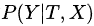感谢阅读
- 注意不含评估以后的翻译
- 原论文地址
- 标题以及摘要
- 介绍部分
- MiniRAG 框架
- 2.1 HETEROGENEOUS GRAPH INDEXING WITH SMALL LANGUAGE MODELS
- 2.2 LIGHTWEIGHT GRAPH-BASED KNOWLEDGE RETRIEVAL
- 2.2.1 QUERY SEMANTIC MAPPING
- 2.2.2 TOPOLOGY-ENHANCED GRAPH RETRIEVAL
注意不含评估以后的翻译
原论文地址
点我跳转
标题以及摘要
MINIRAG: TOWARDS EXTREMELY SIMPLE
RETRIEVAL-AUGMENTED GENERATION
MINIRAG:朝着极简的检索增强生成方法迈进
ABSTRACT
The growing demand for efficient and lightweight Retrieval-Augmented Generation (RAG) systems has highlighted significant challenges when deploying Small Language Models (SLMs) in existing RAG frameworks. Current approaches face severe performance degradation(退化,腿部,这里翻译成下降) due to SLMs’ limited semantic(语义) understanding and text processing capabilities, creating barriers for widespread adoption in resource-constrained scenarios. To address these fundamental limitations, we present MiniRAG a novel RAG system designed for extreme simplicity and efficiency. MiniRAG introduces two key technical innovations: (1) a semantic-aware heterogeneous graph indexing mechanism that combines text chunks and named entities in a unified structure, reducing reliance on complex semantic understanding, and (2) a lightweight topology-enhanced retrieval approach that leverages graph structures for efficient knowledge discovery without requiring advanced language capabilities. Our extensive experiments demonstrate that MiniRAG achieves comparable performance to LLM-based methods even when using SLMs while requiring only 25% of the storage space. Additionally, we contribute a comprehensive benchmark dataset for evaluating lightweight RAG systems under realistic on-device scenarios with complex queries. We fully open-source our implementation and datasets at: https://github.com/HKUDS/MiniRAG.
摘要
随着对高效且轻量级的检索增强生成(RAG)系统的需求不断增加,在现有的RAG框架中部署小型语言模型(SLM)时出现了显著的挑战。目前的方法由于SLM在语义理解和文本处理能力上的限制,面临严重的性能下降,这为资源受限的场景中的广泛应用带来了障碍。为了应对这些根本性限制,我们提出了MiniRAG,这是一种为极简和高效设计的新型RAG系统。MiniRAG引入了两个关键技术创新:(1)一种语义感知的异构图索引机制,将文本块和命名实体结合成一个统一的结构,从而减少对复杂语义理解的依赖;(2)一种轻量级的拓扑增强检索方法,利用图结构进行高效的知识发现,而无需高级语言能力。我们的广泛实验表明,即使在使用SLM的情况下,MiniRAG也能实现与基于大语言模型(LLM)的方法相媲美的性能,同时只需25%的存储空间。此外,我们还贡献了一个综合基准数据集,用于在复杂查询的现实设备场景下评估轻量级RAG系统。我们的实现和数据集已完全开源,地址为:https://github.com/HKUDS/MiniRAG。
介绍部分
Recent advancements in Retrieval-Augmented Generation (RAG) have significantly changed how language models access and utilize external knowledge, showcasing impressive capabilities in a wide range of applications, from question answering to document synthesis (Fan et al., 2024). These systems have achieved remarkable performance by leveraging sophisticated retrieval mechanisms and powerful language models. However, they predominantly rely on Large Language Models (LLMs) throughout their entire pipeline—covering tasks from index construction and knowledge retrieval to final response generation (Gao et al., 2023).This heavy reliance on LLMs introduces substantial computational overhead and resource demands, creating significant barriers to deploying such systems in resource-constrained environments, such as edge devices, privacy-sensitive applications, and real-time processing systems (Liu et al., 2024). Despite the growing demand for efficient and lightweight language model applications, current RAG frameworks offer limited solutions to maintain strong performance under these practical constraints, exposing a critical gap between theoretical capabilities and real-world deployment needs.
