输出
我们会遇到不同的任务,针对输出的不一样,我们对任务进行划分
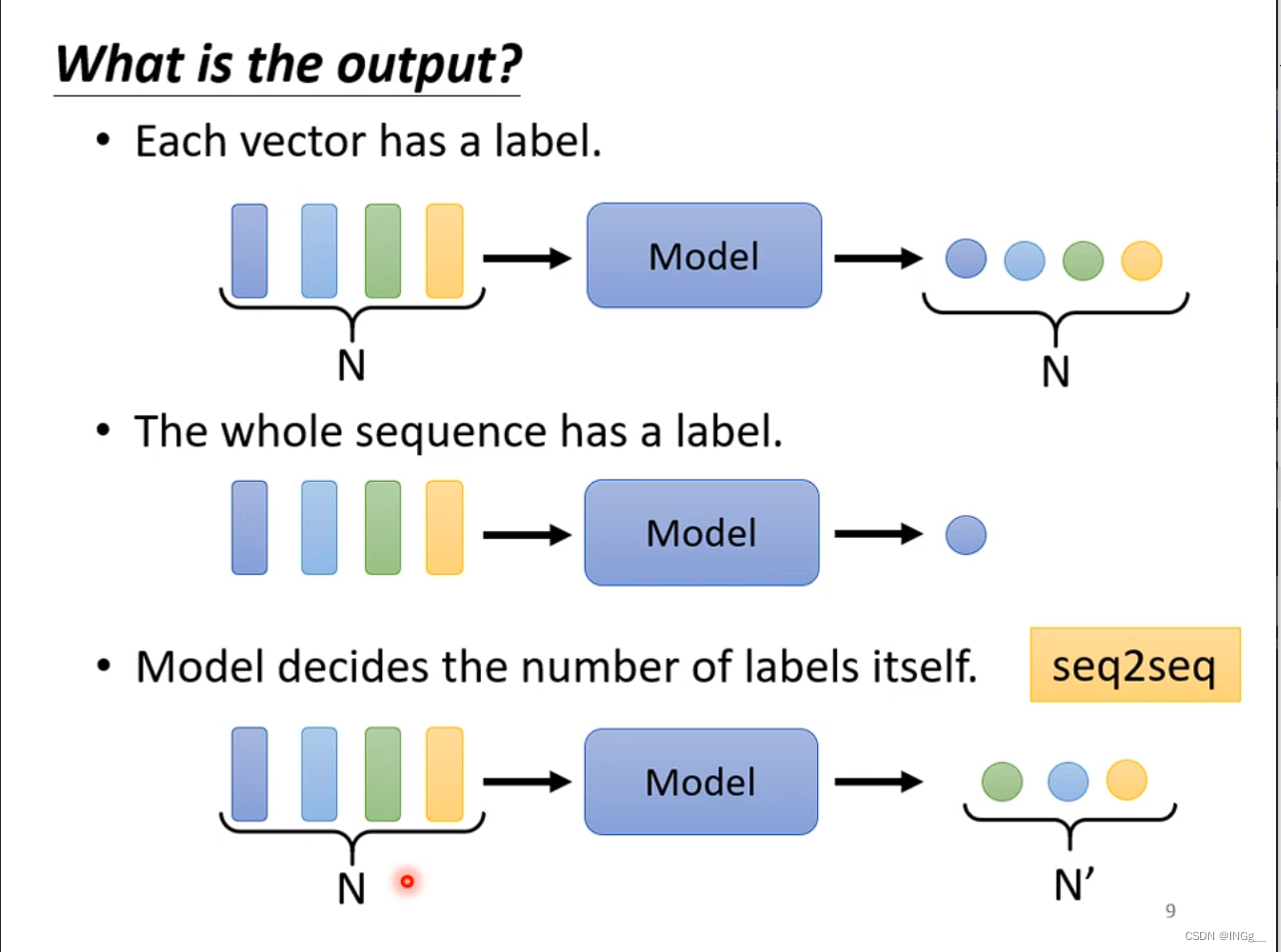
给多少输出多少
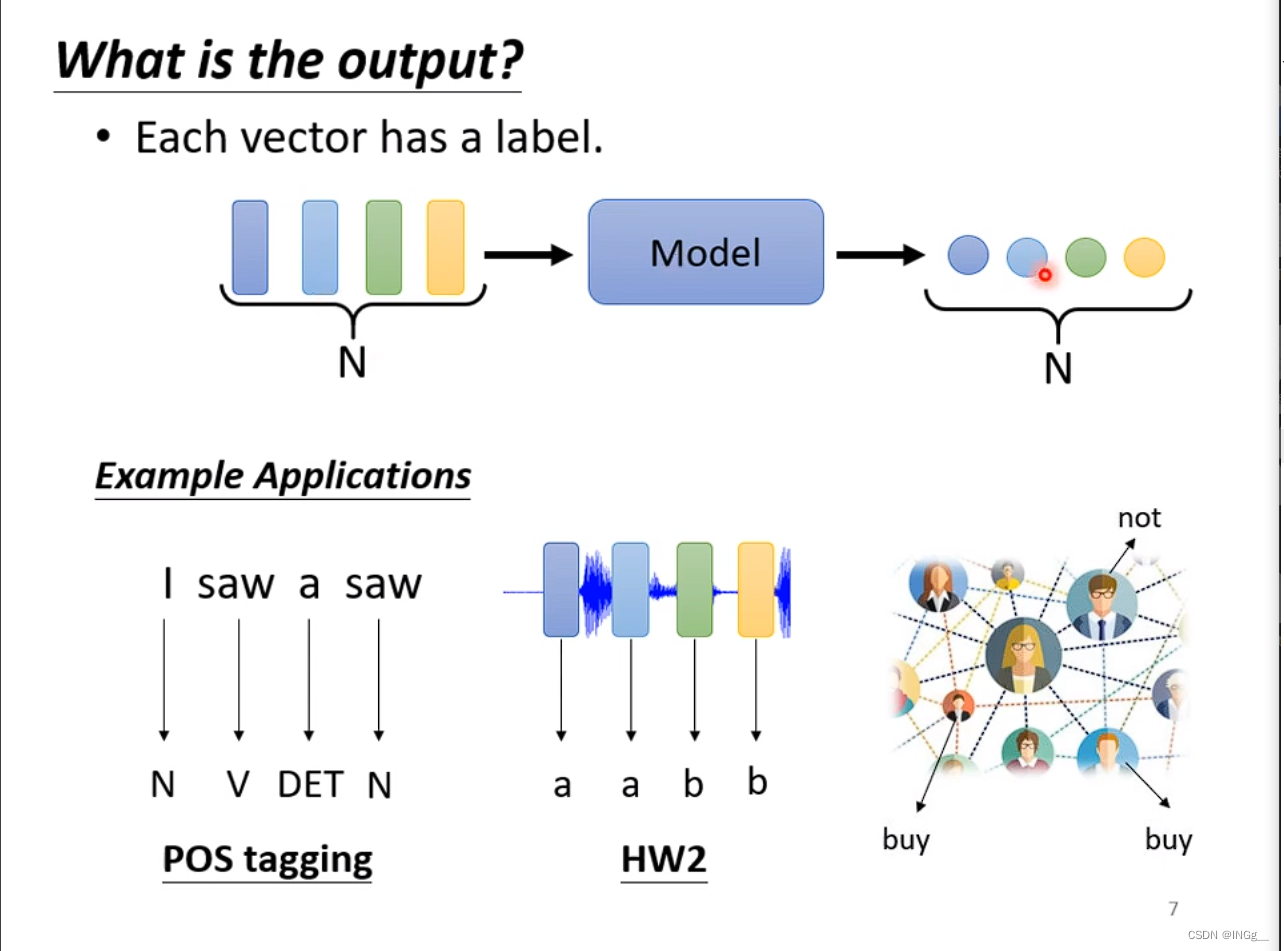
给一堆向量,输出一个label,比如说情感分析
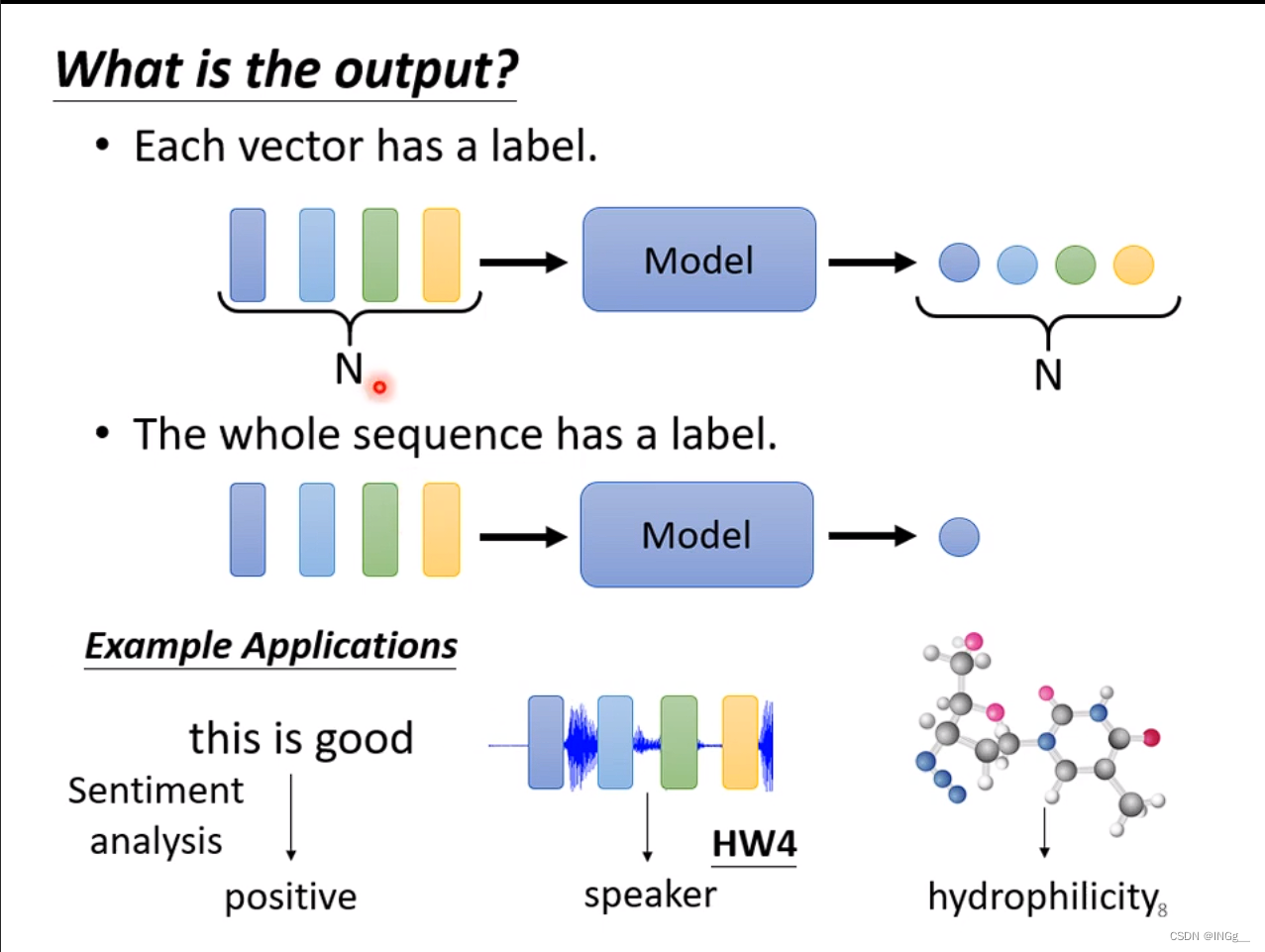
