第11步---MySQL的优化
1.概念
原先写功能。后来对平静进行优化
-
设计
-
查询语句
-
索引
-
存储
2.查看执行效率
-- 查看当前会话sql得执行类型得统计信息SHOW session STATUS like 'Com%'
上面展示得信息就是统计了当前会话得执行得操作得次数。
-- 查看全局得
SHOW GLOBAL STATUS like 'Com%'
-- 查看基于innoDB引擎得操作
SHOW STATUS LIKE 'Innodb_rows_%'
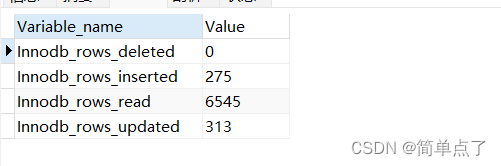
3.sql优化操作
查看慢sql
-- 查看慢日志得配置得信息
SHOW VARIABLES LIKE '%slow_query_log%';
系统得慢日志是默认是关闭的状态的需要自己单独进行开启。
开启慢日志查询
-- 开启慢日志查询
set GLOBAL slow_query_log=1;重新查看慢日志的信息

-- 查看慢日志的执行的阈值的信息
SHOW VARIABLES LIKE '%long_query_time%';
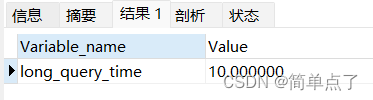
只有执行的执行的时间超过了10s的就会被记录下来。
-- 修改慢日志的执行的阈值的信息
SET SESSION long_query_time=5;-- 查看慢日志的执行的阈值的信息
SHOW VARIABLES LIKE '%long_query_time%';
要是进行全局修改的修改的话只能修改本地的配置文件。
4.定位执行效率低下的sql
-- 查看当前客户端连接服务器的线程执行的状态信息
SHOW PROCESSLIST;
5.Explain执行计划
-- 查看当前sql的执行计划
EXPLAIN SELECT * FROM account WHERE name ='zhangsan';

-
id是表的查询序号
-
type是简单表还是子查询等
-
输出结果的表
-
type:连接的类型
-
用到的索引
-
实际的索引
-
索引字段的长度
-
扫描字段的长度
-
扫描行的长度
-
执行情况的说明和描述
-- 查看表的连接情况
EXPLAIN SELECT * FROM dept d join emp e ON d.deptno=e.deptno;

上面的表都是平行的关系,没有主副之分的。
要是子查询的话有顺序的关系。id的值越大执行的顺序就越高。里面的子查询最先被加载的。
主查询是子查询最外层的查询。

select_type指定的是表中的数据来自于什么地方。可以来自基本表,可以来自衍生表等等。
6.type类型
all:表示全表扫描。

5.7以上的版本不再显示system。
普通的索引是ref。只有唯一索引才会出现const。
CREATE TABLE `user2` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;CREATE TABLE `user2_sex` (`id` int(11) NOT NULL AUTO_INCREMENT,`age` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;INSERT INTO `xx`.`user2` (`id`, `name`) VALUES (1, '张三');
INSERT INTO `xx`.`user2` (`id`, `name`) VALUES (2, '李四');
INSERT INTO `xx`.`user2` (`id`, `name`) VALUES (3, '王五');INSERT INTO `xx`.`user2_sex` (`id`, `age`) VALUES (1, 20);
INSERT INTO `xx`.`user2_sex` (`id`, `age`) VALUES (2, 22);
INSERT INTO `xx`.`user2_sex` (`id`, `age`) VALUES (3, 23);EXPLAIN SELECT * FROM user2 a,user2_sex b WHERE a.id=b.id;

下面给第二个添加一个主键索引。
eq_ref比ref效率更高。
range:
EXPLAIN SELECT * FROM user2 WHERE id>2;index:扫描的是索引列
all:把整个表都进行扫描一遍
执行的效率:
system<const<eq_ref<ref<range<index<all
7.其他执行字段
table
-
显示的不一定是真实的名字可以是数据表的简称
rows:
-
扫描的行的数量
key:
-
possible_keys:显示可能应用在这张表的索引,一个或多个。
-
key:实际使用的索引。如果为null,就是没有使用索引。
EXPLAIN SELECT * FROM user2 WHERE id>2;

要是直接查询全部的话就是不会显示
EXPLAIN SELECT * FROM user2 ;

extra
-
显示额外的执行计划
EXPLAIN SELECT * FROM user2 order by name ;
EXPLAIN SELECT count(*) FROM user2 GROUP BY name ;


8.show profile查看执行效率
-- 采用show profile
-- 8.x不支持的
show @@have_profiling;-- 不支持的话
SET profiling=1;执行一些简单的操作
SHOW DATABASES;
USE xx;
SELECT * FROM user2 WHERE id>2;SHOW PROFILES;

