目录
- 一、引言
- 1.1 计算机视觉的定义
- 1.1.1 核心技术
- 1.1.2 应用场景
- 1.2 历史背景及发展
- 1.2.1 1960s-1980s: 初期阶段
- 1.2.2 1990s-2000s: 机器学习时代
- 1.2.3 2010s-现在: 深度学习的革命
- 1.3 应用领域概览
- 1.3.1 工业自动化
- 1.3.2 医疗图像分析
- 1.3.3 自动驾驶
- 1.3.4 虚拟现实与增强现实
- 二、计算机视觉五大核心任务
- 2.1 图像分类与识别
- 2.1.1 图像分类与识别的基本概念
- 2.1.2 早期方法与技术演进
- 2.1.3 深度学习的引入与革新
- 卷积神经网络在图像分类中的应用
- 总结
- 2.2 物体检测与分割
- 2.2.1 物体检测
- 早期方法
- 深度学习方法
- 2.2.2 物体分割
- 语义分割
- 实例分割
- 总结
- 2.3 人体分析
- 2.3.1 人脸识别
- 2.3.2 人体姿态估计
- 2.3.3 动作识别
- 2.3.4 人体分割
- 2.4 三维计算机视觉
- 2.4.1 三维重建
- 立体视觉
- 多视图几何
- 点云生成和融合
- 2.4.2 3D物体检测和识别
- 基于2D图像的方法
- 基于点云的方法
- 2.4.3 三维语义分割
- 基于体素的方法
- 基于点云的方法
- 2.4.4 三维姿态估计
- 单视图方法
- 多视图方法
- 总结
- 2.5 视频理解与分析
- 2.5.1 视频分类
- 2.5.2 动作识别
- 2.5.3 视频物体检测与分割
- 2.5.4 视频摘要与高亮检测
- 2.5.5 视频生成和编辑
- 总结
- 三、无监督学习与自监督学习在计算机视觉中的应用
- 3.1 无监督学习
- 聚类
- 降维与表示学习
- 3.2 自监督学习
- 对比学习
- 预训练任务设计
- 3.3 跨模态学习
- 4. 总结
本篇文章深入探讨了计算视觉的定义和主要任务。内容涵盖了图像分类与识别、物体检测与分割、人体分析、三维计算机视觉、视频理解与分析等技术,最后展示了无监督学习与自监督学习在计算机视觉中的应用。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
一、引言
