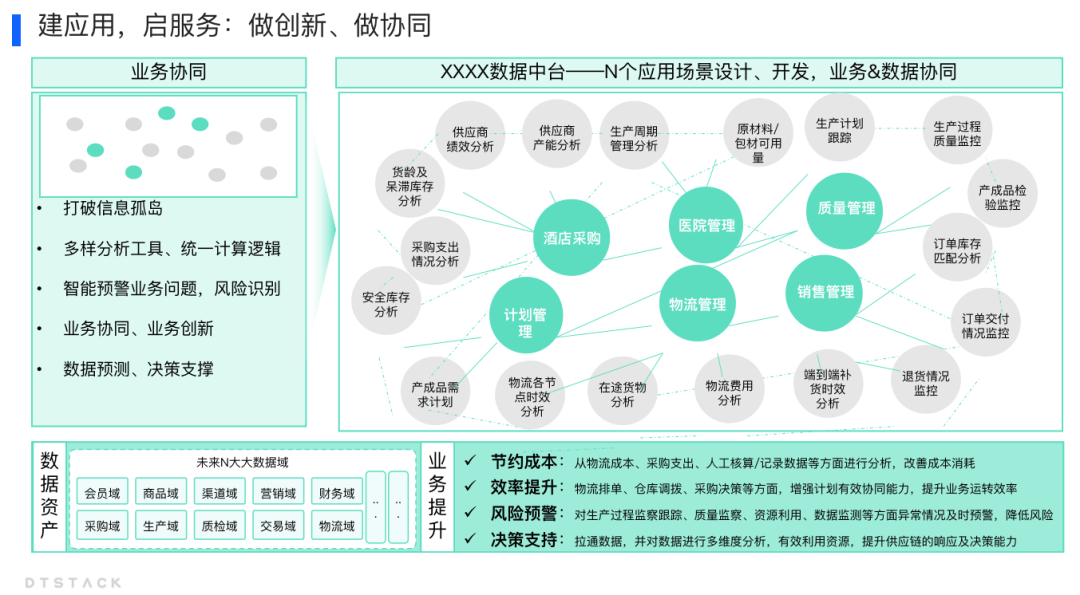
目录
- 0 写在前面
- 1 什么是机器学习?
- 2 ACM 班总教头:俞勇
- 3 动手学习机器学习
- 赠书活动
0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。强基计划实现从理论到实践的全面覆盖,由本人亲自从底层编写、测试与文章配套的各个经典算法,不依赖于现有库,可以大大加深对算法的理解。
🚀详情:机器学习强基计划(附几十种经典模型源码)
1 什么是机器学习?
摆在最前面的问题是:机器学习这么一个高大上的概念到底是什么?和传统编程逻辑有什么区别?
用一句话概括:机器学习是致力于研究如何通过计算的手段,利用经验产生模型以改善系统自身性能的学科
这里面有几个抽象的概念,什么是经验?什么是模型?怎么才算改善系统自身性能?接下来通过一个例子来具象化地说明一下。
在经济学中,个人的收入与消费之间存在着密切的关系。收入越多,消费水平也越高;收入较少,消费水平也较低。从一个社会整体来看,个人的平均收入x与平均消费y之间大致呈线性关系。现在我们看看路人甲的收入和消费水平的关系
收入x 消费水平y 1.0 0.5 1.2 0.8 1.5 1.3 现在的问题是:请问在一个社会中,收入水平为1.5的人群,消费水平如何?
首先,把路人甲的数据放在坐标系里可视化一下

在中学阶段,我们学过一个概念,叫线性最小二乘法,它的实现思路是:首先给出一个点集,然后用一条直线去拟合这个点集,使所有点到这条直线的距离最小——误差最小。现在让我们做出这样一条直线。

得出的这条直线能干嘛呢?能用来预测!我们现在可以根据这条直线来判断任意收入水平下,你的消费水平如何。
在这个例子中,这三个点就是经验,我们是根据路人甲已有的经验来预测的,在机器学习中,经验表现为数据;而这条直线就叫模型,模型体现的是数据内部蕴含的潜在模式和规律。
有人会说,你这也太扯淡了,就用一个人的三个数据就能做收入水平预测这么大的课题?
确实是这样,所以机器学习需要的数据量是非常大的,只有在大数据的支持下,得到的模型才有实际意义。比如说,我们又采样了一部分人群的数据,得到的结果如下