查看单个sql的执行的时间的信息。
SHOW PROFILE FOR QUERY 90;
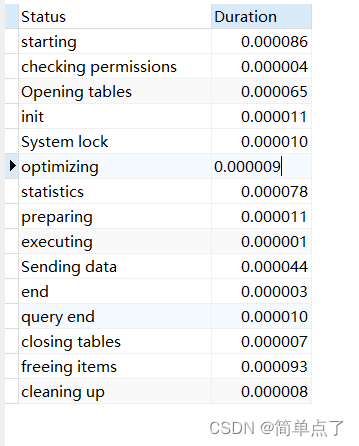
查看cpu的执行的时间的信息
SHOW PROFILE cpu FOR QUERY 109;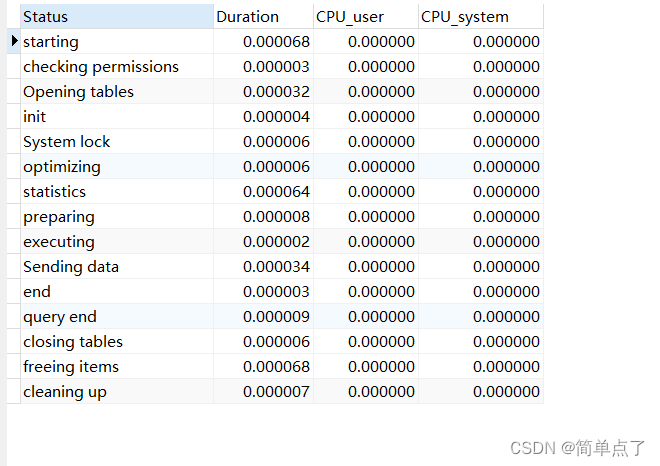
-
1:整个阶段的时间
-
2:用户消耗
-
3:系统的cpu的消耗
9.查看trace优化器
sql中提供了跟踪的trace,通过trace文件可以进一步为什么优化器执行的过程。
-- 设置trace
set optimizer_trace ='enabled=on',end_markers_in_json=on;
-- 设置最大的显示内存
SET optimizer_trace_max_mem_size=1000000;SELECT * FROM user2;-- 执行sql
SELECT * FROM information_schema.OPTIMIZER_TRACE \G;下面是在dos终端显示的内容。navicat中是显示不出来的。
*************************** 1. row ***************************QUERY: SELECT * FROM user2TRACE: {"steps": [{"join_preparation": {"select#": 1,"steps": [{"expanded_query": "/* select#1 */ select `user2`.`id` AS `id`,`user2`.`name` AS `name` from `user2`"}] /* steps */} /* join_preparation */},{"join_optimization": {"select#": 1,"steps": [{"table_dependencies": [{"table": "`user2`","row_may_be_null": false,"map_bit": 0,"depends_on_map_bits": [] /* depends_on_map_bits */}] /* table_dependencies */},{"rows_estimation": [{"table": "`user2`","table_scan": {"rows": 3,"cost": 0.25} /* table_scan */}] /* rows_estimation */},{"considered_execution_plans": [{"plan_prefix": [] /* plan_prefix */,"table": "`user2`","best_access_path": {"considered_access_paths": [{"rows_to_scan": 3,"access_type": "scan","resulting_rows": 3,"cost": 0.55,"chosen": true}] /* considered_access_paths */} /* best_access_path */,"condition_filtering_pct": 100,"rows_for_plan": 3,"cost_for_plan": 0.55,"chosen": true}] /* considered_execution_plans */},{"attaching_conditions_to_tables": {"original_condition": null,"attached_conditions_computation": [] /* attached_conditions_computation */,"attached_conditions_summary": [{"table": "`user2`","attached": null}] /* attached_conditions_summary */} /* attaching_conditions_to_tables */},{"refine_plan": [{"table": "`user2`"}] /* refine_plan */}] /* steps */} /* join_optimization */},{"join_execution": {"select#": 1,"steps": [] /* steps */} /* join_execution */}] /* steps */
}10.索引优化
最左原则
避免索引失效。
-
全值匹配是会出现失效的。
-
组合索引的时候从左到右进行匹配的。只要包含就行与顺序是无关的。
-
不能违背最左原则
11.其他常见失效的情况
索引失效的其他的常见的做法
-
范围上不能进行运算
-
字符串不加单引号索引会失效。不影响查询,会自动地进行类型地转换
-
尽量避免覆盖索引。避免select *。

