什么是爬虫?程序蜘蛛,沿着互联网获取相关信息,收集目标信息。
一、python环境安装
1、先从Download Python | Python.org中下载最新版本的python解释器
2、再从Download PyCharm: Python IDE for Professional Developers by JetBrains中下载community版本的pycharm(免费且够用)
pycharm安装中文插件(安装后重启pycharm即可)
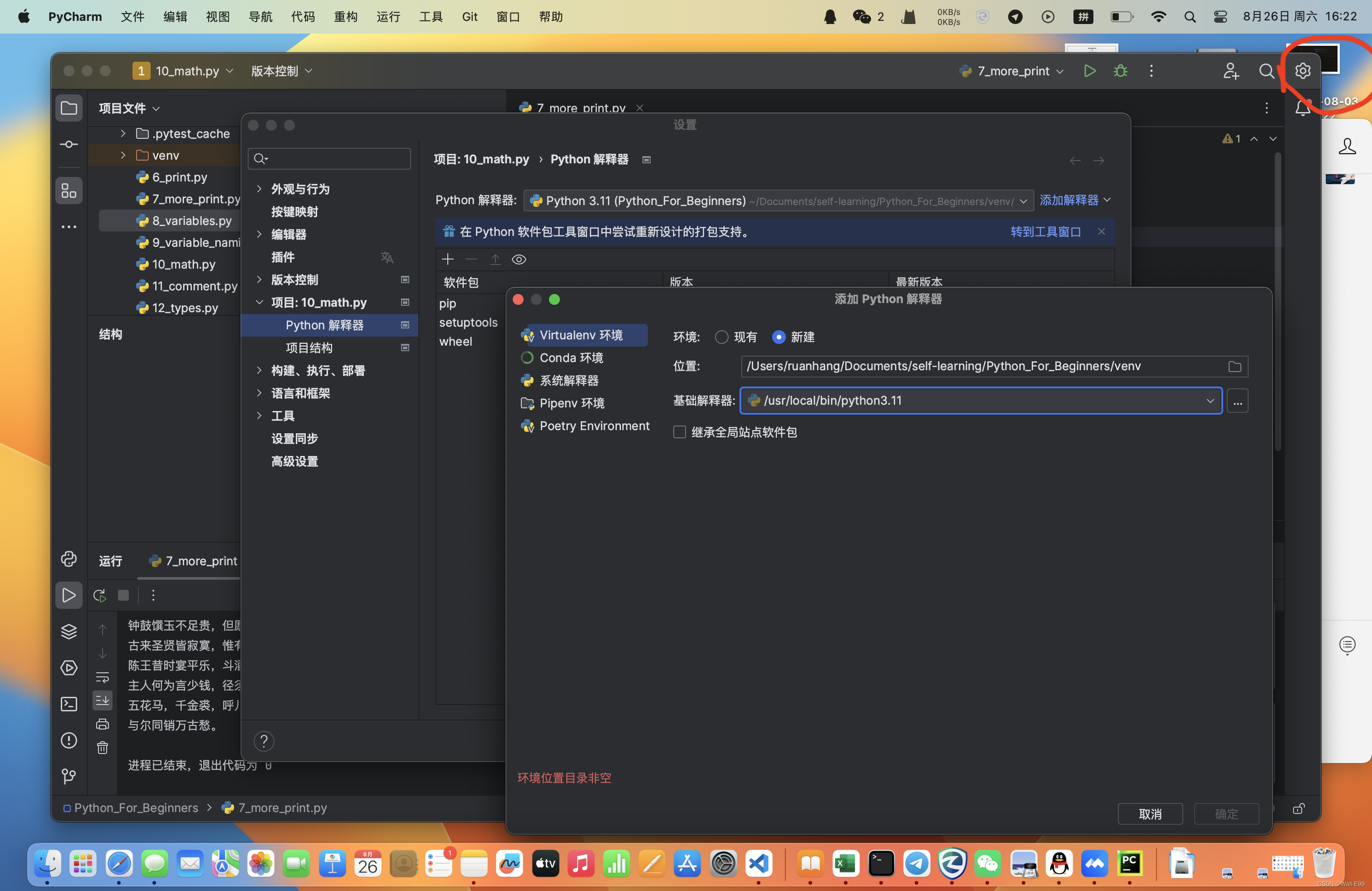
3、如果向博主一样需要直接打开文件运行,可能需要添加一下解释器
二 爬虫的流程
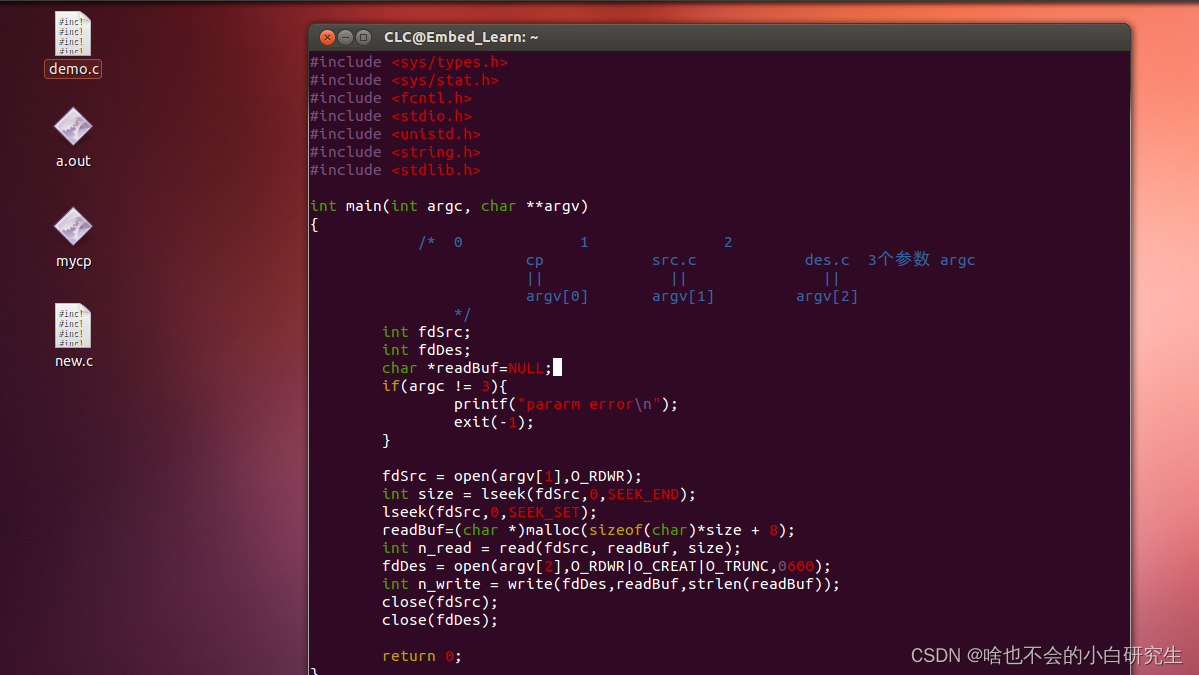
1、获取网页内容(浏览器会将内容渲染成更直观的页面,而程序获得的网页是一串代码)
http请求(python request实现)
2、解析网页内容(在全面的内容中把想要的数据提取出来)
html格式 (python Beautiful Soup库)
