文章目录
- 前言
- 1、批量插入或者查询数据库
- 2、异步思想 耗时操作,考虑放到异步
- 3、空间换时间思想:恰当使用缓存。
- 4. 预取思想:提前初始化到缓存
- 5、借用线程池
- 6. 事件回调思想:拒绝阻塞等待。
- 7、锁粒度避免过粗
- 8、切换存储方式:文件中转暂存数据
- 9、索引
- 10、 优化SQL
- 11、避免大事务的问题
- 12、 深分页问题
- 13、优化程序结构
- 14、压缩传输内容
- 15、线程池设计要合理
- 16、机器问题 (fullGC、线程打满、太多IO资源没关闭等等)
前言
在工作中大家会遇到接口响应慢的问题,导致线上用户在等待,现在总结出了18中接口方案的优化,供大家参考,如果有遗漏请大家也留言补充。
1、批量插入或者查询数据库
随着数据的增加,数据库查询的性能也在增加,因此我们需要优化数据库的每次查询或者插入的数量,来保证数据。
反例:
//直接遍历插入,数据量大,耗时
for(User user :list){insert(user);
}
正例
batchInsert(list);//批量插入,每次按照一定的数量进行插入
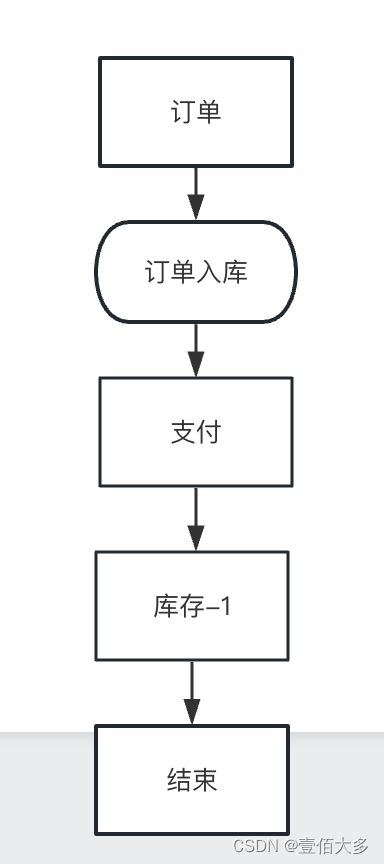
2、异步思想 耗时操作,考虑放到异步
耗时操作,考虑用异步处理,这样可以降低接口耗时。
反例
正例
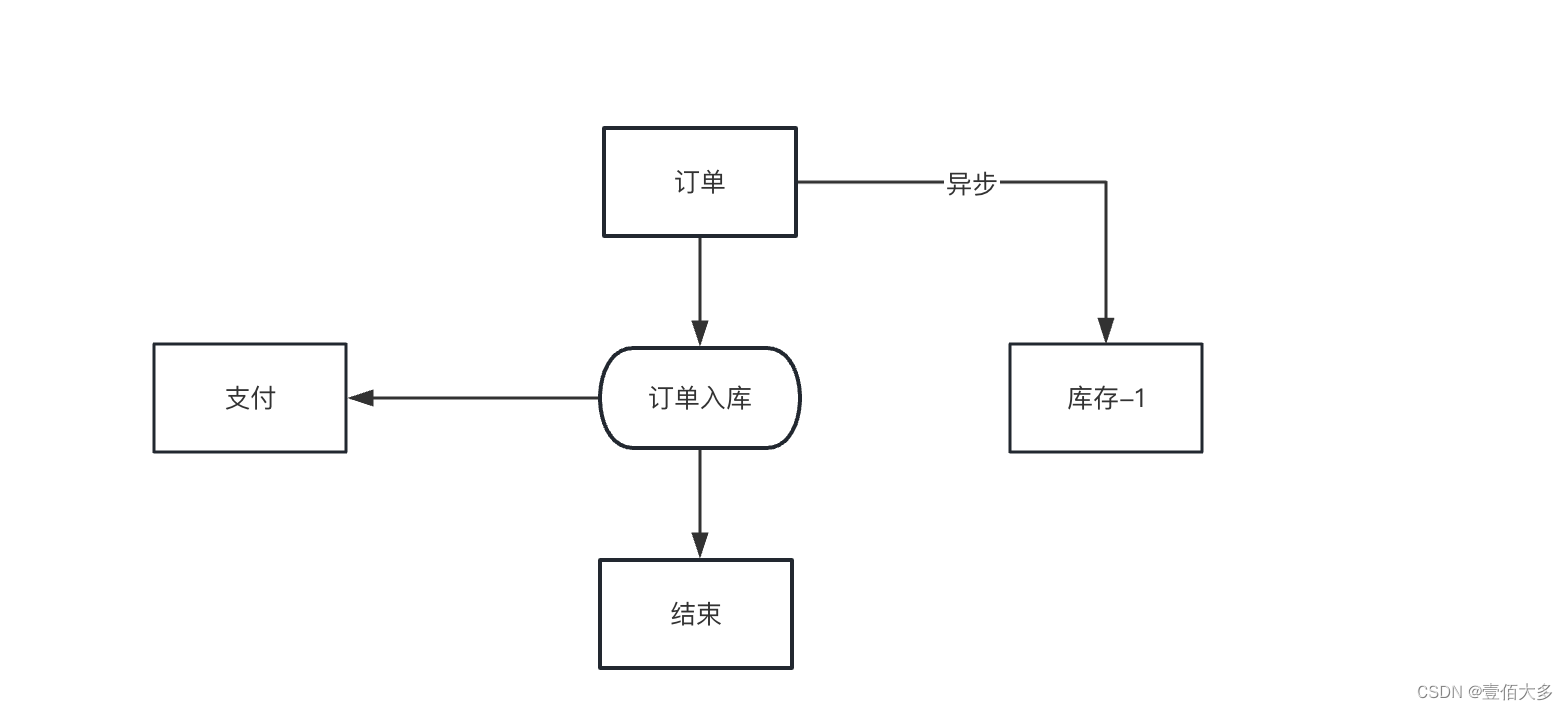
异步的实现方式,你可以用线程池,也可以用消息队列实现。
3、空间换时间思想:恰当使用缓存。
在适当的业务场景,恰当地使用缓存,是可以大大提高接口性能的。缓存其实就是一种空间换时间的思想,就是你把要查的数据,提前放好到缓存里面,需要时,直接查缓存,而避免去查数据库或者计算的过程。
这里的缓存包括:Redis缓存,JVM本地缓存,memcached,或者Map等等。我
4. 预取思想:提前初始化到缓存
