一、环境:
①、linux cuda-11.3 opecv4.8.0
不知道头文件和库文件路径,用命令查找:
# find /usr/local -name cuda.h 2>/dev/null # 查询cuda头文件路径
/usr/local/cuda-11.3/targets/x86_64-linux/include/cuda.h# find /usr/local -name libcudart.so 2>/dev/null # 查询库文件路径
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudart.so# pkg-config --cflags opencv4 # 查看opencv头文件
-I/usr/include/opencv4/opencv -I/usr/include/opencv4# pkg-config --libs opencv4 查看opencv 库文件
-lopencv_stitching -lopencv_aruco -lopencv_bgsegm -lopencv_bioinspired
-lopencv_ccalib -lopencv_dnn_objdetect -lopencv_dnn_superres -lopencv_dpm
-lopencv_highgui -lopencv_face -lopencv_freetype -lopencv_fuzzy -lopencv_hdf
-lopencv_hfs -lopencv_img_hash -lopencv_line_descriptor -lopencv_quality
-lopencv_reg -lopencv_rgbd -lopencv_saliency -lopencv_shape -lopencv_stereo
-lopencv_structured_light -lopencv_phase_unwrapping -lopencv_superres
-lopencv_optflow -lopencv_surface_matching -lopencv_tracking -lopencv_datasets
-lopencv_text -lopencv_dnn -lopencv_plot -lopencv_ml -lopencv_videostab
