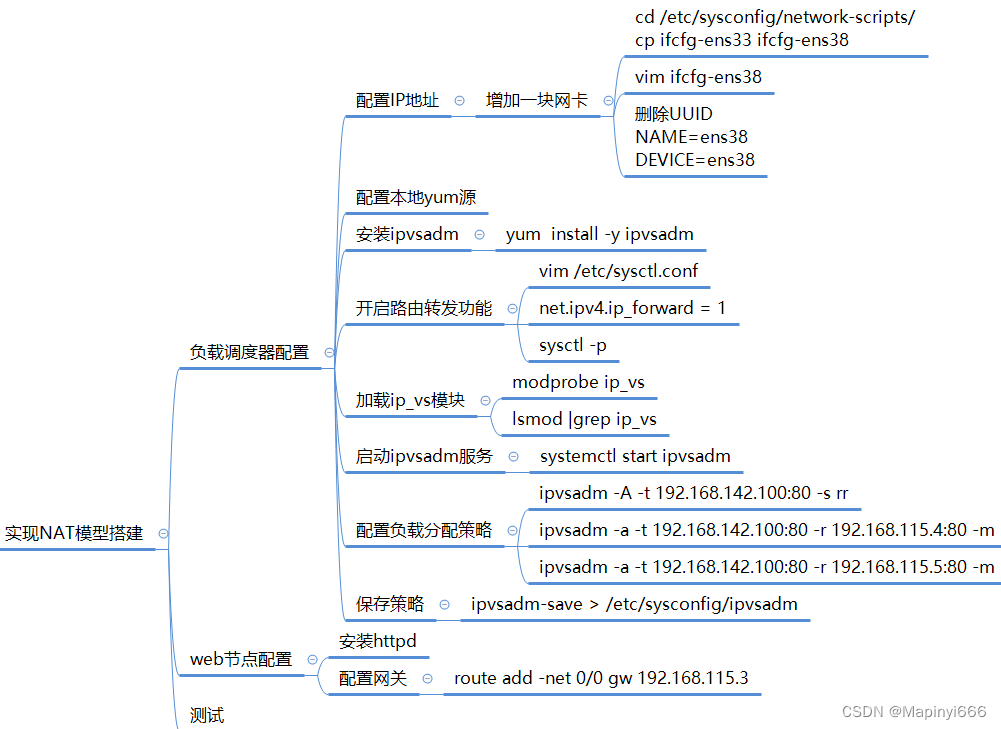
目录
前言:
string
相关命令
内部编码
应用场景
hash
相关命令
内部编码
应用场景
list
相关命令
内部编码
应用场景
set
相关命令
内部编码
应用场景
Zset
相关命令
内部编码
应用场景
渐进式遍历
前言:
redis有多种数据类型,常用的有五种,其他都是在特定场景下使用的数据类型。具体需要使用时可以去redis官网中查阅。这篇文章将详细介绍常用五种数据类型。
string
redis中的字符串,直接按照二进制的方式存储(不会做任何编码转换,怎么存就怎么取)
限制大小最大是512M(单线程操作都比较快)
注意:
当set key时,如果是覆盖了之前的value,那么之前的ttl(生存时间)也会失效,类型可能也会改变(具体的内部编码)。
相关命令
ex:设置过期时间(单位:秒) px:设置过期时间(单位:毫秒) NX:只有key不存在时才设置。如果key之前存在,设置不执行 XX:只有key存在时才设置,如果key之前不存在,设置不执行
SET key value [expiration EX seconds|PX milliseconds] [NX|XX] // 存储数据
mset key [key...] // 同时存储多个key
mget key [key...] // 同时获取多个key
setNX key // 不存在时才能设置,存在则设置失败
setEX key seconds value // 存储key并且设置过期时间(秒)
psetEX key 毫秒 value // 存储key并且设置过期时间(毫秒)
incr key // key + 1(key不存在则把这个key的value当做0来使用)(操作value需要是整数)
incrby key n // key + n
decr key // key - 1
decrby key n // key - n
incrbyfloat value // key + value(操作小数)
append key value // 字符串拼接(返回值:拼接后的长度。单位:字节)
getrange key start end // 截取子字符串,左闭右闭,单位:字节(-1:倒数第一个元素)(汉字很可能切出来的不完整)
setrange key offset value // 替换字符串,返回值:替换后字符串长度,单位:字节。针对不存在的key也可以操作,会把offset之前字节填充为0X00
strlen key // 获得字符串长度,单位:字节 内部编码
1)int 8字节/64位的整数。
2)embstr 压缩字符串(对数据重新进行编码,占用更小的内存空间),表示比较短的字符串。
3)raw 普通字符串,表示比较长的字符串,单纯使用字节数组存储。
应用场景
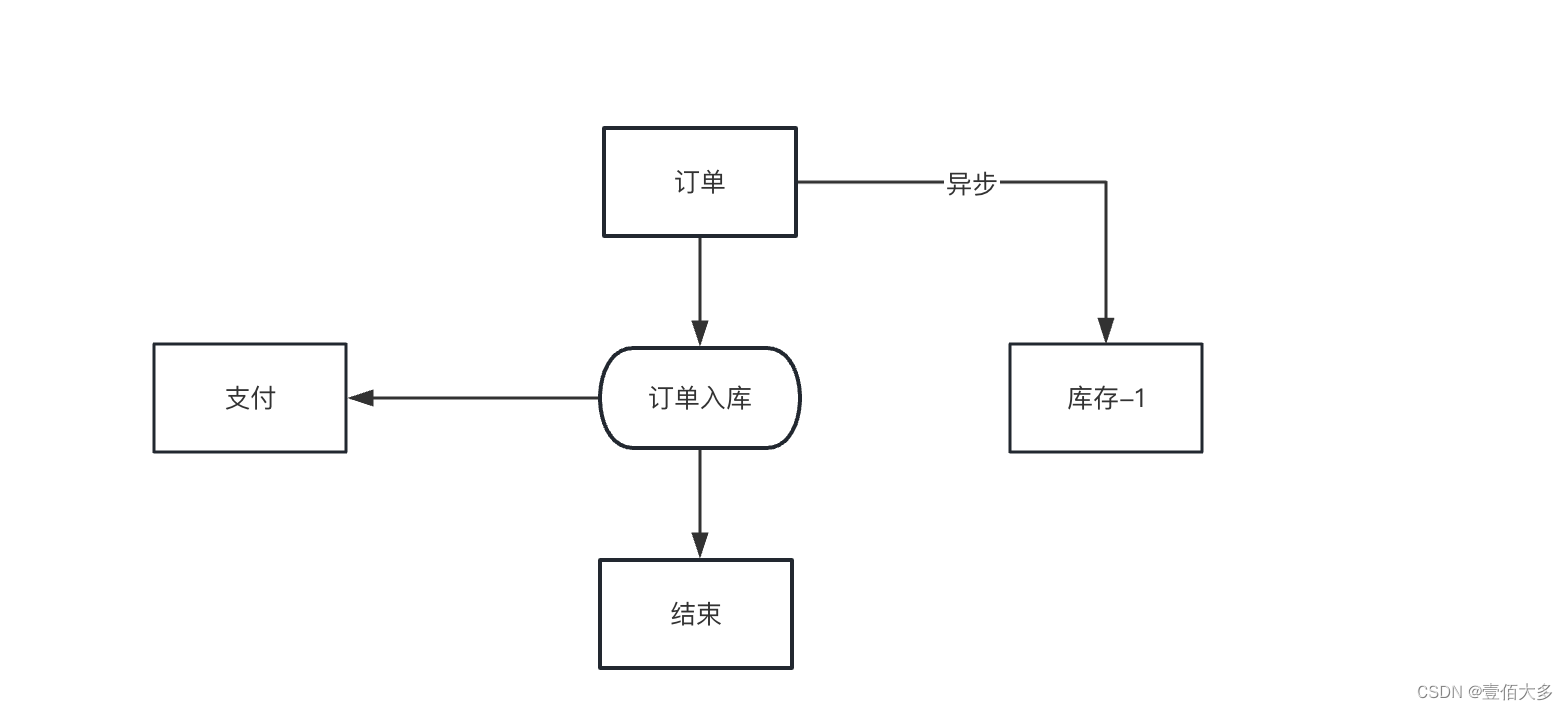
1)缓存
用户先访问缓存,如果没有数据,则查找数据库,同时同步到redis中。
防止redis中数据量太大:1)redis中的key设置过期时间 。2)redis内存不足时,可以使用内存淘汰策略。
2)统计数据
redis中的数据异步的写入数据库中,进行数据分析统计。
3)存储会话
分布式系统中,服务器集群共享一份会话信息,就可以判断用户的登录状态。(就算负载均衡把请求打到不同的服务器,也没事)
4)手机验证码
获取验证码间隔60秒,可以使用redis存储验证码,并且设置过期时间。
hash
key-value的存储方式,在redis中数据key被称为field。
相关命令
hset key field value [field value...] // 存储键值对
hget key field // 获取键值对
hexists key field 判断fileld是否存在,返回值:1存在 0不存在
