核心概念
要理解协程的实现, 首先需要了解go中的三个非常重要的概念, 它们分别是G, M和P,
没有看过golang源代码的可能会对它们感到陌生, 这三项是协程最主要的组成部分, 它们在golang的源代码中无处不在.
G (goroutine)
G是goroutine的头文字, goroutine可以解释为受管理的轻量线程, goroutine使用go关键词创建.
举例来说, func main() { go other() }, 这段代码创建了两个goroutine,
一个是main, 另一个是other, 注意main本身也是一个goroutine.
goroutine的新建, 休眠, 恢复, 停止都受到go运行时的管理.
goroutine执行异步操作时会进入休眠状态, 待操作完成后再恢复, 无需占用系统线程,
goroutine新建或恢复时会添加到运行队列, 等待M取出并运行.
需要框架源码的朋友可以看我个人简介联系我,推荐分布式架构源码。

M (machine)
M是machine的头文字, 在当前版本的golang中等同于系统线程.
M可以运行两种代码:
-
go代码, 即goroutine, M运行go代码需要一个P
-
原生代码, 例如阻塞的syscall, M运行原生代码不需要P
M会从运行队列中取出G, 然后运行G, 如果G运行完毕或者进入休眠状态, 则从运行队列中取出下一个G运行, 周而复始.
有时候G需要调用一些无法避免阻塞的原生代码, 这时M会释放持有的P并进入阻塞状态, 其他M会取得这个P并继续运行队列中的G.
go需要保证有足够的M可以运行G, 不让CPU闲着, 也需要保证M的数量不能过多.
P (process)
P是process的头文字, 代表M运行G所需要的资源.
一些讲解协程的文章把P理解为cpu核心, 其实这是错误的.
虽然P的数量默认等于cpu核心数, 但可以通过环境变量GOMAXPROC修改, 在实际运行时P跟cpu核心并无任何关联.
P也可以理解为控制go代码的并行度的机制,
如果P的数量等于1, 代表当前最多只能有一个线程(M)执行go代码,
如果P的数量等于2, 代表当前最多只能有两个线程(M)执行go代码.
执行原生代码的线程数量不受P控制.
因为同一时间只有一个线程(M)可以拥有P, P中的数据都是锁自由(lock free)的, 读写这些数据的效率会非常的高.
数据结构
在讲解协程的工作流程之前, 还需要理解一些内部的数据结构.
G的状态
-
空闲中(_Gidle): 表示G刚刚新建, 仍未初始化
-
待运行(_Grunnable): 表示G在运行队列中, 等待M取出并运行
-
运行中(_Grunning): 表示M正在运行这个G, 这时候M会拥有一个P
-
系统调用中(_Gsyscall): 表示M正在运行这个G发起的系统调用, 这时候M并不拥有P
-
等待中(_Gwaiting): 表示G在等待某些条件完成, 这时候G不在运行也不在运行队列中(可能在channel的等待队列中)
-
已中止(_Gdead): 表示G未被使用, 可能已执行完毕(并在freelist中等待下次复用)
-
栈复制中(_Gcopystack): 表示G正在获取一个新的栈空间并把原来的内容复制过去(用于防止GC扫描)
M的状态
M并没有像G和P一样的状态标记, 但可以认为一个M有以下的状态:
-
自旋中(spinning): M正在从运行队列获取G, 这时候M会拥有一个P
-
执行go代码中: M正在执行go代码, 这时候M会拥有一个P
-
执行原生代码中: M正在执行原生代码或者阻塞的syscall, 这时M并不拥有P
-
休眠中: M发现无待运行的G时会进入休眠, 并添加到空闲M链表中, 这时M并不拥有P
自旋中(spinning)这个状态非常重要, 是否需要唤醒或者创建新的M取决于当前自旋中的M的数量.
P的状态
-
空闲中(_Pidle): 当M发现无待运行的G时会进入休眠, 这时M拥有的P会变为空闲并加到空闲P链表中
-
运行中(_Prunning): 当M拥有了一个P后, 这个P的状态就会变为运行中, M运行G会使用这个P中的资源
-
系统调用中(_Psyscall): 当go调用原生代码, 原生代码又反过来调用go代码时, 使用的P会变为此状态
-
GC停止中(_Pgcstop): 当gc停止了整个世界(STW)时, P会变为此状态
-
已中止(_Pdead): 当P的数量在运行时改变, 且数量减少时多余的P会变为此状态
本地运行队列
在go中有多个运行队列可以保存待运行(_Grunnable)的G, 它们分别是各个P中的本地运行队列和全局运行队列.
入队待运行的G时会优先加到当前P的本地运行队列, M获取待运行的G时也会优先从拥有的P的本地运行队列获取,
本地运行队列入队和出队不需要使用线程锁.
本地运行队列有数量限制, 当数量达到256个时会入队到全局运行队列.
本地运行队列的数据结构是环形队列, 由一个256长度的数组和两个序号(head, tail)组成.
当M从P的本地运行队列获取G时, 如果发现本地队列为空会尝试从其他P盗取一半的G过来,
这个机制叫做Work Stealing, 详见后面的代码分析.
全局运行队列
全局运行队列保存在全局变量sched中, 全局运行队列入队和出队需要使用线程锁.
全局运行队列的数据结构是链表, 由两个指针(head, tail)组成.
空闲M链表
当M发现无待运行的G时会进入休眠, 并添加到空闲M链表中, 空闲M链表保存在全局变量sched.
进入休眠的M会等待一个信号量(m.park), 唤醒休眠的M会使用这个信号量.
go需要保证有足够的M可以运行G, 是通过这样的机制实现的:
-
入队待运行的G后, 如果当前无自旋的M但是有空闲的P, 就唤醒或者新建一个M
-
当M离开自旋状态并准备运行出队的G时, 如果当前无自旋的M但是有空闲的P, 就唤醒或者新建一个M
-
当M离开自旋状态并准备休眠时, 会在离开自旋状态后再次检查所有运行队列, 如果有待运行的G则重新进入自旋状态
因为"入队待运行的G"和"M离开自旋状态"会同时进行, go会使用这样的检查顺序:
入队待运行的G => 内存屏障 => 检查当前自旋的M数量 => 唤醒或者新建一个M
减少当前自旋的M数量 => 内存屏障 => 检查所有运行队列是否有待运行的G => 休眠
这样可以保证不会出现待运行的G入队了, 也有空闲的资源P, 但无M去执行的情况.
空闲P链表
当P的本地运行队列中的所有G都运行完毕, 又不能从其他地方拿到G时,
拥有P的M会释放P并进入休眠状态, 释放的P会变为空闲状态并加到空闲P链表中, 空闲P链表保存在全局变量sched
下次待运行的G入队时如果发现有空闲的P, 但是又没有自旋中的M时会唤醒或者新建一个M, M会拥有这个P, P会重新变为运行中的状态.
