STL容器适配器
什么是适配器,C++ STL容器适配器详解
在详解什么是容器适配器之前,初学者首先要理解适配器的含义。
其实,容器适配器中的“适配器”,和生活中常见的电源适配器中“适配器”的含义非常接近。我们知道,无论是电脑、手机还是其它电器,充电时都无法直接使用 220V 的交流电,为了方便用户使用,各个电器厂商都会提供一个适用于自己产品的电源线,它可以将 220V 的交流电转换成适合电器使用的低压直流电。
从用户的角度看,电源线扮演的角色就是将原本不适用的交流电变得适用,因此其又被称为电源适配器。
再举一个例子,假设一个代码模块 A,它的构成如下所示:
class A{
public:void f1(){}void f2(){}void f3(){}void f4(){}
};
现在我们需要设计一个模板 B,但发现,其实只需要组合一下模块 A 中的 f1()、f2()、f3(),就可以实现模板 B 需要的功能。其中 f1() 单独使用即可,而 f2() 和 f3() 需要组合起来使用,如下所示:
class B{
private:A * a;
public:void g1(){a->f1();}void g2(){a->f2();a->f3();}
};
可以看到,就如同是电源适配器将不适用的交流电变得适用一样,模板 B 将不适合直接拿来用的模板 A 变得适用了,因此我们可以将模板 B 称为 B 适配器。
容器适配器也是同样的道理,简单的理解容器适配器,其就是将不适用的序列式容器(包括 vector、deque 和 list)变得适用。容器适配器的底层实现和模板 A、B 的关系是完全相同的,即通过封装某个序列式容器,并重新组合该容器中包含的成员函数,使其满足某些特定场景的需要。
容器适配器本质上还是容器,只不过此容器模板类的实现,利用了大量其它基础容器模板类中已经写好的成员函数。当然,如果必要的话,容器适配器中也可以自创新的成员函数。
需要注意的是,STL 中的容器适配器,其内部使用的基础容器并不是固定的,用户可以在满足特定条件的多个基础容器中自由选择。
STL容器适配器的种类
STL 提供了 3 种容器适配器,分别为 stack 栈适配器、queue 队列适配器以及 priority_queue 优先权队列适配器。其中,各适配器所使用的默认基础容器以及可供用户选择的基础容器,如表 1 所示。
表 1 STL 容器适配器及其基础容器
| 容器适配器 | 基础容器筛选条件 | 默认使用的基础容器 |
|---|---|---|
| stack | 基础容器需包含以下成员函数:empty()size()back()push_back()pop_back()满足条件的基础容器有 vector、deque、list。 | deque |
| queue | 基础容器需包含以下成员函数:empty()size()front()back()push_back()pop_front()满足条件的基础容器有 deque、list。 | deque |
| priority_queue | 基础容器需包含以下成员函数:empty()size()front()push_back()pop_back()满足条件的基础容器有vector、deque。 | vector |
不同场景下,由于不同的序列式容器其底层采用的数据结构不同,因此容器适配器的执行效率也不尽相同。但通常情况下,使用默认的基础容器即可。当然,我们也可以手动修改,具体的修改容器适配器基础容器的方法,后续讲解具体的容器适配器会详细介绍。
C++ stack(STL stack)容器适配器用法详解
stack 栈适配器是一种单端开口的容器(如图 1 所示),实际上该容器模拟的就是栈存储结构,即无论是向里存数据还是从中取数据,都只能从这一个开口实现操作。
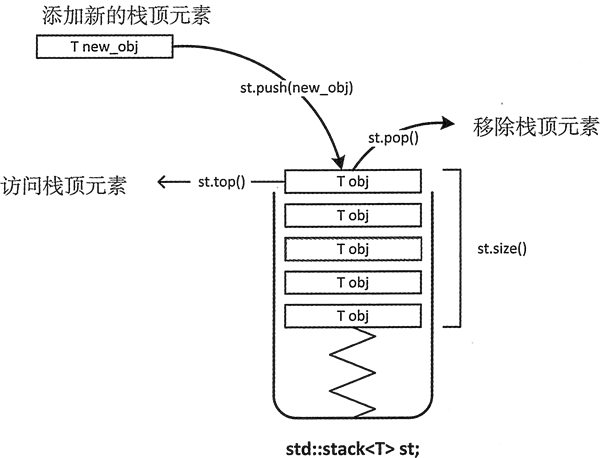
图 1 stack 适配器示意图
如图 1 所示,stack 适配器的开头端通常称为栈顶。由于数据的存和取只能从栈顶处进行操作,因此对于存取数据,stack 适配器有这样的特性,即每次只能访问适配器中位于最顶端的元素,也只有移除 stack 顶部的元素之后,才能访问位于栈中的元素。
栈中存储的元素满足“后进先出(简称LIFO)”的准则,stack 适配器也同样遵循这一准则。
stack容器适配器的创建
由于 stack 适配器以模板类 stack<T,Container=deque>(其中 T 为存储元素的类型,Container 表示底层容器的类型)的形式位于头文件中,并定义在 std 命名空间里。因此,在创建该容器之前,程序中应包含以下 2 行代码:
#include <stack>
using namespace std;
std 命名空间也可以在使用 stack 适配器时额外注明。
创建 stack 适配器,大致分为如下几种方式。
- 创建一个不包含任何元素的 stack 适配器,并采用默认的 deque 基础容器:
std::stack<int> values;
上面这行代码,就成功创建了一个可存储 int 类型元素,底层采用 deque 基础容器的 stack 适配器。
- 上面提到,stack<T,Container=deque> 模板类提供了 2 个参数,通过指定第二个模板类型参数,我们可以使用出 deque 容器外的其它序列式容器,只要该容器支持 empty()、size()、back()、push_back()、pop_back() 这 5 个成员函数即可。
在介绍适配器时提到,序列式容器中同时包含这 5 个成员函数的,有 vector、deque 和 list 这 3 个容器。因此,stack 适配器的基础容器可以是它们 3 个中任何一个。例如,下面展示了如何定义一个使用 list 基础容器的 stack 适配器:
std::stack<std::string, std::list<int>> values;
- 可以用一个基础容器来初始化 stack 适配器,只要该容器的类型和 stack 底层使用的基础容器类型相同即可。例如:
std::list<int> values {1, 2, 3};
std::stack<int,std::list<int>> my_stack (values);
注意,初始化后的 my_stack 适配器中,栈顶元素为 3,而不是 1。另外在第 2 行代码中,stack 第 2 个模板参数必须显式指定为 list(必须为 int 类型,和存储类型保持一致),否则 stack 底层将默认使用 deque 容器,也就无法用 lsit 容器的内容来初始化 stack 适配器。
- 还可以用一个 stack 适配器来初始化另一个 stack 适配器,只要它们存储的元素类型以及底层采用的基础容器类型相同即可。例如:
std::list<int> values{ 1, 2, 3 };
std::stack<int, std::list<int>> my_stack1(values);
std::stack<int, std::list<int>> my_stack=my_stack1;
//std::stack<int, std::list<int>> my_stack(my_stack1);
可以看到,和使用基础容器不同,使用 stack 适配器给另一个 stack 进行初始化时,有 2 种方式,使用哪一种都可以。
注意,第 3、4 种初始化方法中,my_stack 适配器的数据是经过拷贝得来的,也就是说,操作 my_stack 适配器,并不会对 values 容器以及 my_stack1 适配器有任何影响;反过来也是如此。
stack容器适配器支持的成员函数
和其他序列容器相比,stack 是一类存储机制简单、提供成员函数较少的容器。表 1 列出了 stack 容器支持的全部成员函数。
表 1 stack容器适配器支持的成员函数
| 成员函数 | 功能 |
|---|---|
| empty() | 当 stack 栈中没有元素时,该成员函数返回 true;反之,返回 false。 |
| size() | 返回 stack 栈中存储元素的个数。 |
| top() | 返回一个栈顶元素的引用,类型为 T&。如果栈为空,程序会报错。 |
