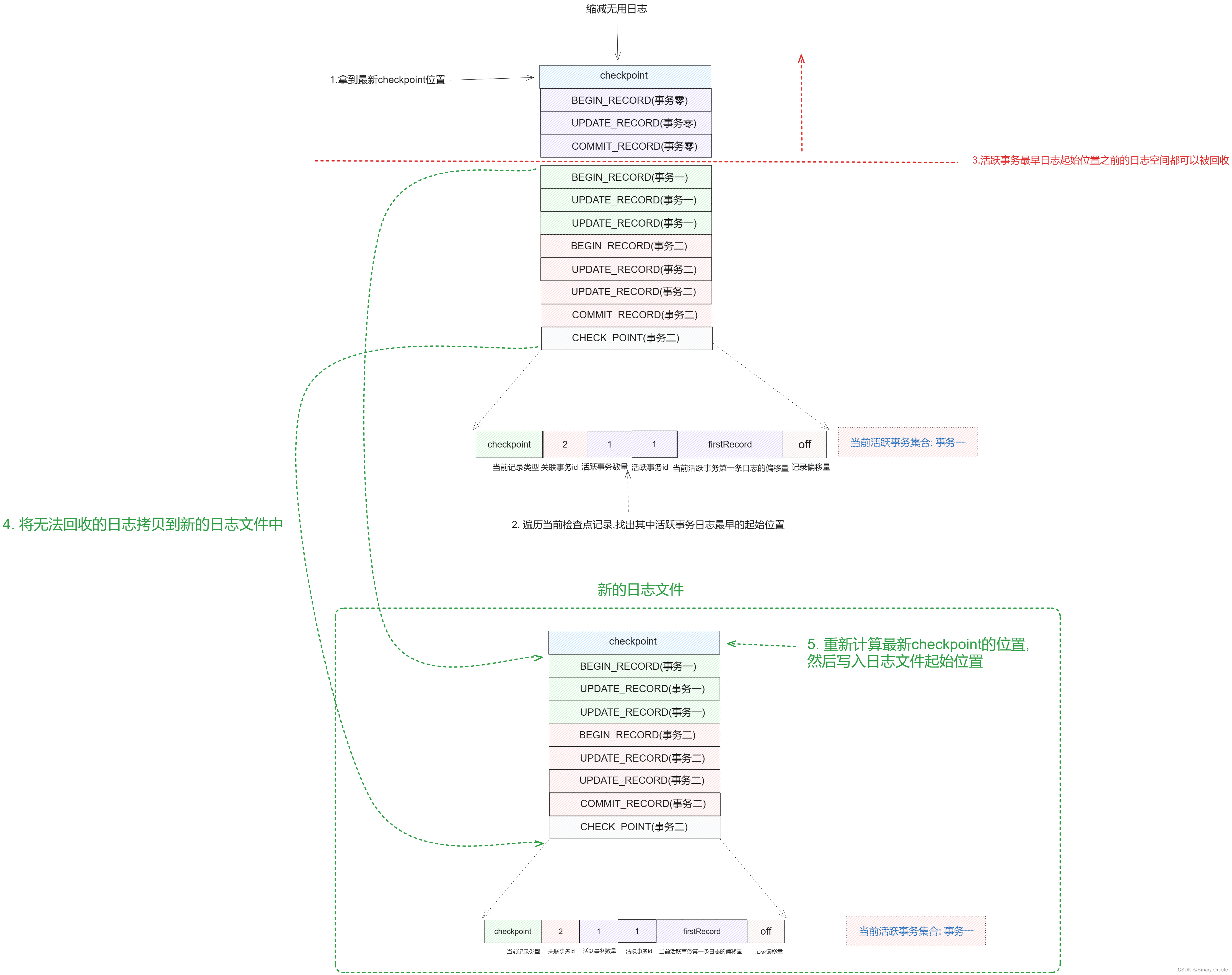
logCheckpoint方法源码大家可自行查看,这里不再多述,下面我们来看一下recover方法的源码:
/*** Recover the database system by ensuring that the updates of* committed transactions are installed and that the* updates of uncommitted transactions are not installed.*/public void recover() throws IOException {synchronized (Database.getBufferPool()) {synchronized (this) {recoveryUndecided = false;// some code goes hereraf.seek(0);// 已提交事务集合Set<Long> commitId = new HashSet<>();// 事务id-前置镜像Map<Long, List<Page>> beforePages = new HashMap<>();// 事务id-后置镜像Map<Long, List<Page>> afterPages = new HashMap<>();// 记录checkpoint时间点所有活跃的事务,判断是回滚还是重放Map<Long, Long> activeTransactions = new HashMap<>();// 获取最新checkpoint位置long checkpoint = raf.readLong();// 定位到最新的checkpoint位置if (checkpoint != -1) {raf.seek(checkpoint);}// 前置判断,判断raf是否已经遍历到末尾while (raf.getFilePointer() != raf.length()) {int type = raf.readInt();long tid = raf.readLong();if (type == UPDATE_RECORD) {Page before_image = readPageData(raf);Page