采集的数据存储后通常会分为多个文件或数据库,如何将这些文件按需拼接,或按键进行连接十分重要。这节将介绍数据索引的复杂操作如分层索引,stack,unstack,seet_index,reset_index等帮助重构数据,数据的拼接如merge,join,concat,combine_first等帮助连接数据,以及数据透视表的使用。
目录
- A. 分层索引
- 1. 创建分层索引
- A.1.1 Series分层索引
- A.1.2 DataFrame分层索引
- A.1.3 直接创建多层索引再重用它
- 2. 分层索引的引用与属性
- A.2.1 对分层Series的引用
- A.2.1 分层DataFrame的层数判断
- 3. 多层行列索引之间的转换
- A.3.1 Series.unstack() DataFrame.stack() 用法
- A.3.2 DataFrame.set_index 与 DataFrame.reset_index
- A.3.3 索引轴更换顺序与排序
- 4. 分层计算统计量
- B. 组合与合并数据
- 1. pd.merge() pd.join()使用键连接数据
- B.1.1 根据Df的列(键)合成数据
- B.1.2 根据Df的索引列合成数据
- B.1.3 合成的集合选择方式(how参数)
- B.1.4 合成时不作为键但列名相同的列(suffixes参数)
- B.1.5 pd.merge参数总结(其他参数)
- B.1.6 使用pd.join简化按索引列合并
- 2. pd.concat()按轴方向串联数据
- 3. df.combine_first()实现有重复索引的选择性拼接
- C. 数据透视表
- C.1 df.pivot
- C.2 pd.melt
A. 分层索引
1. 创建分层索引
A.1.1 Series分层索引
- 在创建Series时,使用嵌套列表的方式指定它的索引,就会生成分层索引的Series数组
- 可以使用S.index.names 对多层索引命名
- S.index 是一个多层索引对象MultiIndex,它的每一个元素是一个元组
data = pd.Series(np.random.uniform(size=9),index=[["a", "a", "a", "b", "b", "c", "c", "d", "d"],[1, 2, 3, 1, 3, 1, 2, 2, 3]],)
data.index.names = ['word','num']
A.1.2 DataFrame分层索引
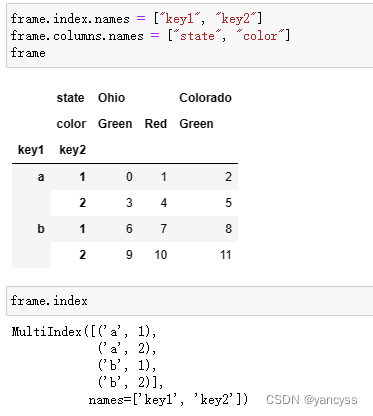
- 在创建DataFrame时,指定它的行和列都是用嵌套列表,就会生成分层索引的Df
- 可以对行和列的分层索引命名 Df.index.name=[ ] ,Df.columns.names=[ ]
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),index=[["a", "a", "b", "b"], [1, 2, 1, 2]],columns=[["Ohio", "Ohio", "Colorado"],["Green", "Red", "Green"]])