再次应用最小二乘法,我们发现直线变了。数据量越大、质量越高,其现实意义越强、偶然性越小。所以机器学习模型就会随之变得有效(称为泛化性,但这个概念后面再说),我们可以认为系统性能得到了改善。
这是符合我们人类认知规律的!随着我们经历的事情越来越多,阅历也就是经验越来越丰富,对事物的认识也越来越深刻。可能过去我们对某个事物的错误认识,会在接下来的人生阶段得到纠正,这就是机器学习的道理。
事实上,我们在高中就接触机器学习了,上面说的最小二乘法就是后面介绍线性回归等模型的理论基础!
所以机器学习的概念实质上并没有想象得那么高大上,就是机器模仿人的学习,从数据内部获得潜在客观规律的过程。
2 ACM 班总教头:俞勇
最近,彪悍的上海交大 ACM 班俞勇教授团队推出了一本重量级新书——《动手学机器学习》。这对于技术人来说是难得的福音,因为它一次性讲明白了机器学习这回事。
上海交大 ACM 班到底有多彪悍?看看它的杰出校友们吧。
科研领域有在斯坦福任教的杨笛一,有在卡耐基梅隆大学任教的陈天奇,他也是 XGBoost 作者、TVM发起人。企业界则有依图科技联合创始人林晨曦,第四范式创始人戴文渊。MXNet 的作者大神李沐,其所著的《动手学深度学习》更是诸多技术人的必读经典。
因此 ACM 班在业界享有中国 AI 人才的“黄埔军校”之称。了不起的成就背后是伟大的愿景,ACM 班的创立者俞勇教授一直在为培养中国的图灵奖得主而努力。颁发图灵奖的机构就是 ACM(美国计算机协会),可见俞勇教授给 ACM 班取名时就寄予了多么深切的期望。

3 动手学习机器学习
《动手学机器学习》的定位是在引领初学者入门,在内容设置上是从讲解基础理论算法开始,逐渐进入有监督学习模型与无监督学习模型的论述,力求让学习者系统化掌握机器学习的主干知识。
本书的主创团队有三位作者,除了总教头俞勇教授,还有将教学成果整理成书的张伟楠副教授,他在强化学习、数据挖掘、知识图谱等领域颇有建树。作者赵寒烨也在强化学习、机器学习方面有着深入的研究。
实力如此强劲的技术天团,为本书在业界树立了权威的标杆
下面对书中四个主要部分的内容进行说明。
- 机器学习基础
在基础部分,主要是帮助学习者抓住最核心的概念和原理,讲解了最基础的两个算法:KNN(K 近邻算法)和线性回归。基于这两个算法讨论了机器学习的基本思想与实验原则。
扎实掌握好这部分内容,就具备了在大部分机器学习场景中上手实践解决问题的能力。- 参数化模型
本部分主要是讨论监督学习任务的参数化模型,包括逻辑斯谛回归、双线性模型、神经网络与多层感知机、卷积神经网络、循环神经网络等内容。
这些方法的共通特征,主要是基于数据的损失函数对模型参数求梯度,进而更新模型。- 非参数化模型
这部分聚焦在监督学习的非参数化模型上,包括支持向量机、决策树、集成学习与梯度提升决策树等内容。之所以将非参数模型单独作为一个部分,是为了让学习者从原理和代码方面更好地体会与参数化模型的区别、优劣。- 无监督模型
本部分讨论了对于没有标注的数据进行处理的无监督学习方法,包括 K 均值聚类、主成分分析、概率图模型、EM 算法、自动编码器等内容。
对无监督学习进行了不同任务、不同技术角度的讨论,让学习者可以充分体会与监督学习的区别。
《动手学机器学习》的最大亮点就是为动手实践提供了傻瓜式的体验环境,主创团队将 ACM 班的实践成果精炼出来,理论与代码相结合,让学习者可以平滑上手。
书中包括机器学习的概念定义、理论分析和算法过程和可运行代码。学习者可根据自己的学习状况,灵活选择想要阅读的内容。
不过,毕竟不是零基础入门,在动手之前学习者要具备两项基础能力,一是数学概念和数理统计知识,包括矩阵运算、概率分布和数值分析方法等;二是基本的 Python 的编程能力,能看懂代码并调试运行。
本书丰富的技术案例涵盖了基础算法、监督学习的参数化模型与非参数化模型,以及非监督模型。对于书中提到的知识点,学习者都可以亲手实践。主创团队对代码示例进行了精心选择,力求功能简洁且易修改。
《动手学机器学习》的内容在成书之前就经过了 ACM 班的教学检验,书中的原理讲解、算法说明、代码案例都在教与学的互动中去芜存菁,可以说这本书就是思考与实践的淬炼结晶。
当先进的教学成果走出校园,在业界传播普及机器学习知识,推动了产业的发展时,也引得大佬们交口称赞。
从根本上说,机器学习是一门研究算法的学科,而这些算法的作用,就在于能够通过非显式编程的形式,利用经验数据提升某个任务的性能指标。
所以这里的难度在于,即使我们理解了算法,也无法从结果倒推回去,这是难以还原的。显式编程则直观得多,直接针对问题给出解答,例如要对一组数据排序,就实现一个快速排序算法。
对于学习者来说,要将机器学习在自己的业务领域内应用好,就要转变思维,“往后站一步”,从显式编程转为编写机器学习算法程序。这就是非显式编程的含义,在不同任务中,基于任务自身的数据,训练出一个解决问题的模型。

《动手学机器学习》就是要帮助学习者系统化地理解机器学习,弄明白算法原理,学会用非显式编程解决自己的问题。书中对每种算法都给出了开箱即用的示例代码,学习者轻松扩展一下就可以用在实际工作中。
赠书活动

本文赠书四本,规则如下
【抽奖方式】
- 关注博主,点赞收藏文章,并做出有效评论
- 根据评论记录随机抽取用户赠送实体图书
- 订阅机器学习强基计划必得实体图书一本
- 截止日期:8.27日晚8点,届时通过blink公布获奖信息,请中奖用户及时私信
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《运动规划实战精讲》
- …