| push(const T& val) | 先复制 val,再将 val 副本压入栈顶。这是通过调用底层容器的 push_back() 函数完成的。 |
| push(T&& obj) | 以移动元素的方式将其压入栈顶。这是通过调用底层容器的有右值引用参数的 push_back() 函数完成的。 |
| pop() | 弹出栈顶元素。 |
| emplace(arg…) | arg… 可以是一个参数,也可以是多个参数,但它们都只用于构造一个对象,并在栈顶直接生成该对象,作为新的栈顶元素。 |
| swap(stack & other_stack) | 将两个 stack 适配器中的元素进行互换,需要注意的是,进行互换的 2 个 stack 适配器中存储的元素类型以及底层采用的基础容器类型,都必须相同。 |
下面这个例子中演示了表 1 中部分成员函数的用法:
#include <iostream>
#include <stack>
#include <list>
using namespace std;
int main()
{//构建 stack 容器适配器list<int> values{ 1, 2, 3 };stack<int, list<int>> my_stack(values);//查看 my_stack 存储元素的个数cout << "size of my_stack: " << my_stack.size() << endl;//将 my_stack 中存储的元素依次弹栈,直到其为空while (!my_stack.empty()){ cout << my_stack.top() << endl;//将栈顶元素弹栈my_stack.pop();}return 0;
}
运行结果为:
size of my_stack: 3
3
2
1
表 1 中其它成员函数的用法也非常简单,这里不再给出具体示例,后续章节用法会做具体介绍。
stack容器适配器实现计算器(含实现代码)
前面章节中,已经对 stack 容器适配器及其用法做了详细的讲解。本节将利用 stack 适配器实现一个简单的计算机程序,此计算机支持基本的加(+)、 减(-)、乘(*)、除(/)、幂(^)运算。
这里,先给大家展示出完整的实现代码,读者可先自行思考该程序的实现流程。当然,后续也会详细的讲解:
#include <iostream>
#include <cmath> // pow()
#include <stack> // stack<T>
#include <algorithm> // remove()
#include <stdexcept> // runtime_error
#include <string> // string
using std::string;
// 返回运算符的优先级,值越大,优先级越高
inline size_t precedence(const char op)
{if (op == '+' || op == '-')return 1;if (op == '*' || op == '/')return 2;if (op == '^')return 3;throw std::runtime_error{ string {"表达中包含无效的运算符"} +op };
}
// 计算
double execute(std::stack<char>& ops, std::stack<double>& operands)
{double result{};double rhs{ operands.top() }; // 得到右操作数operands.pop(); double lhs{ operands.top() }; // 得到做操作数operands.pop(); switch (ops.top()) // 根据两个操作数之间的运算符,执行相应计算{case '+':result = lhs + rhs;break;case '-':result = lhs - rhs;break;case '*':result = lhs * rhs;break;case '/':result = lhs / rhs;break;case '^':result = std::pow(lhs, rhs);break;default:throw std::runtime_error{ string{"invalid operator: "} +ops.top() };}ops.pop(); //计算完成后,该运算符要弹栈operands.push(result);//将新计算出来的结果入栈return result;
}
int main()
{std::stack<double> operands; //存储表达式中的运算符std::stack<char> operators; //存储表达式中的数值string exp; //接受用户输入的表达式文本try{while (true){std::cout << "输入表达式(按Enter结束):" << std::endl;std::getline(std::cin, exp, '\n');if (exp.empty()) break;//移除用户输入表达式中包含的无用的空格exp.erase(std::remove(std::begin(exp), std::end(exp), ' '), std::end(exp));size_t index{};//每个表达式必须以数字开头,index表示该数字的位数operands.push(std::stod(exp, &index)); // 将表达式中第一个数字进栈std::cout << index << std::endl;while (true){operators.push(exp[index++]); // 将运算符进栈size_t i{};operands.push(std::stod(exp.substr(index), &i)); //将运算符后的数字也进栈,并将数字的位数赋值给 i。index += i; //更新 indexif (index == exp.length()) {while (!operators.empty()) //如果 operators不为空,表示还没有计算完execute(operators, operands);break;}//如果表达式还未遍历完,但子表达式中的运算符优先级比其后面的运算符优先级大,就先计算当前的子表达式的值while (!operators.empty() && precedence(exp[index]) <= precedence(operators.top()))execute(operators, operands);}std::cout << "result = " << operands.top() << std::endl;}}catch (const std::exception& e){std::cerr << e.what() << std::endl;}std::cout << "计算结束" << std::endl;return 0;
}
下面是一些示例输出:
输入表达式(按Enter结束):
5*2-3
result = 7
输入表达式(按Enter结束):
4+4*2
result = 12
输入表达式(按Enter结束):↙ <--键入Enter计算结束
计算器程序的实现流程
了解一个程序的功能,通常是从 main() 函数开始。因此,下面从 main() 函数开始,给大家讲解程序的整个实现过程。
首先,我们创建 2 个 stack 适配器,operands 负责将表达式中的运算符逐个压栈,operators 负责将表达式的数值逐个压栈,同时还需要一个 string 类型的 exp,用于接收用户输入的表达式。
正如上面代码中所有看到的,所有的实现代码都包含在一个由 try 代码块包裹着的 while 循环中,这样既可以实现用户可以多次输入表达式的功能(当输入的表达式为一个空字符串时,循环结束),还可以捕获程序运行过程中抛出的任何异常(在 catch 代码块中,调用异常对象的成员函数 what() 会将错误信息输出到标准错误流中)。
