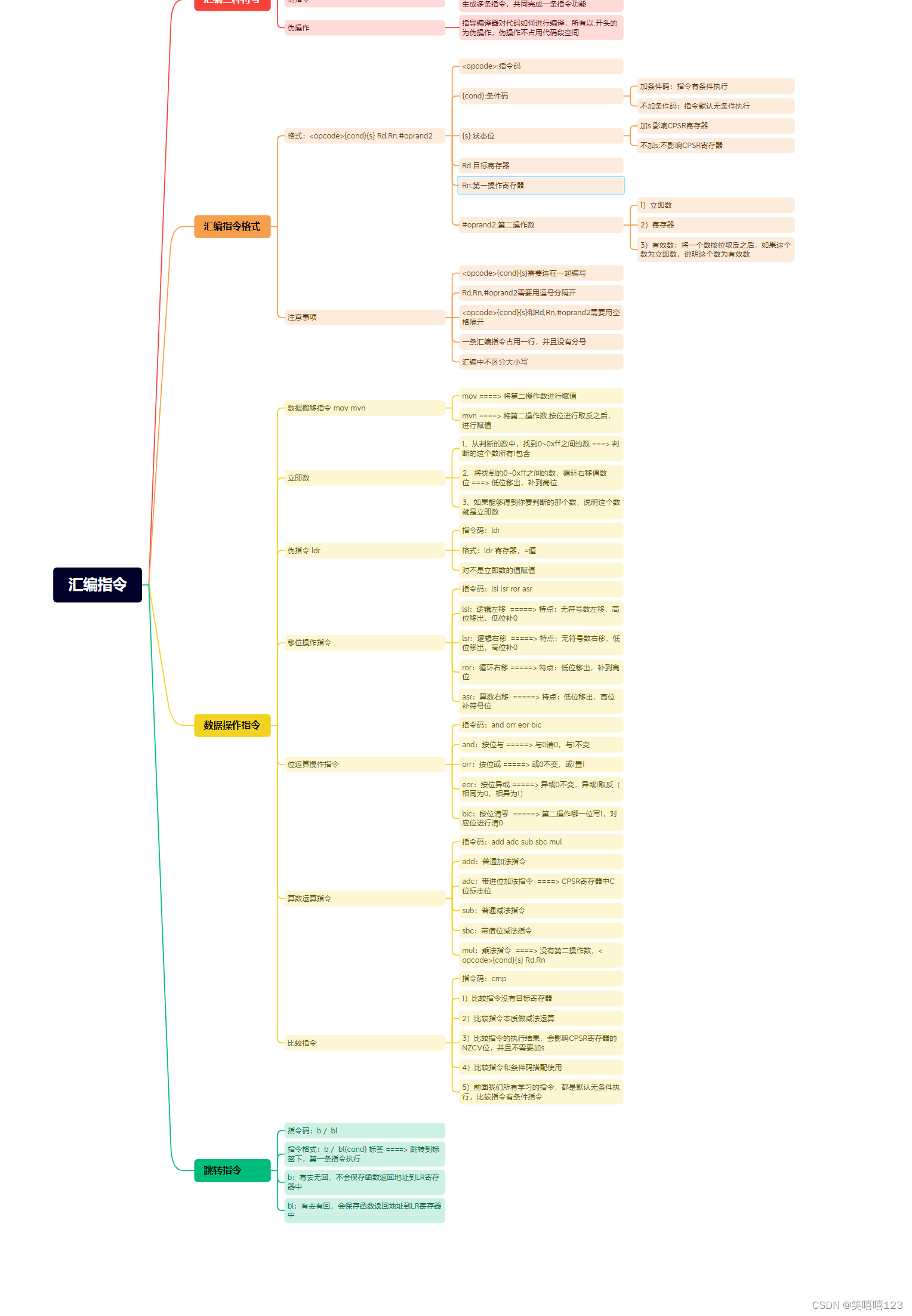
一、数据库、数据仓库、数据湖
1.什么是数据库 (Database, DB)
数据库是指长期储存在计算机中的有组织的, 可共享的数据集合
就是存储数据的仓库
数据库有三个特点: 永久存储, 有组织, 可共享
数据库是一种结构化数据存储技术,用于存储和管理有组织的数据。数据库通常使用关系型模型来组织数据,并使用SQL来查询和操作数据。数据库是用于处理事务性数据的最常见类型的存储,适用于需要高度结构化和规范化的应用场景,例如企业管理系统、电子商务平台等。
2.什么是数据仓库(Data Warehouse)
数据仓库是一个面向主题的、集成的、非易失的、随着时间变化的,用于支持管理人员决策的数据集合。
数据仓库是一种专门用于分析和报告的大型结构化数据存储技术。与传统数据库不同,数据仓库通常包含历史记录和大量冗余信息,以便支持复杂的分析查询。它们通常是企业级解决方案,用于从各种源中采集和存储数据,以便进行分析和报告。通常使用数据仓库ETL工具将数据从多个源中提取并转换为通用格式,然后将其加载到数据仓库中,并使用OLAP工具进行多维分析。
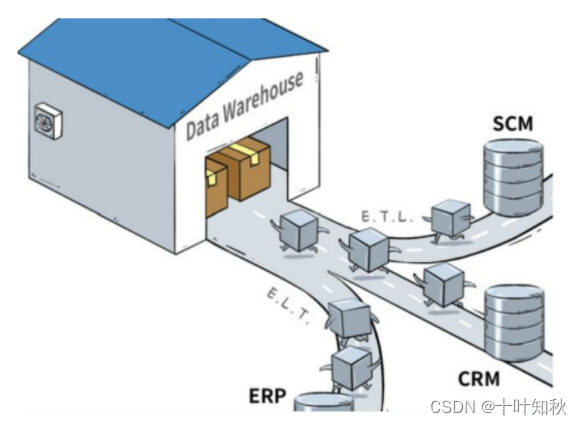
将数据经过数仓建模形成 ODS、DWD、DWS、DM 等不同数据层,每层都需要进行清洗、加工、整合等数据开发(ETL)工作,并最终加载到关系型数据库中。
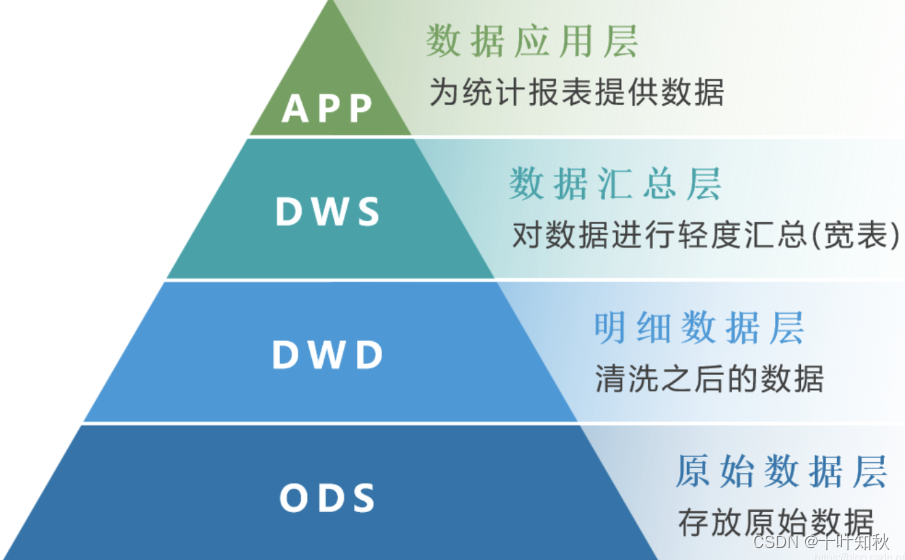
3.什么是数据湖
数据湖是一种存储理念,用于存储各种原始数据。
数据湖是一种非结构化或半结构化大型数据存储技术,用于存储各种类型和格式的原始或未处理的数据。数据库、数据仓库和数据湖的区别之一在于,数据湖通常不需要预定义模式或架构,并且可以在需要时进行灵活地查询和分析。数据湖也可以从多个源中采集和存储数据,但它们通常不会在数据加载之前对其进行转换。由于其灵活性和可扩展性,数据湖适用于大规模数据分析和机器学习等应用场景。
数据湖三种格式:
