1. 上传小文件到集群
在hadoop路径下执行命令创建一个文件夹用于存放即将上传的文件:
[atguigu@hadoop102 ~]$ hadoop fs -mkdir /input
上传:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/work.txt /input




2.上传大文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /input


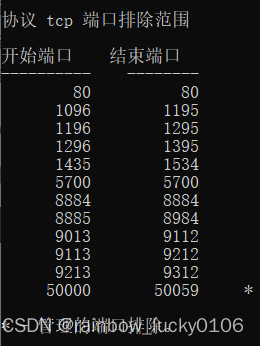
注意:数据文件实际存在是在hadoop安装路径的data节点下
3 查看HDFS文件存储路径

4. 让yarn执行一个计算操作
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /wcoutput
注意:次数的/input是集群路径,就是页面中出现的那个路径,