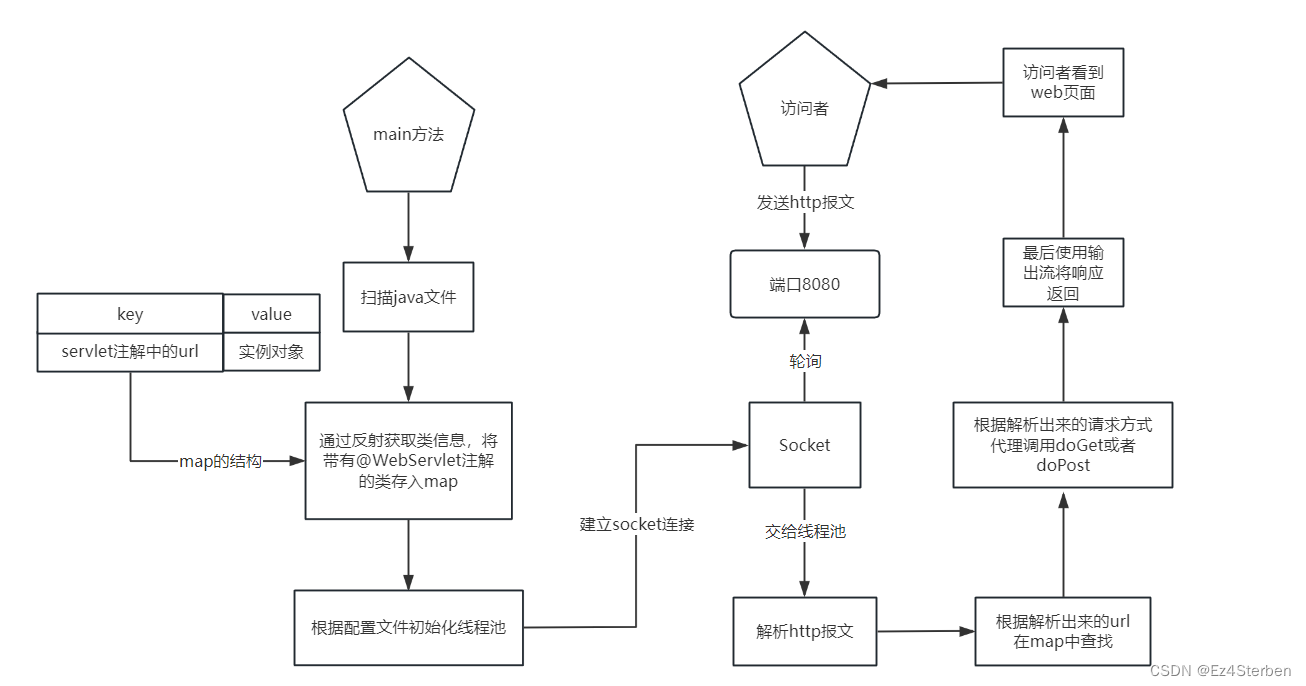
Hey!作为一名专业的爬虫代理供应商,我今天要和大家分享一些关于爬虫异常捕获与处理的方法。在进行爬虫操作时,我们经常会遇到各种异常情况,例如网络连接错误、请求超时、数据解析错误等等。这些异常情况可能会导致程序崩溃或数据丢失,因此,我们需要学会如何捕获和处理这些异常,保证爬虫的稳定性和可靠性。
1.使用try-except块捕获异常
在编写爬虫代码时,我们可以使用try-except块来捕获并处理异常。try块中包含可能引发异常的代码,而except块用于处理捕获到的异常。通过使用try-except块,我们可以预先处理一些常见的异常情况,减少程序的崩溃。
例如,以下是一个示例代码,展示了如何使用try-except块来捕获和处理请求超时的异常:
```python
import requests
try:
response=requests.get(‘http://www.example.com’,timeout=10)
#处理返回的数据…
except requests.Timeout:
print(“请求超时”)
#处理超时情况的逻辑…
except requests.RequestException as e:
print(“请求异常:”,e)
#处理其他异常的逻辑…
```
在这个示例中,我们通过使用try-except块,捕获了可能发生的请求超时异常。如果发生了请求超时异常,我们可以在except块中执行相应的处理逻辑,例如打印错误信息或进行重试操作。
2.记录日志并发送通知
除了捕获和处理异常,我们还应该记录日志并发送通知,以便及时了解和解决异常情况。通过记录日志,我们可以追踪异常的发生及其原因,从而帮助定位和排除问题。同时,我们也可以设置一个警报系统,当发生异常时,自动发送通知给相关人员。
以下是一个示例代码,展示了如何在Python中使用logging模块记录日志:
```python
import logging
#配置日志
logging.basicConfig(filename=‘spider.log’,level=logging.ERROR)
try:
#爬虫操作…
except Exception as e:
#捕获异常并记录日志
logging.error(“爬虫异常:%s”,e)
```
通过配置logging模块,我们可以将错误信息写入指定的日志文件中。当发生异常时,我们可以轻松地追踪日志文件以了解异常的细节,并及时解决问题。
以上就是我对于爬虫异常捕获与处理方法的说明。希望这些方法能够帮助你提高爬虫的稳定性和可靠性,在遇到异常情况时能够妥善处理。
如果你还有其他疑问或者想分享自己的经验,请在评论区留言,让我们共同学习、探索爬虫的奇妙世界!愿每个爬虫都能稳如磐石,数据源源不断!

![[保研/考研机试] KY124 二叉搜索树 浙江大学复试上机题 C++实现](https://img-blog.csdnimg.cn/597052c09e38465a885e775ff4caafeb.png)