文章目录
- Ch2. 一维随机变量及其分布
- 1.一维随机变量
- 1.随机变量
- 2.分布函数 F ( x ) F(x) F(x)
- (1)定义
- (2)分布函数的性质 (充要条件)
- (3)分布函数的应用——求概率
- 3.最大最小值函数
- 2.一维离散型随机变量及其概率分布(分布律)
- 3.一维连续型随机变量及其概率分布(概率密度)
- 4.一般类型(混合型)随机变量及其分布
- 5.常见的随机变量分布类型:八大分布
- 1.离散型 (5种)
- ①0-1分布
- ②二项分布 X~B(n,p)
- ③泊松分布
- ④几何分布
- ⑤超几何分布
- 2. 连续型 (3种)
- ①均匀分布
- ②指数分布
- ③正态分布
- 独立可加性 (XY独立且同类型分布)
- 6.一维随机变量函数的分布
- Ch3. 多维随机变量及其分布
- 1.二维(n维)随机变量
- 1.多维随机变量
- 2.多维随机变量的分布函数
- (1)联合分布函数
- (2)边缘分布函数
- 2.二维离散型随机变量及其分布
- (1)联合分布律
- (2)边缘分布律
- (3)条件分布律
- 3.二维连续型随机变量及其分布
- (1)二维随机变量的概率密度 f(x,y):联合概率密度
- (1)定义
- (2)性质
- (2)边缘分布
- 1.边缘概率分布
- 2.边缘概率密度
- (3)条件分布
- 1.条件概率密度
- 2.条件分布函数
- (4)二维均匀分布
- (5)二维正态分布
- 4.独立性 【随机变量的独立性】
- (1)定义 (相互独立的充要条件)
- (2)独立的性质
- 5.二维随机变量 函数的分布
- (1)(离散型,离散型)→离散型
- (2)(连续型,连续型)→连续型
- ①分布函数法
- ②卷积公式
- (3)(离散型,连续型)→连续型
- ①离散+连续:全概率公式
Ch2. 一维随机变量及其分布
1.一维随机变量
1.随机变量
①X=X(ω)
②一般用大写字母表示


2.分布函数 F ( x ) F(x) F(x)
(1)定义
1.定义:
称函数 F ( x ) = P { X ≤ x } ( − ∞ < x < + ∞ ) F(x)=P\{ X≤x\} \ (-∞<x<+∞) F(x)=P{X≤x} (−∞<x<+∞) 为随机变量X的分布函数,或称 X服从F(x)分布,记为X~F(x)
(2)分布函数的性质 (充要条件)
① 0 ≤ F ( x ) ≤ 1 0≤F(x)≤1 0≤F(x)≤1:分布函数是事件的概率,满足有界性
② F ( x ) 单调不减 F(x)单调不减 F(x)单调不减:x从-∞取到+∞的过程中,F(x)单调不减,从0逐渐变大到1
③ F ( x ) 右连续 F(x)右连续 F(x)右连续:F(a+0)=F(a)
④ lim x → − ∞ F ( x ) = F ( − ∞ ) = 0 , lim x → + ∞ F ( x ) = F ( + ∞ ) = 1 \lim\limits_{x→-∞}F(x)=F(-∞)=0,\lim\limits_{x→+∞}F(x)=F(+∞)=1 x→−∞limF(x)=F(−∞)=0,x→+∞limF(x)=F(+∞)=1
若函数F(x)满足性质②-④,则F(x)必为某个随机变量的分布函数。
⑤ f ( x ) = F ′ ( x ) f(x)=F'(x) f(x)=F′(x)

(3)分布函数的应用——求概率
1.一元分布函数:
P { X ≤ a } = F ( a ) P\{X≤a\}=F(a) P{X≤a}=F(a)
P { X < a } = F ( a − ) P\{X<a\}=F(a^-) P{X<a}=F(a−)
P { X = a } = P { X ≤ a } − P { X < a } = F ( a ) − F ( a − ) P\{X=a\}=P\{X≤a\}-P\{X<a\}=F(a)-F(a^-) P{X=a}=P{X≤a}−P{X<a}=F(a)−F(a−)
【一点处的概率,用于离散型、混合型随机变量】
若 P { X = a } = 0 ,即 F ( a ) − F ( a − ) P\{X=a\}=0,即F(a)-F(a^-) P{X=a}=0,即F(a)−F(a−),即要求左连续。
P { X > a } = 1 − P { X ≤ a } = 1 − F ( a ) P\{X>a\}=1-P\{X≤a\}=1-F(a) P{X>a}=1−P{X≤a}=1−F(a)
因为分布函数统一用F字母,所以不同分布函数是用F的不同角标来区分,如X和Y不同分布,则分布函数为 F X ( z ) 、 F Y ( z F_X(z)、F_Y(z FX(z)、FY(z)
2.二元分布函数:
F Z ( z ) = P { Z ≤ z } = P { Z ( X , Y ) ≤ z } F_Z(z) = P\{Z≤z\}=P\{Z(X,Y)≤z\} FZ(z)=P{Z≤z}=P{Z(X,Y)≤z}
3.最大最小值函数
① P { m a x { X , Y } ≤ a } = P { X ≤ a , Y ≤ a } P\{max\{X,Y\}≤a\}=P\{X≤a,Y≤a\} P{max{X,Y}≤a}=P{X≤a,Y≤a}
② P { m i n { X , Y } ≥ a } = P { X ≥ a , Y ≥ a } P\{min\{X,Y\}≥a\}=P\{X≥a,Y≥a\} P{min{X,Y}≥a}=P{X≥a,Y≥a}
P { a < m a x { X , Y } ≤ b } = P { a < U ≤ b } = P { U ≤ b } − P { U ≤ a } = P { X ≤ b , Y ≤ b } − P { X ≤ a , Y ≤ a } P\{a<max\{X,Y\}≤b\}=P\{a<U≤b\}=P\{U≤b\}-P\{U≤a\}=P\{X≤b,Y≤b\}-P\{X≤a,Y≤a\} P{a<max{X,Y}≤b}=P{a<U≤b}=P{U≤b}−P{U≤a}=P{X≤b,Y≤b}−P{X≤a,Y≤a}
例题1:08年7. Z=max{X,Y}与Z=min{X,Y}的分布函数

分析:
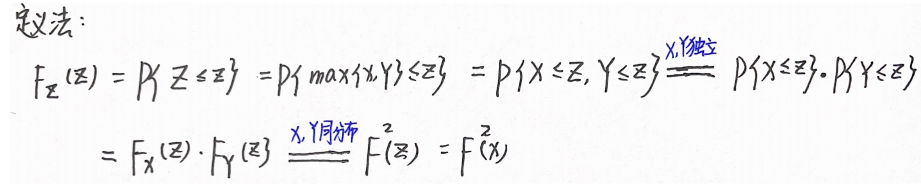
F 2 ( x ) : Z = m a x { X , Y } F²(x):Z=max\{X,Y\} F2(x):Z=max{X,Y},独立,同分布
F ( x ) F ( y ) : Z = m a x { X , Y } F(x)F(y):Z=max\{X,Y\} F(x)F(y):Z=max{X,Y},独立,不同分布
1 − [ 1 − F ( x ) ] 2 : Z = m i n { X , Y } 1-[1-F(x)]²:Z=min\{X,Y\} 1−[1−F(x)]2:Z=min{X,Y},独立,同分布
1 − [ 1 − F ( x ) ] [ 1 − F ( y ) ] : Z = m i n { X , Y } 1-[1-F(x)][1-F(y)]:Z=min\{X,Y\} 1−[1−F(x)][1−F(y)]:Z=min{X,Y},独立,不同分布
答案:A
例题1变式——将Z改为 Z = m i n { X , Y } Z=min\{X,Y\} Z=min{X,Y},再求Z的分布函数
分析:主要是看①max还是min,②是否同分布。就看这两个。最大值是乘积,最小值是 1-[ ],同分布无角标,不同分布有角标
①分布函数的定义:分布函数F与概率P的关系
②最大值最小值的定义
③独立:P的乘积可拆为乘积的P,同理F可拆
④同分布:角标可以抹去了,合并。
答案:
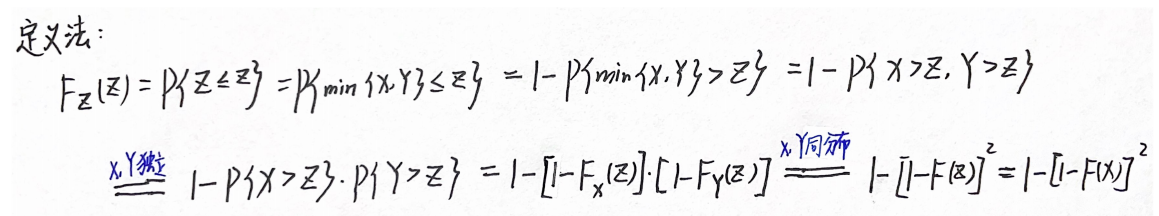
4.习题
习题1:10年7.
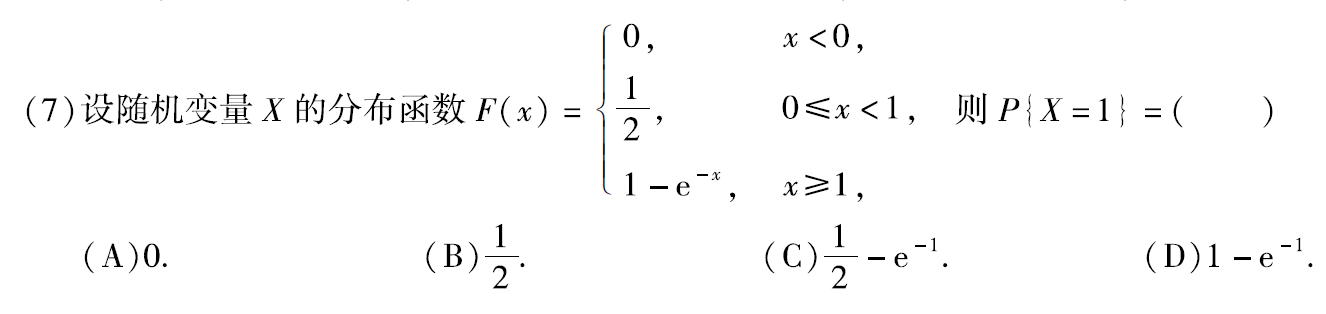
分析: P X = 1 = F ( 1 ) − F ( 1 − 0 ) = 1 − e − 1 − 1 2 = 1 2 − e − 1 P{X=1}=F(1)-F(1-0)=1-e^{-1}-\dfrac{1}{2}=\dfrac{1}{2}-e^{-1} PX=1=F(1)−F(1−0)=1−e−1−21=21−e−1
答案:C
习题2:19年14. 分类讨论、数学期望

