【今日】

目录
一 Stream接口简介
Optional类
Collectors类
二 数据过滤
1. filter()方法
2.distinct()方法
3.limit()方法
4.skip()方法
三 数据映射
四 数据查找
1. allMatch()方法
2. anyMatch()方法
3. noneMatch()方法
4. findFirst()方法
五 数据收集
1.数据统计
2.数据分组
流处理有点类似数据库的SQL语句,可以执行非常复杂的过滤、映射、查找和收集功能,并且代码量很少。唯一的缺点是代码可读性不高,如果开发者基础不好,可能会看不懂流API所表达的含义。
我们再这里先创建一个公共类----Employee 员工类,方便后续的流处理。
员工的集合数据
| 姓名(name) | 年龄(age) | 薪资(salary) | 性别(sex) | 部门(dept) |
| 老张 | 40 | 9000 | 男 | 运营部 |
| 小刘 | 24 | 5000 | 女 | 开发部 |
| 大刚 | 32 | 7500 | 男 | 销售部 |
| 翠花 | 28 | 5500 | 女 | 销售部 |
| 小马 | 21 | 3000 | 男 | 开发部 |
| 老王 | 35 | 6000 | 女 | 人事部 |
| 小王 | 21 | 3000 | 女 | 人事部 |
import java.util.ArrayList;
import java.util.List;public class Employee {//员工类private String name; //姓名private int age; //年龄private double salary; //薪资private String sex; //性别private String dept; //部门public Employee(String name, int age, double salary, String sex, String dept) {//构造方法this.name = name;this.age = age;this.salary = salary;this.sex = sex;this.dept = dept;}public String toString() {//重写toString()方法,输出员工信息return "姓名:" + name + ", 年龄:" + age + ", 薪资:" + salary + ", 性别:" + sex + ", 部门:" + dept;}//以下是获得员工相关信息的方法public String GetName() {//获得名字的方法return name;}public int GetAge() {//获得年龄的方法return age;}public double GetSalary() {//获得薪资的方法return salary ;}public String GetSex() {//获得性别的方法return sex;}public String Getdept() {//获得部门的方法return dept;}static List<Employee>GetEmpList(){List<Employee> list = new ArrayList<>();list.add(new Employee("老张",40,9000,"男","运营部"));list.add(new Employee("小刘",24,5000,"女","开发部"));list.add(new Employee("大刚",32,7500,"男","销售部"));list.add(new Employee("翠花",28,5500,"女","销售部"));list.add(new Employee("小马",21,3000,"男","开发部"));list.add(new Employee("老王",35,6000,"女","人事部"));list.add(new Employee("小王",21,3000,"女","人事部"));return list; }
