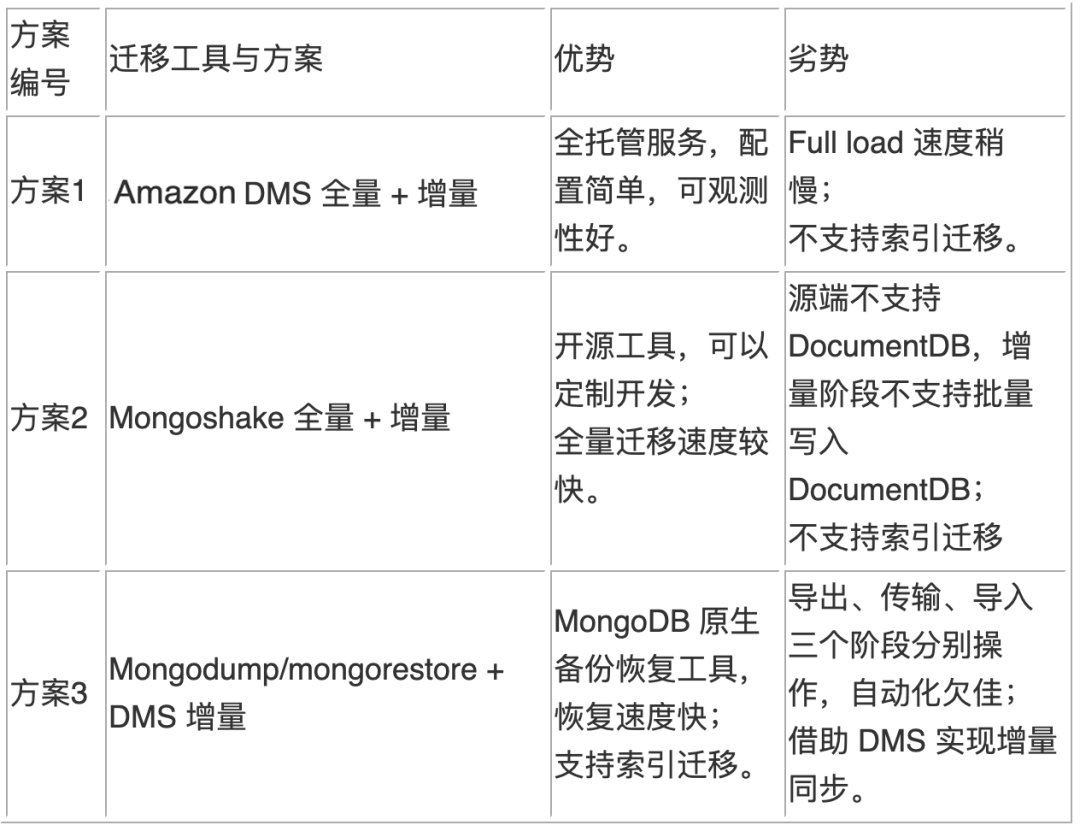
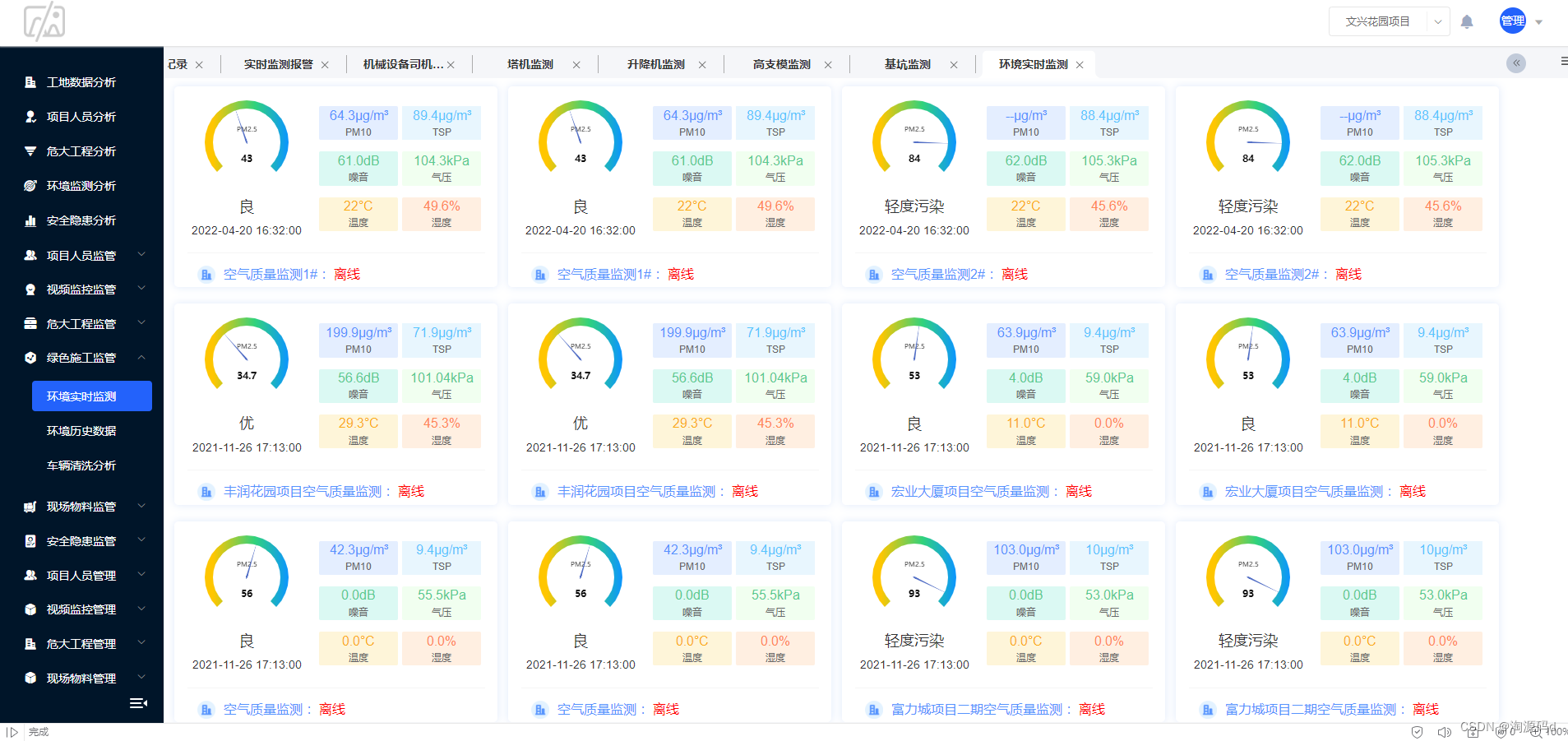
性能测试场景设计
- 一、引言:如果公司要求你去做性能测试,遇到这些场景,我们要如何设计?
- 二、6种常见设计方法
- 1、普通性能场景设计
- 2、负载测试性能场景
- 3、压力测试场景
- 4、面向目标性能场景
-
一、引言:如果公司要求你去做性能测试,遇到这些场景,我们要如何设计?
需求1, 活动页面,要你做性能测试, 看是否能满足1000个人同时访问
需求2:对接的接口,如果要满足 50tps,这样的场景怎么设计
需求3: 秒杀活动要看秒杀时,服务器能否支持500个人同时秒杀
-
二、6种常见设计方法
- 普通性能场景设计
- 阶梯性能场景(负载测试场景)
- 压力测试场景
- 面向目标场景(lr很容易,但是jmeter,没有系统讲解,会不知道怎么做)
- 混合场景设计(混合,if条件)不同数量的人,向不同的接口发起请求