3、储存或分析数据
注意事项
1、请求数量和频率不要太高(无异于DDoS攻击)
2、有反爬限制(例如验证码)就不要强行突破
三、什么事HTTP请求和响应
HTTP(Hypertext Transfer Protocol超文本传输协议)
HTTP请求
GET方法:获得数据
POST方法:创建数据
七、什么是HTML网页结构
网页三大要素:
(1)HTML定义网页的结构和信息(爬虫最需要关心的)
(2)CSS 定义网页的样式 //网站背景 样式
(3)JavaScript 定义用户和网页的交互逻辑
<!DOCTYPE HTML>
<html><body><h1>这是一个标题</h1><p>这是一段文字这是一段文字这是一段文字<p></body>
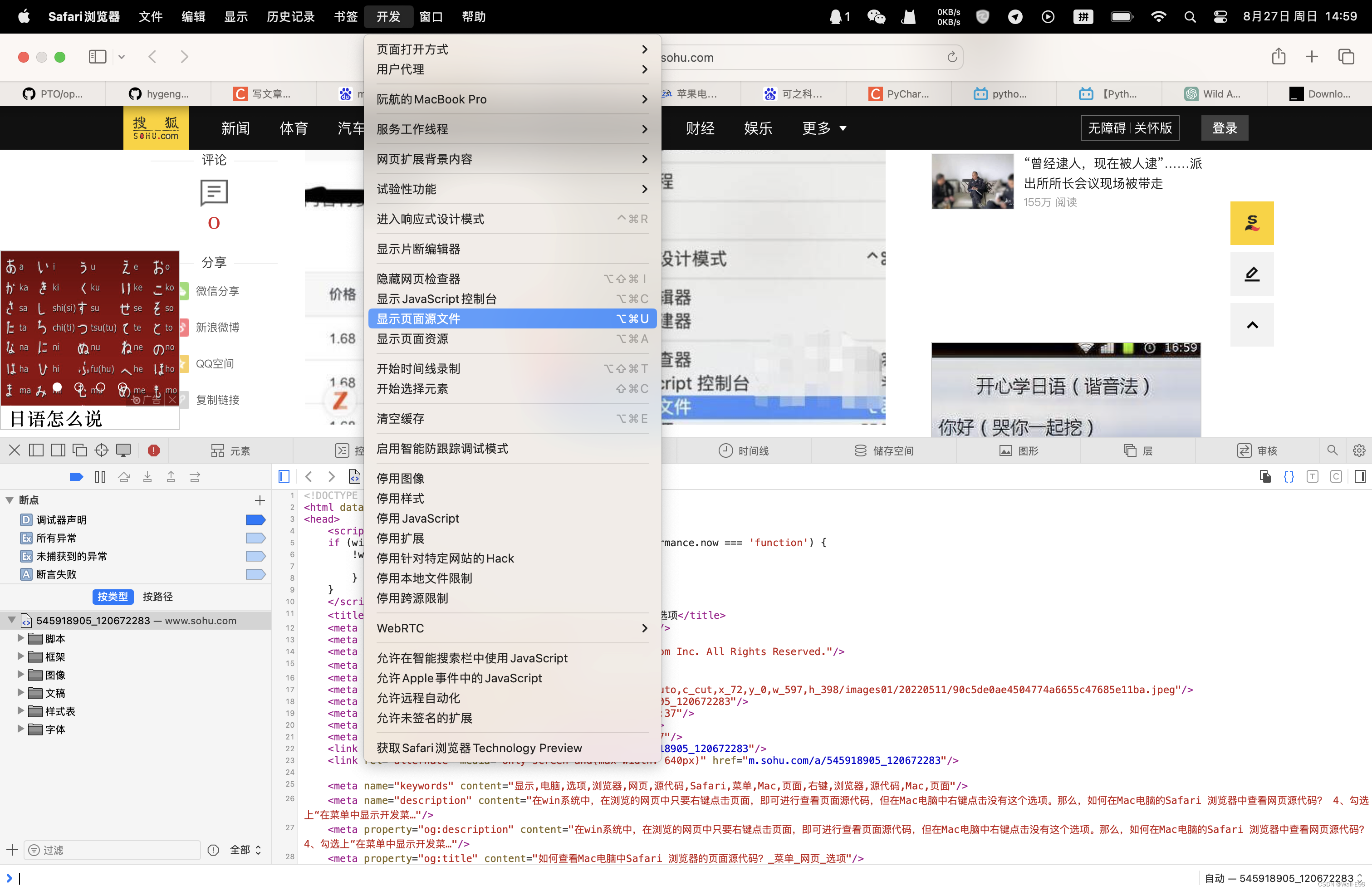
<!html>显示网页源代码
mac用户 先在safari高级选项中设置,然后在开发中打开
七、HTML常见标签
7.1 标题 数字越小,字号越大
<h1> 这是一个一级标题 </h1>