hdel key field [field...] // 删除指定field,返回值:成功删除的个数
hkeys key // 获取哈希表中的所有field,时间复杂度:O(N)N哈希表中元素个数
hvals key // 获取哈希表中所有value,时间复杂度:O(N)N哈希表中元素个数
hgetall key // 获取hash表中所有field,value。时间复杂度:O(N)N哈希表中元素个数
hmget key field [field...] // 获取多个field的value值
hstrlen key field // 计算value字符串长度
hlen key // 获取哈希表中元素个数,不需要遍历
hsetnx key field value // 不存在时才设置成功,存在则设置失败
hincrby key field n // value + n(操作整数)
hincrbyfloat key field n // value + n(操作小数)内部编码
ziplist hashtable
哈希表中的元素比较少,使用ziplist。如果元素比较多,使用hashtable表示。
哈希表中value长度比较短,使用ziplist。如果value长度比较长,使用hashtable。
注意:
ziplist进行读写元素,速度比较慢。
应用场景
作为缓存,可以存储结构化数据(对象)。
list
列表,内部数据结构可以认为是双端队列。同时redis提供了阻塞版本的操作命令。
相关命令
lpush key value [value...] // 头插法,返回值:list长度
lrange key start stop // 范围获取数据,前闭后闭,越界会尽量显示list中的数据,下标支持负数
rpush key value [value...] // 尾插法,返回值:list长度
rpushx key value // key存在才会入数据,x:exists
lpop key // 头删,返回删除的元素
rpop key // 尾删,返回删除的元素
lindex key index // 给定下标,获取元素。O(N)
linsert key before|after pivot value // 指定基准前或后插入数据。如果存在多个基准,从左往右找,找到第一个基准值进行插入。O(N)
llen key // 获取list长度
lrem key count value // 删除指定元素,count为数量。count > 0从左往右删count个。count < 0从右往左删count个。count = 0删除list中所有value
ltrim key start stop // 保留这个区间数据,删除其他所有数据。闭区间
lset key index value // 根据下标,修改元素。越界会报错
blpop key [key...] timeout // 如果队列为空出数据则阻塞(阻塞期间redis可以执行其他命令),只要某一个key不为空,则立刻出数据
brpop key [key...] timeout
内部编码
使用quicklist,结合了ziplist和linkedlist。每个链表节点中都是ziplist

应用场景
1)作为数组,存储多个元素
存储mysql中表中的关联字段。结构化数据可使用hash存储。可以将关系型数据库中的数据进行映射。
2)作为消息队列(生产者消费者模型)
可以使用阻塞版本的操作,实现生产者消费者模型。客户端和服务器之间的中间列表就可以做到一个缓冲功能。
注意:
如果使用for循环list,使用hgetall获取每个hash中数据,会存在多次网络请求,可能会阻塞redis服务器。
解决方案:使用pipeline(流水线|管道)将多个redis命令合并为一条命令。进行网络通信。
如果list中数据量太大,范围查找中间数据,效率会比较低。
解决方案:将一个list分为多个list(类似,分库分表)
set
1)集合中的元素是无序的(变换顺序还是原来那个set)
