epoll
参考文献
https://www.cnblogs.com/lojunren/p/3856290.html
https://www.51cto.com/article/717096.html
linux下的I/O复用epoll详解
要深刻理解epoll,首先得了解epoll的三大关键要素:mmap、红黑树、链表。
IO多路复用
首先需要了解什么是IO多路复用
IO多路复用是一种同步的IO模型。利用IO多路复用模型,可以实现一个线程监视多个文件句柄;一旦某个文件句柄就绪,就能够通知到对应应用程序进行相应的读写操作;没有文件句柄就绪时就会阻塞应用程序,从而释放出CPU资源。
IO可以理解为,在操作系统中,数据在内核态和用户态之间的读、写操作,大部分情况下是指网络IO;
多路大部分情况下是指多个TCP连接,也就是多个Socket 或者多个Channel;
复用是指复用一个或多个线程资源。IO多路复用意思就是说,一个或多个线程处理多个 TCP 连接。尽可能地减少系统开销,无需创建和维护过多的进程/线程。
三种实现IO多路复用的模型
分别是Select、poll 和 epoll。下面详细介绍一下三种多路复用模型的基本原理和优缺点:
select模型
它的基本原理是,采用轮询和遍历的方式。也就是说,在客户端操作服务器时,会创建三种文件描述符,简称FD。分别是writefds(写描述符)、readfds(读描述符)和 exceptfds(异常描述符)。
而select会阻塞监视这三种文件描述符,等有数据、可读、可写、出异常或超时都会返回;
返回后通过遍历fdset,也就是文件描述符的集合,来找到就绪的FD,然后,触发相应的IO操作。
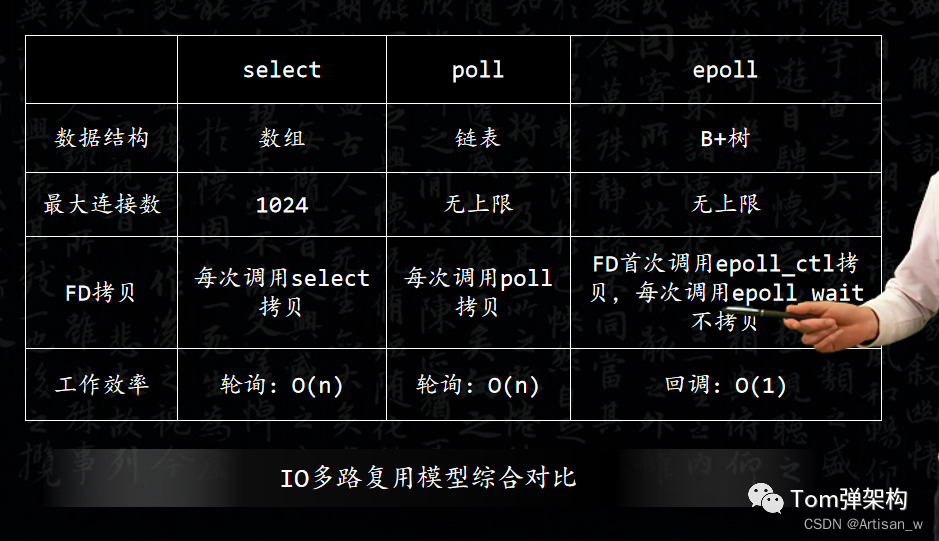
它的优点是跨平台支持性好,几乎在所有的平台上支持。它的缺点也很明显,由于select是采用轮询的方式进行全盘扫描,因此,随着FD数量增多而导致性能下降。
因此,每次调用select()方法,都需要把FD集合从用户态拷贝到内核态,并进行遍历。而操作系统对单个进程打开的FD数量是有限制的,一般默认是1024个。虽然,可以通过操作系统的宏定义FD_SETSIZE修改最大FD数量限制,但是,在IO吞吐量巨大的情况下,效率提升仍然有限。