还有一种任务是由机器决定的要输出多少个label,seq2seq的任务就是这种,翻译也是
Sequence Labeling
如果要考虑时序信息,每次可以选取前后固定长度的信息输入到fc层,但是运算量很大需要的参数也很多
新的方法能考虑整个input sequence
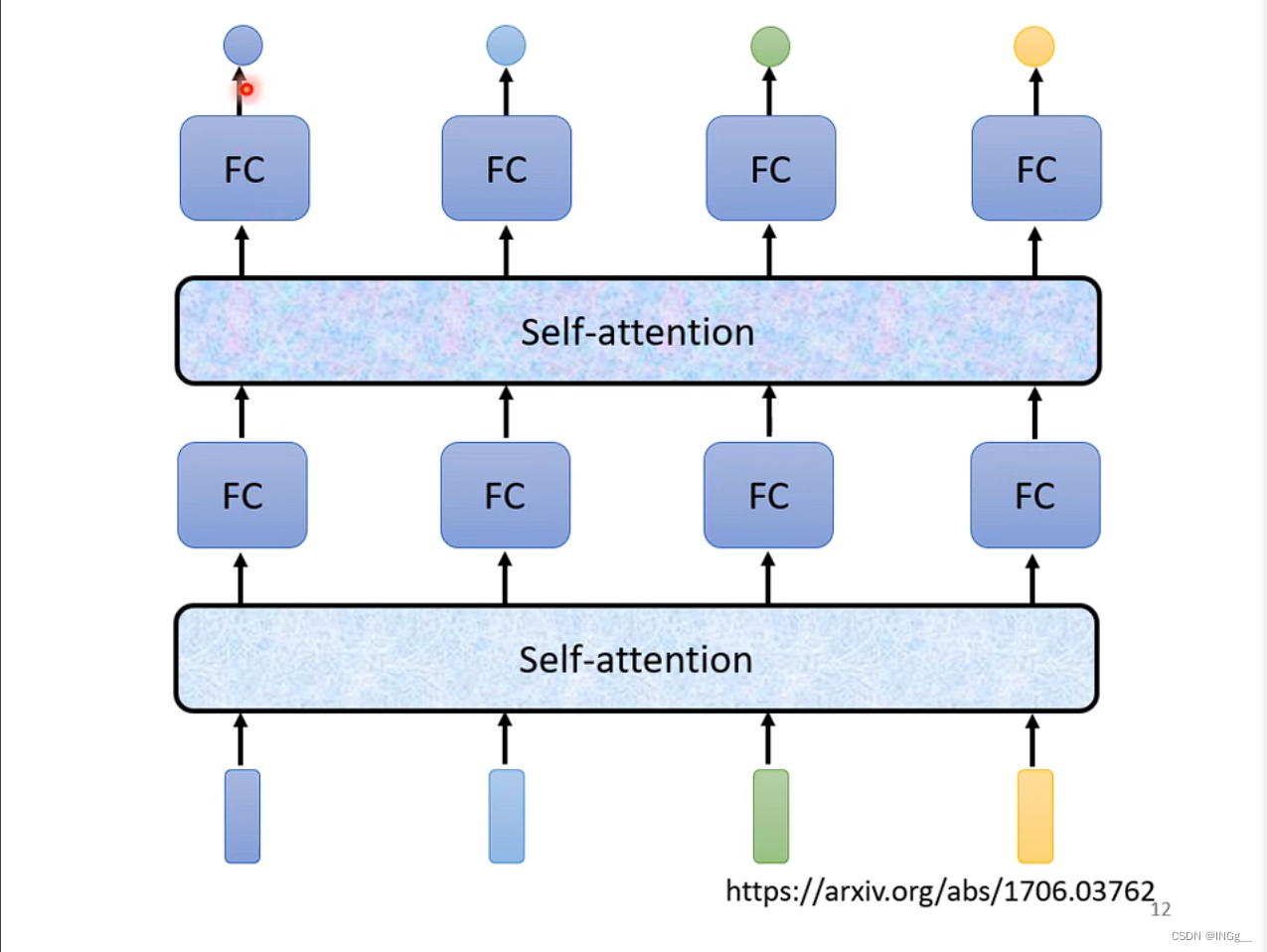