工作流程(概览)
下图是协程可能出现的工作状态, 图中有4个P, 其中M1~M3正在运行G并且运行后会从拥有的P的运行队列继续获取G:
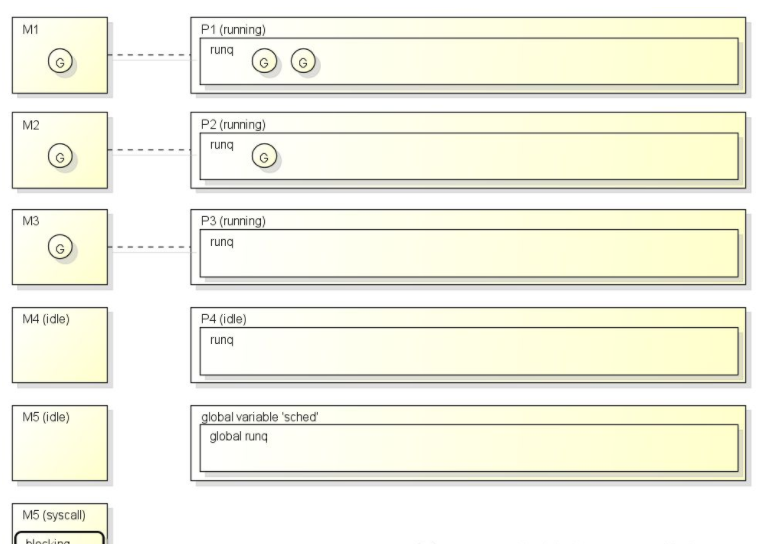
只看这张图可能有点难以想象实际的工作流程, 这里我根据实际的代码再讲解一遍:
package mainimport ("fmt""time"
)func printNumber(from, to int, c chan int) {for x := from; x <= to; x++ {fmt.Printf("%d\n", x)time.Sleep(1 * time.Millisecond)}c <- 0
}func main() {c := make(chan int, 3)go printNumber(1, 3, c)go printNumber(4, 6, c)_ = <- c_ = <- c
}程序启动时会先创建一个G, 指向的是main(实际是runtime.main而不是main.main, 后面解释):
图中的虚线指的是G待运行或者开始运行的地址, 不是当前运行的地址.

M会取得这个G并运行:
这时main会创建一个新的channel, 并启动两个新的G:
接下来G: main会从channel获取数据, 因为获取不到, G会保存状态并变为等待中(_Gwaiting)并添加到channel的队列:
因为G: main保存了运行状态, 下次运行时将会从_ = <- c继续运行.
接下来M会从运行队列获取到G: printNumber并运行: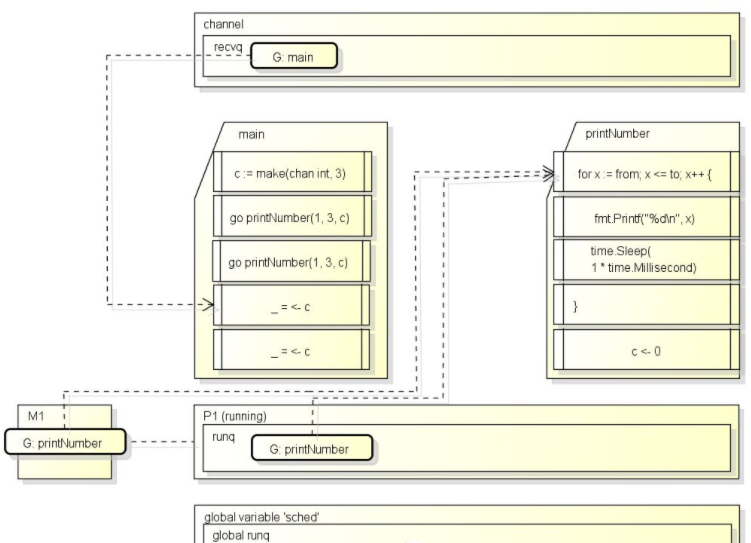
printNumber会打印数字, 完成后向channel写数据,
写数据时发现channel中有正在等待的G, 会把数据交给这个G, 把G变为待运行(_Grunnable)并重新放入运行队列:
接下来M会运行下一个G: printNumber, 因为创建channel时指定了大小为3的缓冲区, 可以直接把数据写入缓冲区而无需等待:
然后printNumber运行完毕, 运行队列中就只剩下G: main了: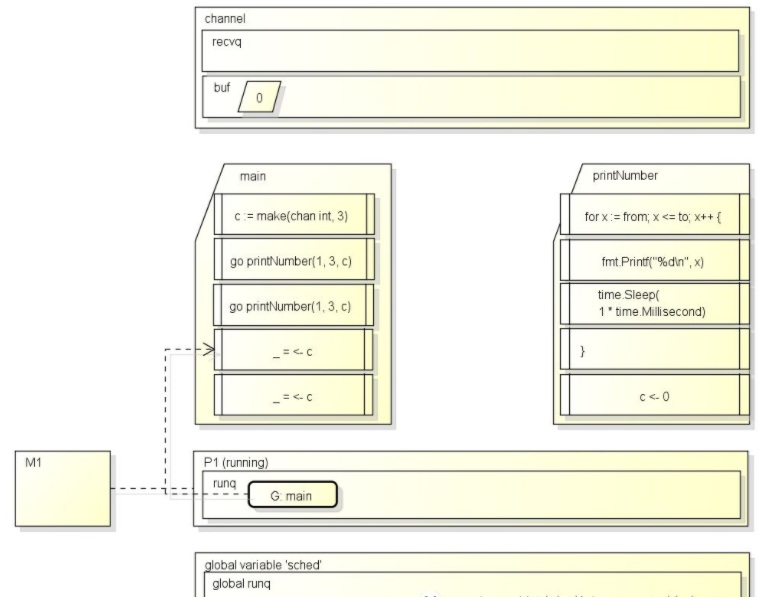
最后M把G: main取出来运行, 会从上次中断的位置_ <- c继续运行:
第一个_ <- c的结果已经在前面设置过了, 这条语句会执行成功.
第二个_ <- c在获取时会发现channel中有已缓冲的0, 于是结果就是这个0, 不需要等待.
最后main执行完毕, 程序结束.
有人可能会好奇如果最后再加一个_ <- c会变成什么结果, 这时因为所有G都进入等待状态, go会检测出来并报告死锁:
fatal error: all goroutines are asleep - deadlock!开始代码分析
关于概念的讲解到此结束, 从这里开始会分析go中的实现代码, 我们需要先了解一些基础的内容.