分析:
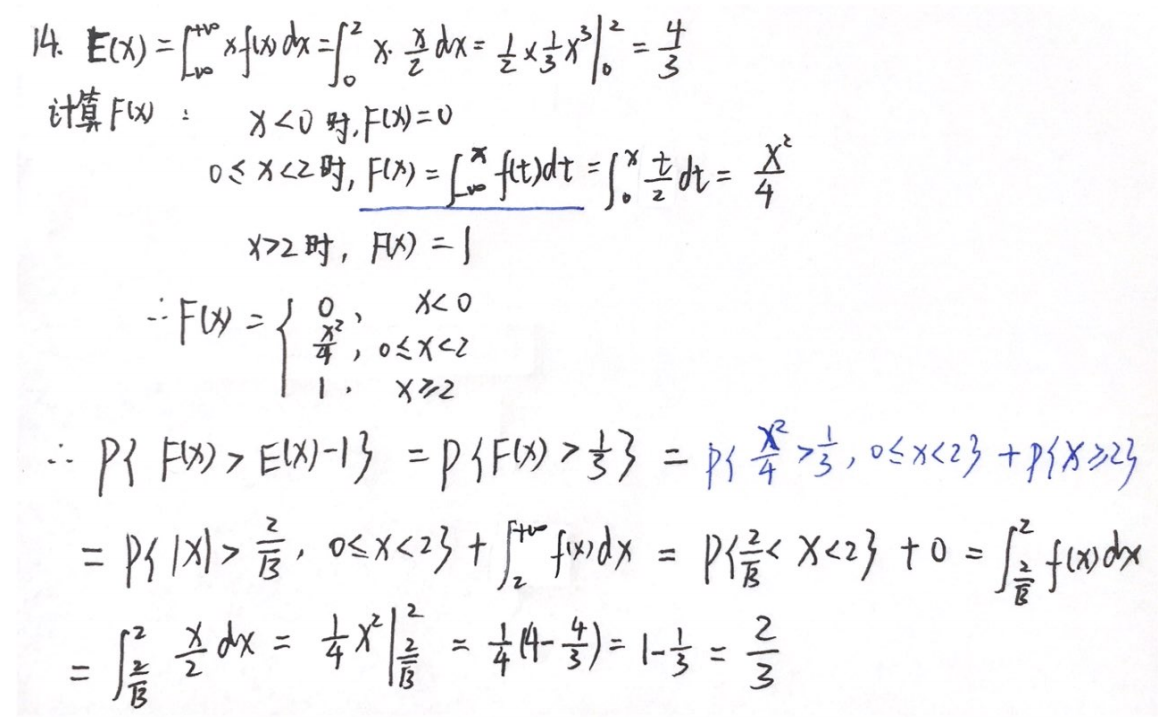
答案: 2 3 \dfrac{2}{3} 32
习题3:09年8.

分析:
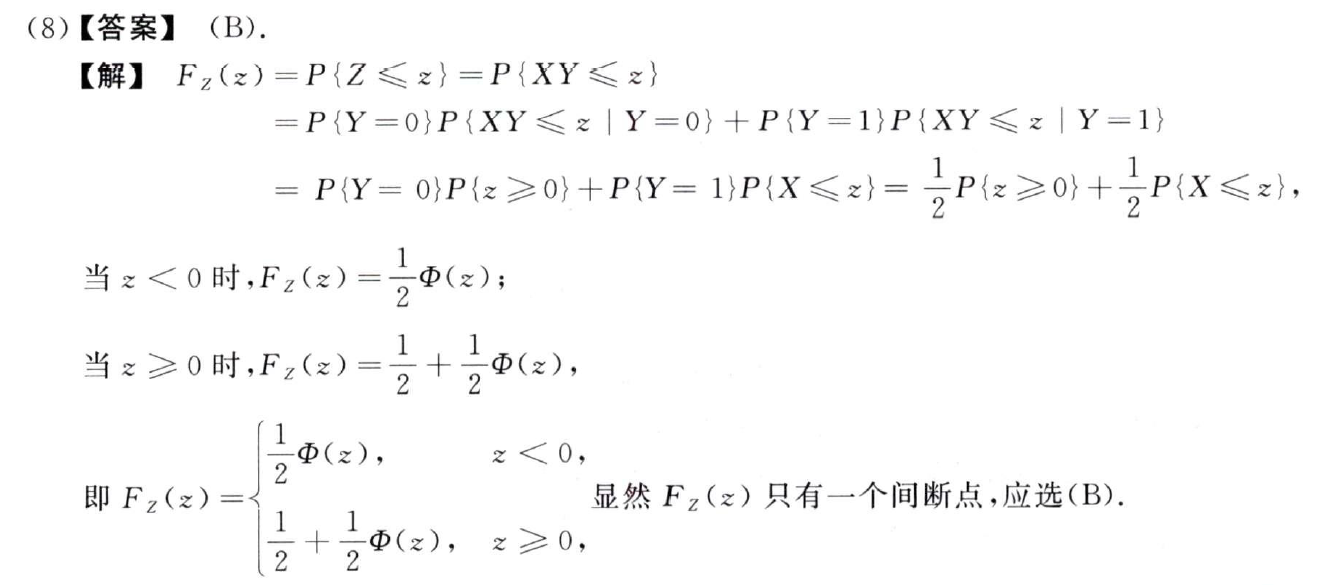
答案:B
习题4:23李林四(一)9.

分析:

答案:D
习题5:16年22(3)
常见的两类随机变量——离散型随机变量、连续型随机变量
2.一维离散型随机变量及其概率分布(分布律)
1.离散型随机变量:如果随机变量X只能取有限个或可列个值 x 1 , x 2 , . . . x_1,x_2,... x1,x2,...,则称X为离散型随机变量
2.分布律:
(1)分布律的定义
称 P { X = x i } = p i , i = 1 , 2 , . . . P\{X=x_i\}=p_i,i=1,2,... P{X=xi}=pi,i=1,2,...为离散型随机变量X的分布律 或 X的概率分布,记为 X ∼ p i X \sim p_i X∼pi。其函数图形为“步步高的阶梯函数”。
离散型随机变量的概率分布是分布律。可用矩阵或表格表示。

(2)分布律的性质(充要条件)
① p k ≥ 0 p_k≥0 pk≥0
②规范性(归一性): ∑ i = 1 + ∞ p i = 1 \sum\limits_{i=1}^{+∞}p_i=1 i=1∑+∞pi=1
3.特点
(1)分布函数 F ( x ) = ∑ x i ≤ x p i F(x)=\sum\limits_{x_i≤x}p_i F(x)=xi≤x∑pi,即F(x) = x扫过的离散点的概率之和。F(x)是“步步高的阶梯函数”。
(2)归一性: ∑ i = 1 n p i = 1 \sum\limits_{i=1}^np_i=1 i=1∑npi=1
(3)概率:
①一点处概率: P { X = a } = F ( a ) − F ( a − 0 ) P\{X=a\}=F(a)-F(a-0) P{X=a}=F(a)−F(a−0)
②区间上概率: P { X ∈ B } = ∑ x i ∈ B p i P\{X∈B\}=\sum\limits_{x_i∈B}p_i P{X∈B}=xi∈B∑pi
4.离散型随机变量的概率分布(分布律)
①先求该离散型随机变量的取值范围,一一列举:
Z=XY的取值范围:-1,0,1
②求每一个取值的概率:
P{XY=-1}=…
P{XY=0}=…
P{XY=1}=…
③列分布律:
| Z=XY | -1 | 0 | 1 |
|---|---|---|---|
| P |
例题1:23李林四(一)16. 数学期望+分布律

分析:

答案: 3 − 3 2 \dfrac{3-\sqrt{3}}{2} 23−3
3.一维连续型随机变量及其概率分布(概率密度)
1.定义:
若随机变量X的分布函数可表示为 F ( x ) = ∫ − ∞ x f ( t ) d t ( − ∞ < x < + ∞ ) F(x)=\int_{-∞}^xf(t)dt \ (-∞<x<+∞) F(x)=∫−∞xf(t)dt (−∞<x<+∞),
其中f(x)是非负可积函数,则称X为连续型随机变量,称f(x)为连续型随机变量X的概率密度函数,简称概率密度,记为 X~f(x)
2.概率密度f(x)的性质、充要条件:
①非负性: f ( x ) ≥ 0 f(x)≥0 f(x)≥0
②归一性: ∫ − ∞ + ∞ f ( x ) d x = 1 \int_{-∞}^{+∞}f(x){\rm d}x=1 ∫−∞+∞f(x)dx=1
③ P { a < X ≤ b } = F ( b ) − F ( a ) = ∫ a b f ( x ) d x P\{a<X≤b\} = F(b) - F(a)= \int_{a}^{b}f(x){\rm d}x P{a<X≤b}=F(b)−F(a)=∫abf(x)dx
④在f(x)的连续点x处, F ′ ( x ) = f ( x ) F'(x) = f(x) F′(x)=f(x)
其中①② 非负性和归一性,是f(x)成为概率密度的充要条件
已知f(x)为概率密度,则 f ( a x + b ) 为概率密度 ⇔ a = ± 1 f(ax+b)为概率密度\Leftrightarrow a=±1 f(ax+b)为概率密度⇔a=±1
【若|a|≠1,或f(x²) 或f²(x)均不是概率密度】
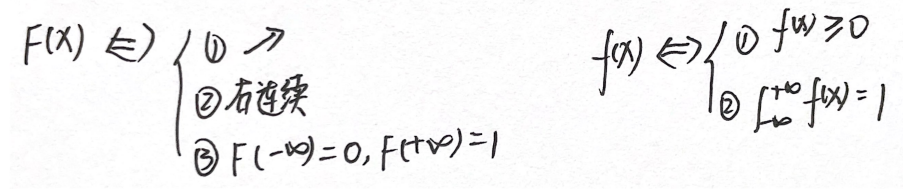
F 1 ( x ) F 2 ( x ) F_1(x)F_2(x) F1(x)F2(x)为 m a x { X 1 , X 2 } max\{X₁,X₂\} max{X1,X2}的分布函数, f 1 ( x ) F 2 ( x ) + F 1 ( x ) f 2 ( x ) f_1(x)F_2(x)+F_1(x)f_2(x) f1(x)F2(x)+F1(x)f2(x)为它的概率密度
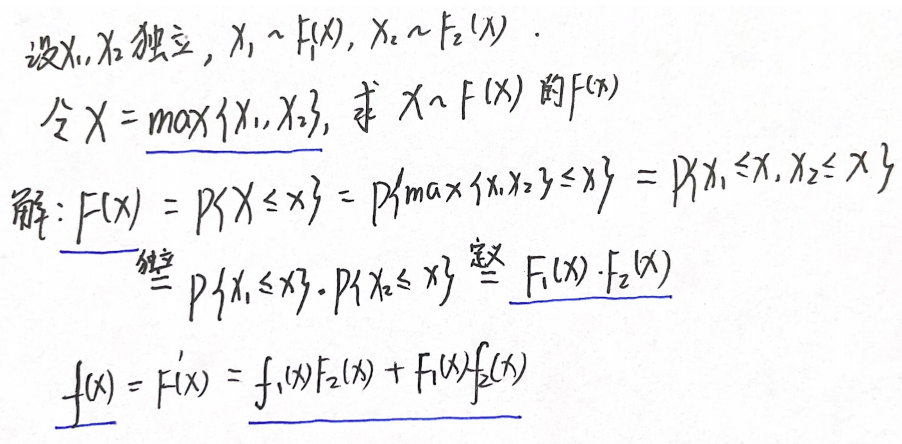
3.求解f(x)
①F(x)求导:先求F(x),则 f ( x ) = F ′ ( x ) f(x)=F'(x) f(x)=F′(x)
②由二维概率密度求边缘概率密度:已知f(x,y)表达式,则 f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y f_X(x)=\int_{-∞}^{+∞}f(x,y)dy fX(x)=∫−∞+∞f(x,y)dy
4.特点
(1)分布函数 F ( x ) = P { X ≤ x } = ∫ − ∞ x f ( t ) d t F(x)=P\{X≤x\}=\int_{-∞}^xf(t)dt F(x)=P{X≤x}=∫−∞xf(t)dt,记为 X ∼ f ( x ) X\sim f(x) X∼f(x)。F(x)是连续函数。
(2)f(x)非负、可积,且有归一性: ∫ − ∞ + ∞ f ( x ) d x = 1 \int_{-∞}^{+∞}f(x){\rm d}x=1 ∫−∞+∞f(x)dx=1
(3)概率:
①一点处概率: P { X = a } = 0 P\{X=a\}=0 P{X=a}=0 。(即<、≤的概率相等)
②区间上概率: P { X ∈ B } = ∫ B f ( x ) d x P\{X∈B\}=\int_Bf(x){\rm d}x P{X∈B}=∫Bf(x)dx
5.概率P、分布函数F、概率密度f的关系
① P { X ≤ a } = F ( a ) = ∫ − ∞ a f ( x ) d x P\{X≤a\}=F(a)=\int_{-∞}^af(x)dx P{X≤a}=F(a)=∫−∞af(x)dx
P { X > a } P\{X>a\} P{X>a} = 1 − P { X ≤ a } = 1 − F ( a ) =1-P\{X≤a\}=1-F(a) =1−P{X≤a}=1−F(a) = ∫ a + ∞ f ( x ) d x =\int_a^{+∞}f(x)dx =∫a+∞f(x)dx
P P P{ a < X ≤ b a<X≤b a<X≤b } = F ( b ) − F ( a ) = ∫ a b f ( x ) d x = F(b)-F(a) =\int_a^bf(x)dx =F(b)−F(a)=∫abf(x)dx
② F ( x ) = ∫ − ∞ x f ( t ) d t F(x)=\int_{-∞}^xf(t)dt F(x)=∫−∞xf(t)dt
f ( x ) = F ′ ( x ) f(x)=F'(x) f(x)=F′(x)
f可以唯一确定F,但F不能推出f。如U(a,b)和U[a,b],f的x一个开区间,一个闭区间,都能得到同样的F(x)
例题1:02年10.