fc专注处理某一个位置的信息,self-attention来考虑整个sequence的信息
模型细节
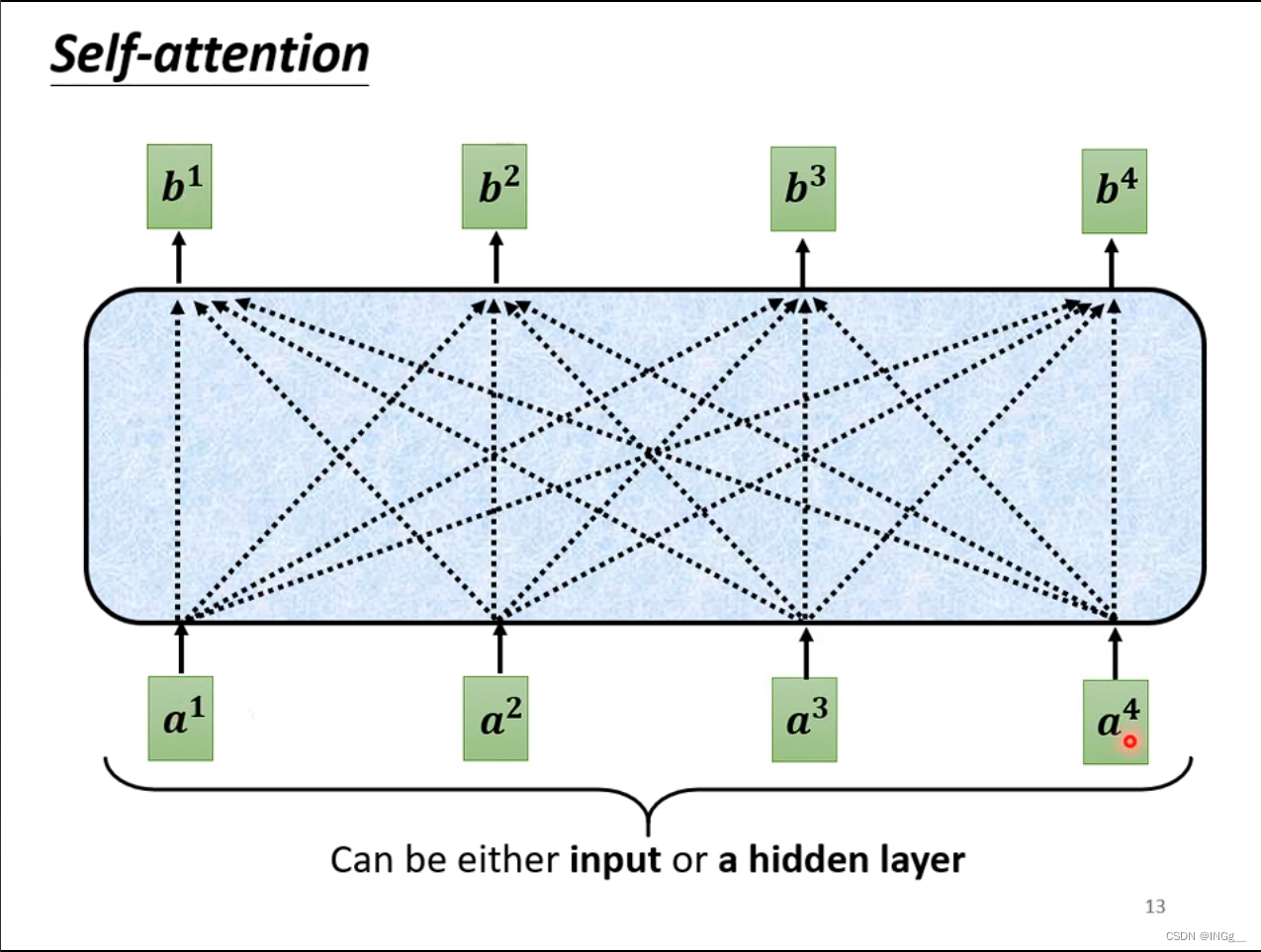
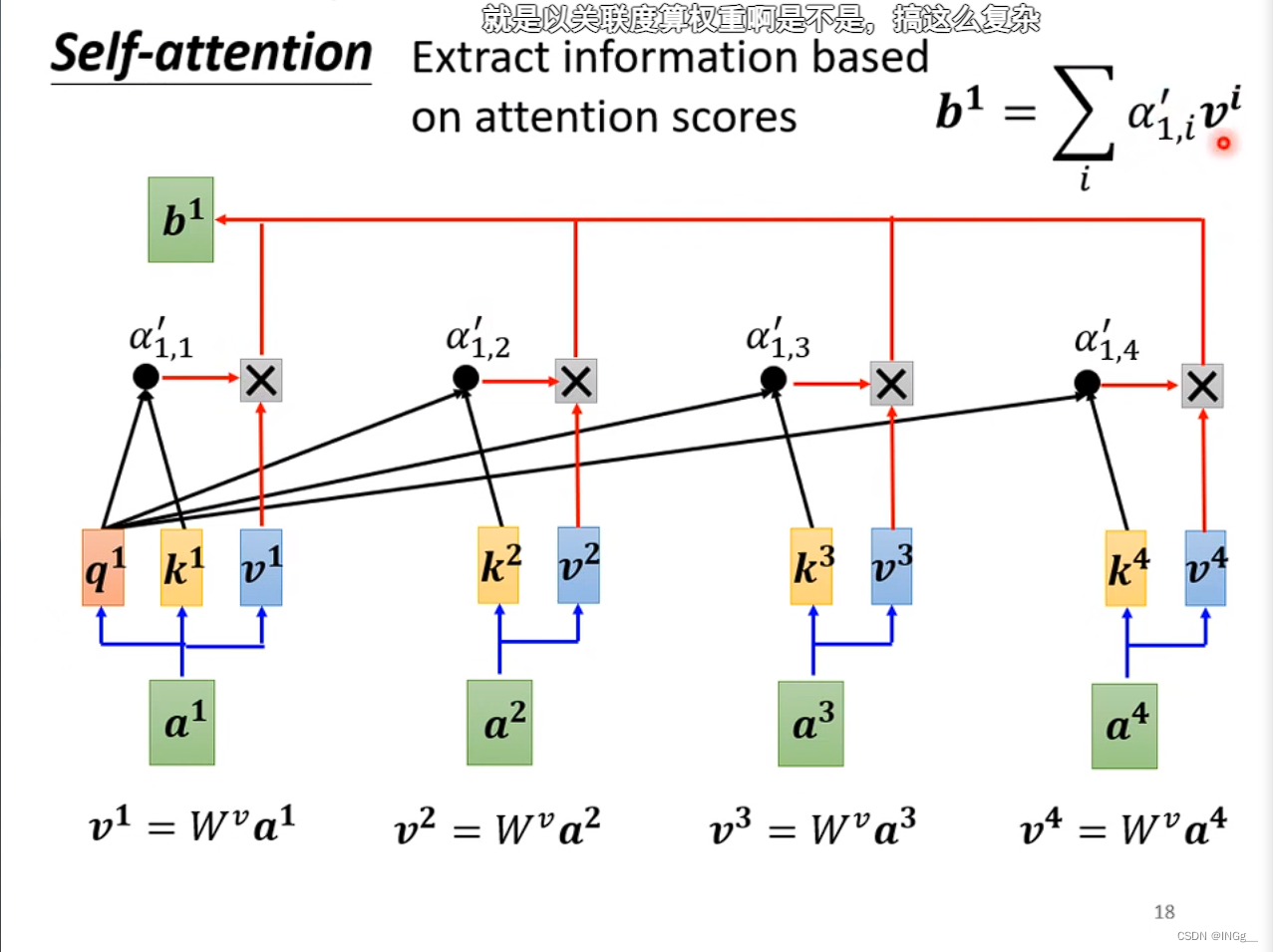
每个b都是考虑整个sequence来产生的
那么是如何产生的?