after_image = readPageData(raf);List<Page> before = beforePages.getOrDefault(tid, new ArrayList<>());before.add(before_image);beforePages.put(tid, before);List<Page> after = afterPages.getOrDefault(tid, new ArrayList<>());after.add(after_image);afterPages.put(tid, after);} else if (type == COMMIT_RECORD) {// 可能会包含checkpoint发生时的活跃事务的提交记录commitId.add(tid);} else if (type == CHECKPOINT_RECORD) {int count = raf.readInt();while (count-- > 0) {activeTransactions.put(raf.readLong(), raf.readLong());}}raf.readLong();}// 处理未提交的事务for (Long tid : beforePages.keySet()) {if (!commitId.contains(tid)) {List<Page> pages = beforePages.get(tid);for (Page page : pages) {Database.getCatalog().getDatabaseFile(page.getId().getTableId()).writePage(page);}}}// 处理已提交的事务for (Long tid : commitId) {if (afterPages.containsKey(tid)) {List<Page> pages = afterPages.get(tid);for (Page page : pages) {Database.getCatalog().getDatabaseFile(page.getId().getTableId()).writePage(page);}}}// 处理checkpoint点发生时的活跃事务,判断是提交还是回滚for (Map.Entry<Long, Long> entry : activeTransactions.entrySet()) {Long transactionId = entry.getKey();Long offset = entry.getValue();// 当前活跃事务重放还是回滚取决于当前活跃事务在checkpoint后是否提交了// 如果提交了,那么重放,否则回滚recoveryOrRollbackByOffset(new TransactionId(transactionId), offset, commitId.contains(transactionId));}}}}private void recoveryOrRollbackByOffset(TransactionId transactionId, Long offset,boolean recover) throws IOException {raf.seek(offset);while (raf.getFilePointer() != raf.length()) {int type = raf.readInt();long tid = raf.readLong();if (type == UPDATE_RECORD) {Page before_image = readPageData(raf);Page after_image = readPageData(raf);Page targetPage = recover ? after_image : before_image;if(tid == transactionId.getId()) {Database.getCatalog().getDatabaseFile(targetPage.getId().getTableId()).writePage(targetPage);}} else if (type == CHECKPOINT_RECORD) {int count = raf.readInt();while (count-- > 0) {raf.readLong();raf.readLong();}}raf.readLong();}}
奔溃恢复过程不算难,但是需要对checkpoint点的活跃事务进行特殊处理:
-
活跃事务一在checkpoint后commit了,处理情况如下:
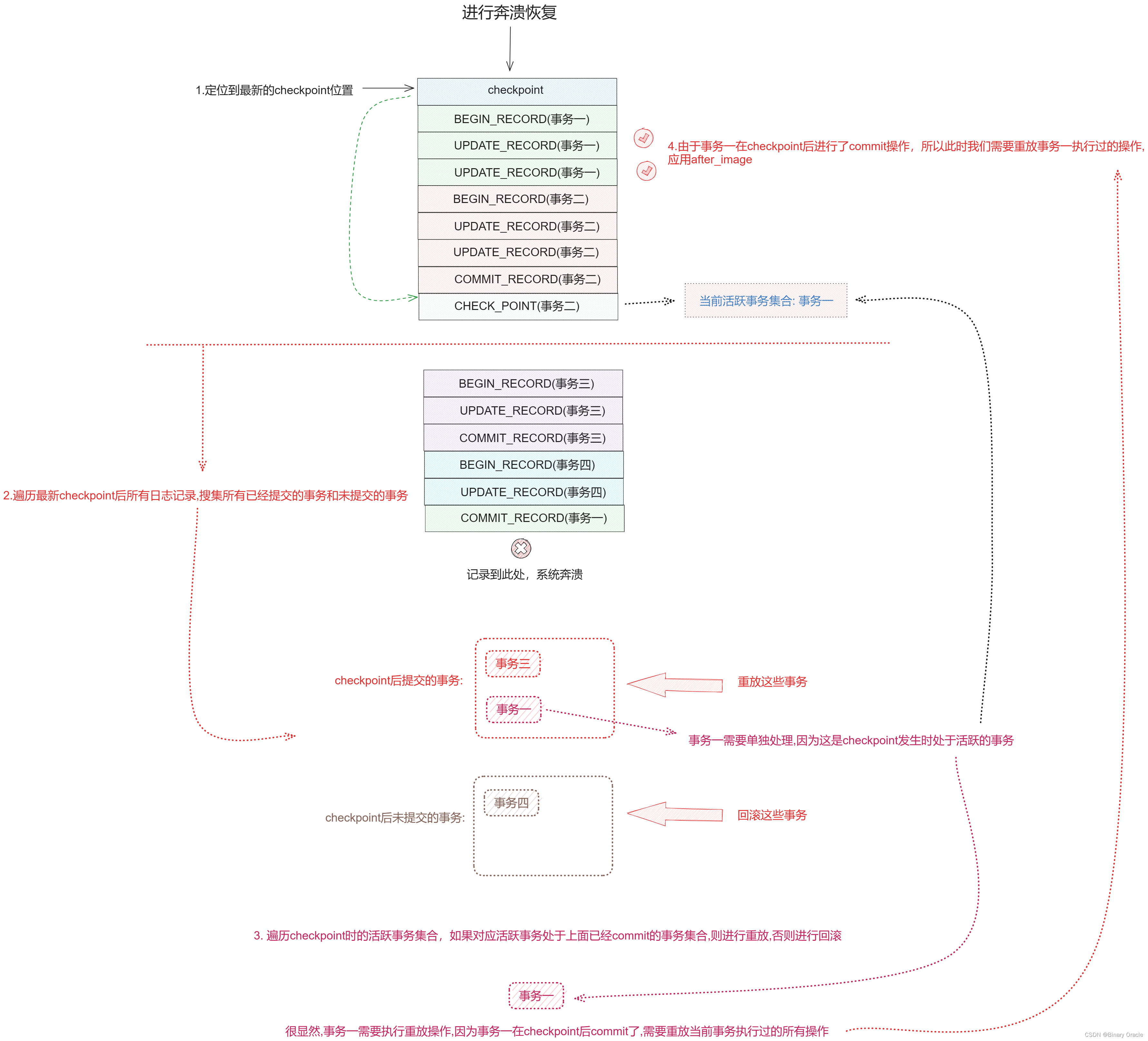
-
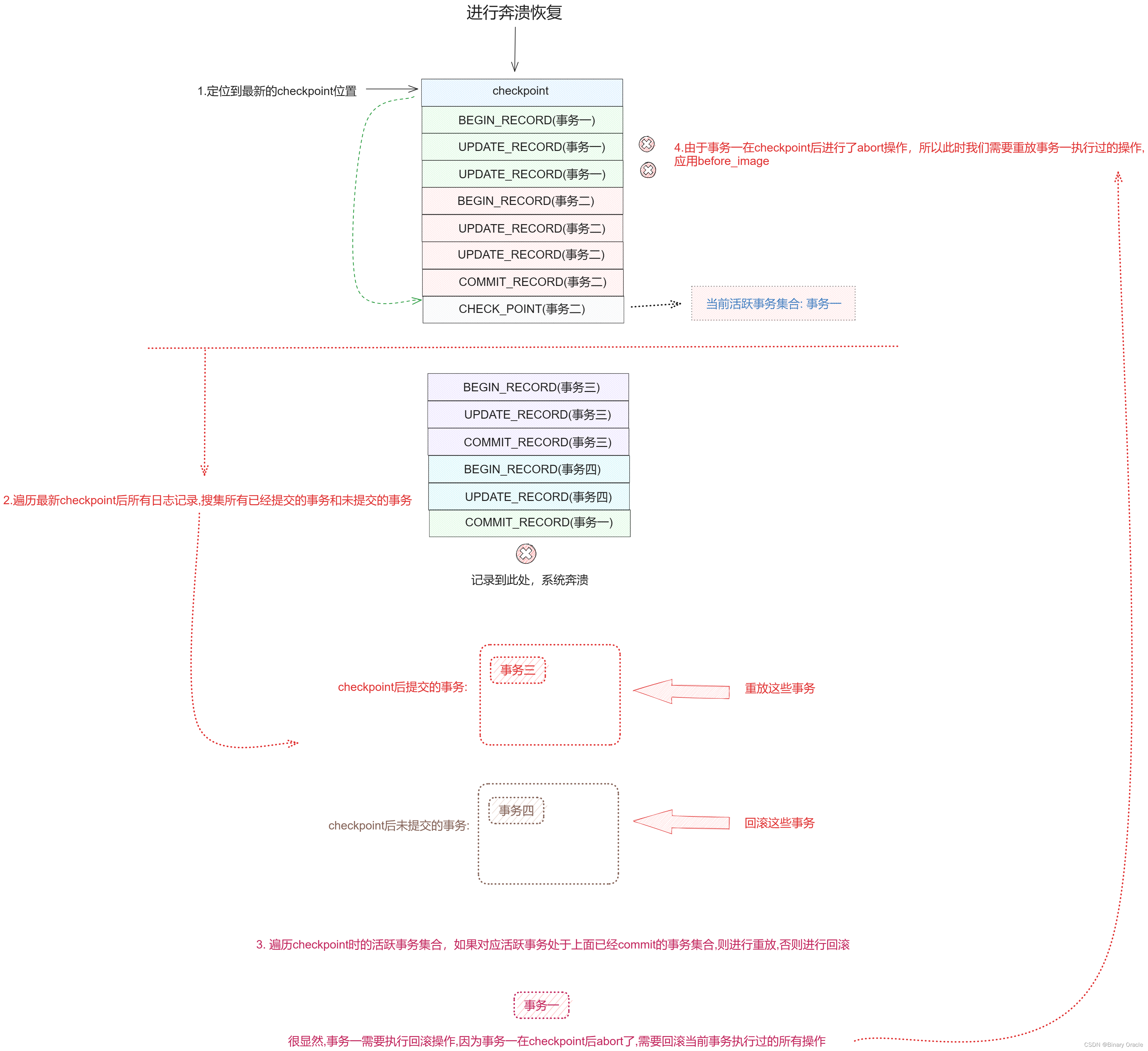
如果活跃事务一在checkpoint后没有commit记录或者存在abort记录,则需要执行回滚操作
测试结果
疑问点分析
我看网上不少博客在开始这一小节中两个flushPage方法是这样实现的,如下所示:
private synchronized void flushPage(PageId pid) throws IOException {Page flush = pageCache.get(pid);// 通过tableId找到对应的DbFile,并将page写入到对应的DbFile中int tableId = pid.getTableId();DbFile dbFile = Database.getCatalog().getDatabaseFile(tableId);// append an update record to the log, with a before-image and after-imageTransactionId dirtier = flush.isDirty();if (dirtier != null) {Database.getLogFile().logWrite(dirtier, flush.getBeforeImage(), flush);Database.getLogFile().force();}// 将page刷新到磁盘dbFile.writePage(flush);flush.markDirty(false, null);}
第一个flushPage方法并没有什么问题,但是第二个flushPages方法的实现个人觉得存在问题,因为笔者测试过程中存在测试用例测试失败:
/** Write all pages of the specified transaction to disk.