篇前感悟:
阅读分布式系统文章的意义其实并不在于你个人真正地去开发这样一个基于这种协议的系统,因为真正去开发一个高可用的分布式系统实在是太难了(对我来说…)更多的还是汲取其中的思想,包括设计思路,优化思路等等。 简单地举个例子,比如说这篇优化中的witness角色引入,也许也可以在其他系统中得到应用。 真正能在工程实践中使用到的并非是完整的一篇论文,而是其中的一个点、两个点。
建议阅读:
- 更多背景介绍: https://zhuanlan.zhihu.com/p/428147777
- 更多细节:https://zhuanlan.zhihu.com/p/66427412
一、假设
- 仅处理crash failure,不考虑拜占庭故障
- 针对异步网络
- 2f+1个节点可以容忍f个节点发生非拜占庭故障
二、协议架构
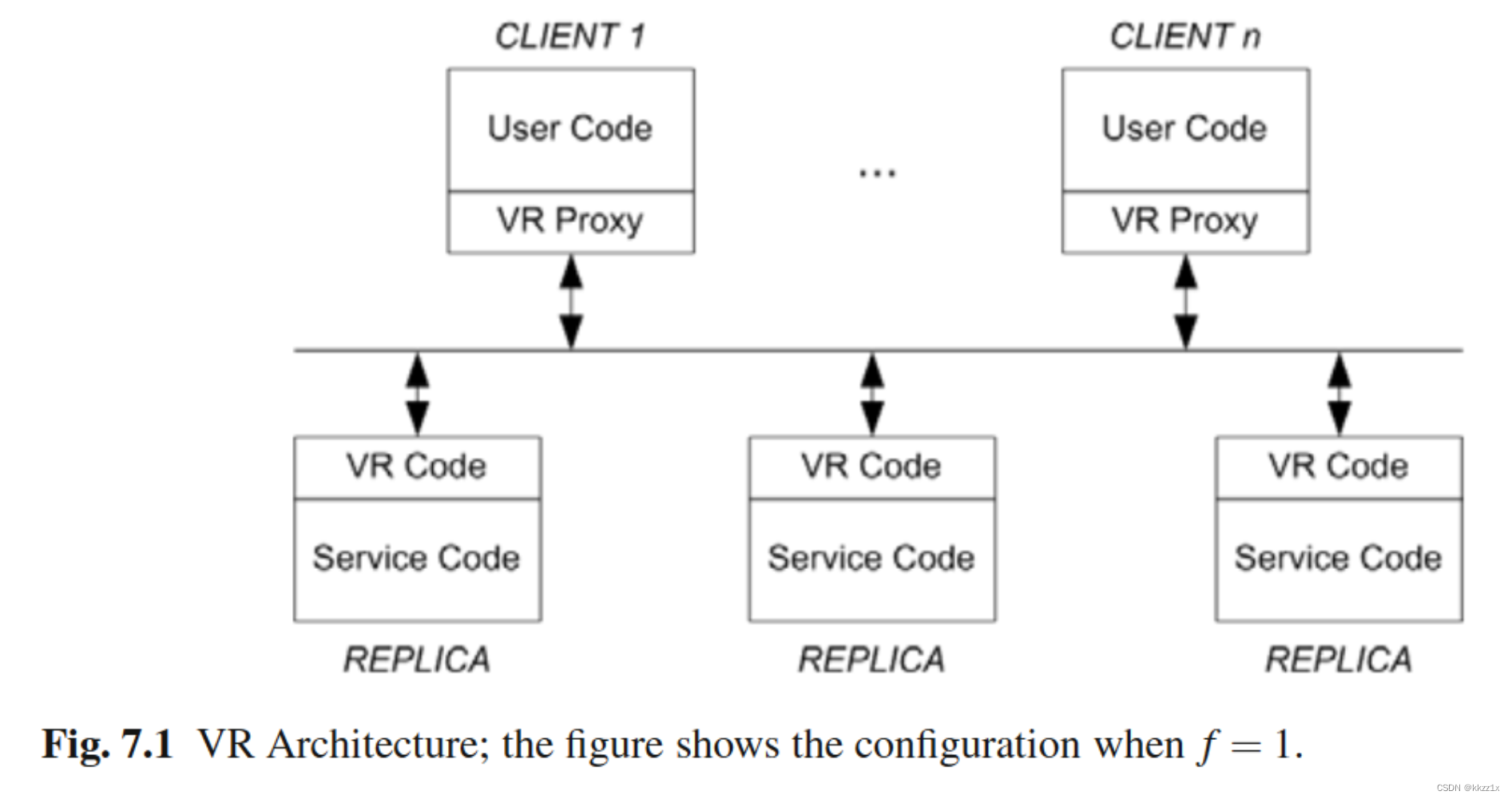
在这里,Replica也就是节点; VR Code负责处理VR协议,Service Code负责处理和执行命令 。
三、协议组成
1. normal operation
正常执行流程。
- client发送消息到primary
- primary收到后比较request-number和client-table中的信息,如果req-num < client table中记录的,则丢弃+ 发送response,因为req已经处理过了。否则继续。
- primary 的 op-number 增加,request 增加到log末尾,然后发送prepare消息给其他节点(backups,副本)
- backups按顺序处理prepare。 一个副本需要具备op-number前所有entry才能处理请求。如果缺失entry,说明状态落后,需要state transfer。
处理的时候,同primary,本地的op-number增加,request 增加到本地log中,更新client-table, 返回prepareOK给primary - primary收集了多数prepareOK消息时,就可以认为当前的operation可以commit了,这个operation就可以被顺序执行到,commit-number增加,通知client,更新执行结果到client-table
- 对于已经commit的消息,需要通知backups,这个通知消息并不是单独发,而是包含在下一次prepare消息中(这样节约了一次发送开销)。如果长期没有client请求,也就是长期无需发送prepare消息的话,那就再单独发送一次commit消息给backups
- backups接收到发来的commit消息,再执行operation,更新result到client-table
注: 这里的op-number 类比于是Raft中的log index, commit-number类比于是commit index。 如果一切正常,长时间来看commit-number == op-number
如果step5,primary已经commit,但此时primary宕机了,那如何将commit-number通知到backup呢?那就涉及到part 3-recovery了。而其他节点也会发现primary不在了,那么此时就要做view change