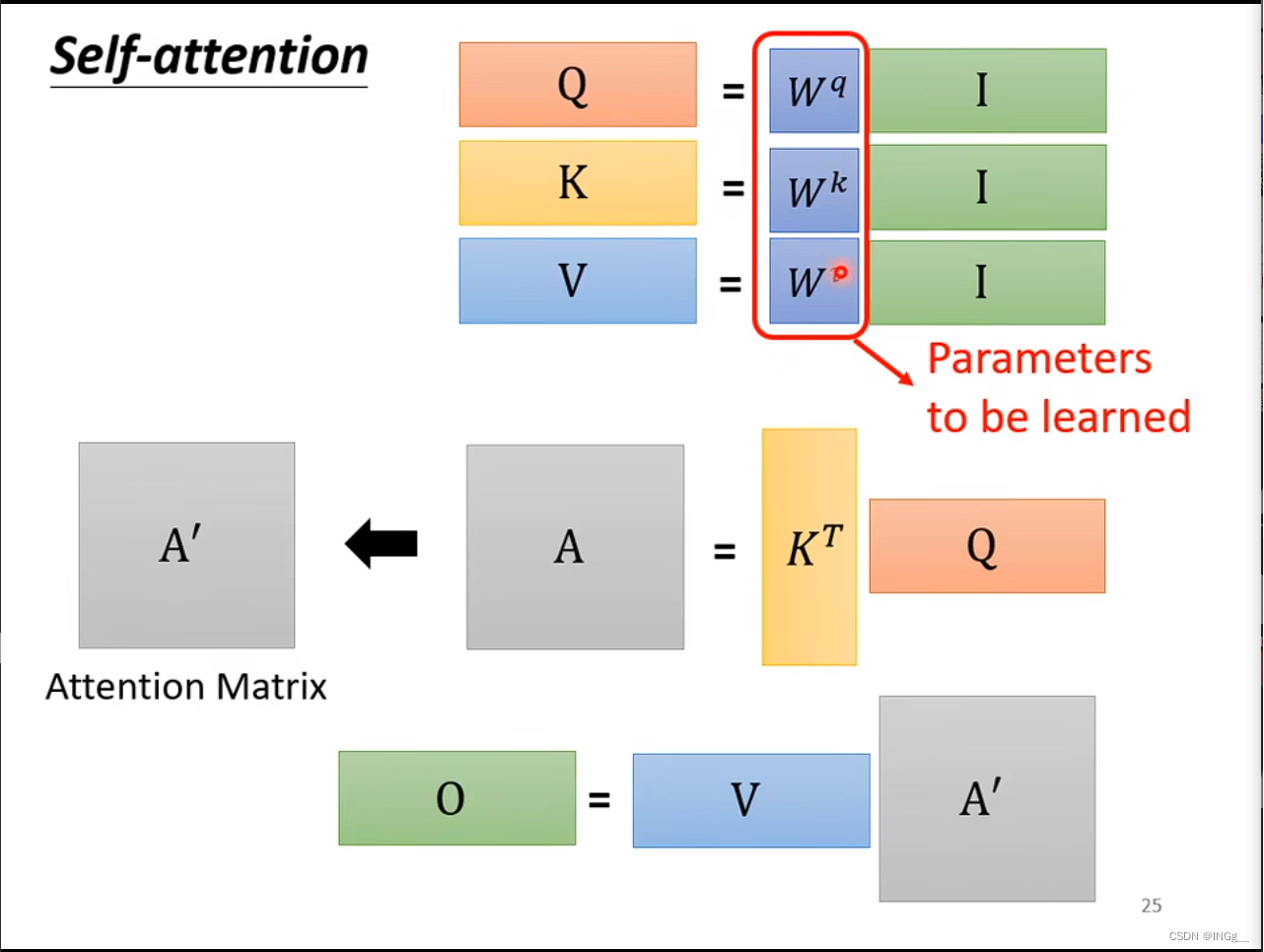
我们需要找到一些相关的向量来帮助决定 a 1 a^1 a1,用 α \alpha α来表示相关的重要性
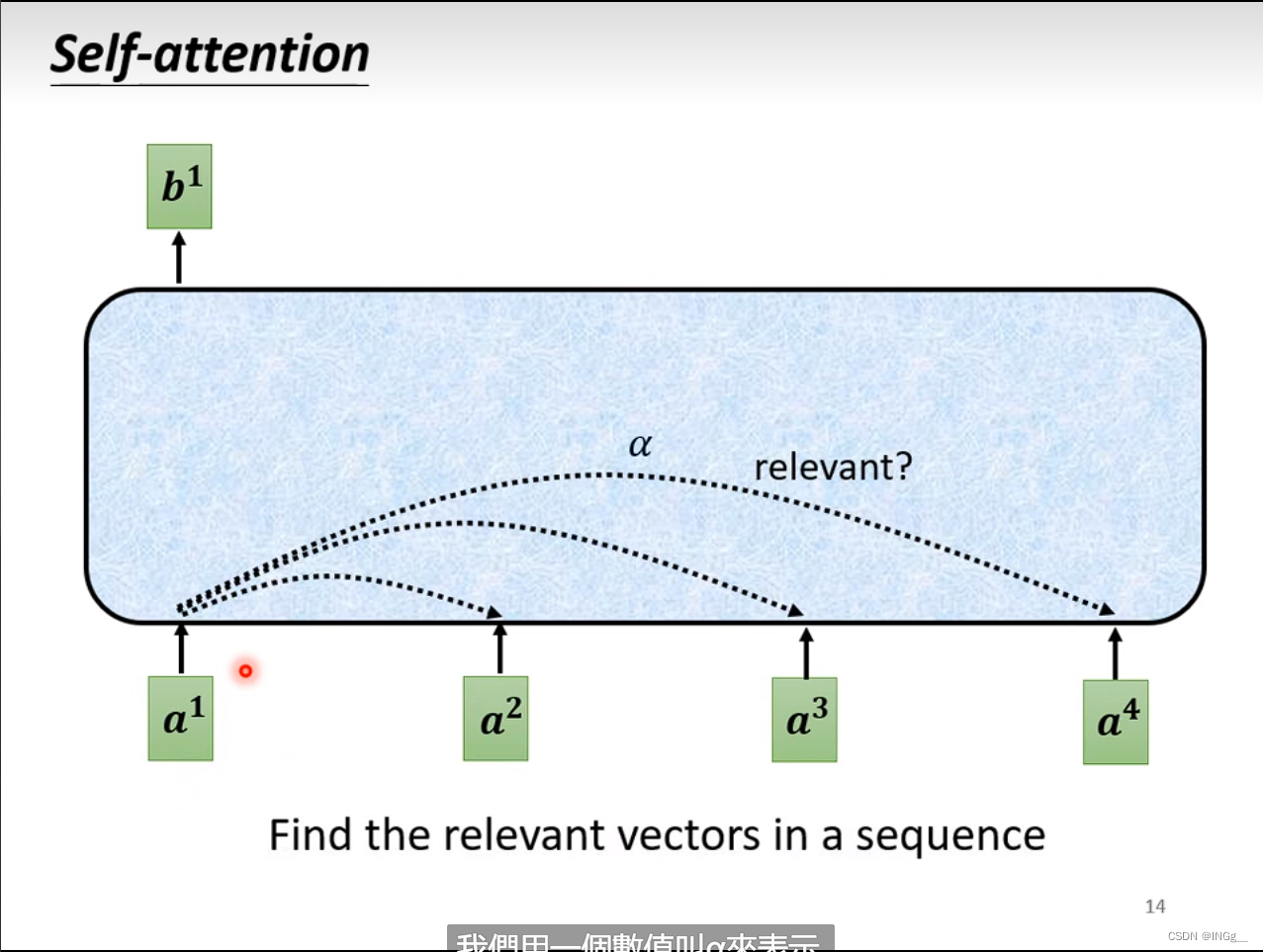
那么怎么决定 α \alpha α呢,有两种方式
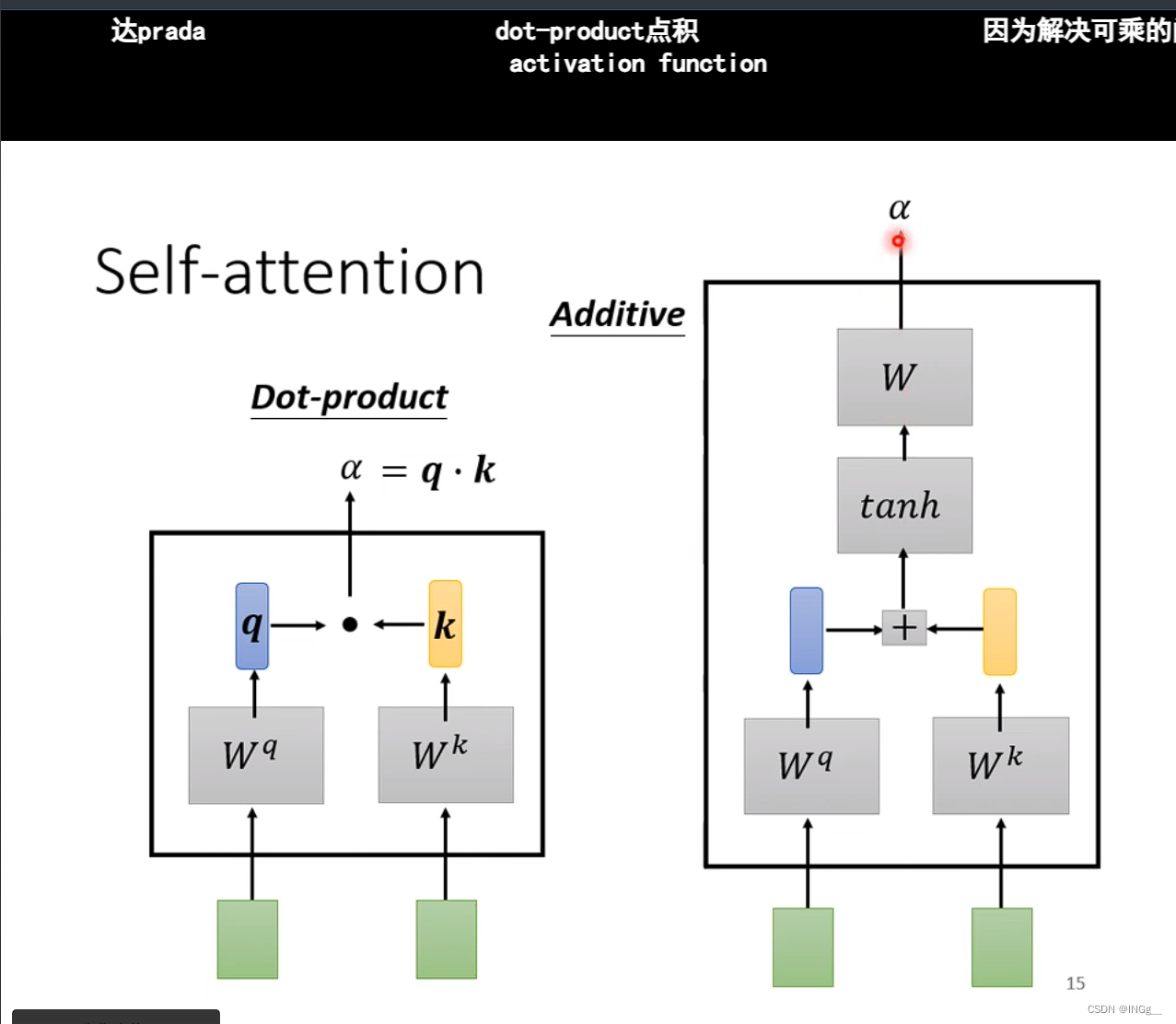
