文章目录
- 一、flink 流式读取文件夹、文件
- 二、flink 写入文件系统——StreamFileSink
- 三、查看完整代码
一、flink 流式读取文件夹、文件
Apache Flink针对文件系统实现了一个可重置的source连接器,将文件看作流来读取数据。如下面的例子所示:
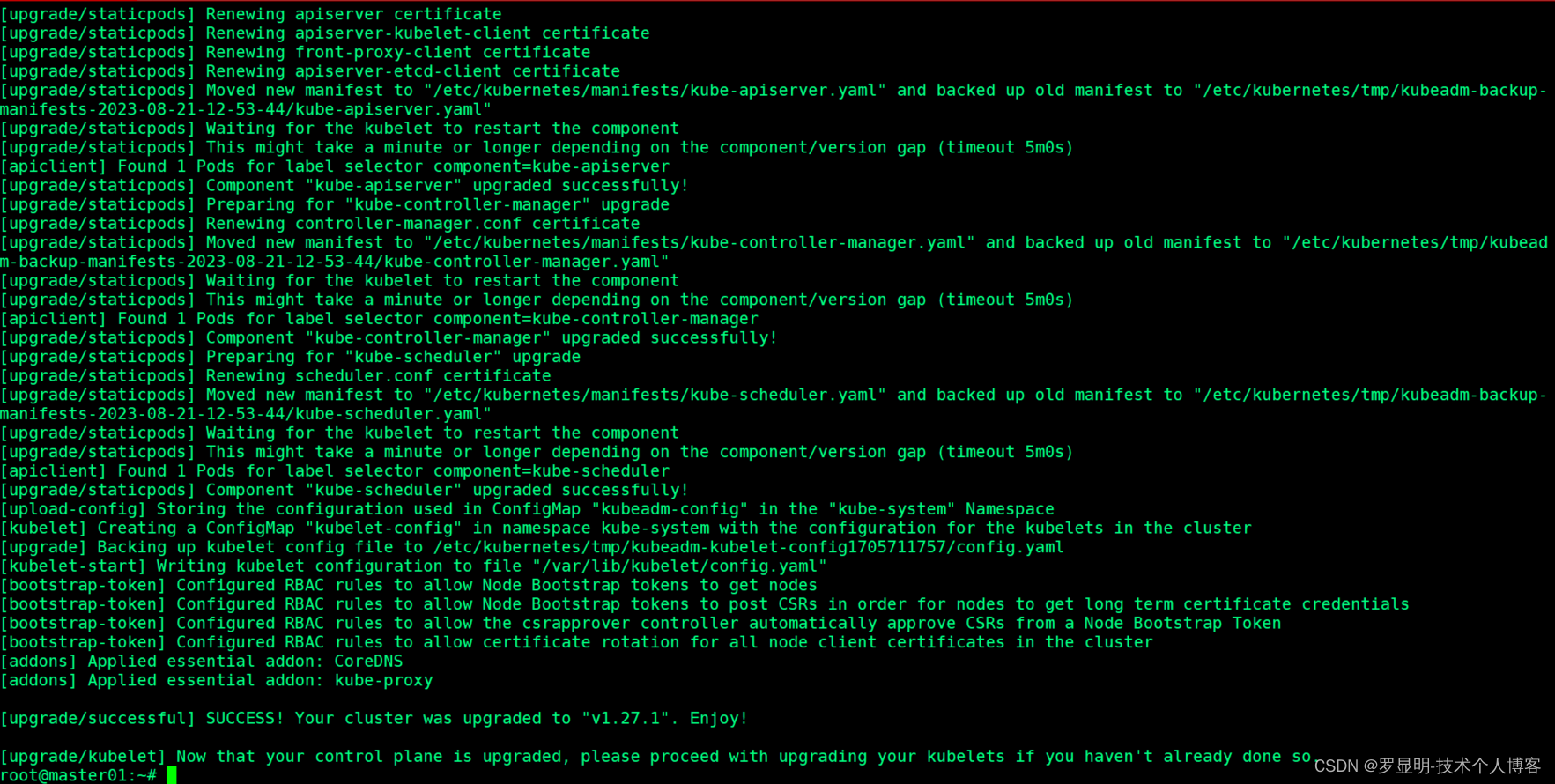
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();TextInputFormat textInputFormat = new TextInputFormat(null);DataStreamSource<String> source = env.readFile(textInputFormat, sourcePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 30000L);
StreamExecutionEnvironment.readFile()接收如下参数:
- FileInputFormat参数,负责读取文件中的内容。
- 文件路径。如果文件路径指向单个文件,那么将会读取这个文件。如果路径指向一个文件夹,FileInputFormat将会扫描文件夹中所有的文件。
- PROCESS_CONTINUOUSLY将会周期性的扫描文件,以便扫描到文件新的改变。
- 30000L表示多久扫描一次监听的文件。
FileInputFormat是一个特定的InputFormat,用来从文件系统中读取文件。FileInputFormat分两步读取文件。首先扫描文件系统的路径,然后为所有匹配到的文件创建所谓的input splits。一个input split将会定义文件上的一个范围,一般通过读取的开始偏移量和读取长度来定义。在将一个大的文件分割成一堆小的splits以后,这些splits可以分发到不同的读任务,这样就可以并行的读取文件了。FileInputFormat的第二步会接收一个input split,读取被split定义的文件范围,然后返回对应的数据。
DataStream应用中使用的FileInputFormat需要实现CheckpointableInputFormat接口。这个接口定义了方法来做检查点和重置文件片段的当前的读取位置。
在Flink 1.7中,Flink提供了一些类,这些类继承了FileInputFormat,并实现了CheckpointableInputFormat接口。TextInputFormat一行一行的读取文件,而CsvInputFormat使用逗号分隔符来读取文件。
二、flink 写入文件系统——StreamFileSink
该Sink不但可以将数据写入到各种文件系统中,而且整合了checkpoint机制来保证Exacly Once语义,还可以对文件进行分桶存储,还支持以列式存储的格式写入,功能更强大。
streamFileSink中输出的文件,其生命周期会经历3中状态:
- in-progress Files 当前文件正在写入中
- Pending Files 当处于 In-progress 状态的文件关闭closed了,就变为 Pending 状态
- Finished Files 在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态
下面是一个简答的例子 , 将接收到的数据流 ,写入到文件中保存 !
数据文件格式是行式存储格式
BucketAssigner<String, String> assigner = new DateTimeBucketAssigner<>("yyyy-MM-dd", ZoneId.of("Asia/Shanghai"));StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(new Path(savePath),new SimpleStringEncoder<>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(20))//至少包含 20 分钟的数据.withInactivityInterval(TimeUnit.MINUTES.toMillis(20))//最近 20 分钟没有收到新的数据.withMaxPartSize(1024 * 1024 * 1024)//文件大小已达到 1 GB.build()).withBucketAssigner(assigner).build();
其中特别说明了,如果使用 FileSink 在 STREAMING 模式的时候,必须开启 checkpoint,不然的话会导致每个分片文件一直处于 in-progress 或者 pending 状态,不能保证整个写入流程的安全性。
所以在我们上述的示例中,我们并未开启 checkpoint 导致写出文件一直处于 inprogress 状态。如果加上 checkpoint 后:
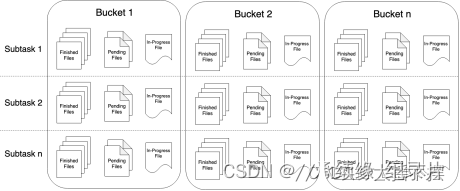
将数据以列式存储的格式输出到文件中
三、查看完整代码
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.io.TextInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import org.apache.flink.streaming.api.functions.source.FileProcessingMode;import java.time.ZoneId;
import java.util.concurrent.TimeUnit;public class WordTest {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.设置CK&状态后端env.setStateBackend(new FsStateBackend("hdfs://nameservice1/tmp/kafka_test/data/chatgpt/mnbvc/checkpoint"));env.enableCheckpointing(1000*60*3);// 每 ** ms 开始一次 checkpointenv.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 设置模式为精确一次env.getCheckpointConfig().setCheckpointTimeout(1000*60*5);// Checkpoint 必须在** ms内完成,否则就会被抛弃env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 同一时间只允许一个 checkpoint 进行env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);// 确认 checkpoints 之间的时间会进行 ** msenv.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);// 允许两个连续的 checkpoint 错误env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10,TimeUnit.SECONDS)));//重启策略:重启3次,间隔10s// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);String sourcePath = "hdfs://nameservice1/ec/data/chatgpt/mnbvc/mnbvc_website/format_com";String savePath = "hdfs://nameservice1/ec/data/chatgpt/mnbvc/mnbvc_website/format_filter_01";TextInputFormat textInputFormat = new TextInputFormat(null);DataStreamSource<String> source = env.readFile(textInputFormat, sourcePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 30000L);BucketAssigner<String, String> assigner = new DateTimeBucketAssigner<>("yyyy-MM-dd", ZoneId.of("Asia/Shanghai"));StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(new Path(savePath),new SimpleStringEncoder<>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(TimeUnit.MINUTES.toMillis(20))//至少包含 20 分钟的数据.withInactivityInterval(TimeUnit.MINUTES.toMillis(20))//最近 20 分钟没有收到新的数据.withMaxPartSize(1024 * 1024 * 1024)//文件大小已达到 1 GB.build()).withBucketAssigner(assigner).build();source.map(line -> JSONObject.parseObject(line)).filter(line -> line.getString("text").length() > 200 && line.getInteger("id") % 7 == 0).map(line -> JSON.toJSONString(line)).addSink(fileSink);env.execute();}
}