汇编代码
从以下的go代码:
package mainimport ("fmt""time"
)func printNumber(from, to int, c chan int) {for x := from; x <= to; x++ {fmt.Printf("%d\n", x)time.Sleep(1 * time.Millisecond)}c <- 0
}func main() {c := make(chan int, 3)go printNumber(1, 3, c)go printNumber(4, 6, c)_, _ = <- c, <- c
}可以生成以下的汇编代码(平台是linux x64, 使用的是默认选项, 即启用优化和内联):
(lldb) di -n main.main
hello`main.main:
hello[0x401190] <+0>: movq %fs:-0x8, %rcx
hello[0x401199] <+9>: cmpq 0x10(%rcx), %rsp
hello[0x40119d] <+13>: jbe 0x401291 ; <+257> at hello.go:16
hello[0x4011a3] <+19>: subq $0x40, %rsp
hello[0x4011a7] <+23>: leaq 0xb3632(%rip), %rbx ; runtime.rodata + 38880
hello[0x4011ae] <+30>: movq %rbx, (%rsp)
hello[0x4011b2] <+34>: movq $0x3, 0x8(%rsp)
hello[0x4011bb] <+43>: callq 0x4035a0 ; runtime.makechan at chan.go:49
hello[0x4011c0] <+48>: movq 0x10(%rsp), %rax
hello[0x4011c5] <+53>: movq $0x1, 0x10(%rsp)
hello[0x4011ce] <+62>: movq $0x3, 0x18(%rsp)
hello[0x4011d7] <+71>: movq %rax, 0x38(%rsp)
hello[0x4011dc] <+76>: movq %rax, 0x20(%rsp)
hello[0x4011e1] <+81>: movl $0x18, (%rsp)
hello[0x4011e8] <+88>: leaq 0x129c29(%rip), %rax ; main.printNumber.f
hello[0x4011ef] <+95>: movq %rax, 0x8(%rsp)
hello[0x4011f4] <+100>: callq 0x430cd0 ; runtime.newproc at proc.go:2657
hello[0x4011f9] <+105>: movq $0x4, 0x10(%rsp)
hello[0x401202] <+114>: movq $0x6, 0x18(%rsp)
hello[0x40120b] <+123>: movq 0x38(%rsp), %rbx
hello[0x401210] <+128>: movq %rbx, 0x20(%rsp)
hello[0x401215] <+133>: movl $0x18, (%rsp)
hello[0x40121c] <+140>: leaq 0x129bf5(%rip), %rax ; main.printNumber.f
hello[0x401223] <+147>: movq %rax, 0x8(%rsp)
hello[0x401228] <+152>: callq 0x430cd0 ; runtime.newproc at proc.go:2657
hello[0x40122d] <+157>: movq $0x0, 0x30(%rsp)
hello[0x401236] <+166>: leaq 0xb35a3(%rip), %rbx ; runtime.rodata + 38880
hello[0x40123d] <+173>: movq %rbx, (%rsp)
hello[0x401241] <+177>: movq 0x38(%rsp), %rbx
hello[0x401246] <+182>: movq %rbx, 0x8(%rsp)
hello[0x40124b] <+187>: leaq 0x30(%rsp), %rbx
hello[0x401250] <+192>: movq %rbx, 0x10(%rsp)
hello[0x401255] <+197>: callq 0x4043c0 ; runtime.chanrecv1 at chan.go:354
hello[0x40125a] <+202>: movq $0x0, 0x28(%rsp)
hello[0x401263] <+211>: leaq 0xb3576(%rip), %rbx ; runtime.rodata + 38880
hello[0x40126a] <+218>: movq %rbx, (%rsp)
hello[0x40126e] <+222>: movq 0x38(%rsp), %rbx
hello[0x401273] <+227>: movq %rbx, 0x8(%rsp)
hello[0x401278] <+232>: leaq 0x28(%rsp), %rbx
hello[0x40127d] <+237>: movq %rbx, 0x10(%rsp)
hello[0x401282] <+242>: callq 0x4043c0 ; runtime.chanrecv1 at chan.go:354
hello[0x401287] <+247>: movq 0x28(%rsp), %rbx
hello[0x40128c] <+252>: addq $0x40, %rsp
hello[0x401290] <+256>: retq
hello[0x401291] <+257>: callq 0x4538d0 ; runtime.morestack_noctxt at asm_amd64.s:365
hello[0x401296] <+262>: jmp 0x401190 ; <+0> at hello.go:16
hello[0x40129b] <+267>: int3
hello[0x40129c] <+268>: int3
hello[0x40129d] <+269>: int3
hello[0x40129e] <+270>: int3
hello[0x40129f] <+271>: int3(lldb) di -n main.printNumber
hello`main.printNumber:
hello[0x401000] <+0>: movq %fs:-0x8, %rcx
hello[0x401009] <+9>: leaq -0x8(%rsp), %rax
hello[0x40100e] <+14>: cmpq 0x10(%rcx), %rax
hello[0x401012] <+18>: jbe 0x401185 ; <+389> at hello.go:8
hello[0x401018] <+24>: subq $0x88, %rsp
hello[0x40101f] <+31>: xorps %xmm0, %xmm0
hello[0x401022] <+34>: movups %xmm0, 0x60(%rsp)
hello[0x401027] <+39>: movq 0x90(%rsp), %rax
hello[0x40102f] <+47>: movq 0x98(%rsp), %rbp
hello[0x401037] <+55>: cmpq %rbp, %rax
hello[0x40103a] <+58>: jg 0x40112f ; <+303> at hello.go:13
hello[0x401040] <+64>: movq %rax, 0x40(%rsp)
hello[0x401045] <+69>: movq %rax, 0x48(%rsp)
hello[0x40104a] <+74>: xorl %ebx, %ebx
hello[0x40104c] <+76>: movq %rbx, 0x60(%rsp)
hello[0x401051] <+81>: movq %rbx, 0x68(%rsp)
hello[0x401056] <+86>: leaq 0x60(%rsp), %rbx
hello[0x40105b] <+91>: cmpq $0x0, %rbx
hello[0x40105f] <+95>: je 0x40117e ; <+382> at hello.go:10
hello[0x401065] <+101>: movq $0x1, 0x78(%rsp)
hello[0x40106e] <+110>: movq $0x1, 0x80(%rsp)
hello[0x40107a] <+122>: movq %rbx, 0x70(%rsp)
hello[0x40107f] <+127>: leaq 0xb73fa(%rip), %rbx ; runtime.rodata + 54400
hello[0x401086] <+134>: movq %rbx, (%rsp)
hello[0x40108a] <+138>: leaq 0x48(%rsp), %rbx
hello[0x40108f] <+143>: movq %rbx, 0x8(%rsp)
hello[0x401094] <+148>: movq $0x0, 0x10(%rsp)
hello[0x40109d] <+157>: callq 0x40bb90 ; runtime.convT2E at iface.go:128
hello[0x4010a2] <+162>: movq 0x18(%rsp), %rcx
hello[0x4010a7] <+167>: movq 0x20(%rsp), %rax
hello[0x4010ac] <+172>: movq 0x70(%rsp), %rbx
hello[0x4010b1] <+177>: movq %rcx, 0x50(%rsp)
hello[0x4010b6] <+182>: movq %rcx, (%rbx)
hello[0x4010b9] <+185>: movq %rax, 0x58(%rsp)
hello[0x4010be] <+190>: cmpb $0x0, 0x19ea1b(%rip) ; time.initdone.
hello[0x4010c5] <+197>: jne 0x401167 ; <+359> at hello.go:10
hello[0x4010cb] <+203>: movq %rax, 0x8(%rbx)
hello[0x4010cf] <+207>: leaq 0xfb152(%rip), %rbx ; go.string.* + 560
hello[0x4010d6] <+214>: movq %rbx, (%rsp)
hello[0x4010da] <+218>: movq $0x3, 0x8(%rsp)
hello[0x4010e3] <+227>: movq 0x70(%rsp), %rbx
hello[0x4010e8] <+232>: movq %rbx, 0x10(%rsp)
hello[0x4010ed] <+237>: movq 0x78(%rsp), %rbx
hello[0x4010f2] <+242>: movq %rbx, 0x18(%rsp)
hello[0x4010f7] <+247>: movq 0x80(%rsp), %rbx
hello[0x4010ff] <+255>: movq %rbx, 0x20(%rsp)
hello[0x401104] <+260>: callq 0x45ad70 ; fmt.Printf at print.go:196
hello[0x401109] <+265>: movq $0xf4240, (%rsp) ; imm = 0xF4240
hello[0x401111] <+273>: callq 0x442a50 ; time.Sleep at time.go:48
hello[0x401116] <+278>: movq 0x40(%rsp), %rax
hello[0x40111b] <+283>: incq %rax
hello[0x40111e] <+286>: movq 0x98(%rsp), %rbp
hello[0x401126] <+294>: cmpq %rbp, %rax
hello[0x401129] <+297>: jle 0x401040 ; <+64> at hello.go:10
hello[0x40112f] <+303>: movq $0x0, 0x48(%rsp)
hello[0x401138] <+312>: leaq 0xb36a1(%rip), %rbx ; runtime.rodata + 38880
hello[0x40113f] <+319>: movq %rbx, (%rsp)
hello[0x401143] <+323>: movq 0xa0(%rsp), %rbx
hello[0x40114b] <+331>: movq %rbx, 0x8(%rsp)
hello[0x401150] <+336>: leaq 0x48(%rsp), %rbx
hello[0x401155] <+341>: movq %rbx, 0x10(%rsp)
hello[0x40115a] <+346>: callq 0x403870 ; runtime.chansend1 at chan.go:99
hello[0x40115f] <+351>: addq $0x88, %rsp
hello[0x401166] <+358>: retq
hello[0x401167] <+359>: leaq 0x8(%rbx), %r8
hello[0x40116b] <+363>: movq %r8, (%rsp)
hello[0x40116f] <+367>: movq %rax, 0x8(%rsp)
hello[0x401174] <+372>: callq 0x40f090 ; runtime.writebarrierptr at mbarrier.go:129
hello[0x401179] <+377>: jmp 0x4010cf ; <+207> at hello.go:10
hello[0x40117e] <+382>: movl %eax, (%rbx)
hello[0x401180] <+384>: jmp 0x401065 ; <+101> at hello.go:10
hello[0x401185] <+389>: callq 0x4538d0 ; runtime.morestack_noctxt at asm_amd64.s:365
hello[0x40118a] <+394>: jmp 0x401000 ; <+0> at hello.go:8
hello[0x40118f] <+399>: int3这些汇编代码现在看不懂也没关系, 下面会从这里取出一部分来解释.
