ElasticSearch集群
1、相关概念
1. 单节点故障问题
单台服务器,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用。单点的elasticsearch也是一样,那单点的es服务器存在哪些可能出现的问题呢?
单台机器存储容量有限
单服务器容易出现单点故障,无法实现高可用
单服务的并发处理能力有限
所以,为了应对这些问题,我们需要对elasticsearch搭建集群
集群中节点数量没有限制,大于等于2个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是3个以上。
2. 集群的相关概念
1) 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
2) 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于ElasticSearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
3) 分片和复制 shards&replicas
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,ElasticSearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由ElasticSearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,ElasticSearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片( 副本)。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
2、【集群搭建】
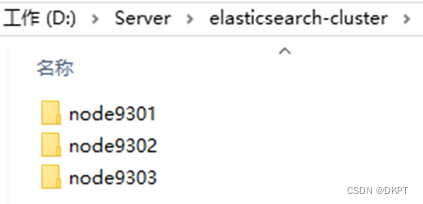
1. 准备三台elasticsearch服务器
创建elasticsearch-cluster文件夹,在内部复制三个elasticsearch服务
2. 修改每台服务器配置
修改elasticsearch-cluster\node*\config\elasticsearch.yml配置文件
1) node1节点:
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
2) node2节点:
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
3) node3节点:
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
3. 启动各个节点服务器
先清理掉之前数据:删除elasticsearch-cluster\node*\data目录下的nodes目录
双击elasticsearch-cluster\node*\bin\elasticsearch.bat
-
启动节点1:
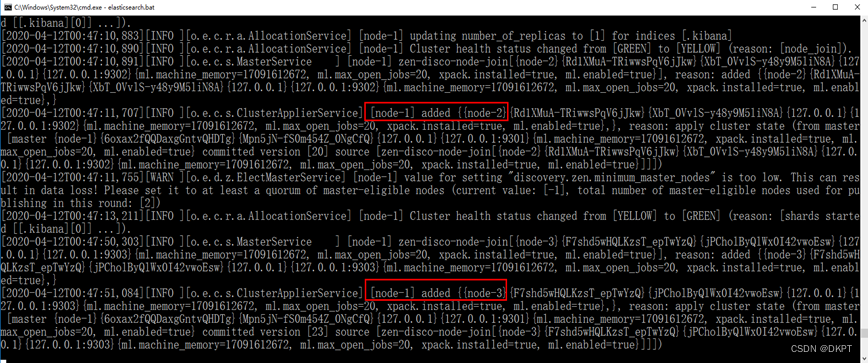
-
启动节点2:
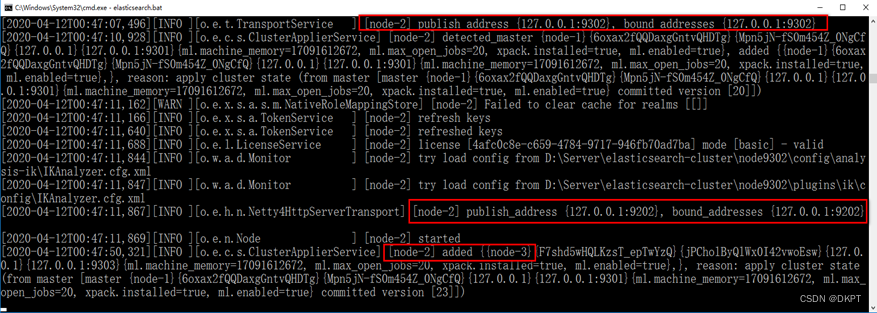
-
启动节点3:
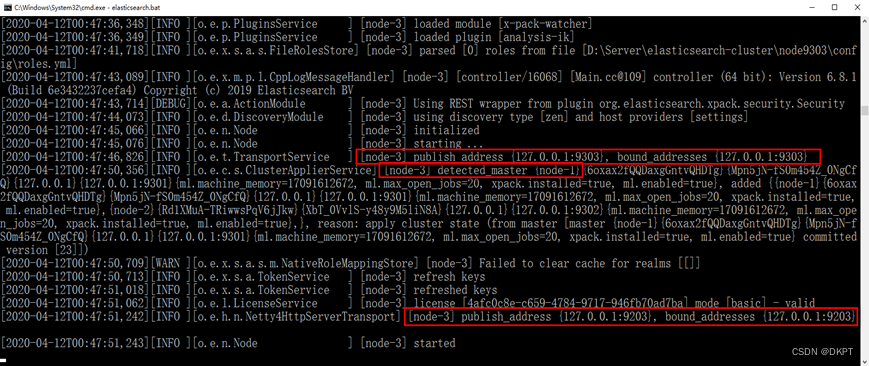
3、【集群测试】
1. 安装ES插件ElasticSearch-head
在Chrome浏览器地址栏中输入:chrome://extensions/,或按照下图打开“扩展程序”
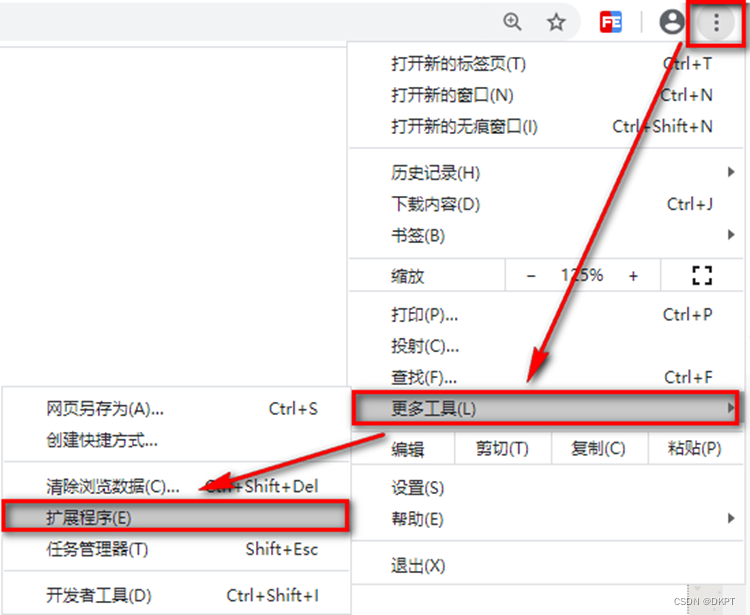
将【ElasticSearch-head-Chrome-0.1.5-Crx4Chrome.crx】文件拖到扩展程序页面上即可。
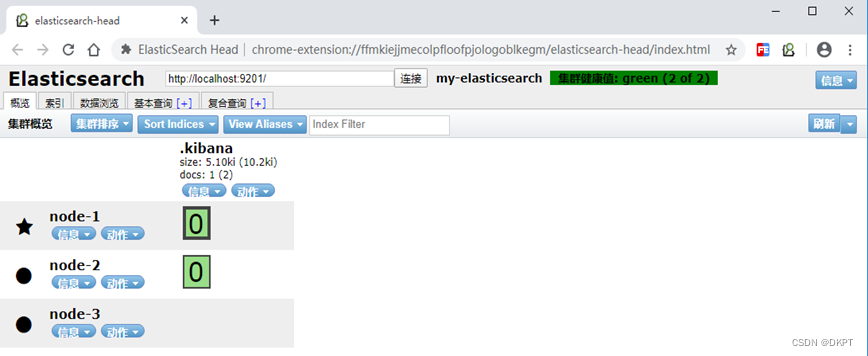
2. 使用elasticsearch-head查看集群情况
没有创建任何索引前的情况,只有一个默认的索引.kibana
3. 集群测试
创建索引及映射
# 请求方法:PUT
PUT /shopping
{"settings": {},"mappings": {"product":{"properties": {"title":{"type": "text","analyzer": "ik_max_word"},"subtitle":{"type": "text","analyzer": "ik_max_word"},"images":{"type": "keyword","index": false},"price":{"type": "float","index": true}}}}
}
添加文档
POST /shopping/product
{"title":"小米手机","images":"http://www.gulixueyuan.com/xm.jpg","price":3999.00
}
4. 再次使用elasticsearch-head查看集群情况
命令查看:
GET _cluster/health
{"cluster_name" : "my-elasticsearch","status" : "green","timed_out" : false,"number_of_nodes" : 3,"number_of_data_nodes" : 3,"active_primary_shards" : 6,"active_shards" : 12,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}
Elasticsearch-head查看:
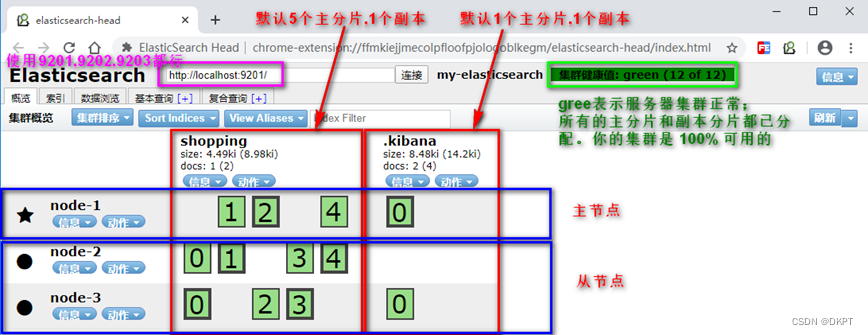
服务器运行状态:
Green
所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow
所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red
至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。