计算机视觉(Computer Vision)是一门将人类的视觉能力赋予机器的学科。它涵盖了图像识别、图像处理、模式识别等多个方向,并已成为人工智能研究的重要组成部分。本文将详细介绍计算机视觉的定义、历史背景及发展、和当前的应用领域概览。

1.1 计算机视觉的定义
计算机视觉不仅是一门研究如何使机器理解和解释视觉世界的科学,更是一种追求让机器拥有与人类相近视觉处理能力的技术。它通过分析数字图像和视频,使得机器能够识别、追踪和理解现实世界中的对象和场景。此外,计算机视觉还包括图像恢复、三维重构等深入的研究方向。
1.1.1 核心技术
核心技术包括但不限于特征提取、目标检测、图像分割、3D重建等,通过多个技术的结合实现更为复杂的视觉任务。
1.1.2 应用场景
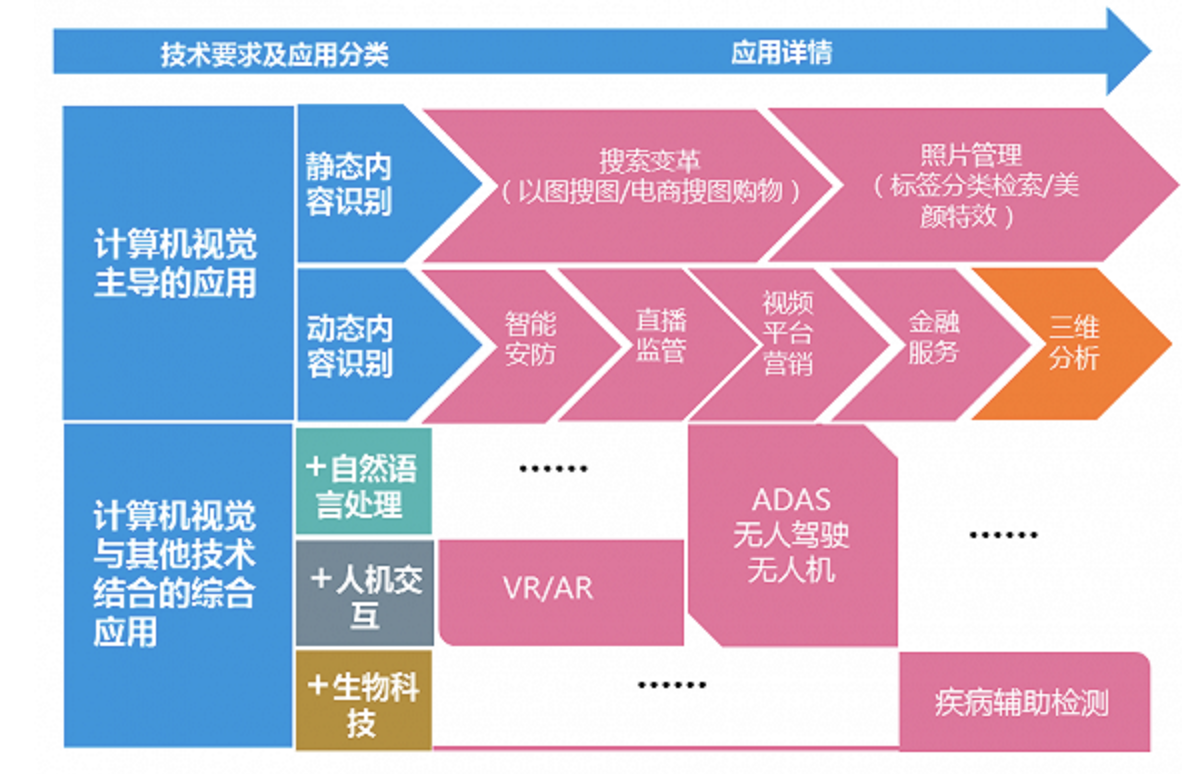
计算机视觉被广泛应用于自动驾驶、医疗诊断、智能监控等众多领域,推动了相关产业的快速发展。
1.2 历史背景及发展
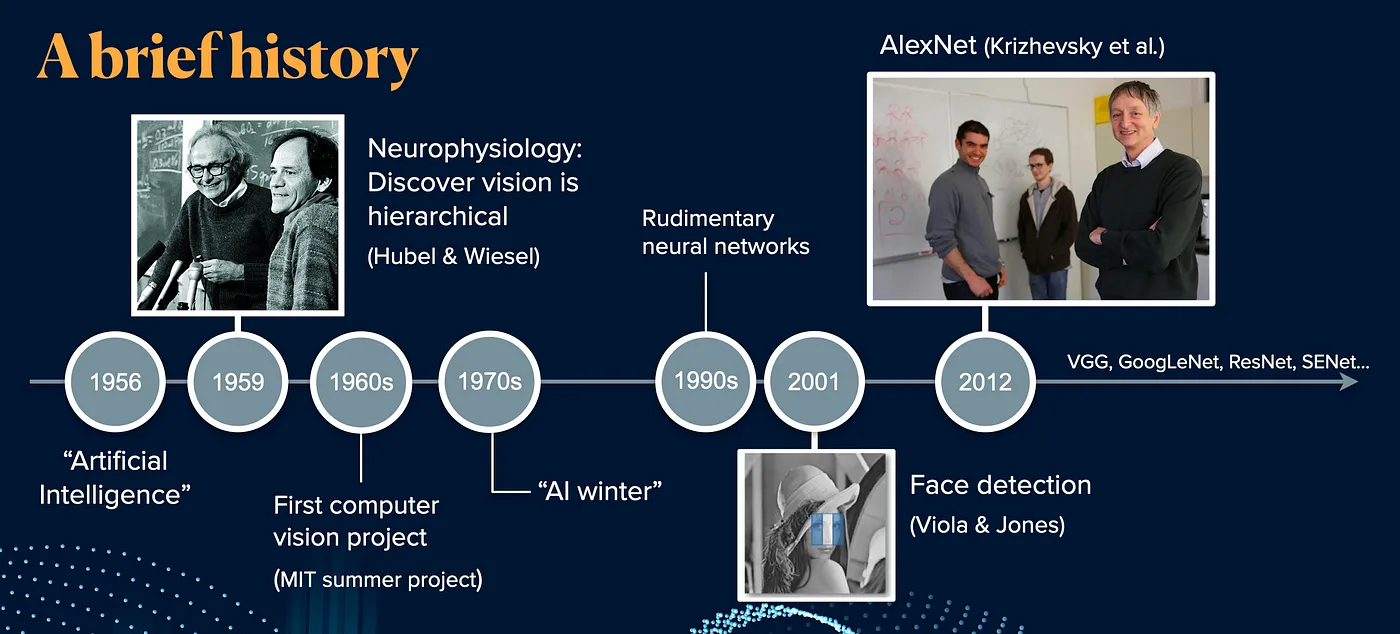
计算机视觉的发展历程丰富多彩,从上世纪60年代初步探索到如今的深度学习技术革命,可以分为以下几个主要阶段:
1.2.1 1960s-1980s: 初期阶段
- 图像处理: 主要关注简单的图像处理和特征工程,例如边缘检测、纹理识别等。
- 模式识别: 诸如手写数字识别等初级任务的实现。
1.2.2 1990s-2000s: 机器学习时代
- 特征学习: 通过机器学习方法使得特征学习和对象识别变得更加复杂和强大。
- 支持向量机和随机森林的应用: 提供了新的解决方案。
1.2.3 2010s-现在: 深度学习的革命
- 卷积神经网络: CNN的广泛应用为计算机视觉带来了突破性进展。
- 迁移学习和强化学习的结合: 在计算机视觉任务上获得了重大进展。
1.3 应用领域概览
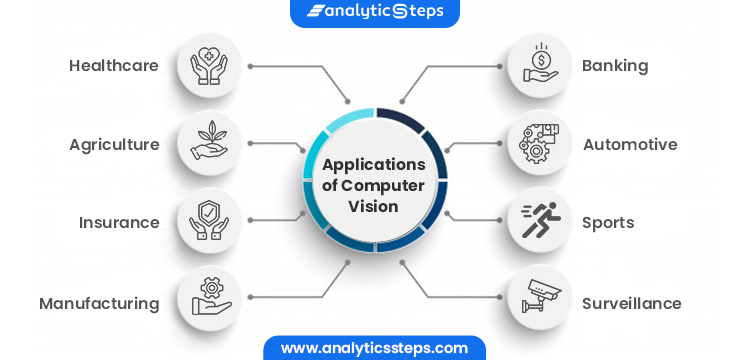
计算机视觉已经渗透到了许多行业,其应用不仅仅局限于科技领域,更广泛地影响了我们的日常生活。
1.3.1 工业自动化
利用图像识别技术,自动化地进行产品质量检测、分类,提高了生产效率和精确度。
1.3.2 医疗图像分析
计算机视觉结合深度学习进行疾病诊断和预测,改变了传统医疗方式。
1.3.3 自动驾驶
计算机视觉在自动驾驶中起到关键作用,实时分析周围环境,为车辆路径规划和决策提供准确信息。
1.3.4 虚拟现实与增强现实