分析:
A. ∫ − ∞ + ∞ f ( x ) d x = ∫ − ∞ + ∞ ( f 1 ( x ) + f 2 ( x ) ) d x = ∫ − ∞ + ∞ f 1 ( x ) d x + ∫ − ∞ + ∞ f 2 ( x ) d x = 2 ≠ 1 ∴ f 1 ( x ) + f 2 ( x ) \int_{-∞}^{+∞}f(x)dx=\int_{-∞}^{+∞}(f_1(x)+f_2(x))dx=\int_{-∞}^{+∞}f_1(x)dx+\int_{-∞}^{+∞}f_2(x)dx=2≠1 \quad ∴f_1(x)+f_2(x) ∫−∞+∞f(x)dx=∫−∞+∞(f1(x)+f2(x))dx=∫−∞+∞f1(x)dx+∫−∞+∞f2(x)dx=2=1∴f1(x)+f2(x)不是概率密度
B. ∫ − ∞ + ∞ f ( x ) d x = ∫ − ∞ + ∞ f 1 ( x ) f 2 ( x ) d x ≠ 1 ∴ f 1 ( x ) f 2 ( x ) \int_{-∞}^{+∞}f(x)dx=\int_{-∞}^{+∞}f_1(x)f_2(x)dx≠1\quad ∴f_1(x)f_2(x) ∫−∞+∞f(x)dx=∫−∞+∞f1(x)f2(x)dx=1∴f1(x)f2(x)不是概率密度
C. F ( + ∞ ) = F 1 ( + ∞ ) + F 2 ( + ∞ ) = 2 ≠ 1 ∴ F 1 ( x ) + F 2 ( x ) F(+∞)=F_1(+∞)+F_2(+∞)=2≠1 \quad ∴F_1(x)+F_2(x) F(+∞)=F1(+∞)+F2(+∞)=2=1∴F1(x)+F2(x)不是分布函数
D.① 0 ≤ F 1 ( x ) F 2 ( x ) ≤ 1 0≤F_1(x)F_2(x)≤1 0≤F1(x)F2(x)≤1
② F 1 ( x ) F 2 ( x ) F_1(x)F_2(x) F1(x)F2(x)单调不减
③ F 1 ( x ) F 2 ( x ) F_1(x)F_2(x) F1(x)F2(x)右连续
④ F ( + ∞ ) = F 1 ( + ∞ ) F 2 ( + ∞ ) = 1 , F ( − ∞ ) = F 1 ( − ∞ ) F 2 ( − ∞ ) = 0 F(+∞)=F_1(+∞)F_2(+∞)=1,F(-∞)=F_1(-∞)F_2(-∞)=0 F(+∞)=F1(+∞)F2(+∞)=1,F(−∞)=F1(−∞)F2(−∞)=0
∴ F 1 ( x ) F 2 ( x ) F_1(x)F_2(x) F1(x)F2(x)必为某个随机变量的分布函数。
答案:D
例题2:11年7.

分析:
①如果对乘法的求导法则熟悉,则会发现D的 f 1 ( x ) F 2 ( x ) + f 2 ( x ) F 1 ( x ) = [ F 1 ( x ) F 2 ( x ) ] ′ f_1(x)F_2(x)+f_2(x)F_1(x) = [F_1(x)F_2(x)]' f1(x)F2(x)+f2(x)F1(x)=[F1(x)F2(x)]′
②验证性质: ∫ − ∞ + ∞ f 1 ( x ) F 2 ( x ) + f 2 ( x ) F 1 ( x ) d x = F 1 ( x ) F 2 ( x ) ∣ − ∞ + ∞ = 1 × 1 − 0 × 0 = 1 \int_{-∞}^{+∞}f_1(x)F_2(x)+f_2(x)F_1(x)\rm dx=F_1(x)F_2(x)|_{-∞}^{+∞}=1×1-0×0=1 ∫−∞+∞f1(x)F2(x)+f2(x)F1(x)dx=F1(x)F2(x)∣−∞+∞=1×1−0×0=1
满足 f ( x ) ≥ 0 f(x)≥0 f(x)≥0、 ∫ − ∞ + ∞ f ( x ) d x = 1 \int_{-∞}^{+∞}f(x){\rm d}x=1 ∫−∞+∞f(x)dx=1,为概率密度
答案:D
6.习题
习题1:2016年23.
求概率密度,先求分布函数,再求导。
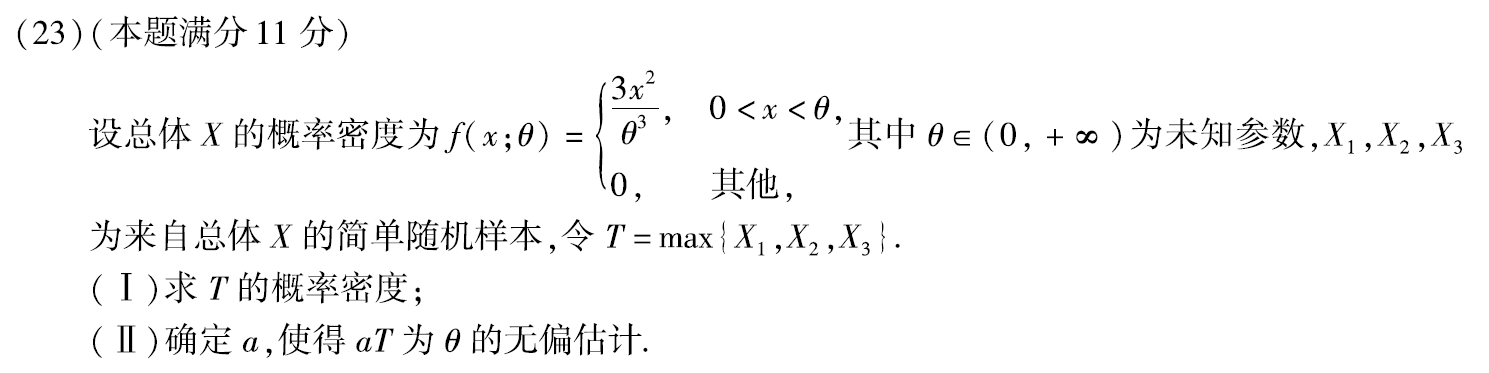
答案:
(1)FT(t) = P{T≤t} = P{ max{X1,X2,X3}≤t } = P{ X1≤t,X2≤t,X3≤t } = P{X1≤t}·P{X2≤t}·P{X3≤t} = P3{X≤t} = F3X(t)
(2)aT为θ的无偏估计 ⇦⇨ E(aT)=θ

4.一般类型(混合型)随机变量及其分布
1.定义
2.解题
只能用定义 F ( X ) = P { X ≤ x } F(X)=P\{X≤x\} F(X)=P{X≤x},分区间讨论。最好画图。注意自变量取遍(-∞,+∞)
3.类型
①离散型→离散型
②连续型→连续型 或 混合型

5.常见的随机变量分布类型:八大分布
1.离散型 (5种)
①0-1分布
0-1分布的概率分布为:
① P { X = 1 } = p , P { X = 0 } = 1 − p P\{X=1\}=p,P\{X=0\}=1-p P{X=1}=p,P{X=0}=1−p
或 ② P { X = k } = p k ( 1 − p ) 1 − k , k = 0 , 1 P\{X=k\}=p^k(1-p)^{1-k},k=0,1 P{X=k}=pk(1−p)1−k,k=0,1
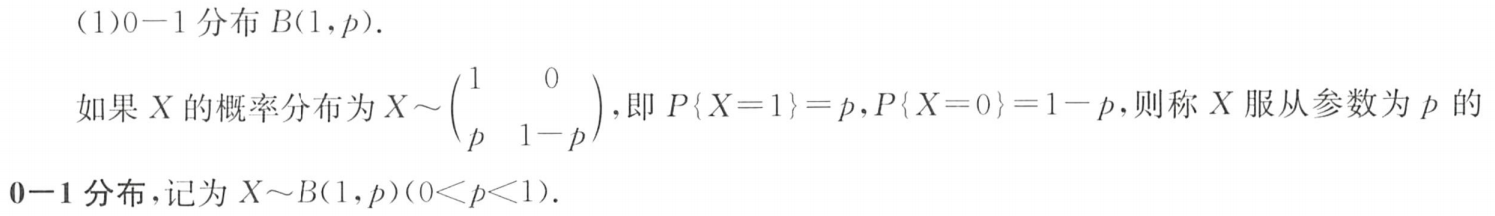
②二项分布 X~B(n,p)
n重伯努利实验:干一件事,要么成功,要么失败。成功概率为p,失败概率为1-p。则干这件事n次,成功了k次的概率为
P { X = k } = C n k p k ( 1 − p ) n − k ( k = 0 , 1 , 2 , . . . , n ) P\{X=k\}={\rm C}_n^kp^k(1-p)^{n-k} \qquad (k=0,1,2,...,n) P{X=k}=Cnkpk(1−p)n−k(k=0,1,2,...,n)
其中, C n k = n ⋅ ( n − 1 ) ⋅ . . . ⋅ ( n − k + 1 ) k ! {\rm C}_n^k=\dfrac{n·(n-1)·...·(n-k+1)}{k!} Cnk=k!n⋅(n−1)⋅...⋅(n−k+1)
习题1:09年14. 二项分布的期望与方差、E(S²)=D(X)、无偏估计
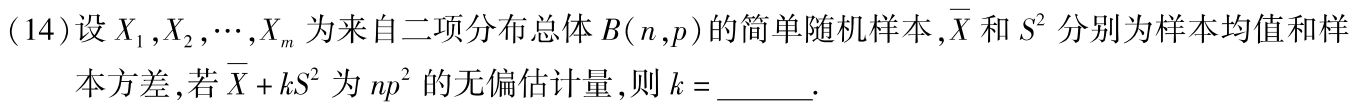
分析:
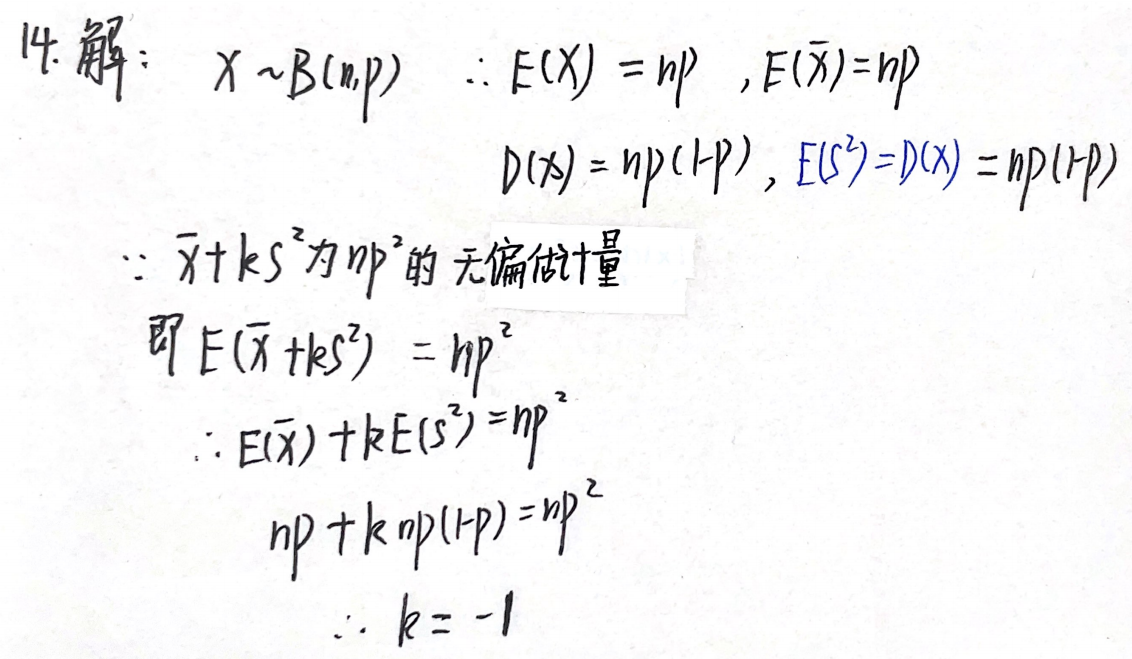
答案:-1
习题2:16年8.