<h2> 这是一个二级标题 </h2>
<h3> 这是一个三级标题 </h3>
<h4> 这是一个四级标题 </h4>
<h5> 这是一个五级标题 </h5>
<h6> 这是一个六级标题 </h6>
7.2 文本段落
<p>给岁月<br>以文明</p>
<p>而不是给文明以岁月</p>
<br> //是强制换行
<b> </b> //加粗
<i> </i> //斜体
<u> </u> //下划线
<img src="链接" width=“500px”> //图片
<a href="https://...">我的主页</a> //超链接7.3 容器
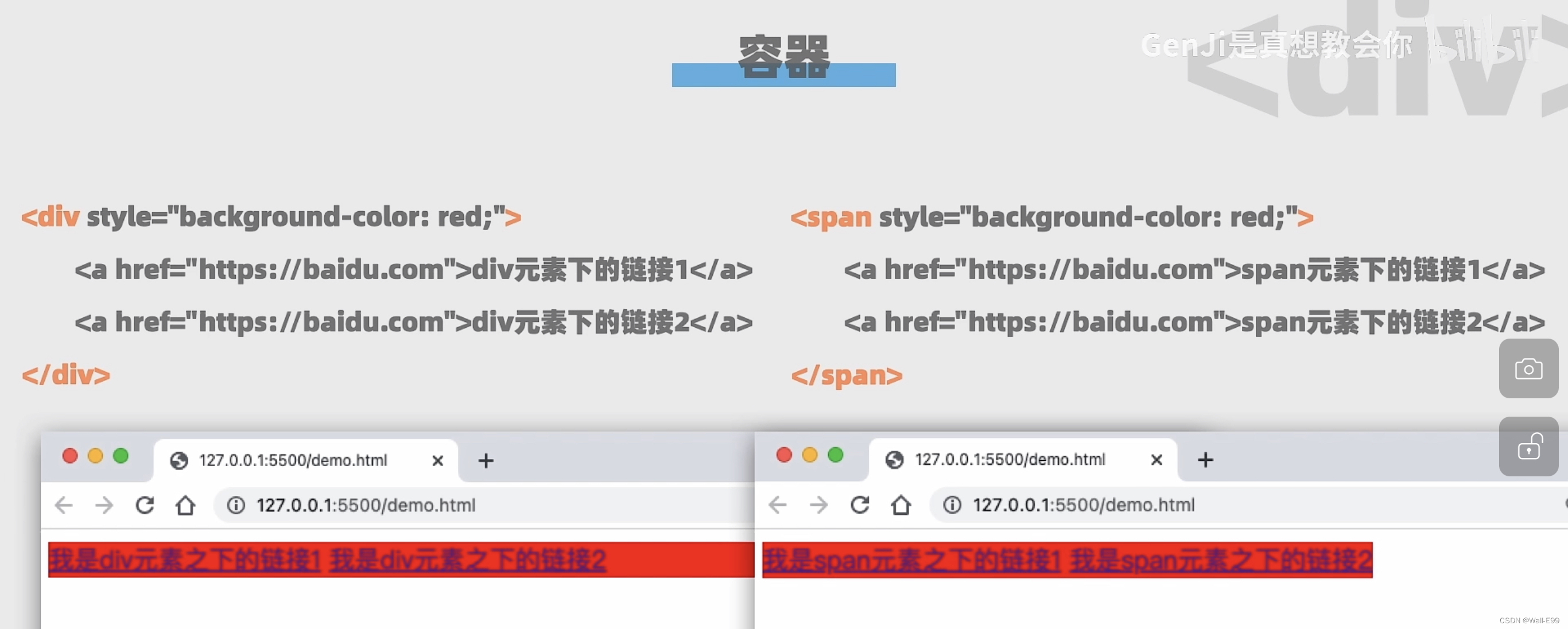
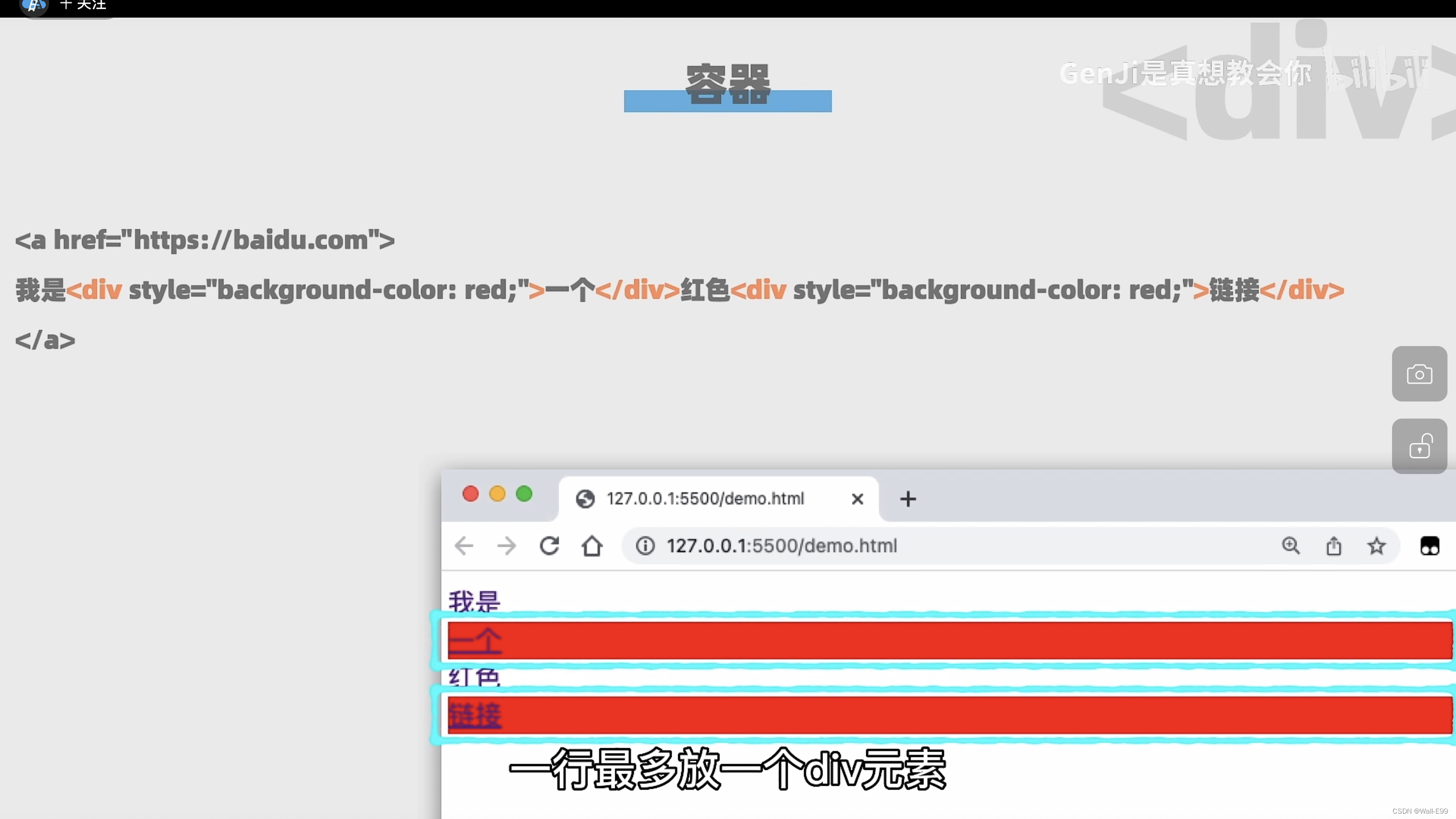
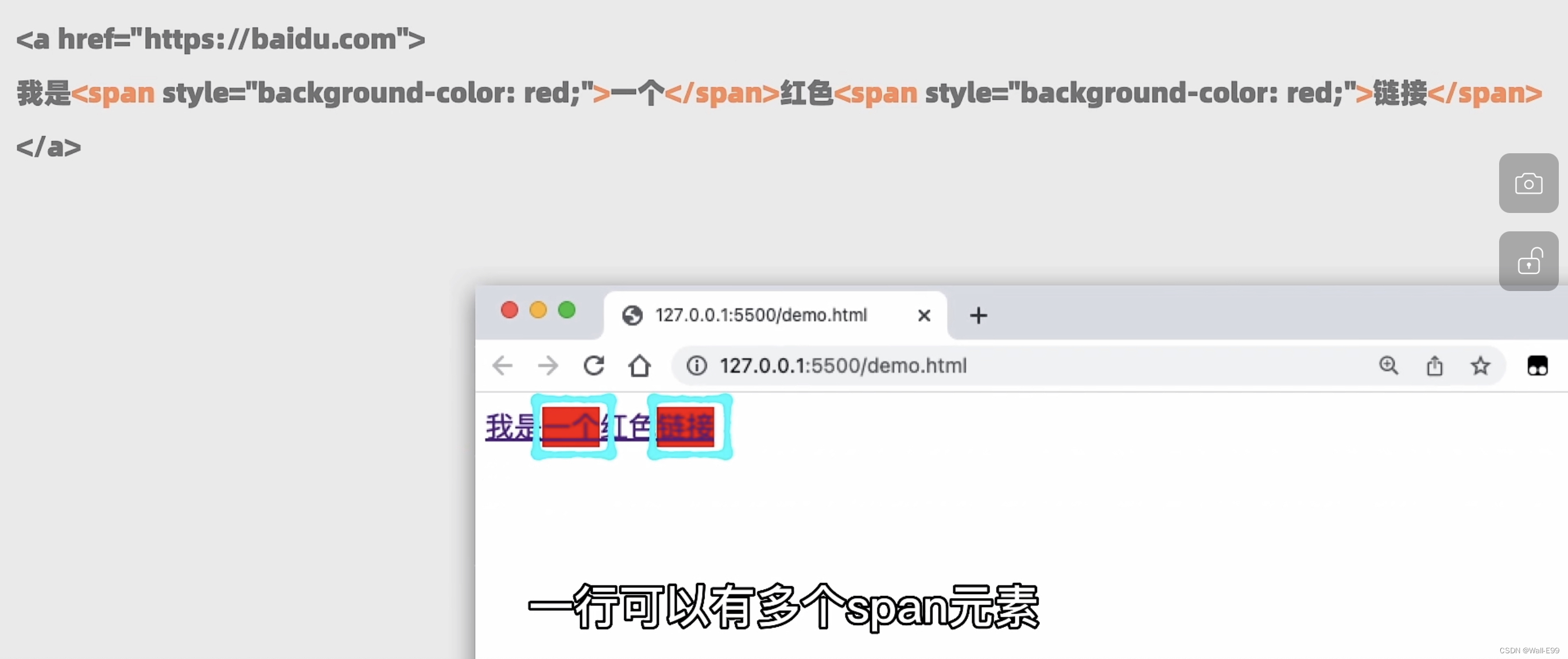
7.4 有序列表ordered list/无序列表unordered list
<ol> //有序列表<li>语文</li><li>数学</li><li>英语</li>