当用户输入完要计算的表达式之后,由于整个表达式是以字符串的形式接收的,考虑到字符串中可能掺杂空格,影响后续对字符串的处理,因此又必须借助 remove() 函数来移除输入表达式中的多余空格(第 70 行代码处)。
得到统一格式的表达式之后,接下来才是实现计算功能的核心,其实现思路为:
-
因为所有的运算符都需要两个操作数,所以有效的输入表达式格式为“操作数 运算符 操作数 运算符 操作数…”,即序列的第一个和最后一个元素肯定都是操作数,每对操作数之间有一个运算符。由于有效表达式总是以操作数开头,所以第一个操作数在分析表达式的嵌套循环之前被提取出来。
-
在循环中,输入字符串的运算符会被压入 operators 栈。在确认没有到达字符串末尾后,再从 exp 提取第二个操作数。这时 stod() 的第一个参数是从 index 开始的 exp 字符串,它是被压入 operators 栈的运算符后的所有字符。此时字符串中第一个运算符的索引为 i,因为 i 是相对于 index 的,所以我们会将 index 加上 i 的值,使它指向操作数后的一个运算符(如果是 exp 中的最后一个操作数,它会指向字符串末尾的下一个位置)。
-
当 index 的值超过 exp 的最后一个字符时,会执行 operators 容器中剩下的运算符。如果没有到达字符串末尾,operators 容器也不为空,我们会比较 operators 栈顶运算符和 exp 中下一个运算符的优先级。如果栈顶运算符的优先级高于下一个运算符,就先执行栈顶的运算符。否则,就不执行栈顶运算符,在下一次循环开始时,将下一个运算符压入 operators 栈。通过这种方式,就可以正确计算出带优先级的表达式的值。
以“5-2*3+1”为例,以上程序的计算过程如下:
- 取 5 和 2 进 operands 栈容器,同时它们之间的 - 运算符进 operators 栈容器,判断后续是否还有表达式,显然还有“*3+1”,这种情况下,取 operators 栈顶运算符 - 和后续的 * 运算符做优先级比较,由于 * 的优先级更高,此时继续将后续的 * 和 3 分别进栈;
此时,operands 中从栈顶依次存储的是 3、2、5,operators 容器中从栈顶依次存储的是 *、-。
- 继续判断后续是否还有表达式,由于还有“+1”,则取 operators 栈顶运算符 * 和 + 运算符做优先级比较,显然前者的优先级更高,此时将 operands 栈顶的 2 个元素(2 和 3)取出并弹栈,同时将 operators 栈顶元素()取出并弹栈,计算它们组成的表达式 23,并将计算结果再入 operands 栈。
计算到这里,operands 中从栈顶依次存储的是 6、5,operators 中从栈顶依次存储的是 -。
- 由于 operator 容器不空,因此继续取新的栈顶运算符“-”和“+”做优先级比较,由于它们的优先级是相同的,因为继续将 operands 栈顶的 2 个元素(5 和 6)取出并弹栈,同时将 operators 栈顶元素(-) 取出并弹栈,计算它们组成的表达式“5-6”,并将计算结果 -1 再入 operands 栈。
此时,operands 中从栈顶依次存储的是 -1,operator 为空。
- 由于此时 operator 栈为空,因此将后续“+1”表达式中的 1 和 + 分别进栈。由于后续再无其他表达式,此时就可以直接取 operands 位于栈顶的 2 个元素(-1 和 1),和 operator 的栈顶运算符(+),执行 -1+1 运算,并将计算结果再入 operands 栈。
通过以上几步,最终“5-2*3+1”的计算结果 0 位于 operands 的栈顶。
C++ STL queue容器适配器详解
和 stack 栈容器适配器不同,queue 容器适配器有 2 个开口,其中一个开口专门用来输入数据,另一个专门用来输出数据,如图 1 所示。
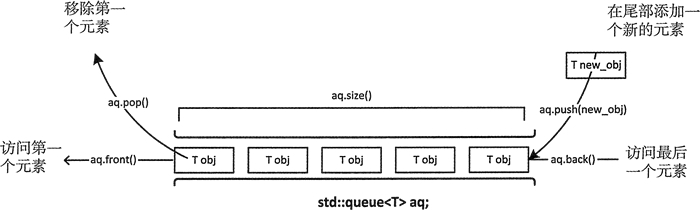
图 1 queue容器适配器
这种存储结构最大的特点是,最先进入 queue 的元素,也可以最先从 queue 中出来,即用此容器适配器存储数据具有“先进先出(简称 “FIFO” )”的特点,因此 queue 又称为队列适配器。
其实,STL queue 容器适配器模拟的就是队列这种存储结构,因此对于任何需要用队列进行处理的序列来说,使用 queue 容器适配器都是好的选择。
queue容器适配器的创建
queue 容器适配器以模板类 queue<T,Container=deque>(其中 T 为存储元素的类型,Container 表示底层容器的类型)的形式位于头文件中,并定义在 std 命名空间里。因此,在创建该容器之前,程序中应包含以下 2 行代码:
#include <queue>
using namespace std;
创建 queue 容器适配器的方式大致可分为以下几种。
- 创建一个空的 queue 容器适配器,其底层使用的基础容器选择默认的 deque 容器:
std::queue<int> values;
通过此行代码,就可以成功创建一个可存储 int 类型元素,底层采用 deque 容器的 queue 容器适配器。
- 当然,也可以手动指定 queue 容器适配器底层采用的基础容器类型。通过学习 《STL容器适配器详解》一节我们知道,queue 容器适配器底层容器可以选择 deque 和 list。
作为 queue 容器适配器的基础容器,其必须提供 front()、back()、push_back()、pop_front()、empty() 和 size() 这几个成员函数,符合条件的序列式容器仅有 deque 和 list。
例如,下面创建了一个使用 list 容器作为基础容器的空 queue 容器适配器:
std::queue<int, std::list<int>> values;
注意,在手动指定基础容器的类型时,其存储的数据类型必须和 queue 容器适配器存储的元素类型保持一致。
- 可以用基础容器来初始化 queue 容器适配器,只要该容器类型和 queue 底层使用的基础容器类型相同即可。例如:
std::deque<int> values{1,2,3};
std::queue<int> my_queue(values);
由于 my_queue 底层采用的是 deque 容器,和 values 类型一致,且存储的也都是 int 类型元素,因此可以用 values 对 my_queue 进行初始化。
- 还可以直接通过 queue 容器适配器来初始化另一个 queue 容器适配器,只要它们存储的元素类型以及底层采用的基础容器类型相同即可。例如:
std::deque<int> values{1,2,3};
std::queue<int> my_queue1(values);
std::queue<int> my_queue(my_queue1);
//或者使用
//std::queue<int> my_queue = my_queue1;
注意,和使用基础容器不同,使用 queue 适配器给另一个 queue 进行初始化时,有 2 种方式,使用哪一种都可以。
值得一提的是,第 3、4 种初始化方法中 my_queue 容器适配器的数据是经过拷贝得来的,也就是说,操作 my_queue 容器适配器中的数据,并不会对 values 容器以及 my_queue1 容器适配器有任何影响;反过来也是如此。
queue容器适配器支持的成员函数
queue 容器适配器和 stack 有一些成员函数相似,但在一些情况下,工作方式有些不同。表 2 罗列了 queue 容器支持的全部成员函数。
表 2 queue容器适配器支持的成员函数
| 成员函数 | 功能 |
|---|---|
| empty() | 如果 queue 中没有元素的话,返回 true。 |
| size() | 返回 queue 中元素的个数。 |
| front() | 返回 queue 中第一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。 |
| back() | 返回 queue 中最后一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。 |