}一 Stream接口简介
流处理的接口都定义在java.uil.stream包下。BaseStream接口是最基础的接口,但最常用的是BaseStream接口的一个子接口——Stream接口,基本上绝大多数的流处理都是在Stream接口上实现的。所忆, Stream接口是泛型接口,所以流中操作的元素可以是任何类的对象。
Stream接口的常用
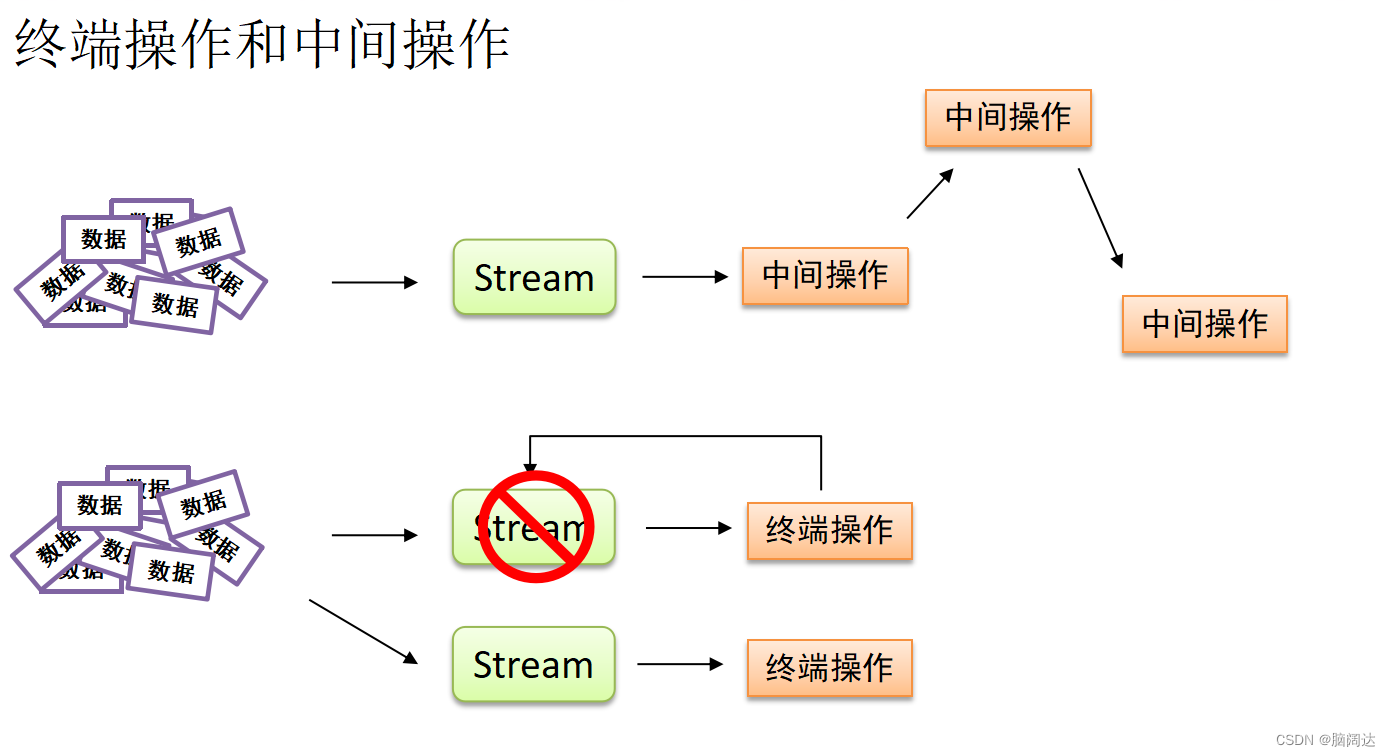
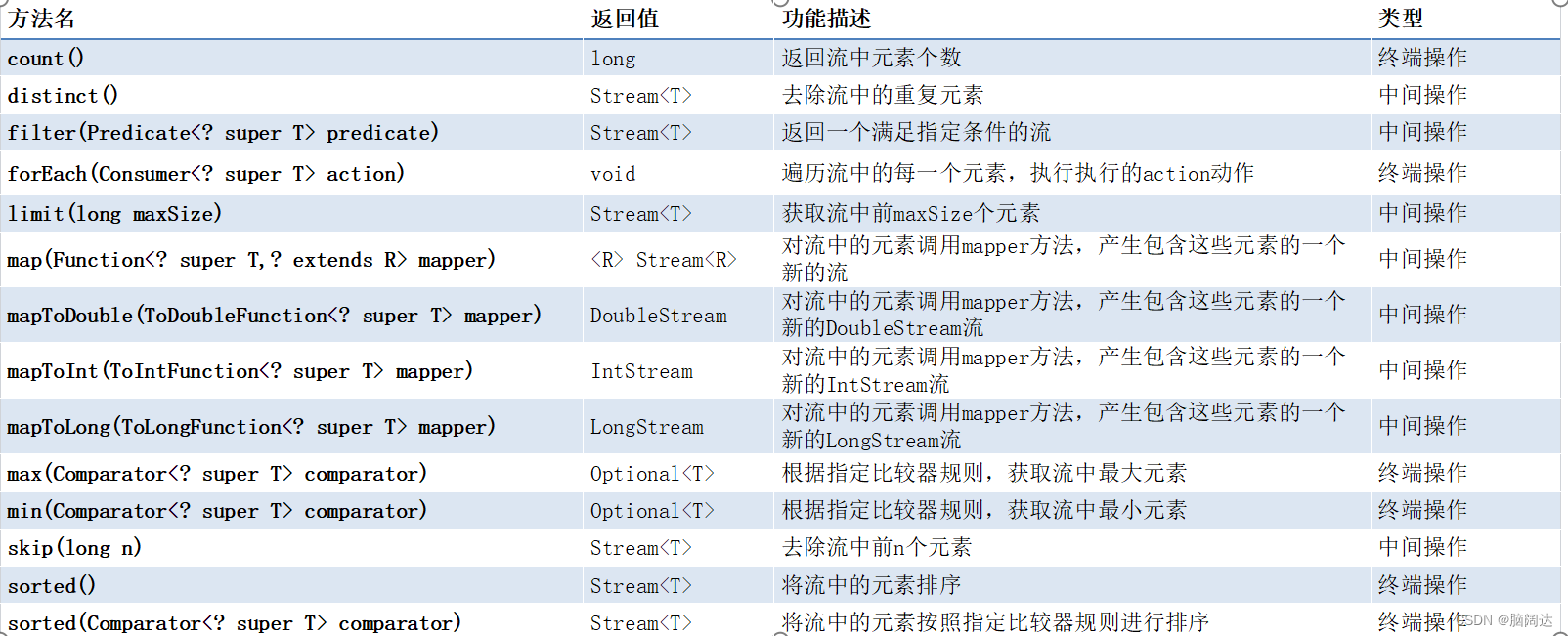 中间操作和终端操作。中间操作类型的方法会生成一个新的流对象,被操作的流对象仍然可以执行其他操作;终端操作会消费流,操作结束之后,被操作的流对象就不能再次执行其他操作了。这是两者的最大区别。
中间操作和终端操作。中间操作类型的方法会生成一个新的流对象,被操作的流对象仍然可以执行其他操作;终端操作会消费流,操作结束之后,被操作的流对象就不能再次执行其他操作了。这是两者的最大区别。
collection接口新增两个可以获取流对象的方法。第一个方法最常用,可以获取集合的顺序流,方下:
Stream<E> stream();第二个方法可以获取集合的并行流,方法如下:
Stream<E> parallelstream();因为所有集合类都是Collection接口的子类,如ArrayList类、HashSet类等,所以这些类都可以进行流处理。例如:
List<Integer> list = new ArrayList<Integer>(); //创建集合 Stream<Integer> s = list.stream(); //获取集合流对象
Optional类
Optional类像是一个容器,可以保存任何对象,并且针对 NullPointerException空指针异常做了化,保证Optional类保存的值不会是null。因此,Optional类是针对“对象可能是null也可能不是mlr的场景为开发者提供了优质的解决方案,减少了烦琐的异常处理。Optional类是用final修饰的,所以不能有子类。Optional类是带有泛型的类,所以该类可以保任何对象的值。
从Optional类的声明代码中就可以看出这些特性,JDK中的部分代码如下:
public final class Optional<T>(private final T value;......... //省略其他代码 }Optional类中有一个叫作value的成员属性,这个属性就是用来保存具体值的。value 是用泛型T修饰的,并且还用了final修饰,这表示一个Optional对象只能保存一个值。
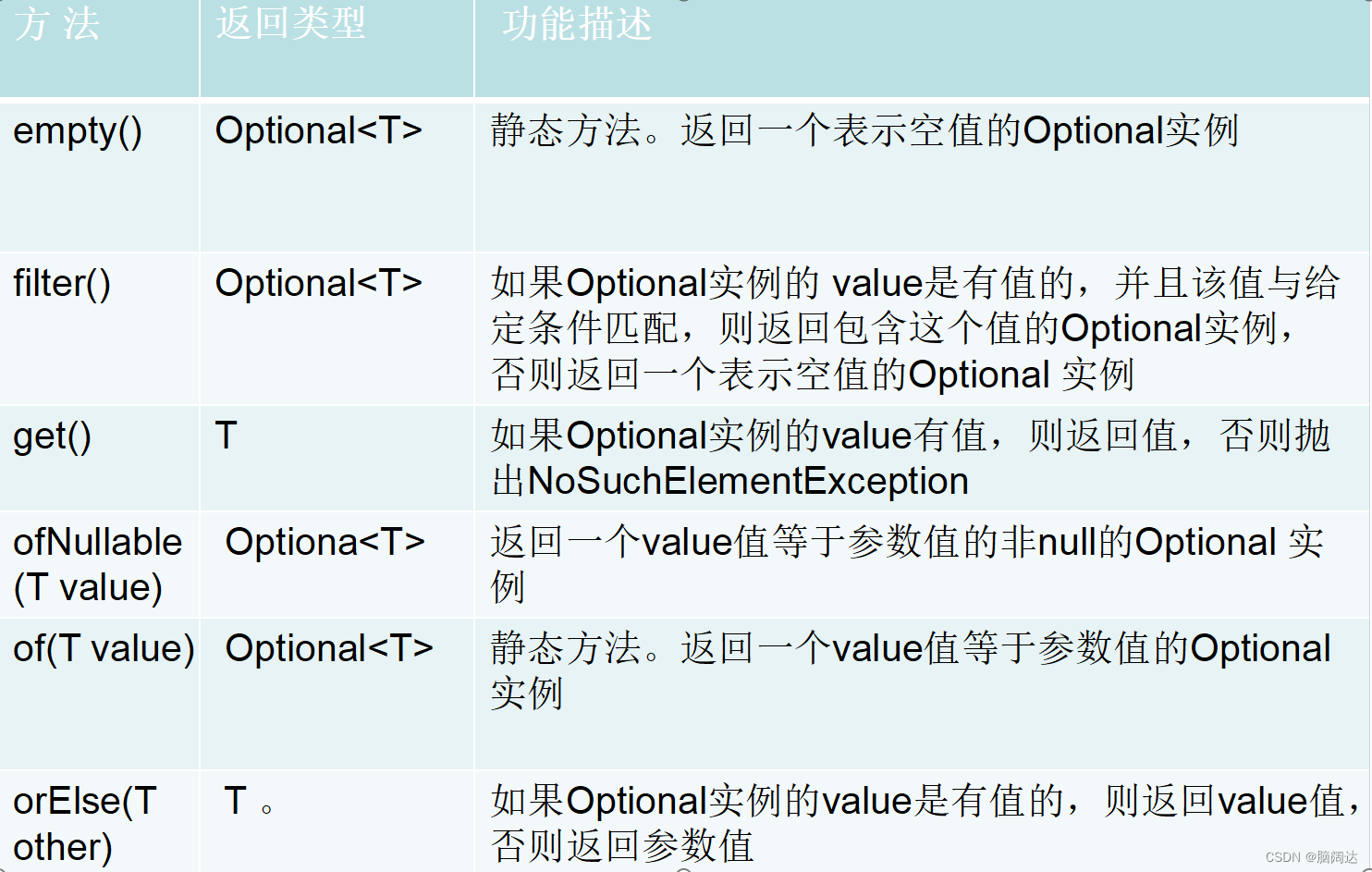
Optional类提供的常用方法
Collectors类
collectors类为收集器类,该类实现了java.util.Colleetor接口,可以将Stream流对象进行各种各样的封装、归集、分组等操作。同时,Collectors类还提供了很多实用的数据加工方法,如数据统计计算等.