分析:
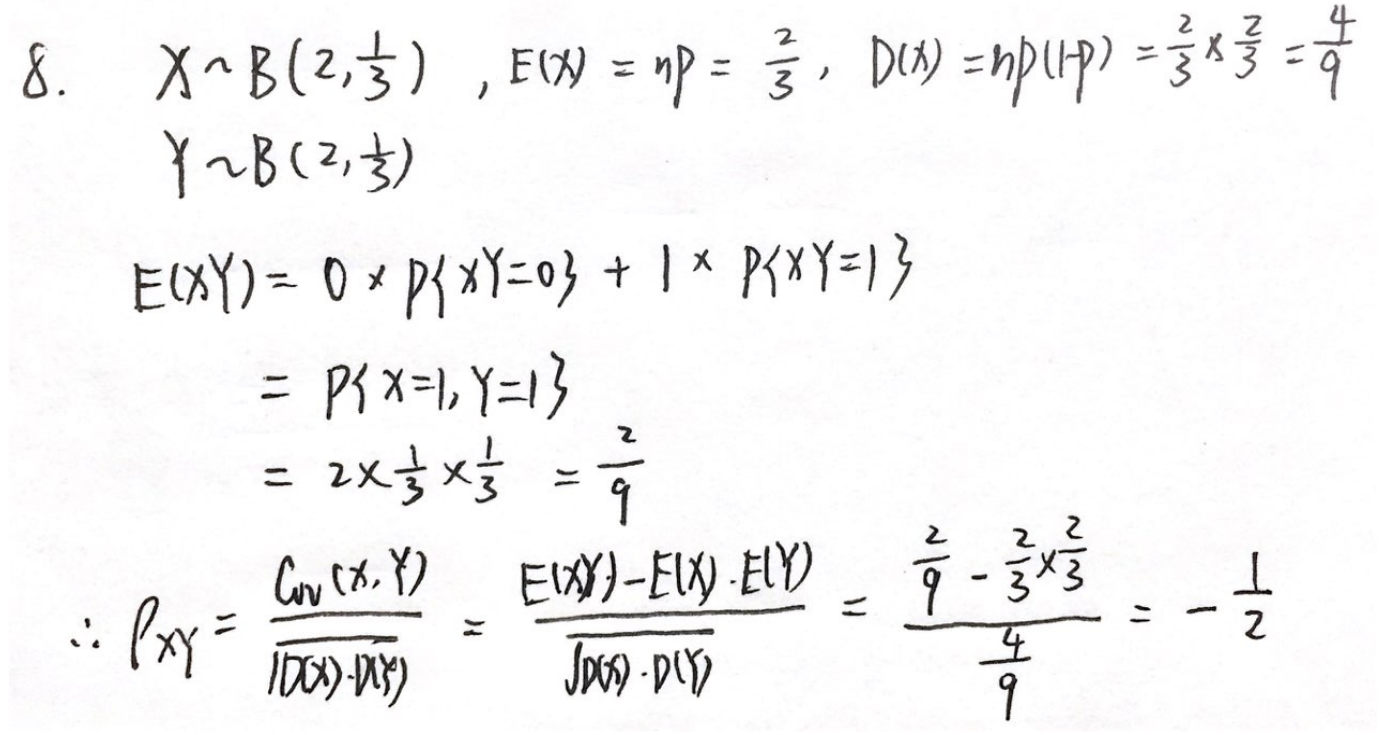
答案:A
习题3:01年19. 考点:二项分布、泊松分布、条件概率
③泊松分布
若随机变量X的概率分布为
P { X = k } = λ k k ! e − λ ( k = 0 , 1 , 2 , . . . ; λ > 0 ) P\{X=k\}=\dfrac{λ^k}{k!}e^{-λ} \qquad (k=0,1,2,...;λ>0) P{X=k}=k!λke−λ(k=0,1,2,...;λ>0)
则称X服从参数为λ的泊松分布(Poisson),记作 X ∼ P ( λ ) X\sim P(λ) X∼P(λ)。E(X)=λ,D(X)=λ。
λ称为强度。泊松分布的数学期望 E(X)=λ。
应用:
①某场合下,单位时间内源源不断的质点来流的数量
②稀有事件发生的概率
泊松分布由二项分布近似而来。


习题1:01年19. 考点:二项分布、泊松分布、条件概率

分析:
X服从泊松分布,X~P(λ)
Y服从二项分布,Y~B(n,p)
④几何分布
【几何分布 G ( p ) G(p) G(p),首中即停止的伯努利试验。】
若X的概率分布为 P { X = k } = ( 1 − p ) k − 1 p ( k = 1 , 2 , . . . ; 0 < p < 1 ) P\{X=k\}=(1-p)^{k-1}p \qquad (k=1,2,...;0<p<1) P{X=k}=(1−p)k−1p(k=1,2,...;0<p<1),则称X服从参数为p的几何分布,记为 X ∼ G ( p ) X\sim G(p) X∼G(p)

几何分布是离散型的等待分布
例题1: 几何分布推广,首二中即停止: P = C k − 1 1 ( 1 − p ) k − 2 p 2 P=C_{k-1}^1(1-p)^{k-2}p^2 P=Ck−11(1−p)k−2p2
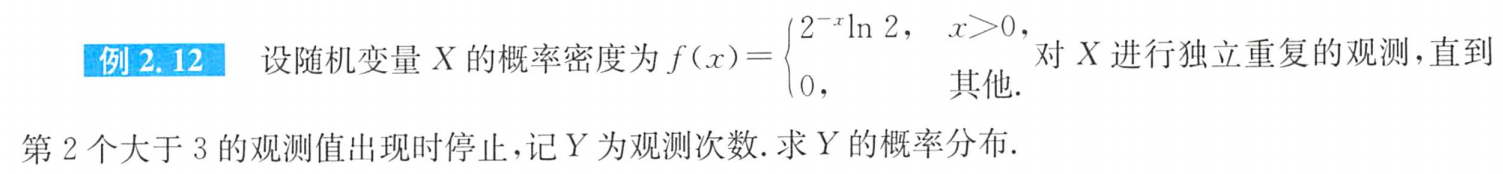
答案:

⑤超几何分布
超几何分布 H ( n , N , M ) H(n,N,M) H(n,N,M)
P { X = k } = C M k C N − M n − k C N n P\{X=k\}=\dfrac{C_M^kC_{N-M}^{n-k}}{C_N^n} P{X=k}=CNnCMkCN−Mn−k
2. 连续型 (3种)
①均匀分布

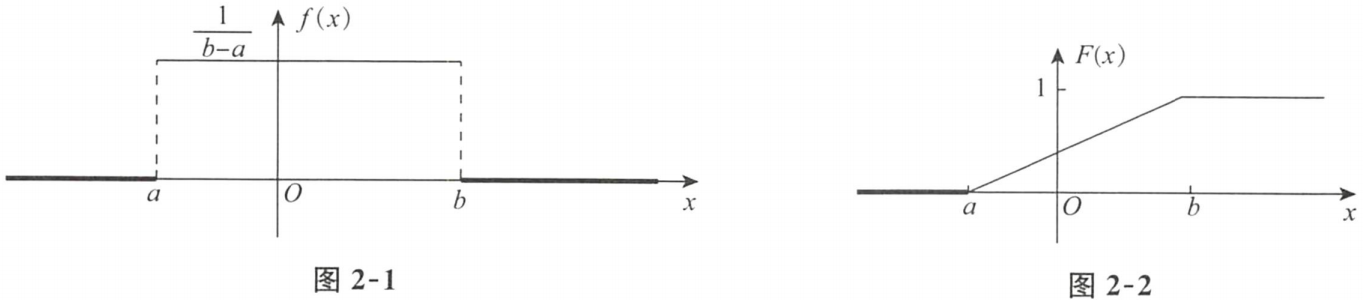
均匀分布,是一维的几何概型
②指数分布
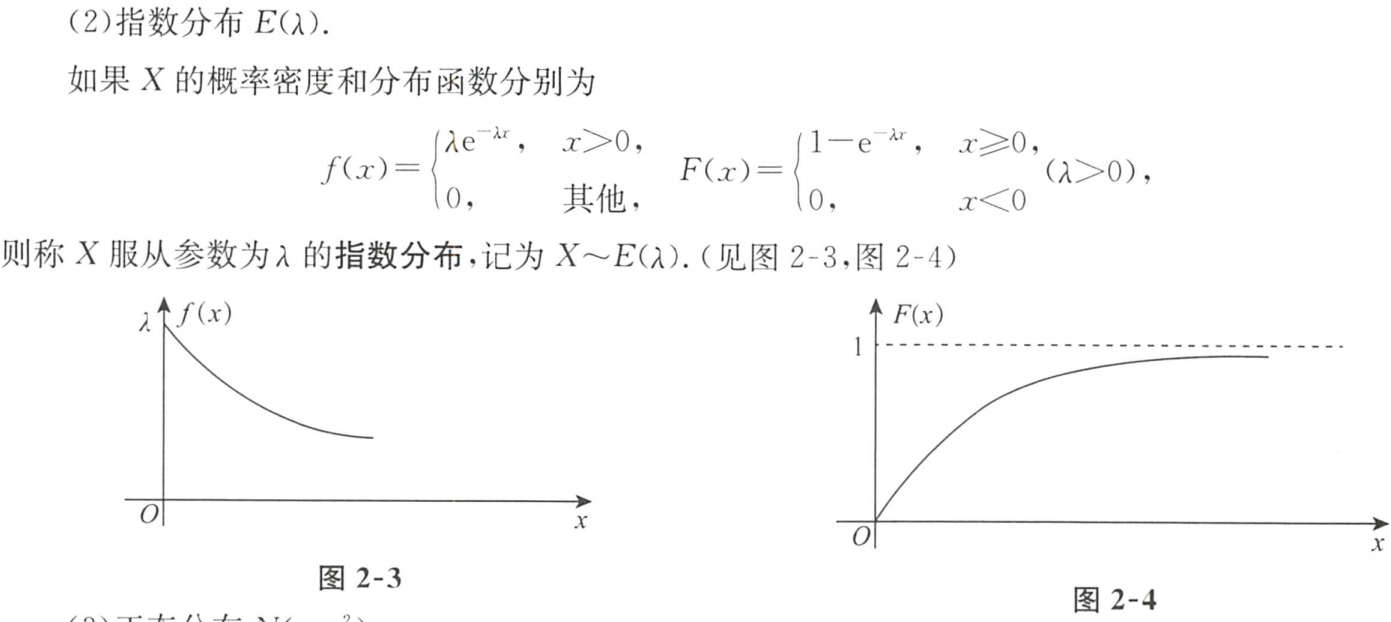
1.指数分布的概率密度:
若连续型 随机变量X的概率密度为
f ( x ) = { λ e − λ x , x > 0 0 , x ≤ 0 f(x)=\begin{cases} λe^{-λx}, & x>0\\ 0, & x≤0 \end{cases} f(x)={λe−λx,0,x>0x≤0
其中λ>0为常数,则称X服从参数为λ的指数分布,记为X~E(λ)
2.指数分布的分布函数:
F ( x ) = { 1 − e − λ x , x > 0 0 , x ≤ 0 F(x)=\begin{cases} 1-e^{-λx}, & x>0\\ 0, & x≤0 \end{cases} F(x)={1−e−λx,0,x>0x≤0
指数分布是连续型等待分布。
指数分布的λ是失效率,指数分布的数学期望 E ( X ) = 1 λ E(X)=\dfrac{1}{λ} E(X)=λ1
3.指数分布的无记忆性
P { X > s + t ∣ X > t } = P { X > s + t } P { X > t } = e − λ ( s + t ) e − λ t = e − λ s = P { X > s } P\{X>s+t|X>t\}=\dfrac{P\{X>s+t\}}{P\{X>t\}}=\dfrac{e^{-λ(s+t)}}{e^{-λt}}=e^{-λs}=P\{X>s\} P{X>s+t∣X>t}=P{X>t}P{X>s+t}=e−λte−λ(s+t)=e−λs=P{X>s}
① P { X > X 1 ∣ X > X 2 } = P { X > X 1 − X 2 } P\{X>X_1|X>X_2\}=P\{X>X_1-X_2\} P{X>X1∣X>X2}=P{X>X1−X2}
②指数分布的λ是失效率,在失效率λ不变的情况下,该理想元件是无损耗的。因此工作1年失效的概率和工作2年失效的概率相等,因此有无记忆性。
习题1:19年22(1)