poll模型
poll 模型的原理与select模型基本一致,也是采用轮询加遍历,唯一的区别就是 poll 采用链表的方式来存储FD。
所以,它的优点点是没有最大FD的数量限制。
它的缺点和select一样,也是采用轮询方式全盘扫描,同样也会随着FD数量增多而导致性能下降。
epoll模型
由于select和poll都会因为吞吐量增加而导致性能下降,因此,才出现了epoll模型。
epoll模型是采用时间通知机制来触发相关的IO操作。它没有FD个数限制,而且从用户态拷贝到内核态只需要一次。它主要通过系统底层的函数来注册、激活FD,从而触发相关的 IO 操作,这样大大提高了性能。
epoll模型最大的优点是将轮询改成了回调,大大提高了CPU执行效率,也不会随FD数量的增加而导致效率下降。当然,它也没有FD数量限制,也就是说,它能支持的FD上限是操作系统的最大文件句柄数。一般而言,1G 内存大概支持 10 万个句柄。分布式系统中常用的组件如Redis、Nginx都是优先采用epoll模型。
它的缺点是只能在Linux下工作。
对比
epool模型工作原理
主要是通过调用以下三个系统函数来注册、激活FD,从而触发相关的 IO 操作:
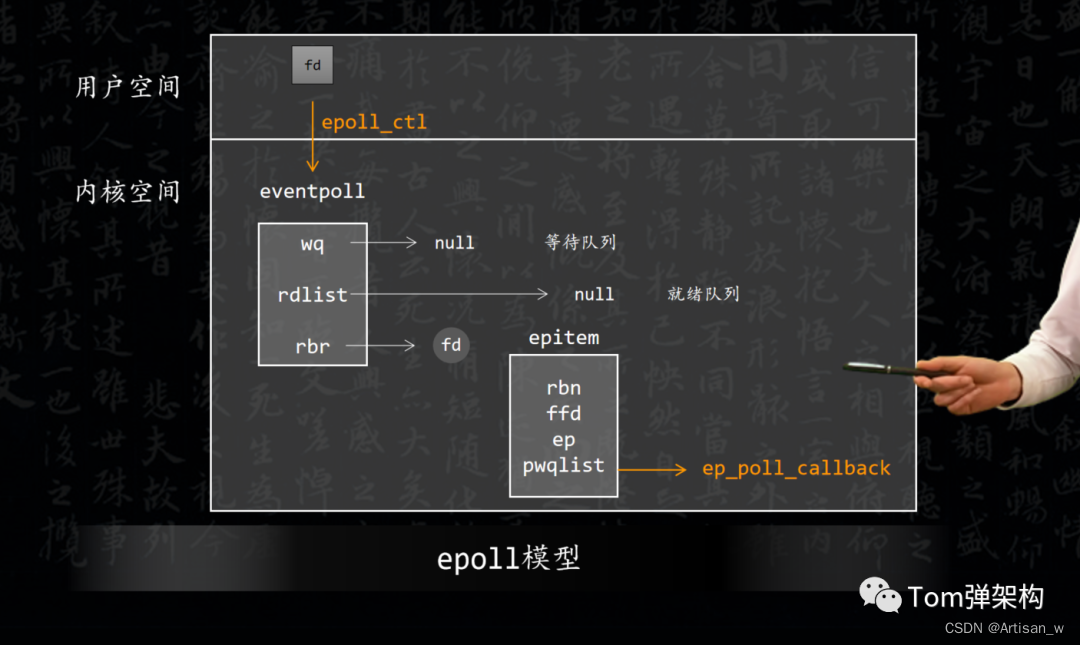
(1)epoll_create()函数,在系统启动时,会在Linux内核里面申请一个B+树结构的文件系统,然后,返回epoll对象,也是一个FD。
(2)epoll_ctl()函数,每新建一个连接的时候,会同步更新epoll对象中的FD,并且绑定一个 callback回调函数。
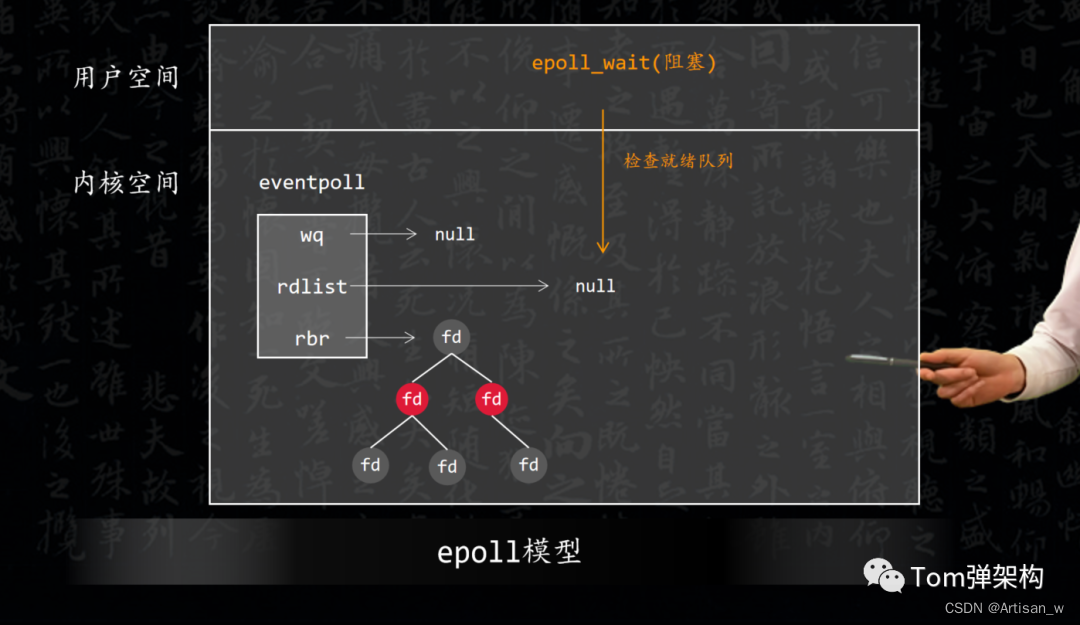
(3)epoll_wait()函数,轮询所有的callback集合,并触发对应的 IO 操作

![[oneAPI] BERT](https://img-blog.csdnimg.cn/e086f4c3fcaf4edda6062074fd7764c6.png)