- 有时间规律场景
-
1、普通性能场景设计
-
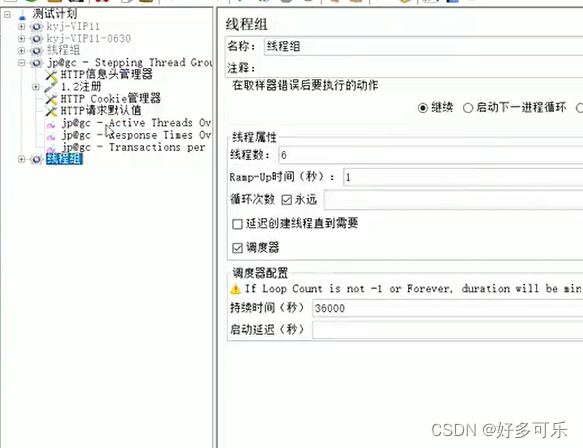
线程组
-
1)线程数: 模拟的并发用户数量
- 线程数,有没有限制呢?
- jmeter本身是没有对线程数做限制
- 但是, jmeter启动这些并发用户数时,需要消耗资源,受电脑cpu的主频限制,一台电脑不可能创建无限量的线程数
- 实际的情况是比如http协议的脚本的线程数,大概能产生1500左右。2000个可能产生,但是可能会出错。1000左右比较保守,可能能产生。
- 也就是说,1台电脑,http协议脚本,保守估计是可以产生1000个并发用户数
- 如果你想模拟超过1000并发用户数,你可能需要考虑 分布式来实现
- 线程数,有没有限制呢?
-
2)ramp-up时间
- 启动所有线程的时间(前提:线程数设置在合理的范围)
- 在ramp-up时间结束点,所有的线程都会启动
- 案例:5s内启动300个线程

