文章目录
- 数据不均衡危害
- 如何解决
- SMOTE
- 原理
- 代码
- 效果
数据不均衡危害
在模型预测中,数据不均衡是指不同类别的样本数量差异很大。这种情况可能会对模型的性能和结果产生一些危害:
- 偏斜的预测结果:由于某些类别的样本数量较少,模型可能会倾向于预测数量更多的类别,而忽略数量较少的类别。这会导致模型在预测时出现偏斜,对少数类别的预测效果较差。
- 误导性的评估指标:在数据不均衡的情况下,使用传统的评估指标(如准确率)可能会产生误导。因为模型可以简单地将所有样本预测为数量更多的类别,从而获得较高的准确率,而忽略了对少数类别的预测能力。
- 不稳定的模型训练:当数据不均衡时,模型可能会过度拟合数量较多的类别,而忽略数量较少的类别。这可能导致模型在实际应用中的泛化能力较差,对新样本的预测表现不佳。
- 不准确的特征重要性:在数据不均衡的情况下,模型可能会错误地认为与数量更多的类别相关的特征更重要,而忽略了与数量较少的类别相关的特征。这可能导致模型对于不同类别的预测能力的偏差。
如何解决
为了解决数据不均衡的问题,可以采取以下一些方法:
- 重采样技术:通过欠采样(随机删除数量较多的样本)或过采样(复制数量较少的样本)来平衡数据集中的类别数量。
- 类别权重调整:通过为数量较少的类别赋予更高的权重,来平衡不同类别的重要性。
- 引入合成样本:通过生成合成样本来增加数量较少的类别的样本数量,例如使用SMOTE(Synthetic Minority Over-sampling Technique)算法。
- 使用集成方法:使用集成学习方法,如随机森林或梯度提升树,可以通过组合多个模型的预测结果来改善对少数类别的预测能力。
综上所述,数据不均衡可能会对模型预测的准确性和稳定性产生负面影响。通过合适的数据处理和模型调整方法,可以改善模型在不均衡数据集上的表现。
SMOTE
原理
SMOTE(Synthetic Minority Over-sampling Technique)是一种用于解决类别不平衡问题的数据增强算法。其原理如下:
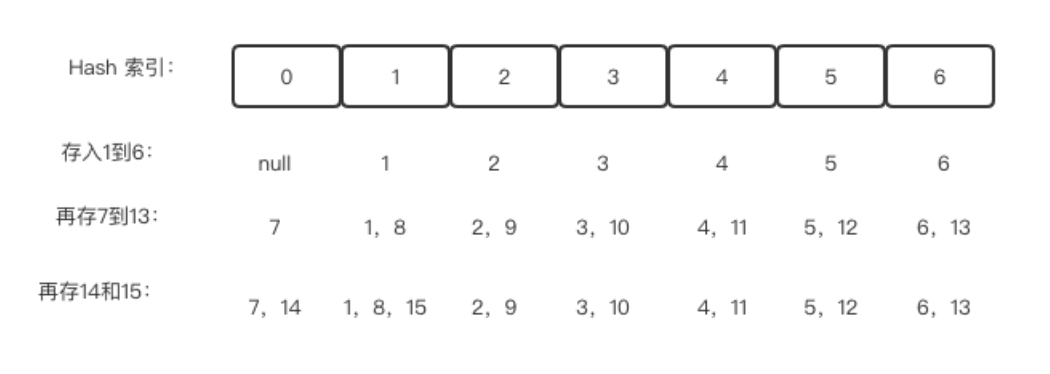
- 首先,对于数据集中的每一个少数类样本,计算其与其K个最近邻样本的差值:diff = neighbor - sample,其中neighbor是样本的一个最近邻样本,sample是当前样本。
- 然后,对于每一个少数类样本,随机选择其中一个最近邻样本,并根据公式生成一个新的样本:new_sample = sample + random * diff,其中random是一个[0, 1]之间的随机数。
- 最后,将生成的新样本添加到原始数据集中,使得少数类样本的数量增加,从而达到平衡数据集的目的。
SMOTE的关键思想是通过合成新的少数类样本来增加数据集中少数类样本的数量,从而达到平衡数据集的目的。通过引入合成样本,SMOTE可以更好地捕捉到少数类样本之间的特征分布,从而提高分类器的性能。
代码
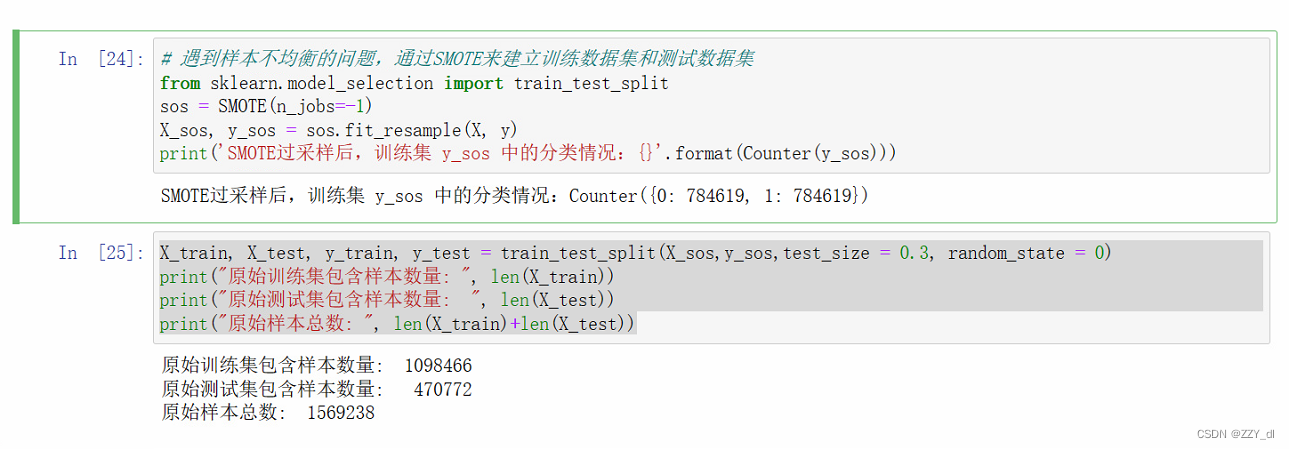
# 遇到样本不均衡的问题,通过SMOTE来建立训练数据集和测试数据集
from sklearn.model_selection import train_test_split
sos = SMOTE(n_jobs=-1)
X_sos, y_sos = sos.fit_resample(X, y)
print('SMOTE过采样后,训练集 y_sos 中的分类情况:{}'.format(Counter(y_sos)))X_train, X_test, y_train, y_test = train_test_split(X_sos,y_sos,test_size = 0.3, random_state = 0)
print("原始训练集包含样本数量: ", len(X_train))
print("原始测试集包含样本数量: ", len(X_test))
print("原始样本总数: ", len(X_train)+len(X_test))
效果
初始:
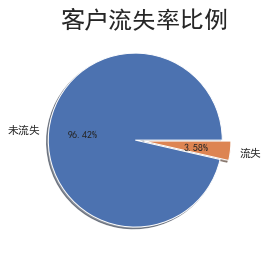
处理后:





![[JavaWeb]【五】web后端开发-Tomcat SpringBoot解析](https://img-blog.csdnimg.cn/a172da766cd44c8f903a4bee3461ac87.png)