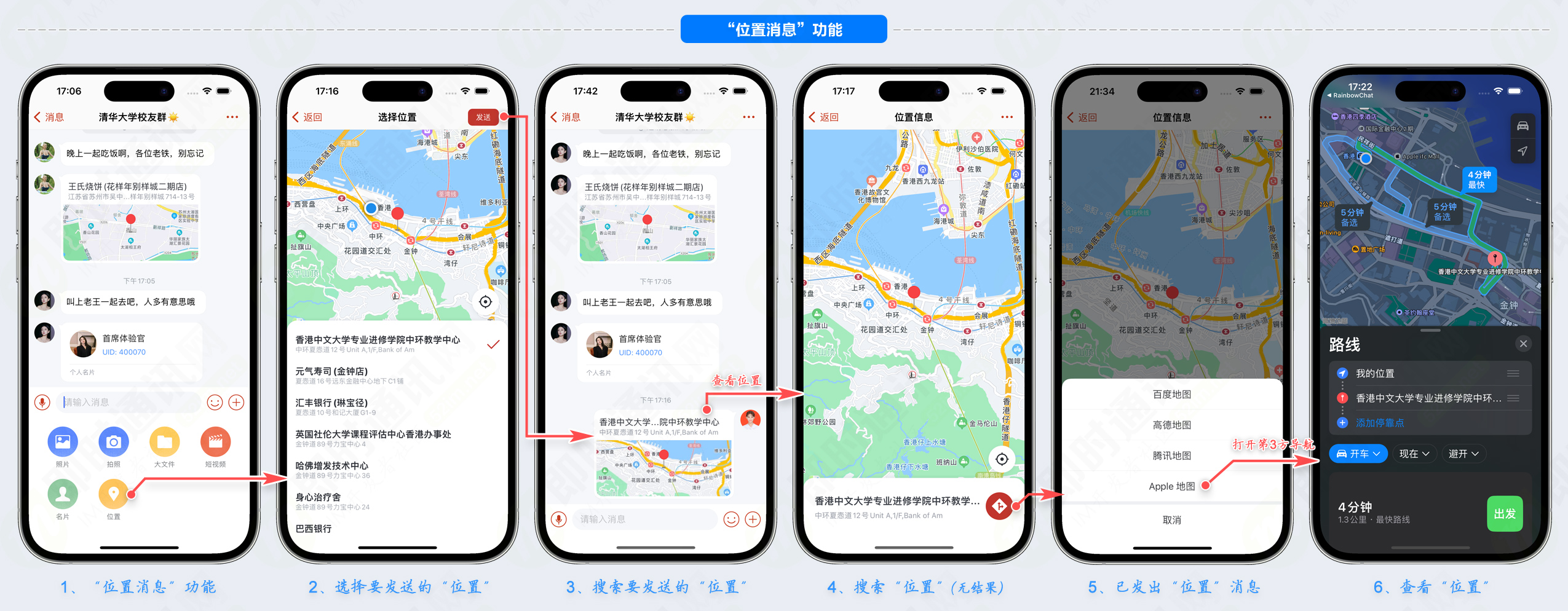
比较不同算法的准确度,选择合适的算法,在处理机器学习的问题时是非常重要的。本节将介绍一种模式,在scikit-learn中可以利用它比较不同的算法,并选择合适的算法。你可以将这种模式作为自己的模板,来处理机器学习的问题;也可以通过对其他不同算法的比较,改进这个模板。
在本节将会学习以下内容:
- 如何设计一个实验来比较不同的机器学习算法。
- 一个可以重复利用的、用来评估算法性能的模板。
- 如何可视化算法的比较结果。
选择最佳的机器学习算法
当参与一个机器学习的项目时,会经常因为如何选择一种合适的算法模型而苦恼。每种模型都有各自适合处理的数据特征,通过交叉验证等抽样验证方式可以得到每种模型的准确度,并选择合适的算法。通过这种评估方式,可以找到一种或两种最适合问题的算法。
当得到一个新的数据集时,应该通过不同的维度来审查数据,以便于找到数据的特征,这种方法也适用于选择算法模型。同样需要从不同的维度,用不同的方法来观察机器学习算法的准确度,并从中选择一种或两种对问题最有效的算法。一种比较好的方法是通过可视化的方式来展示平均准确度、方差等属性,以便于更方便地选择算法。接下来就介绍如何通过scikit-learn来实现对算法的比较。
机器学习算法的比较
最合适的算法比较方法是:使用相同的数据、相同的方法来评估不同的算法,以便得到一个准确的结果。下面将使用同一个数据集来比较六种分类算法,以便选择合适的算法来解决问题。
- 逻辑回归(LR)。
- 线性判别分析(LDA)。
- K近邻(KNN)。
- 分类与回归树(CART)。
- 贝叶斯分类器。
- 支持向量机(SVM)。
我们继续使用 Pima Indians 数据集来介绍如何比较算法。这个数据集是一个二分类数据集,结果只有两个分类;用来训练算法模型的数据是八种全部由数字构成的属性特征值。采用10折交叉验证来分离数据,并采用相同的随机数分配方式来确保所有的算法都使用相同的数据。为了便于整理结果,给每一种算法设定一个短名字。
代码如下:
import pandas as pd
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrixfrom sklearn.model_selection import cross_val_score, ShuffleSplit, train_test_split, KFold