分析:Z = 指数分布×两点分布
答案:
(1) E(X)~1,∴ F ( x ) = { 1 − e − x , x > 0 0 , x ≤ 0 F(x)=\begin{cases} 1-e^{-x}, & x>0\\ 0, & x≤0 \end{cases} F(x)={1−e−x,0,x>0x≤0
f Z ( z ) = F Z ′ ( z ) f_Z(z)=F_Z'(z) fZ(z)=FZ′(z)
对于FZ(z):
FZ(z) = P{Z≤z} = P{XY≤z} = P{Y=-1}·P{XY≤z|Y=-1} + P{Y=1}·P{XY≤z|Y=1} = p·P{-X≤z} + (1-p)·P{X≤z}
对于P{-X≤z} :
P{-X≤z} = P{-z≤X} = P{X≥-z} = 1-P{X≤-z} =1-FX(-z) [连续型随机变量,某一点的概率为0]
∴FZ(z) =p·[1-FX(-z)] + (1-p)·FX(z)
对z的取值进行分类讨论:
当z>0时,FZ(z) =p·[1-0] + (1-p)·(1-e-z) = p+(1-p)·(1-e-z)
当z≤0时,FZ(z) =p·[1-(1-ez)] + (1-p)·0 = pez
∴ F Z ( z ) = { p + ( 1 − p ) ⋅ ( 1 − e − z ) , z > 0 p e z , z ≤ 0 F_Z(z) =\begin{cases} p+(1-p)·(1-e^{-z}) , & z>0\\ pe^z, & z≤0 \end{cases} FZ(z)={p+(1−p)⋅(1−e−z),pez,z>0z≤0
∴ f Z ( z ) = F Z ′ ( z ) { ( 1 − p ) ⋅ e − z , z > 0 p e z , z ≤ 0 f_Z(z) =F_Z'(z)\begin{cases} (1-p)·e^{-z} , & z>0\\ pe^z, & z≤0 \end{cases} fZ(z)=FZ′(z){(1−p)⋅e−z,pez,z>0z≤0
③正态分布
若X的概率密度为:
f ( x ) = 1 2 π σ e − 1 2 ( x − μ σ ) 2 = 1 2 π σ e − ( x − μ ) 2 2 σ 2 ( − ∞ < x < + ∞ ) f(x)=\dfrac{1}{\sqrt{2π}σ}e^{-\frac{1}{2}(\frac{x-μ}{σ})^2}=\dfrac{1}{\sqrt{2π}σ}e^{-\frac{{(x-μ^)}^2}{2σ^2}} \quad(-∞<x<+∞) f(x)=2πσ1e−21(σx−μ)2=2πσ1e−2σ2(x−μ)2(−∞<x<+∞)
其中-∞<μ<+∞,σ>0,则称X服从参数为N(μ,σ²)的正态分布,或称X为正态变量,记为 X ∼ N ( μ , σ 2 ) X\sim N(μ,σ²) X∼N(μ,σ2)。
①f(x)关于x=μ对称。
②当 x = μ x=μ x=μ时,f(x)取最大值 f ( μ ) = 1 2 π σ f(μ)=\dfrac{1}{\sqrt{2π}σ} f(μ)=2πσ1,只与 σ σ σ有关。
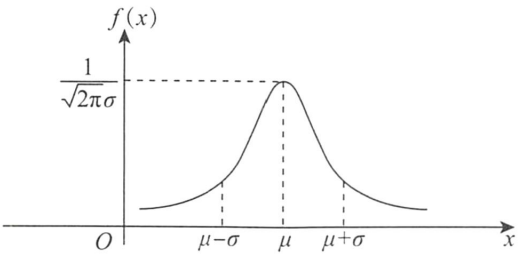

1.标准正态分布
X~N(0,1),则标准正态分布的概率密度φ(x)为:
φ ( x ) = 1 2 π e − x 2 2 , ( − ∞ < x < + ∞ ) Ф ( x ) = ∫ − ∞ x 1 2 π e − x 2 2 d x ∫ − ∞ + ∞ φ ( x ) d x = ∫ − ∞ + ∞ 1 2 π e − x 2 2 d x = 1 φ(x)=\dfrac{1}{\sqrt{2π}}e^{-\frac{x^2}{2}},\quad (-∞<x<+∞)\\[5mm] Ф(x)=\int_{-∞}^x\dfrac{1}{\sqrt{2π}}e^{-\frac{x^2}{2}}dx\\[5mm] \int_{-∞}^{+∞}φ(x)dx=\int_{-∞}^{+∞}\frac{1}{\sqrt{2π}}e^{-\frac{x^2}{2}}{\rm d}x = 1 φ(x)=2π1e−2x2,(−∞<x<+∞)Ф(x)=∫−∞x2π1e−2x2dx∫−∞+∞φ(x)dx=∫−∞+∞2π1e−2x2dx=1


上α分位点
若X~N(0,1),点 μ α μ_α μα右侧概率为α ( P { X > μ α } = α P\{X>μ_α\}=α P{X>μα}=α),则称 μ α μ_α μα为标准正态分布的上α分位点(上侧α分位数)

公式:
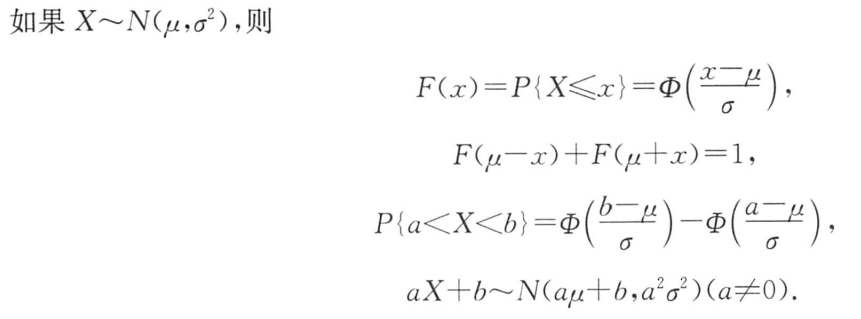
推论:
① Ф ( 0 ) = 1 2 Ф(0)=\dfrac{1}{2} Ф(0)=21
② Ф ( x ) + Ф ( − x ) = 1 Ф(x)+Ф(-x)=1 Ф(x)+Ф(−x)=1
结论:对于标准正态分布 X ∼ N ( 0 , 1 ) X\sim N(0,1) X∼N(0,1)
① P = ∫ − ∞ + ∞ φ ( x ) d x = 1 P=\int_{-∞}^{+∞}φ(x)dx=1 P=∫−∞+∞φ(x)dx=1
② E ( X ) = ∫ − ∞ + ∞ x φ ( x ) d x = 0 E(X)=\int_{-∞}^{+∞}xφ(x)dx=0 E(X)=∫−∞+∞xφ(x)dx=0
(理解1:φ(x)是偶函数,xφ(x)为奇函数,在对称区间上积分为0. 理解2: ∫ − ∞ + ∞ x φ ( x ) d x \int_{-∞}^{+∞}xφ(x)dx ∫−∞+∞xφ(x)dx即为标准正态分布的数学期望,X~N(0,1),则期望为0)
2.正态分布的独立可加性
若X与Y分别服从正态分布 N ( μ 1 , σ 1 2 ) N(μ_1,σ_1^2) N(μ1,σ12)与 N ( μ 2 , σ 2 2 ) N(μ_2,σ_2^2) N(μ2,σ22),且X与Y相互独立。
则 Z = X − Y Z=X-Y Z=X−Y也服从正态分布, Z ∼ N ( μ 1 − μ 2 , σ 1 2 + σ 2 2 ) Z\sim N( μ_1-μ_2, σ_1^2+σ_2^2) Z∼N(μ1−μ2,σ12+σ22)
独立可加性 (XY独立且同类型分布)
若X与Y独立,且满足以下5种同类型分布,则具有独立可加性.
| 分布 | X,Y独立 | ⇨ 独立可加性 |
|---|---|---|
| ①二项分布 | X~B(m,p), Y~B(n,p) | X+Y~ B(m+n,p) |
| ②泊松分布 | X~P(λ₁), Y~P(λ₂) | X+Y~ P(λ₁+λ₂) |
| ③正态分布 | X~N(μ₁,σ₁²), Y~N(μ₂,σ₂²) | X ± Y ∼ N ( μ 1 ± μ 2 , σ 1 2 + σ 2 2 ) X±Y\sim N(μ₁±μ₂,σ²₁+σ₂²) X±Y∼N(μ1±μ2,σ12+σ22) |
| ④卡方分布 | X~χ²(m), Y~χ²(n) | X+Y~ χ²(m+n) |
| ⑤指数分布 | X~E(λ₁), X~E(λ₂) | m i n { X , Y } min\{X,Y\} min{X,Y} ∼ E ( λ 1 + λ 2 ) \sim E(λ₁+λ₂) ∼E(λ1+λ2) |
3.正态分布 μ,σ 对图像的影响
期望μ:对称轴位置
方差σ:方差越大,越分散(越不集中,在均值附近的面积越小)
例题1:23李林六套卷(三)9. 独立可加性
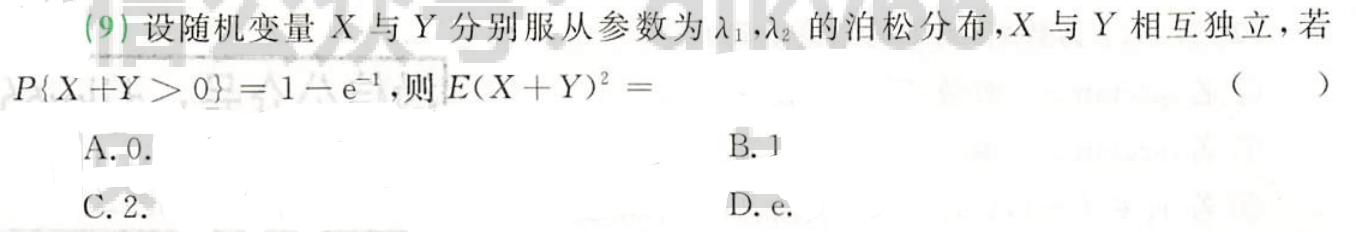
分析:

答案:C
习题1:17年14. 标准正态分布
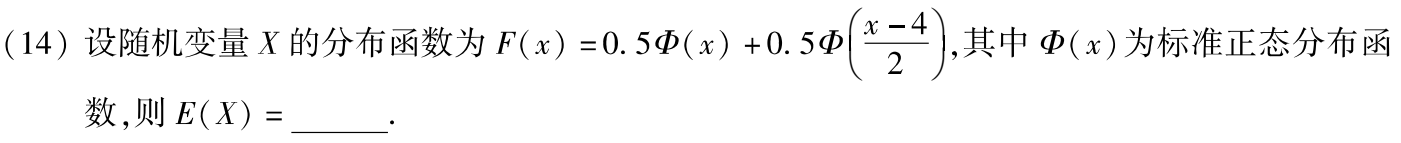
分析:

答案:2
习题2:19年23(1)

习题3:12年23. 正态分布的独立可加性

分析:
(3)注意样本与总体独立同分布
答案:
(1)∵X与Y相互独立且分别服从正态分布
∴由正态分布的独立可加性知 Z=X-Y 也服从正态分布,Z~N(0,3σ2)
(3) E ( σ ^ 2 ) = E ( ∑ i = 1 n Z i 2 3 n ) = 1 3 n E ( ∑ i = 1 n Z i 2 ) = 1 3 n ∑ i = 1 n E ( Z i 2 ) = 1 3 n ∑ i = 1 n E ( Z 2 ) = 1 3 n × n × [ D ( Z ) + E 2 ( Z ) ] = 1 3 × ( 3 σ 2 + 0 ) = σ 2 E(\hat{σ}^2)=E(\dfrac{{\sum\limits_{i=1}^n}Z_i^2}{3n})=\dfrac{1}{3n}E(\sum\limits_{i=1}^n{Z_i^2})=\dfrac{1}{3n}\sum\limits_{i=1}^nE({Z_i^2})=\dfrac{1}{3n}\sum\limits_{i=1}^nE({Z^2})=\dfrac{1}{3n}×n×[D(Z)+E^2(Z)]=\dfrac{1}{3}×(3σ^2+0)=σ^2 E(σ^2)=E(3ni=1∑nZi2)=3n1E(i=1∑nZi2)=3n1i=1∑nE(Zi2)=3n1i=1∑nE(Z2)=3n1×n×[D(Z)+E2(Z)]=31×(3σ2+0)=σ2
∴ σ ^ 2 \hat{σ}^2 σ^2是σ2的无偏估计
习题4:13年07. 正态分布 μ,σ 对图像的影响
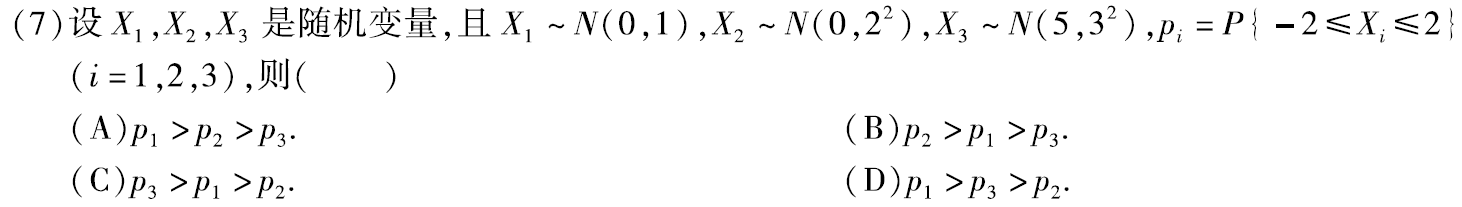
答案:A
习题5:06年14. 正态分布 μ,σ 对图像的影响
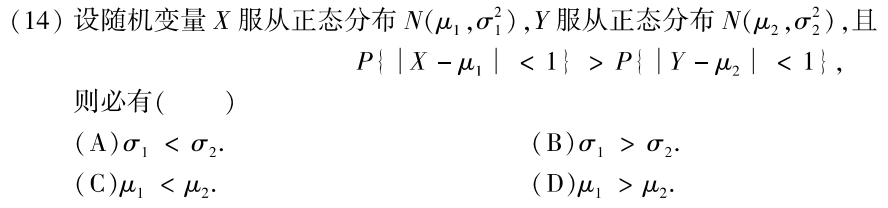
答案:A
习题6:16年7. 正态分布 μ,σ 对图像的影响
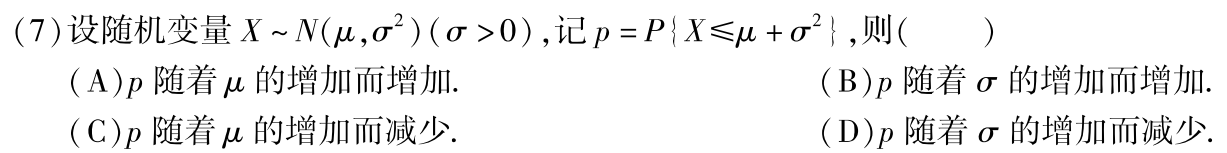
分析:将X标准化为标准正态分布

答案:B
6.一维随机变量函数的分布
Ch3. 多维随机变量及其分布
多维随机变量:联合、边缘、条件、独立性、函数分布
1.二维(n维)随机变量
1.多维随机变量
X:一维随机变量
(X,Y):二维随机变量
(X₁,X₂,…,Xn):n维随机变量

2.多维随机变量的分布函数
(1)联合分布函数
(1)概念
F ( x , y ) = P { X ≤ x , Y ≤ y } F(x,y)=P\{X≤x,Y≤y\} F(x,y)=P{X≤x,Y≤y} (-∞<x<+∞,-∞<y<+∞)

(2)性质
③二维规范性/归一性:若为二维连续型随机变量, F ( + ∞ , + ∞ ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1 F(+∞,+∞)=\int_{-∞}^{+∞}\int_{-∞}^{+∞}f(x,y){\rm d}x{\rm d}y = 1 F(+∞,+∞)=∫−∞+∞∫−∞+∞f(x,y)dxdy=1
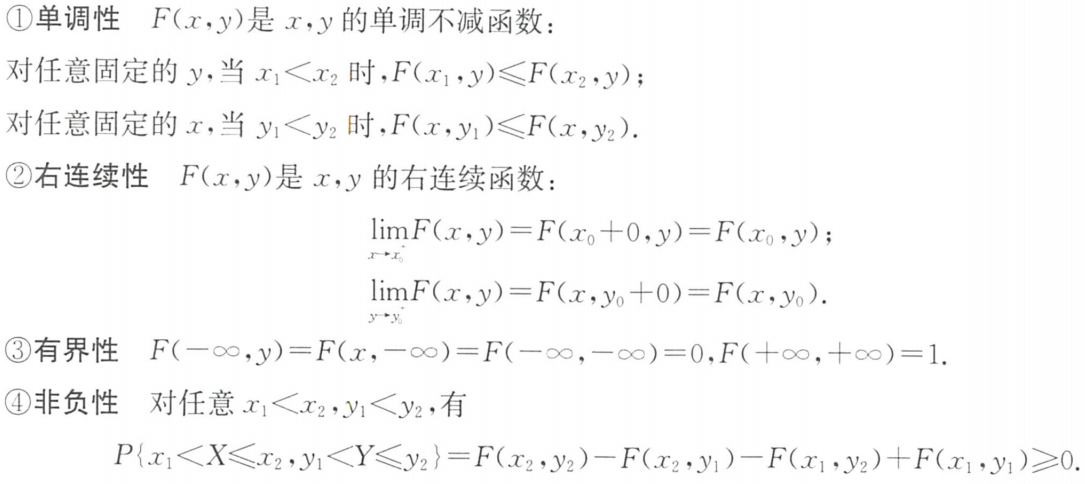
例题1:10年22.(1)
(2)边缘分布函数
F X ( x ) = P { X ≤ x , Y ≤ + ∞ } = F ( x , + ∞ ) F_X(x)=P\{X≤x,Y≤+∞\}=F(x,+∞) FX(x)=P{X≤x,Y≤+∞}=F(x,+∞)
F Y ( y ) = P { X ≤ + ∞ , Y ≤ y } = F ( + ∞ , y ) F_Y(y)=P\{X≤+∞,Y≤y\}=F(+∞,y) FY(y)=P{X≤+∞,Y≤y}=F(+∞,y)