- 没有必要的时候尽量不要写select *的操作。

- 避免l以%
- 开头的like模糊查询。索引失效。要是%放在最后面的话就可以利用索引
12.不使用索引的情况
不使用索引的情况
-
当全表查询的速度比索引快的时候不用索引
-
is null 和 is not null 有时候失效。有时候是有效的。根据实际的数据是有关的。
-
in走索引。not in索引失效。但是主键索引都是会用的。
-
单列索引和复合索引,尽量比卖你使用复合索引。
-
多个索引的话,即使where中有多个索引列,则只有一个是最优的索引是有效的。
13.SQL优化-大批量插入数据
大批量插入数据
-
要保证主键列是有序的插入的速度是比较快的
CREATE TABLE tb_user
(id int(11) NOT NULL AUTO_INCREMENT,username varchar(45) NOT NULL,password varchar(96) NOT NULL,name varchar(45) NOT NULL,birthday datetime DEFAULT NULL,sex char(1) DEFAULT NULL,email varchar(45) DEFAULT NULL,phone varchar(45) DEFAULT NULL,qq varchar(32) DEFAULT NULL,status varchar(32) NOT NULL COMMENT '用户状态',create_time datetime NOT NULL,update_time datetime DEFAULT NULL,PRIMARY KEY (id),UNIQUE KEY unique_user_username (username)
) ;
我们将文件中的数据保存到表中。插入的数据最好是要插入的数据是有顺序的。
-
指定字段之间的分隔符 逗号
-
指定行之间的分割符是 换行符
-
load是加载本地的文件插入到数据库中的
load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n';
需要开启系统的相关的操作
-- 1、首先,检查一个全局系统变量 'local_infile' 的状态, 如果得到如下显示 Value=OFF,则说明这是不可用的
show global variables like 'local_infile';-- 2、修改local_infile值为on,开启local_infile
set global local_infile=1;此时执行load操作。
主键乱序的比主键不乱序的执行的效率是低的。
关闭唯一性校验
-- 关闭唯一性校验
SET UNIQUE_CHECKS=0;执行插入操作
-- 插入完成之后再开启校验的操作
SET UNIQUE_CHECKS=1;
14.insert优化
-
将多个insert转换成一个插入的操作
-
采用手动事务提交的方式。
-
插入的数据尽量保持有序
15.order by优化
常见的两种排序的方式
-
直接对返回的数据进行的排序就是filesort,所有不是通过索引直接返回排序结果的排序叫做filesort
-
有序索引顺序扫描直接返回有序数据。这种情况极为using index。不需要额外排序,操作效率高。
DROP TABLE IF EXISTS emp;
-- 优化order by语句
CREATE TABLE `emp` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(100) NOT NULL,`age` int(3) NOT NULL,`salary` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ;
insert into `emp` (`id`, `name`, `age`, `salary`) values('1','Tom','25','2300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('2','Jerry','30','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('3','Luci','25','2800');
insert into `emp` (`id`, `name`, `age`, `salary`) values('4','Jay','36','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('5','Tom2','21','2200');
insert into `emp` (`id`, `name`, `age`, `salary`) values('6','Jerry2','31','3300');
insert into `emp` (`id`, `name`, `age`, `salary`) values('7','Luci2','26','2700');
insert into `emp` (`id`, `name`, `age`, `salary`) values('8','Jay2','33','3500');
insert into `emp` (`id`, `name`, `age`, `salary`) values('9','Tom3','23','2400');
insert into `emp` (`id`, `name`, `age`, `salary`) values('10','Jerry3','32','3100');
insert into `emp` (`id`, `name`, `age`, `salary`) values('11','Luci3','26','2900');
insert into `emp` (`id`, `name`, `age`, `salary`) values('12','Jay3','37','4500');-- 创建组合索引
CREATE INDEX idx_emp_age_salary on emp (age,salary);-- Using filesort
EXPLAIN SELECT * FROM emp ORDER BY age;-- Using filesort
EXPLAIN SELECT * FROM emp ORDER BY age,salary;
上面出现的不能使用索引的原因是select *
-- Using index
EXPLAIN SELECT id FROM emp ORDER BY age;-- Using index
EXPLAIN SELECT id,age FROM emp ORDER BY age;-- Using index
EXPLAIN SELECT id,age,salary FROM emp ORDER BY age;-- Using filesort
EXPLAIN SELECT id,age,salary,name FROM emp ORDER BY age;-- Using index; Using filesort
EXPLAIN SELECT id,age FROM emp ORDER BY age ASC ,salary DESC;-- Backward index scan; Using index
EXPLAIN SELECT id,age FROM emp ORDER BY age DESC ,salary DESC;-- Using index; Using filesort
EXPLAIN SELECT id,age FROM emp ORDER BY salary,age;order by后面的排序的字段尽量和索引的顺序是一致的。
可以适当的提高排序的缓存的空间大小。
show variables like 'max_length_for_sort_data'; -- 4096
show variables like 'sort_buffer_size'; -- 262144
上面的值越大越优先选择一次扫描。
16.优化子查询
连接查询比子查询效率更高一点。尽量不采用临时表的形式进行查询。
17.优化limit
数据量越大需要的数据越少,消耗的性能越大,查询900010的10条数据,前面900000排序号的数据被舍弃了,导致了性能的损耗。
优化的方式
-
可以对索引列进行排序,在这个基础上进行limit。可以跟原先的表进行关联查询。
explain select * from tb_user limit 900000,10; -- 0.684 速度是比较慢的explain select * from tb_user a, (select id from tb_user order by id limit 900000,10) b where a.id = b.id; -- 0.486 速度是比较快的。用到了id索引列然后进行了关联查询
- 转换成某个id的查询
采用下面的方式也是可以的
explain select * from tb_user where id > 900000 limit 10;