调用规范
不同平台对于函数有不同的调用规范.
例如32位通过栈传递参数, 通过eax寄存器传递返回值.
64位windows通过rcx, rdx, r8, r9传递前4个参数, 通过栈传递第5个开始的参数, 通过eax寄存器传递返回值.
64位linux, unix通过rdi, rsi, rdx, rcx, r8, r9传递前6个参数, 通过栈传递第7个开始的参数, 通过eax寄存器传递返回值.
go并不使用这些调用规范(除非涉及到与原生代码交互), go有一套独自的调用规范.
go的调用规范非常的简单, 所有参数都通过栈传递, 返回值也通过栈传递,
例如这样的函数:
type MyStruct struct { X int; P *int }
func someFunc(x int, s MyStruct) (int, MyStruct) { ... }调用函数时的栈的内容如下:
可以看得出参数和返回值都从低位到高位排列, go函数可以有多个返回值的原因也在于此. 因为返回值都通过栈传递了.
需要注意的这里的"返回地址"是x86和x64上的, arm的返回地址会通过LR寄存器保存, 内容会和这里的稍微不一样.
另外注意的是和c不一样, 传递构造体时整个构造体的内容都会复制到栈上, 如果构造体很大将会影响性能.
TLS
TLS的全称是Thread-local storage, 代表每个线程的中的本地数据.
例如标准c中的errno就是一个典型的TLS变量, 每个线程都有一个独自的errno, 写入它不会干扰到其他线程中的值.
go在实现协程时非常依赖TLS机制, 会用于获取系统线程中当前的G和G所属的M的实例.
因为go并不使用glibc, 操作TLS会使用系统原生的接口, 以linux x64为例,
go在新建M时会调用arch_prctl这个syscall设置FS寄存器的值为M.tls的地址,
运行中每个M的FS寄存器都会指向它们对应的M实例的tls, linux内核调度线程时FS寄存器会跟着线程一起切换,
这样go代码只需要访问FS寄存器就可以存取线程本地的数据.
上面的汇编代码中的
hello[0x401000] <+0>: movq %fs:-0x8, %rcx会把指向当前的G的指针从TLS移动到rcx寄存器中.
栈扩张
因为go中的协程是stackful coroutine, 每一个goroutine都需要有自己的栈空间,
栈空间的内容在goroutine休眠时需要保留, 待休眠完成后恢复(这时整个调用树都是完整的).
这样就引出了一个问题, goroutine可能会同时存在很多个, 如果每一个goroutine都预先分配一个足够的栈空间那么go就会使用过多的内存.
为了避免这个问题, go在一开始只为goroutine分配一个很小的栈空间, 它的大小在当前版本是2K.
当函数发现栈空间不足时, 会申请一块新的栈空间并把原来的栈内容复制过去.
上面的汇编代码中的
hello[0x401000] <+0>: movq %fs:-0x8, %rcx
hello[0x401009] <+9>: leaq -0x8(%rsp), %rax
hello[0x40100e] <+14>: cmpq 0x10(%rcx), %rax
hello[0x401012] <+18>: jbe 0x401185 ; <+389> at hello.go:8会检查比较rsp减去一定值以后是否比g.stackguard0小, 如果小于等于则需要调到下面调用morestack_noctxt函数.
细心的可能会发现比较的值跟实际减去的值不一致, 这是因为stackguard0下面会预留一小部分空间, 编译时确定不超过预留的空间可以省略比对.
写屏障(Write Barrier)
因为go支持并行GC, GC的扫描和go代码可以同时运行, 这样带来的问题是GC扫描的过程中go代码有可能改变了对象的依赖树,
例如开始扫描时发现根对象A和B, B拥有C的指针, GC先扫描A, 然后B把C的指针交给A, GC再扫描B, 这时C就不会被扫描到.
为了避免这个问题, go在GC的标记阶段会启用写屏障(Write Barrier).
启用了写屏障(Write Barrier)后, 当B把C的指针交给A时, GC会认为在这一轮的扫描中C的指针是存活的,
即使A可能会在稍后丢掉C, 那么C就在下一轮回收.
写屏障只针对指针启用, 而且只在GC的标记阶段启用, 平时会直接把值写入到目标地址:
关于写屏障的详细将在下一篇(GC篇)分析.
值得一提的是CoreCLR的GC也有写屏障的机制, 作用跟这里说明的一样.
闭包(Closure)
闭包这个概念本身应该不需要解释, 我们实际看一看go是如何实现闭包的:
package mainimport ("fmt"
)func executeFn(fn func() int) int {return fn();
}func main() {a := 1b := 2c := executeFn(func() int {a += breturn a})fmt.Printf("%d %d %d\n", a, b, c)
}这段代码的输出结果是3 2 3, 熟悉go的应该不会感到意外.
main函数执行executeFn函数的汇编代码如下:
hello[0x4a096f] <+47>: movq $0x1, 0x40(%rsp) ; 变量a等于1
hello[0x4a0978] <+56>: leaq 0x151(%rip), %rax ; 寄存器rax等于匿名函数main.main.func1的地址
hello[0x4a097f] <+63>: movq %rax, 0x60(%rsp) ; 变量rsp+0x60等于匿名函数的地址
hello[0x4a0984] <+68>: leaq 0x40(%rsp), %rax ; 寄存器rax等于变量a的地址
hello[0x4a0989] <+73>: movq %rax, 0x68(%rsp) ; 变量rsp+0x68等于变量a的地址
hello[0x4a098e] <+78>: movq $0x2, 0x70(%rsp) ; 变量rsp+0x70等于2(变量b的值)
hello[0x4a0997] <+87>: leaq 0x60(%rsp), %rax ; 寄存器rax等于地址rsp+0x60
hello[0x4a099c] <+92>: movq %rax, (%rsp) ; 第一个参数等于地址rsp+0x60
hello[0x4a09a0] <+96>: callq 0x4a08f0 ; 执行main.executeFn
hello[0x4a09a5] <+101>: movq 0x8(%rsp), %rax ; 寄存器rax等于返回值我们可以看到传给executeFn的是一个指针, 指针指向的内容是[匿名函数的地址, 变量a的地址, 变量b的值].