近期在检索增强生成(RAG)领域的进展,彻底改变了语言模型访问和利用外部知识的方式,展示了在广泛应用中的卓越能力,从问答到文档生成(F,2024)。这些系统通过复杂的检索机制和强大的语言模型取得了显著的性能。然而,它们在整个流程中主要依赖于大语言模型(LLM),从索引构建和知识检索到最终响应生成(G,2023)。对LLM的这种广泛依赖引入了巨大的计算开销和资源需求,这为在资源受限的环境中部署系统,如边缘设备、隐私敏感应用和实时处理系统,带来了显著的障碍(Liu等人,2024)。尽管对高效和轻量级语言模型应用的需求不断增长,当前的RAG框架在这些实际约束条件下维持强大性能的解决方案有限,暴露了理论能力与现实部署需求之间的关键差距。
The limitations of existing RAG systems become particularly evident when attempting to deploy Small Language Models (SLMs) for resource-efficient(高效利用资源) applications. While these compact models offer significant advantages in computational efficiency and deployment flexibility, they encounter fundamental challenges in key RAG operations, such as semantic understanding and effective information retrieval.Current RAG architectures, like LightRAG (Guo et al., 2024) and GraphRAG (Edge et al., 2024), were originally designed to leverage the sophisticated capabilities of Large Language Models (LLMs). However, these architectures fail to accommodate the inherent constraints of SLMs in several critical functions. Specifically, SLMs struggle with tasks such as sophisticated query interpretation, multi-step reasoning, semantic matching between queries and documents, and nuanced information synthesis.This architectural mismatch manifests in two major ways: either severe performance degradation, where accuracy significantly drops, or complete system failure, where certain advanced RAG frameworks become entirely inoperable when transitioning from LLMs to SLMs.
现有RAG系统的局限性在尝试利用小型语言模型(SLM)进行资源高效部署时尤为明显。尽管这些紧凑型模型在计算效率和部署灵活性方面具有显著优势,但它们在关键的RAG操作中面临根本性挑战——从语义理解到有效的信息检索。目前的RAG架构(例如2024年Guo等人做的LightRAG和Edge他们做的GraphRAG),最初设计时是为了利用LLM的复杂能力,但未能适应SLM在多个关键功能中的固有限制:复杂的查询解释、多步推理、查询与文档之间的语义匹配以及细致的信息综合。这种架构不匹配表现为两种主要方式:一种是性能严重下降,导致准确度下降;另一种是系统完全失效,当从LLM过渡到SLM时,某些先进的RAG框架变得完全无法操作。
To address these fundamental(根本性的) challenges, we introduce MiniRAG, a novel RAG system that reimagines the information retrieval and generation pipeline with an emphasis on extreme simplicity and computational efficiency. Our design is based on three key observations about Small Language Models (SLMs): (1) although SLMs struggle with complex semantic understanding, they excel in pattern matching and localized text processing; (2) explicit structural information can effectively compensate for their limited semantic capabilities; and (3) breaking down complex RAG operations into simpler, well-defined steps can preserve system robustness without requiring advanced reasoning abilities. These insights led us to prioritize structural knowledge representation over semantic complexity, marking a significant shift away from traditional LLM-centric RAG architectures.
为了解决这些根本性的挑战,我们提出了MiniRAG,一种创新的RAG系统,它重新构想了信息检索和生成流程,重点关注极简性和计算效率。我们的设计基于对小型语言模型(SLM)的三个关键观察:(1)虽然SLM在复杂的语义理解方面存在困难,但它们在模式匹配和局部文本处理方面表现出色;(2)显式的结构信息可以有效弥补其有限的语义能力;(3)将复杂的RAG操作分解为更简单、定义明确的步骤可以在不需要高级推理能力的情况下保持系统的鲁棒性。这些洞察促使我们优先考虑结构化知识表示而非语义复杂性,从而标志着与传统LLM中心的RAG架构的显著不同。
Our design of MiniRAG is driven by three fundamental observations: (1) although Small Language Models (SLMs) struggle with semantic understanding, they excel in pattern matching and localized text processing; (2) explicit structural information can compensate for their limited semantic capabilities by providing navigational cues for retrieval; and (3) breaking down complex RAG operations into simpler, well-defined steps can maintain system robustness without requiring advanced reasoning capabilities. These insights led us to prioritize structural knowledge representation over semantic complexity, leveraging graph-based patterns that align with SLMs’ strengths while bypassing their limitations. This design philosophy allows MiniRAG to achieve efficient and reliable performance even with lightweight models, marking a significant shift away from traditional LLM-centric RAG architectures.
