一. embedding
简单来说,embedding就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的物体有相近的含义,比如 Embedding(复仇者联盟)和Embedding(钢铁侠)之间的距离就会很接近,但 Embedding(复仇者联盟)和Embedding(乱世佳人)的距离就会远一些。
除此之外Embedding甚至还具有数学运算的关系,比如Embedding(马德里)-Embedding(西班牙)+Embedding(法国)≈Embedding(巴黎)
从另外一个空间表达物体,甚至揭示了物体间的潜在关系,上次体会这样神奇的操作还是在学习傅里叶变换的时候,从某种意义上来说,Embedding方法甚至具备了一些本体论的哲学意义。
Embedding在大模型中的价值
前面说的其实都是Embedding在之前的价值。但是,大语言模型时代,例如ChatGPT这样的模型流行之后,大家发现embedding有了新的价值,即解决大模型的输入限制。
此前,OpenAI官方也发布了一个案例,即如何使用embedding来解决长文本输入问题,我们DataLearner官方博客也介绍了这个教程:OpenAI官方教程:如何使用基于embeddings检索来解决GPT无法处理长文本和最新数据的问题 | 数据学习者官方网站(Datalearner)
像 GPT-3 这样的语言模型有一个限制,即它们可以处理的输入文本量有限。这个限制通常在几千到数万个tokens之间,具体取决于模型架构和可用的硬件资源。
这意味着对于更长的文本,例如整本书或长文章,可能无法一次将所有文本输入到语言模型中。在这种情况下,文本必须被分成较小的块或“片段”,可以由语言模型单独处理。但是,这种分段可能会导致输出的上下文连贯性和整体连贯性问题,从而降低生成文本的质量。
这就是Embedding的重要性所在。通过将单词和短语表示为高维向量,Embedding允许语言模型以紧凑高效的方式编码输入文本的上下文信息。然后,模型可以使用这些上下文信息来生成更连贯和上下文适当的输出文本,即使输入文本被分成多个片段。
此外,可以在大量文本数据上预训练Embedding,然后在小型数据集上进行微调,这有助于提高语言模型在各种自然语言处理应用程序中的准确性和效率。
如何基于Embedding让大模型解决长文本(如PDF)的输入问题?
这里我们给一个案例来说明如何用Embedding来让ChatGPT回答超长文本中的问题。
如前所述,大多数大语言模型都无法处理过长的文本。除非是GPT-4-32K,否则大多数模型如ChatGPT的输入都很有限。假设此时你有一个很长的PDF,那么,你该如何让大模型“读懂”这个PDF呢?
首先,你可以基于这个PDF来创建向量embedding,并在数据库中存储(当前已经有一些很不错的向量数据库了,如Pinecone)。
接下来,假设你想问个问题“这个文档中关于xxx是如何讨论的?”。那么,此时你有2个向量embedding了,一个是你的问题embedding,一个是之前PDF的embedding。此时,你应该基于你的问题embedding,去向量数据库中搜索PDF中与问题embedding最相似的embedding。然后,把你的问题embedding和检索的得到的最相似的embedding一起给ChatGPT,然后让ChatGPT来回答。
当然,你也可以针对问题和检索得到的embedding做一些提示工程,来优化ChatGPT的回答。
二、大模型
机器学习基础
深度学习
通过构建和训练深层神经网络来学习和提取数据中的特征,从而实现高度自动化和准确性能的模型训练和预测。