Iceberg、Hudi和Delta是三个用于大数据存储和处理的开源项目。它们都旨在提供更可靠、高效和可扩展的数据管理和分析解决方案。
4.数据仓库与数据湖的区别
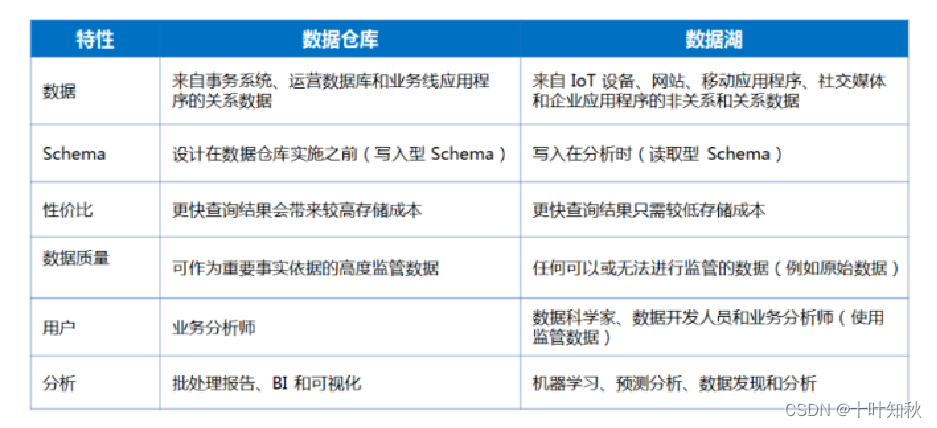
【注】写入型schema” v.s.“读取型schema”,其实本质上来讲是数据schema的设计发生在哪个阶段的问题。
“写入型schema”背后隐含的逻辑是数据在写入之前,就需要根据业务的访问方式确定数据的schema,然后按照既定schema,完成数据导入,带来的好处是数据与业务的良好适配;但是这也意味着数仓的前期拥有成本会比较高,特别是当业务模式不清晰、业务还处于探索阶段时,数仓的灵活性不够。
数据湖强调的“读取型schema”,背后的潜在逻辑则是认为业务的不确定性是常态:我们无法预期业务的变化,那么我们就保持一定的灵活性,将设计去延后,让整个基础设施具备使数据“按需”贴合业务的能力。
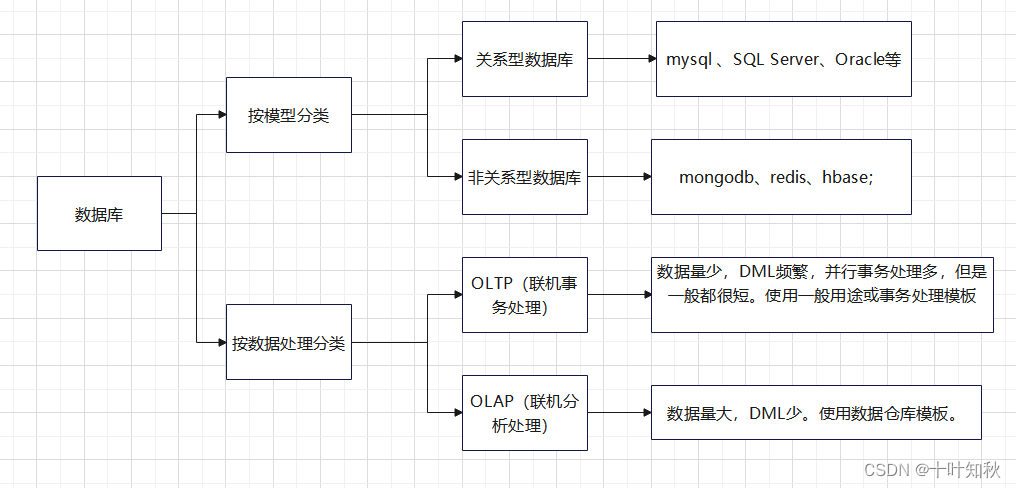
二、关系型数据库与非关系型数据库
1.关系型数据库
1.1概念
关系型数据库:指采用了关系模型来组织数据的数据库。
关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
● 关系:一张二维表,每个关系都具有一个关系名,也就是表名。
● 元组:二维表中的一行,在数据库中被称为记录。
● 属性:二维表中的一列,在数据库中被称为字段。
● 域:属性的取值范围,也就是数据库中某一列的取值限制。
● 关键字:一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成。
● 关系模式:指对关系的描述。其格式为:关系名 (属性 1,属性 2, … … ,属性 N),在数据库中成为表结构。
1.2.优势与不足
优势:
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的 SQL 语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性 (实体完整性、参照完整性和用户定义的完整性) 大大减低了数据冗余和数据不一致的概率