2. view change
在VR协议中的view 可以理解为Raft的term。view change就是切主;view number可以理解为Raft的任期号。
-
发生时间:replica发现自己超时未收到primary的消息,那么递增自己的view-number or 收到了view change的更大的view-number(说明存在其他replica已经开始选主),那么view-number更新为收到的新number
-
一个replica收到f个startViewChange消息时候,就发送消息doViewChange给新的primary
-
新的primary收到f+1条消息,更新自己的view-number,并选择view-number最大的消息log作为new log,如果view-number相同,则选择op-number最大的;设置commit-number为所有消息中的最大值,更新status为normal,发送给其他副本view change结束的消息;其他副本更新相关信息
(对比Raft, Raft只能是主给从发log,而这里可以从节点给新主节点发log) -
new primary开始负责接收client消息
3. recovery
宕机后的节点重新加入集群,需要重新请求所有日志。
区别于state transfer: 节点并没有宕机,但是日志落后,此时需要state transfer。
- 发送recovery给所有replica,携带唯一序号
- 处于normal状态的replica响应, 只有primary给请求者回复log内容
- 收到f+1个响应(包括primary),则更新本地log,更新完后切换状态到normal
四、优化
-
effective recovery
就是需要节点每隔一段时间持久化一下当前state,在recovery的时候直接从磁盘中拿出之前该节点的state就行,而不用传输全部的log (和Raft的 snapshot还是有点区别的,snapshot是指传输的时候把log打包,但目的是一样的,就是让恢复的时候无需全量传输log) -
view change
doViewChange消息中携带1-2个最新的log,而不是全部log。log用于更新新primary状态,由于新primary一般比较新,所以带少量即可。 -
witness
2f+1节点集群中只有f+1个节点需要active(active状态的节点需要存储状态和执行operation),其他f个为witness(不需要存state和执行op)。 active replica出现故障,witness才参与进来。大多数正常时间,witness节点把资源拿去干别的。 -
batching
客户端发来的请求可以收集一下,一起跑。节约通信开销,但是一次处理的时间变长(延迟增加) -
fast reads
仅primary处理读请求,而不需要得到其他节点的response (prepareOK)
需要额外实现lease机制,保证读请求的primary在有效期内,防止网络分区带来的脑裂问题。