MiniRAG的设计受到三个基本观察的启发:(1)尽管小型语言模型(SLM)在语义理解方面存在困难,但它们在模式匹配和局部文本处理方面表现出色;(2)显式的结构信息可以通过提供检索的导航线索,弥补其有限的语义能力;(3)将复杂的RAG操作分解为更简单、定义明确的步骤,可以在不需要高级推理能力的情况下保持系统的鲁棒性。这些洞察促使我们优先考虑结构化知识表示而非语义复杂性,并利用图结构模式,这些模式自然与SLM的优势相契合,同时绕过了它们的局限性。这一设计理念使得MiniRAG即便在轻量级模型下,也能实现高效且可靠的性能,标志着与传统LLM中心的RAG架构的重大不同。
Our MiniRAG introduces two key technical innovations that capitalize on these insights: (1) a semantic-aware heterogeneous graph indexing mechanism that combines text chunks and named entities into a unified structure, thereby reducing reliance on complex semantic understanding, and (2) a lightweight, topology-enhanced retrieval approach that utilizes graph structures and heuristic search patterns for efficient knowledge discovery. Through thoughtful design choices and architectural optimization, these components work together synergistically to enable robust RAG functionality, even with limited model capabilities, fundamentally reimagining how RAG systems can operate within the constraints of SLMs while leveraging their strengths.
我们的MiniRAG引入了两项关键技术创新,充分利用了这些洞察:(1)一种语义感知的异构图索引机制,将文本块和命名实体结合成一个统一的结构,从而减少对复杂语义理解的依赖;(2)一种轻量级的拓扑增强检索方法,利用图结构和启发式搜索模式进行高效的知识发现。通过精心的设计选择和架构优化,这些组件协同工作,使得即使在模型能力有限的情况下,也能实现强大的RAG功能,根本性地重新构想了RAG系统如何在SLM的约束下操作,同时发挥其优势。
Through extensive experimentation across various datasets and Small Language Models (SLMs), we demonstrate the exceptional performance of MiniRAG. Compared to existing lightweight RAG systems, MiniRAG achieves 1.3 to 2.5 times higher effectiveness while using only 25% of the storage space. Even when transitioning from LLMs to SLMs, our system maintains remarkable robustness, with accuracy reductions ranging from just 0.8% to 20% across different scenarios. Notably, MiniRAG consistently achieves state-of-the-art performance in all evaluation settings, including tests on two comprehensive datasets with four different SLMs, while maintaining a lightweight footprint suitable for resource-constrained environments such as edge devices and privacy-sensitive applications. To support further research in this area, we also introduce LiHuaWorld, a comprehensive benchmark dataset specifically designed to evaluate lightweight RAG systems in realistic on-device scenarios, such as personal communication and local document retrieval.
通过对多个数据集和小型语言模型(SLM)进行广泛的实验,我们展示了MiniRAG的卓越性能。与现有的轻量级RAG系统相比,MiniRAG在使用仅占25%存储空间的情况下,效果提高了1.3到2.5倍。即使从LLM过渡到SLM,我们的系统依然保持了显著的鲁棒性,准确度的减少幅度在不同场景下仅为0.8%到20%。最值得注意的是,MiniRAG在所有评估设置中始终保持最先进的性能,包括在两个全面的数据集上对四种不同的SLM进行测试,同时保持适用于资源受限环境(如边缘设备和隐私敏感应用)的轻量级特性。为了促进该领域的进一步研究,我们还推出了LiHuaWorld,这是一个专门为评估在真实设备场景下(如个人通信和本地文档检索)中的轻量级RAG系统而设计的综合基准数据集。
MiniRAG 框架
In this section, we present the detailed architecture of our proposed MiniRAG framework. As illustrated in Fig.1, MiniRAG consists of two key components: (1) heterogeneous graph indexing (Sec.2.1), which creates a semantic-aware knowledge representation, and (2) lightweight graph-based knowledge retrieval (Sec.2.2), which enables efficient and accurate information retrieval.