frame.index.names = ["key1", "key2"]
frame.columns.names = ["state", "color"]

A.1.3 直接创建多层索引再重用它
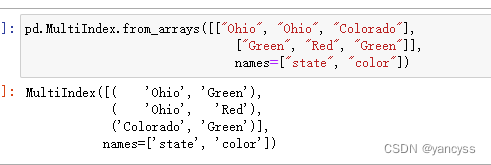
除了在创建Series和DataFrame时,通过嵌套列别指定所层索引的形式,还可以直接生成所层索引MultiIndex,这样可以重复使用这个索引。
pd.MultiIndex.from_arrays([["Ohio", "Ohio", "Colorado"],["Green", "Red", "Green"]],names=["state", "color"])
2. 分层索引的引用与属性
A.2.1 对分层Series的引用
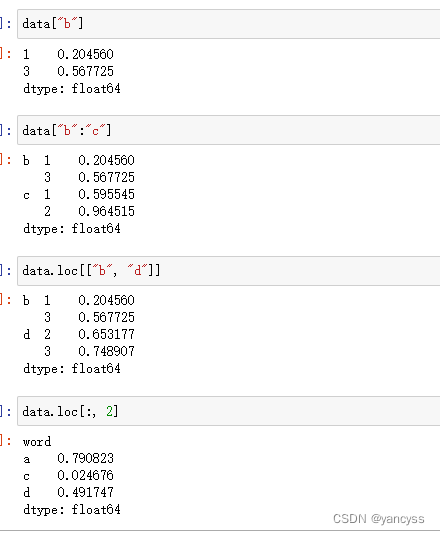
A.3.1 可以看出Series分层索引与Df之间可以相互转换,所以使用对Df的引用方法可以实现对Series的引用。下面实例中data是前文的data
A.2.1 分层DataFrame的层数判断
Df.index.nlevels
Df.columns.nelvels

3. 多层行列索引之间的转换
A.3.1 Series.unstack() DataFrame.stack() 用法
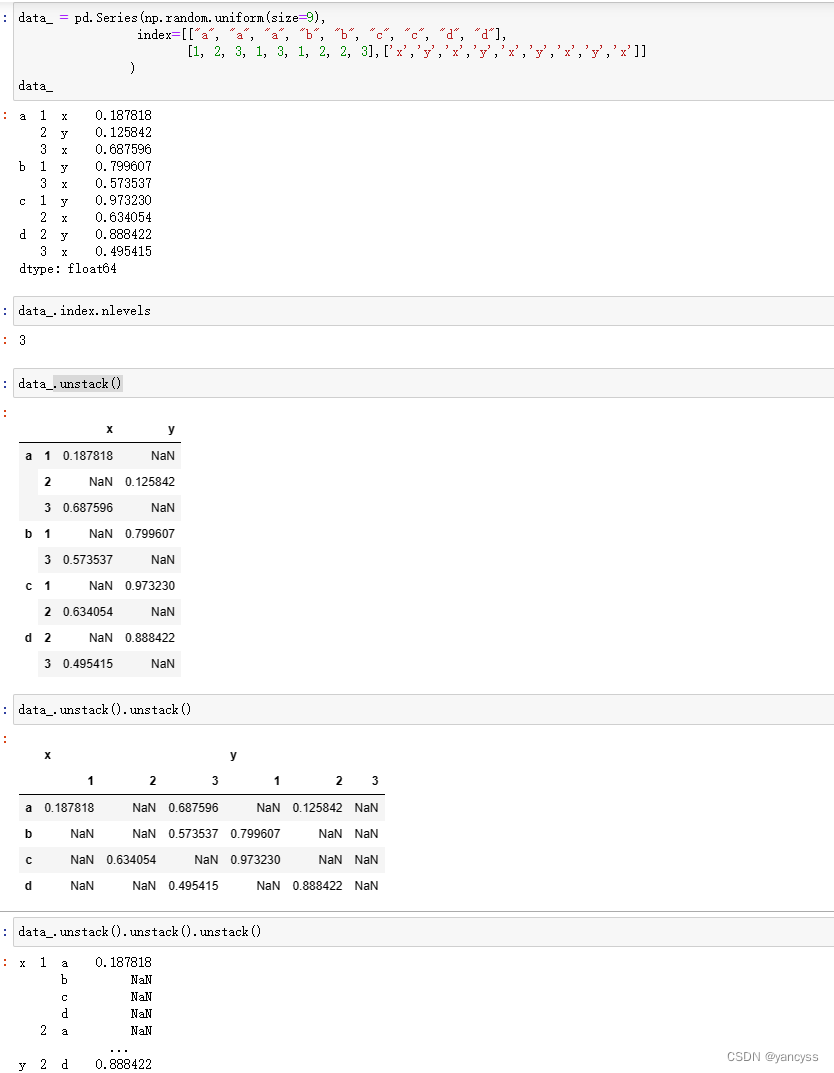
每一次使用unstack相当于把行中最内层的索引放到列最内层中,比如原来行有a,b,c和1,2,3这两种索引,使用一次unstack会把内层的1,2,3这个索引放到行上,形成Df。

对于三层的行索引可以更清晰的看出,比如下面这个数据有a,b,c ;1,2,3;x,y,z三种,每一次使用unstack会把最内层的行索引放到最内层的列索引中。直到最后索引顺序变为x,y,z;1,2,3;a,b,c。
data_ = pd.Series(np.random.uniform(size=9),index=[["a", "a", "a", "b", "b", "c", "c", "d", "d"],[1, 2, 3, 1, 3, 1, 2, 2, 3],['x','y','x','y','x','y','x','y','x']])
data_.index.nlevels
data_.unstack()
data_.unstack().unstack()
data_.unstack().unstack().unstack()
- 可以通过level指定要挪动的索引,可以使用整数位置或者索引标签名称,但是默认还是会放到列的最内侧。
df.unstack(level=0)
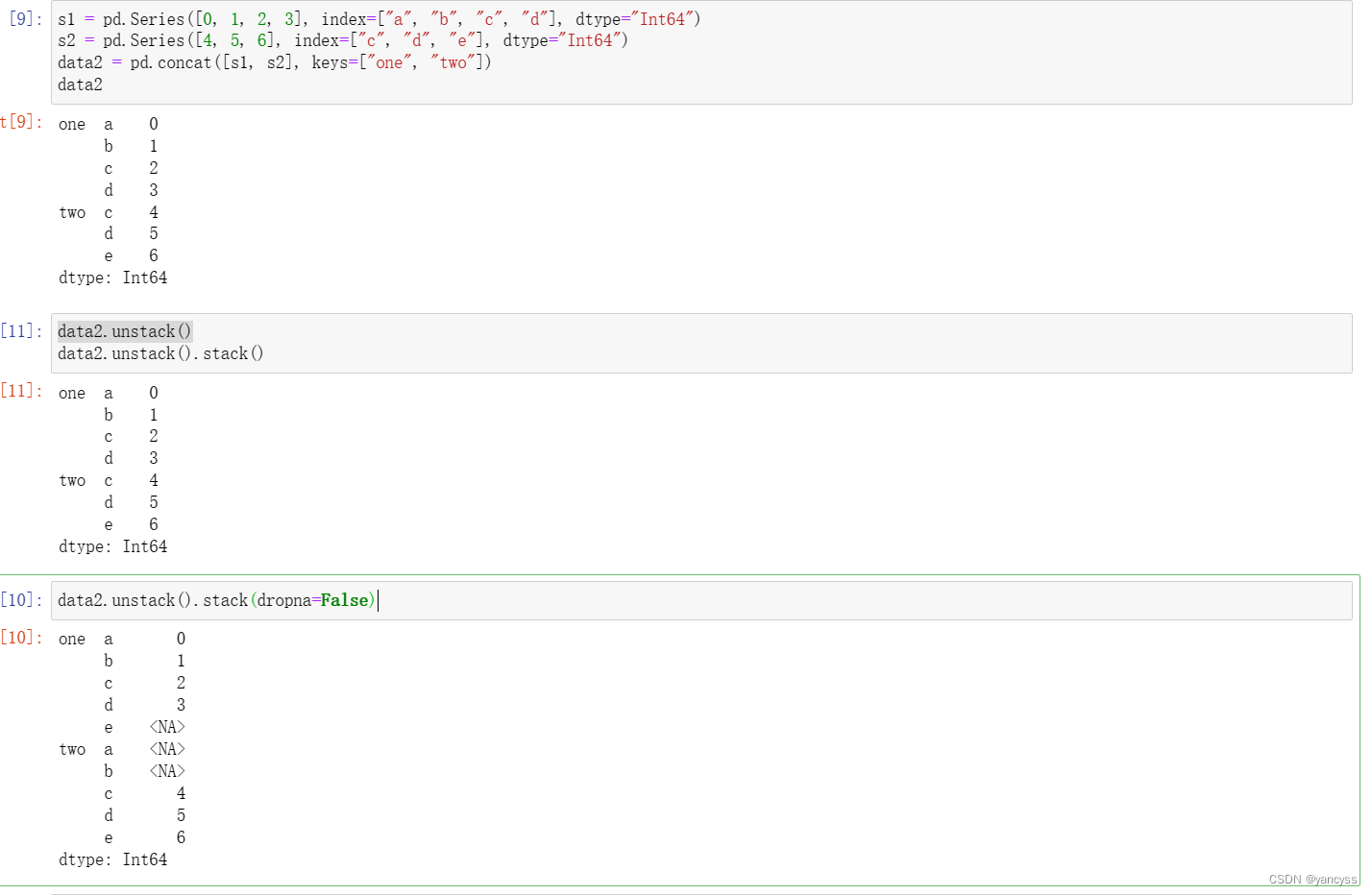
df.unstack(level=‘name1’) - 使用.stack方法后会默认将含有空值的行删除,使用dropna=Falese参数可以保留空值。