边缘分布函数,考试常考
常见的两类二维随机变量:离散型随机变量、连续型随机变量
2.二维离散型随机变量及其分布
(1)联合分布律
p i j = P { X = x i , Y = y j } i , j = 1 , 2 , . . . p_{ij}=P\{X=x_i,Y=y_j\} \quad i,j=1,2,... pij=P{X=xi,Y=yj}i,j=1,2,...
(X,Y)的分布律 或 X和Y的联合分布律,记为 ( X , Y ) ∼ p i j (X,Y)\sim p_{ij} (X,Y)∼pij
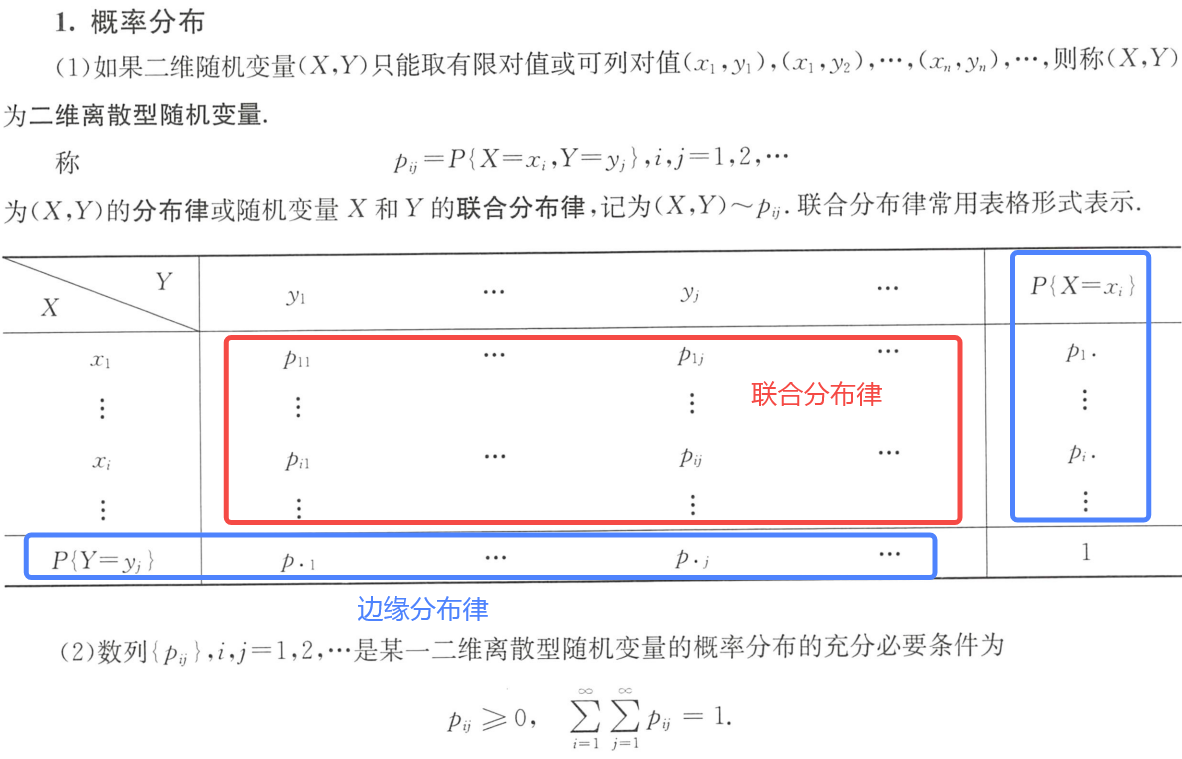
联合分布律的求法:求出每个P{ }的值,画分布律
例题1:09年22.(2)
(2)边缘分布律
联合分布律的右边缘 p i ⋅ p_{i·} pi⋅、下边缘 p ⋅ j p_{·j} p⋅j,称为X、Y的边缘分布律
联合分布律: p i j = P { X = x i , Y = y j } p_{ij}=P\{X=x_i,Y=y_j\} pij=P{X=xi,Y=yj}
边缘分布率:
① p i ⋅ = P { X = x i } p_{i·}=P\{X=x_i\} pi⋅=P{X=xi}
② p ⋅ j = P { Y = y j } p_{·j}=P\{Y=y_j\} p⋅j=P{Y=yj}
(3)条件分布律
条件 = 联合 边缘 条件=\dfrac{联合}{边缘} 条件=边缘联合

3.二维连续型随机变量及其分布
(1)二维随机变量的概率密度 f(x,y):联合概率密度
(1)定义
设F(x,y) 是 二维随机变量(X,Y) 的 分布函数,若存在非负函数f(x,y),使得对于任意实数x、y,有 F ( x , y ) = ∫ − ∞ y ∫ − ∞ x f ( u , v ) d u d v F(x,y)=\int_{-∞}^y\int_{-∞}^xf(u,v)dudv F(x,y)=∫−∞y∫−∞xf(u,v)dudv
则称(X,Y)为二维连续型随机变量,称函数f(x,y)为二维随机变量(X,Y)的概率密度(随机变量X和Y的联合概率密度)
(2)性质
1.非负性:f(x,y)≥0
2.规范性/归一性:
F ( x , y ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = F ( + ∞ , + ∞ ) = 1 F(x,y)=\int_{-∞}^{+∞}\int_{-∞}^{+∞}f(x,y)dxdy=F(+∞,+∞)=1 F(x,y)=∫−∞+∞∫−∞+∞f(x,y)dxdy=F(+∞,+∞)=1
3.设D是xOy平面上的一个区域,则(X,Y)落在D内的概率为
P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\{(X,Y)∈D\}=\iint\limits_Df(x,y){\rm d}x{\rm d}y P{(X,Y)∈D}=D∬f(x,y)dxdy
举例: 若 Z = 2 X − Y ,则 F Z ( z ) = P { Z ≤ z } = P { 2 X − Y ≤ z } = ∬ 2 x − y ≤ z f ( x , y ) d x d y 若Z=2X-Y,则F_Z(z)=P\{Z≤z\}=P\{2X-Y≤z\}=\iint\limits_{2x-y≤z}f(x,y)dxdy 若Z=2X−Y,则FZ(z)=P{Z≤z}=P{2X−Y≤z}=2x−y≤z∬f(x,y)dxdy
当(X,Y)服从二维均匀分布时, P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y = S ( D ) S ( A ) P\{(X,Y)∈D\}=\iint\limits_Df(x,y){\rm d}x{\rm d}y=\dfrac{S(D)}{S(A)} P{(X,Y)∈D}=D∬f(x,y)dxdy=S(A)S(D)
4.偏导

例题1:03年5. 二维连续型随机变量的分布:f(x,y)的性质 注意积分区域的限:D∩定义域

分析:设D是xOy平面上的一个区域,则(X,Y)落在D内的概率为 P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\{(X,Y)∈D\}=\iint\limits_Df(x,y){\rm d}x{\rm d}y P{(X,Y)∈D}=D∬f(x,y)dxdy
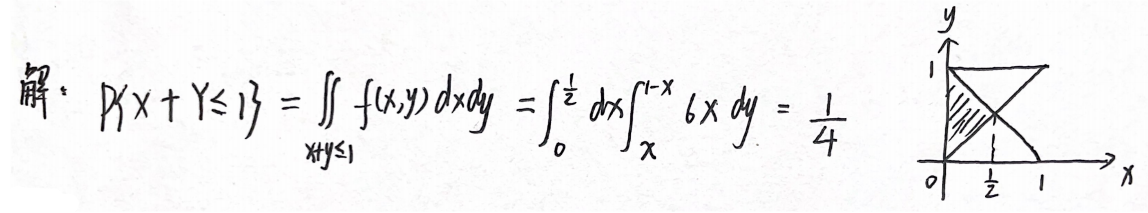
答案: 1 4 \dfrac{1}{4} 41
例题2:12年07. f(x,y)的性质: P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\{(X,Y)∈D\}=\iint\limits_Df(x,y){\rm d}x{\rm d}y P{(X,Y)∈D}=D∬f(x,y)dxdy

分析:
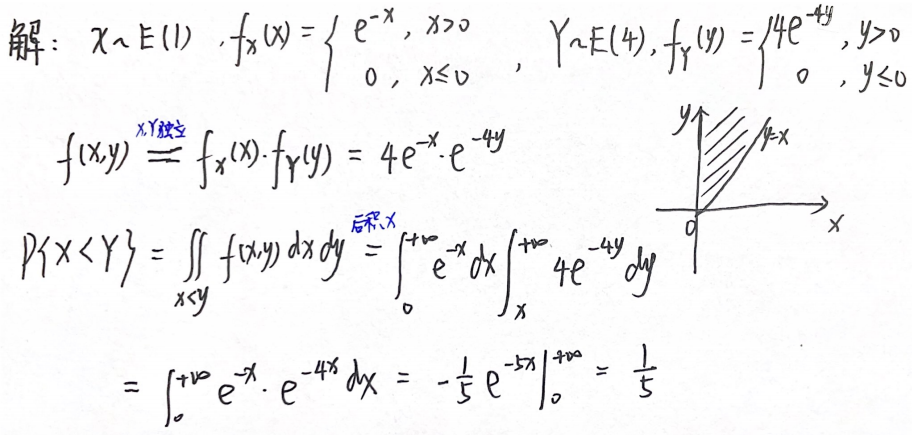
答案:A
例题3:16年22.(2)
(2)边缘分布
1.边缘概率分布
F X ( x ) = F ( x , + ∞ ) = ∫ − ∞ x [ ∫ − ∞ + ∞ f ( u , v ) d v ] d u F_X(x)=F(x,+∞)=\int_{-∞}^x[\int_{-∞}^{+∞}f(u,v)dv]du FX(x)=F(x,+∞)=∫−∞x[∫−∞+∞f(u,v)dv]du
F Y ( y ) = F ( + ∞ , y ) F_Y(y)=F(+∞,y) FY(y)=F(+∞,y)
2.边缘概率密度
f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y f_X(x) = \int_{-∞}^{+∞}f(x,y){\rm d}y fX(x)=∫−∞+∞f(x,y)dy 【注意上下限是代y的取值,x是常数】
f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x f_Y(y) = \int_{-∞}^{+∞}f(x,y){\rm d}x fY(y)=∫−∞+∞f(x,y)dx
例题1:由联合概率密度求边缘概率密度
口诀:求谁不积谁,后积先定限,限内画条线,先交写下限,后交写上限

例题2:10年22.(2)
(3)条件分布
1.条件概率密度
f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) f_{X|Y}(x\ |\ y) = \dfrac{f(x,y)}{f_Y(y)} fX∣Y(x ∣ y)=fY(y)f(x,y)
f Y ∣ X ( y ∣ x ) = f ( x , y ) f X ( x ) f_{Y|X}(y\ |\ x) = \dfrac{f(x,y)}{f_X(x)} fY∣X(y ∣ x)=fX(x)f(x,y) 【条件= 联合/边缘】
概率密度乘法公式:
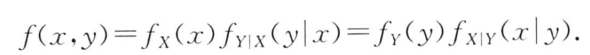
2.条件分布函数
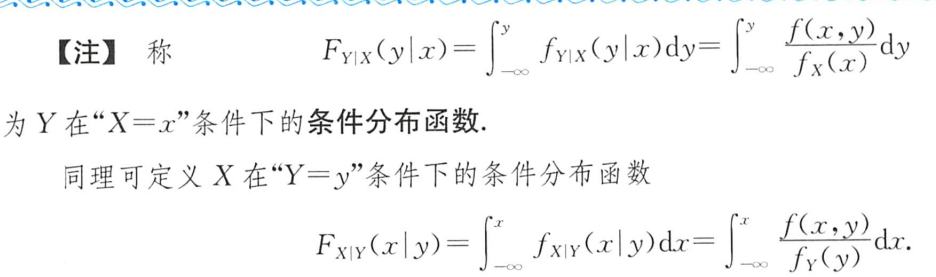
例题1:07年10. 条件概率密度

分析:
∵ 随机变量(X,Y)服从二维正态分布,且X与Y不相关,则X与Y相互独立。
∴ f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) = f X ( x ) ⋅ f Y ( y ) f Y ( y ) = f X ( x ) f_{X|Y}(x\ |\ y) = \dfrac{f(x,y)}{f_Y(y)}=\dfrac{f_X(x)·f_Y(y)}{f_Y(y)}=f_X(x) fX∣Y(x ∣ y)=fY(y)f(x,y)=fY(y)fX(x)⋅fY(y)=fX(x)

答案:A
例题2:22年10.
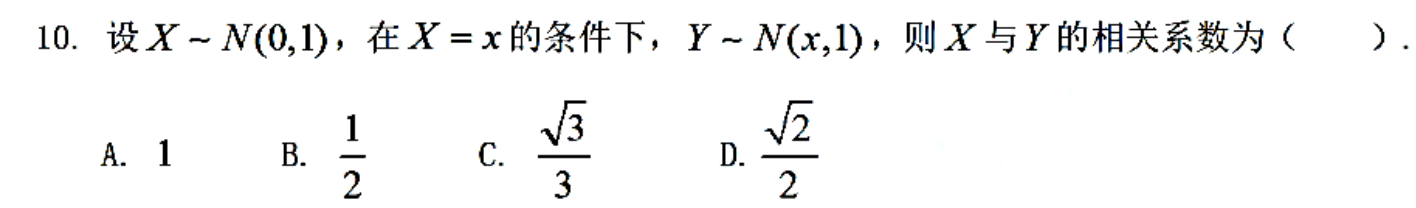
答案:D
例题3:10年22.(2)
(4)二维均匀分布
设D是坐标平面xOy上面积为A的有界区域D,若二维随机变量(X,Y)的概率密度为
f ( x , y ) = { 1 A , ( x , y ) ∈ D , 0 , ( x , y ) ∉ D f(x,y)= \left \{\begin{array}{cc} \dfrac{1}{A}, &(x,y)∈D,\\ 0, & (x,y)∉D \end{array}\right. f(x,y)={A1,0,(x,y)∈D,(x,y)∈/D
则称(X,Y)在区域D上服从均匀分布,记为 (X,Y) ~ UD
例题1:16年22.