| push(const T& obj) | 在 queue 的尾部添加一个元素的副本。这是通过调用底层容器的成员函数 push_back() 来完成的。 |
| emplace() | 在 queue 的尾部直接添加一个元素。 |
| push(T&& obj) | 以移动的方式在 queue 的尾部添加元素。这是通过调用底层容器的具有右值引用参数的成员函数 push_back() 来完成的。 |
| pop() | 删除 queue 中的第一个元素。 |
| swap(queue &other_queue) | 将两个 queue 容器适配器中的元素进行互换,需要注意的是,进行互换的 2 个 queue 容器适配器中存储的元素类型以及底层采用的基础容器类型,都必须相同。 |
和 stack 一样,queue 也没有迭代器,因此访问元素的唯一方式是遍历容器,通过不断移除访问过的元素,去访问下一个元素。
下面这个例子中演示了表 2 中部分成员函数的用法:
#include <iostream>
#include <queue>
#include <list>
using namespace std;
int main()
{//构建 queue 容器适配器std::deque<int> values{ 1,2,3 };std::queue<int> my_queue(values);//{1,2,3}//查看 my_queue 存储元素的个数cout << "size of my_queue: " << my_queue.size() << endl;//访问 my_queue 中的元素while (!my_queue.empty()){cout << my_queue.front() << endl;//访问过的元素出队列my_queue.pop();}return 0;
}
运行结果为:
size of my_queue: 3
1
2
3
表 2 中其它成员函数的用法也非常简单,这里不再给出具体示例,后续章节用法会做具体介绍。
C++ queue容器适配器模拟超市结账环节
前面章节介绍了 queue 容器适配器的具有用法,本节将利用 queue 模拟超市中结账环节运转的程序。
在超市营业过程中,结账队列的长度是超市运转的关键因素。它会影响超市可容纳的顾客数,因为太长的队伍会使顾客感到气馁,从而放弃排队,这和医院可用病床数会严重影响应急处理设施的运转,是同样的道理。
首先,我们要在头文件 Customer.h 中定义一个类来模拟顾客:
#ifndef CUSTOMER_H
#define CUSTOMER_H
class Customer
{
protected:size_t service_t {}; //顾客结账需要的时间
public:explicit Customer(size_t st = 10) :service_t {st}{}//模拟随着时间的变化,顾客结账所需时间也会减短Customer& time_decrement(){if (service_t > 0)--service_t;return *this;}bool done() const { return service_t == 0; }
};
#endif
这里只有一个成员变量 service_t,用来记录顾客结账需要的时间。每个顾客的结账时间都不同。每过一分钟,会调用一次 time_decrement() 函数,这个函数会减少 service_t 的值,它可以反映顾客结账所花费的时间。当 service_t 的值为 0 时,成员函数 done() 返回 true。
超市的每个结账柜台都有一队排队等待的顾客。Checkout.h 中定义的 Checkout 类如下:
#ifndef CHECKOUT_H
#define CHECKOUT_H
#include <queue> // For queue container
#include "Customer.h"
class Checkout
{
private:std::queue<Customer> customers; //该队列等到结账的顾客数量
public:void add(const Customer& customer) { customers.push(customer); }size_t qlength() const { return customers.size(); }void time_increment(){if (!customers.empty()){ //有顾客正在等待结账,如果顾客结账了,就出队列if (customers.front().time_decrement().done())customers.pop(); }}bool operator<(const Checkout& other) const { return qlength() < other.qlength(); }bool operator>(const Checkout& other) const { return qlength() > other.qlength(); }
};
#endif
可以看到,queue 容器是 Checkout 唯一的成员变量,用来保存等待结账的 Customer 对象。成员函数 add() 可以向队列中添加新顾客。只能处理队列中的第一个元素。 每过一分钟,调用一次 Checkout 对象的成员函数 time_increment(},它会调用第一个 Customer 对象的成员函数 time_decrement() 来减少剩余的等待时间,然后再调用成员函数 done()。如果 done() 返回 true,表明顾客结账完成,因此把他从队列中移除。Checkout 对象的比较运算符可以比较队列的长度。
为了模拟超市结账,我们需要有随机数生成的功能。因此打算使用 头文件中的一个非常简单的工具,但不打算深入解释它。我们会在教程后面的章节深入探讨 random 头文件中的内容。程序使用了一个 uniform_int_distribution() 类型的实例。顾名思义,它定义的整数值在最大值和最小值之间均匀分布。在均匀分布中,所有这个范围内的值都可能相等。可以在 10 和 100 之间定义如下分布:
std::uniform_int_distribution<> d {10, 100};
这里只定义了分布对象 d,它指定了整数值分布的范围。为了获取这个范围内的随机数,我们需要使用一个随机数生成器,然后把它作为参数传给 d 的调用运算符,从而返回一个随机整数。 random 头文件中定义了几种随机数生成器。这里我们使用最简单的一个,可以按如下方式定义:
std::random_device random_number_engine;
为了在 d 分布范围内生成随机数,我们可以这样写:
auto value = d(random_number_engine);
value 的值在 d 分布范围内。
完整模拟器的源文件如下:
#include <iostream> // For standard streams
#include <iomanip> // For stream manipulators
#include <vector> // For vector container
#include <string> // For string class
#include <numeric> // For accumulate()
#include <algorithm> // For min_element & max_element
#include <random> // For random number generation
#include "Customer.h"
#include "Checkout.h"
using std::string;
using distribution = std::uniform_int_distribution<>;
// 以横向柱形图的方式输出每个服务时间出现的次数
void histogram(const std::vector<int>& v, int min)