data = pd.DataFrame(np.arange(6).reshape((2, 3)),index=pd.Index(["Ohio", "Colorado"], name="state"),columns=pd.Index(["one", "two", "three"],name="number"))
result.unstack(level=0)
result.unstack(level="state")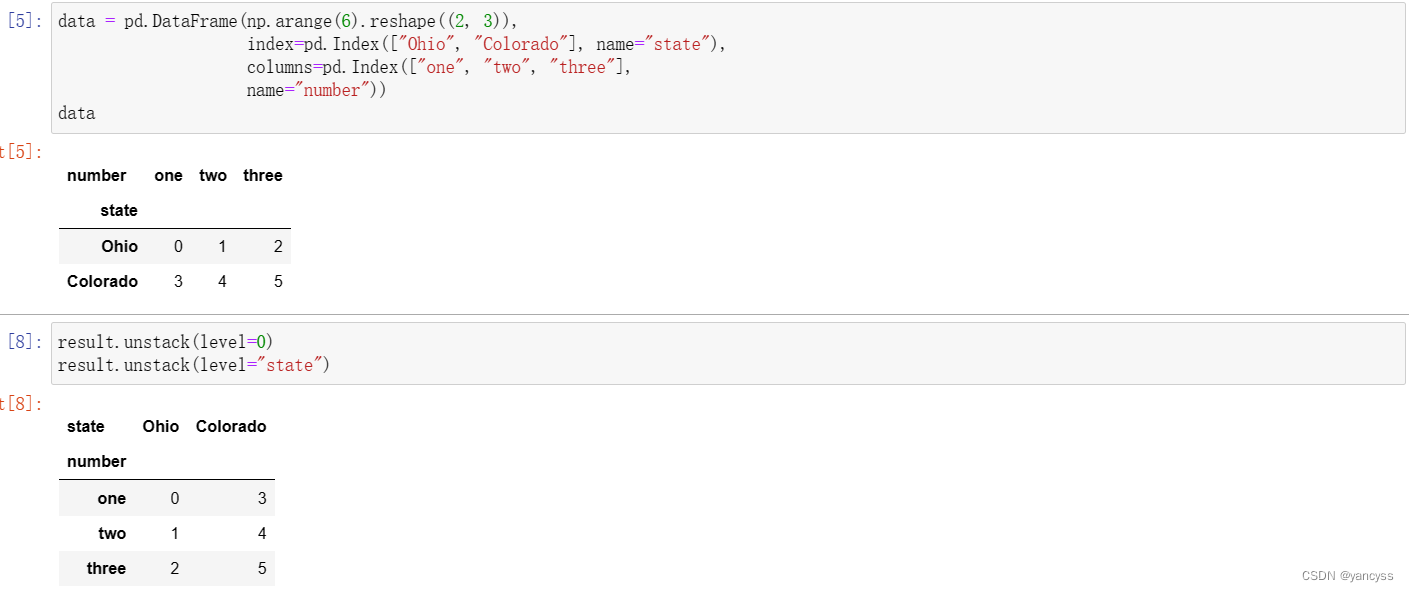
s1 = pd.Series([0, 1, 2, 3], index=["a", "b", "c", "d"], dtype="Int64")
s2 = pd.Series([4, 5, 6], index=["c", "d", "e"], dtype="Int64")
data2 = pd.concat([s1, s2], keys=["one", "two"])data2.unstack()
data2.unstack().stack(dropna=False)
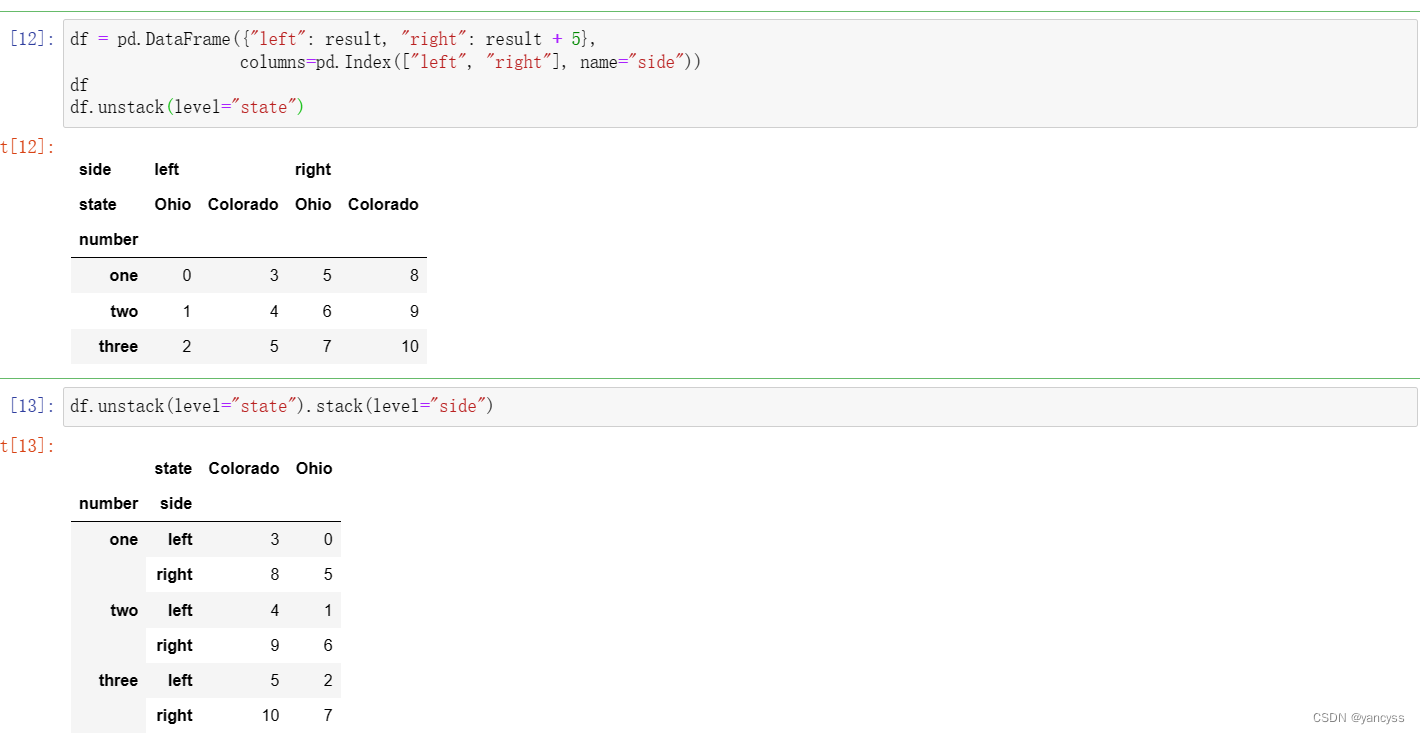
df = pd.DataFrame({"left": result, "right": result + 5},columns=pd.Index(["left", "right"], name="side"))
df
df.unstack(level="state")df.unstack(level="state").stack(level="side")
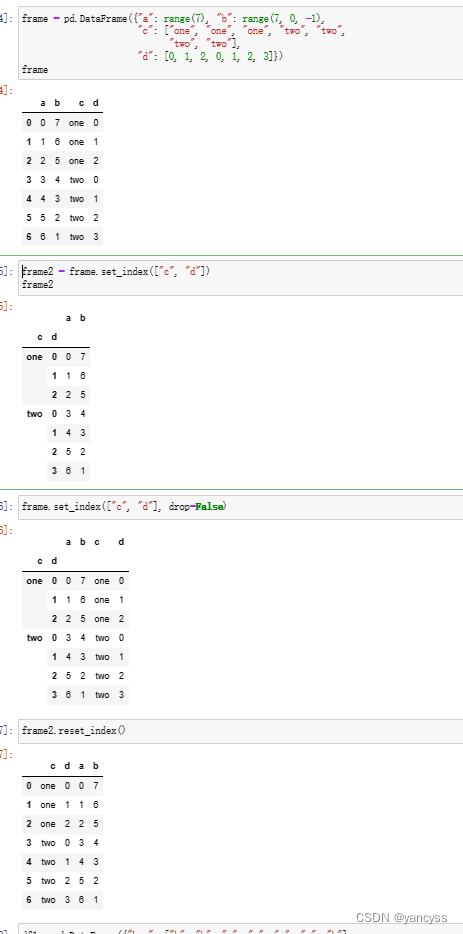
A.3.2 DataFrame.set_index 与 DataFrame.reset_index
- 可以 选择把Df的某列或某几列作为多层索引Df.set_index([‘col1’,‘col2’])
- 默认变成索引的列不再出现在列中,但是使用drop=False可以让成为索引的列仍然出现在行中
- 将所有的索引都移动到列中Df.reset_index
frame = pd.DataFrame({"a": range(7), "b": range(7, 0, -1),"c": ["one", "one", "one", "two", "two","two", "two"],"d": [0, 1, 2, 0, 1, 2, 3]})
frame2 = frame.set_index(["c", "d"])
frame.set_index(["c", "d"], drop=False)
frame2.reset_index()
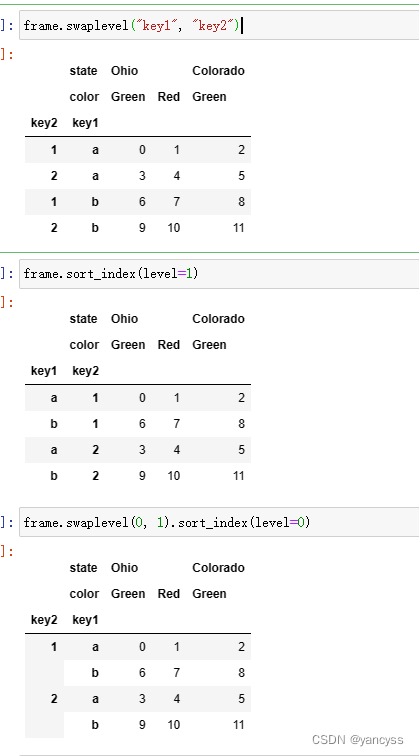
A.3.3 索引轴更换顺序与排序
Df.swaplevel('key1,key2']
Df.sort_index(level=1)
Df.sawplevel(0,1).sort_index(level=0)
4. 分层计算统计量
使用groupby