通过计算机视觉技术创建沉浸式的虚拟环境,为娱乐和教育等领域提供了全新的体验方式。
二、计算机视觉五大核心任务
当然,技术深度和内容的丰富性是非常重要的。以下是针对所提供内容的改进版本:
2.1 图像分类与识别
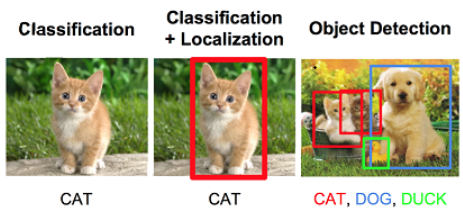
图像分类与识别是计算机视觉的核心任务之一,涉及将输入的图像或视频帧分配到一个或多个预定义的类别中。本章节将深入探讨这一任务的关键概念、技术演进、最新的研究成果,以及未来可能的发展方向。
2.1.1 图像分类与识别的基本概念
图像分类是将图像分配到某个特定类别的任务,而图像识别则进一步将类别关联到具体的实体或对象。例如,分类任务可能会识别图像中是否存在猫,而识别任务会区分不同种类的猫,从宠物猫到野生豹子的区分。
2.1.2 早期方法与技术演进
早期的图像分类与识别方法重依赖于手工设计的特征和统计机器学习算法。这些方法的发展历程包括:
- 特征提取: 采用如 SIFT、HOG等特征来捕捉图像的局部信息。
- 分类器的应用: 利用SVM、决策树等分类器进行图像的分级。
然而,这些方法在许多实际应用中的性能受限,因为特征工程的复杂性和泛化能力的限制。
2.1.3 深度学习的引入与革新
随着深度学习的出现,图像分类与识别取得了显著的进展。尤其是卷积神经网络(CNN)的引入,为领域内的研究和实际应用带来了革命性的改变。
卷积神经网络在图像分类中的应用
卷积神经网络通过层叠的卷积层、池化层和全连接层来自动学习图像特征,消除了手工设计特征的需要。下面是一个简单的CNN结构示例:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense# 定义模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(1, activation='sigmoid'))# 输出模型结构
model.summary()
总结
图像分类与识别作为计算机视觉的基石,其技术演进完美地反映了整个领域的快速进展。从手工设计的特征到复杂的深度学习模型,该领域不仅展示了计算机视觉的强大能力,还为未来的创新和发展奠定了坚实的基础。随着更先进的算法和硬件的发展,我们期待未来图像分类与识别能够在更多场景中发挥作用,满足人们日益增长的需求。
2.2 物体检测与分割
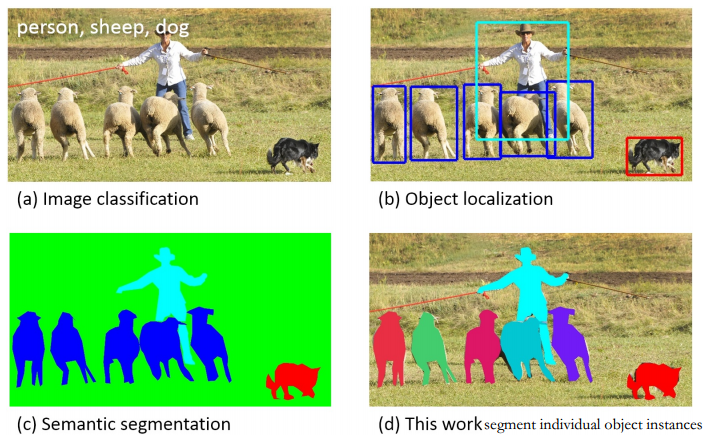