collecctors类的方法 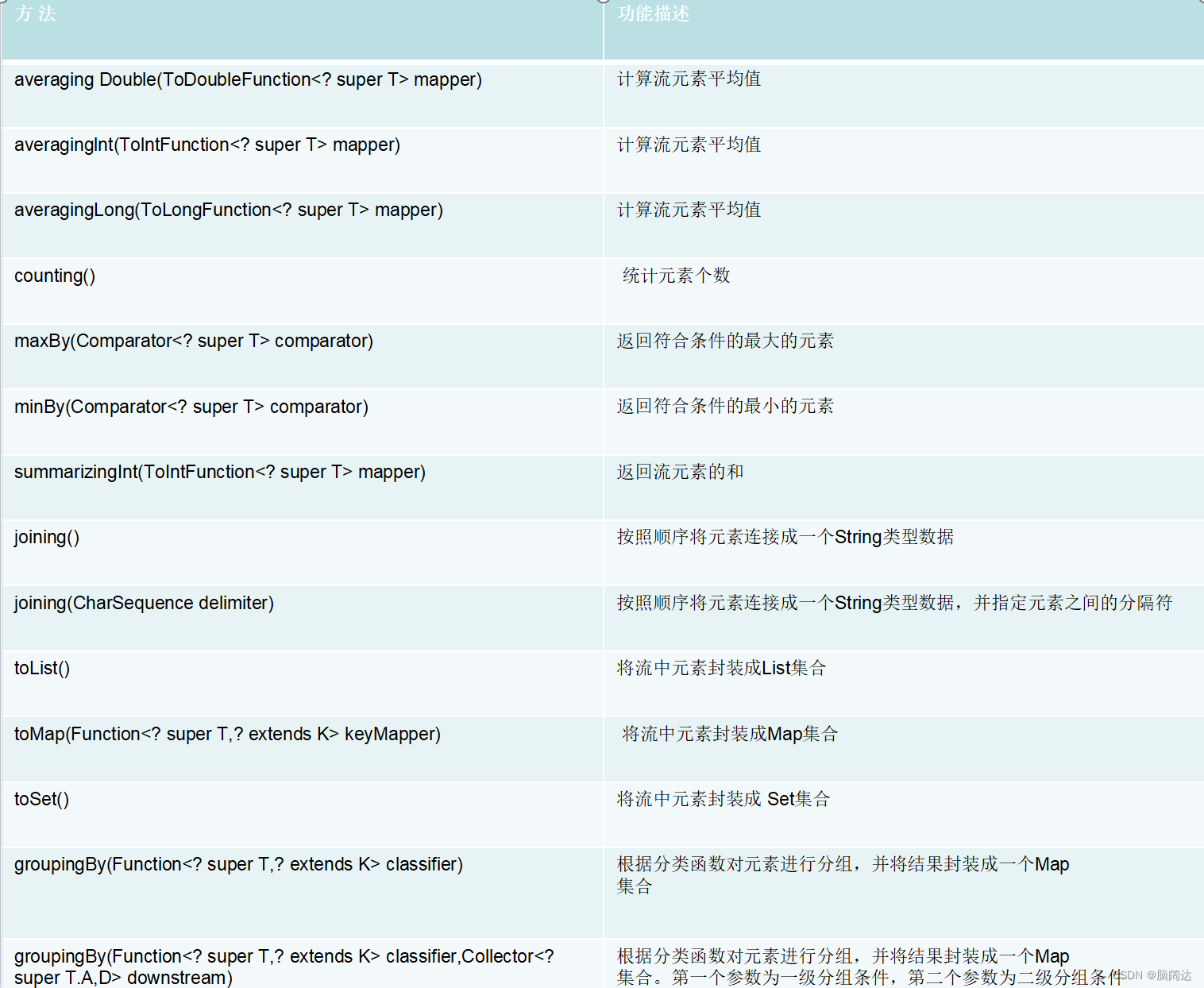
二 数据过滤
数据过滤就是在杂乱的数据中筛选出需要的数据,类似SQL语句中的WHERE关键字,给出一的条件,将符合条件的数据过滤并展示出来。
1. filter()方法
filter()方法是Stream接口提供的过滤方法。该方法可以将lambda表达式作为参数,然后按照lambà表达式的逻辑过滤流中的元素。过滤出想要的流元素后,还需使用Stream提供的collect0方法按照指定方法重新封装。
基于Employee 员工类实现:
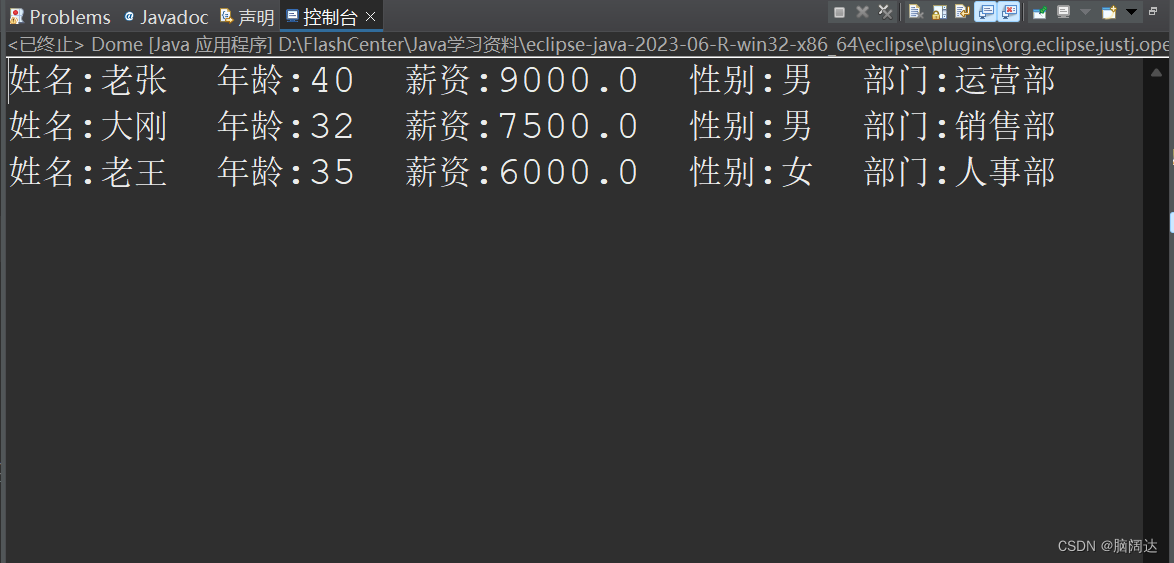
找出年龄大于30的员工
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//找出年龄大于30的员工List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream = stream.filter(e->e.GetAge()>30);List<Employee> result = stream.collect(Collectors.toList());for(Employee emp:result) {System.out.println(emp);}}
}
2.distinct()方法
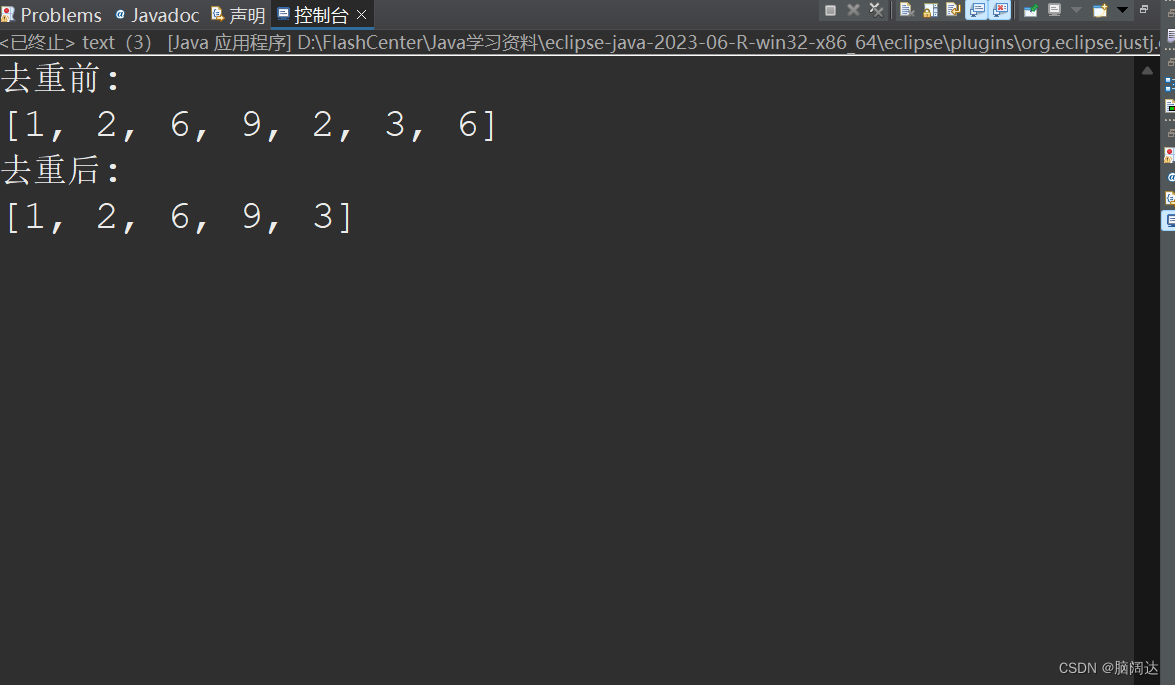
distinct)方法是Stream接口提供的过滤方法。该方法可以去除流中的重复元素,效果与SQL语句中的DISTINCT关键字一样。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class text {public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(6);list.add(9);list.add(2);list.add(3);list.add(6);System.out.println("去重前:");System.out.println(list);List<Integer> result = list.stream().distinct().collect(Collectors.toList());System.out.println("去重后:");System.out.println(result);}
}
3.limit()方法
limit()方法是Stream接口提供的方法,该方法可以获取流中前N个元素。
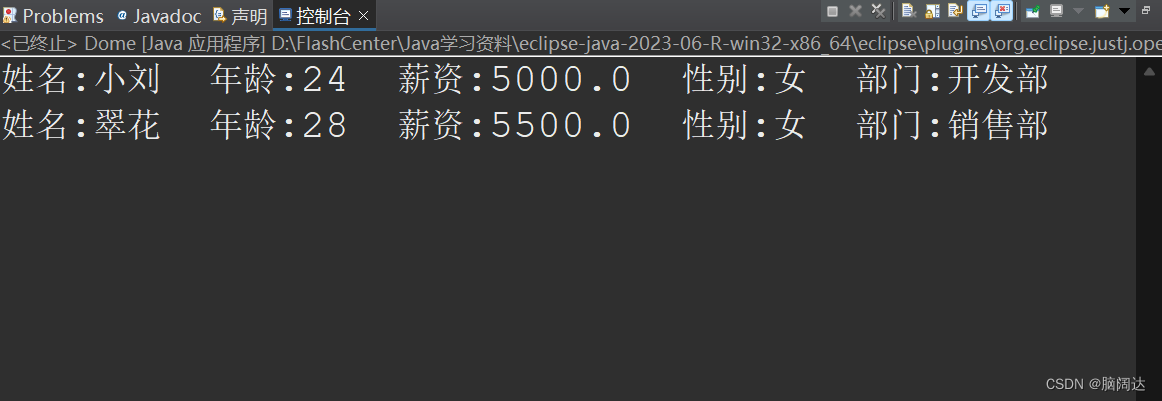
