🌷🍁 博主猫头虎 带您 Go to New World.✨🍁
🦄 博客首页——猫头虎的博客🎐
🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
🌊 《IDEA开发秘籍专栏》学会IDEA常用操作,工作效率翻倍~💐
🌊 《100天精通Golang(基础入门篇)》学会Golang语言,畅玩云原生,走遍大小厂~💐
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
文章目录
- 解决Pandas KeyError: "None of [Index([...])] are in the [columns]"问题
- 摘要
- 问题描述
- 原因
- 解决方案
- 1. 检查列名
- 2. 选择存在的列
- 总结
- 原创声明
解决Pandas KeyError: "None of [Index([…])] are in the [columns]"问题

摘要
在使用Pandas处理数据时,我们可能会遇到一个常见的错误,即尝试从DataFrame中选择不存在的列时引发的KeyError。在本文中,我们将探讨这个问题的原因,并提供一种解决方案。
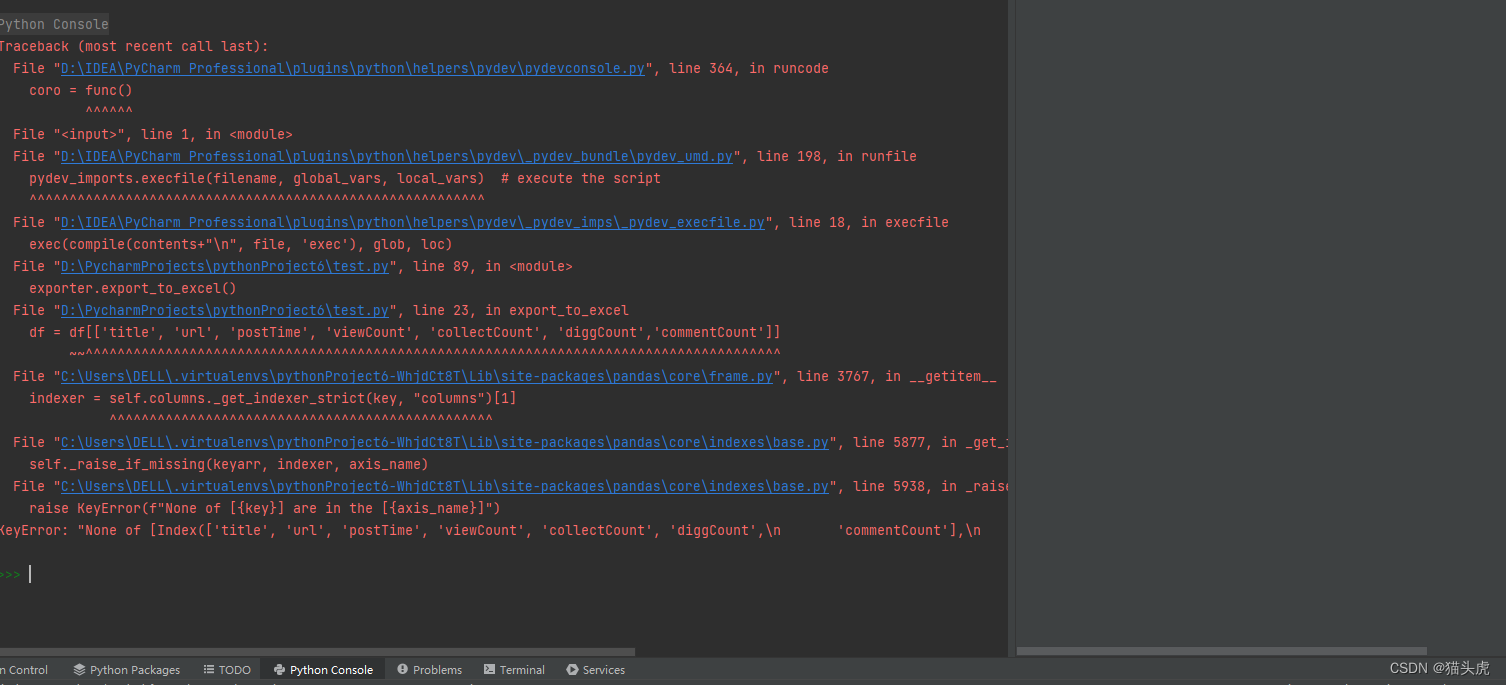
问题描述
当我们尝试从DataFrame中选择一组列,但其中一些列并不在DataFrame中时,就会出现这个问题。例如,考虑以下代码:
df = df[['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount','commentCount']]
如果df中不存在上述列中的任何一个,我们就会收到以下错误消息:
KeyError: "None of [Index(['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount'], dtype='object')] are in the [columns]"
原因
这个错误的主要原因是我们尝试访问DataFrame中不存在的列。可能的原因有:
- 列名的拼写错误或大小写错误。
- 数据源的结构已经发生了变化,导致某些预期的列不再存在。
- 数据源中没有足够的数据来生成所有预期的列。
解决方案
1. 检查列名
首先,确保你要选择的列名与df中的列名完全匹配,包括大小写。你可以使用以下代码来查看df的所有列名:
print(df.columns)
2. 选择存在的列
为了确保代码的健壮性,我们可以选择那些确实存在的列,而不是硬编码我们想要的列名。以下是如何做到这一点的方法:
cols_to_select = ['title', 'url', 'postTime', 'viewCount', 'collectCount', 'diggCount', 'commentCount']
existing_cols = [col for col in cols_to_select if col in df.columns]
df = df[existing_cols]
这样,即使某些列不存在,我们的代码也不会崩溃。
总结
在使用Pandas处理数据时,我们必须确保我们尝试访问的列确实存在于DataFrame中。通过动态地选择存在的列,我们可以确保代码的健壮性,即使数据源的结构发生了变化。
原创声明
======= ·
- 原创作者: 猫头虎
作者wx: [ libin9iOak ]
| 学习 | 复习 |
|---|---|
| ✔ |
本文为原创文章,版权归作者所有。未经许可,禁止转载、复制或引用。
作者保证信息真实可靠,但不对准确性和完整性承担责任。
未经许可,禁止商业用途。
如有疑问或建议,请联系作者。
感谢您的支持与尊重。
点击
下方名片,加入IT技术核心学习团队。一起探索科技的未来,共同成长。