预取思想很容易理解,就是提前把要计算查询的数据,初始化到缓存。如果你在未来某个时间需要用到某个经过复杂计算的数据,才实时去计算的话,可能耗时比较大。这时候,我们可以采取预取思想,提前把将来可能需要的数据计算好,放到缓存中,等需要的时候,去缓存取就行。这将大幅度提高接口性能
5、借用线程池
线程池可以帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。
如果你每次需要用到线程,都去创建,就会有增加一定的耗时,而线程池可以重复利用线程,避免不必要的耗时。 池化技术不仅仅指线程池,很多场景都有池化思想的体现,它的本质就是预分配与循环使用。
6. 事件回调思想:拒绝阻塞等待。
如果你调用一个系统B的接口,但是它处理业务逻辑,耗时需要10s甚至更多。然后你是一直阻塞等待,直到系统B的下游接口返回,再继续你的下一步操作吗?这样显然不合理。
我们参考IO多路复用模型。即我们不用阻塞等待系统B的接口,而是先去做别的操作。等系统B的接口处理完,通过事件回调通知,我们接口收到通知再进行对应的业务操作即可。
7、锁粒度避免过粗
在高并发的情况下,为了保证数据的正确性,需要加锁。
因为加锁的效率肯定会变低,因此锁的范围就显得很重要,因此我们需要更细力度的去加锁,而不是将整个代码块都进行加锁。
反例
Lock lock=new ReentrantLock();
lock.lock
//这里不管有没有数据安全问题都进行加锁
lock.unlock();
反例
Lock lock=new ReentrantLock();
lock.lock
//只锁可能出现数据安全的地方
//这里如果是写出现的数据问题,就加写锁,如果为读出现的问题,就加读锁。
lock.unlock();
8、切换存储方式:文件中转暂存数据
如果数据量太大,就会导致数据库的执行会特别缓慢,这时候要考虑,先保存到本地,然后在去异步写入到数据库。
9、索引
索引优化这块的话,一般从这几个维度去思考:
你的SQL加索引了没?