frame.groupby(level="key2").sum()
frame.groupby(level="color", axis="columns").sum()

B. 组合与合并数据
1. pd.merge() pd.join()使用键连接数据
将两个Df对象按照某列的对应关系,或者索引之间的对应关系合并成一张表,在关系型数据库中这种操作很常见。在pandas中使用merge或者join函数完成这种合并连接。下面详细介绍pd.merge()的详细用法。假设待连接的两个数组分别是df1,df2。
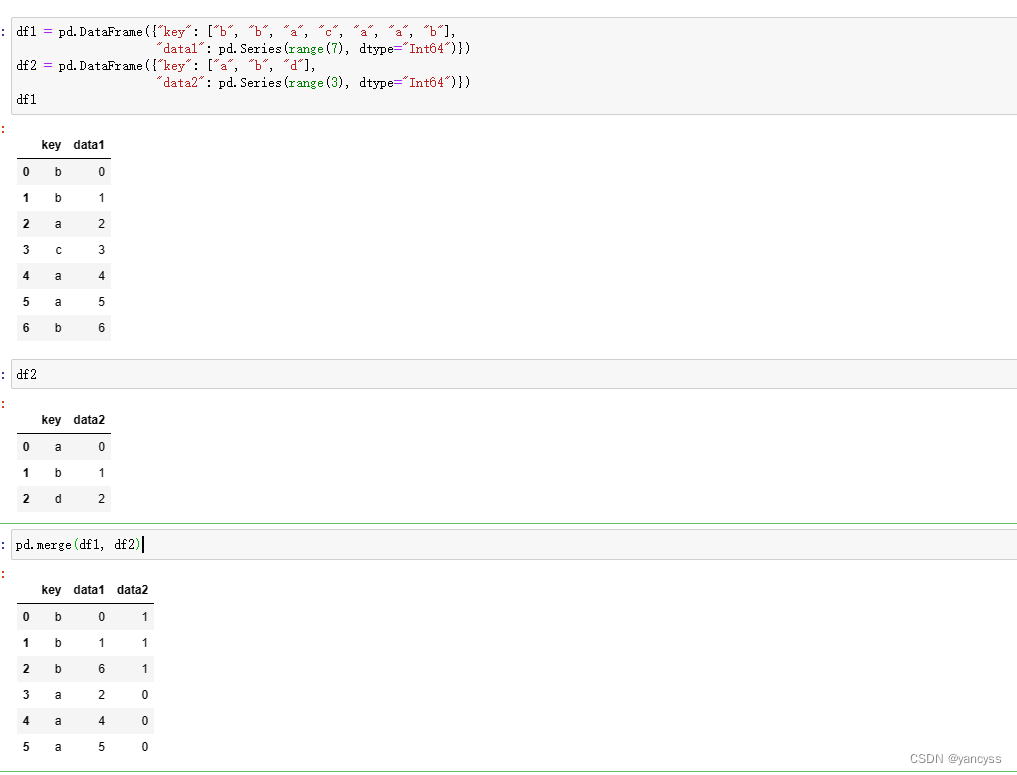
B.1.1 根据Df的列(键)合成数据
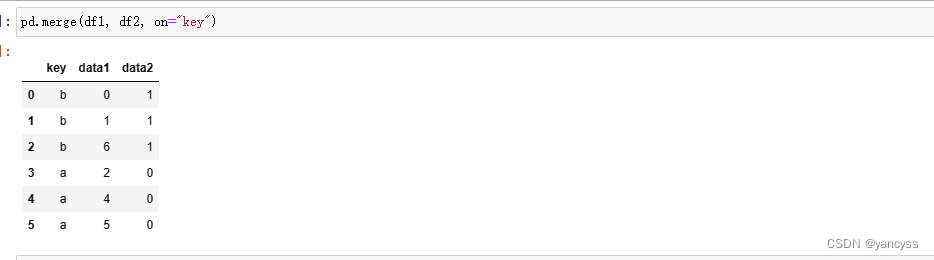
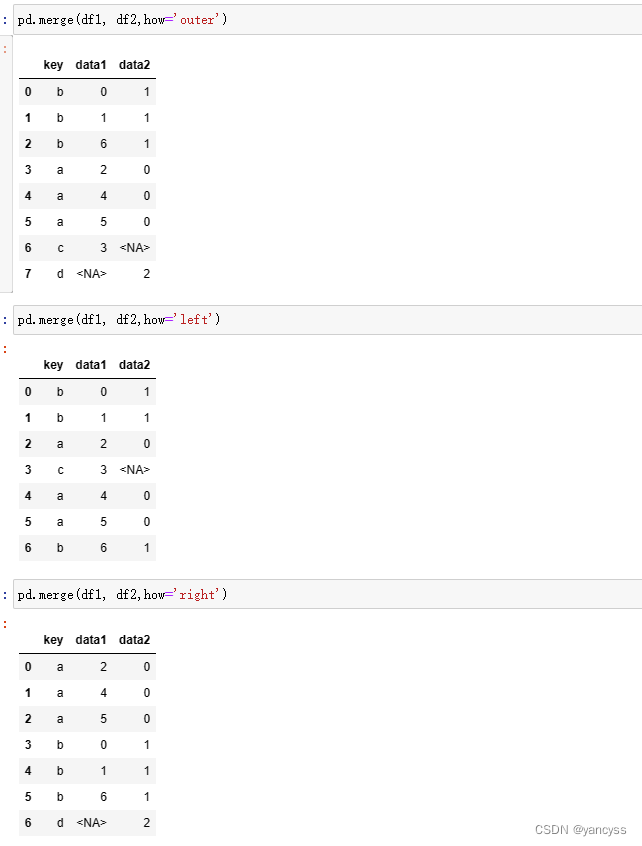
- pd.merge(df1,df2) 不指定键名,将默认使用重复的列作为键连接两个数组
- pd.merge(df1,df2,on=‘key’) ;on 参数需要是两个数组共有的列名,将以它为键进行合并
- pd.merge(df1,df2,left_on=‘lkey’,right_on=‘rkey’) ;用于两个数组分别以不同的列名作为键合并
- 也可以指定多个列为连接的键pd.merge(left, right, on=[“key1”, “key2”])
#data
df1 = pd.DataFrame({"key": ["b", "b", "a", "c", "a", "a", "b"],"data1": pd.Series(range(7), dtype="Int64")})
df2 = pd.DataFrame({"key": ["a", "b", "d"],"data2": pd.Series(range(3), dtype="Int64")})#pd.merge
pd.merge(df1, df2)
pd.merge(df1, df2, on="key")#left_on,right_on
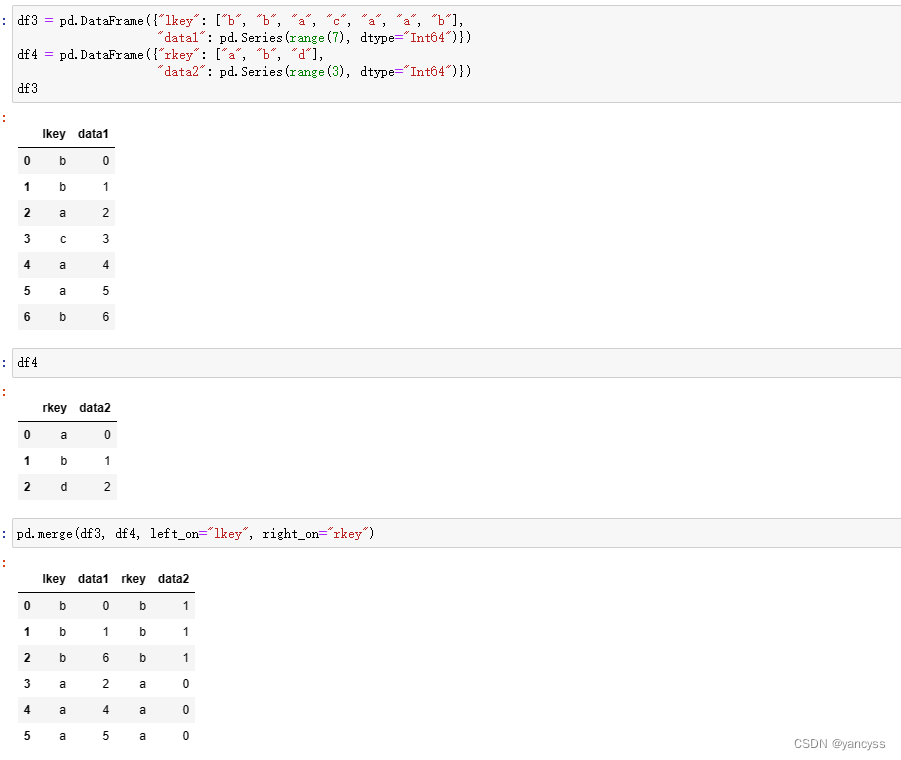
df3 = pd.DataFrame({"lkey": ["b", "b", "a", "c", "a", "a", "b"],"data1": pd.Series(range(7), dtype="Int64")})
df4 = pd.DataFrame({"rkey": ["a", "b", "d"],"data2": pd.Series(range(3), dtype="Int64")})
pd.merge(df3, df4, left_on="lkey", right_on="rkey") #指定多个键,默认将取两个键都对应的在两个数组间的交集
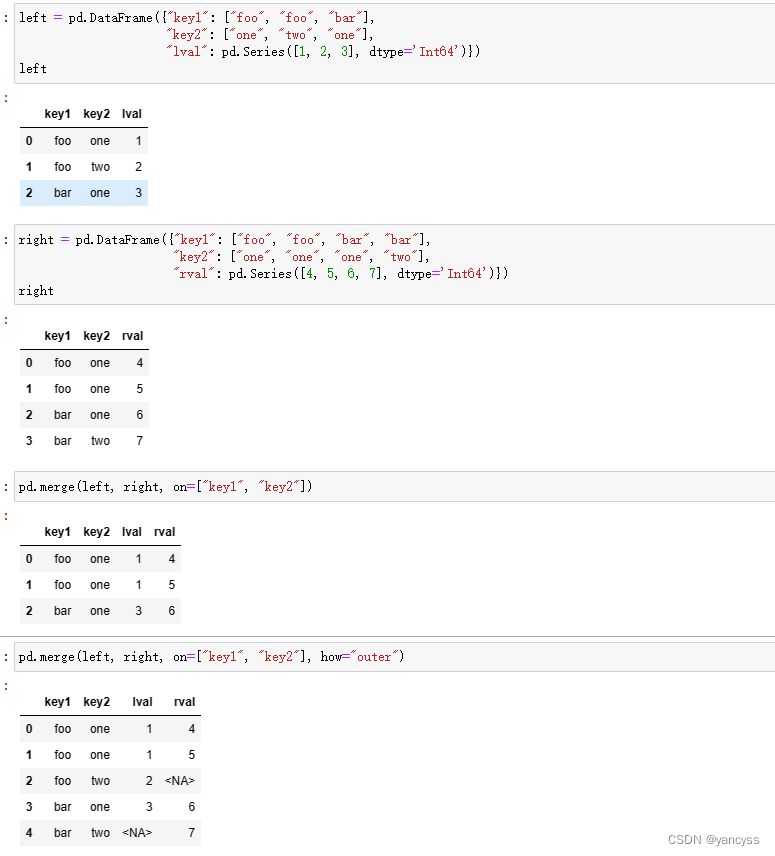
left = pd.DataFrame({"key1": ["foo", "foo", "bar"],"key2": ["one", "two", "one"],"lval": pd.Series([1, 2, 3], dtype='Int64')})