变量a传地址的原因是匿名函数中对a进行了修改, 需要反映到原来的a上.
executeFn函数执行闭包的汇编代码如下:
hello[0x4a08ff] <+15>: subq $0x10, %rsp ; 在栈上分配0x10的空间
hello[0x4a0903] <+19>: movq %rbp, 0x8(%rsp) ; 把原来的寄存器rbp移到变量rsp+0x8
hello[0x4a0908] <+24>: leaq 0x8(%rsp), %rbp ; 把变量rsp+0x8的地址移到寄存器rbp
hello[0x4a090d] <+29>: movq 0x18(%rsp), %rdx ; 把第一个参数(闭包)的指针移到寄存器rdx
hello[0x4a0912] <+34>: movq (%rdx), %rax ; 把闭包中函数的指针移到寄存器rax
hello[0x4a0915] <+37>: callq *%rax ; 调用闭包中的函数
hello[0x4a0917] <+39>: movq (%rsp), %rax ; 把返回值移到寄存器rax
hello[0x4a091b] <+43>: movq %rax, 0x20(%rsp) ; 把寄存器rax移到返回值中(参数后面)
hello[0x4a0920] <+48>: movq 0x8(%rsp), %rbp ; 把变量rsp+0x8的值恢复寄存器rbp(恢复原rbp)
hello[0x4a0925] <+53>: addq $0x10, %rsp ; 释放栈空间
hello[0x4a0929] <+57>: retq ; 从函数返回可以看到调用闭包时参数并不通过栈传递, 而是通过寄存器rdx传递, 闭包的汇编代码如下:
hello[0x455660] <+0>: movq 0x8(%rdx), %rax ; 第一个参数移到寄存器rax(变量a的指针)
hello[0x455664] <+4>: movq (%rax), %rcx ; 把寄存器rax指向的值移到寄存器rcx(变量a的值)
hello[0x455667] <+7>: addq 0x10(%rdx), %rcx ; 添加第二个参数到寄存器rcx(变量a的值+变量b的值)
hello[0x45566b] <+11>: movq %rcx, (%rax) ; 把寄存器rcx移到寄存器rax指向的值(相加的结果保存回变量a)
hello[0x45566e] <+14>: movq %rcx, 0x8(%rsp) ; 把寄存器rcx移到返回结果
hello[0x455673] <+19>: retq ; 从函数返回闭包的传递可以总结如下:
-
闭包的内容是[匿名函数的地址, 传给匿名函数的参数(不定长)...]
-
传递闭包给其他函数时会传递指向"闭包的内容"的指针
-
调用闭包时会把指向"闭包的内容"的指针放到寄存器rdx(在go内部这个指针称为"上下文")
-
闭包会从寄存器rdx取出参数
-
如果闭包修改了变量, 闭包中的参数会是指针而不是值, 修改时会修改到原来的位置上
闭包+goroutine
细心的可能会发现在上面的例子中, 闭包的内容在栈上, 如果不是直接调用executeFn而是go executeFn呢?
把上面的代码改为go executeFn(func() ...)可以生成以下的汇编代码:
hello[0x455611] <+33>: leaq 0xb4a8(%rip), %rax ; 寄存器rax等于类型信息
hello[0x455618] <+40>: movq %rax, (%rsp) ; 第一个参数等于类型信息
hello[0x45561c] <+44>: callq 0x40d910 ; 调用runtime.newobject
hello[0x455621] <+49>: movq 0x8(%rsp), %rax ; 寄存器rax等于返回值(这里称为新对象a)
hello[0x455626] <+54>: movq %rax, 0x28(%rsp) ; 变量rsp+0x28等于新对象a
hello[0x45562b] <+59>: movq $0x1, (%rax) ; 新对象a的值等于1
hello[0x455632] <+66>: leaq 0x136e7(%rip), %rcx ; 寄存器rcx等于类型信息
hello[0x455639] <+73>: movq %rcx, (%rsp) ; 第一个参数等于类型信息
hello[0x45563d] <+77>: callq 0x40d910 ; 调用runtime.newobject
hello[0x455642] <+82>: movq 0x8(%rsp), %rax ; 寄存器rax等于返回值(这里称为新对象fn)
hello[0x455647] <+87>: leaq 0x82(%rip), %rcx ; 寄存器rcx等于匿名函数main.main.func1的地址
hello[0x45564e] <+94>: movq %rcx, (%rax) ; 新对象fn+0的值等于main.main.func1的地址
hello[0x455651] <+97>: testb (%rax), %al ; 确保新对象fn不等于nil
hello[0x455653] <+99>: movl 0x78397(%rip), %ecx ; 寄存器ecx等于当前是否启用写屏障
hello[0x455659] <+105>: leaq 0x8(%rax), %rdx ; 寄存器rdx等于新对象fn+0x8的地址
hello[0x45565d] <+109>: testl %ecx, %ecx ; 判断当前是否启用写屏障
hello[0x45565f] <+111>: jne 0x455699 ; 启用写屏障时调用后面的逻辑
hello[0x455661] <+113>: movq 0x28(%rsp), %rcx ; 寄存器rcx等于新对象a
hello[0x455666] <+118>: movq %rcx, 0x8(%rax) ; 设置新对象fn+0x8的值等于新对象a
hello[0x45566a] <+122>: movq $0x2, 0x10(%rax) ; 设置新对象fn+0x10的值等于2(变量b的值)
hello[0x455672] <+130>: movq %rax, 0x10(%rsp) ; 第三个参数等于新对象fn(额外参数)
hello[0x455677] <+135>: movl $0x10, (%rsp) ; 第一个参数等于0x10(函数+参数的大小)
hello[0x45567e] <+142>: leaq 0x22fb3(%rip), %rax ; 第二个参数等于一个常量构造体的地址
hello[0x455685] <+149>: movq %rax, 0x8(%rsp) ; 这个构造体的类型是funcval, 值是executeFn的地址
hello[0x45568a] <+154>: callq 0x42e690 ; 调用runtime.newproc创建新的goroutine我们可以看到goroutine+闭包的情况更复杂, 首先go会通过逃逸分析算出变量a和闭包会逃逸到外面,
这时go会在heap上分配变量a和闭包, 上面调用的两次newobject就是分别对变量a和闭包的分配.
在创建goroutine时, 首先会传入函数+参数的大小(上面是8+8=16), 然后传入函数+参数, 上面的参数即闭包的地址.
m0和g0
go中还有特殊的M和G, 它们是m0和g0.
m0是启动程序后的主线程, 这个m对应的实例会在全局变量m0中, 不需要在heap上分配,
m0负责执行初始化操作和启动第一个g, 在之后m0就和其他的m一样了.
g0是仅用于负责调度的G, g0不指向任何可执行的函数, 每个m都会有一个自己的g0,
在调度或系统调用时会使用g0的栈空间, 全局变量的g0是m0的g0.
如果上面的内容都了解, 就可以开始看golang的源代码了.