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]
# 分割数据集
n_splits = 10seed = 7kflod = KFold(n_splits=n_splits, random_state=seed, shuffle=True)models = {}models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['SVM'] = SVC()
models['NB'] = GaussianNB()results = []for key in models:result = cross_val_score(models[key], X, Y, cv=kflod)results.append(result)print("%s: %.3f (%.3f)" % (key, result.mean(), result.std()))#图表展示
import matplotlib.pyplot as pltfig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)ax.set_xticklabels(models.keys())
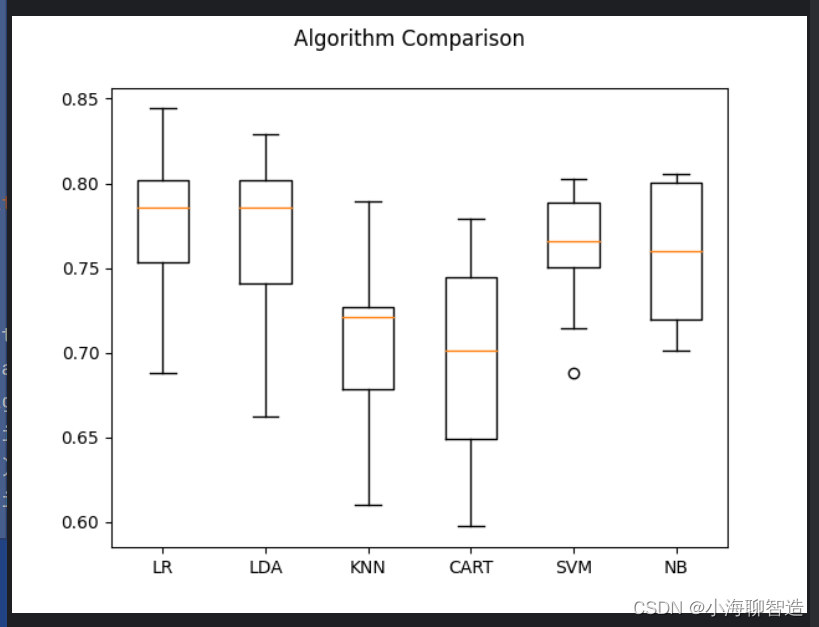
plt.show()运行结果:
执行结果给出了每种算法的平均准确度和标准方差
LR: 0.776 (0.045)
LDA: 0.767 (0.048)
KNN: 0.711 (0.051)
CART: 0.693 (0.059)
SVM: 0.760 (0.035)
NB: 0.759 (0.039)
同时也可以通过箱线图展示算法的准确度,以及10折交叉验证中每次验证结果的分布状况。其执行结果如图
本节给出了一种对多种算法进行分析比较的方法。通过这个方法可以找到一种或两种算法对给定数据集能够生成准确度最高的模型,从而选择合适的算法。这个方法也可以应用到所有机器学习的问题中。接下来将学习在scikit-learn中如何通过Pipelines来实现自动化流程处理。


![[MyBatis系列④]核心配置文件](https://img-blog.csdnimg.cn/bc3e9339d22f48d6a744edface62c793.png)