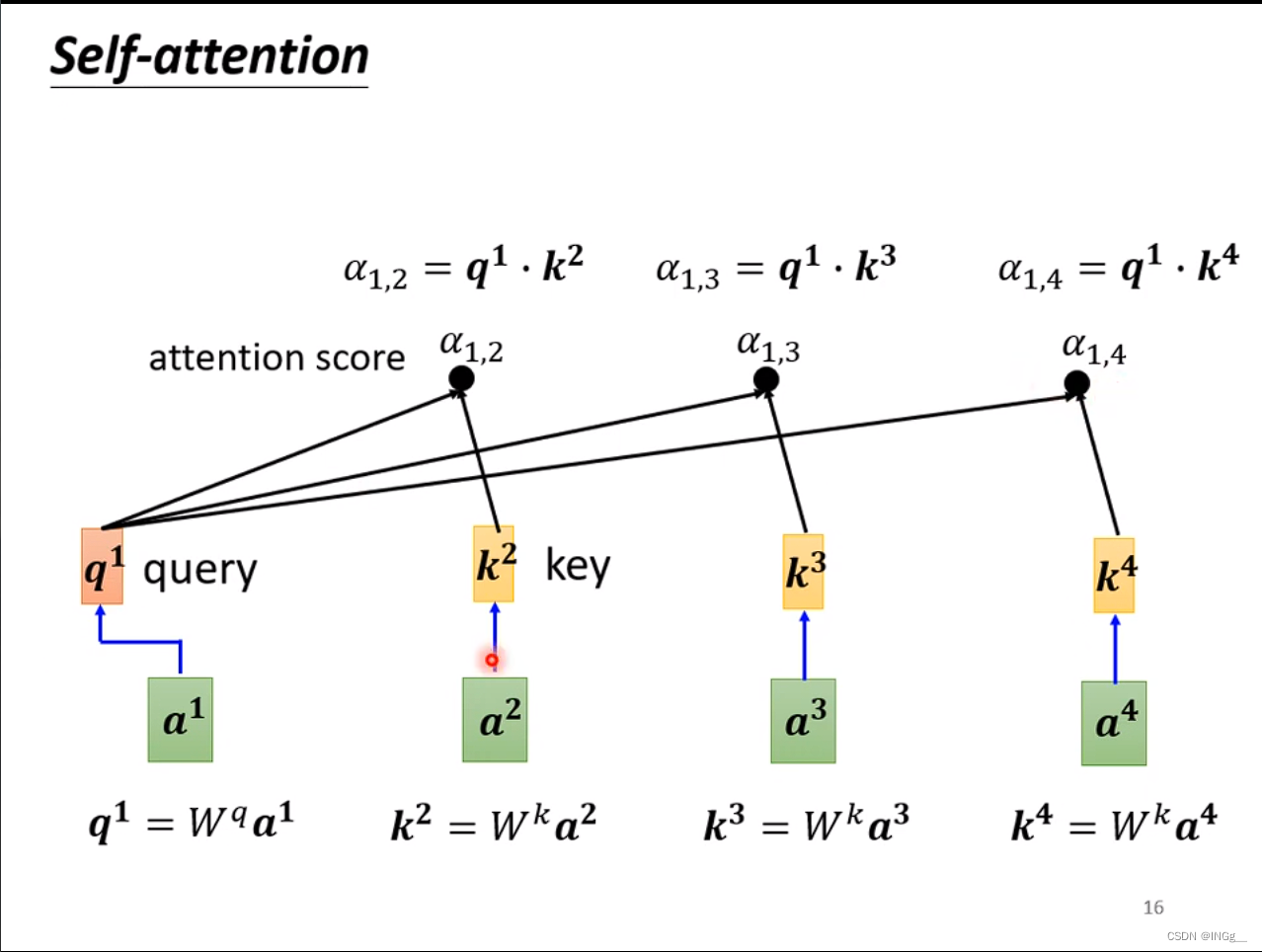
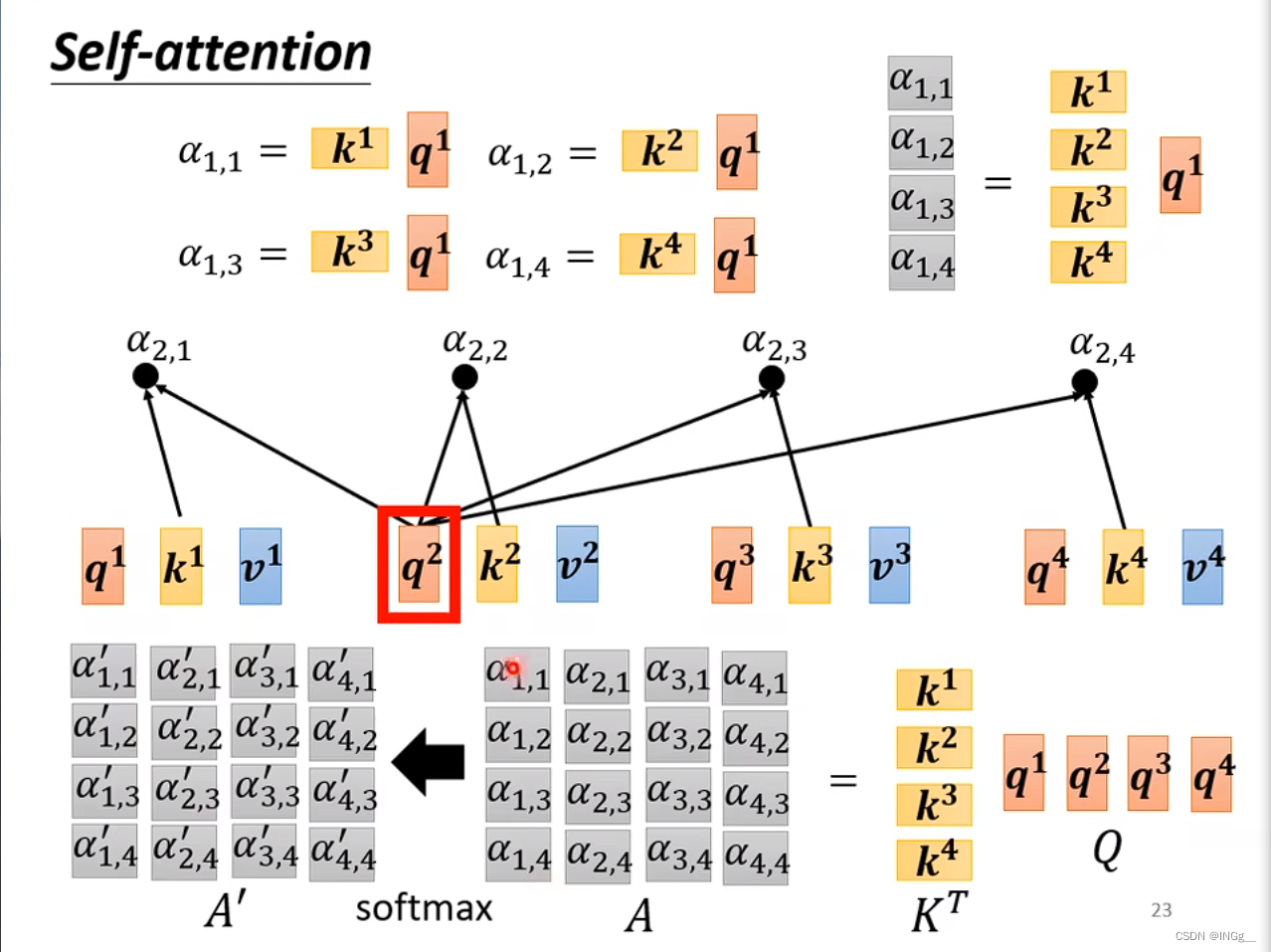
用 a 1 a^1 a1分别与其他的向量分别进行计算相关性
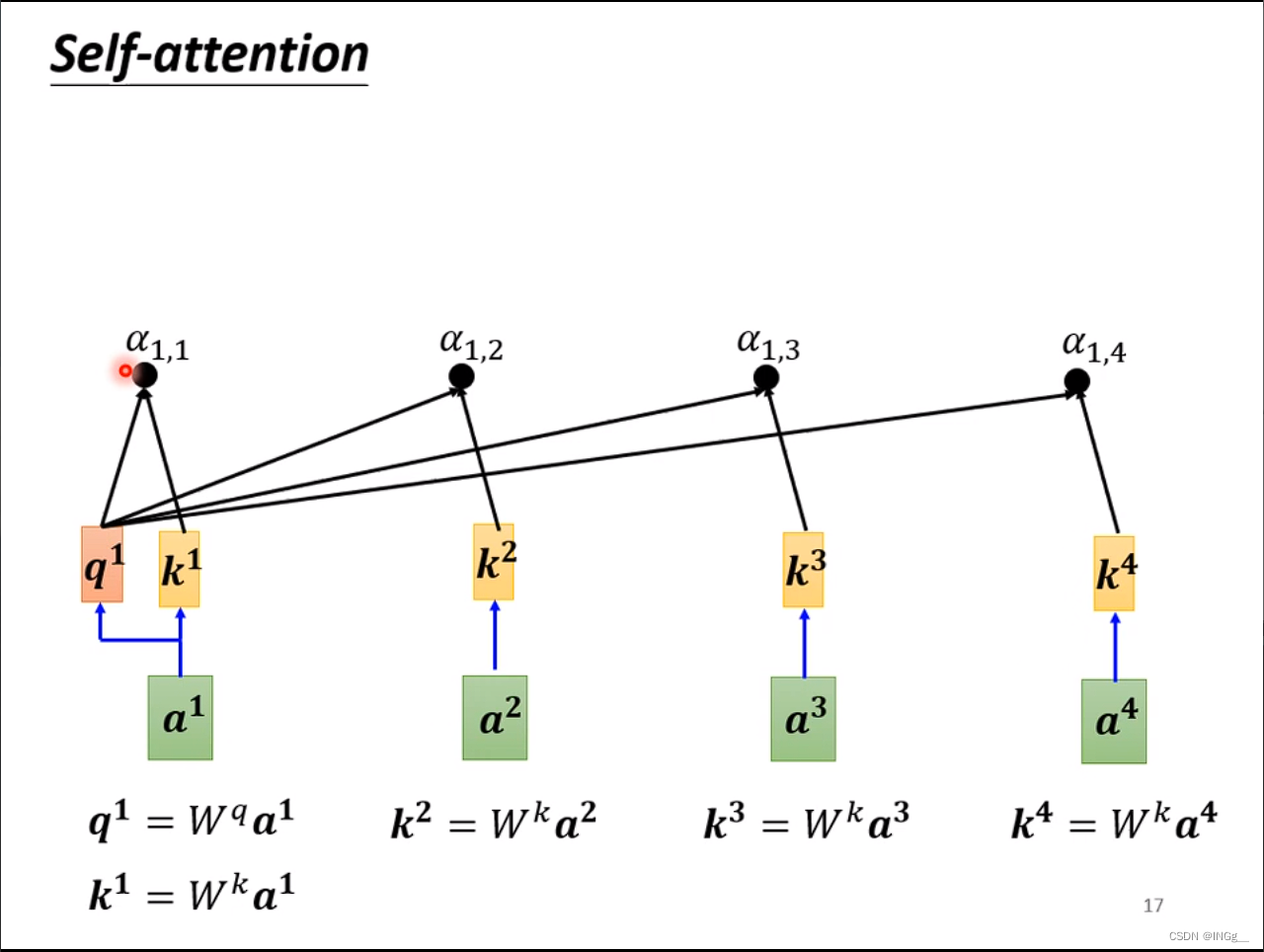
一般而言,也会跟自己计算相关性
然后接一个softmax