{string bar (60, '*'); for (size_t i {}; i < v.size(); ++i){std::cout << std::setw(3) << i+min << " " //结账等待时间为 index + min<< std::setw(4) << v[i] << " " //输出出现的次数<< bar.substr(0, v[i]) << (v[i] > static_cast<int>(bar.size()) ? "...": "")<< std::endl;}
}
int main()
{std::random_device random_n;//设置最大和最小的结账时间,以分钟为单位int service_t_min {2}, service_t_max {15};distribution service_t_d {service_t_min, service_t_max};//设置在超市开业时顾客的人数int min_customers {15}, max_customers {20};distribution n_1st_customers_d {min_customers, max_customers};// 设置顾客到达的最大和最小的时间间隔int min_arr_interval {1}, max_arr_interval {5};distribution arrival_interval_d {min_arr_interval, max_arr_interval};size_t n_checkouts {};std::cout << "输入超市中结账柜台的数量:";std::cin >> n_checkouts;if (!n_checkouts){std::cout << "结账柜台的数量必须大于 0,这里将默认设置为 1" << std::endl;n_checkouts = 1;}std::vector<Checkout> checkouts {n_checkouts};std::vector<int> service_times(service_t_max-service_t_min+1);//等待超市营业的顾客人数int count {n_1st_customers_d(random_n)};std::cout << "等待超市营业的顾客人数:" << count << std::endl;int added {};int service_t {};while (added++ < count){service_t = service_t_d(random_n);std::min_element(std::begin(checkouts), std::end(checkouts))->add(Customer(service_t));++service_times[service_t - service_t_min];}size_t time {};const size_t total_time {600}; // 设置超市持续营业的时间size_t longest_q {}; // 等待结账最长队列的长度// 新顾客到达的时间int new_cust_interval {arrival_interval_d(random_n)};//模拟超市运转的过程while (time < total_time) {++time; //时间增长// 新顾客到达if (--new_cust_interval == 0){service_t = service_t_d(random_n); // 设置顾客结账所需要的时间std::min_element(std::begin(checkouts), std::end(checkouts))->add(Customer(service_t));++service_times[service_t - service_t_min]; // 记录结账需要等待的时间//记录最长队列的长度for (auto & checkout : checkouts)longest_q = std::max(longest_q, checkout.qlength());new_cust_interval = arrival_interval_d(random_n);}// 更新每个队列中第一个顾客的结账时间for (auto & checkout : checkouts)checkout.time_increment();}std::cout << "最大的队列长度为:" << longest_q << std::endl;std::cout << "\n各个结账时间出现的次数::\n";histogram(service_times, service_t_min);std::cout << "\n总的顾客数:"<< std::accumulate(std::begin(service_times), std::end(service_times), 0)<< std::endl;return 0;
}
直接使用 using 指令可以减少代码输入,简化代码。顾客结账信息记录在 vector 中。结账时间减去 service_times 的最小值可以用来索引需要自增的 vector 元素,这导致 vector 的第一个元素会记录下最少结账时间出现的次数。histogram() 函数会以水平条形图的形式生成每个服务时间出现次数的柱状图。
程序中 checkouts 的值为 600,意味着将模拟开业时间设置为 600 分钟,也可以用参数输入这个时间。main() 函数生成了顾客结账时间,超市开门时等在门外的顾客数,以及顾客到达时间间隔的分布对象。我们可以轻松地将这个程序扩展为每次到达的顾客数是一个处于一定范围内的随机数。
通过调用 min_element() 算法可以找到最短的 Checkout 对象队列,因此顾客总是可以被分配到最短的结账队列。在这次模拟开始前,当超市开门营业时,在门外等待的顾客的初始序列被添加到 Checkout 对象中,然后结账时间记录被更新。
模拟在 while 循环中进行,在每次循环中,time 都会增加 1 分钟。在下一个顾客到达期间,new_cust_interval 会在每次循环中减小,直到等于 0。用新的随机结账时间生成新的顾客,然后把它加到最短的 Checkout 对象队列中。这个时候也会更新变量 longest_q,因为在添加新顾客后,可能出现新的最长队列。然后调用每个 Checkout 对象的 time_increment() 函数来处理队列中的第一个顾客。
下面是一些示例输出:
输入超级中结账柜台的数量:2
等待超市营业的顾客人数:20
最大的队列长度为:43各个结账时间出现的次数:2 13 *************3 20 ********************4 11 ***********5 16 ****************6 12 ************7 18 ******************8 17 *****************9 18 ******************
10 10 **********
11 22 **********************
12 19 *******************
13 13 *************
14 16 ****************
15 18 ******************总的顾客数:223
这里有 2 个结账柜台,最长队列的长度达到 43,已经长到会让顾客放弃付款。
以上代码还可以做更多改进,让模拟更加真实,例如,均匀分配并不符合实际,顾客通常成群结队到来。可以增加一些其他的因素,比如收银员休息时间、某个收银员生病工作状态不佳,这些都会导致顾客不选择这个柜台结账。
C++ STL priority_queue容器适配器详解
priority_queue 容器适配器模拟的也是队列这种存储结构,即使用此容器适配器存储元素只能“从一端进(称为队尾),从另一端出(称为队头)”,且每次只能访问 priority_queue 中位于队头的元素。
但是,priority_queue 容器适配器中元素的存和取,遵循的并不是 “First in,First out”(先入先出)原则,而是“First in,Largest out”原则。直白的翻译,指的就是先进队列的元素并不一定先出队列,而是优先级最大的元素最先出队列。