不足: - 网站的用户并发性非常高,往往达到每秒上万次读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
- 网站每天产生的数据量是巨大的,对于关系型数据库来说,在一张包含海量数据的表中查询,效率是非常低的。
- 在基于 web 的结构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库却没有办法像web server和app server那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。当需要对数据库系统进行升级和扩展时,往往需要停机维护和数据迁移。
- 性能欠佳:在关系型数据库中,导致性能欠佳的最主要原因是多表的关联查询,以及复杂的数据分析类型的复杂 SQL 报表查询。为了保证数据库的 ACID 特性,必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一个格式化的数据结构。
数据库事务必须具备ACID特性,ACID分别是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
1.3.当下流行的关系型数据库
● Oracle
● Microsoft SQL Server
● MySQL
● PostgreSQL
● DB2
● Microsoft Access
● SQLite
● Teradata
● MariaDB(MySQL 的一个分支)
● SAP
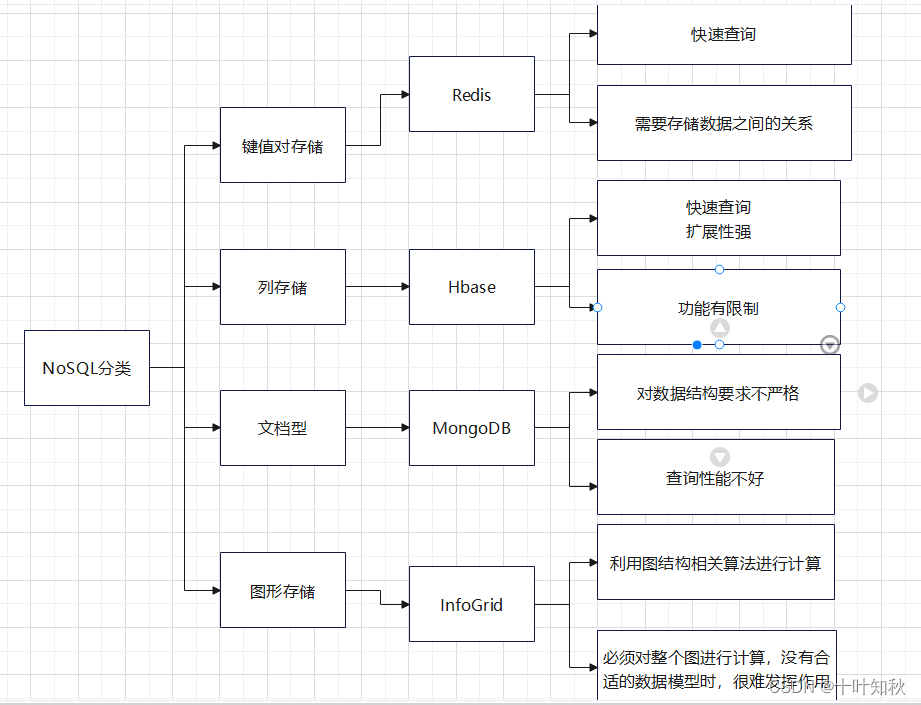
2.非关系型数据库
1.1概念
非关系型数据库:指非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。
非关系型数据库结构:
非关系型数据库以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,不局限于固定的结构,可以减少一些时间和空间的开销。
1.2.优点与不足
优点:
- 用户可以根据需要去添加自己需要的字段,为了获取用户的不同信息,不像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。
- 适用于SNS(Social Networking Services)中,例如 facebook,微博。系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库难以应付,需要新的结构化数据存储。由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
不足: - 只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,关系型数据库显得更为合适。
- 不适合持久存储海量数据。
1.3.分类 - 键值数据库:Redis、Memcached、Riak
- 列族数据库:Bigtable、HBase、Cassandra
- 文档数据库:MongoDB、CouchDB、MarkLogic
- 图形数据库:Neo4j、InfoGrid
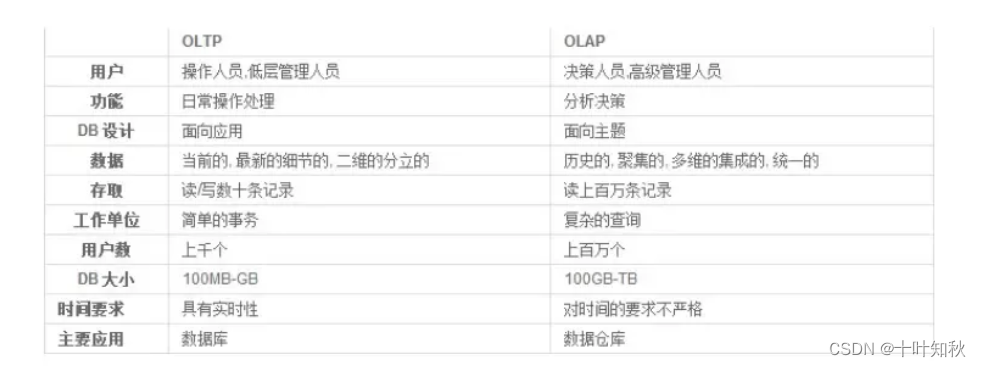
三、OLAP与OLTP
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作; OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
1.什么是OLAP
OLAP(On-Line Analytical Processing)联机分析处理
也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。应用在数据仓库,使用对象是决策者。OLAP系统强调的是数据分析,响应速度要求没那么高。