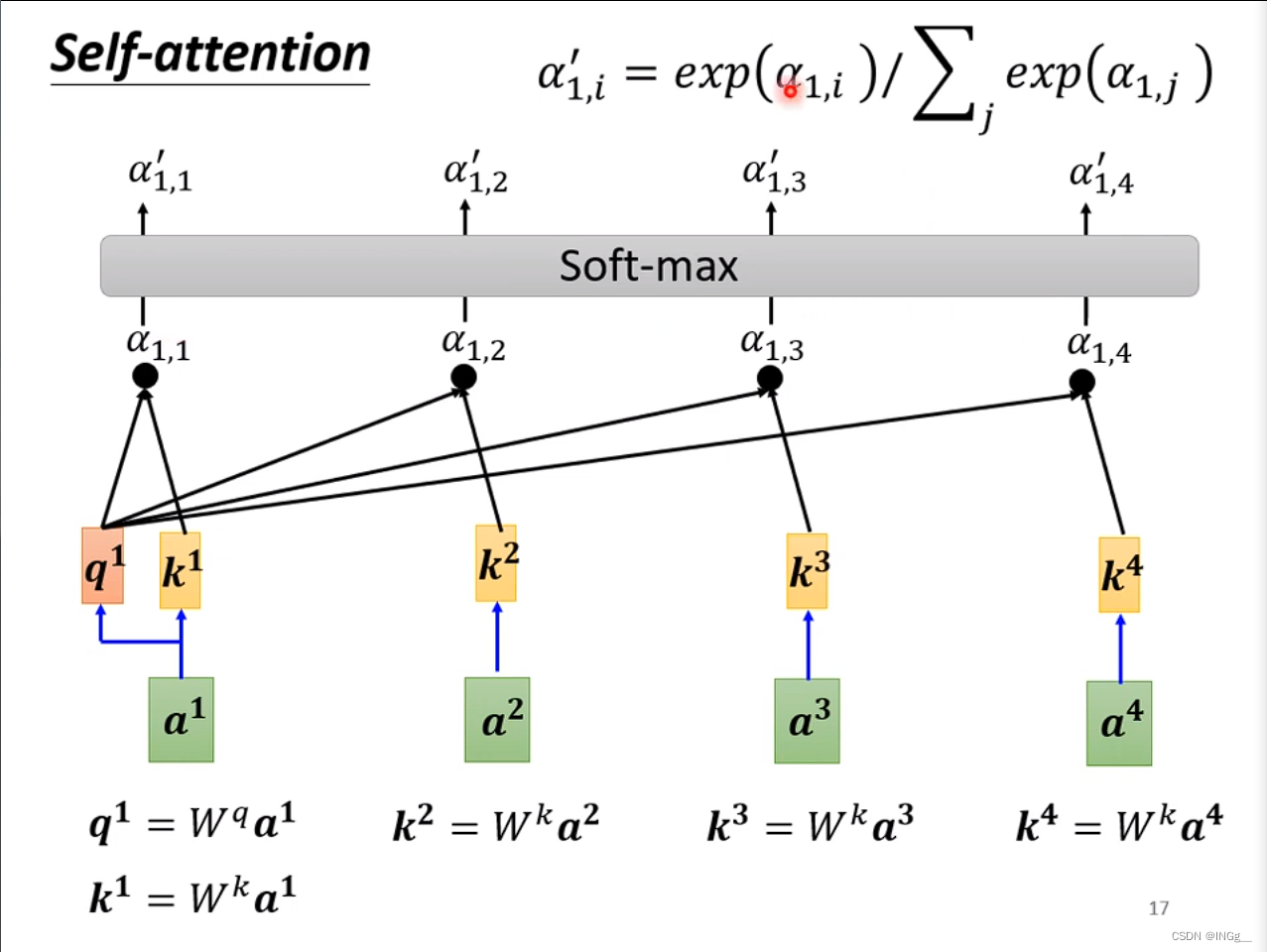
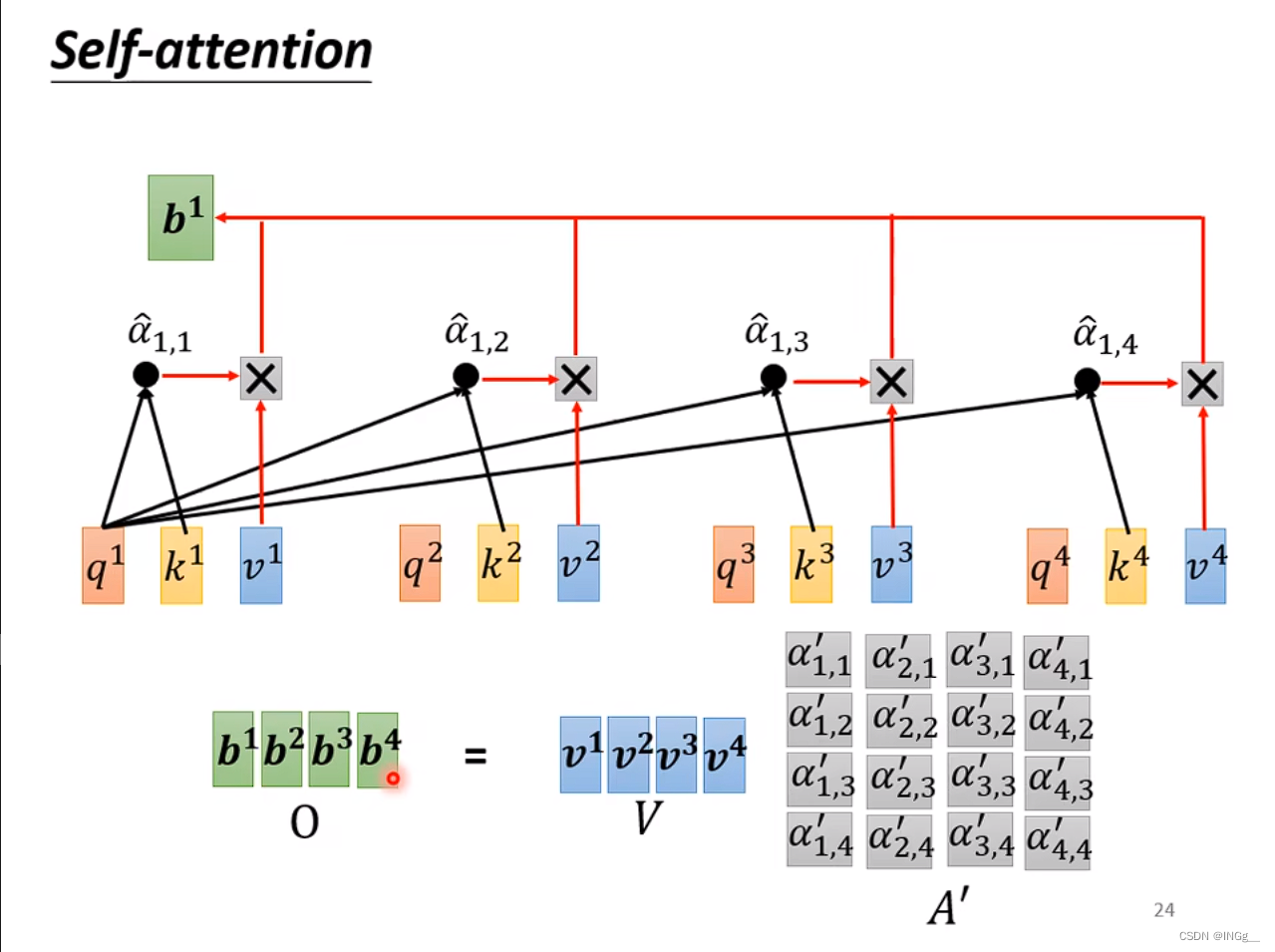
根据attention的分数,也就是计算出来的每一个 α \alpha α值来抽取重要的信息
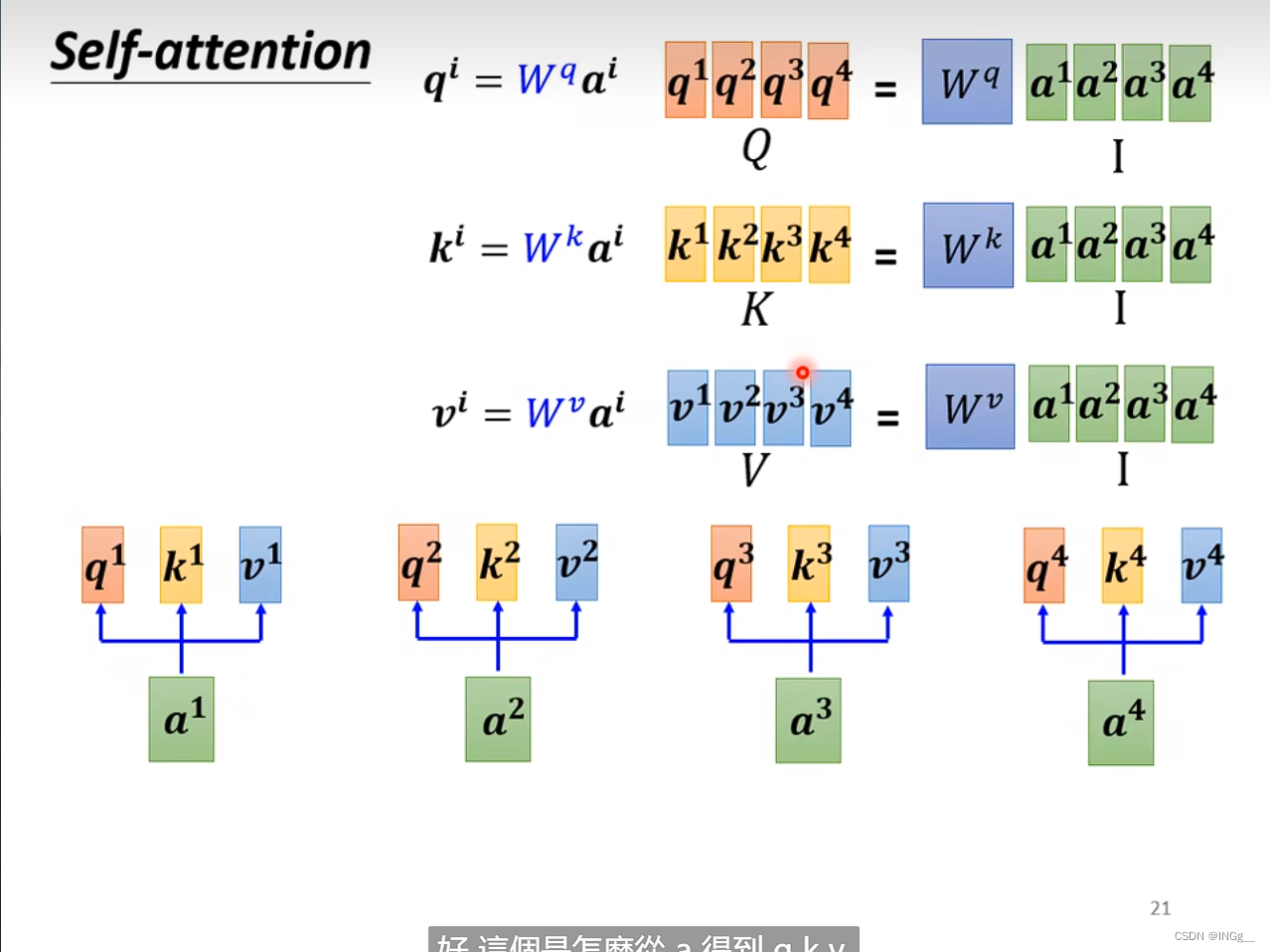
转换为矩阵运算形式:
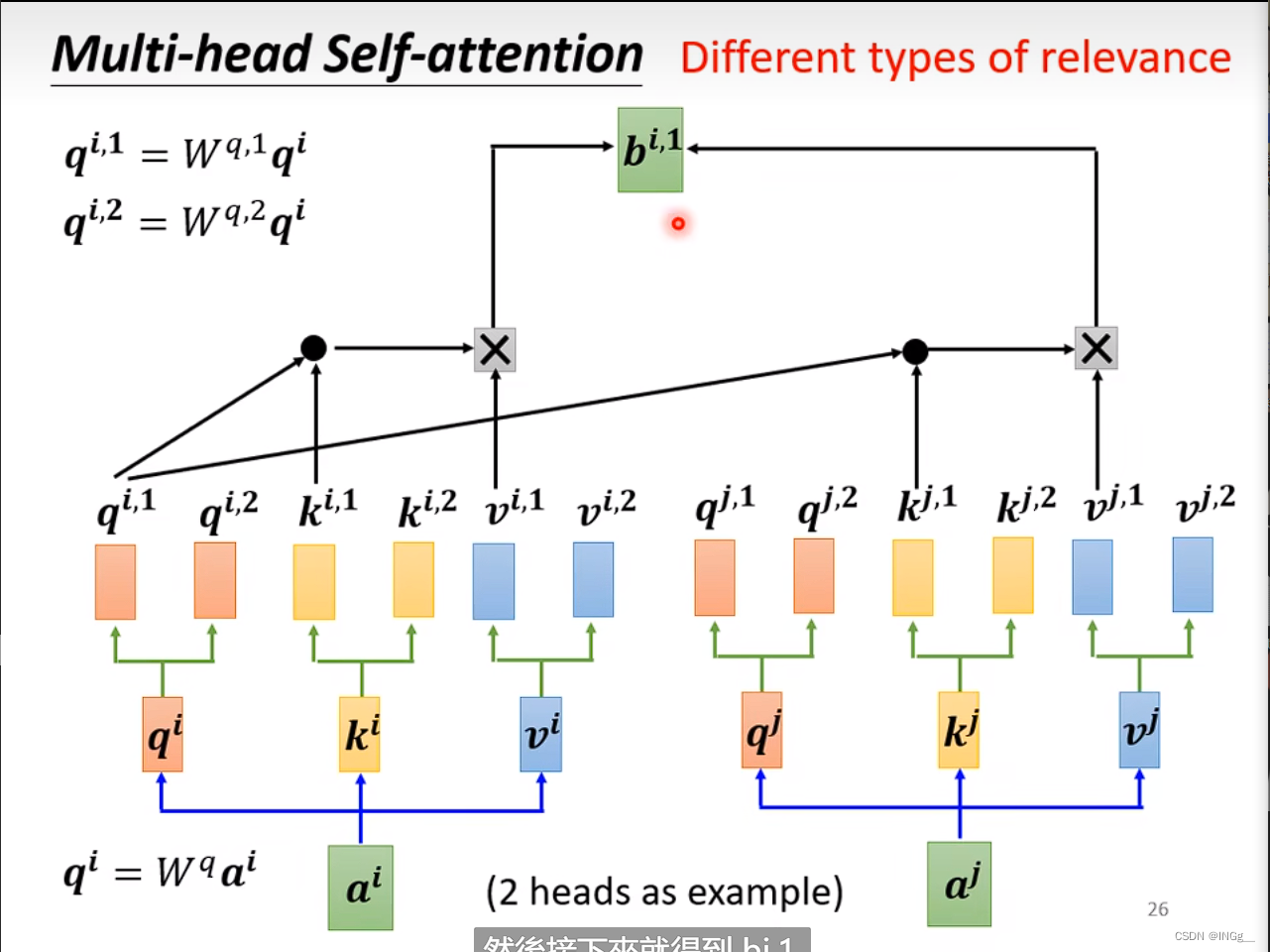
多头注意力
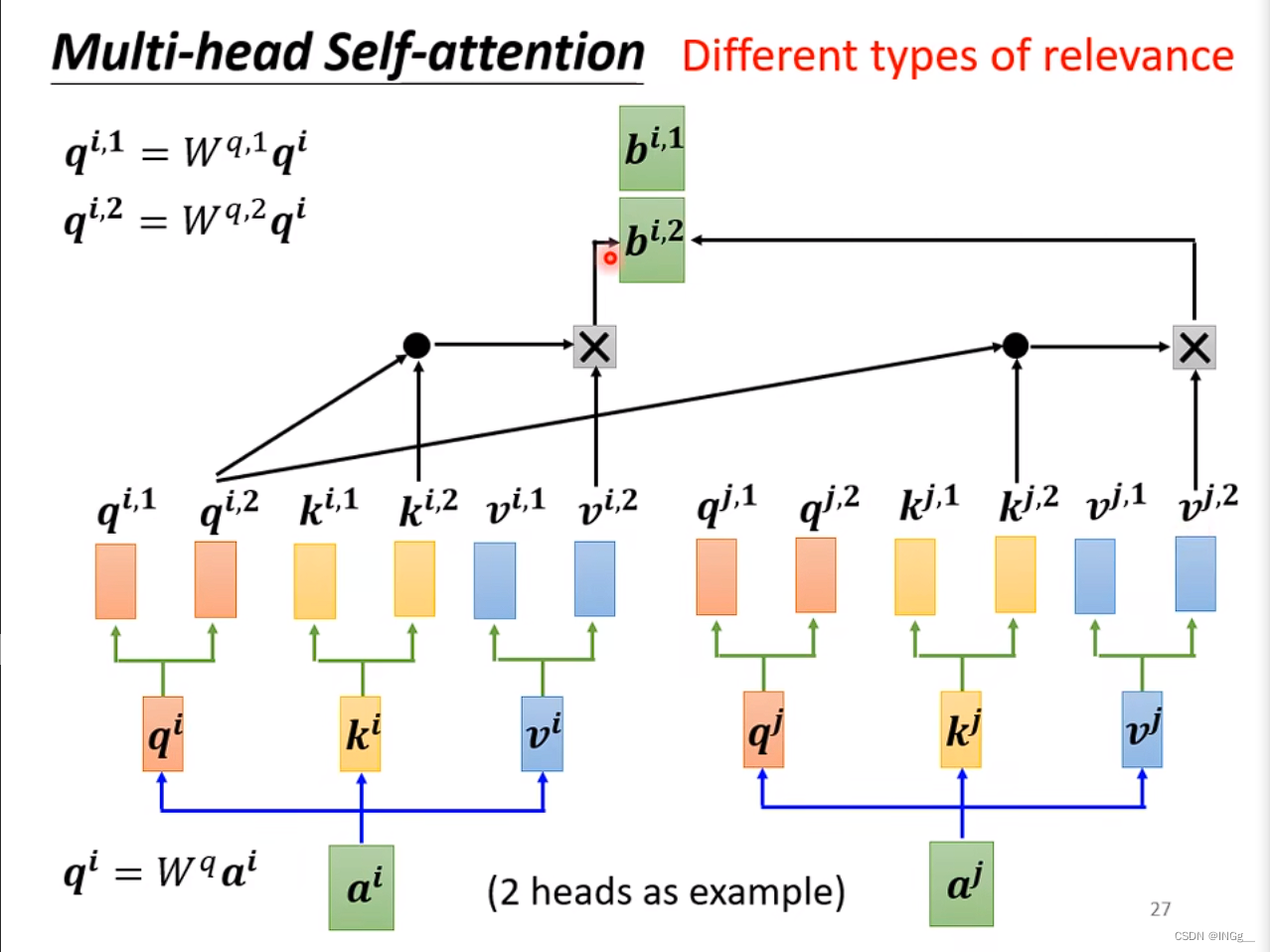
多头注意力是自注意力的一个进阶的版本
多头注意力的关键在于Q是有不同的多个进行询问的,这样带来的好处与卷积也比较类似,我们采用不同的Q来负责不同种类的相关性