深度学习和大模型: 大模型技术通常与深度学习相结合,因为深度学习网络通常具有大量的参数和复杂的结构。大模型技术通过增加模型的规模和容量,例如增加网络层数、神经元的数量或卷积核的大小,以增强模型的表达能力和学习性能。大模型技术还包括优化算法和训练策略,以有效地训练和优化这些庞大的深度学习模型。
大模型概念
-
预训练是指在大规模的未标记数据上进行的初始化模型训练阶段。模型通过对大量的文本数据进行自监督学习,学习到语言的各种结构和表达方式。预训练的目标是让模型能够在下游任务中具有更好的理解和表达能力。预训练通常是通过自编码器或掩码语言建模的方式进行,其中模型要根据上下文预测缺失的词或片段。
-
微调:
微调是在预训练完成后,将预训练模型应用于特定任务并进行有监督的训练的过程。在微调阶段,模型使用标记的训练数据进行进一步的训练,以适应特定任务的要求。微调以较低的学习率进行,以避免过度调整预训练模型的参数,从而保留预训练模型所学到的知识。通常,微调的数据集规模相对较小,因此可以使用更少的计算资源和时间来完成。 -
语料:
语料是指用于模型训练的文本数据集。对于预训练大模型来说,用于预训练的语料库通常是非常庞大的,例如大规模的网页文本、维基百科、书籍、新闻等。预训练模型需要处理大量的语料来学习普遍的语言知识。对于微调阶段,语料可以是特定任务的标记训练集。
预训练、微调和语料是在大型NLP模型中实现强大性能的重要因素。通过预训练技术,模型可以从大量无监督的数据中学习语言特征,从而提高模型的泛化能力。通过微调过程,模型可以将预训练知识转移到特定任务中,并根据特定任务的训练数据进行细化调整。同时,使用多样化且广泛的语料库可以提高模型对不同领域和上下文的理解能力。
需要注意的是,预训练和微调的过程是基于大量的计算资源和大规模的数据集进行的。这也导致了建立和训练大型模型的门槛相对较高,并且模型可能带来较大的计算和存储要求。
大模型框架
除了ChatGPT,近期影响较大的有:Meta AI的LLaMA、斯坦福基于LLaMA的Alpaca、清华大学的GLM和ChatGLM
三、LangChain
参考:什么是LangChain - 知乎
LangChain是一个开源框架,允许从事人工智能的开发者将例如GPT-4的大语言模型与外部计算和数据来源结合起来。该框架目前以Python或JavaScript包的形式提供。
假设,你想从你自己的数据、文件中具体了解一些情况(可以是一本书、一个pdf文件、一个包含专有信息的数据库)。LangChain可以将GPT-4和这些外部数据连接起来,甚至可以让LangChain帮助你采取你想采取的行动,例如发一封邮件。
三个重要概念:
- Components
-LLM Wrapper:包装器,允许我们连接到大语言模型,例如GPT-4或HuggingFace的模型。
-Prompt Templates:提示模板,使我们不必对文本进行硬编码,而文本是LLM的输入。
-Indexes for relevant information retrieval:相关内容的索引,允许我们为LLM提取相关信息。
- Chains
允许我们将多个组件组合在一起,以解决一个特定的任务,并建立一个完整的LLM应用程序。
- Agents
允许LLM与外部API互动。

二、 原理
将你的文件切成小块,把这些小块存储在一个矢量数据库中,这些块被存储为embedding,意味着它们是文本的矢量表示。

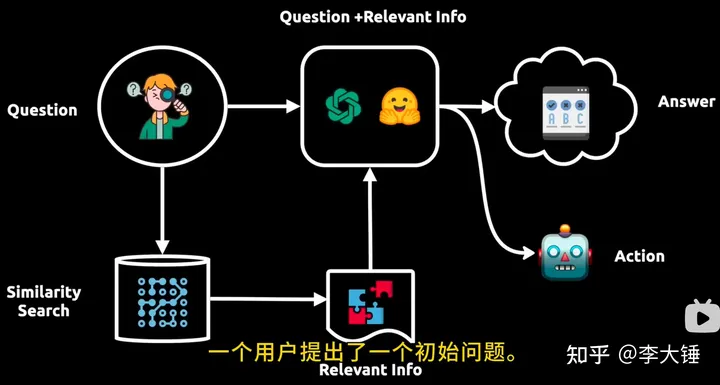
pipeline执行流程:
>>一个用户提出了初始问题。
>>然后,这个问题被发送到大语言模型,并将该问题的向量表示在向量数据库中做相似性搜索。
>>获取相关的信息块,将其反馈给大语言模型。
>>大语言模型通过初始问题和来自矢量数据库的相关信息,提供一个答案或采取一个行动。