</ol><ul> //无序列表<li>语文</li><li>数学</li><li>英语</li>
</ul>7.5 表格行
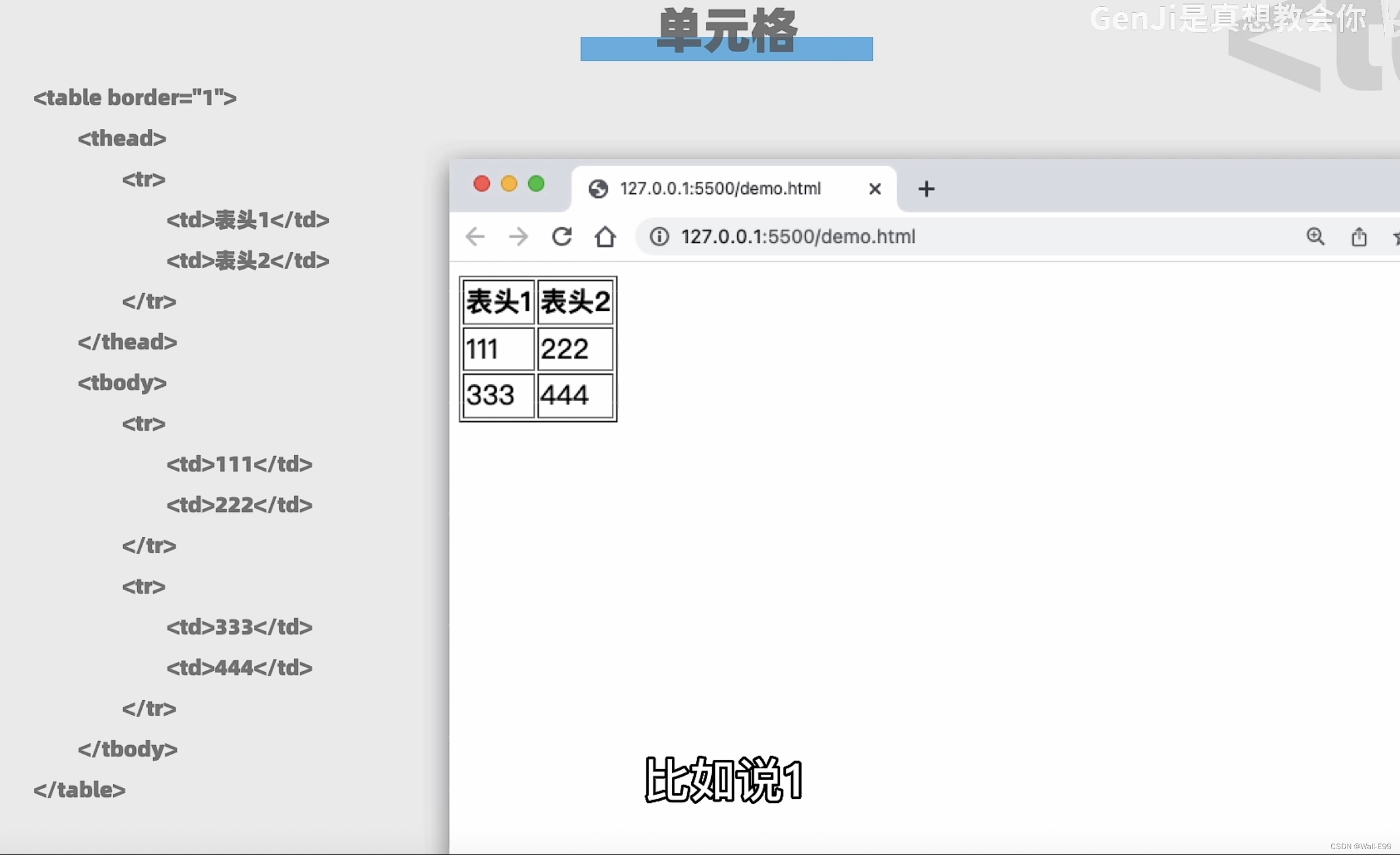
7.6 class属性








![[QT]设置程序仅打开一个,再打开就唤醒已打开程序的窗口](https://img-blog.csdnimg.cn/8e3c0d6e8cdb4c55a80a3fe2ef116a80.gif)