在本节中,我们将详细介绍所提出的MiniRAG框架的架构。如图1所示,MiniRAG由两个关键组件组成:(1)异构图索引(第2.1节),用于创建语义感知的知识表示;(2)轻量级图结构知识检索(第2.2节),实现高效且准确的信息检索。
2.1 HETEROGENEOUS GRAPH INDEXING WITH SMALL LANGUAGE MODELS
2.1 基于小型语言模型的异构图索引
In resource-constrained RAG systems, Small Language Models (SLMs) face significant operational constraints that affect their effectiveness. These limitations primarily involve a reduced ability to extract and comprehend complex entity relationships and subtle contextual connections from raw text, as well as a diminished capacity to efficiently summarize large volumes of text and handle retrieved information containing noise and irrelevant content.
在资源受限的RAG(检索增强生成)系统中,小型语言模型(SLMs)面临显著的操作性限制,这些限制影响了其效果。主要体现在以下两方面:其一是从原始文本中提取和理解复杂实体关系及细微上下文关联的能力降低,其二是高效总结大量文本以及处理包含噪声和无关内容的检索信息的能力减弱。

图片的理解:
- Heterogeneous Graph Indexing(异构图索引)
输入文本:左侧输入的是一段非结构化文本,例如包含 Wi-Fi 密码、房屋规则等信息。
图结构:
Chunk Node(块节点):从文本中提取的语义单元。
Entity Node(实体节点):文本中的具体实体,如名称、地点、事件等。
Entity-Entity Edge(实体与实体之间的边):反映实体之间的关系。
Entity-Chunk Edge(实体与文本块之间的边):连接实体和相关语义单元。
目的:将文本转化为一个可操作的异构图结构,捕捉文本中的关系和语义信息。 - Lightweight Graph-Based Knowledge Retrieval(轻量化图知识检索)
Step 1: Query Semantic Mapping(查询语义映射):
输入查询语句(如图中的问题:“What does Briar remind everyone to bring to practice?”)。
系统会将查询映射到可能的答案类型(例如“事件”、“概念”等)以及相关的实体(如“Briar”、“practice”)。
Step 2: Topology-enhanced Graph Retrieval(拓扑增强的图检索):
系统根据查询语义和图的拓扑结构,发现关键的关系路径。
通过路径权重(如 ω = 0.36 或 1.07 等)来评估不同路径的重要性。 - Integration & Generation(整合与生成)
高分节点和边:通过检索确定哪些节点和边与查询最相关(用颜色标注)。
答案生成:结合高分节点和边的信息,系统生成最终答案。例如,答案是“Water Bottles”。
Figure 1: The MiniRAG employs a streamlined workflow built on key components, including heterogeneous graph indexing and lightweight graph-based knowledge retrieval. This architecture is designed to address the unique challenges faced by on-device RAG systems, optimizing for both efficiency and effectiveness.
图1:MiniRAG 采用了一个以关键组件为基础的简化工作流程,包括异构图索引和轻量化图知识检索。该架构旨在解决设备端 RAG 系统所面临的独特挑战,并在效率和效果之间实现优化。
As shown in Fig.2, a comparison between SLM (Phi-3.5-mini (Abdin et al., 2024)) and LLM (gpt-4o-mini (OpenAI, 2023)) highlights these limitations in practice. While both models can identify the “HOUSE RULES” entity, the SLM’s description lacks specific details and fails to capture the rules and purposes present in the original text (Limitation 1). Additionally, during the answering phase, SLMs struggle to locate relevant information within extensive contexts and are often distracted by irrelevant content, a challenge that LLMs do not face (Limitation 2).