注意,“First in,Largest out”原则是笔者为了总结 priority_queue 存取元素的特性自创的一种称谓,仅为了方便读者理解。
那么,priority_queue 容器适配器中存储的元素,优先级是如何评定的呢?很简单,每个 priority_queue 容器适配器在创建时,都制定了一种排序规则。根据此规则,该容器适配器中存储的元素就有了优先级高低之分。
举个例子,假设当前有一个 priority_queue 容器适配器,其制定的排序规则是按照元素值从大到小进行排序。根据此规则,自然是 priority_queue 中值最大的元素的优先级最高。
priority_queue 容器适配器为了保证每次从队头移除的都是当前优先级最高的元素,每当有新元素进入,它都会根据既定的排序规则找到优先级最高的元素,并将其移动到队列的队头;同样,当 priority_queue 从队头移除出一个元素之后,它也会再找到当前优先级最高的元素,并将其移动到队头。
基于 priority_queue 的这种特性,因此该容器适配器有被称为优先级队列。
priority_queue 容器适配器“First in,Largest out”的特性,和它底层采用堆结构存储数据是分不开的。有关该容器适配器的底层实现,后续章节会进行深度剖析。
STL 中,priority_queue 容器适配器的定义如下:
template <typename T,typename Container=std::vector<T>,typename Compare=std::less<T> >
class priority_queue{//......
}
可以看到,priority_queue 容器适配器模板类最多可以传入 3 个参数,它们各自的含义如下:
-
typename T:指定存储元素的具体类型;
-
typename Container:指定 priority_queue 底层使用的基础容器,默认使用 vector 容器。
作为 priority_queue 容器适配器的底层容器,其必须包含 empty()、size()、front()、push_back()、pop_back() 这几个成员函数,STL 序列式容器中只有 vector 和 deque 容器符合条件。
-
typename Compare:指定容器中评定元素优先级所遵循的排序规则,默认使用
std::less<T>按照元素值从大到小进行排序,还可以使用
std::greater<T>按照元素值从小到大排序,但更多情况下是使用自定义的排序规则。
其中,std::less 和 std::greater 都是以函数对象的方式定义在 头文件中。关于如何自定义排序规则,后续章节会做详细介绍。
创建priority_queue的几种方式
由于 priority_queue 容器适配器模板位于<queue>头文件中,并定义在 std 命名空间里,因此在试图创建该类型容器之前,程序中需包含以下 2 行代码:
#include <queue>
using namespace std;
创建 priority_queue 容器适配器的方法,大致有以下几种。
- 创建一个空的 priority_queue 容器适配器,第底层采用默认的 vector 容器,排序方式也采用默认的 std::less 方法:
std::priority_queue<int> values;
- 可以使用普通数组或其它容器中指定范围内的数据,对 priority_queue 容器适配器进行初始化:
//使用普通数组
int values[]{4,1,3,2};
std::priority_queue<int>copy_values(values,values+4);//{4,2,3,1}
//使用序列式容器
std::array<int,4>values{ 4,1,3,2 };
std::priority_queue<int>copy_values(values.begin(),values.end());//{4,2,3,1}
注意,以上 2 种方式必须保证数组或容器中存储的元素类型和 priority_queue 指定的存储类型相同。另外,用来初始化的数组或容器中的数据不需要有序,priority_queue 会自动对它们进行排序。
- 还可以手动指定 priority_queue 使用的底层容器以及排序规则,比如:
int values[]{ 4,1,2,3 };
std::priority_queue<int, std::deque<int>, std::greater<int> >copy_values(values, values+4);//{1,3,2,4}
事实上,std::less 和 std::greater 适用的场景是有限的,更多场景中我们会使用自定义的排序规则。
由于自定义排序规则的方式不只一种,因此这部分知识将在后续章节做详细介绍。
priority_queue提供的成员函数
priority_queue 容器适配器提供了表 2 所示的这些成员函数。
表 2 priority_queue 提供的成员函数
| 成员函数 | 功能 |
|---|---|
| empty() | 如果 priority_queue 为空的话,返回 true;反之,返回 false。 |
| size() | 返回 priority_queue 中存储元素的个数。 |
| top() | 返回 priority_queue 中第一个元素的引用形式。 |
| push(const T& obj) | 根据既定的排序规则,将元素 obj 的副本存储到 priority_queue 中适当的位置。 |
| push(T&& obj) | 根据既定的排序规则,将元素 obj 移动存储到 priority_queue 中适当的位置。 |
| emplace(Args&&… args) | Args&&… args 表示构造一个存储类型的元素所需要的数据(对于类对象来说,可能需要多个数据构造出一个对象)。此函数的功能是根据既定的排序规则,在容器适配器适当的位置直接生成该新元素。 |
| pop() | 移除 priority_queue 容器适配器中第一个元素。 |
| swap(priority_queue& other) | 将两个 priority_queue 容器适配器中的元素进行互换,需要注意的是,进行互换的 2 个 priority_queue 容器适配器中存储的元素类型以及底层采用的基础容器类型,都必须相同。 |
和 queue 一样,priority_queue 也没有迭代器,因此访问元素的唯一方式是遍历容器,通过不断移除访问过的元素,去访问下一个元素。
下面的程序演示了表 2 中部分成员函数的具体用法:
#include <iostream>
#include <queue>
#include <array>
#include <functional>
using namespace std;
int main()
{//创建一个空的priority_queue容器适配器std::priority_queue<int>values;//使用 push() 成员函数向适配器中添加元素values.push(3);//{3}values.push(1);//{3,1}values.push(4);//{4,1,3}values.push(2);//{4,2,3,1}//遍历整个容器适配器while (!values.empty()){//输出第一个元素并移除。std::cout << values.top()<<" ";values.pop();//移除队头元素的同时,将剩余元素中优先级最大的移至队头}return 0;
}
运行结果为:
4 3 2 1
表 2 中其它成员函数的用法也非常简单,这里不再给出具体示例,后续章节用法会做具体介绍。
priority_queue容器适配器实现自定义排序
前面讲解 priority_queue 容器适配器时,还遗留一个问题,即当 头文件提供的排序方式(std::less 和 std::greater)不再适用时,如何自定义一个满足需求的排序规则。
首先,无论 priority_queue 中存储的是基础数据类型(int、double 等),还是 string 类对象或者自定义的类对象,都可以使用函数对象的方式自定义排序规则。例如:
#include<iostream>
#include<queue>
using namespace std;
//函数对象类
template <typename T>
class cmp
{
public://重载 () 运算符bool operator()(T a, T b){return a > b;}
};
int main()
{int a[] = { 4,2,3,5,6 };priority_queue<int,vector<int>,cmp<int> > pq(a,a+5);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}return 0;
}
运行结果为:
2 3 4 5 6
注意,C++ 中的 struct 和 class 非常类似,前者也可以包含成员变量和成员函数,因此上面程序中,函数对象类 cmp 也可以使用 struct 关键字创建:
struct cmp
{//重载 () 运算符bool operator()(T a, T b){return a > b;}
};
可以看到,通过在 cmp 类(结构体)重载的 () 运算符中自定义排序规则,并将其实例化后作为 priority_queue 模板的第 3 个参数传入,即可实现为 priority_queue 容器适配器自定义比较函数。
除此之外,当 priority_queue 容器适配器中存储的数据类型为结构体或者类对象(包括 string 类对象)时,还可以通过重载其 > 或者 < 运算符,间接实现自定义排序规则的目的。
注意,此方式仅适用于 priority_queue 容器中存储的为类对象或者结构体变量,也就是说,当存储类型为类的指针对象或者结构体指针变量时,此方式将不再适用,而只能使用函数对象的方式。
要想彻底理解这种方式的实现原理,首先要搞清楚 std::less 和 std::greater 各自的底层实现。实际上, 头文件中的 std::less 和 std::greater ,各自底层实现采用的都是函数对象的方式。比如,std::less 的底层实现代码为:
template <typename T>
struct less {//定义新的排序规则bool operator()(const T &_lhs, const T &_rhs) const {return _lhs < _rhs;}
};
std::greater 的底层实现代码为:
template <typename T>
struct greater {bool operator()(const T &_lhs, const T &_rhs) const {return _lhs > _rhs;}
};
可以看到,std::less 和 std::greater 底层实现的唯一不同在于,前者使用 < 号实现从大到小排序,后者使用 > 号实现从小到大排序。
那么,是否可以通过重载 < 或者 > 运算符修改 std::less 和 std::greater 的排序规则,从而间接实现自定义排序呢?答案是肯定的,举个例子:
#include<queue>
#include<iostream>
using namespace std;
class node {
public:node(int x = 0, int y = 0) :x(x), y(y) {}int x, y;
};
//新的排序规则为:先按照 x 值排序,如果 x 相等,则按 y 的值排序
bool operator < (const node &a, const node &b) {if (a.x > b.x) return 1;else if (a.x == b.x)if (a.y >= b.y) return 1;return 0;
}
int main() {//创建一个 priority_queue 容器适配器,其使用默认的 vector 基础容器以及 less 排序规则。priority_queue<node> pq;pq.push(node(1, 2));pq.push(node(2, 2));pq.push(node(3, 4));pq.push(node(3, 3));pq.push(node(2, 3));cout << "x y" << endl;while (!pq.empty()) {cout << pq.top().x << " " << pq.top().y << endl;pq.pop();}return 0;
}
输出结果为:
x y
1 2
2 2
2 3
3 3
3 4
可以看到,通过重载 < 运算符,使得 std::less 变得适用了。
读者还可以自行尝试,通过重载 > 运算符,赋予 std::greater 和之前不同的排序方式。
当然,也可以以友元函数或者成员函数的方式重载 > 或者 < 运算符。需要注意的是,以成员函数的方式重载 > 或者 < 运算符时,该成员函数必须声明为 const 类型,且参数也必须为 const 类型,至于参数的传值方式是采用按引用传递还是按值传递,都可以(建议采用按引用传递,效率更高)。
例如,将上面程序改为以成员函数的方式重载 < 运算符:
class node {
public:node(int x = 0, int y = 0) :x(x), y(y) {}int x, y;bool operator < (const node &b) const{if ((*this).x > b.x) return 1;else if ((*this).x == b.x)if ((*this).y >= b.y) return 1;return 0;}
};
同样,在以友元函数的方式重载 < 或者 > 运算符时,要求参数必须使用 const 修饰。例如,将上面程序改为以友元函数的方式重载 < 运算符。例如:
class node {
public:node(int x = 0, int y = 0) :x(x), y(y) {}int x, y;friend bool operator < (const node &a, const node &b);
};
//新的排序规则为:先按照 x 值排序,如果 x 相等,则按 y 的值排序
bool operator < (const node &a, const node &b){if (a.x > b.x) return 1;else if (a.x == b.x)if (a.y >= b.y) return 1;return 0;
}
总的来说,以函数对象的方式自定义 priority_queue 的排序规则,适用于任何情况;而以重载 > 或者 < 运算符间接实现 priority_queue 自定义排序的方式,仅适用于 priority_queue 中存储的是结构体变量或者类对象(包括 string 类对象)。
深度剖析priority_queue容器的底层实现
priority_queue 优先级队列之所以总能保证优先级最高的元素位于队头,最重要的原因是其底层采用堆数据结构存储结构。
有读者可能会问,priority_queue 底层不是采用 vector 或 deque 容器存储数据吗,这里又说使用堆结构存储数据,它们之间不冲突吗?显然,它们之间是不冲突的。
首先,vector 和 deque 是用来存储元素的容器,而堆是一种数据结构,其本身无法存储数据,只能依附于某个存储介质,辅助其组织数据存储的先后次序。其次,priority_queue 底层采用 vector 或者 deque 作为基础容器,这毋庸置疑。但由于 vector 或 deque 容器并没有提供实现 priority_queue 容器适配器 “First in,Largest out” 特性的功能,因此 STL 选择使用堆来重新组织 vector 或 deque 容器中存储的数据,从而实现该特性。
注意,虽然不使用堆结构,通过编写算法调整 vector 或者 deque 容器中存储元素的次序,也能使其具备 “First in,Largest out” 的特性,但执行效率通常没有使用堆结构高。
那么,堆到底是什么,它又是怎样组织数据的呢?
