一、B+树和B树区别
二、 B+ 树形成过程
三、页分裂过程
3.1 页分裂过程实例
3.1.1 原有数据1、3、5形成如下数据页
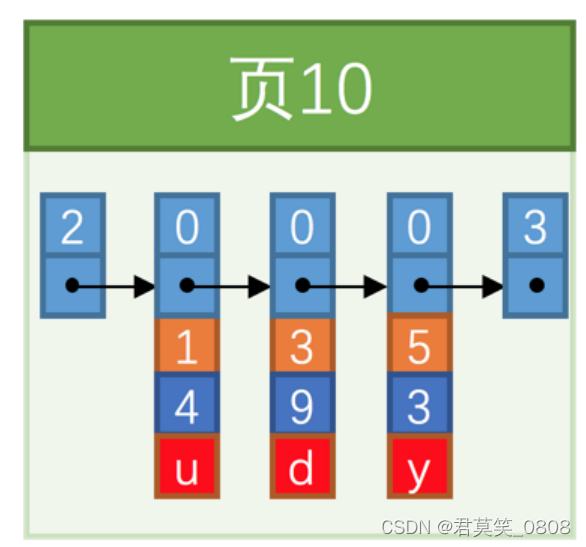
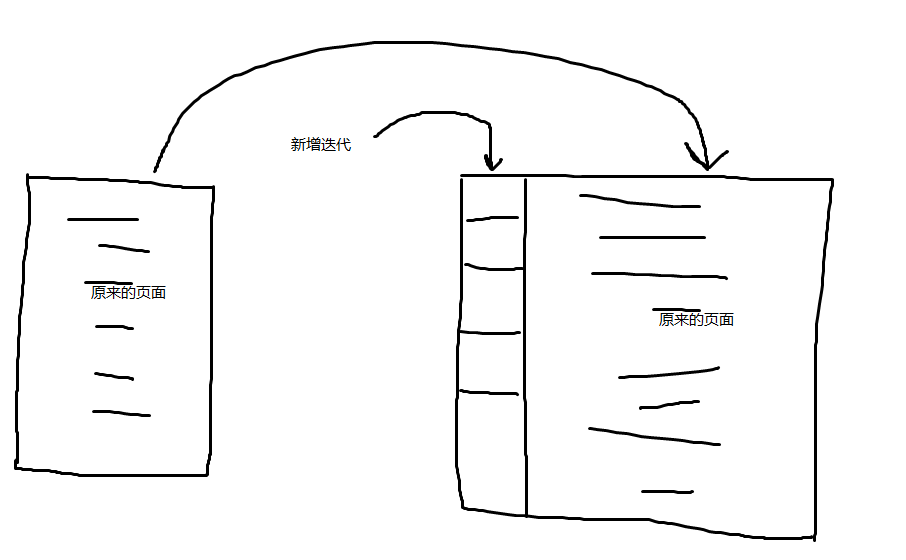
3.1.2 先新插入数据4,因为 页10 最多只能放3条记录所以我们不得不再分配一个新页:
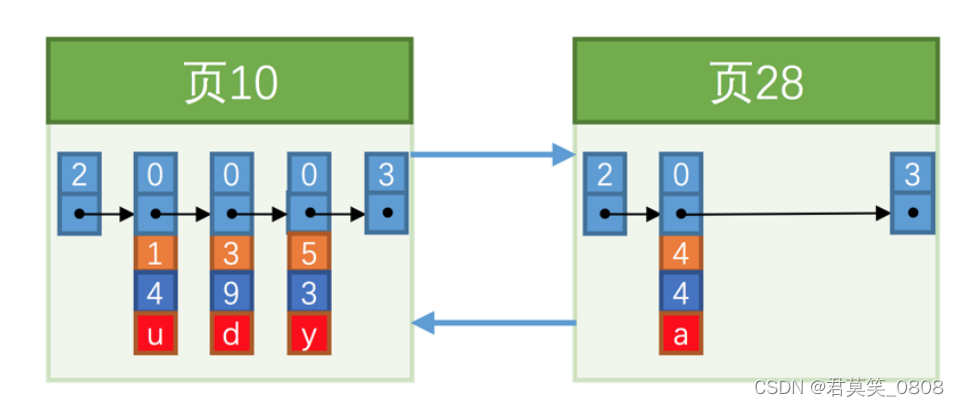
新分配的数据页编号可能并不是连续的,也就是说我们使用的这些页在存储空间里可能并不挨着。它们只是通过维护着上一个页和下一个页的编号而建立了链表关系。另外,页10 中用户记录最大的主键值是 5 ,而 页28 中有一条记录的主键值是 4 ,因为 5 > 4 ,所以这就不符合下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所 以在插入主键值为 4 的记录的时候需要伴随着一次记录移动,也就是把主键值为 5 的记录移动到 页28 中, 然后再把主键值为 4 的记录插入到 页10 中,这个过程的示意图如下:
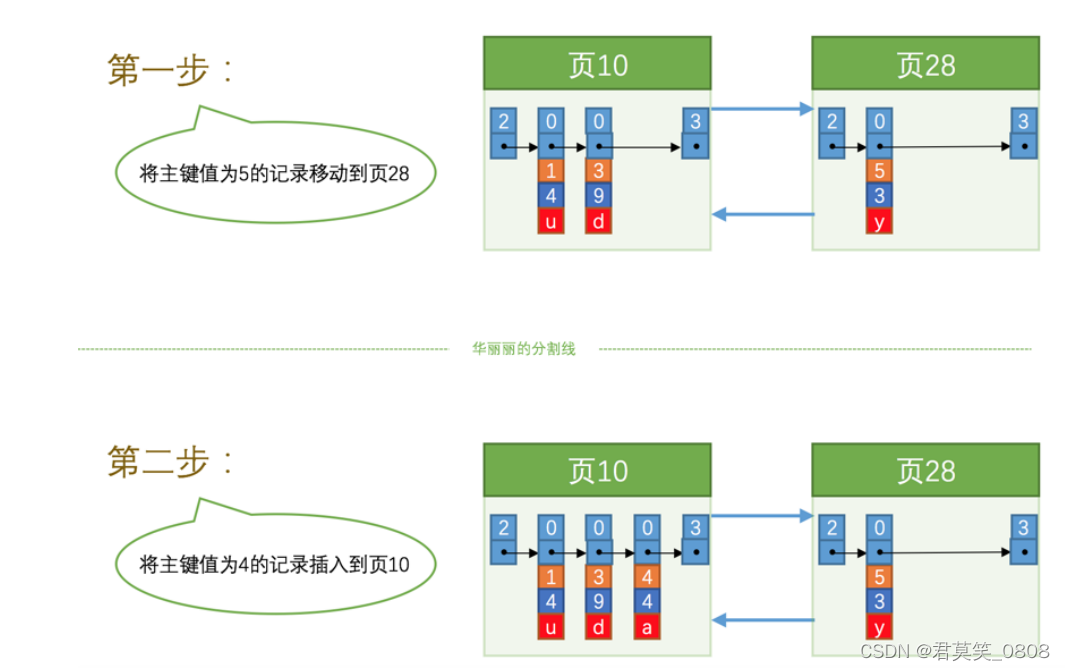
这个过程表明了在对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作来始终保 证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。这个过程 我们也可以称为 页分裂 。
3.2 B+树形成过程
数据页的编号可能并不是连续的,所以在向 i表中插入许多条记录后,可能是这样的效果:

16KB 的页在物理存储上可能并不挨着,如果想从这么多页中根据主键值快速定位某些记录所在的页,我们需要给它们做个目录,每个页对应一个目录项,每个目录项包括下边两个部分:
1、页的用户记录中最小的主键值,我们用 key 来表示。
2、页号,我们用 page_no 表示。
最终形成如下图所示结构:

3.3 根据目录项查找数据
页28对应目录项2,这个目录项包含着该页的页号 28 以及该页中用户记录的最小主键值 5 。我们只需要把几个目录项在物理存储器上连续存储,比如把他们放到一个数组里,就可以实现根据主键值快速查找某条记录的功能了。比方说我们想找主键值为 20 的记录,具体查找过程分两步:
1、先从目录项中根据二分法快速确定出主键值为 20 的记录在 目录项3 中 12 < 20 < 209 ,它对应的页是 页9 。
2、根据前边说的在页中查找记录的方式去页9 中定位具体的记录。至此,针对数据页做的简易目录就搞定了。不过忘了说了,这个 目录 有一个别名,称为索引 。
四、InnoDB中的索引方案
4.1 目录项记录
复用了之前存储 用户记录的数据页来存储目录项,为了和用户记录做一下区分,我们把这些用来表示目录项的记录称为 目录项记录 。区分目录项和用户记录使用record_type 属性。
0:普通的用户记录
1:目录项记录
2:最小记录
3:最大记录
目录项记录和普通的 用户记录 的不同点:
1、目录项记录 的 record_type 值是1,而普通用户记录的 record_type 值是0。
2、目录项记录只有主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列,另外还有 InnoDB 自己添加的隐藏列。
3、只有在存储 目录项记录 的页中的主键值最小的 目录项记录 的 min_rec_mask 值为 1 ,其他别的记录的 min_rec_mask 值都是 0 。
4.2 聚簇索引
4.3 二级索引
4.4 联合索引
五、 B+树索引注意事项
5.1 MyISAM中的索引方案简单介绍
InnoDB 中索引即数据,也就是 聚簇索引的那棵 B+ 树的叶子节点中已经把所有完整的用户记录都包含了,而 MyISAM 的索引方案虽然也使用树形 结构,但是MyISAM却将索引和数据分开存储:
将表中的记录按照记录的插入顺序单独存储在一个文件中,称之为 数据文件 。这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少记录就成了。我们可以通过行号而快速访问到一条记录。
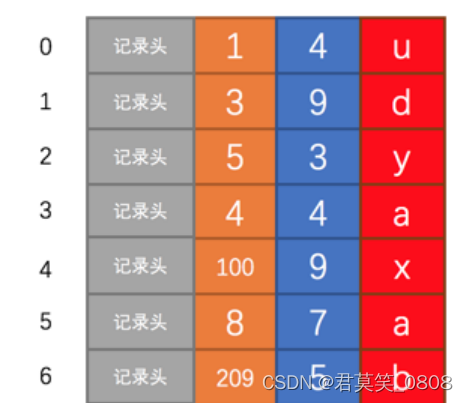
数据按顺序写入数据文件(不按照主键大小排序),索引信息另外存储到一个称为 索引文件, MyISAM 会单独为 表的主键创建一个索引,叶子节点仅存储 主键值 + 行号;先通过索引找到对应的行号,再通过行号去找对应的记录!MyISAM 中却需要进行一次 回表 操作,相当于全部是二级索引。