找出性别为女的前两名员工
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//找出性别为女的前两名员工List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream=stream.filter(e->e.GetSex().equals("女")).limit(2);List<Employee> result = stream.collect(Collectors.toList());for(Employee emp:result) {System.out.println(emp);}}
}
4.skip()方法
skip()方法是Stream接口提供的方法,该方法可以忽略流中的N个元素。
取出所有男员工,并忽略前两个。
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//找出性别为女的前两名员工List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream=stream.filter(e->e.GetSex().equals("男")).skip(2);List<Employee> result = stream.collect(Collectors.toList());for(Employee emp:result) {System.out.println(emp);}}
}// List<Employee> list = Employee.GetEmpList();list.stream().filter(e->e.GetSex().equals("男")).skip(2).forEach(n->{System.out.println(n);
这段代码可以替代上述的主代码实现相同功能
三 数据映射
数据的映射和过滤概念不同:过滤是在流中找到符合条件的元素,映射是在流中获得具体的数量Stream接口提供了map()方法用来实现数据映射,map()方法会按照参数中的函数逻辑获取新的对象,新的流对象中元素类型可能与旧流对象元素类型不相同。

import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
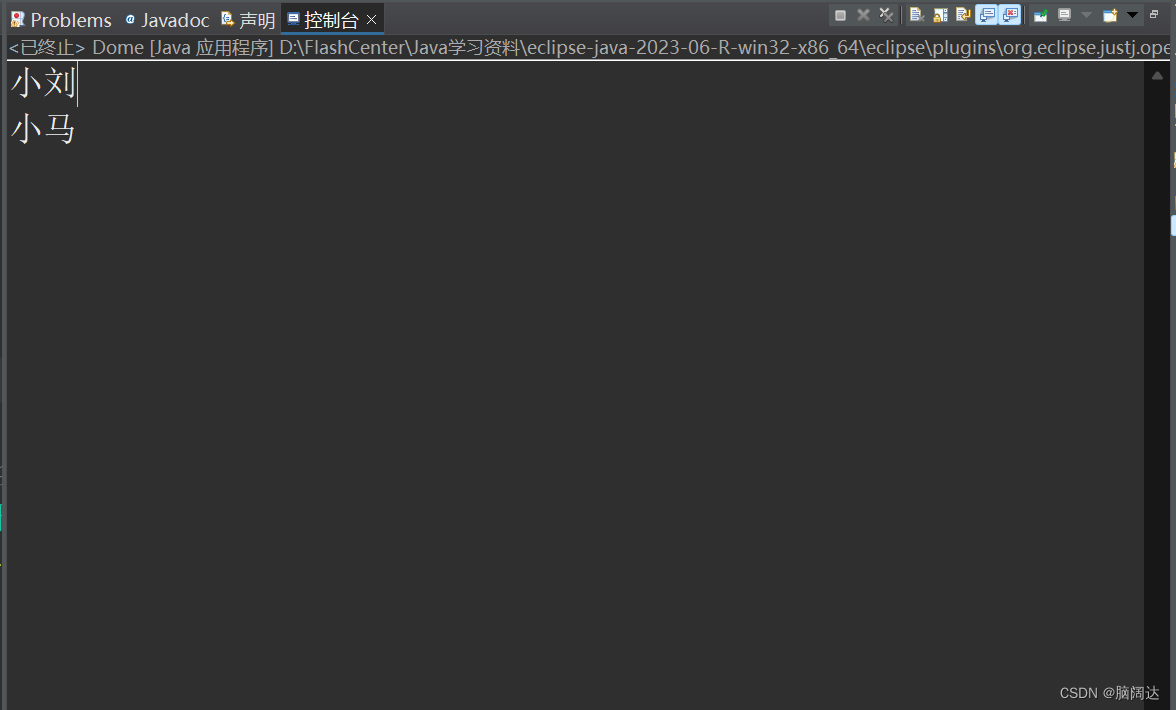