2)集合中的元素不能重复。
3)和list类似,集合中的每个元素也是string类型。
相关命令
sadd key member [member...] // 存储元素,返回值添加成功了几个元素
smembers key // 查询集合中所有member
sismember key member // 判断集合中member是否存在。1表示存在,0表示不存在
scard key // 返回集合中元素个数
spop key [count] // 随机删除set中的数据,count可以指定一次删除多个
smove source destination member // 从source中删除,再插入到distination中
srem key member [member...] // 从set中删除member
sinter key [key...] // 返回多个key的交集。O(N * M) N:最小集合元素个数,M:最大集合元素个数
sinterstore destination key [key...] / 返回多个key集合数据存储在destination集合中。返回交集元素个数。O(N)
sunion key [key...] // 返回多个key的并集。O(N)
sunionstore destination key [key...] // 将多个key的并集存储在destination集合中。返回并集元素个数。O(N)
sdiff key [key...] // 返回多个Key的差集,前面key - 后面key,和key的顺序有关联。O(N)
sdiffstore destination key [key...] // 将差集存储在destination集合中,返回差集元素个数。O(N)内部编码
1)intset 当元素均为整数,并且元素个数不是很多。
2)hashtable 其他都是用哈希表存储了。
应用场景
1)保存用户标签(用户画像)。大数据时代下,为每个用户建立表标签(特点),方便服务器进行用户分析,进行数据推送。(每个用户都是相互独立的存在)
2)计算用户之间共同好友,可以做一些好友推荐。(可以使用集合间运算)
3)争对业务场景进行去重。
Zset
1)value采用member和score的方式存储,内部会根据每个member的score进行排序。
2)有序集合。member必须唯一,score可以重复。底层默认按照score升序排列。
相关命令
时间复杂度:O(logN) 底层是跳表,需要遍历跳表找到指定位置进行插入,保证集合有序
分数相同按照member字典序排列
zadd key [NX | XX] [CH] [INCR] score member [score member...] // 返回值:有序集合添加元素的个数 时间复杂度:O(logN) NX:member不存在就添加 XX:member存在就修改 CH:修改返回值为修改集合member的个数 INCR:指定member增加score
zrange key start stop [withscores] // 查找有序集合范围中的member,withscores:同时可以查找score
zcard key // 返回集合中元素个数
zcount key min max // 返回指定分数区间中元素个数,使用(来设置开区间。时间复杂度:O(logN)) 需要查找第一个start元素。inf:正无穷大 -inf:负无穷大
zrevrange key start stop [withscores] // 逆序查找出来的集合,按照分数降序
zrangebyscore key min max [withscores] // 查找指定score区间中的member。时间复杂度:O(logN + M)M:max - min