right = pd.DataFrame({"key1": ["foo", "foo", "bar", "bar"],"key2": ["one", "one", "one", "two"],"rval": pd.Series([4, 5, 6, 7], dtype='Int64')})
pd.merge(left, right, on=["key1", "key2"], how="outer")
B.1.2 根据Df的索引列合成数据
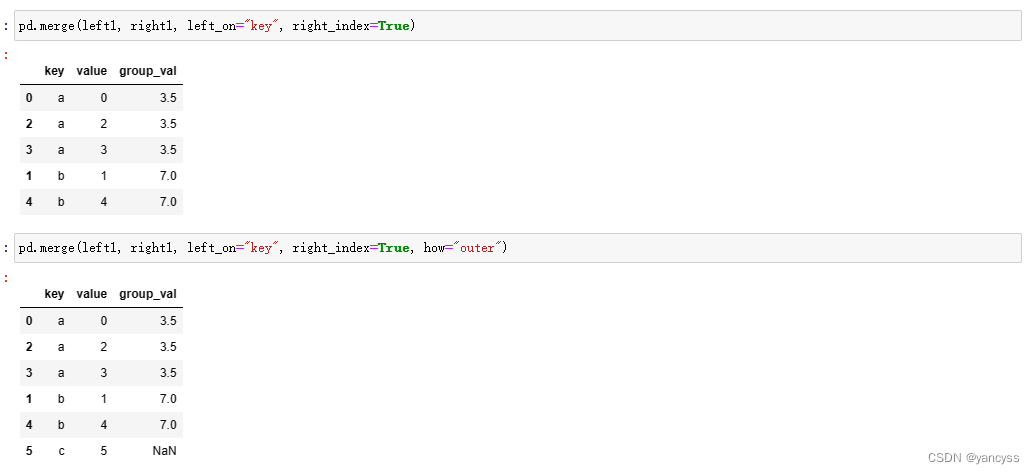
某个数组待合并的键并不出现在列中,而是以索引的方式出现在数组中,也可以实现索引与列之间的连接。
- right_index = True 使用右侧数组的索引为键值
- left_index = True 使用左侧数组的索引为键值
- 若一侧指定了多个列为键值,那么另一侧需要有对应的多层索引,也就是A.部分提到的知识。
#data
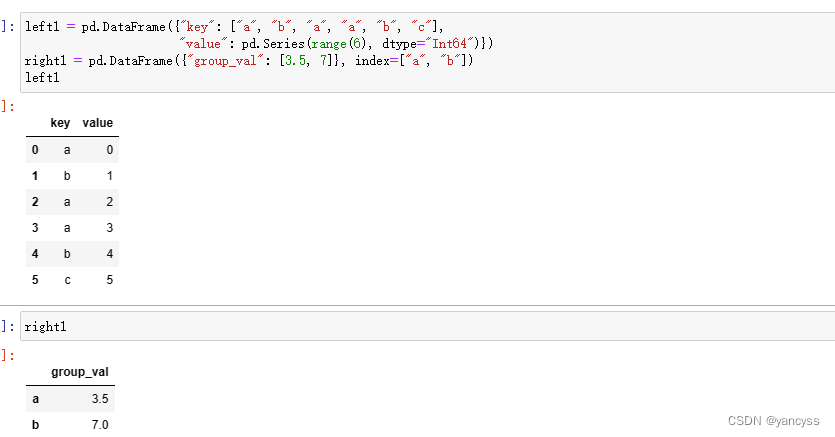
left1 = pd.DataFrame({"key": ["a", "b", "a", "a", "b", "c"],"value": pd.Series(range(6), dtype="Int64")})
right1 = pd.DataFrame({"group_val": [3.5, 7]}, index=["a", "b"])#这里左侧使用键,右侧使用索引
pd.merge(left1, right1, left_on="key", right_index=True)
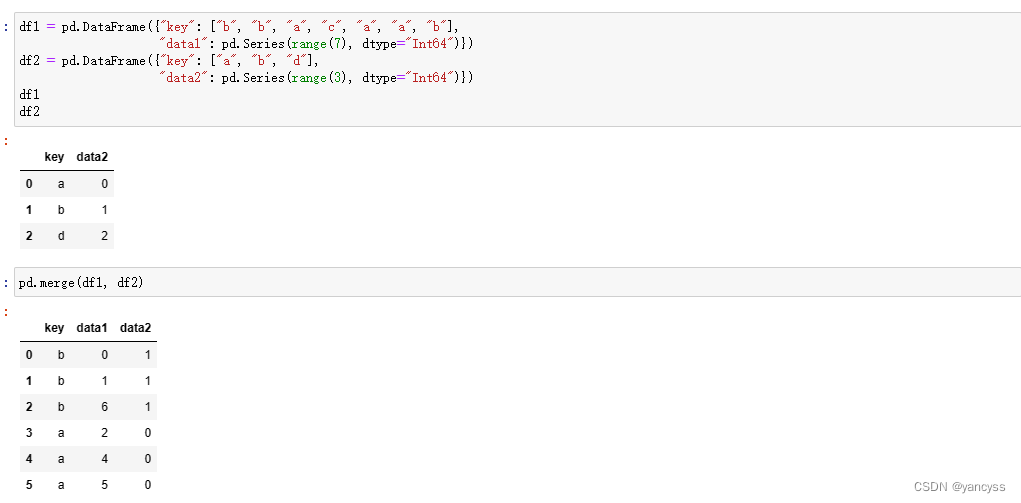
B.1.3 合成的集合选择方式(how参数)
两个合并的数组,键值可能不完全相同,通过how参数可以指定结果使用哪种方式对键值进行选择
- inner 使用两个数组共有的键值作为最终结果,即取交集(默认方式)
- left 使用左侧数组的键值
- right 使用右侧数组的键值
- outer 使用二者相结合的键值,即取并集
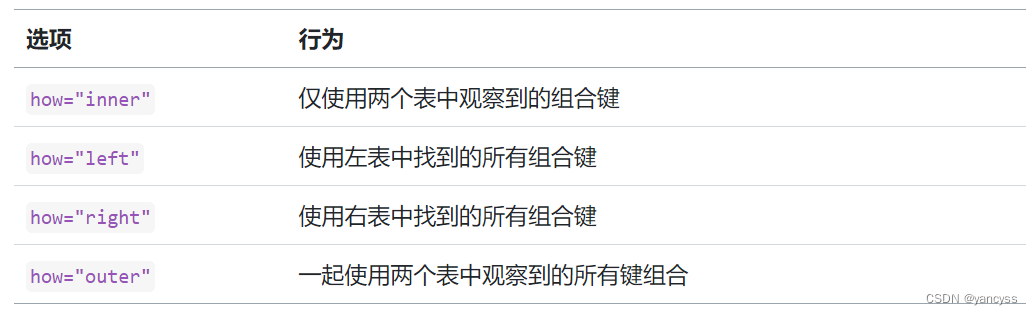
pd.merge(df1, df2,how='outer')
pd.merge(df1, df2,how='outer')
pd.merge(df1, df2,how='right')
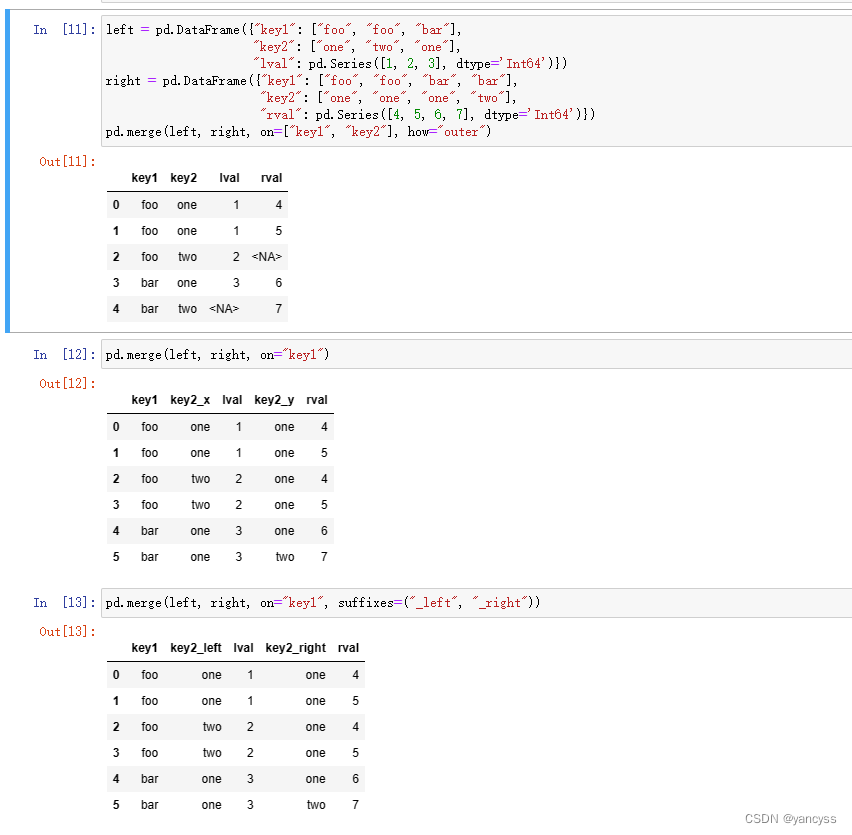
B.1.4 合成时不作为键但列名相同的列(suffixes参数)
当不以重名的列作为键进行合并时,合并后为区分两个列会自动添加一个后缀
也可以使用suffixes参数手动指定添加的后缀 suffixes(‘_left’,‘_right’)
pd.merge(left, right, on="key1", suffixes=("_left", "_right"))
B.1.5 pd.merge参数总结(其他参数)