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {//获取开发部的所有员工的名单List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream = list.stream();//获取集合流对象stream=stream.filter(e->e.Getdept().equals("开发部"));Stream<String> names = stream.map(Employee::GetName);//获取集合流对象List<String> result = names.collect(Collectors.toList());for(String emp:result) {System.out.println(emp);}}
}
四 数据查找
1. allMatch()方法
allMatchO方法是Stream接口提供的方法,该方法会判断流中的元素是否全部符合某一条件,返回结果是boolean值。如果所有元素都符合条件则返回true,否则返回false。
【代码实列】
import java.util.List;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息boolean result= list.stream().allMatch(n->n.GetAge()>25);System.out.println("所有员工是否都大于25岁:"+result);}
}【运行结果】 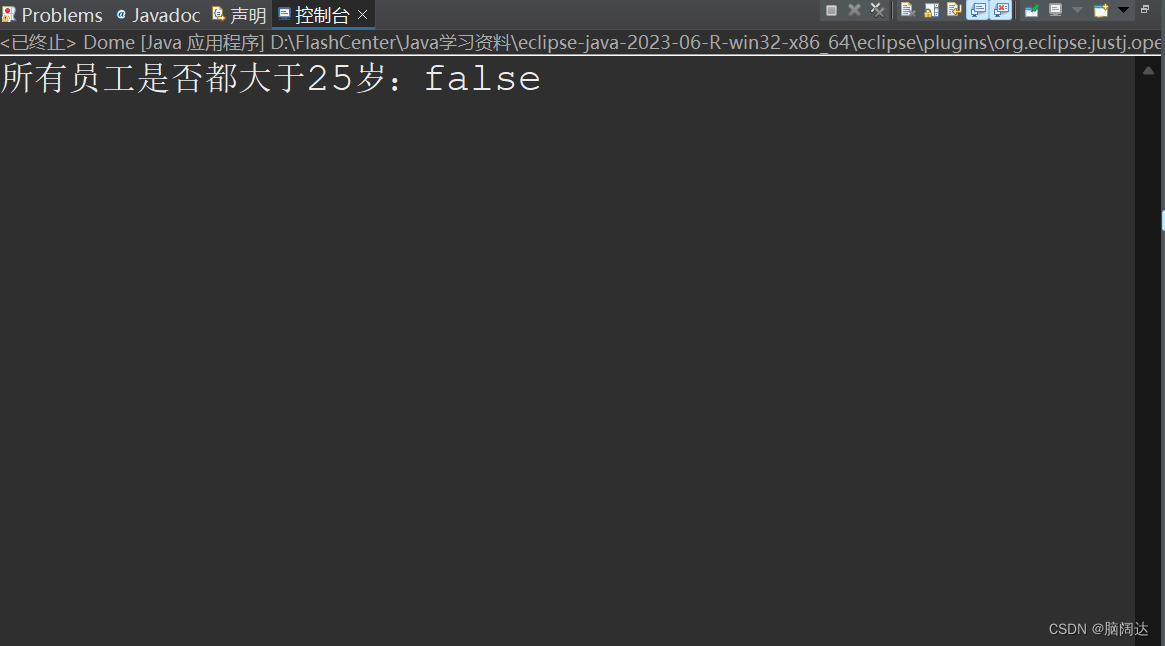
2. anyMatch()方法
anyMatchO方法是Stream接口提供的方法,该方法会判断流中的元素是否有符合某一条件,只要有一个元素符合条件就返回true,如果没有元素符合条件才会返回false。
【代码实列】
import java.util.List;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息boolean result= list.stream().anyMatch(n->n.GetAge()>=40);System.out.println("该公司员工是否有40或以上的工岁吗?:"+result);}
} 【运行结果】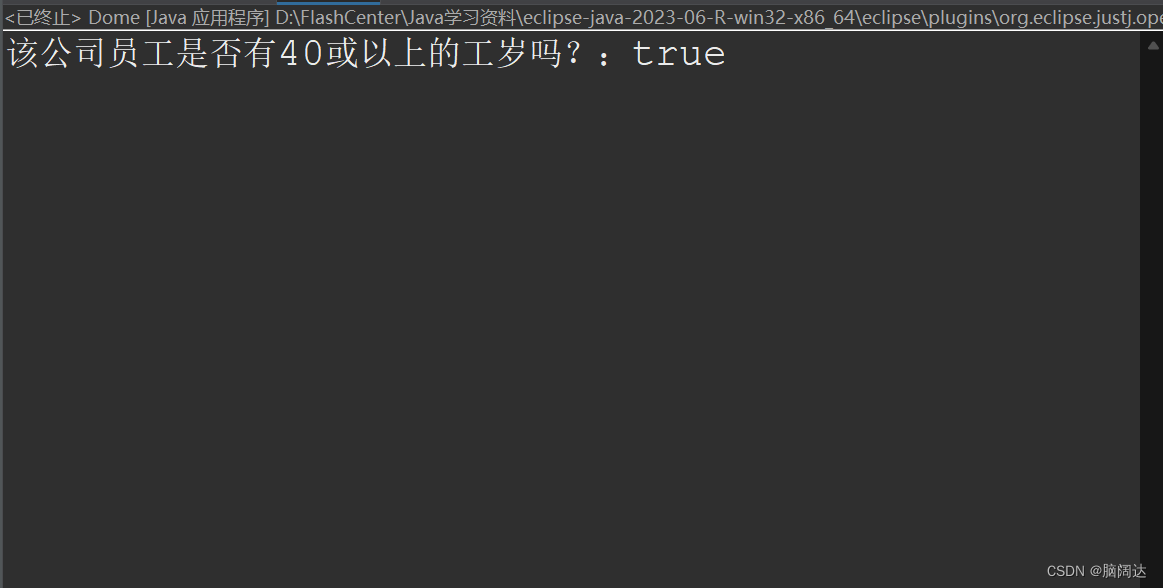
3. noneMatch()方法
noneMatch()方法是Stream接口提供的方法,该方法会判断流中的所有元素是否都不符合某一条件。这个方法的逻辑和allMatch()方法正好相反。
【代码实列】
import java.util.List;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息boolean result= list.stream().noneMatch(e->e.GetSalary()<2000);System.out.println("该公司员工是否不存在工资低于2000的员工?:"+result);}