答案:查看李艳芳的讲解
(5)二维正态分布
1.定义:
若二维随机变量(X,Y)的概率密度为
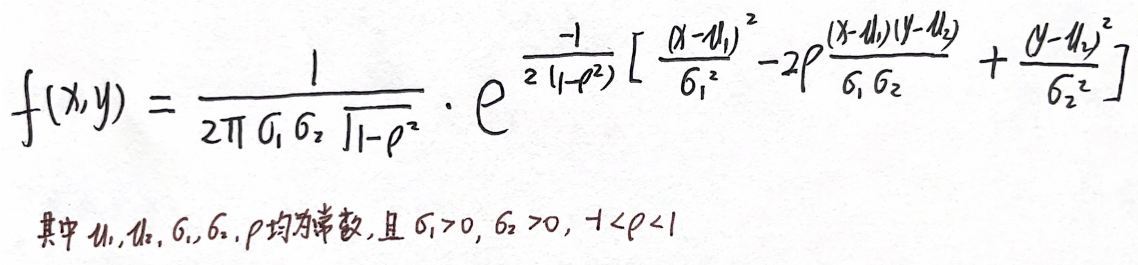
则称(X,Y)为服从参数μ1,μ2,σ1,σ2,ρ的二维正态分布,记作 ( X , Y ) ∼ N ( μ 1 , μ 2 ; σ 1 , σ 2 ; ρ ) (X,Y)\sim N(μ_1,μ_2;σ_1,σ_2;ρ) (X,Y)∼N(μ1,μ2;σ1,σ2;ρ)
2.性质
(1)二维正态分布:X与Y相互独立 ⇦⇨ X与Y不相关,ρXY=0
(2)若(X,Y)服从二维正态分布,则:
①X、Y各自服从一维正态分布:
即若有 ( X , Y ) ∼ N ( μ 1 , μ 2 ; σ 1 , σ 2 ; ρ ) (X,Y)\sim N(μ_1,μ_2;σ_1,σ_2;ρ) (X,Y)∼N(μ1,μ2;σ1,σ2;ρ),则 X ∼ N ( μ 1 , σ 1 ) X\sim N(μ_1,σ_1) X∼N(μ1,σ1), Y ∼ N ( μ 2 , σ 2 ) Y\sim N(μ_2,σ_2) Y∼N(μ2,σ2)
②X,Y的线性组合 a X + b Y ( a ≠ 0 或 b ≠ 0 ) aX+bY\quad (a≠0或b≠0) aX+bY(a=0或b=0) 也服从正态分布
例题1:15年14. 二维正态分布, ρ = 0 ρ=0 ρ=0则X与Y独立
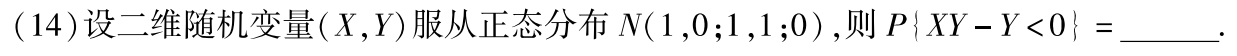
分析:
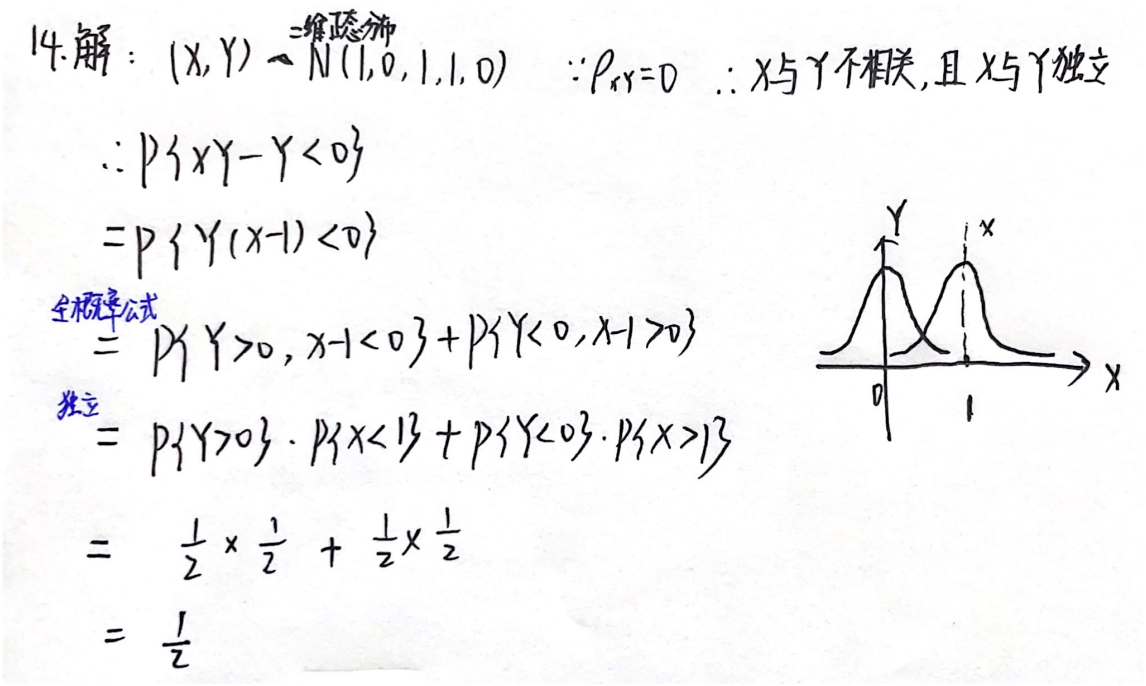
答案: 1 2 \dfrac{1}{2} 21
例题2:11年14.
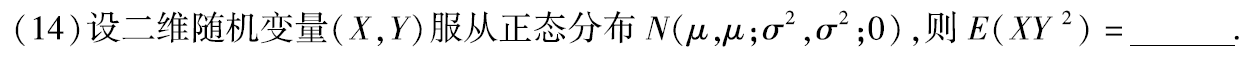
分析:∵ρ=0 ∴X与Y相互独立 ∴E(XY²)=E(X)·E(Y²)=E(X)·[D(X)+E²(Y)]=μ(σ²+μ²)
答案:μ(σ²+μ²)
例题3:07年10.
4.独立性 【随机变量的独立性】
(1)定义 (相互独立的充要条件)
对于(X,Y)是二维随机变量:
①普通:
P { X ≤ x , Y ≤ y } = P { X ≤ x } ⋅ P { Y ≤ y } ⇔ X , Y 独立 P\{X≤x,Y≤y\}=P\{X≤x\}·P\{Y≤y\}\Leftrightarrow X,Y独立 P{X≤x,Y≤y}=P{X≤x}⋅P{Y≤y}⇔X,Y独立
F ( x , y ) = F X ( x ) ⋅ F Y ( y ) ⇔ X , Y 独立 F(x,y)=F_X(x)·F_Y(y)\Leftrightarrow X,Y独立 F(x,y)=FX(x)⋅FY(y)⇔X,Y独立
②离散: ∀ i , j ∀i,j ∀i,j,有 p i j = p i ⋅ ⋅ p ⋅ j ⇔ X , Y 独立 p_{ij}=p_{i·}·p_{·j}\Leftrightarrow X,Y独立 pij=pi⋅⋅p⋅j⇔X,Y独立
若 ョ i , j ョi,j ョi,j,使得 p i j ≠ p i ⋅ ⋅ p ⋅ j p_{ij}≠p_{i·}·p_{·j} pij=pi⋅⋅p⋅j,则X,Y不独立
③连续: f ( x , y ) = f X ( x ) ⋅ f Y ( y ) ⇔ X , Y 独立 f(x,y)=f_X(x)·f_Y(y)\Leftrightarrow X,Y独立 f(x,y)=fX(x)⋅fY(y)⇔X,Y独立
(2)独立的性质
两变量独立,则P{ }可拆:P{X≤a}·P{Y≤b} = P{X≤a,Y≤b}
注意,F要先转换为P,然后P可拆。
详情查看此文:https://blog.csdn.net/Edward1027/article/details/126604163
5.二维随机变量 函数的分布
常考三类多维随机变量
(1)(离散型,离散型)→离散型
比较简单
(2)(连续型,连续型)→连续型
①分布函数法
P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\{(X,Y)∈D\}=\iint\limits_Df(x,y){\rm d}x{\rm d}y P{(X,Y)∈D}=D∬f(x,y)dxdy
① F Z ( z ) = P { Z ≤ z } = P { g ( x , y ) ≤ z } = ∬ g ( x , y ) ≤ z f ( x , y ) d x d y F_Z(z)=P\{Z≤z\}=P\{g(x,y)≤z\}=\iint\limits_{g(x,y)≤z}f(x,y){\rm d}x{\rm d}y FZ(z)=P{Z≤z}=P{g(x,y)≤z}=g(x,y)≤z∬f(x,y)dxdy
② f Z ( z ) = F Z ′ ( z ) f_Z(z)=F_Z'(z) fZ(z)=FZ′(z)
②卷积公式
卷积公式:专门针对 加、减、乘、除
口诀:积谁不换谁,换完求偏导 (对z求偏导,乘其系数的绝对值)
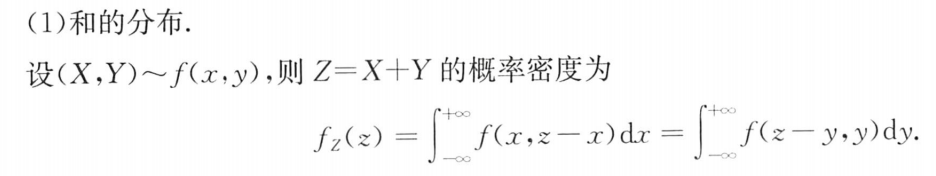
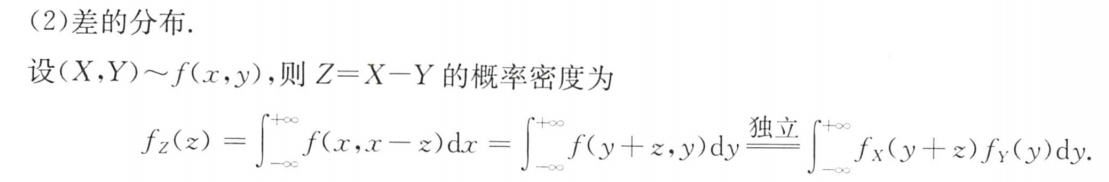


(3)(离散型,连续型)→连续型
①离散+连续:全概率公式
X和Y,一格离散,一个连续:Z=XY,先用全概率公式,再用独立性
例题1:基础30讲 3.11 离散+连续:全概率公式 (“全集分解思想”)

答案:

习题1:09年8. 离散+连续:全概率公式

分析:

答案:B
习题2:23李林4套卷(二)22.(1) 离散+连续:全概率公式

答案:



![[Vue] Vue2和Vue3的生命周期函数](https://img-blog.csdnimg.cn/6fb8a4e983ea4fc6ae691fc3f3662fc0.png)
![Qt扫盲-Qt Model/View 理论总结 [下篇]](https://img-blog.csdnimg.cn/ac454f9df6ba4048bfaa7daabc22561b.png)