你的索引是否真的生效?
你的索引建立是否合理?(主要是根据数据量的大小,当前加索引列的更新是否频繁,当前的索引是否太多)
10、 优化SQL
1、select 具体的字段,而不是select *
2、多用limit
3、尽量用union all 代替union
4、优化group by
5、优化order by
6、小表驱动大表
7、字段字段类型使用是否合理
8、优化limit分页
9、exist&in的合理利用
10、join关联的表不宜过多
11、delete+in子查询不走索引
12、in的元素不能太多
11、避免大事务的问题
为了保证数据库数据的一致性,在涉及到多个数据库修改操作时,我们经常需要用到事务。而使用spring声明式事务,又非常简单,只需要用一个注解就行@Transactional
正例
@Transactional
public int createUser(User user){//保存用户信息userDao.save(user);passCertDao.updateFlag(user.getPassId());return user.getUserId();
}
反例
@Transactional
public int createUser(User user){//保存用户信息userDao.save(user);passCertDao.updateFlag(user.getPassId());sendEmailRpc(user.getEmail());return user.getUserId();
}
这样实现可能会有坑,事务中嵌套RPC远程调用,即事务嵌套了一些非DB操作。如果这些非DB操作耗时比较大的话,可能会出现大事务问题。
所谓大事务问题就是,就是运行时间长的事务。由于事务一致不提交,就会导致数据库连接被占用,即并发场景下,数据库连接池被占满,影响到别的请求访问数据库,影响别的接口性能。
大事务引发的问题主要有:接口超时、死锁、主从延迟等等。因此,为了优化接口,我们要规避大事务问题。我们可以通过这些方案来规避大事务:
RPC远程调用不要放到事务里面
一些查询相关的操作,尽量放到事务之外
事务中避免处理太多数据
12、 深分页问题
深分页问题,为什么会慢?我们看下这个SQL
select id,name,balance from account where create_time> ‘2020-09-19’ limit 100000,10;
limit 100000,10意味着会扫描100010行,丢弃掉前100000行,最后返回10行。即使create_time,也会回表很多次。
我们可以通过标签记录法和延迟关联法来优化深分页问题。
标签记录法
就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
假设上一次记录到100000,则SQL可以修改为:
select id,name,balance FROM account where id > 100000 limit 10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了id主键索引。但是这种方式有局限性:需要一种类似连续自增的字段。
延迟关联法,就是把条件转移到主键索引树,然后减少回表。优化后的SQL如下:
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > ‘2020-09-19’ limit 100000, 10) AS acct2 on acct1.id= acct2.id;
优化思路就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
13、优化程序结构
避免创建不必要的对象,避免数据库查询出来不需要的数据等
14、压缩传输内容
压缩传输内容,传输报文变得更小,因此传输会更快啦。10M带宽,传输10k的报文,一般比传输1M的会快呀。
15、线程池设计要合理
我们使用线程池,就是让任务并行处理,更高效地完成任务。但是有时候,如果线程池设计不合理,接口执行效率则不太理想。
一般我们需要关注线程池的这几个参数:核心线程、最大线程数量、阻塞队列。
如果核心线程过小,则达不到很好的并行效果。
如果阻塞队列不合理,不仅仅是阻塞的问题,甚至可能会OOM
如果线程池不区分业务隔离,有可能核心业务被边缘业务拖垮。
16、机器问题 (fullGC、线程打满、太多IO资源没关闭等等)
有时候,我们的接口慢,就是机器处理问题。主要有fullGC、线程打满、太多IO资源没关闭等等。
之前排查过一个fullGC问题:运营小姐姐导出60多万的excel的时候,说卡死了,接着我们就收到监控告警。后面排查得出,我们老代码是Apache POI生成的excel,导出excel数据量很大时,当时JVM内存吃紧会直接Full GC了。
如果线程打满了,也会导致接口都在等待了。所以。如果是高并发场景,我们需要接入限流,把多余的请求拒绝掉。
如果IO资源没关闭,也会导致耗时增加。这个大家可以看下,平时你的电脑一直打开很多很多文件,是不是会觉得很卡。
文章参考GZH:捡田螺的男孩

![java八股文面试[JVM]——JVM内存结构](https://img-blog.csdnimg.cn/71e5729699b94462afab8e548c4d8db3.png#pic_center)