物体检测与分割在计算机视觉中具有核心地位,它不仅是关于识别图像中的物体,更关乎精确定位和分割这些物体。该领域涉及的挑战从基础的图像处理到复杂的深度学习方法都有。本章节将深入探讨物体检测与分割的关键概念、主流方法和最新进展。
2.2.1 物体检测
物体检测不仅要求识别图像中的对象,还要精确确定其位置和类别。它的应用包括人脸识别、交通分析、产品质检等。
早期方法
早期的物体检测方法主要依赖于手工特征和传统机器学习方法。
- 滑动窗口: 结合手工特征如HOG,通过滑动窗口的方式在多个尺度和位置寻找对象。
- SVM分类器: 通常与滑动窗口相结合,使用SVM分类器进行物体分类。
深度学习方法
深度学习技术的出现极大地推动了物体检测领域的进展。
- R-CNN系列: 从R-CNN到Faster R-CNN,逐渐演进,实现了对物体的精确检测,特别是在使用区域提议网络(RPN)和ROI池化方面的创新。
- YOLO: YOLO(You Only Look Once)以其一次前向传播的实时检测能力而受到关注。
- SSD: SSD(Single Shot Multibox Detector)通过多尺度特征图来检测不同大小的对象,也具备实时检测的优势。
# 使用YOLO进行物体检测的代码示例
from yolov3.utils import detect_imageimage_path = "path/to/image.jpg"
output_path = "path/to/output.jpg"
detect_image(image_path, output_path)
# 输出图片包括检测到的物体的边界框
2.2.2 物体分割
物体分割任务则更为细致,涉及到像素级别的对象分析。
语义分割
语义分割旨在将图像中每个像素分配给一个特定的类别,不区分同一类别的不同实例。
- FCN: FCN(全卷积网络)是语义分割的开创性工作之一。
- U-Net: U-Net通过对称的编码器和解码器结构,实现了精确的医学图像分割。
实例分割
实例分割则进一步区分同一类别的不同对象实例。
- Mask R-CNN: Mask R-CNN在Faster R-CNN基础上增加了对象掩码生成分支,实现了实例分割。
总结
物体检测与分割结合了图像处理、机器学习和深度学习的多个方面,是计算机视觉中的复杂和多面任务。其在自动驾驶、医疗诊断、智能监控等领域有着广泛的应用。未来的研究将更多聚焦于多模态信息融合、少样本学习、实时高精度检测等前沿挑战,持续推动该领域的创新和发展。