其他参数如下表,等待读者参考官方文档自行探索。

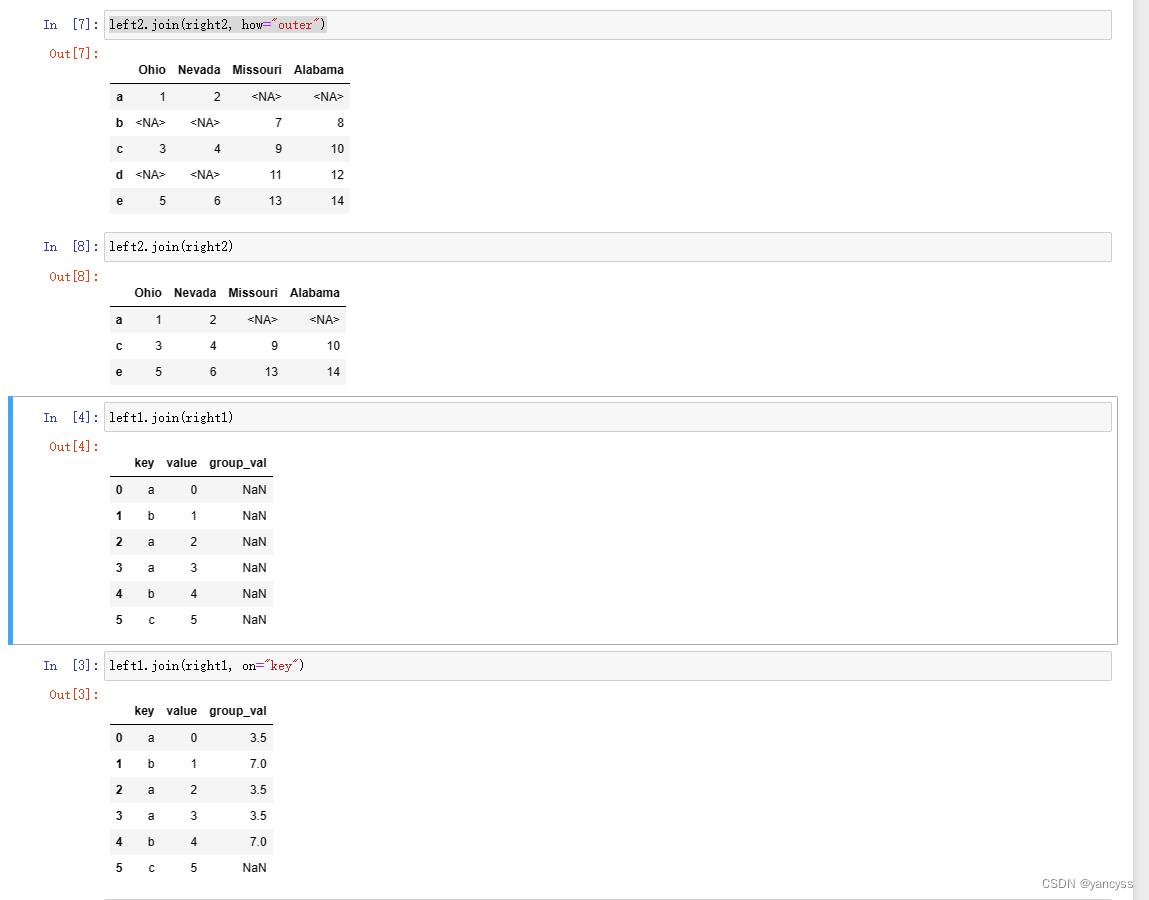
B.1.6 使用pd.join简化按索引列合并
上述pd.merge()方法在使用索引为键值的情况,参数略微有一些繁琐。而pd.join()方法 可以简化。
- 当df1 和 df2 都以索引作为键进行合并时使用 df1.join(df2) 默认的连接方式为左连接(相当于how=left)
- 当df1使用列 与df2的索引 作为键进行合并时,df1.join(df2,on=‘key’)
- 可以使用join向df1插入多个数组 df1.join([df2,df3]) 默认的连接方式也是左连接
# data
left1 = pd.DataFrame({"key": ["a", "b", "a", "a", "b", "c"],"value": pd.Series(range(6), dtype="Int64")})
right1 = pd.DataFrame({"group_val": [3.5, 7]}, index=["a", "b"])
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]],index=["a", "c", "e"],columns=["Ohio", "Nevada"]).astype("Int64")
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],index=["b", "c", "d", "e"],columns=["Missouri", "Alabama"]).astype("Int64")
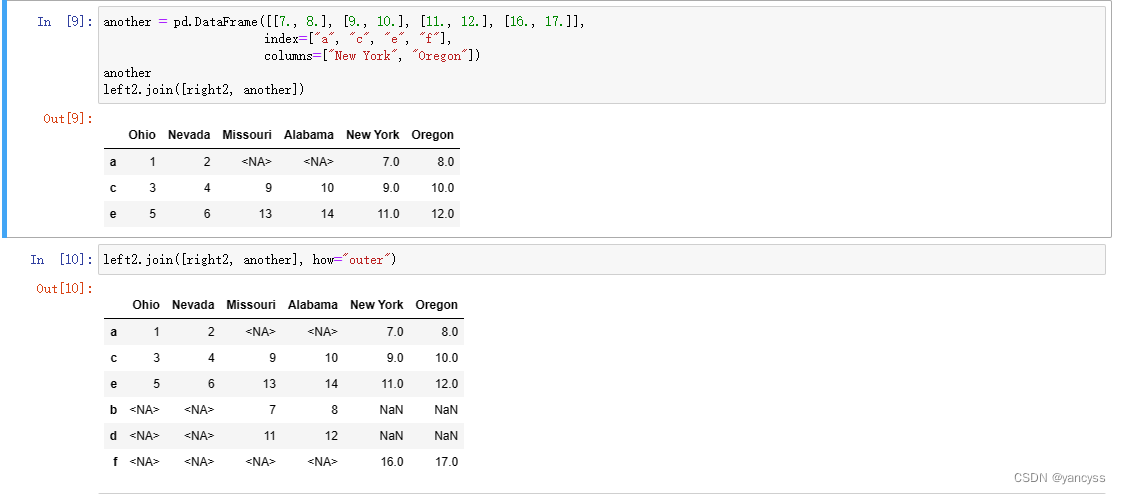
another = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [16., 17.]],index=["a", "c", "e", "f"],columns=["New York", "Oregon"]) # df1.join(df2)
left2.join(right2)# df1.join(df2,how='outer')
left2.join(right2, how="outer")# df1.join(df,on='key') key是df1的键
left1.join(right1, on="key")# df1.join([df2,df3])
left2.join([right2, another])
left2.join([right2, another], how="outer")
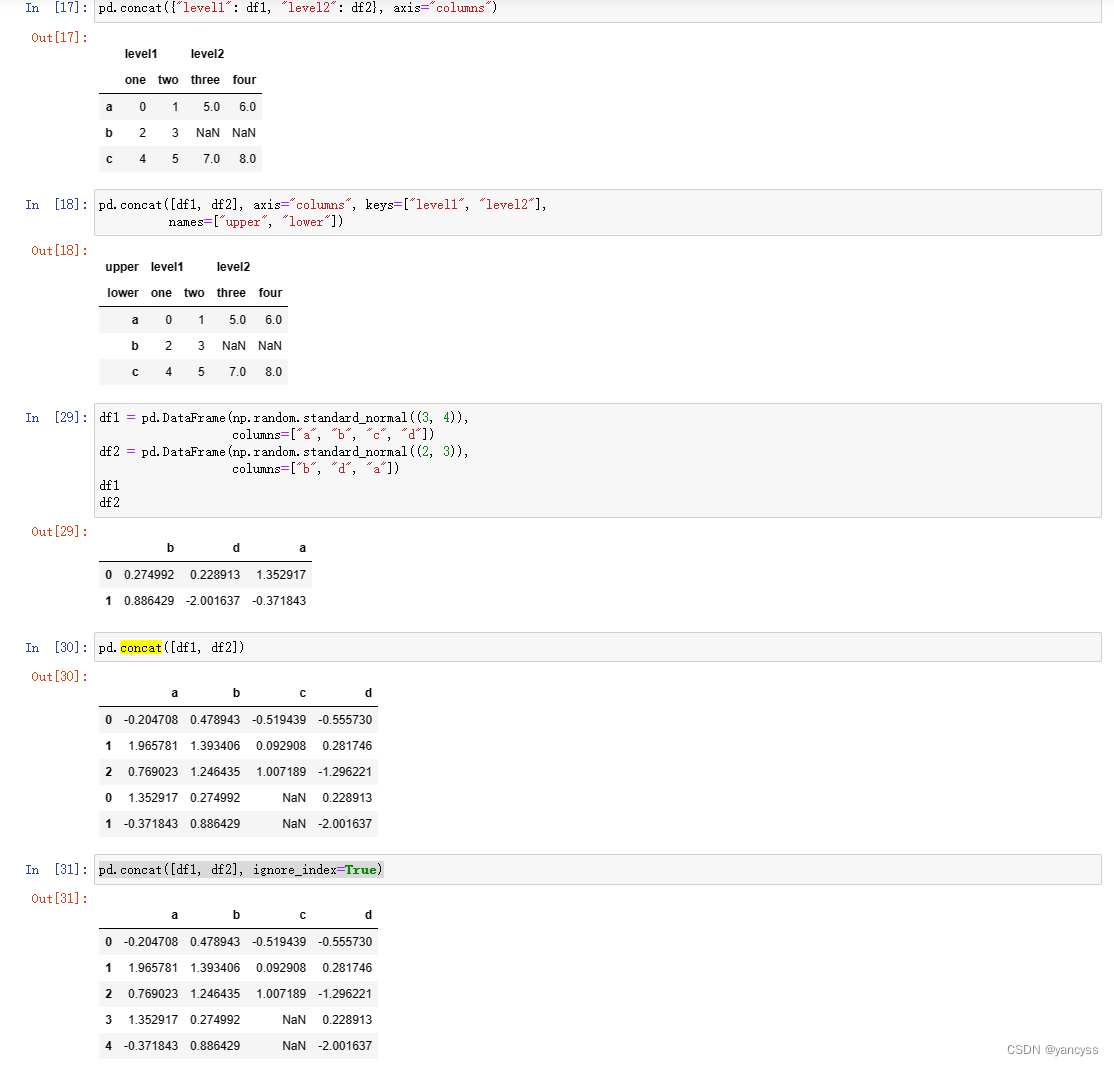
2. pd.concat()按轴方向串联数据
- pd.concat()会按照指定轴的方向,将数组以及索引都连接起来。
- pd.concat()第一个参数制定待连接的对象,可以是列表的形式pd.concat([df1,df2’])