程序初始化
go程序的入口点是runtime.rt0_go, 流程是:
-
分配栈空间, 需要2个本地变量+2个函数参数, 然后向8对齐
-
把传入的argc和argv保存到栈上
-
更新g0中的stackguard的值, stackguard用于检测栈空间是否不足, 需要分配新的栈空间
-
获取当前cpu的信息并保存到各个全局变量
-
调用_cgo_init如果函数存在
-
初始化当前线程的TLS, 设置FS寄存器为m0.tls+8(获取时会-8)
-
测试TLS是否工作
-
设置g0到TLS中, 表示当前的g是g0
-
设置m0.g0 = g0
-
设置g0.m = m0
-
调用runtime.check做一些检查
-
调用runtime.args保存传入的argc和argv到全局变量
-
调用runtime.osinit根据系统执行不同的初始化
-
这里(linux x64)设置了全局变量ncpu等于cpu核心数量
-
-
调用runtime.schedinit执行共同的初始化
-
这里的处理比较多, 会初始化栈空间分配器, GC, 按cpu核心数量或GOMAXPROCS的值生成P等
-
生成P的处理在procresize中
-
-
调用runtime.newproc创建一个新的goroutine, 指向的是
runtime.main-
runtime.newproc这个函数在创建普通的goroutine时也会使用, 在下面的"go的实现"中会详细讲解
-
-
调用runtime·mstart启动m0
-
启动后m0会不断从运行队列获取G并运行, runtime.mstart调用后不会返回
-
runtime.mstart这个函数是m的入口点(不仅仅是m0), 在下面的"调度器的实现"中会详细讲解
-
第一个被调度的G会运行runtime.main, 流程是:
-
标记主函数已调用, 设置mainStarted = true
-
启动一个新的M执行sysmon函数, 这个函数会监控全局的状态并对运行时间过长的G进行抢占
-
要求G必须在当前M(系统主线程)上执行
-
调用runtime_init函数
-
调用gcenable函数
-
调用main.init函数, 如果函数存在
-
不再要求G必须在当前M上运行
-
如果程序是作为c的类库编译的, 在这里返回
-
调用main.main函数
-
如果当前发生了panic, 则等待panic处理
-
调用exit(0)退出程序
G M P的定义
G的定义在这里.
M的定义在这里.
P的定义在这里.
G里面比较重要的成员如下
-
stack: 当前g使用的栈空间, 有lo和hi两个成员
-
stackguard0: 检查栈空间是否足够的值, 低于这个值会扩张栈, 0是go代码使用的
-
stackguard1: 检查栈空间是否足够的值, 低于这个值会扩张栈, 1是原生代码使用的
-
m: 当前g对应的m
-
sched: g的调度数据, 当g中断时会保存当前的pc和rsp等值到这里, 恢复运行时会使用这里的值
-
atomicstatus: g的当前状态
-
schedlink: 下一个g, 当g在链表结构中会使用
-
preempt: g是否被抢占中
-
lockedm: g是否要求要回到这个M执行, 有的时候g中断了恢复会要求使用原来的M执行
M里面比较重要的成员如下
-
g0: 用于调度的特殊g, 调度和执行系统调用时会切换到这个g
-
curg: 当前运行的g
-
p: 当前拥有的P
-
nextp: 唤醒M时, M会拥有这个P
-
park: M休眠时使用的信号量, 唤醒M时会通过它唤醒
-
schedlink: 下一个m, 当m在链表结构中会使用
-
mcache: 分配内存时使用的本地分配器, 和p.mcache一样(拥有P时会复制过来)
-
lockedg: lockedm的对应值
P里面比较重要的成员如下
-
status: p的当前状态
-
link: 下一个p, 当p在链表结构中会使用
-
m: 拥有这个P的M
-
mcache: 分配内存时使用的本地分配器
-
runqhead: 本地运行队列的出队序号
-
runqtail: 本地运行队列的入队序号
-
runq: 本地运行队列的数组, 可以保存256个G
-
gfree: G的自由列表, 保存变为_Gdead后可以复用的G实例
-
gcBgMarkWorker: 后台GC的worker函数, 如果它存在M会优先执行它
-
gcw: GC的本地工作队列, 详细将在下一篇(GC篇)分析
go的实现
使用go命令创建goroutine时, go会把go命令编译为对runtime.newproc的调用, 堆栈的结构如下: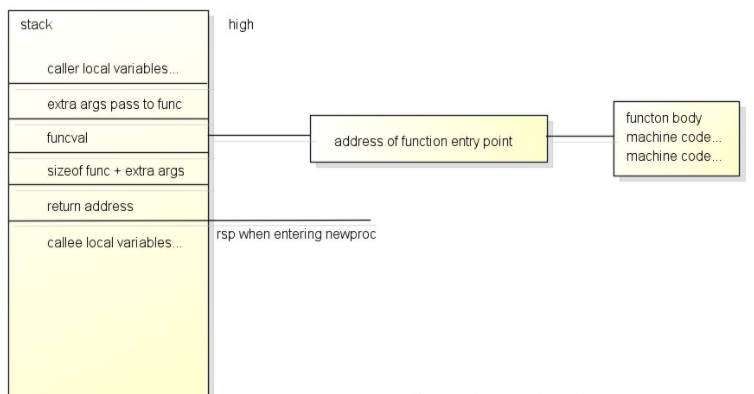
第一个参数是funcval + 额外参数的长度, 第二个参数是funcval, 后面的都是传递给goroutine中执行的函数的额外参数.
funcval的定义在这里, fn是指向函数机器代码的指针.
runtime.newproc的处理如下:
-
计算额外参数的地址argp
-
获取调用端的地址(返回地址)pc
-
使用systemstack调用newproc1
systemstack会切换当前的g到g0, 并且使用g0的栈空间, 然后调用传入的函数, 再切换回原来的g和原来的栈空间.
切换到g0后会假装返回地址是mstart, 这样traceback的时候可以在mstart停止.
这里传给systemstack的是一个闭包, 调用时会把闭包的地址放到寄存器rdx, 具体可以参考上面对闭包的分析.
runtime.newproc1的处理如下:
-
调用getg获取当前的g, 会编译为读取FS寄存器(TLS), 这里会获取到g0
-
设置g对应的m的locks++, 禁止抢占
-
获取m拥有的p
-
新建一个g
-
首先调用gfget从p.gfree获取g, 如果之前有g被回收在这里就可以复用
-
获取不到时调用malg分配一个g, 初始的栈空间大小是2K
-
需要先设置g的状态为已中止(_Gdead), 这样gc不会去扫描这个g的未初始化的栈
-
-
把参数复制到g的栈上
-
把返回地址复制到g的栈上, 这里的返回地址是goexit, 表示调用完目标函数后会调用goexit
-
设置g的调度数据(sched)
-
设置sched.sp等于参数+返回地址后的rsp地址
-
设置sched.pc等于目标函数的地址, 查看gostartcallfn和gostartcall
-
设置sched.g等于g
-
-
设置g的状态为待运行(_Grunnable)
-
调用runqput把g放到运行队列
-
runqputslow会把本地运行队列中一半的g放到全局运行队列, 这样下次就可以继续用快速的本地运行队列了
-
首先随机把g放到p.runnext, 如果放到runnext则入队原来在runnext的g
-
然后尝试把g放到P的"本地运行队列"
-
如果本地运行队列满了则调用runqputslow把g放到"全局运行队列"
-
-
如果当前有空闲的P, 但是无自旋的M(nmspinning等于0), 并且主函数已执行则唤醒或新建一个M
-
首先交换nmspinning到1, 成功再继续, 多个线程同时执行wakep只有一个会继续
-
调用startm函数
-
newm会新建一个m的实例, m的实例包含一个g0, 然后调用newosproc动一个系统线程
-
newosproc会调用syscall clone创建一个新的线程
-
线程创建后会设置TLS, 设置TLS中当前的g为g0, 然后执行mstart
-
调用pidleget从"空闲P链表"获取一个空闲的P
-
调用mget从"空闲M链表"获取一个空闲的M
-
如果没有空闲的M, 则调用newm新建一个M
-
调用notewakeup(&mp.park)唤醒线程
-
这一步非常重要, 用于保证当前有足够的M运行G, 具体请查看上面的"空闲M链表"
-
唤醒或新建一个M会通过wakep函数
-
创建goroutine的流程就这么多了, 接下来看看M是如何调度的.