2.3 人体分析

人体分析是计算机视觉中一个重要且活跃的研究领域,涵盖了对人体的识别、检测、分割、姿态估计和动作识别等多方面任务。人体分析的研究和应用在许多领域都有深远的影响,包括安全监控、医疗健康、娱乐、虚拟现实等。
2.3.1 人脸识别
人脸识别不仅是定位图像中人脸的技术,还涉及了人脸的验证和识别。
- 人脸检测: 通过使用如Haar级联等算法,精确地定位图像中的人脸位置。
- 人脸验证和识别: 应用深度学习方法,例如FaceNet,以判断两张人脸是否属于同一个人,或从大型数据库中找到匹配的人脸。
2.3.2 人体姿态估计
人体姿态估计涉及了识别人体的关键关节位置和整体姿态,它在运动分析、健康监测等领域有着重要应用。
- 单人姿态估计: 通过识别单个人体的关键关节,例如使用OpenPose等方法。
- 多人姿态估计: 针对复杂场景,可同时识别多个人体的关键关节。
# 使用OpenPose估计人体姿态的代码示例
import cv2
body_model = cv2.dnn.readNetFromTensorflow("path/to/model")
image = cv2.imread("path/to/image.jpg")
body_model.setInput(cv2.dnn.blobFromImage(image))
points = body_model.forward()
# points中包括了人体的关键关节信息
2.3.3 动作识别
动作识别从图像或视频中识别特定的人体动作或行为。
- 基于序列的方法: 使用RNN或LSTM分析一系列图像,以捕捉动作的时序特点。
- 基于三维卷积的方法: 利用3D CNN分析视频中的时空特征,获取更丰富的动作信息。
2.3.4 人体分割
人体分割是从背景和其他对象中分离人体的技术。
- 语义分割: 将整个人体与背景分开,无需区分个体。
- 实例分割: 进一步区分不同的人体实例,适用于
2.4 三维计算机视觉
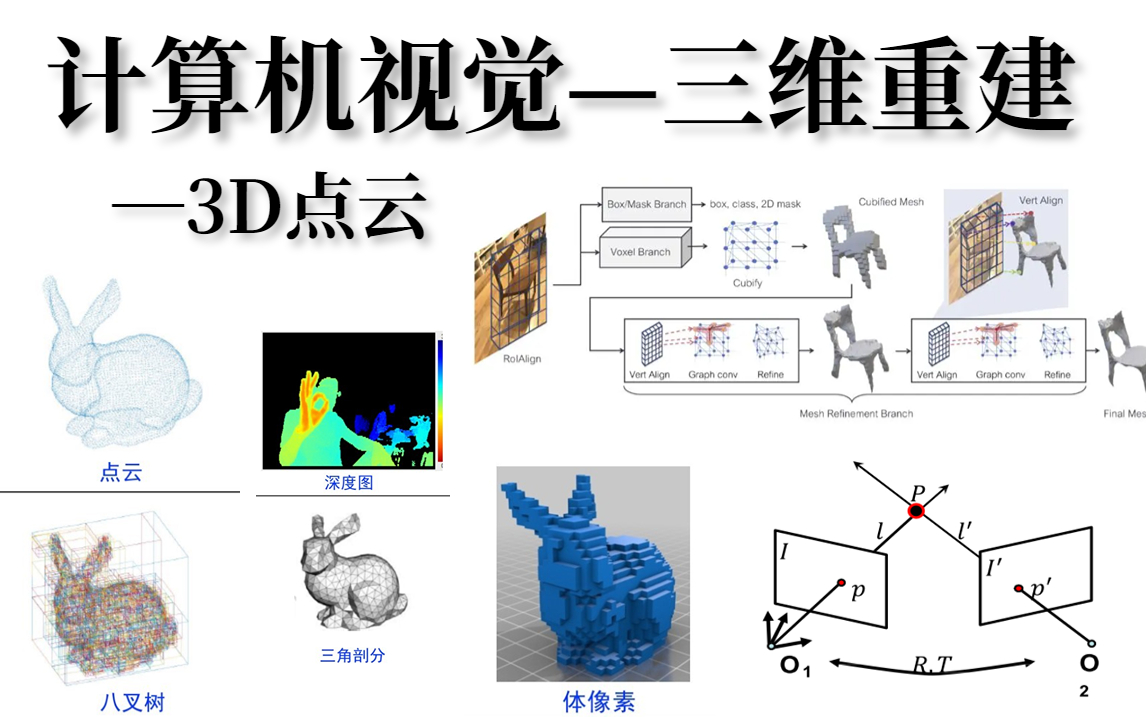
三维计算机视觉不仅是一个令人兴奋的研究领域,也为许多实际应用提供了基础,包括虚拟现实(VR)、增强现实(AR)、3D建模、机器人导航等。本章节将深入探讨三维计算机视觉的主要概念和方法。