- 默认连接方向是向下(沿行),如果需要向右拼接(沿列)需要指定参数 axis=‘columns’
- 默认是取待串联的数组各个索引的并集。如需要取交集,需要指定参数join=‘inner’
- 可以对被拼接的轴增加一层索引,通过keys参数指示来自哪个是数组pd.concat([df1,df2,df3],keys=[‘1’,‘2’,‘3’])
- pd.concat()第一个参数制定待连接的对象,也可以是字典的形式pd.concat({‘l1’:df1,‘l2’:df2})这里l1 l2 也会给被拼接轴增加一层索引,指示数据来自哪个数组。
- names参数可以对形成的多层索引命名。
- 默认生成的新数组索引时原数组的拼接(沿轴串联保留索引),若想重新生成索引,使用ignore_index=True
# data 三个数组索引没有交集
s1 = pd.Series([0, 1], index=["a", "b"], dtype="Int64")
s2 = pd.Series([2, 3, 4], index=["c", "d", "e"], dtype="Int64")
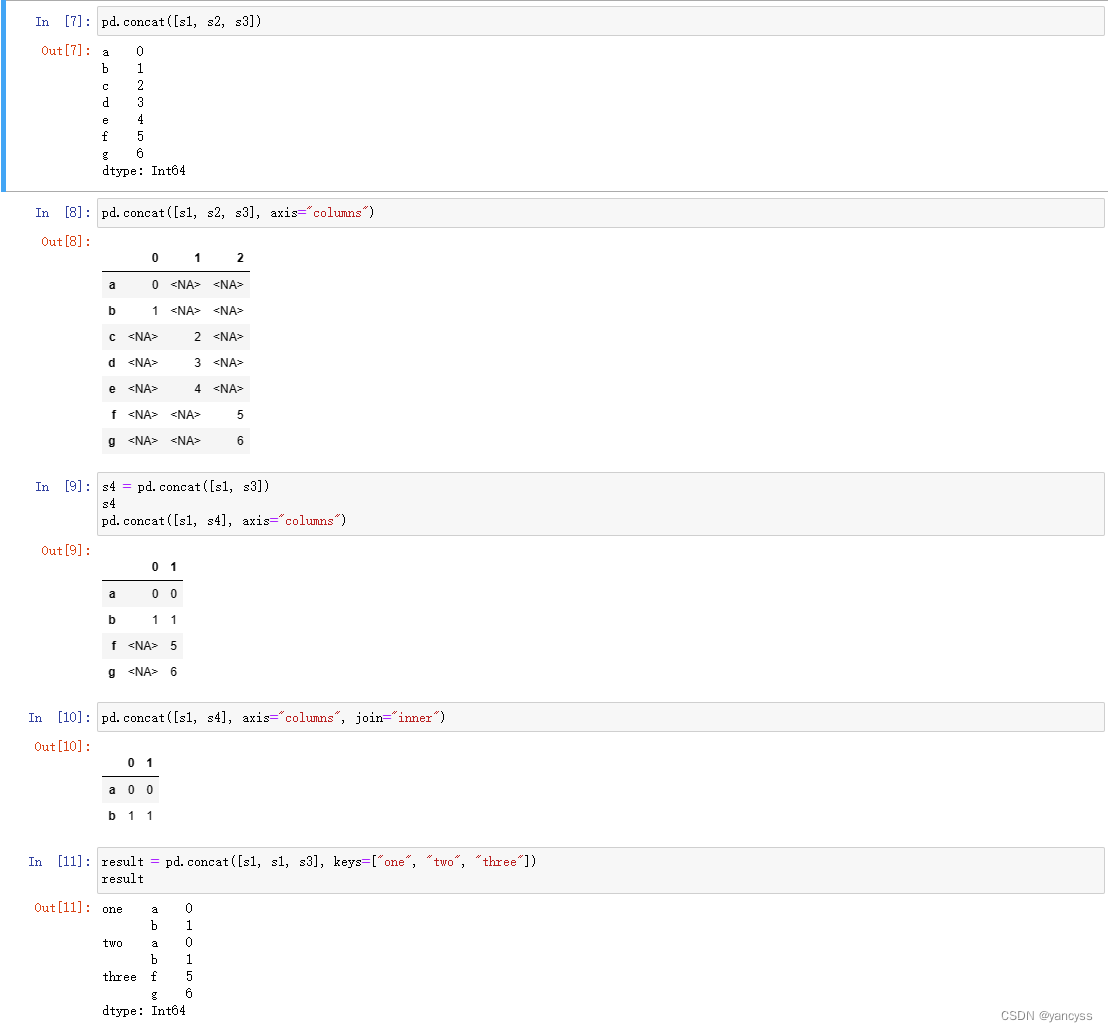
s3 = pd.Series([5, 6], index=["f", "g"], dtype="Int64")# 默认横向拼接,默认取并集
pd.concat([s1, s2, s3])#纵向拼接
pd.concat([s1, s2, s3], axis="columns")#对于有重复的数据,取并集
s4 = pd.concat([s1, s3])
#取交集
pd.concat([s1, s4], axis="columns", join="inner")#依据数据来源设置分层索引
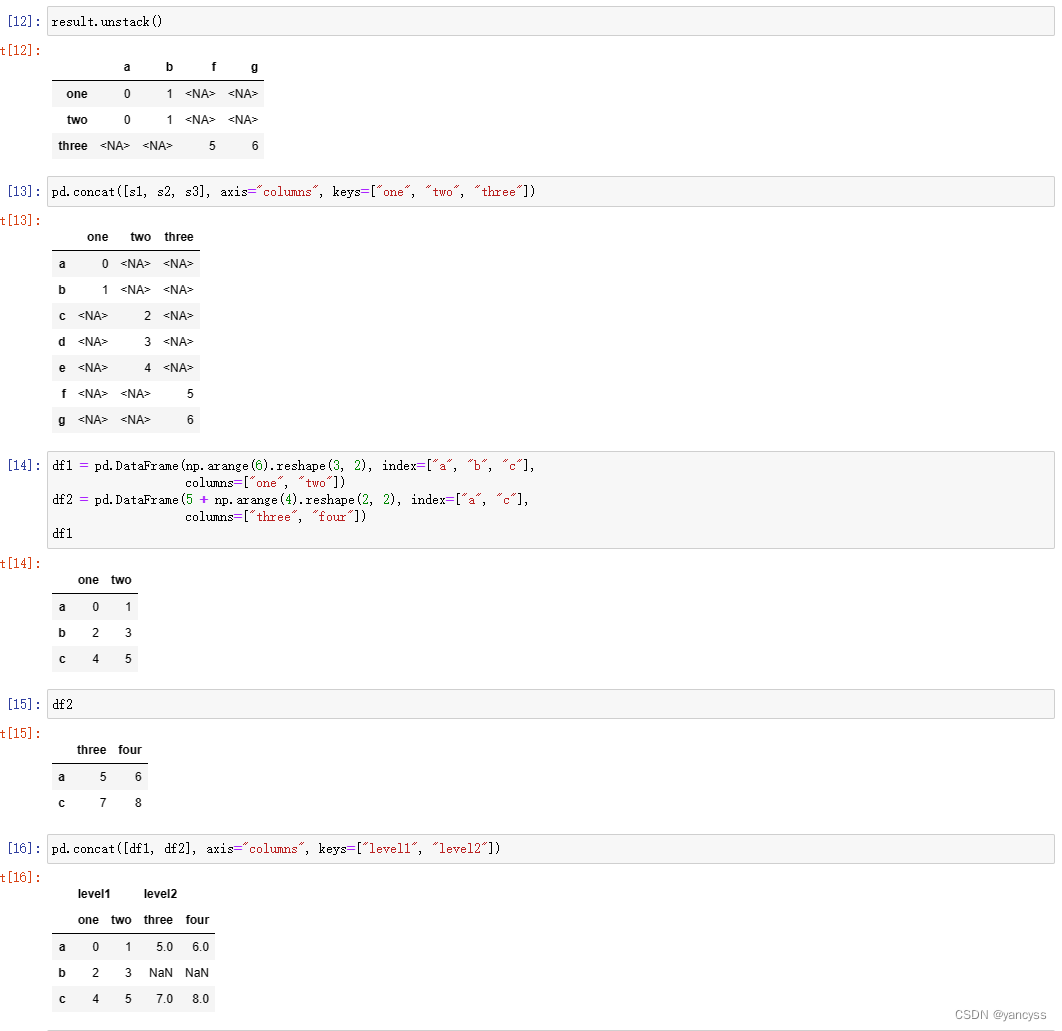
result = pd.concat([s1, s1, s3], keys=["one", "two", "three"])#data 两个Df
df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=["a", "b", "c"],columns=["one", "two"])
df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=["a", "c"],columns=["three", "four"])#纵向拼接,按数据来源设置分层索引
pd.concat([df1, df2], axis="columns", keys=["level1", "level2"])
#也可以按字典方式设置分层索引并传入数据
pd.concat({"level1": df1, "level2": df2}, axis="columns")#默认索引是将原来的拼接在一起但是也可以指定重新排雷索引
df1 = pd.DataFrame(np.random.standard_normal((3, 4)),columns=["a", "b", "c", "d"])