zpopmax key [count] // 删除并返回最高的count个元素。返回值:被删除的member和score。如果存在多个分数最大的元素,只删除member字典序大的数据。时间复杂度:O(logN * M)需要找到每个元素进行删除,底层使用通用的删除函数
bzpopmax key [key...] timeout // 带有阻塞的弹出,如果为空就会阻塞。和blpop机制一样。时间复杂度:O(logN)需要找到数据
zpopmin key [count] // 删除score最小的count个元素。时间复杂度:O(logN + M)
bzpopmin key [key...] timeout // 带有阻塞的弹出
zrank key member // 返回member的下标,从左往右由0开始。时间复杂度:O(logN)
zrevrank key member // 返回member下标,从右往左由0开始
zscore key member // 根据member找到score。时间复杂度:O(1) redis在这里做了特殊优化
zrem key member [member...] // 删除指定的member。时间复杂度:O(logN * M) 需要一个一个删除。M命令中member的个数
zremrangebyrank key start stop // 根据下标进行范围删除。时间复杂度:O(logN + M) M:stop - start
zremrangebyscore key min max // 根据score进行范围删除。(可设置开区间。时间复杂度:O(logN + M) M:max - min
zincrby key increment member // 指定member对score + increment。时间复杂度:O(logN)
zinterstore destination numkeys key [key...] [weights weight [weight...]] [aggregate < sum | min | max] // 求多个key的交集存在destination中。weights:指定key的权重,最终结果会将key中所有score * weight作为结果。aggregate:交集中score相同的处理选择。时间复杂度:O(logM * M)近似值,M:最终结果有序集合元素个数
zunionstore destination numkeys key [key...] [weights weight [weight...]] [aggregate < sum | min | max] // 用法和上述一致内部编码
1)ziplist 如果有序集合中元素较少,或者单个元素体积较小。
2)skiplist 如果有序集合中元素较多,或者单个元素体积很大。跳表:查询元素时间复杂度log(N)
应用场景
排行榜系统。微博热搜,游戏天梯排行,成绩排行。
微博热搜,可以根据多维度数据进行加权计算,得到最终的综合得分(热度)。每个维度使用有序集合存储(id, score)然后进行集合间运算,就可以使用加权计算出最终的热度排行。
渐进式遍历
pattern:key的匹配模式
count:建议命令一次遍历几个元素,具体是几个是在count上下浮动
type:指定遍历key的value类型
cursor:光标,字符串。下次开始遍历的位置
scan cursor [MATCH pattern] [COUNT count] [TYPE type]注意:
渐进式遍历,在遍历过程中,不会在服务器这边存储任何状态信息。此处遍历是可以随时终止的,不会对服务器产生任何副作用。
渐进式遍历虽然解决了阻塞问题,但如果遍历过程中键有所变化(增加,修改,删除),可能导致遍历时键的重复遍历或者遗漏。开发中务必需要考虑。









![java八股文面试[JVM]——JVM内存结构](https://img-blog.csdnimg.cn/71e5729699b94462afab8e548c4d8db3.png#pic_center)