2.4.1 三维重建
三维重建是从一组二维图像中重建出三维场景的过程。这个过程涉及多个复杂的技术和算法。
立体视觉
立体视觉是通过比较来自两个或多个相机的图像,以估计场景的深度信息。这为进一步的3D重建提供了基础。
多视图几何
多视图几何是一种利用多个视图的几何关系来重建三维结构的方法。通过对极几何和三角测量的应用,可以实现精确的三维重建。
点云生成和融合
点云生成和融合方法如SLAM(同时定位和映射)技术,可以从多视角图像生成精确的三维结构。
2.4.2 3D物体检测和识别
3D物体检测和识别不仅涉及识别物体的类别,还确定其在三维空间中的方位和姿态。
基于2D图像的方法
这些方法利用2D图像和深度信息进行3D推理,例如使用3D CNN来识别和定位3D对象。
基于点云的方法
一些先进的方法,如PointNet,直接处理三维点云数据,可以在更复杂的场景中实现精确检测和识别。
2.4.3 三维语义分割
三维语义分割涉及将3D场景分割成有意义的部分,并为每个部分分配语义标签。
基于体素的方法
如3D U-Net,这些方法将3D空间划分为体素并进行分割,提供了强大的三维分割能力。
基于点云的方法
基于点云的方法,如PointNet,能够直接处理点云数据,实现精确的三维语义分割。
2.4.4 三维姿态估计
三维姿态估计涉及估计物体在三维空间中的位置和方向。
单视图方法
从单个图像估计3D姿态,虽然挑战较大,但在一些特定应用中足够有效。
多视图方法
结合多个视角的信息进行精确估计,为许多先进的三维视觉任务提供了关键技术。
总结
三维计算机视觉是一门充满挑战和机遇的领域。从基础的三维重建到复杂的3D物体识别和语义分割,这个领域的研究对许多先进技术和应用产生了深远影响。随着硬件和算法的不断进步,三维计算机视觉将继续推动许多前沿技术的发展,如自动驾驶、智能城市建设、虚拟与增强现实等。未来,我们可以期待这一领域将产生更多创新和突破。
2.5 视频理解与分析

视频理解与分析是计算机视觉的一个重要分支,不仅涉及对视频内容的识别和解释,还包括时空结构的推理。相比单一的图像分析,视频分析更能深入挖掘视觉信息的连续性和内在联系,从而开拓了计算机视觉的新领域。
2.5.1 视频分类
视频分类的目的是识别和标记视频的整体内容,它可以进一步细分为不同的任务。
- 短片分类: 主要关注视频中的特定活动或场景,如识别动作、表情等。该任务广泛应用于社交媒体内容分析、广告推荐等。