计算方式上,与自注意力机制比较类似,每个计算过程中 只关注对应的(比如计算1的时候只把1拿出来)
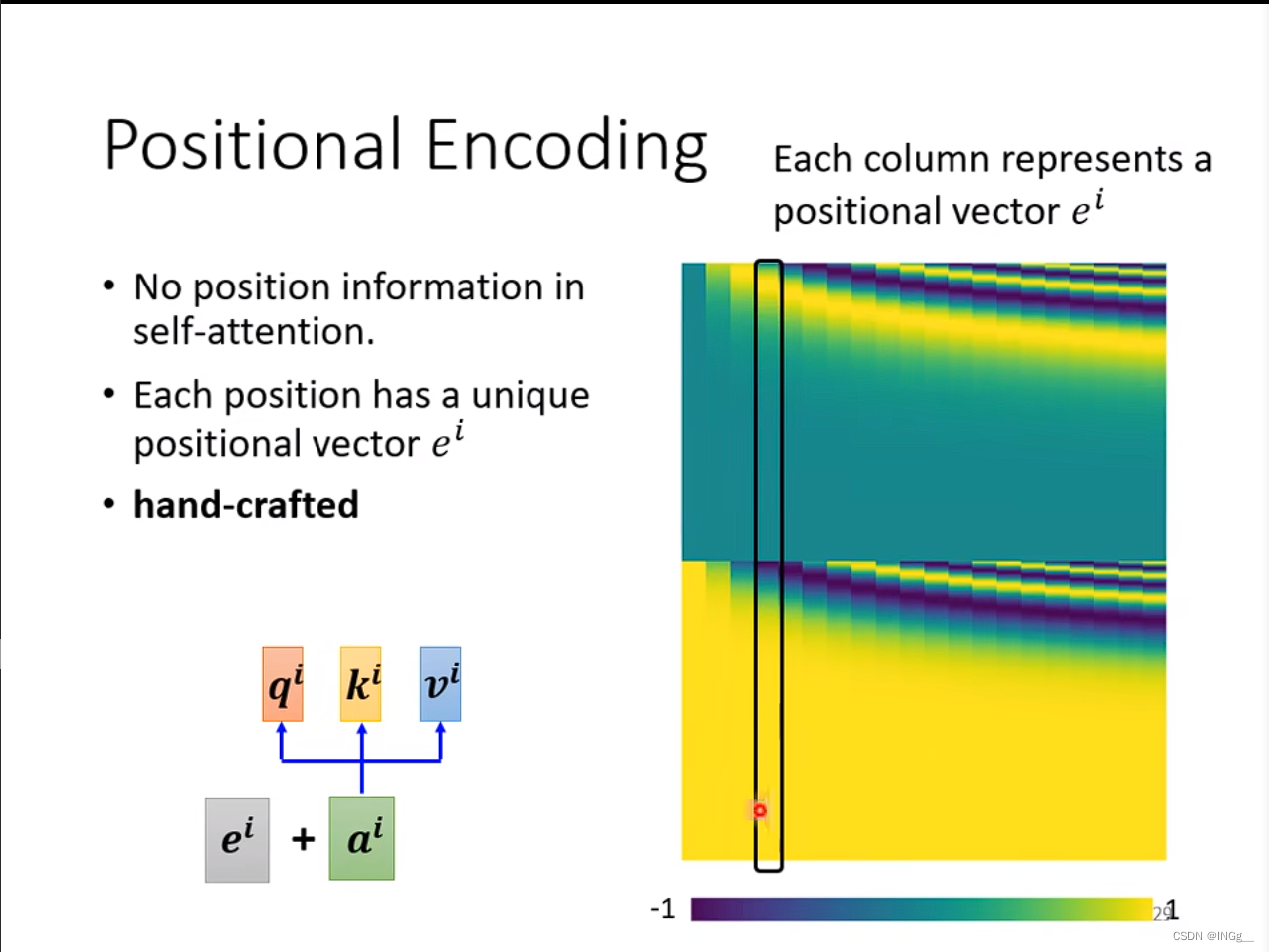
位置编码
有时位置的距离也比较重要,我们需要存储位置的信息
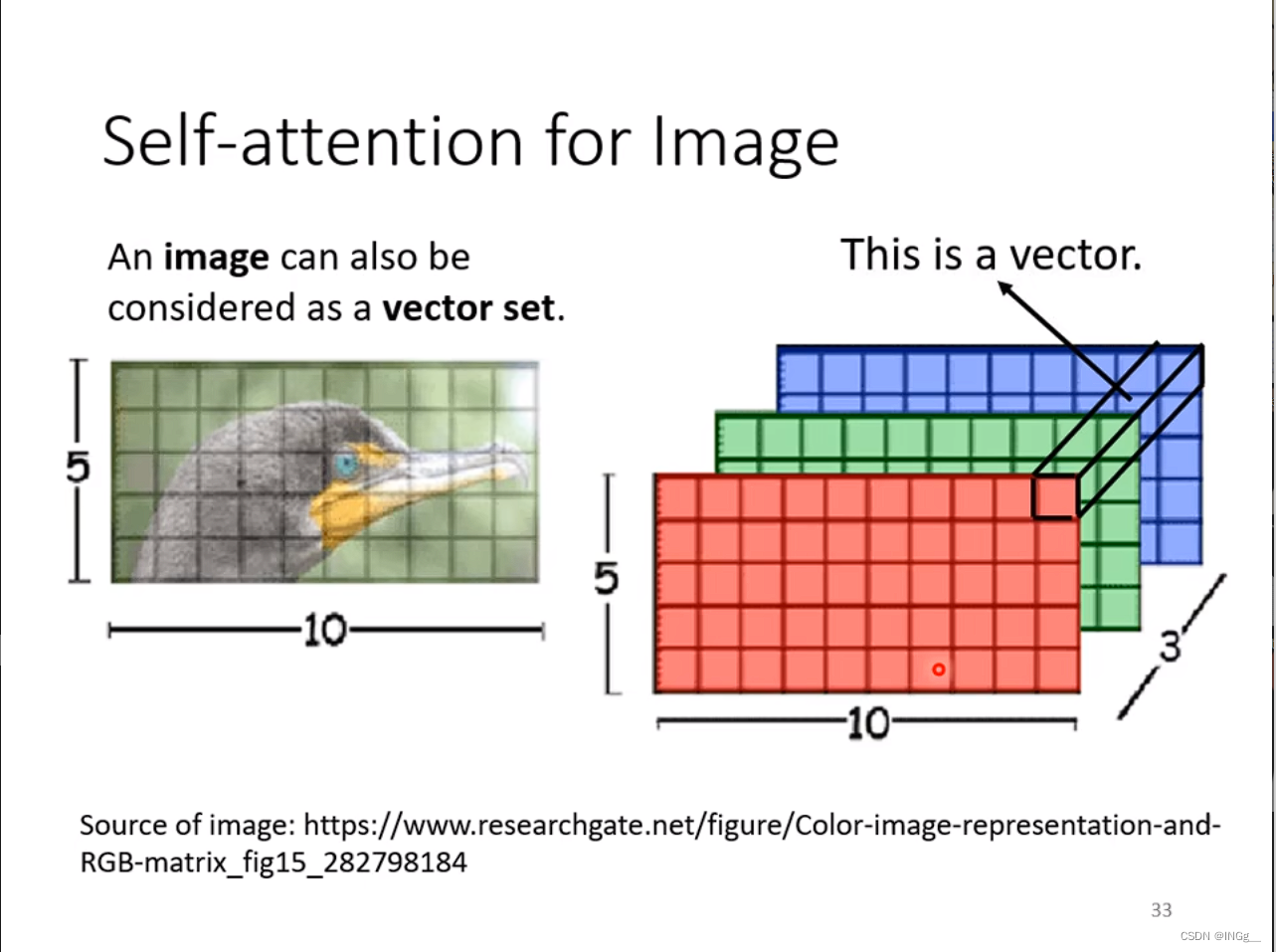
For Image
横着来看做一个vector,众多vector作为输入,输入进model