1.概念
时序数据库全称为时间序列数据库。时间序列数据库指主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
时间序列数据主要由电力行业、化工行业、气象行业、地理信息等各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据量)。
2.特点
基于时间序列数据的特点,关系型数据库无法满足对时间序列数据的有效存储与处理,因此迫切需要一种专门针对时间序列数据来做优化的数据库系统,即时间序列数据库。
对于时序大数据的存储和处理往往采用关系型数据库的方式进行处理,但由于关系型数据库天生的劣势导致其无法进行高效的存储和数据的查询。时序大数据解决方案通过使用特殊的存储方式,使得时序大数据可以高效存储和快速处理海量时序大数据,是解决海量数据处理的一项重要技术。该技术采用特殊数据存储方式,极大提高了时间相关数据的处理能力,相对于关系型数据库它的存储空间减半,查询速度极大的提高。
3.一些常见的时序数据库
- InfluxDB: InfluxDB是一个开源的时序数据库,设计用于处理高度时间相关的数据。它提供了高性能的写入和查询操作,支持灵活的数据模型和标签索引,适用于物联网、监控、应用性能管理等领域。
- TimescaleDB: TimescaleDB是一个开源的、构建在关系型数据库PostgreSQL之上的时序数据库扩展。它结合了关系型数据库的功能和时序数据库的性能,提供了强大的时间序列数据处理能力,并支持标准SQL查询。
- kdb+: kdb+是一个商业级的时序数据库,被广泛应用于金融行业。它以其出色的性能和高效的数据压缩而闻名,并提供了强大的查询和分析功能。
kdb+/q被官方称为世界上最快的时间序列数据库,它使用统一的数据库处理实时数据和历史数据,同时具备 CEP(复杂事件处理)引擎、内存数据库、磁盘数据库等功能。列式存储的特性,使得对于某个列的统计分析操 作异常方便。
与一般数据库或大数据平台相比,kdb+/q具有更快的速度和更低的总拥有成本,非常适合海量数据处理,主 要被用于海量数据分析、高频交易、人工智能、物联网等领域。在延迟性上有着苛刻要求的金融领域,有着 独特的优势。
-
OpenTSDB : OpenTSDB 是一种基于 HBase 来构建的分布式、可扩展的时间序列数据库。OpenTSDB 被广泛应用于存储、索引和服务从大规模计算机系统(网络设备、操作系统、应用程序)采集来的监控指标数据,并且使这些数据易于访问和可视化。
-
Prometheus: Prometheus是一个开源的时序数据库和监控系统,用于收集和存储度量指标数据。它特别适合于云原生应用和微服务架构。
作为新一代的监控框架,Prometheus具备强大的多维度数据模型,有多种可视化图形界面,使用pull模式采集时间序列数据,可以采用push gateway的方式把时间序列数据推送至Prometheus server端。

这些时序数据库都可以处理高频率的数据,并提供了各种功能来存储、查询和分析时间序列数据。
4.InfluxDB
时序数据库 InfluxDB 是一款专门处理高写入和查询负载的时序数据库,基于 InfluxDB 能够快速构建具有海量时序数据处理能力的分析和监控软件。
该项目的发起者是 influxdata 公司,该公司提供了一套用于处理时序数据的完整解决方案,InfluxDB 是该解决方案中的核心产品。