df2 = pd.DataFrame(np.random.standard_normal((2, 3)),columns=["b", "d", "a"])
pd.concat([df1, df2], ignore_index=True)
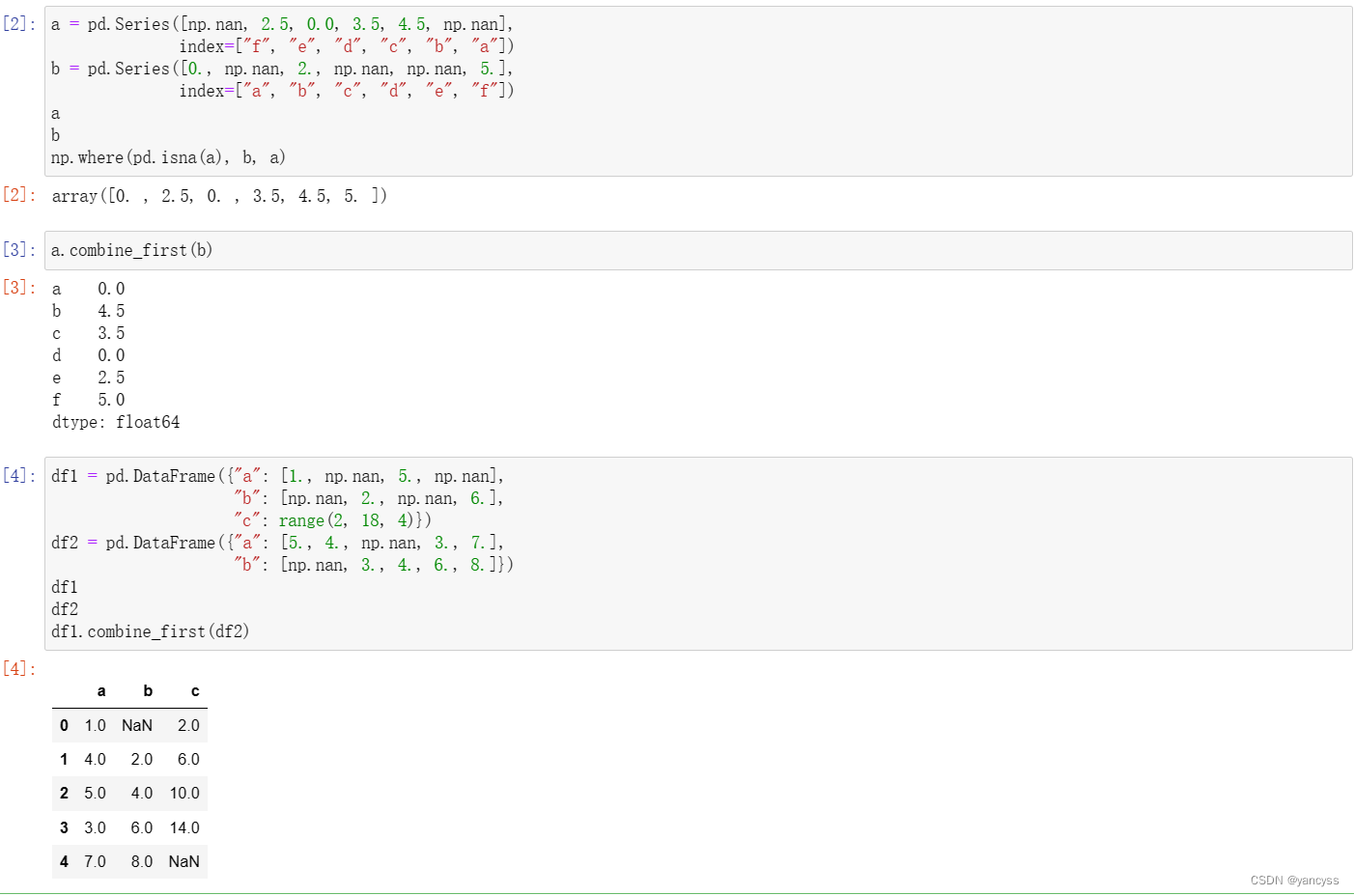
3. df.combine_first()实现有重复索引的选择性拼接
pd.merge可以实现将重复索引作为键值,连接其他列
pd.concat 可以实现将重复索但值不同会合成不同的行
而df.combine_first()可以实现对于重复色索引,但是值不同,选择其中某个数组的值行层新的列。
a.combine_first(b)实现的功能类似于np.where(pd.sina(a),b,a) ,也就是说当a为空值时,选择b的值填入,当a为非空时选择a的值。
对于Df来说,就是对每一列进行上述操作。
# data
a = pd.Series([np.nan, 2.5, 0.0, 3.5, 4.5, np.nan],index=["f", "e", "d", "c", "b", "a"])
b = pd.Series([0., np.nan, 2., np.nan, np.nan, 5.],index=["a", "b", "c", "d", "e", "f"])#以下两个命令类似
np.where(pd.isna(a), b, a)
a.combine_first(b)#data
df1 = pd.DataFrame({"a": [1., np.nan, 5., np.nan],"b": [np.nan, 2., np.nan, 6.],"c": range(2, 18, 4)})
df2 = pd.DataFrame({"a": [5., 4., np.nan, 3., 7.],"b": [np.nan, 3., 4., 6., 8.]})
df1.combine_first(df2)
C. 数据透视表
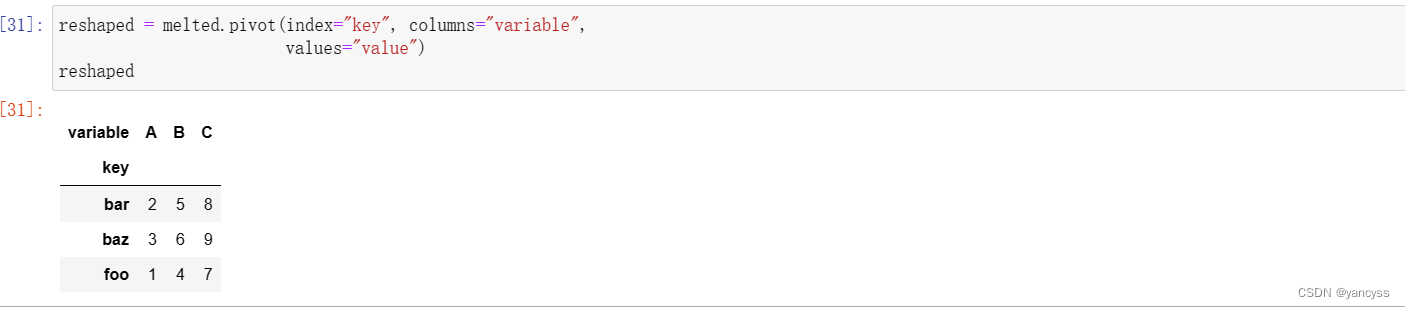
C.1 df.pivot
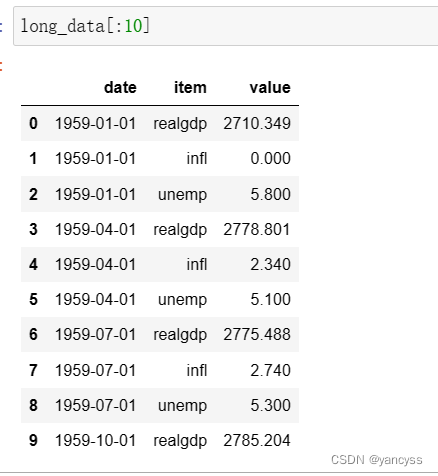
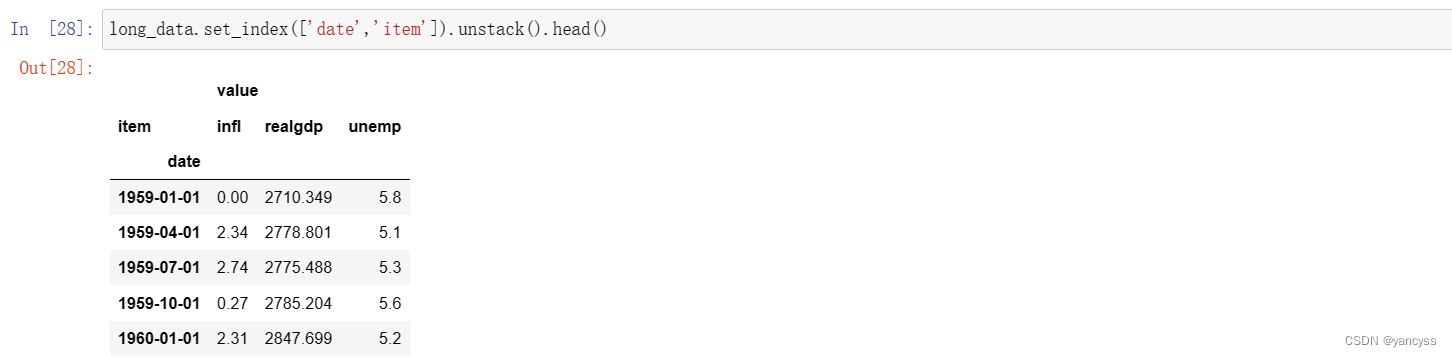
假设现在数据的解构如下表,item列代表不同的键(可以转换成很多列),value代表不同的值
现要将其转换为常规Df的新式,即每一列都是一种数据使用Df.pivot(index= ,columns=‘item’,value=)
如下图:
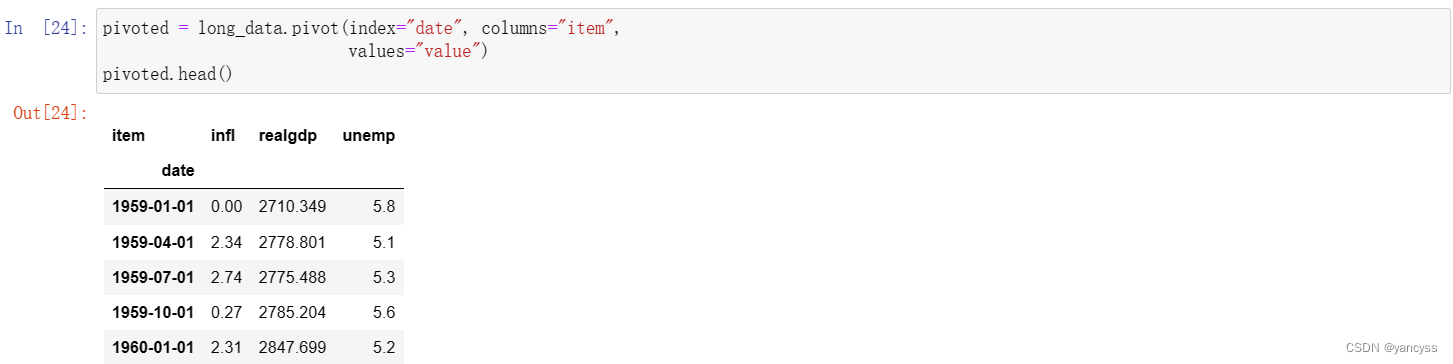
- 达到的效果和把item列移动到列索引类似。
C.2 pd.melt
pd.melt 与df.pivot达到的效果相反。
pd.melt(df,id_vars=‘key’)会将Df的各列合并成一列,其中id_vars可以不指定
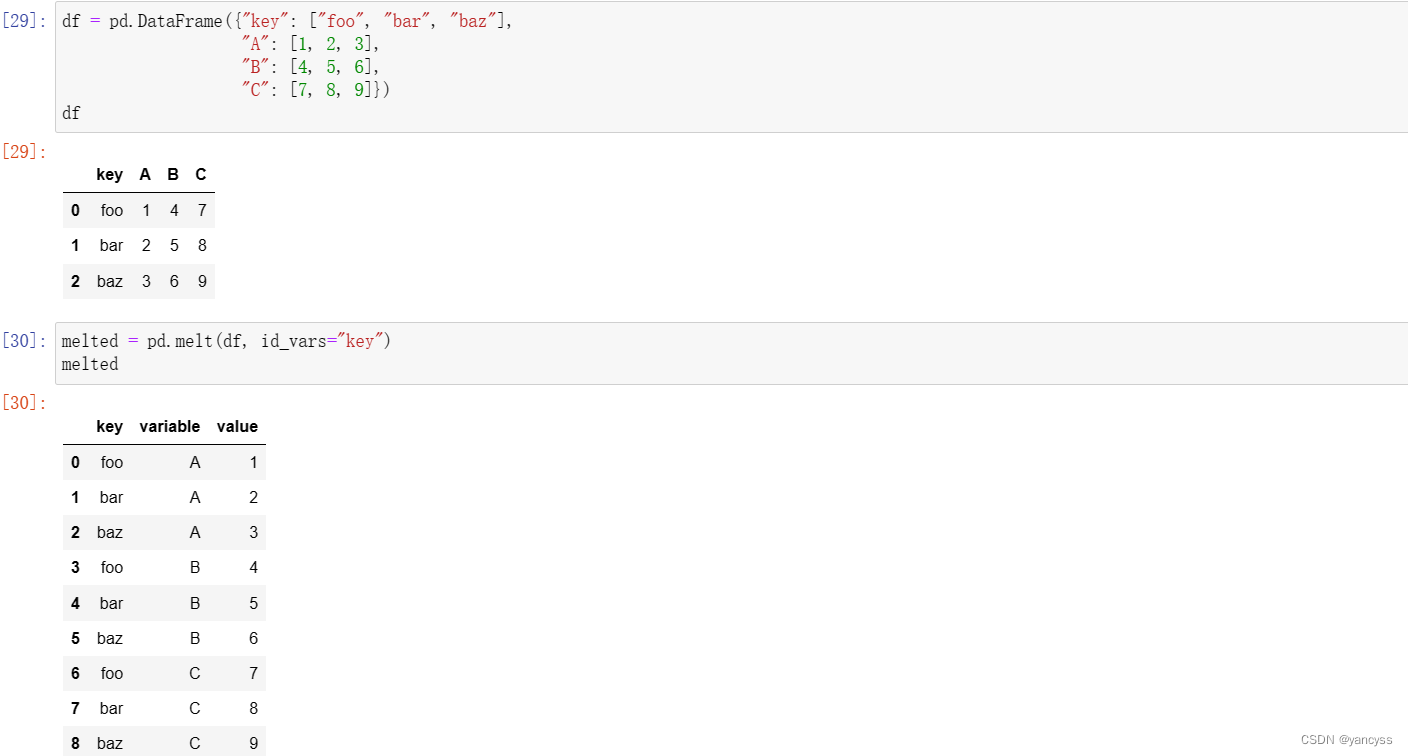
使用pivot复原