A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部 分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息。
2.什么是OLTP
OLTP(On-Line Transaction Processing)联机事务处理
它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。主要应用是传统关系型数据库。OLTP系统强调的是内存效率,实时性比较高。
3.OLTP与OLAP之间的比较:
总得来说:
联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据仓库模板。
联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁,并行事务处理多,但是一般都很短。使用一般用途或事务处理模板。
决策支持系统(DDS,Decision support system),典型的操作是全表扫描,长查询,长事务,但是一般事务的个数很少,往往是一个事务独占系统。
四、数据源、数据元、元数据
1.数据源
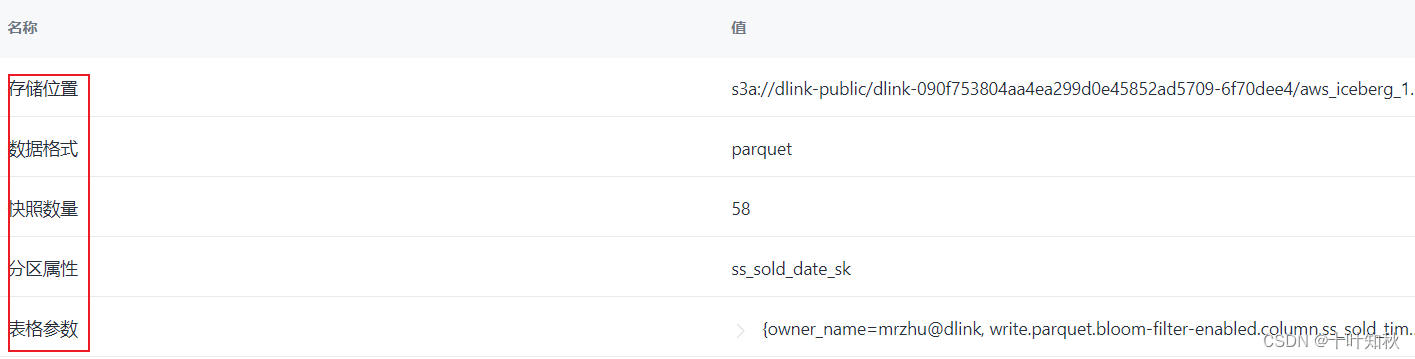
数据源(Data Source):数据源是指存储和提供数据的地方或系统。数据源可以是数据库、文件系统、API、传感器、网络服务等。它是数据的来源,提供了访问和读取数据的接口。数据源可以是结构化的数据库,也可以是非结构化的文件或流式数据。常见的数据源包括关系型数据库(如MySQL、Oracle)、分布式文件系统(如HDFS、Amazon S3)以及实时流处理系统(如Apache Kafka)等。
如dlink中:

2.数据元
据元(Data Element):数据元是指数据的基本单元,通常是指数据的最小、不可再分的组成部分。数据元可以是一个数据项、字段、属性、列或其他类似的概念。例如,在关系型数据库中,数据元可以是表的一列(字段);在文本文档中,数据元可以是一个单词或一个字符。数据元是组成数据的基本单位,它们的组合和关联形成了更复杂的数据结构。