如图2所示,将 SLM(Phi-3.5-mini (Abdin et al., 2024))与 LLM(gpt-4o-mini (OpenAI, 2023))进行比较,揭示了这些限制在实际中的表现。尽管两种模型都能够识别出“HOUSE RULES”实体,但 SLM 的描述缺乏具体细节,未能捕捉到原始文本中的规则和目的(限制1)。此外,在回答阶段,SLM 难以在广泛的上下文中定位相关信息,常常被无关内容分散注意力,而这种问题在 LLM 中并不存在(限制2)。

Figure 2: Compared to Large Language Models (LLMs), Small Language Models (SLMs) exhibit significant limitations during both the indexing and answering phases. On the left, SLMs produce noticeably lower-quality descriptions compared to LLMs. On the right, when processing the same input, SLMs struggle to identify relevant information within large contexts, whereas LLMs handle this task effectively. To address these challenges in resource-constrained RAG systems, MiniRAG is designed with the following objectives:
The indexing mechanism must extract key relationships and contextual connections from the data, compensating for the limited entity understanding and summarization capabilities of small models.
The indexing approach should condense retrieved content to include only the most query-relevant elements, minimizing distractions or misleading information that could hinder the small model’s ability to summarize and effectively denoise the retrieved data.
图2:与大型语言模型(LLMs)相比,小型语言模型(SLMs)在索引和回答阶段表现出显著的局限性。左图显示,SLMs 生成的描述质量明显低于 LLMs。右图显示,当处理相同输入时,SLMs 难以在大规模上下文中定位相关信息,而 LLMs 则能够有效完成此任务。为了有效应对资源受限的 RAG 系统中的这些挑战,MiniRAG 的设计目标包括:
索引机制应提取数据中的关键关系和上下文连接,以弥补小模型在实体理解和总结能力方面的不足。
索引方法应将检索到的内容浓缩为与查询最相关的元素,尽量减少可能干扰或误导小模型能力的无关信息,从而提升其总结能力并有效去噪检索内容。
To achieve the aforementioned goals, we propose a data indexing mechanism that generates a Semantic-Aware Heterogeneous Graph. This graph structure systematically integrates both text chunks and named entities extracted from raw text, creating a rich semantic network to facilitate precise information retrieval. The heterogeneous graph consists of the following components:
Nodes:
Text Chunk Nodes (Vc): Represent coherent segments of the original text that retain contextual integrity.
Entity Nodes (Ve): Key semantic elements extracted from text chunks, including events, locations, temporal references, and domain-specific concepts that serve as semantic anchors.
This dual-node design allows data chunks to directly participate in the retrieval process, ensuring the identification of contextually relevant content while mitigating information distortion caused by the small language model’s limited summarization capabilities.
Edges:
Entity-Entity Connections (Eα): Capture semantic relationships, hierarchical structures, and temporal or spatial dependencies between named entities.
Entity-Chunk Connections (Eβ): Link named entities to their corresponding textual contexts, preserving both contextual relevance and semantic coherence.