-lopencv_videoio -lopencv_viz -lopencv_ximgproc -lopencv_video -lopencv_xobjdetect -lopencv_objdetect -lopencv_calib3d -lopencv_imgcodecs -lopencv_features2d
-lopencv_flann -lopencv_xphoto -lopencv_photo -lopencv_imgproc -lopencv_core添加到makefile文件里面:
# 这里定义头文件库文件和链接目标没有加-I -L -l,后面用foreach一次性增加
include_paths := /usr/local/cuda-11.3/targets/x86_64-linux/include /usr/include/opencv4 /usr/include/opencv4/opencv
library_paths := /usr/local/cuda-11.3/targets/x86_64-linux/lib
link_librarys := cudart opencv_core opencv_imgcodecs opencv_imgproc $(shell pkg-config --libs opencv4 | sed 's/-l//g')
因为OpenCV的库文件太多,使用shell函数将pkg-config命令的结果作为一个命令执行,并将其分割为单独的库名称,使用了sed命令来移除pkg-config命令返回的库名称中的横线-。这样,link_librarys中的库名称和pkg-config命令返回的库名称都将不带横线。这样就可以正确链接opencv4.8.0中的库了。
二、GPU的大致了解
原文:Bringing HPC Techniques to Deep Learning - Andrew Gibiansky
1、DataParallel模式(DP),Parameter Center模式,主从模式(主卡收集梯度,从卡发送参数和接受结果)
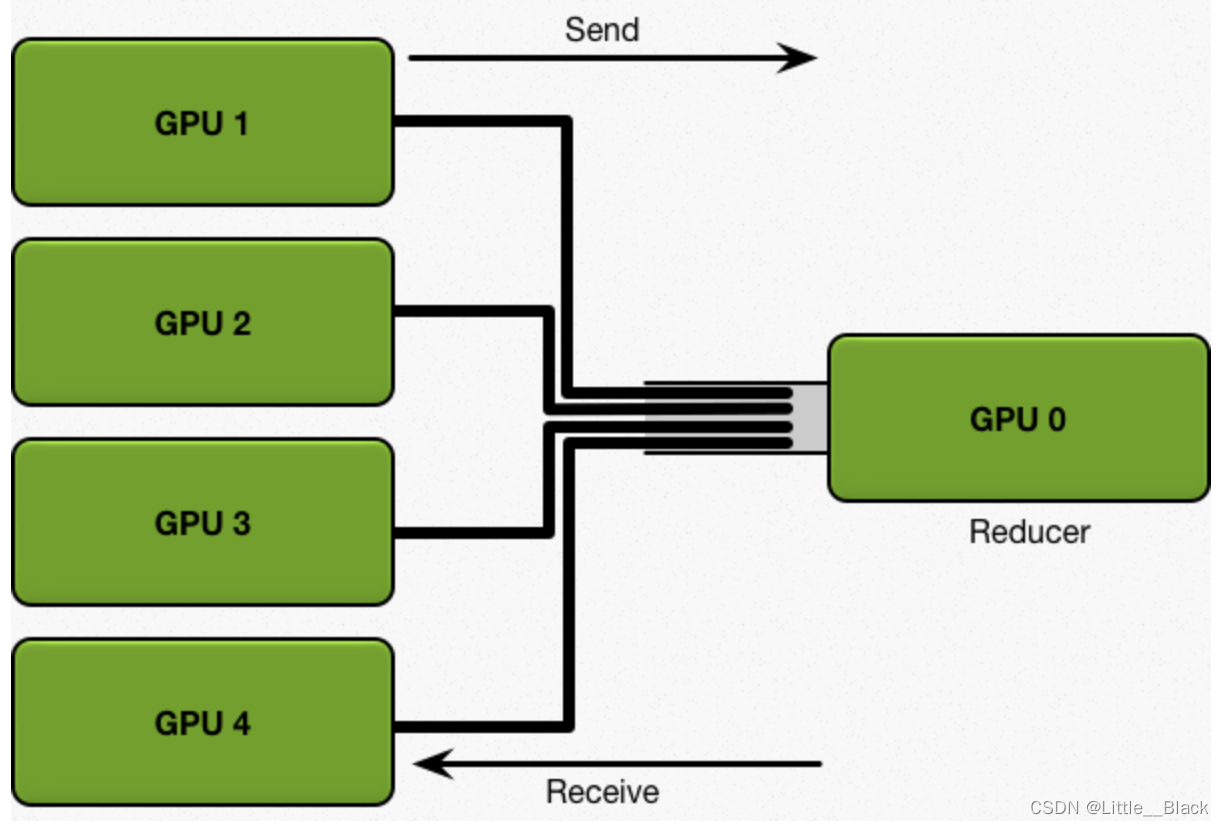
速度受限于主卡到从卡的带宽和速度。我们定义:
D = 模型参数总量,设为1GB
S = 单条线路的传输速率,设为1GB/s,也就是任何显卡传数据到GPU0,或者传输出去都是最大1GB/s
N = 显卡的个数,这里为5
则有:
①. 数据的传输量为4 x D x 2,我们经过了1次Scatter Reduce传输了4D数据量,经过了1次Allgather传输了4D数据量
②. 我们传输耗时理论为4 x 2 x D / S,得到结果约为8秒,公式为:Times = 2(N-1) * D / S
③. 我们传输的数据总量(显卡数相关):Data Transferred = 2(N-1) * D
2、DistributedDataParallel模式(DDP),Ring模式,环形模式
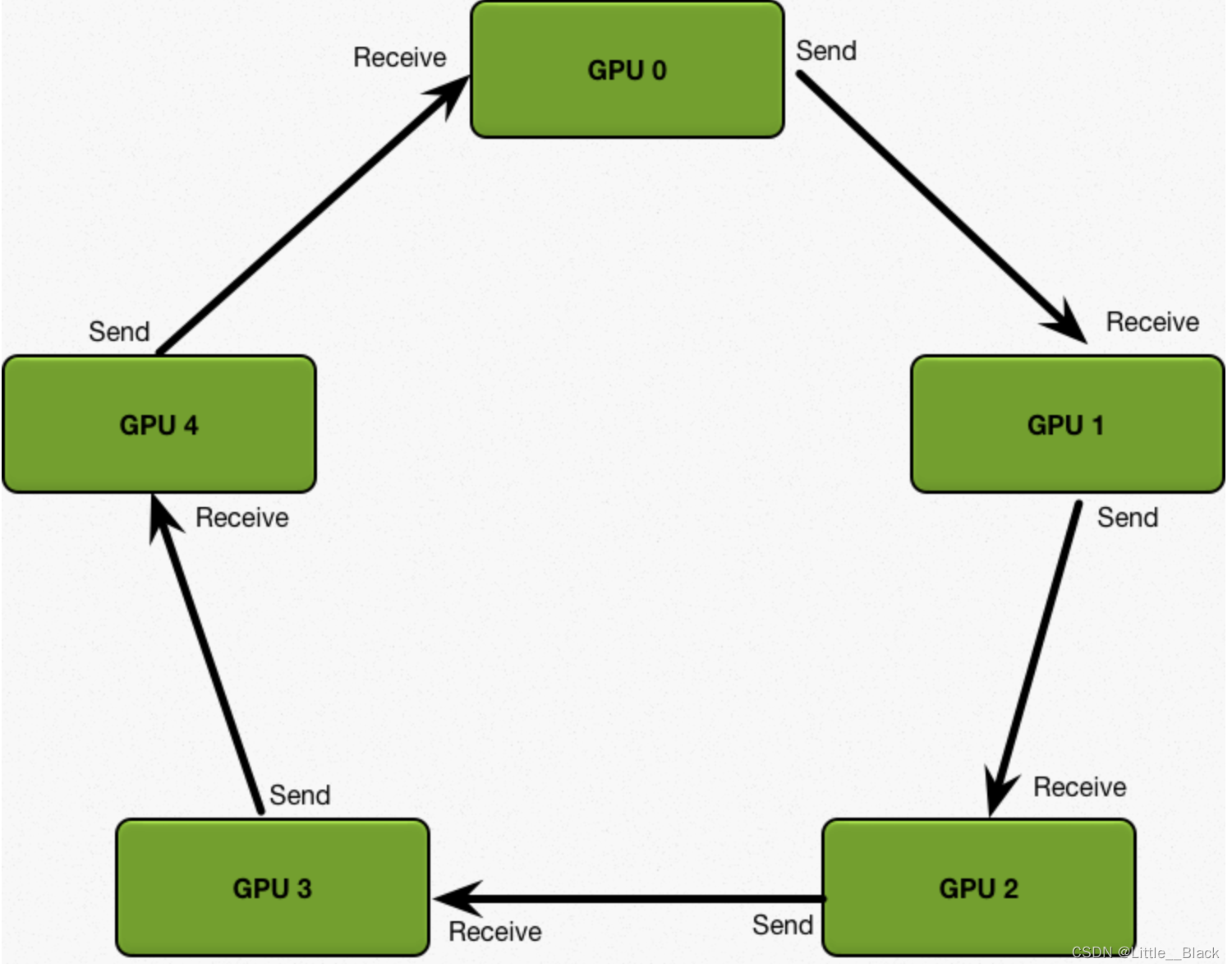
传输速度只与单个显卡的速度和带宽。我们定义:
D = 模型参数总量,设为1GB
S = 单条线路的传输速率,设为1GB/s,也就是任何显卡传数据到GPU0,或者传输出去都是最大1GB/s
N = 显卡的个数,这里为5
①、Scatter-Reduce(循环N-1次):
每个卡都传递其显卡索引对应的那份数据,给相邻的下一个显卡做累加,递所使用的线路是相邻显卡路径,不存在等待堆积,执行一次耗时: 1/N
②、Allgather(循环N-1次):
将每个卡中存在的完整数据发送给相邻下一个卡,执行一次耗时:1/N
则:
- 我们Scatter-Reduce时经过了N-1次1/N大小的数据传输,耗时认为是𝐷/𝑆 * 1/𝑁 * (𝑁−1)
- 我们Allgather时经过了N-1次1/𝑁大小的数据传输,耗时认为是𝐷/𝑆 * 1/𝑁 * (𝑁−1)
- 因此传输的耗时为:𝑇𝑖𝑚𝑒𝑠=2(𝑁−1) * 1/𝑁 * 𝐷/𝑆
- 传输的数据量为:𝐷𝑎𝑡𝑎𝑇𝑟𝑎𝑛𝑠𝑓𝑒𝑟𝑟𝑒𝑑=2(𝑁−1) * 𝐷 / 𝑁
可见:传输的数据量与显卡数量无关了 只与对应的显卡之间的数据传输速度有关
总结:
- DP模式下的主从模式,通信速度受限于单个显卡的通信速率。传递的数据量为2(𝑁−1)𝐷
- N为显卡数,D为模型参数大小
- DDP模式下的RingAllReduce,通信速度受限于显卡邻居间通信速率
- 于PCIE下,受限于主板的PCIE速度,而不是显卡的速度
- 于NVLINK下则最高可达100GB/s甚至更高
- 传递的数据量为2(𝑁−1)*𝐷/𝑁,与显卡数量无关,也因此其效率高







![[halcon] 局部图片保存 gen_circle 和 gen_rectangle2 对比 这怕不是bug吧](https://img-blog.csdnimg.cn/9861f707a5c049e58b00a5e37fd5e3e5.png)