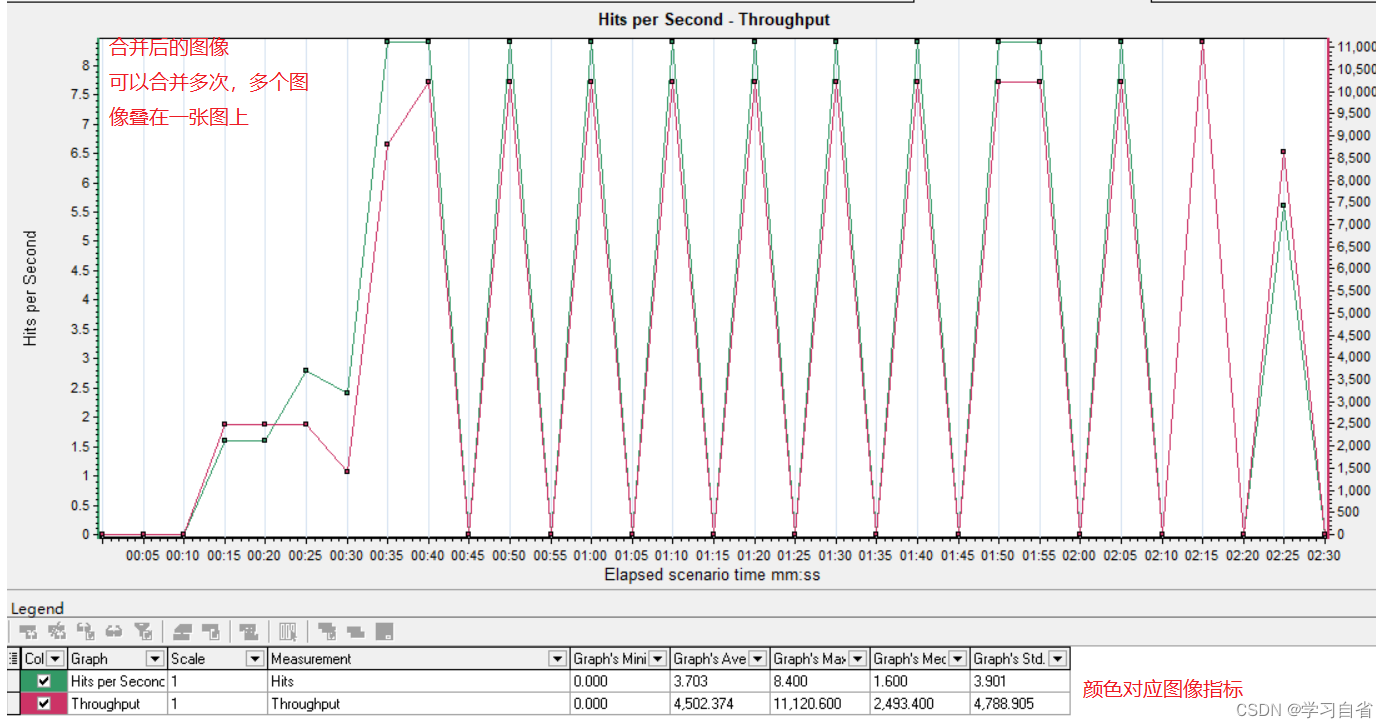
查看访问日志时候发现有SemrushBot爬虫
![]()
屏蔽方法:
使用robots.txt文件是一种标准的协议,用于告诉搜索引擎哪些页面可以和不能被爬取,如想禁止Googlebot爬取整个网站的话,可以在该文件中添加以下内容:
User-agent: Googlebot
Disallow: /对于遵循robots协议的蜘蛛,可以直接在robots禁止。上面常见的无用蜘蛛禁止方法如下,将下面的内容加入到网站根目录下面的robots.txt就可以了。
User-agent: SemrushBot Disallow: / User-agent: DotBot Disallow: / User-agent: MegaIndex.ru Disallow: / User-agent: MauiBot Disallow: / User-agent: AhrefsBot Disallow: / User-agent: MJ12bot Disallow: / User-agent: BLEXBot Disallow: /
恶意蜘蛛列表
- SemrushBot,这是semrush下面的一个蜘蛛,是一家做搜索引擎优化的公司,因此它抓取网页的目的就很明显了。这种蜘蛛对网站没有任何用处,好在它还遵循robots协议,因此可以直接在robots屏蔽。
- DotBot, 这是moz旗下的,作用是提供seo服务的蜘蛛,但是对我们并没有什么用处。好在遵循robots协议,可以使用robots屏蔽
- AhrefsBot, 这是ahrefs旗下的蜘蛛,作用是提供seo服务,对我们没有任何用处,遵循robots协议。
- MJ12bot,这是英国的一个搜索引擎蜘蛛,但是对中文站站点就没有用处了,遵循robots协议。
- MauiBot,这个不太清楚是什么,但是有时候很疯狂,好在遵循robots协议。
- MegaIndex.ru,这是一个提供反向链接查询的网站的蜘蛛,因此它爬网站主要是分析链接,并没有什么作用。遵循robots协议。
- BLEXBot, 这个是webmeup下面的蜘蛛,作用是收集网站上面的链接,对我们来说并没有用处。遵循robots协议



![java八股文面试[JVM]——垃圾回收器](https://img-blog.csdnimg.cn/a56639a6c9c0481686b5d4b72b114552.jpeg#pic_center)