*/public synchronized void flushPages(TransactionId tid) throws IOException {// some code goes here// not necessary for lab1|lab2for (Map.Entry<PageId, Page> entry : pageCache.entrySet()) {Page page = entry.getValue();// 核心: 未提交的事务在此处会更新自己的before_image为最新镜像// 那么如果此时调用flushAllPages方法,log日志中记录的就是当前未提交事务的最新before_image// 后面如果未提交事务回滚,拿着日志中记录的最新的before_image进行回滚,显然是错误的page.setBeforeImage();if (page.isDirty() == tid) {flushPage(page.getId());}}}
首先,flushPage方法只会在事务正常提交的时候被调用,为的是将本次事务修改产生的脏页全部落盘并且在落盘前先记录最新更改日志到日志文件中。
还有一个flushAllPages方法如下所示,该方法是为了模拟no steal mode模式,即未提交事务修改产生的脏页可能会提前落盘,此时同样会在落盘前记录日志:
public synchronized void flushAllPages() throws IOException {pageCache.forEach((pageId, page) -> {try {// 只有脏页才刷新if (page.isDirty() != null) {flushPage(page.getId());}} catch (IOException e) {e.printStackTrace();}});}
如果就这样实现,我们来看一下下面这个测试用例:
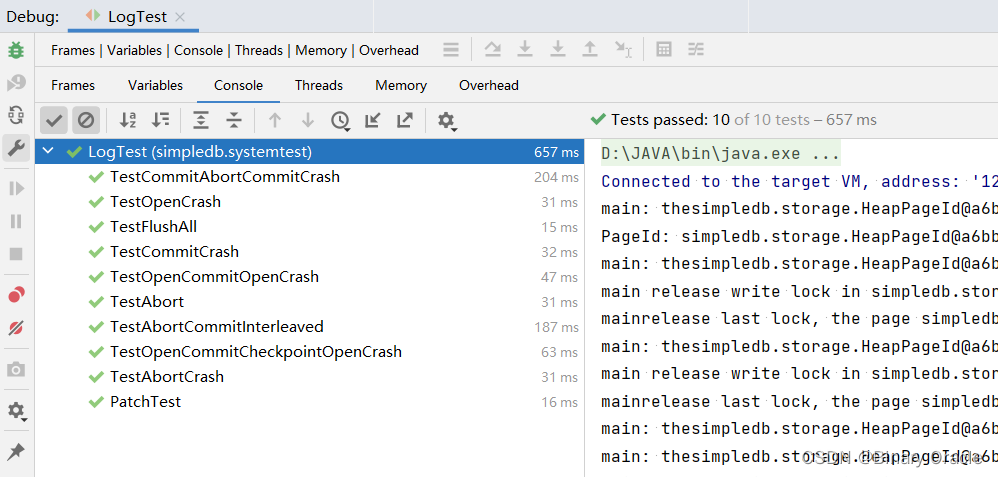
@Testpublic void TestAbortCommitInterleaved()throws IOException, DbException, TransactionAbortedException {setup();// *** Test:// T1 start, T2 start and commit, T1 abortTransaction t1 = Database.newTransaction();t1.start();insertRow(hf1, t1, 