- 在ramp-up时间内,是否均匀产出并发用户数,是无法确定的(拿上面的例子举例,不能保证每秒启动60个线程)
- 在启动时间内,产生的并发用户数,一产生,就会去发起请求
- 启动了并发用户,就会去发起请求,不同时间产生的并发用户数,与前面产生的并发用户数,调用的接口可能不一样
- jmeter做性能测试,更多时候,使用的是,广义并发
- ramp-up时间要大于等于1
- 线程数和ramp-up时间,怎么设置才比较合理?
- 500以内并发用户, ramp-up时间建议设置2~4s
- 500-1000的并发,ramp-up时间建议设置5s
- >1000 ramp-up时间建议设置5-8s
- 一个原则:
- ramp-up时间在总执行时间中,占比要很低(比如你总执行时间是10s,那上面那些建议时间就太高啦hhh)。
- 一般的情况,一个性能测试的总执行时间是几十秒钟~几十分钟
-
3) 循环次数

- 默认必须大于等于1
- 循环次数,就是每个并发用户数要去执行的请求数量
- 如果勾选了永远选项,就会一直循环,直到你点击停止
- 这个停止会有问题吗?
- 如果勾选了永远后点击停止,会导致请求报错或卡死
- 这个选项要与调度器 一起使用
- 调度器:
- 持续时长:设置持续时长(s)
- 启动延迟:设置延迟时长(s),一般真正做性能测试的时候不用
- 实践:300个并发用户,持续运行300s(忘了截图了,先把数据贴上来吧,尴尬。我们的脚本可以加上聚合报告和响应时间图)
- 聚合报告如下: avgRT: 0.117s 90%RT:0.262s avgTPS: 2544.9
- 结论:
- 90%RT:0.262s 可以看到,这个响应时间是比较快的,因为用户满意度指数1.5s
- 300个人, avgTPS: 2544.9 tps>user 那么,每个人1秒钟发了约8个请求,所以,我们本次300个并发用户数,未超过这个接口能承受最大并发用户数
- 可以简单得到一个结论: 这个查询接口最大并发用户数大于300
- 这个停止会有问题吗?
-
-
-
2、负载测试性能场景
- 负载测试: 逐步增加并发用户数
- 我们可以下载插件实现这个功能 下载插件步骤
- 插件管理: jpgc(这里后面记得加个空格,否则搜不到哦) 安装这个插件
- 添加方式:线程组-jp@gc stepping thread group