} 【运行结果】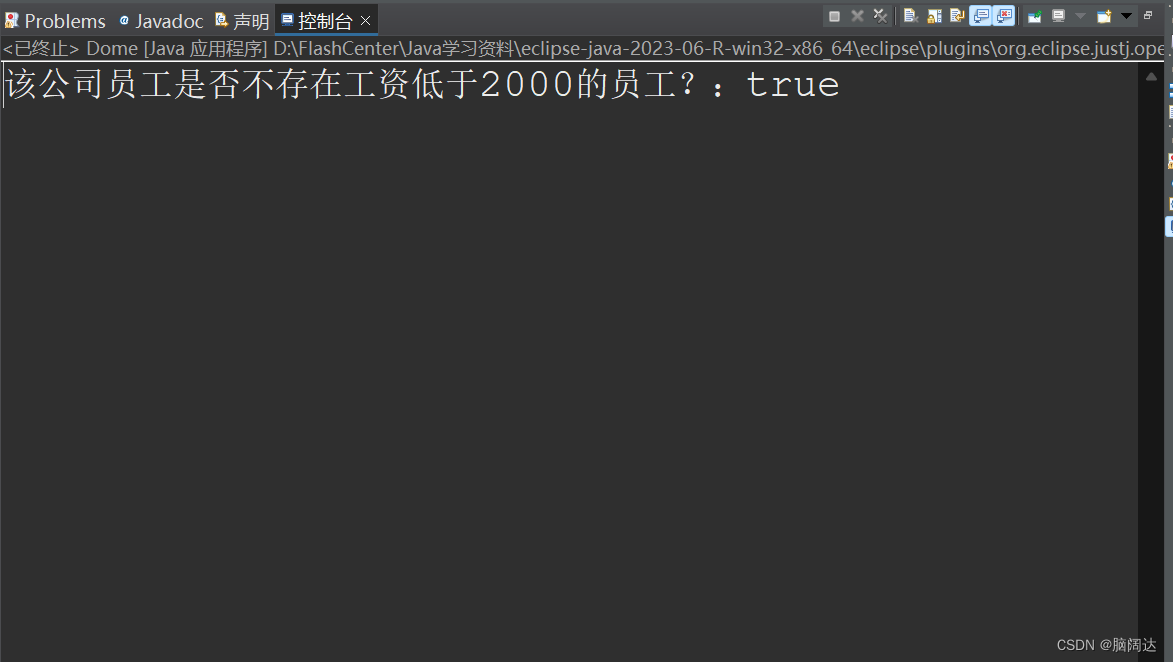
4. findFirst()方法
findFirst方法是Stream接口提供的方法,这个方法会返回符合条件的第一个元素。
【代码实列】
import java.util.List;
import java.util.Optional;
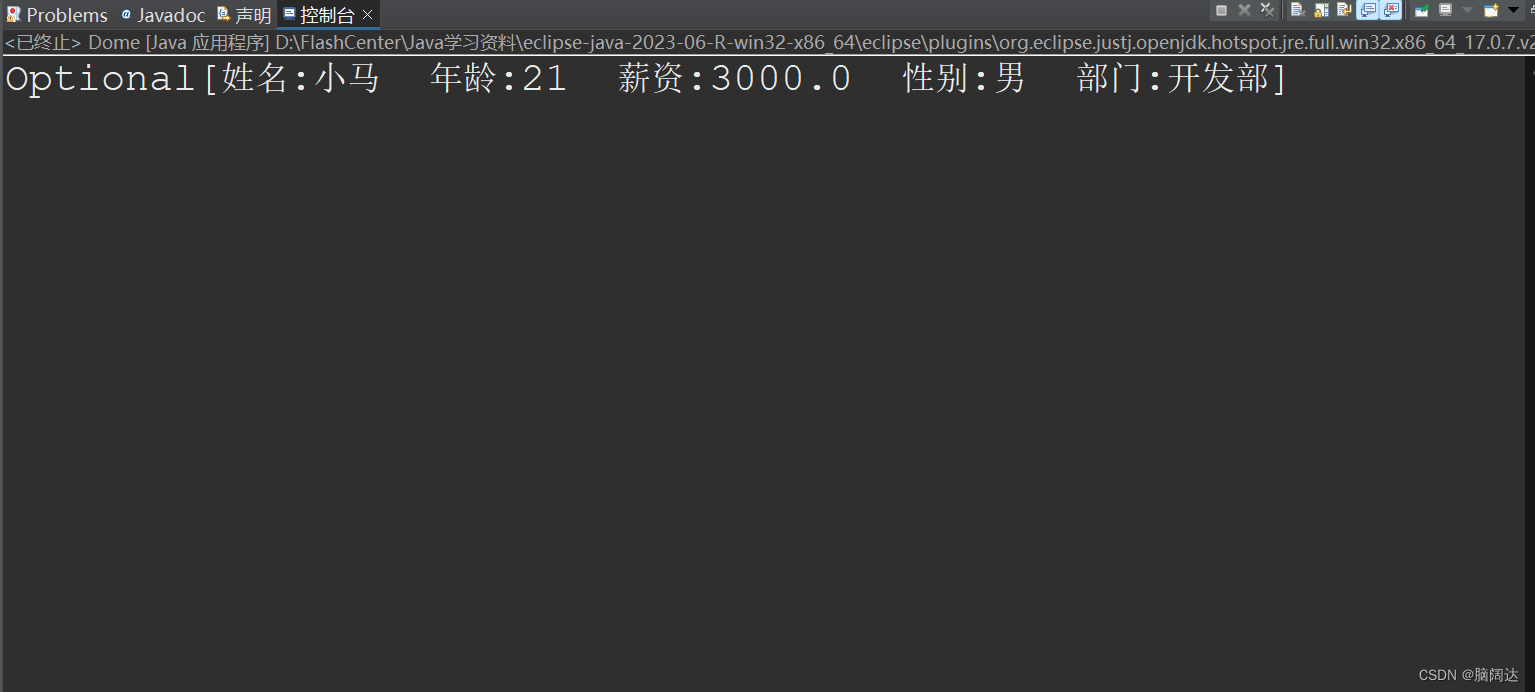
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Stream<Employee> stream= list.stream().filter(e->e.GetAge()==21);Optional<Employee> e =stream.findFirst();System.out.println(e);}
} 【运行结果】
五 数据收集
1.数据统计
数据统计不仅可以筛选出特殊元素,还可以对元素的属性进行统计计算。这种复杂的统计操作不是由Stream实现的,而是由Collectors收集器类实现的,收集器提供了非常丰富的API,有着强大的数据挖掘能力。
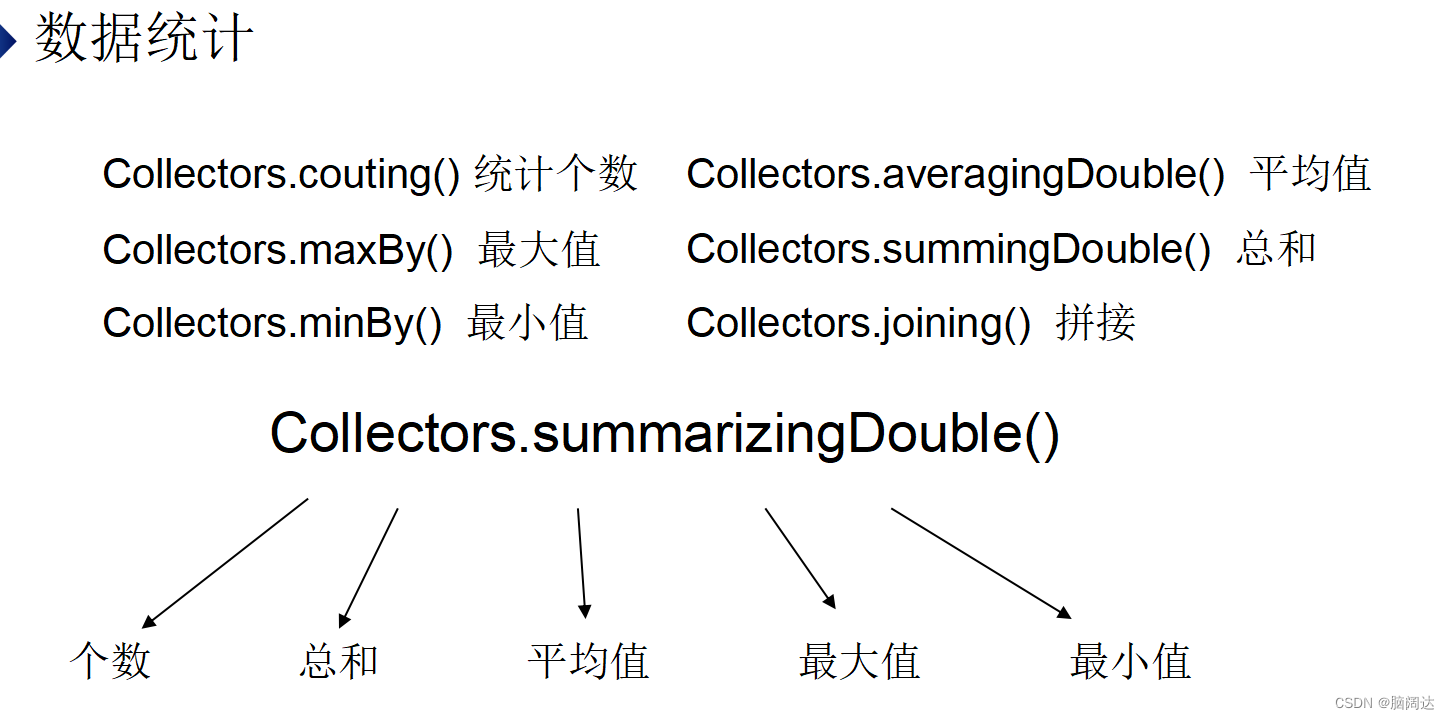
【代码实列】
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collector;
import java.util.stream.Collectors;
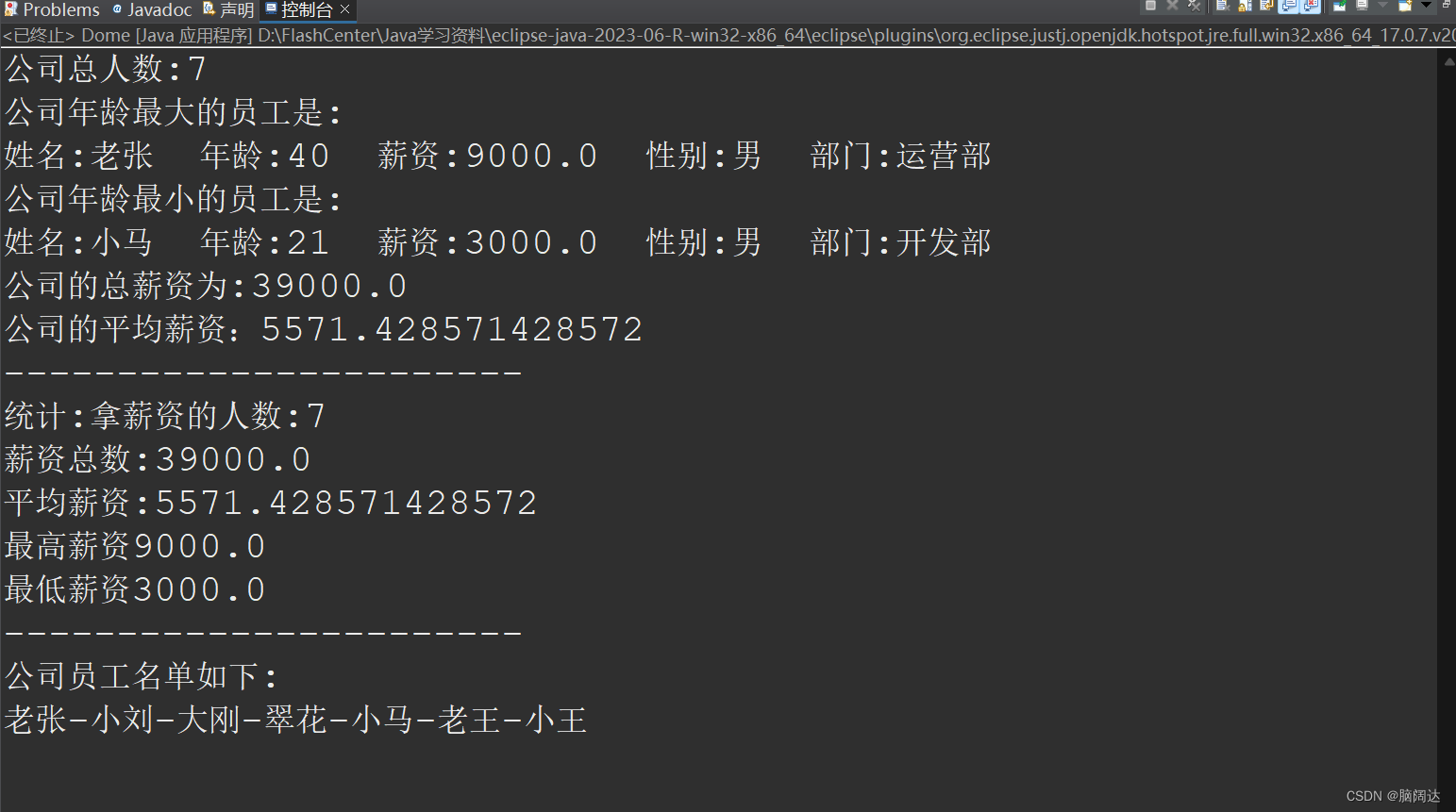
import java.util.stream.Stream;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息//输出公司总人数long count = list.stream().collect(Collectors.counting());count = list.stream().count();System.out.println("公司总人数:"+count);//输出公司年龄最大的员工Optional<Employee> ageMax= list.stream().collect(Collectors.maxBy(Comparator.comparing(Employee::GetAge)));Employee oder = ageMax.get();System.out.println("公司年龄最大的员工是:");System.out.println(oder);//输出公司年龄最大的Optional<Employee> ageMin= list.stream().collect(Collectors.minBy(Comparator.comparing(Employee::GetAge)));Employee younger = ageMin.get();System.out.println("公司年龄最小的员工是:");System.out.println(younger);//输出公司的总薪资double sum = list.stream().collect(Collectors.summingDouble(Employee::GetSalary));System.out.println("公司的总薪资为:"+sum);//统计公司薪资的平均值double Avg = list.stream().collect(Collectors.averagingDouble(Employee::GetSalary));System.out.println("公司的平均薪资:"+Avg);System.out.println("-----------------------");java.util.DoubleSummaryStatistics s = list.stream().collect(Collectors.summarizingDouble(Employee::GetSalary));System.out.println("统计:拿薪资的人数:"+s.getCount()+" ");System.out.println("薪资总数:"+s.getSum()+" ");System.out.println("平均薪资:"+s.getAverage()+" ");System.out.println("最高薪资"+s.getMax()+" ");System.out.println("最低薪资"+s.getMin()+" ");System.out.println("-----------------------");String nameList = list.stream().map(Employee::GetName).collect(Collectors.joining("-"));System.out.println("公司员工名单如下:\n"+nameList);}
} 【运行结果】
2.数据分组
😶🌫️😶🌫️😶🌫️数据分组就是将流中元素按照指定的条件分开保存,类似SQL语言中的“GROUPBY”关键字。分组之后的数据会按照不同的标签分别保存成一个集合,然后按照“键值”关系封装在Map对象中。数据分组有一级分组和多级分组两种场景,首先先来介绍一级分组。