- 长片分类: 针对整部电影或电视剧进行分析,可能涉及情感、风格、主题等多方面的识别。此项技术可用于推荐系统、内容审查等。
2.5.2 动作识别
动作识别是从视频中捕捉特定动作或行为的过程。
- 基于2D卷积的方法: 通过捕捉时间维度上的连续性,例如使用C3D模型,适用于短时间的动作识别。
- 基于3D卷积的方法: 如I3D模型,更好地捕捉时空信息,用于更复杂的场景。
# 使用I3D模型进行动作识别的代码示例
import tensorflow as tf
i3d_model = tf.keras.applications.Inception3D(include_top=True, weights='imagenet')
video_input = tf.random.normal([1, 64, 224, 224, 3]) # 随机输入
predictions = i3d_model(video_input)
# 输出预测结果
print(predictions)
2.5.3 视频物体检测与分割
视频物体检测与分割集合了物体的检测、跟踪和分割技术。
- 物体检测: 通过时序分析,结合方法如Faster R-CNN与光流,能够在视频序列中精确定位物体。
- 实例分割: 更细致地在视频中对单个实例进行分割,应用场景包括医学影像、智能监控等。
2.5.4 视频摘要与高亮检测
视频摘要与高亮检测的目的是从大量视频数据中提取关键信息。
- 基于关键帧的方法: 选择具有代表性的帧作为摘要,用于快速浏览或索引。
- 基于学习的方法: 如使用强化学习选择精彩片段,应用于自动生成比赛精彩时刻回放等。
2.5.5 视频生成和编辑
视频生成和编辑涉及更高层次的创造和定制。
- 视频风格转换: 通过神经风格迁移技术,可实现不同风格的转换。
- 内容生成: 例如使用GANs技术,能够合成全新的视频内容,为艺术创作、娱乐产业提供了新的可能性。
总结
视频理解与分析作为一个多维度、多层次的领域,不仅推动了媒体和娱乐技术的进步,还在监控、医疗、教育等多个方向展现出广泛的实用价值。它的研究涉及图像分析、时空建模、机器学习等多个方面的交叉与融合。随着技术的不断发展和深入,未来的视频理解预计将实现更精确、更智能、更自动化的水平,为人们的生活和工作提供更广阔的便利和可能。
三、无监督学习与自监督学习在计算机视觉中的应用