- 优点:
- 开箱即用,运维简单
- 多值存储模型、丰富的数据类型
- 提供了类 SQL 的查询语言
- 独创 TSM 索引
- 缺点:
- 开源版本不支持集群部署,对于大规模应用来说,使用前需要慎重考虑
5.TimescaleDB
TimescaleDB是唯一支持完整SQL的开放源代码时间序列数据库,已针对支持全面SQL的快速提取和复杂查询进行了优化。它基于PostgreSQL,并且为时间序列数据提供了最好的NoSQL和Relational世界。
TimescaleDB使开发人员和组织能够更多地利用其功能:分析过去,了解现在和预测未来。在查询层面统一时序数据和关系数据可消除数据孤岛,并使演示和原型更容易实现。可扩展性和完整的SQL接口的结合赋予员工提出数据问题。
6.kdb+
kdb+ 号称最快的内存数据库之一。列式存储的特性,使得对于某个列的统计分析操作异常方便。
优点:
单体架构,轻松支持 billion以上数据;
分布式扩展,无性能损耗;
超低延迟+高并发支持;
列式存储+内存数据库;
灵活的Q语言,内置非常多的统计计算方法。
缺点:
搭配的Q 语言,学习难度较高。
7.OpenTSDB
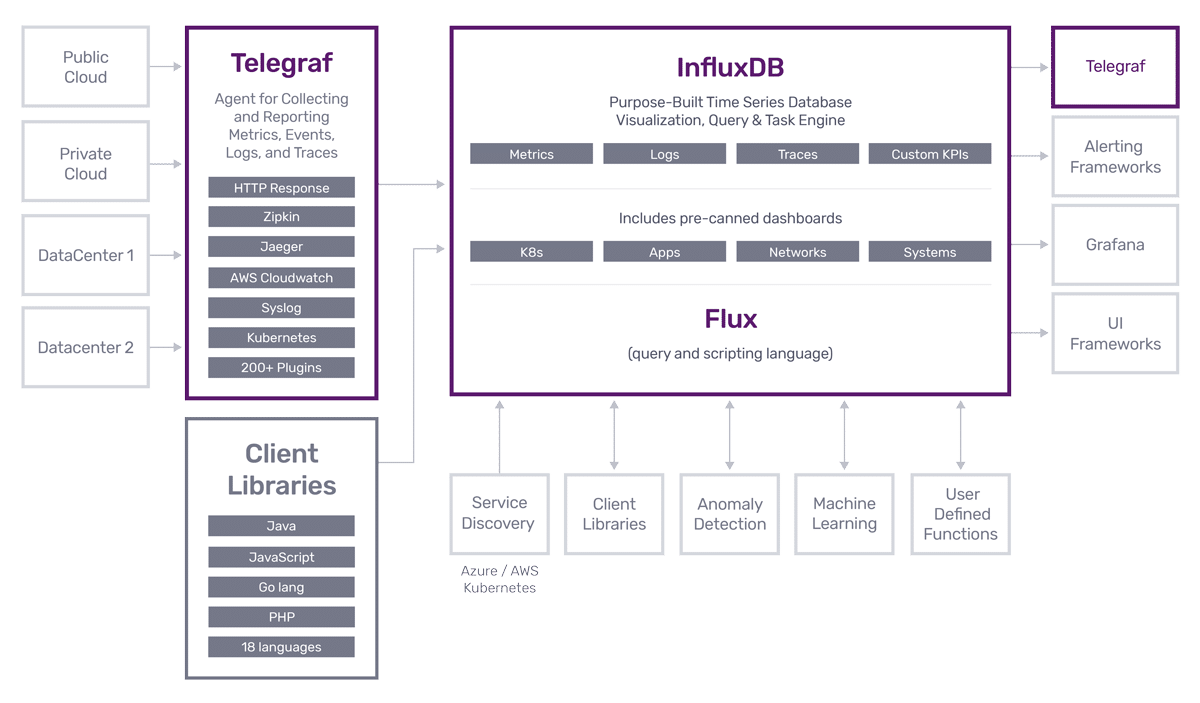
OpenTSDB 由时间序列守护程序 (TSD) 以及一组命令行实用程序组成。每个 TSD 都是独立的。 没有主节点,没有共享状态。
- 优点:
TSD 是无状态的,所有状态数据保存在 HBase 中,天然支持水平扩展 - 缺点:
- Hadoop 全家桶运维难度较大,需要专人负责
- 新版本的 OpenTSDB 底层支持 Cassandra
- 存储模型过于简化
- 单值模型且只能存储数值类型数据
- 单个 metric 最多支持 8 个 tag key
- 虽然利用了 HBase 作为底层存储,但是没有提供对 MapReduce 的支持。
- 可以通过 Spark 实现复杂的处理逻辑
- Hadoop 全家桶运维难度较大,需要专人负责
8.Prometheus
Prometheus 是一个开源的服务监控系统和时间序列数据库。
优点:
具有丰富的查询语言;
可视化数据展示;
集成监控和报警功能;
维护简单。
缺点:
没有集群解决方案;
聚合分析能力较弱;
为运行时正确的监控数据准备的,不能解决大容量存储问题,无法做到100%精准,存在由内核故障、刮擦故障等因素造成的微小误差。
9.QuestD
对于那些既希望利用InfluxDB内联协议的灵活性,又熟悉PostgreSQL的人来说,QuestDB(YC S20)作为一个较新的时序数据库,可以满足开发者的这两个要求。它是一个用Java和C++编写的开源TSDB,从原理上说,QuestDB是利用内存映射文件,在数据提交到磁盘之前,实现快速读写的。
QuestDB通过使用Java和C++,来从头开始构建数据库,其主要特征体现在:
- 性能:解决摄取过程中,特别是在处置高基数的数据集过程中的瓶颈。同时,它还通过顺次存储的时分数据(即,在内存中的混洗),以及仅分析请求的列/分区,而并非以整张表的方式,来支持快速的数据检索。此外,QuestDB还会运用SIMD指令,实现并行化操作。
- 兼容性:QuestDB支持InfluxDB的内联(inline)协议、PostgreSQL wire、REST API、以及CSV上传的方式,来摄取数据。那些习惯了其他TSDB的用户,可以轻松地移植他们的现有应用程序,而无需进行大量的重写工作。
- 通过SQL进行查询:虽然能够支持多种摄取机制,但是QuestDB也会使用SQL作为查询语言,因此用户无需额外地学习Flux之类的特定域语言。
- 优点:快速摄取(特别是对于具有高基数的数据集),支持InfluxDB内联协议和PostgreSQL wire,可以通过标准的SQL查询数据。
- 缺点:在用户社区、可用集成、以及对生产环境就绪等方面,都有待改进。


![java八股文面试[多线程]——sleep wait join yield](https://img-blog.csdnimg.cn/img_convert/7e288643040b63449dde9aa59802b8d6.webp?x-oss-process=image/format,png)