为了实现上述目标,我们提出了一种数据索引机制,生成一个语义感知的异构图(Semantic-Aware Heterogeneous Graph)。这种图结构系统性地整合了从原始文本中提取的文本块和命名实体,构建了一个丰富的语义网络,能够促进精准的信息检索。该异构图由以下组件构成:
节点(Nodes):
文本块节点(Vc):代表原始文本中保留上下文完整性的连贯片段。
实体节点(Ve):从文本块中提取的关键语义元素,包括事件、地点、时间参考以及领域特定概念,这些元素作为语义理解的核心锚点。
这种双节点设计使得数据块能够直接参与检索阶段,确保能够识别出最具上下文相关性的内容,同时有效缓解小型语言模型总结能力不足导致的信息失真问题。
边(Edges):
实体-实体连接(Eα):捕捉命名实体之间的语义关系、层次结构以及时间或空间上的依赖关系。
实体-文本块连接(Eβ):将命名实体与其对应的文本上下文连接起来,保留上下文的相关性和语义连贯性。
下面的文本涉及到公式,所以我导入到了mathauto中进行展示以及翻译(同时对部分内容进行了修改来保证可读性)



2.2 LIGHTWEIGHT GRAPH-BASED KNOWLEDGE RETRIEVAL
2.2 轻量级基于图的知识检索
In on-device Retrieval Augmented Generation (RAG) systems, device computational limitations and data privacy concerns restrict the use of powerful models—such as large language models and advanced text embedding models—necessitating reliance on smaller alternatives. Consequently, current pipelines heavily depend on LLMs for a comprehensive understanding of text semantics when computing embedding similarity for retrieval, yet these smaller models often struggle to capture the precise semantic nuances within lengthy texts, complicating accurate matching. To address these challenges, it is essential to reduce the complexity of input content for generation, ensuring that semantic information is clear and concise, and to shorten the length of input content for smaller language models, thereby facilitating improved comprehension and retrieval accuracy. Additionally, employing effective graph indexing structures can help mitigate performance deficiencies in semantic matching, ultimately enhancing the overall retrieval process. In MiniRAG, we propose a Graph-based Knowledge Retrieval mechanism that leverages a semantic-aware heterogeneous graph G constructed during the indexing phase, in conjunction with lightweight text embeddings, to achieve efficient knowledge retrieval; by employing a graph-based search design, we aim to ease the burden on precise semantic matching with large language models, facilitating the acquisition of rich and accurate textual content at a low computational cost and enhancing the ability of language models to generate precise responses.
在设备端增强检索生成(RAG)系统中,由于设备计算能力受限和数据隐私问题,无法使用大型语言模型和先进文本嵌入模型等强大模型,因此只能依赖较小的替代方案,而现有的管道主要依赖大型语言模型对文本语义的全面理解来计算嵌入相似度进行检索,面临着较小模型难以捕捉长文本中精细语义差异而导致匹配不准确的重大挑战。为了解决这些问题,需要一方面降低生成输入内容的复杂性,使语义信息清晰简洁,另一方面缩短输入文本长度,从而使较小的语言模型能更好地理解并提高检索准确性。此外,采用有效的图索引结构有助于缓解语义匹配性能不足的问题,从而提升整体检索效果。基于此,在 MiniRAG 中,我们提出了一种基于图的知识检索机制,该机制利用在索引阶段构建的语义感知异构图 G,并结合轻量级文本嵌入,实现高效的知识检索;通过采用基于图的搜索设计,我们旨在减轻大型语言模型对精确语义匹配的依赖,从而以较低的计算成本获取丰富而准确的文本内容,并增强语言模型生成精准回答的能力。
2.2.1 QUERY SEMANTIC MAPPING
2.2.1 查询语义映射
In the retrieval phase, the primary goal for a user-input query q is to identify elements related to the query (e.g., text chunks) from the constructed index data, thereby aiding the model in generating accurate responses. To achieve this, it is essential to first parse the query and align it with the index data. Some prior RAG methods utilize LLMs to expand or decompose the query into fine-grained queries (Chan et al., 2024; Edge et al., 2024a; Guo et al., 2024), enhancing the match between the query and the index data. However, this process relies on LLMs to extract high-quality abstract information from the query, which poses challenges for smaller language models. Therefore, in the retrieval process of MiniRAG, we leverage entity extraction—a relatively simple and effective task for small language models—to facilitate the decomposition and mapping of the query
q to our graph-based indexing data (i.e., the semantic-aware heterogeneous graph G).