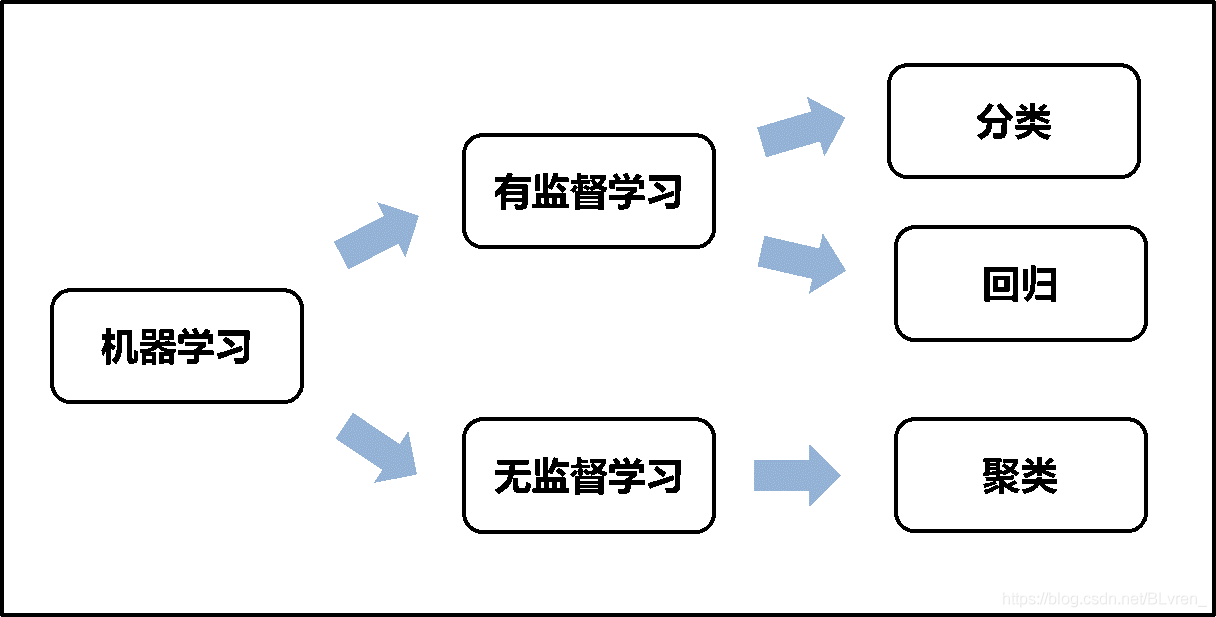
无监督学习和自监督学习在计算机视觉中的应用是目前的热门研究方向。与有监督学习相比,这些方法不需要昂贵且耗时的标注过程,具有巨大的潜力。下面将深入探讨这两种学习方法在视觉中的主要应用。
3.1 无监督学习
聚类
无监督学习中的聚类任务关注如何将相似的数据分组。
- 图像聚类: 如使用K-means算法,可以通过颜色、纹理等特性对图像进行分组,用于图像检索和分类。
- 深度聚类: 如DeepCluster,通过深度学习提取的特征进行聚类,能够捕捉更复杂的模式。
降维与表示学习
降维和表示学习可以揭示数据的内在结构。
- 主成分分析(PCA): PCA是一种常用的图像降维方法,有助于去除噪声,更好地理解图像的主要成分。
- 自编码器(AE): 自编码器能够学习数据的压缩表示,常用于图像去噪、压缩等任务。
3.2 自监督学习
自监督学习通过数据的一部分来预测其余部分,在无监督的环境中进行训练,涵盖了多种训练任务。
对比学习
对比学习通过比较正例和负例来学习数据的表示。
- SimCLR: SimCLR通过比较正例和负例学习特征表示。
# SimCLR的代码示例
from models import SimCLR
model = SimCLR(base_encoder)
loss = model.contrastive_loss(features) # 对比损失
- MoCo: MoCo使用队列和动量编码器进行更稳健的对比学习,有助于训练更准确的模型。
预训练任务设计
- 预测颜色: 通过灰度图像预测原始颜色,有助于理解图像的颜色构成。
- 自回归预测: 如使用PixelCNN预测图像下一个像素的值,增强对图像生成的掌控力。
3.3 跨模态学习
- 图像与文本匹配: 如使用CLIP同时学习视觉和文本表示,推动了多模态的研究进展。
- 音频与图像匹配: 无监督的方法在音频和图像之间建立关联,开拓了多媒体分析的新领域。
4. 总结
无监督学习与自监督学习打开了一条不依赖昂贵标注的新路径。通过丰富的方法,如聚类、对比学习、自回归预测等,这一领域在计算机视觉中的应用日益广泛。最新的研究展示了自监督学习在视觉表征学习方面与有监督方法越来越接近甚至超越的能力,暗示了未来可能的研究方向和广泛的应用场景。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人