- 总共启动100个线程,然后用5秒钟增加10个并发用户数,持续运行30秒。当100个线程全部启动后,持续运行60然后每1s逐步停止5个线程
-
完全不知道项目的性能瓶颈范围时,我们怎么设置?
- 答:我们可以从0 - 100,200…逐步加压,这样就可以找到瓶颈啦~
-
已经找到一个范围了,怎么设置?
- 答:举个栗子,比如我们已经找到了最大的范围是20-30,那我们可以设置总线程数为30,然后设置每60s增加1个线程,然后设置那个线程的启动时间为1s,持续60s。最后每1s停止5个线程,直到最终停止

- 答:举个栗子,比如我们已经找到了最大的范围是20-30,那我们可以设置总线程数为30,然后设置每60s增加1个线程,然后设置那个线程的启动时间为1s,持续60s。最后每1s停止5个线程,直到最终停止
-
那么线程组跑完以后,我们要怎么查看呢?
- 我们可以通过添加监听器的方式进行查看,gc为我们提供了5个监听器
- jp@gc - Active Threads Over Time:随着时间变化的并发用户数图
- jp@gc - Flexible File Writer
- jp@gc - PerfMon Metrics Collector
- jp@gc - Response Times Over Time:响应时间和随着时间变化的响应时间图
- jp@gc - Transactions per Second :tps的图,可以看成功和失败,如果这边显示失败,可能表示服务器已经到达瓶颈

ps:分析的时候可以多张图一起看
- 我们可以通过添加监听器的方式进行查看,gc为我们提供了5个监听器
- 我们思考个问题,增加的这个量,一定相同吗?
- 答: 增加的量(步长),可以相同,也可以不相同
- 相同只是一种特殊请求 stepping threads group(就是上面这个)
- 不相同的增量,是不能用这个的
- 答: 增加的量(步长),可以相同,也可以不相同
- 在阶梯线程组,执行过程中,我们的并发用户数是时刻发生变化
- 阶梯线程组设计的规律:
- 缓起步,快结束
- 快结束: 并不是瞬间结束,只是相对缓慢的结束,为什么要这么做呢,因为如果立刻停止,可能导致服务中断而报错(把这种人为导致的错误算在服务器头上显然是不合理的)
- 缓起步,快结束
- 阶梯线程组可以看聚合报告吗?
- 答:聚合报告中的数据,都是平均值。在负载场景/阶梯场景,看了也没有意义
- 但是这边注意一点,性能测试时,能不启用监听器,则不启用
- 真正做性能测试,怎么做呢?
- CLI-mode 无图形界面模式 命令行
- GUI-mode 仅仅用于编写调试脚本
- 没有监听器,我们怎么知道性能测试结果?
- jmeter的html报告,与是否启用添加监听器无关,不信我们可以测试下。我们在不添加监听器的情况下,先在工具里点击generate html report,然后把jtl文件导入第一个,选择jmeter.properties/user.properties导入第二个,然后新建一个空文件夹,导入第三个,然后点击生成,然后查看报告,一样可以看到结果



- jmeter的html报告,与是否启用添加监听器无关,不信我们可以测试下。我们在不添加监听器的情况下,先在工具里点击generate html report,然后把jtl文件导入第一个,选择jmeter.properties/user.properties导入第二个,然后新建一个空文件夹,导入第三个,然后点击生成,然后查看报告,一样可以看到结果
- 真正做性能测试,怎么做呢?
-
3、压力测试场景
- 特点:长时间,看稳定性
- 具体我们要怎么设计压力测试场景呢?
- 比如我们有个接口的最大的并发数是29,那我们可以这么设计:
-
29 * 20% = 6 我们可以用20%的线程,就是6个线程压10h
-
29 * 80% = 24 我们可以用80%的线程,就是24个线程压10h,这个我们用阶梯测试的方式来演示

-
4、面向目标性能场景
-
需求: 期望我项目的接口,都要能满足50tps
- 50tps表示每秒50个事务
- 我们为什么得出要50t/s呢,我们可以来算下:
- 1分钟: 50*60s = 3000个事务
- 1小时 3000 * 60 = 180000 事务,就是1小时要处理18w个请求
- 10小时就是180w,24h就是432w个请求
- 单纯一个接口都能支持这么大的请求了,而且还有其他接口帮忙分担流量。中小微企业的产品日均访问量约为千万, 50tps基本已经能满足要求了
-