3);Transaction t2 = Database.newTransaction();t2.start();insertRow(hf2, t2, 21);insertRow(hf2, t2, 22);// commit函数中是会调用flushPages方法将与当前t2事务相关的脏页都刷到磁盘上的t2.commit();insertRow(hf1, t1, 4);abort(t1);Transaction t = Database.newTransaction();t.start();// 这里会抛出异常,因为此时3是存在的,这是为什么呢?look(hf1, t, 3, false);look(hf1, t, 4, false);look(hf2, t, 21, true);look(hf2, t, 22, true);t.commit();}void abort(Transaction t)throws IOException {// t.transactionComplete(true); // abortDatabase.getBufferPool().flushAllPages(); // XXX defeat NO-STEAL-based abortDatabase.getLogFile().logAbort(t.getId()); // does rollback tooDatabase.getBufferPool().flushAllPages(); // prevent NO-STEAL-based abort from// un-doing the rollbackDatabase.getBufferPool().transactionComplete(t.getId(), false); // release locks}
事务t2的commit方法中,会更新事务t1关联的前置镜像从null变为3,然后调用abort方法回滚事务t1,在该方法中,首先调用flushAllPages方法将所有脏页都刷新到磁盘上,包括未提交事务产生的脏页,此时事务t1修改产生的脏页落盘,如下所示:
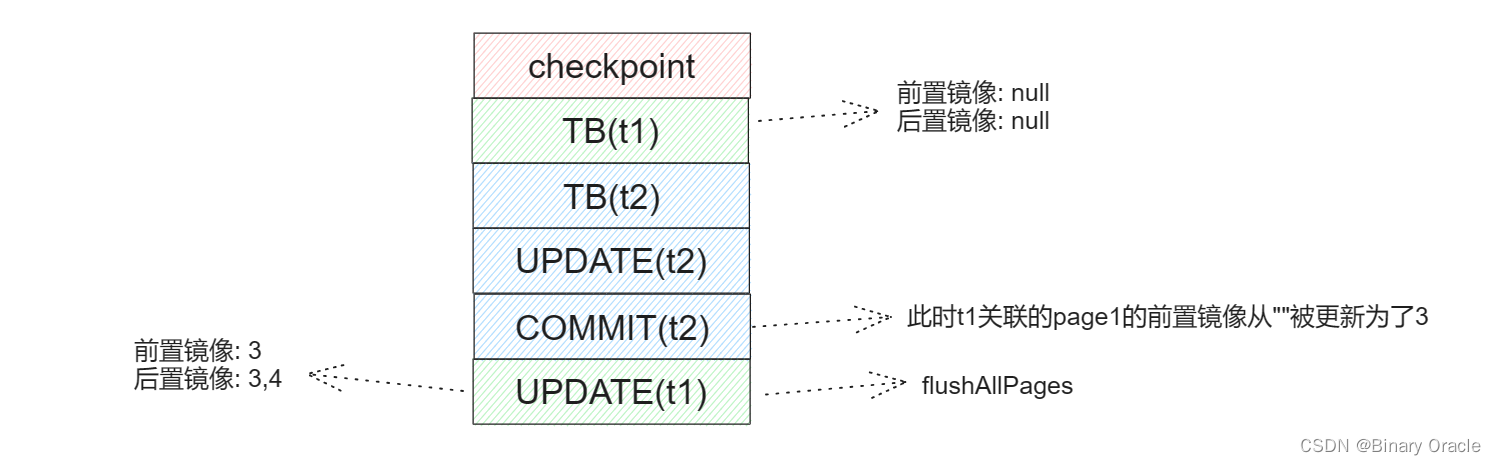