priority_queue底层的堆存储结构
以下内容要求读者对数据结构中的树存储结构有一定的了解,如果没有,请先阅读《树存储结构》一章。
简单的理解堆,它在是完全二叉树的基础上,要求树中所有的父节点和子节点之间,都要满足既定的排序规则:
- 如果排序规则为从大到小排序,则表示堆的完全二叉树中,每个父节点的值都要不小于子节点的值,这种堆通常称为大顶堆;
- 如果排序规则为从小到大排序,则表示堆的完全二叉树中,每个父节点的值都要不大于子节点的值,这种堆通常称为小顶堆;
图 1 展示了一个由 {10,20,15,30,40,25,35,50,45} 这些元素构成的大顶堆和小顶堆。其中经大顶堆组织后的数据先后次序变为 {50,45,40,20,25,35,30,10,15},而经小顶堆组织后的数据次序为{10,20,15,25,50,30,40,35,45}。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8TIP5dAT-1692323525705)(file:///C:/Users/10789/Desktop/c%E8%AF%AD%E8%A8%80%E4%B8%AD%E6%96%87%E7%BD%91/STL/5.8%E6%B7%B1%E5%BA%A6%E5%89%96%E6%9E%90priority_queue%E5%AE%B9%E5%99%A8%E7%9A%84%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0_files/2-191226140Kc17.gif)]
图 1 使用堆结构重新组织数据
可以看到,大顶堆中,每个父节点的值都不小于子节点;同样在小顶堆中,每个父节点的值都不大于子节点。但需要注意的是,无论是大顶堆还是小顶堆,同一父节点下子节点的次序是不做规定的,这也是经大顶堆或小顶堆组织后的数据整体依然无序的原因。
可以确定的一点是,无论是通过大顶堆或者小顶堆,总可以筛选出最大或最小的那个元素(优先级最大),并将其移至序列的开头,此功能也正是 priority_queue 容器适配器所需要的。
为了验证 priority_queue 底层确实采用堆存储结构实现的,我们可以尝试用堆结合基础容器 vector 或 deque 实现 priority_queue。值得庆幸的是,STL 已经为我们封装好了可以使用堆存储结构的方法,它们都位于 头文件中。表 2 中列出了常用的几个和堆存储结构相关的方法。
表 2 STL对堆存储结构的支持
| 函数 | 功能 |
|---|---|
| make_heap(first,last,comp) | 选择位于 [first,last) 区域内的数据,并根据 comp 排序规则建立堆,其中 fist 和 last 可以是指针或者迭代器,默认是建立大顶堆。 |
| push_heap(first,last,comp) | 当向数组或容器中添加数据之后,此数据可能会破坏堆结构,该函数的功能是重建堆。 |
| pop_heap(first,last,comp) | 将位于序列头部的元素(优先级最高)移动序列尾部,并使[first,last-1] 区域内的元素满足堆存储结构。 |
| sort_heap(first,last,comp) | 对 [first,last) 区域内的元素进行堆排序,将其变成一个有序序列。 |
| is_heap_until(first,last,comp) | 发现[first,last)区域内的最大堆。 |
| is_heap(first,last,comp) | 检查 [first,last) 区域内的元素,是否为堆结构。 |
以上方法的实现,基于堆排序算法的思想,有关该算法的具体实现原理,可阅读《堆排序》一节做详细了解。
下面例子中,使用了表 2 中的部分函数,并结合 vector 容器提供的成员函数,模拟了 priority_queue 容器适配器部分成员函数的底层实现:
#include <iostream>
#include <vector>
#include<algorithm>
using namespace std;
void display(vector<int>& val) {for (auto v : val) {cout << v << " ";}cout << endl;
}
int main()
{vector<int>values{ 2,1,3,4 };//建立堆make_heap(values.begin(), values.end());//{4,2,3,1}display(values);//添加元素cout << "添加元素:\n";values.push_back(5);display(values);push_heap(values.begin(), values.end());//{5,4,3,1,2}display(values);//移除元素cout << "移除元素:\n";pop_heap(values.begin(), values.end());//{4,2,3,1,5}display(values);values.pop_back();display(values);return 0;
}
运行结果为:
4 2 3 1
添加元素:
4 2 3 1 5
5 4 3 1 2
移除元素:
4 2 3 1 5
4 2 3 1
上面程序可以用 priority_queue 容器适配器等效替代:
#include<iostream>
#include<queue>
#include<vector>
using namespace std;
int main()
{//创建优先级队列std::vector<int>values{ 2,1,3,4 };std::priority_queue<int>copy_values(values.begin(), values.end());//添加元素copy_values.push(5);//移除元素copy_values.pop();return 0;
}
如果调试此程序,查看各个阶段 priority_queue 中存储的元素,可以发现,它和上面程序的输出结果是一致。也就是说,此程序在创建 priority_queue 之后,其存储的元素依次为 {4,2,3,1},同样当添加元素 5 之后,其存储的元素依次为 {5,4,3,1,2},移除一个元素之后存储的元素依次为 {4,2,3,1}。