数据元一般来说由三部分组成:
● 对象类:思想、概念或真实世界中的事物的集合,它们具有清晰的边界和含义,其特征和行为遵循同样的规则。
● 特性:对象类中的所有成员共同具有的一个有别于其它的、显著的特征。
● 表示:它描述了数据被表达的方式
3.元数据
概念:元数据(Metadata):元数据是关于数据的描述信息,它提供了关于数据的定义、结构、属性、关系和其他相关信息的数据。元数据可以包括数据的名称、类型、大小、创建时间、更新时间、所有者、数据源、数据质量等。
数据的作用可总结一下包括:描述、检索、选择、定位和关联分析等
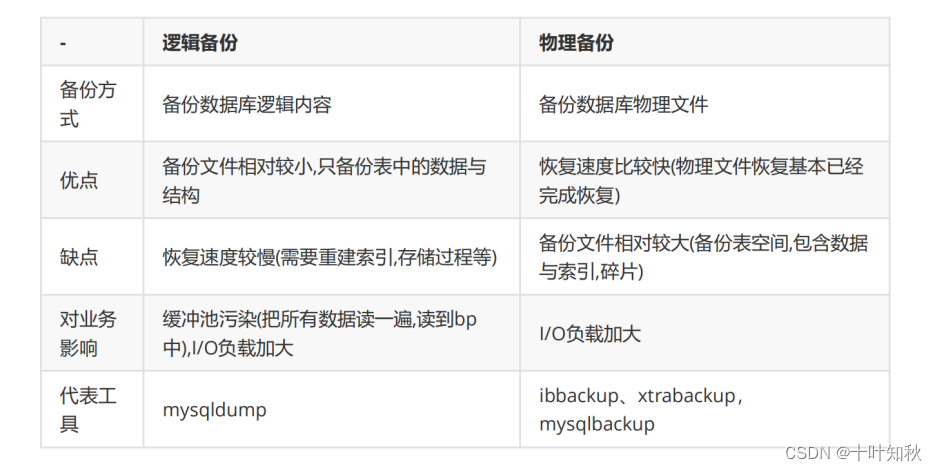
五、物理备份与逻辑备份
物理备份和逻辑备份是两种常见的数据备份方法,用于保护和恢复数据
1.物理备份
定义:物理备份是指直接备份存储在磁盘或存储介质上的原始数据副本。
它是对数据的二进制级别的备份,包括数据文件、操作系统文件、系统配置等。物理备份是一个底层备份方法,通常由数据库管理系统(如MySQL、Oracle等)提供的工具或第三方备份工具执行。
使用场景: 物理备份速度快,适用于大规模的数据恢复和灾难恢复,但对于特定的数据库或应用程序进行单独恢复或数据提取相对困难。使用工具:物理备份通常使用如 xtrabackup、RMAN等工具
2.逻辑备份
定义:逻辑备份是指将数据导出为可读的逻辑格式(如SQL语句、CSV文件等),并备份到文件系统或存储介质中。
使用场景:逻辑备份灵活,适用于特定的数据恢复和迁移需求。它可以选择性地备份特定的表、数据集、视图等,也可以进行数据转换和格式转换。常用的工具有 mysqldump、pg_dump
3.二者区别
六、思考
1.数据库从同构转化为异构,或者从异构转化为同构如何实现?MySQL->Mysql mysql-oracle ?
2.大数据量的数据备份迁移,怎么做,如何选择备份策略,如何保证数据一致性?
3.数据检验的方式方法?