一级分组,就是将所有数据按照一个条件进行归类。例如,学校有100个学生,这些学生分布在3个年级中。学生按照年级分成了3组,然后就不再细分了,这就属于一级分组。
Collectors类提供的groupingBy0方法就是用来进行分组的方法,方法参数是一个Function接口对象,收集器会按照指定的函数规则对数据进行分组。

一级分组:
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Map<String,List<Employee>> map = list.stream().collect(Collectors.groupingBy(Employee::Getdept));for(String key:map.keySet()) {System.out.println("【"+key+"】");List<Employee> deptList = map.get(key);for(Employee e:deptList) {System.out.println(e);}}}
} 
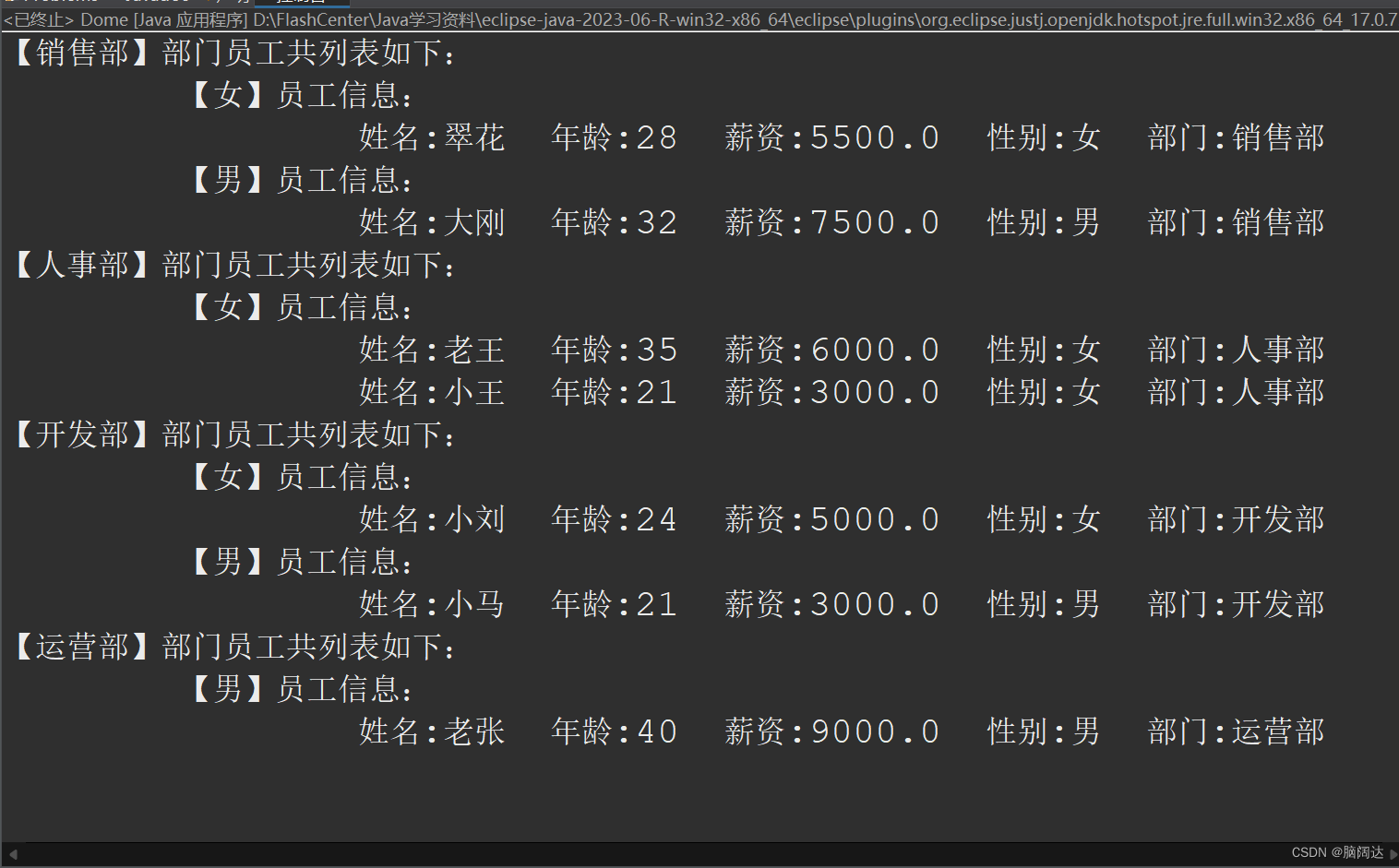
二级分组:
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;public class Dome{public static void main(String[] args) {List<Employee> list = Employee.GetEmpList();//先获取所有的员工测试信息Map<String,Map<String,List<Employee>>> map1 = list.stream().collect(Collectors.groupingBy(Employee::Getdept,Collectors.groupingBy(Employee::GetSex)));for(String key1:map1.keySet()) {System.out.println("【"+key1+"】"+"部门员工共列表如下:");Map<String,List<Employee>> map2 = map1.get(key1);for(String key2:map2.keySet()) {System.out.println("\t【"+key2+"】"+"员工信息:");for(Employee e:map2.get(key2)) {System.out.println("\t\t"+e);}}}}
}