在检索阶段,用户输入的查询 q 的主要目标是从已构建的索引数据中识别与查询相关的元素(例如文本块),从而帮助模型生成准确的回答。为实现这一目标,必须先对查询进行解析并与索引数据对齐。一些先前的 RAG 方法(Chan 等,2024;Edge 等,2024a;Guo 等,2024)利用大型语言模型来扩展或分解查询为更细粒度的查询,从而增强查询与索引数据之间的匹配。然而,这一过程依赖大型语言模型从查询中提取高质量的抽象信息,对于规模较小的语言模型而言十分困难。因此,在 MiniRAG 的检索过程中,我们利用实体抽取——这对于小型语言模型而言相对简单而有效——来辅助对查询 q 的分解与映射,并将其映射到我们的图索引数据(即语义感知的异构图 G)。



个人理解非完全翻译
查询驱动的推理路径发现:在一张能够反映语义信息的异构图中,我们通过查询引导的方式构建推理路径。对于任何给定的查询,模型需要同时考虑两个核心要点:其一是查询与实体节点之间的语义相关性,其二是实体与实体、实体与文本块之间的结构连贯性。这样一来,模型不仅能突出查询和实体节点之间的紧密联系,同时也能保留实体-实体和实体-文本块之间的关系,从而捕捉图中更加复杂的推理链。在这一框架下,推理路径的发现主要包括以下步骤:
1.初始实体识别:先从查询中提取实体,并将这些实体与图中的节点进行匹配,以找到可信的起始点,为后续的路径探索奠定基础。
2.面向答案的实体选择:根据系统预测得到的答案类型,从初始阶段选出的节点中进一步挑选出更有可能成为“答案节点”的候选实体,使得推理过程能够围绕目标答案类型展开。
3.富上下文路径构建:在完成上述实体筛选后,进一步将与这些节点相关的文本信息整合进推理路径中,从而形成完整且具有证据链的推理过程,最终实现从查询实体到潜在答案的连接。
这一轻量级方法既能保证高效性,又能在较为复杂的场景下维持语义上的准确度,非常适合在计算资源有限的边缘设备上部署。后续的搜索算法部分将讨论如何通过对节点或路径的重要性排序,进一步优化并完善推理路径。
2.2.2 TOPOLOGY-ENHANCED GRAPH RETRIEVAL
2.2.2 拓扑增强的图检索
To address the fundamental limitations of small language model-based methods in knowledge retrieval, we propose a topology-aware retrieval approach that effectively combines semantic and structural information from heterogeneous knowledge graphs. Approaches relying on small language models with limited semantic understanding often introduce substantial noise into the retrieval process due to their constrained ability to capture nuanced meanings, contextual variations, and complex entity relationships within real-world knowledge graphs. Our method overcomes these inherent challenges through a carefully designed two-stage process that synergistically leverages both embedding-based similarities and the topological structure of the knowledge graph.


为了解决小型语言模型在知识检索中的根本局限性,我们提出了一种结合语义与结构信息的“拓扑感知检索”方法。由于小型语言模型的语义理解能力较为有限,在应对真实世界知识图中各种含义微妙、上下文多变以及实体关系复杂的情况时,往往会引入大量噪声。我们的方法通过精心设计的两阶段流程,将基于嵌入的相似度匹配与知识图的拓扑结构结合起来,从而有效应对上述挑战。
在第一阶段,我们先基于嵌入相似度来确定初始的“起始实体”和“答案实体”,也可以简单理解为和查询最相关的节点。接下来进入“拓扑增强”的第二阶段,我们利用异构知识图的结构特性,发掘潜在的推理路径,并综合考虑实体之间的关联度、关键关系的重要性以及路径的连贯性来提高检索的精准度和解释性。
具体来说,“关键关系识别”主要关注图中与查询紧密关联的实体-实体连接,通常需要找出从起始节点到答案节点的最短路径附近的高价值边或关系;“查询引导的路径发现”则通过一系列无环路径,系统性地搜索从起始实体延伸至可能答案实体的合理链路,兼顾对先前已识别关键关系的利用;在“检索相关文本片段”步骤里,我们根据实体和文本块之间的关联,提取并筛选与查询最匹配的文本内容,以进一步提升整体检索效果;最后,“整合用于增强生成”会将上述所得的关键关系、文本片段和对应的答案节点统一构造成结构化输入,以便在最终的回答生成中更加精准且可解释。
通过这样分层次、分步骤的检索策略,我们在保持计算效率的同时,能够显著提升对查询相关信息的捕捉能力,并挖掘到更具深度的推理链,为小型语言模型在边缘设备上的增强生成提供了高质量的支持。