调度器的实现
M启动时会调用mstart函数, m0在初始化后调用, 其他的的m在线程启动后调用.
mstart函数的处理如下:
-
调用getg获取当前的g, 这里会获取到g0
-
如果g未分配栈则从当前的栈空间(系统栈空间)上分配, 也就是说g0会使用系统栈空间
-
调用mstart1函数
-
调用gosave函数保存当前的状态到g0的调度数据中, 以后每次调度都会从这个栈地址开始
-
调用asminit函数, 不做任何事情
-
调用minit函数, 设置当前线程可以接收的信号(signal)
-
调用schedule函数
-
调用schedule函数后就进入了调度循环, 整个流程可以简单总结为:
schedule函数获取g => [必要时休眠] => [唤醒后继续获取] => execute函数执行g => 执行后返回到goexit => 重新执行schedule函数schedule函数的处理如下:
-
如果当前GC需要停止整个世界(STW), 则调用stopm休眠当前的M
-
如果M拥有的P中指定了需要在安全点运行的函数(P.runSafePointFn), 则运行它
-
快速获取待运行的G, 以下处理如果有一个获取成功后面就不会继续获取
-
如果当前GC正在标记阶段, 则查找有没有待运行的GC Worker, GC Worker也是一个G
-
为了公平起见, 每61次调度从全局运行队列获取一次G, (一直从本地获取可能导致全局运行队列中的G不被运行)
-
从P的本地运行队列中获取G, 调用runqget函数
-
-
快速获取失败时, 调用findrunnable函数获取待运行的G, 会阻塞到获取成功为止
-
再次检查当前GC是否在标记阶段, 在则查找有没有待运行的GC Worker, GC Worker也是一个G
-
再次检查如果当前GC需要停止整个世界, 或者P指定了需要再安全点运行的函数, 则跳到findrunnable的顶部重试
-
再次检查全局运行队列中是否有G, 有则获取并返回
-
释放M拥有的P, P会变为空闲(_Pidle)状态
-
把P添加到"空闲P链表"中
-
让M离开自旋状态, 这里的处理非常重要, 参考上面的"空闲M链表"
-
首先减少表示当前自旋中的M的数量的全局变量nmspinning
-
再次检查所有P的本地运行队列, 如果不为空则让M重新进入自旋状态, 并跳到findrunnable的顶部重试
-
再次检查有没有待运行的GC Worker, 有则让M重新进入自旋状态, 并跳到findrunnable的顶部重试
-
再次检查网络事件反应器是否有待运行的G, 这里对netpoll的调用会阻塞, 直到某个fd收到了事件
-
如果最终还是获取不到G, 调用stopm休眠当前的M
-
唤醒后跳到findrunnable的顶部重试
-
调用runqsteal尝试从其他P的本地运行队列盗取一半的G
-
如果当前GC需要停止整个世界(STW), 则调用stopm休眠当前的M
-
如果M拥有的P中指定了需要在安全点运行的函数(P.runSafePointFn), 则运行它
-
如果有析构器待运行则使用"运行析构器的G"
-
从P的本地运行队列中获取G, 调用runqget函数
-
从全局运行队列获取G, 调用globrunqget函数, 需要上锁
-
从网络事件反应器获取G, 函数netpoll会获取哪些fd可读可写或已关闭, 然后返回等待fd相关事件的G
-
如果获取不到G, 则执行Work Stealing
-
如果还是获取不到G, 就需要休眠M了, 接下来是休眠的步骤
-
-
成功获取到一个待运行的G
-
让M离开自旋状态, 调用resetspinning, 这里的处理和上面的不一样
-
如果当前有空闲的P, 但是无自旋的M(nmspinning等于0), 则唤醒或新建一个M
-
上面离开自旋状态是为了休眠M, 所以会再次检查所有队列然后休眠
-
这里离开自选状态是为了执行G, 所以会检查是否有空闲的P, 有则表示可以再开新的M执行G
-
-
如果G要求回到指定的M(例如上面的runtime.main)
-
调用startlockedm函数把G和P交给该M, 自己进入休眠
-
从休眠唤醒后跳到schedule的顶部重试
-
-
调用execute函数执行G
execute函数的处理如下:
-
调用getg获取当前的g
-
把G的状态由待运行(_Grunnable)改为运行中(_Grunning)
-
设置G的stackguard, 栈空间不足时可以扩张
-
增加P中记录的调度次数(对应上面的每61次优先获取一次全局运行队列)
-
设置g.m.curg = g
-
设置g.m = m
-
调用gogo函数
-
这个函数会根据g.sched中保存的状态恢复各个寄存器的值并继续运行g
-
首先针对g.sched.ctxt调用写屏障(GC标记指针存活), ctxt中一般会保存指向[函数+参数]的指针
-
设置TLS中的g为g.sched.g, 也就是g自身
-
设置rsp寄存器为g.sched.rsp
-
设置rax寄存器为g.sched.ret
-
设置rdx寄存器为g.sched.ctxt (上下文)
-
设置rbp寄存器为g.sched.rbp
-
清空sched中保存的信息
-
跳转到g.sched.pc
-
因为前面创建goroutine的newproc1函数把返回地址设为了goexit, 函数运行完毕返回时将会调用goexit函数
-
g.sched.pc在G首次运行时会指向目标函数的第一条机器指令,
如果G被抢占或者等待资源而进入休眠, 在休眠前会保存状态到g.sched,
g.sched.pc会变为唤醒后需要继续执行的地址, "保存状态"的实现将在下面讲解.
目标函数执行完毕后会调用goexit函数, goexit函数会调用goexit1函数, goexit1函数会通过mcall调用goexit0函数.
mcall这个函数就是用于实现"保存状态"的, 处理如下:
-
设置g.sched.pc等于当前的返回地址
-
设置g.sched.sp等于寄存器rsp的值
-
设置g.sched.g等于当前的g
-
设置g.sched.bp等于寄存器rbp的值
-
切换TLS中当前的g等于m.g0
-
设置寄存器rsp等于g0.sched.sp, 使用g0的栈空间
-
设置第一个参数为原来的g
-
设置rdx寄存器为指向函数地址的指针(上下文)
-
调用指定的函数, 不会返回
mcall这个函数保存当前的运行状态到g.sched, 然后切换到g0和g0的栈空间, 再调用指定的函数.
回到g0的栈空间这个步骤非常重要, 因为这个时候g已经中断, 继续使用g的栈空间且其他M唤醒了这个g将会产生灾难性的后果.
G在中断或者结束后都会通过mcall回到g0的栈空间继续调度, 从goexit调用的mcall的保存状态其实是多余的, 因为G已经结束了.
goexit1函数会通过mcall调用goexit0函数, goexit0函数调用时已经回到了g0的栈空间, 处理如下:
-
把G的状态由运行中(_Grunning)改为已中止(_Gdead)
-
清空G的成员
-
调用dropg函数解除M和G之间的关联
-
调用gfput函数把G放到P的自由列表中, 下次创建G时可以复用
-
调用schedule函数继续调度
G结束后回到schedule函数, 这样就结束了一个调度循环.
不仅只有G结束会重新开始调度, G被抢占或者等待资源也会重新进行调度, 下面继续来看这两种情况.