当真正执行事务t1的回滚操作时,会重新应用最后一条update记录的前置镜像,很显然这次回滚结果是错误的。
原因:未提交的事务在flushPages方法中会更新自己的before_image为最新镜像,那么如果此时调用flushAllPages方法,log日志中记录的就是当前未提交事务的最新before_image,后面如果未提交事务回滚,拿着日志中记录的最新的before_image进行回滚,显然是错误的。
有聪明的小伙伴会想,能不能把flushPages方法修改成如下模样:
/** Write all pages of the specified transaction to disk.*/public synchronized void flushPages(TransactionId tid) throws IOException {// some code goes here// not necessary for lab1|lab2for (Map.Entry<PageId, Page> entry : pageCache.entrySet()) {Page page = entry.getValue();if (page.isDirty() == tid) {page.setBeforeImage();flushPage(page.getId());}}}
这样一来,flushPages方法中只会更新当前提交事务的最新镜像,这样的逻辑是没错的,但是还是会产生问题,我们来看下面这个测试用例:
@Testpublic void TestCommitAbortCommitCrash()throws IOException, DbException, TransactionAbortedException {setup();// *** Test:// T1 inserts and commitsdoInsert(hf1, 5);// T2 rollBackdontInsert(hf1, 6);Transaction t = Database.newTransaction();t.start();// 此时5不存在,大家可以想想是哪一步出现问题了look(hf1, t, 5, true);look(hf1, t, 6, false);t.commit();}void doInsert(HeapFile