第一阶段:百花齐放(18-19中)
有InstDisc(Instance Discrimination)、CPC、CMC代表工作。在这个阶段方法模型都还没有统一,目标函数也没有统一,代理任务也没有统一,所以说是一个百花齐放的时代
1 判别式代理任务---个体判别任务
1.1 Inst Dict---一个编码器+一个memory bank
《Unsupervised Feature Learning via Non-Parametric Instance Discrimination》
通过无参数的实例判别任务进行无监督特征学习

研究动机:通过观察分类结果,发现相似的类别分数高,不相似的类别分数低,认为原因不是因为标签不同而是因为相似类别的个体长得就是很相似。通过这一现象,提出了个体判别这个代理任务任务目标是,把每张图片都看做一个类别,目标是能够学习一种特征从而把每张图片都区分开。

方法:通过对比学习训练网络,对于个体判别任务,正样本即这个图片本身或经过数据增量,负样本是数据集中其他图片(即memory bank中随机抽取数据)。把所有负样本特征存放在 memory bank 中,每次minibatch的数据特征更换上一次memory bank中的特征。还有一些其他巧妙的设计,如proximal Regularization:为模型的训练增加了一个约束,从而可以使memory bank 中的特征进行动量式的更新;超参数的设定也被MoCo所严格执行。

主要贡献:提出了个体判别任务(Instance Discrimination)代理任务;使用这个代理任务和NCE Loss做对比学习;提出了memory bank这种类似于字典的数据结构存储大量负样本;并提出了如何对特征进行动量的更新。
1.2 Inva Spread---一个编码器
《Unsupervised Embedding Learning via Invariant and Spreading Instance Feature》
通过不变和扩展实例特征进行无监督嵌入式学习
Invariant和spreading,即:相似物体的特征应该保持不变性,不相似物体的特征应该尽可能分散
可以被理解成是 SimCLR 的前身。没有使用大量的数据结构去存储大量负样本,它的正负样本来源于同一个minibatch,(可使得)只使用一个编码器进行端到端的学习。

代理任务也是选取了个体判别这个任务。正负样本选取:图片x1的正样本是x1经过数据增强后的图片,负样本是其他剩下的所有图片,包括原始的图片以及经过数据增强后的图片。

主要贡献:不需要使用大量的数据结构去存储大量负样本;正负样本来源于一个batch:使用一个编码器进行端到端的学习。
2 生成式代理任务---预测、多模态
2.1 CPC---预测未来 一个编码器+一个自回归模型
《Representation Learning with Contrastive Predictive Coding》
利用对比预测编码进行表征学习----预测型代理任务
正负样本的定义:正样本是未来的输入通过编码器后得到的未来时刻的特征输出,这相当于做的预测是 query,而真正未来时刻的输出是由输入决定,也就是说它们相对于预测来说是正样本;负样本的定义很广泛,如,可以任意选取输入通过编码器得到输出,则对于当前的预测时不相似的。

2.2 CMC--多模态 两个或多个编码器
《Contrastive Multiview Coding》--- 对比多视图编码
摘要:核心观点是一个物体的很多个视角都可以被当做正样本。因为我们人观察这个世界是通过很多个传感器的,比如我们的眼睛和我们的耳朵,这些都充当着不同的传感器来给我们大脑提供不同的信号,每一个视角都有可能是带有噪声且不完整的,但是最重要的那些信息其实是在所有的这些视角中间共享的,如基础的物理定律、几何形状、语音信息这些都是共享的。比如一只狗,他可以被我们眼睛看见,也可以被耳朵听到,也可以被感受到。因为作者提出我们想学一个很强大的特征,具有视角的不变性,即不管你给我看哪个视角,到底是看到了一只狗,还是听到了狗叫声,我都能判断出这是一只狗。所以CMC这篇文章就是想增大这个互信息,如果能学到一种特征,可以抓到所有视角下的这个关键因素,那这个特征就很好了。
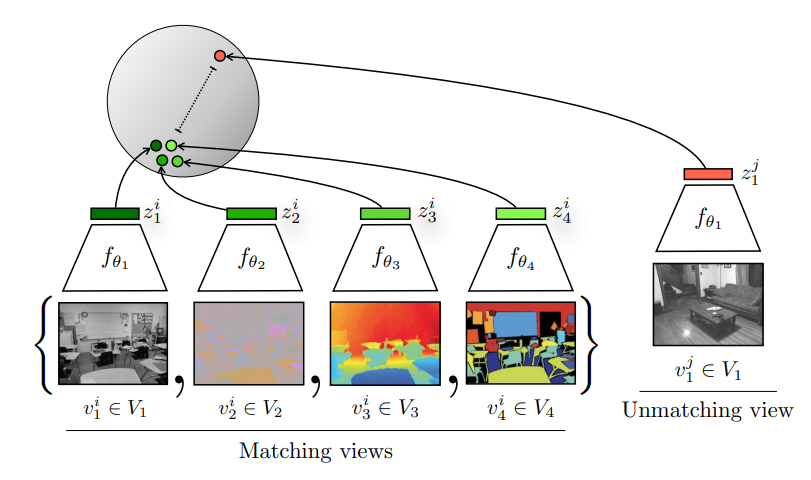
正负样本定义:一个物体的多个视角都可以当做其正样本,包括四个视角:原始图像、图像对应的深度信息(每个物体离观察者到底有多远)、surface normal、这个物体的分割图像。随机挑一个其他图片,该图片属于一个不配对的视角作为负样本。需使用两个或多个编码器。
总结
从第一阶段可以看到:它们使用的代理任务是不一样的,有个体判别,有预测未来,还有多视角多模态;它们使用的目标函数也不尽相同,有 NCE,有infoNCE,还有NCE的其它变体;它们使用的模型也都不一样,比如说invariant spread用了一个编码器;Inst Disc用一个编码器和memory bank;cpc有一个编码器,还有一个自回归模型;cmc可能有两个甚至多个编码器;它们做的任务从图像到视频到音频到文字到强化学习,非常的丰富多彩。