抢占的实现
上面我提到了runtime.main会创建一个额外的M运行sysmon函数, 抢占就是在sysmon中实现的.
sysmon会进入一个无限循环, 第一轮回休眠20us, 之后每次休眠时间倍增, 最终每一轮都会休眠10ms.
sysmon中有netpool(获取fd事件), retake(抢占), forcegc(按时间强制执行gc), scavenge heap(释放自由列表中多余的项减少内存占用)等处理.
retake函数负责处理抢占, 流程是:
-
枚举所有的P
-
调用preemptone函数
-
设置g.preempt = true
-
设置g.stackguard0 = stackPreempt
-
调用handoffp解除M和P之间的关联
-
如果P在系统调用中(_Psyscall), 且经过了一次sysmon循环(20us~10ms), 则抢占这个P
-
如果P在运行中(_Prunning), 且经过了一次sysmon循环并且G运行时间超过forcePreemptNS(10ms), 则抢占这个P
-
为什么设置了stackguard就可以实现抢占?
因为这个值用于检查当前栈空间是否足够, go函数的开头会比对这个值判断是否需要扩张栈.
stackPreempt是一个特殊的常量, 它的值会比任何的栈地址都要大, 检查时一定会触发栈扩张.
栈扩张调用的是morestack_noctxt函数, morestack_noctxt函数清空rdx寄存器并调用morestack函数.
morestack函数会保存G的状态到g.sched, 切换到g0和g0的栈空间, 然后调用newstack函数.
newstack函数判断g.stackguard0等于stackPreempt, 就知道这是抢占触发的, 这时会再检查一遍是否要抢占:
-
如果M被锁定(函数的本地变量中有P), 则跳过这一次的抢占并调用gogo函数继续运行G
-
如果M正在分配内存, 则跳过这一次的抢占并调用gogo函数继续运行G
-
如果M设置了当前不能抢占, 则跳过这一次的抢占并调用gogo函数继续运行G
-
如果M的状态不是运行中, 则跳过这一次的抢占并调用gogo函数继续运行G
即使这一次抢占失败, 因为g.preempt等于true, runtime中的一些代码会重新设置stackPreempt以重试下一次的抢占.
如果判断可以抢占, 则继续判断是否GC引起的, 如果是则对G的栈空间执行标记处理(扫描根对象)然后继续运行,
如果不是GC引起的则调用gopreempt_m函数完成抢占.
gopreempt_m函数会调用goschedImpl函数, goschedImpl函数的流程是:
-
把G的状态由运行中(_Grunnable)改为待运行(_Grunnable)
-
调用dropg函数解除M和G之间的关联
-
调用globrunqput把G放到全局运行队列
-
调用schedule函数继续调度
因为全局运行队列的优先度比较低, 各个M会经过一段时间再去重新获取这个G执行,
抢占机制保证了不会有一个G长时间的运行导致其他G无法运行的情况发生.
channel的实现
在goroutine运行的过程中, 有时候需要对资源进行等待, channel就是最典型的资源.
channel的数据定义在这里, 其中关键的成员如下:
-
qcount: 当前队列中的元素数量
-
dataqsiz: 队列可以容纳的元素数量, 如果为0表示这个channel无缓冲区
-
buf: 队列的缓冲区, 结构是环形队列
-
elemsize: 元素的大小
-
closed: 是否已关闭
-
elemtype: 元素的类型, 判断是否调用写屏障时使用
-
sendx: 发送元素的序号
-
recvx: 接收元素的序号
-
recvq: 当前等待从channel接收数据的G的链表(实际类型是sudog的链表)
-
sendq: 当前等待发送数据到channel的G的链表(实际类型是sudog的链表)
-
lock: 操作channel时使用的线程锁
发送数据到channel实际调用的是runtime.chansend1函数, chansend1函数调用了chansend函数, 流程是:
-
检查channel.recvq是否有等待中的接收者的G
-
如果sudog.elem不等于nil, 调用sendDirect函数从发送者直接复制元素
-
等待接收的sudog.elem是指向接收目标的内存的指针, 如果是接收目标是
_则elem是nil, 可以省略复制 -
等待发送的sudog.elem是指向来源目标的内存的指针
-
复制后调用goready恢复发送者的G
-
把G的状态由等待中(_Gwaiting)改为待运行(_Grunnable)
-
把G放到P的本地运行队列
-
如果当前有空闲的P, 但是无自旋的M(nmspinning等于0), 则唤醒或新建一个M
-
切换到g0调用ready函数, 调用完切换回来
-
如果有, 表示channel无缓冲区或者缓冲区为空
-
调用send函数
-
从发送者拿到数据并唤醒了G后, 就可以从chansend返回了
-
-
判断是否可以把元素放到缓冲区中
-
如果缓冲区有空余的空间, 则把元素放到缓冲区并从chansend返回
-
-
无缓冲区或缓冲区已经写满, 发送者的G需要等待
-
调用gopark函数
-
mcall函数和上面说明的一样, 会把当前的状态保存到g.sched, 然后切换到g0和g0的栈空间并执行指定的函数
-
park_m函数首先把G的状态从运行中(_Grunning)改为等待中(_Gwaiting)
-
然后调用dropg函数解除M和G之间的关联
-
再调用传入的解锁函数, 这里的解锁函数会对解除channel.lock的锁定
-
最后调用schedule函数继续调度
-
通过mcall函数调用park_m函数
-
获取当前的g
-
新建一个sudog
-
设置sudog.elem = 指向发送内存的指针
-
设置sudog.g = g
-
设置sudog.c = channel
-
设置g.waiting = sudog
-
把sudog放入channel.sendq
-
调用goparkunlock函数
-
-
从这里恢复表示已经成功发送或者channel已关闭
-
检查sudog.param是否为nil, 如果为nil表示channel已关闭, 抛出panic
-
否则释放sudog然后返回
-
从channel接收数据实际调用的是runtime.chanrecv1函数, chanrecv1函数调用了chanrecv函数, 流程是:
-
检查channel.sendq中是否有等待中的发送者的G
-
如果无缓冲区, 调用recvDirect函数把元素直接复制给接收者
-
如果有缓冲区代表缓冲区已满
-
复制后调用goready恢复接收者的G, 处理同上
-
把队列中下一个要出队的元素直接复制给接收者
-
把发送的元素复制到队列中刚才出队的位置
-
这时候缓冲区仍然是满的, 但是发送序号和接收序号都会增加1
-
如果有, 表示channel无缓冲区或者缓冲区已满, 这两种情况需要分别处理(为了保证入出队顺序一致)
-
调用recv函数
-
把数据交给接收者并唤醒了G后, 就可以从chanrecv返回了
-
-
判断是否可以从缓冲区获取元素
-
如果缓冲区有元素, 则直接取出该元素并从chanrecv返回
-
-
无缓冲区或缓冲区无元素, 接收者的G需要等待
-
获取当前的g
-
新建一个sudog
-
设置sudog.elem = 指向接收内存的指针
-
设置sudog.g = g
-
设置sudog.c = channel
-
设置g.waiting = sudog
-
把sudog放入channel.recvq
-
调用goparkunlock函数, 处理同上
-
-
从这里恢复表示已经成功接收或者channel已关闭
-
检查sudog.param是否为nil, 如果为nil表示channel已关闭
-
和发送不一样的是接收不会抛panic, 会通过返回值通知channel已关闭
-
释放sudog然后返回
-
关闭channel实际调用的是closechan函数, 流程是:
-
设置channel.closed = 1
-
枚举channel.recvq, 清零它们sudog.elem, 设置sudog.param = nil
-
枚举channel.sendq, 设置sudog.elem = nil, 设置sudog.param = nil
-
调用goready函数恢复所有接收者和发送者的G