hf, int t1)throws DbException, TransactionAbortedException, IOException {Transaction t = Database.newTransaction();t.start();// 插入5,假设插入到了page2上insertRow(hf, t, t1);// 刷新page2到磁盘上 -- 此时事务t1还为提交Database.getBufferPool().flushAllPages();// 提交事务t1 t.commit();} void dontInsert(HeapFile hf, int t1)throws DbException, TransactionAbortedException, IOException {Transaction t = Database.newTransaction();t.start();insertRow(hf, t, t1);abort(t);}
事务t1插入一条记录5后,调用flushAllPages,此时记录5所在page one落盘,前置镜像此时没有变化,但是此时脏页都被落盘了,所以page cache中已无脏页,然后事务t1调用commit方法完成事务提交,commit方法中调用flushPages方法发现没有脏页需要刷盘,直接返回:
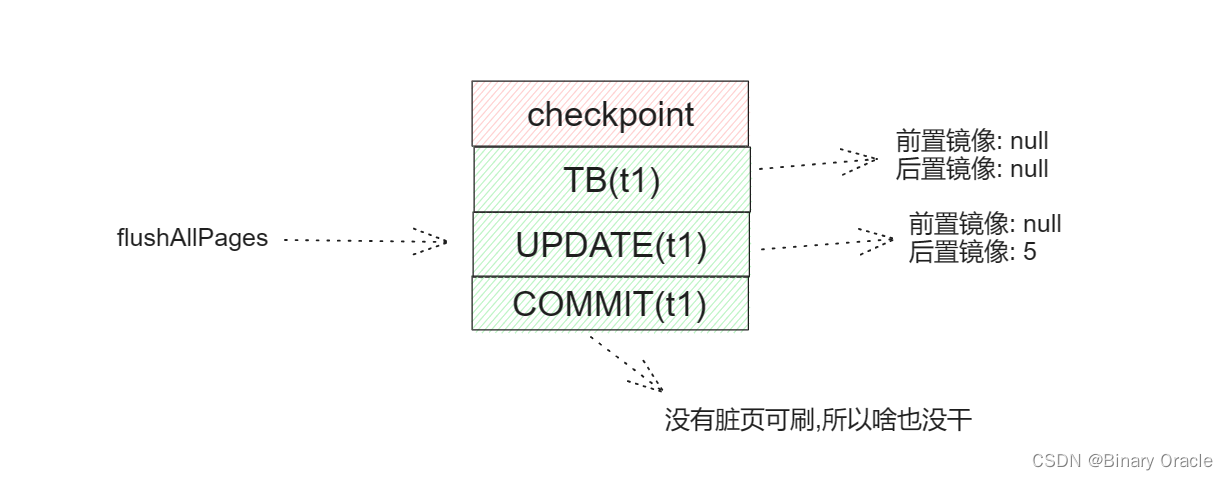
但是此时按理来说,应该将前置镜像更新为5:
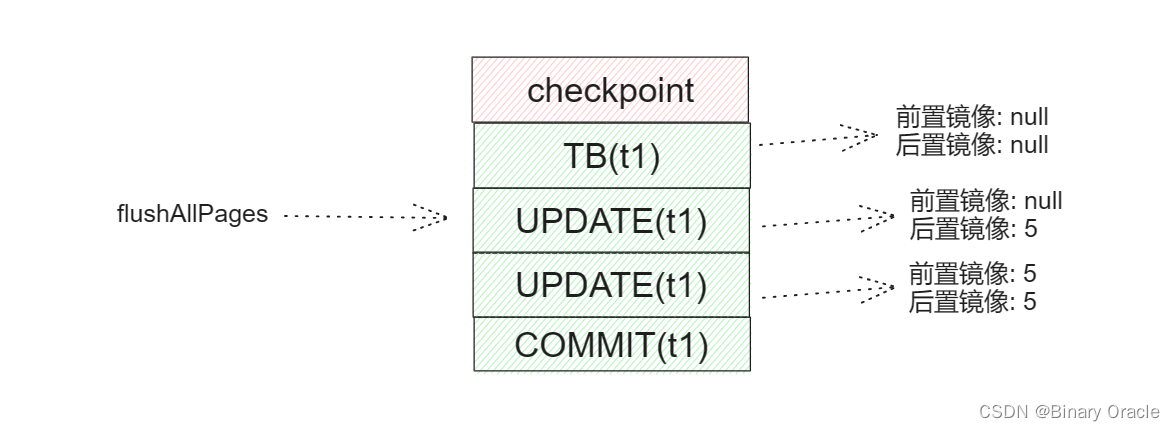
此时,如果事务2调用abort函数进行rollback,abort函数中会首先调用flushAllPages将所有脏页刷盘,并在刷盘前记录日志:
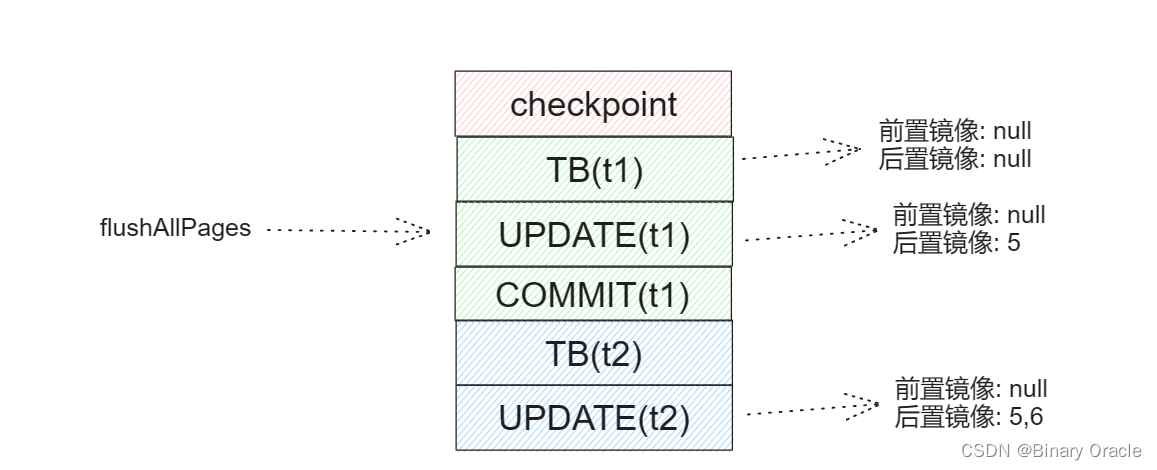
然后事务2进行回滚,应用最后一条update的前置镜像,很显然此次回滚结果不对,问题出在事务1进行commit的时候,没有更新前置镜像。
事务1之所以在事务提交时没有更新前置镜像是因为事务1在commit前调用了flushAllPages方法,将所有的脏页都提前落盘了,真正进行commit的时候发现没有脏页可以更新,也就没有进入if逻辑,从而也就没有更新前置镜像。